文章目录
- 引言
- 一、为什么需要持久化ChatMemory
-
- [1.1 内存存储的局限性](#1.1 内存存储的局限性)
- [1.2 持久化的优势](#1.2 持久化的优势)
- 二、依赖引入
-
- [2.1 Maven依赖配置](#2.1 Maven依赖配置)
- 三、配置详解
-
- [3.1 数据源配置](#3.1 数据源配置)
- [3.2 ChatMemory JDBC配置](#3.2 ChatMemory JDBC配置)
- [3.3 完整配置示例](#3.3 完整配置示例)
- 四、代码改造
-
- [4.1 只需改一个Bean](#4.1 只需改一个Bean)
- [4.2 无缝使用](#4.2 无缝使用)
- [4.3 迁移影响分析](#4.3 迁移影响分析)
- 五、自动配置机制
-
- [5.1 Spring Boot自动配置如何发现并注入JdbcChatMemoryRepository](#5.1 Spring Boot自动配置如何发现并注入JdbcChatMemoryRepository)
- [5.2 自动配置的优势](#5.2 自动配置的优势)
- 六、数据库表结构分析
-
- [6.1 自动建表机制](#6.1 自动建表机制)
- [6.2 表结构字段详解](#6.2 表结构字段详解)
- [6.3 索引策略分析](#6.3 索引策略分析)
- [6.4 表结构的存储特性](#6.4 表结构的存储特性)
- [6.5 真实数据示例](#6.5 真实数据示例)
- 七、工作流程详解
- 八、关键实现细节
-
- [8.1 MessageWindowChatMemory的窗口机制](#8.1 MessageWindowChatMemory的窗口机制)
- [8.2 Conversation ID隔离](#8.2 Conversation ID隔离)
- [8.3 自动初始化表结构](#8.3 自动初始化表结构)
- 九、生产环境最佳实践
-
- [9.1 数据源配置](#9.1 数据源配置)
- [9.2 initialize-schema策略](#9.2 initialize-schema策略)
- [9.3 定期备份和清理](#9.3 定期备份和清理)
- [9.4 监控和告警](#9.4 监控和告警)
- 十、troubleshooting常见问题
- 十一、总结
引言
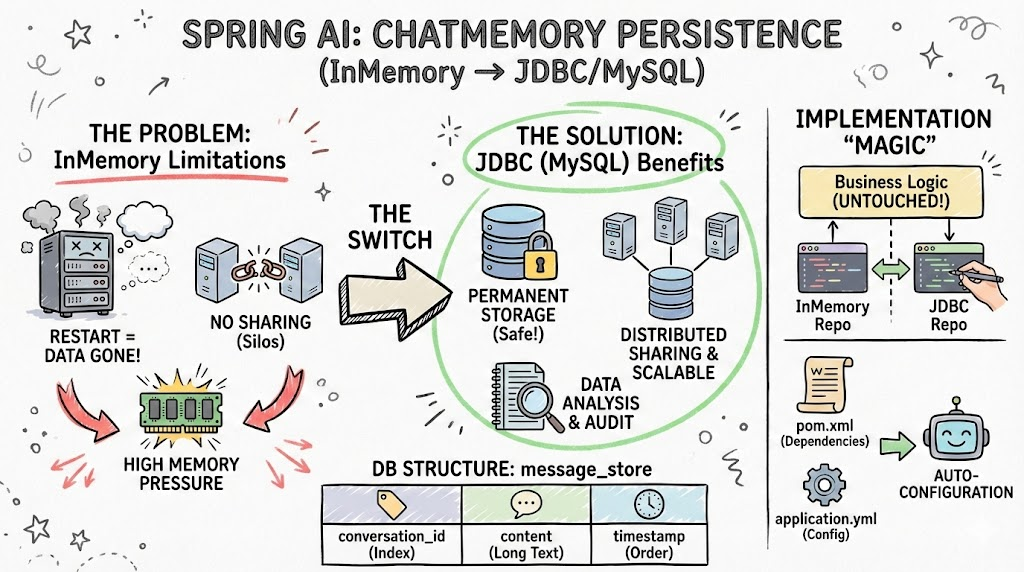
在构建AI对话应用时,对话历史(Chat Memory)的管理至关重要。Spring AI提供的ChatMemory组件能够帮助开发者轻松实现多轮对话能力,让大模型能够记住之前的对话内容,进而提供更连贯、更具上下文感知的回复。
然而,默认的内存存储(InMemoryChatMemoryRepository)存在明显的局限性:应用重启时数据丢失,无法跨实例共享,难以应对生产环境需求。这正是本篇文章的核心议题------如何将ChatMemory持久化到MySQL数据库中。
通过这篇文章,你将学会:
- 理解为什么需要持久化ChatMemory
- 掌握Spring AI JDBC ChatMemoryRepository的工作原理
- 学习从InMemory到JDBC的平滑迁移过程
- 深入理解Spring Boot自动配置的魔力
- 了解数据库表结构的设计
一、为什么需要持久化ChatMemory
1.1 内存存储的局限性
让我们先回顾一下之前使用的InMemory存储方式:
java
@Bean
public ChatMemory chatMemory() {
InMemoryChatMemoryRepository inMemoryChatMemoryRepository = new InMemoryChatMemoryRepository();
return MessageWindowChatMemory.builder()
.chatMemoryRepository(inMemoryChatMemoryRepository)
.build();
}看似简洁的代码,却隐藏着几个严重问题:
问题1:应用重启数据丢失
- 所有对话历史存储在JVM内存中
- 应用停止运行,所有对话记录立即消失
- 用户无法恢复之前的对话上下文
- 在部署新版本、扩容缩容等运维操作时,用户体验中断
问题2:无法跨实例共享
- 在微服务或负载均衡场景中,多个应用实例各自维护独立的内存
- 用户A的对话数据存在实例1中,但路由到实例2时,就无法访问该数据
- 导致多轮对话中断
- 特别是在kubernetes环境中,Pod重启是常见操作,内存数据会完全丢失
问题3:内存压力大
- 长期运行的应用,对话历史不断积累
- JVM内存占用持续增长,可能导致OOM异常
- 没有自然的过期机制清理旧数据
- 每个用户的对话都存储在内存中,数百个并发用户会消耗大量堆内存
问题4:无法进行数据分析
- 对话记录无法持久化,无法进行用户行为分析
- 无法构建对话数据仓库
- 难以优化模型和提升服务质量
- 无法进行A/B测试、用户路径分析等数据驱动的决策
问题5:缺乏审计能力
- 在医疗、金融等受监管行业,必须保留完整的审计日志
- 内存存储无法满足合规性要求
- 无法追溯用户操作历史和系统决策过程
1.2 持久化的优势
采用MySQL存储后,这些问题迎刃而解:
-
数据持久性:对话记录永久保存,支持应用重启后恢复
