文章目录
- 前言
- 背景
- 一、文档内容解析
-
- [1.1、认识Apache Tika](#1.1、认识Apache Tika)
- [1.2、实测Apache Tika](#1.2、实测Apache Tika)
- 1.3、内容解析目的说明
- 二、文本分片(切割)
- 三、上传文档到向量数据库
- 四、实现RAG+大模型检索增强
-
- [4.1、普及知识,认识Advisors API](#4.1、普及知识,认识Advisors API)
-
- 4.1.1、认识RAG检索增强
- [4.1.2、Advisors 的核心功能与设计目标](#4.1.2、Advisors 的核心功能与设计目标)
- [4.1.3、内建 Advisors 的分类与用途](#4.1.3、内建 Advisors 的分类与用途)
- [4.14、示范:自定义 Advisors 的实现](#4.14、示范:自定义 Advisors 的实现)
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
背景
有了向量数据库后,我们现在需要做的就是将知识库相关文档内容解析,然后使用相关工具将文档内容分割,并转换成向量表示存储在Milvus中。
一、文档内容解析
在Java中,文件内容解析可以通过多种方式实现,具体取决于文件的格式和解析需求。如果我们要搭建知识库,文档的类型肯定是多样化的。那么有没有什么工具可以不考虑文档类型,又可以实现我们的需求呢?
- Apache Tika。
1.1、认识Apache Tika
简介:
- 开发语言:Java
- 官方网站:Apache Tika
- 特点:Tika 是一个强大的内容分析工具包,支持从超过1000种文件类型中提取文本、元数据和其他结构化数据。它能够处理多种式的文档,包括但不限于PDF、Word、Excel、PPT等。
- 使用场景:适用于需要处理多种不同格式文档的大规模信息抽取任务。
主要特性:
-
支持广泛的文档格式解析。
-
提供了丰富的元数据提取能力。
-
可以通过命令行或编程接口(如Java API)调用。
-
内置自然语言检测功能。
-
支持OCR(通过集成外部服务如Tesseract)来处理图像中的文字。
优点:
- 强大的多格式支持,几乎可以处理任何类型的文档。
- 易于与大数据生态系统集成(例如Hadoop)。
- 活跃的社区支持和持续更新。
缺点:
- 对于某些特定格式(如PDF),可能不如专用工具精确。性能上可能不是最优,特别是在处理大量小文件时。
1.2、实测Apache Tika
1.2.1、pom.xml引入依赖
引入pom.xml:
xml
<!-- Tika依赖 文件内容提取 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>3.0.0</version>
</dependency>1.2.2、TikaUtil.java:文档解析工具类
java
public class TikaUtil {
/**
* 解析文件(各类格式)为文本
* @param file MultipartFile
* @return String
*/
public static String extractTextString(MultipartFile file) {
try {
// 创建解析器--在不确定文档类型时候可以选择使用AutoDetectParser可以自动检测一个最合适的解析器
Parser parser = new AutoDetectParser();
// 用于捕获文档提取的文本内容。-1 参数表示使用无限缓冲区,解析到的内容通过此hander获取
BodyContentHandler bodyContentHandler = new BodyContentHandler(-1);
// 元数据对象,它在解析器中传递元数据属性---可以获取文档属性
Metadata metadata = new Metadata();
// 带有上下文相关信息的ParseContext实例,用于自定义解析过程。
ParseContext parseContext = new ParseContext();
parser.parse(file.getInputStream(), bodyContentHandler, metadata, parseContext);
// 获取文本
return bodyContentHandler.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}1.