- 用户可以在任何时间点恢复之前的对话上下文
- 支持灾备和数据恢复
-
分布式共享:多个应用实例可共享同一数据库中的对话数据
- 支持水平扩展,轻松应对高并发场景
- 用户请求可以负载均衡到任意实例,不影响对话连续性
-
灵活扩展:可实现多租户、权限控制、数据隔离等功能
- 支持企业级功能需求
- 便于实现细粒度的访问控制
-
数据分析:积累长期数据,支持用户行为分析和模型优化
- 通过分析用户对话数据优化模型prompt
- 识别用户常见问题,优化知识库和FAQ
- 量化产品改进的效果
-
合规性:满足审计日志和数据留存的合规性要求
- 支持医疗、金融等受监管行业的法律要求
- 完整的审计追溯链
- 支持数据导出和隐私保护
二、依赖引入
2.1 Maven依赖配置
在pom.xml中添加以下依赖:
xml
<!-- Spring AI JDBC ChatMemory Repository -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<!-- MySQL JDBC驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>依赖说明:
spring-ai-starter-model-chat-memory-repository-jdbc:Spring AI提供的JDBC实现,包含自动配置和表初始化逻辑mysql-connector-java 8.0.33:MySQL Java驱动程序,确保与数据库的连接
这两个依赖是实现JDBC ChatMemory的最小必要配置。
三、配置详解
3.1 数据源配置
在application.yml中配置数据源连接:
yaml
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/my_db?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&allowMultiQueries=true&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: artisan123456...连接字符串参数解释:
| 参数 | 说明 |
|---|---|
useUnicode=true |
使用Unicode编码,确保中文正常存储 |
characterEncoding=utf-8 |
字符集为UTF-8,支持中文和其他Unicode字符 |
zeroDateTimeBehavior=convertToNull |
MySQL中0000-00-00转换为null,避免异常 |
transformedBitIsBoolean=true |
MySQL BIT类型映射为Java boolean |
allowMultiQueries=true |
允许多条SQL语句一起执行 |
allowPublicKeyRetrieval=true |
允许使用公钥检索进行认证 |
useSSL=false |
不使用SSL连接(开发环境) |
serverTimezone=Asia/Shanghai |
设置时区为上海,避免时间错位 |
3.2 ChatMemory JDBC配置
yaml
spring:
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: always配置参数:
| 参数 | 可选值 | 说明 |
|---|---|---|
initialize-schema |
always / never / create-if-missing |
always:每次启动时重建表结构;never:从不初始化;create-if-missing:表不存在时创建 |
推荐配置策略:
- 开发环境:使用
always,每次启动都重新初始化,确保表结构最新 - 测试环境:使用
create-if-missing,只在首次运行时创建 - 生产环境:使用
never,由DBA负责初始化和维护表结构
3.3 完整配置示例
yaml
spring:
# 数据源配置
datasource:
url: jdbc:mysql://127.0.0.1:3306/my_db?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&allowMultiQueries=true&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: artisan123456...
# AI配置
ai:
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${DASHSCOPE_API_KEY}
chat:
options:
model: qwen3-max
# ChatMemory JDBC配置
chat:
memory:
repository:
jdbc:
initialize-schema: always
server:
port: 8081四、代码改造
4.1 只需改一个Bean
Spring AI的优秀架构设计体现在这里:从InMemory切换到JDBC,只需修改一个Bean定义,无需改动任何业务代码。
Before(使用InMemory):
java
@Bean
public ChatMemory chatMemory() {
InMemoryChatMemoryRepository inMemoryChatMemoryRepository = new InMemoryChatMemoryRepository();
return MessageWindowChatMemory.builder()
.chatMemoryRepository(inMemoryChatMemoryRepository)
.build();
}After(使用JDBC):
java
@Bean
public ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.build();
}只改动两处:
- 删除
InMemoryChatMemoryRepository inMemoryChatMemoryRepository = new InMemoryChatMemoryRepository();这一行 - 在方法参数中添加
JdbcChatMemoryRepository chatMemoryRepository,让Spring自动注入
这正是依赖注入和接口抽象的威力------ChatMemoryRepository是抽象接口,具体实现可以自由切换,业务代码完全不受影响。
这体现了SOLID设计原则中的依赖倒置原则(DIP):高层模块(业务层)依赖于抽象接口(ChatMemoryRepository),而不是依赖于具体实现。这样做的好处是:
- 灵活性:可以轻松切换不同的存储实现(InMemory、JDBC、Redis等)
- 可测试性:单元测试时可以注入mock实现
- 可维护性:存储实现变化不影响业务代码
- 可扩展性:未来可以添加新的存储实现而无需修改现有代码
4.2 无缝使用
业务层代码完全无需改动。例如,在Controller中使用ChatMemory:
java
@Autowired
private ChatMemory chatMemory;
@GetMapping("/memory")
public String memory(@RequestParam("chatId") String chatId,
@RequestParam("question") String question) {
return chatClient
.prompt()
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.advisors(advisorSpec -> advisorSpec.params(
Map.of(ChatMemory.CONVERSATION_ID, chatId)))
.user(question)
.call()
.content();
}这段代码在InMemory和JDBC之间切换时,一行都不需要改。这就是良好的抽象设计的价值所在。
4.3 迁移影响分析
当从InMemory迁移到JDBC时:
第一次启动时的行为变化:
- InMemory:立即可用,无任何初始化
- JDBC:数据库必须存在,
initialize-schema: always时会自动创建表结构
对话数据的处理:
- InMemory:旧数据完全丢失,数据库中是空的
- JDBC:需要考虑是否需要导入旧数据(通常需要一次性数据迁移)
性能特性:
- InMemory:本地访问,纳秒级延迟,无网络开销
- JDBC:涉及数据库往返,毫秒级延迟,需要网络连接
- 在高并发场景下,JDBC的性能可能略低,但可以通过连接池、缓存等手段优化
故障模式:
- InMemory:应用crash则数据丢失,但数据库无故障点
- JDBC:数据库故障会导致对话功能不可用,需要实现数据库故障处理和降级方案
五、自动配置机制
5.1 Spring Boot自动配置如何发现并注入JdbcChatMemoryRepository
当我们在pom.xml中添加spring-ai-starter-model-chat-memory-repository-jdbc依赖后,Spring Boot的自动配置机制会自动发现并应用相关配置。
这个过程包含几个关键步骤:
第一步:classpath扫描
- Spring Boot启动时扫描classpath下所有jar包中的
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件 spring-ai-starter-model-chat-memory-repository-jdbc包含该文件,指向JDBC ChatMemory的自动配置类
第二步:自动配置类加载
- 自动配置类(如
JdbcChatMemoryRepositoryAutoConfiguration)被Spring加载 - 该类包含条件判断,确保存在必要的配置和依赖
第三步:条件判断
java
@Configuration
@ConditionalOnClass(JdbcChatMemoryRepository.class)
@ConditionalOnProperty(
prefix = "spring.ai.chat.memory.repository.jdbc",
name = "initialize-schema",
havingValue = "always|create-if-missing|never"
)
public class JdbcChatMemoryRepositoryAutoConfiguration {
// ...
}@ConditionalOnClass:classpath中必须存在JdbcChatMemoryRepository类@ConditionalOnProperty:application.yml中必须配置spring.ai.chat.memory.repository.jdbc.initialize-schema
第四步:Bean创建
当所有条件满足时,自动配置类创建以下Bean:
java
@Bean
@ConditionalOnMissingBean
public JdbcChatMemoryRepository chatMemoryRepository(
JdbcOperations jdbcOperations,
JdbcChatMemoryRepositoryProperties properties) {
return new JdbcChatMemoryRepository(jdbcOperations, properties);
}JdbcOperations:Spring提供的JDBC操作工具JdbcChatMemoryRepositoryProperties:从配置文件读取的属性
第五步:依赖注入
我们定义的Bean方法:
java
@Bean
public ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
// ...
}Spring检测到参数JdbcChatMemoryRepository,自动注入刚才创建的Bean。
5.2 自动配置的优势
这套机制的优雅之处在于:
- 零配置:不需要额外的@Configuration类或@Bean方法来创建JdbcChatMemoryRepository
- 约定优于配置:遵循命名约定和配置前缀,自动完成配置
- 条件装配:只有当依赖和配置都存在时才自动装配
- 易于覆盖:定义同类型的Bean可以覆盖自动配置
六、数据库表结构分析
6.1 自动建表机制
当应用启动且initialize-schema: always时,Spring AI会自动执行初始化脚本。让我们看看生成的表结构:
sql
CREATE TABLE message_store (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
conversation_id VARCHAR(255) NOT NULL,
message_type VARCHAR(50) NOT NULL,
content LONGTEXT NOT NULL,
timestamp BIGINT NOT NULL,
INDEX idx_conversation_id (conversation_id),
INDEX idx_timestamp (timestamp)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;这个表结构遵循了数据库设计最佳实践:
- InnoDB引擎:提供ACID事务支持,确保数据一致性
- utf8mb4字符集:完全支持Unicode,包括表情符号等扩展字符
- 自增主键:保证消息的全局唯一性和顺序性
- 索引策略:在高频查询字段上建立索引,提高查询性能
6.2 表结构字段详解
| 字段名 | 类型 | 说明 | 索引 |
|---|---|---|---|
id |
BIGINT AUTO_INCREMENT PRIMARY KEY | 消息全局唯一标识,自增主键 | 是 |
conversation_id |
VARCHAR(255) NOT NULL | 对话会话ID,用于隔离不同用户/会话的对话记录 | 是 |
message_type |
VARCHAR(50) NOT NULL | 消息类型:USER(用户消息)或 ASSISTANT(模型回复) | 否 |
content |
LONGTEXT NOT NULL | 消息内容,支持长文本 | 否 |
timestamp |
BIGINT NOT NULL | 消息时间戳,毫秒级精度 | 是 |
字段设计的考虑:
- id字段:使用BIGINT而非INT,预留充足空间。假设每秒1000条消息,10年可容纳约3.1亿条记录,远未达到BIGINT上限
- conversation_id:VARCHAR(255)足够存储UUID或其他常见的会话ID格式
- message_type:枚举类型,只有两个值USER和ASSISTANT,但使用VARCHAR便于future扩展(如SYSTEM消息)
- content:使用LONGTEXT支持长对话内容,理论上可存储4GB的文本
- timestamp:BIGINT毫秒级精度,足以应对高频事件和时间排序需求
6.3 索引策略分析
idx_conversation_id索引的作用:
- 加速按conversation_id的查询
- 业务逻辑中最频繁的查询就是"获取某个会话的所有消息"
- 通过该索引,数据库可以快速定位到属于某个会话的所有行
idx_timestamp索引的作用:
- 支持按时间范围查询
- 便于实现消息老化和清理策略
- 支持分析最近N小时/天的对话趋势
为什么content不建立索引:
- content字段类型是LONGTEXT,建立索引会占用大量存储空间
- 业务逻辑中不会按content内容进行查询,只是读取展示
- 建立索引带来的收益远小于成本
6.4 表结构的存储特性
java
// 数据流动过程
用户消息 → MessageWindowChatMemory → JdbcChatMemoryRepository
↓
INSERT INTO message_store (conversation_id, message_type, content, timestamp)
VALUES (?, ?, ?, ?)
// 读取过程
按conversation_id查询 → SELECT * FROM message_store
WHERE conversation_id = ? ORDER BY timestamp DESC LIMIT ?Spring AI的JdbcChatMemoryRepository会自动处理以下逻辑:
- 消息保存:每条消息(用户消息和AI回复都是独立的消息)都会INSERT一次
- 消息查询:按conversation_id和时间戳排序获取消息
- 消息去重:Spring AI内部会处理重复消息的情况
- 批量操作:在高并发情况下,可能会进行批量插入优化
6.5 真实数据示例
假设用户chatId为"user123"进行对话,表中的数据可能是这样的:
| id | conversation_id | message_type | content | timestamp |
|---|---|---|---|---|
| 1 | user123 | USER | 你好,请介绍一下Spring AI | 1700000000000 |
| 2 | user123 | ASSISTANT | 你好!Spring AI是Spring框架的AI扩展...(完整回复) | 1700000001000 |
| 3 | user123 | USER | 如何使用ChatMemory实现多轮对话? | 1700000002000 |
| 4 | user123 | ASSISTANT | 在Spring AI中,ChatMemory用于存储...(完整回复) | 1700000003000 |
通过按conversation_id分组,可以轻松实现多个独立的对话会话。
性能考虑:
- 表中数据量可能快速增长,随着时间推移会达到百万级甚至千万级
- 需要定期执行ANALYZE TABLE以更新统计信息
- 考虑实现数据分区策略(按日期分区)以提高查询性能
- 考虑定期归档或删除超过保留期的消息
七、工作流程详解
7.1 消息存储流程
java
用户请求 → ChatClient.prompt()
↓
MessageChatMemoryAdvisor 检测到使用ChatMemory
↓
加载conversation_id对应的历史消息
↓
组装系统消息 + 历史消息 + 用户新消息
↓
调用大模型获取回复
↓
回复内容返回给用户
↓
MessageChatMemoryAdvisor 保存用户消息和AI回复到数据库
↓
JdbcChatMemoryRepository.add() 执行INSERT操作详细步骤分析:
- 消息加载阶段:MessageChatMemoryAdvisor会检测是否指定了conversation_id,如果有则从数据库加载该会话的历史消息
- 消息组装阶段:将系统提示词、历史消息和新的用户消息组装成完整的消息列表
- 大模型调用:将组装后的消息列表传递给OpenAI/Qwen等大模型API
- 结果处理:获取大模型的回复文本
- 持久化阶段:将用户消息和AI回复分别作为两条独立的记录存储到数据库
如下时序图描绘了 Spring AI 结合 JdbcChatMemoryRepository 实现的 持久化记忆管理 全链路。它展示了消息如何从内存流转到关系型数据库(如 MySQL/PostgreSQL)。
大模型 (Qwen) 数据库 (JDBC) JdbcChatMemoryRepository MessageChatMemoryAdvisor ChatClient 大模型 (Qwen) 数据库 (JDBC) JdbcChatMemoryRepository MessageChatMemoryAdvisor ChatClient 1. 对话开始 2. 读取持久化记忆 3. 上下文增强与推理 4. 响应分发 5. 记忆持久化 (Post-Process) 记忆保存完成 prompt(question) 1 getMessages(conversationId) 2 SELECT * FROM chat_memory WHERE ... 3 返回历史消息记录 4 转换为 List<Message> 5 组装 System + History + User 6 发送完整 Context 7 返回 AI 回复内容 8 返回结果给用户 9 add(conversationId, userMsg) 10 add(conversationId, aiMsg) 11 INSERT INTO chat_memory ... (用户消息) 12 INSERT INTO chat_memory ... (AI回复) 13
关键环节深度解析
- JDBC 抽象层 :
JdbcChatMemoryRepository是 Spring AI 提供的一个标准实现。它利用JdbcTemplate将对话对象序列化为数据库行。默认情况下,它通常包含chat_id、message_type(USER/ASSISTANT)和content等字段。 - 读取时机 (Step 2-5) :这是典型的"惰性加载"。只有当
ChatClient被触发时,Advisor 才会去数据库捞取历史。这保证了即使应用重启,用户的对话上下文依然存在。 - 写入时机 (Step 9-12) :注意保存操作发生在 AI 回复之后。这是一个严谨的设计:如果 AI 调用失败(例如网络超时),则这一轮错误的对话不会被记入数据库,从而避免了"污染"历史记忆。
- 会话隔离 :通过
conversation_id(通常由前端传入或从 Session 获取),系统可以同时处理成千上万个并发用户的独立记忆,互不干扰。
进阶优化方案
在高性能场景下,频繁的 SELECT 和 INSERT 可能会成为瓶颈。你是否考虑过:
- 增加二级缓存:在 JDBC 之上叠加一个本地缓存(如 Caffeine),减少对数据库的轮询。
- 异步写入 :将
add()操作放入异步线程池,不阻塞用户的响应时间。
--
7.2 消息读取流程
java
应用启动时或新会话开始
↓
MessageChatMemoryAdvisor 收到请求
↓
调用 ChatMemory.getMessages(conversationId)
↓
JdbcChatMemoryRepository.query()
↓
执行 SELECT * FROM message_store
WHERE conversation_id = ? ORDER BY timestamp
↓
将结果转换为Message对象列表
↓
MessageWindowChatMemory 根据滑动窗口策略筛选消息
↓
返回最近N条消息供模型使用关键点说明:
- 窗口策略:MessageWindowChatMemory默认返回最近N条消息(通常是10条),而不是全部历史消息
- 消息转换:数据库中的行记录被转换为Spring AI的Message对象,包括UserMessage和AssistantMessage两种类型
- 性能优化:由于建立了idx_conversation_id索引,数据库查询非常高效,即使有数百万条消息也能快速检索
下面的时序图展示了 Spring AI 中持久化存储 与滑动窗口策略相结合的精细化记忆加载流程。它解释了系统如何在海量历史数据中,既保证"记得住"(JDBC 持久化),又保证"不超限"(滑动窗口筛选)。
数据库 (MySQL/PG) JdbcChatMemoryRepository MessageWindowChatMemory (装饰器) MessageChatMemoryAdvisor 数据库 (MySQL/PG) JdbcChatMemoryRepository MessageWindowChatMemory (装饰器) MessageChatMemoryAdvisor 1. 触发记忆检索 2. 全量/增量从库读取 3. 执行滑动窗口策略 (Memory Pruning) 丢弃过旧的 Context,防止 Token 溢出 4. 返回精简后的上下文 5. 注入 Prompt 并发送给模型 getMessages(conversationId) 1 getMessages(conversationId) 2 SELECT * FROM message_store WHERE id = ? ORDER BY ts 3 返回所有历史行 (ResultSet) 4 转换为 List<Message> (全量历史) 5 筛选最近 N 条消息 (e.g., Last 10) 6 返回 List<Message> (Size <= N) 7
核心机制分析
1. 职责分层 (Layered Responsibility)
JdbcChatMemoryRepository:只负责"搬运"。它不关心消息有多少,只负责把数据库里的数据变成 Java 对象。MessageWindowChatMemory:负责"剪裁"。它作为包装层,根据配置的capacity(容量)对原始数据进行切片。
2. 滑动窗口的必要性
LLM 的上下文窗口(Context Window)是有限的(如 128k tokens)。如果不做筛选:
- 成本剧增:每次对话都会带上从第一天开始的所有记录,Token 消耗呈指数级增长。
- 模型幻觉:过长且无关的旧背景会干扰模型对当前问题的判断。
3. 性能小贴士
在第 5 步的 SELECT 语句中,如果对话历史达到数万条,全量加载到内存再进行 Window 筛选会变得非常缓慢。
优化建议 :在生产环境中,通常会直接在 SQL 层面通过
LIMIT和ORDER BY DESC来实现物理层面的窗口筛选,例如:
SELECT * FROM message_store WHERE conversation_id = ? ORDER BY timestamp DESC LIMIT 20
下一步建议
这种结构非常稳健。当对话非常长 ,但又不能简单丢弃旧信息时,如何通过 Vector Database (RAG) 来实现"语义搜索式"的记忆检索,而不是简单的"最近 N 条"
7.3 核心代码调用链
java
// 1. 用户调用API
chatClient.prompt()
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "user123"))
.user(question)
.call()
// 2. MessageChatMemoryAdvisor执行
// 2.1 读取历史消息
List<Message> messages = chatMemory.getMessages("user123");
// 2.2 JdbcChatMemoryRepository 查询数据库
// 执行 SQL: SELECT * FROM message_store
// WHERE conversation_id = 'user123'
// ORDER BY timestamp DESC LIMIT 10
// 2.3 组装完整的消息列表
messages.add(new UserMessage(question));
// 3. 大模型处理
// 调用OpenAI API,传入消息列表
// {
// "model": "qwen3-max",
// "messages": [
// {"role": "user", "content": "...上一轮问题..."},
// {"role": "assistant", "content": "...上一轮回复..."},
// {"role": "user", "content": "...新问题..."}
// ]
// }
// 4. MessageChatMemoryAdvisor 保存回复
chatMemory.add("user123", response);
// 4.1 JdbcChatMemoryRepository 插入数据库
// 执行 SQL: INSERT INTO message_store
// (conversation_id, message_type, content, timestamp)
// VALUES ('user123', 'ASSISTANT', '...AI回复...', 1700000001000)7.4 并发场景下的消息处理
在高并发环境中,多个用户同时发送消息时,Spring AI的处理方式:
java
// 用户A和用户B同时发送消息
// 线程1:处理用户A的消息
chatClient.prompt()
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "userA"))
.user("问题A")
.call() // 通过conversation_id隔离
// 线程2:处理用户B的消息
chatClient.prompt()
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "userB"))
.user("问题B")
.call() // 完全独立,不相互影响数据库层面:
- 两个INSERT操作分别向表中插入两条不同conversation_id的记录
- 由于有idx_conversation_id索引,即使表很大也能快速定位
- InnoDB的行级锁确保操作的原子性和一致性
八、关键实现细节
8.1 MessageWindowChatMemory的窗口机制
MessageWindowChatMemory并非简单地返回所有历史消息,而是通过滑动窗口策略来控制消息数量:
java
MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.windowSize(10) // 默认值,保留最近10条消息
.build()这个机制有两个作用:
- 成本优化:减少发送给LLM的tokens,降低API调用成本
- 上下文相关性:只保留最近的对话,避免很久以前的消息影响当前对话
8.2 Conversation ID隔离
通过conversation_id实现会话隔离:
java
// 用户A和用户B的对话完全隔离
chatClient.prompt()
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "userA"))
.user("你好")
.call()
chatClient.prompt()
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, "userB"))
.user("你好")
.call()两个用户的消息存储在同一个表中,但通过conversation_id完全隔离,不会相互干扰。
8.3 自动初始化表结构
initialize-schema: always的背后:
java
@Bean
public DatabasePopulator databasePopulator() {
// 1. 读取classpath中的initialization SQL脚本
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("schema-h2.sql"));
// 或 schema-mysql.sql
// 2. 应用启动时自动执行脚本
return populator;
}Spring AI根据配置的数据库类型加载对应的初始化脚本(如schema-mysql.sql),在应用启动时自动执行。
九、生产环境最佳实践
9.1 数据源配置
生产环境应使用连接池,提高性能:
yaml
spring:
datasource:
url: jdbc:mysql://db-server:3306/my_db?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: ${DB_USERNAME}
password: ${DB_PASSWORD}
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 18000009.2 initialize-schema策略
yaml
# 开发环境
spring:
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: always
# 生产环境 - 由DBA管理
spring:
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: never9.3 定期备份和清理
sql
-- 定期备份对话数据
BACKUP TABLE message_store TO '/backup/message_store_backup.sql';
-- 清理7天以前的消息
DELETE FROM message_store
WHERE timestamp < UNIX_TIMESTAMP() * 1000 - 7 * 24 * 60 * 60 * 1000;
-- 定期收集表统计信息,优化查询性能
ANALYZE TABLE message_store;9.4 监控和告警
java
// 监控表大小增长
SELECT table_name, ROUND(((data_length + index_length) / 1024 / 1024), 2) AS size_mb
FROM information_schema.tables
WHERE table_schema = 'my_db' AND table_name = 'message_store';
// 监控慢查询
SELECT * FROM mysql.general_log
WHERE command_type = 'Query' AND execution_time > 1000;十、troubleshooting常见问题
问题1:应用启动时表已存在异常
现象:启动时报错 "Table already exists"
原因:通常是因为多个应用实例同时启动,都尝试创建表
解决方案:
yaml
initialize-schema: create-if-missing # 改为这个配置问题2:连接超时
现象 :SQLException: Connection timeout
原因:数据库连接不可达或防火墙阻止
排查步骤:
- 检查数据库是否启动:
mysql -h 127.0.0.1 -u root -p - 检查数据库名是否存在:
CREATE DATABASE my_db; - 检查URL配置是否正确
问题3:字符编码问题
现象:中文消息存储为乱码或"???"
原因:字符集配置不正确
解决方案:
yaml
spring:
datasource:
url: jdbc:mysql://...?useUnicode=true&characterEncoding=utf-8
jpa:
properties:
hibernate:
connection:
CharSet: utf8mb4
collation: utf8mb4_unicode_ci问题4:消息丢失
现象:对话后重启应用,消息无法恢复
原因:initialize-schema设置为always,导致每次启动都清空表
解决方案:
yaml
# 开发环境改为:
initialize-schema: create-if-missing十一、总结
本文详细阐述了Spring AI MySQL ChatMemory的完整实现方案:
核心要点回顾:
-
为什么持久化:解决内存存储的局限性,支持数据持久化、跨实例共享和数据分析
-
如何配置:只需两步------添加依赖和修改配置文件,Spring Boot自动完成初始化
-
平滑迁移:只需改一个Bean定义,体现了Spring AI优秀的架构设计和依赖注入的威力
-
自动配置机制:Spring Boot通过条件装配、classpath扫描等机制,自动发现和初始化JdbcChatMemoryRepository
-
表结构设计:合理的字段设计和索引策略,确保查询性能和数据隔离
-
生产就绪:提供了最佳实践、troubleshooting指南和监控方案
实践建议:
- 开发阶段 :使用
initialize-schema: always,快速迭代 - 测试阶段 :改为
create-if-missing,验证数据持久化 - 生产环境 :设置为
never,由DBA负责数据库初始化和维护
从InMemory到JDBC的演进,不仅是存储介质的改变,更是架构思想的升级------从单机应用到分布式系统的支持,从临时数据到永久化存储的转变。这正是Spring AI框架设计的精妙之处。
希望这篇文章能帮助你充分理解Spring AI ChatMemory的持久化机制,在实战中灵活运用,构建更健壮、更可靠的AI对话应用。
相关资源
- Spring AI官方文档:https://docs.spring.io/spring-ai/reference/
- MySQL JDBC参数详解:https://dev.mysql.com/doc/connector-j/8.0/en/
- Spring Boot自动配置原理:https://spring.io/projects/spring-boot
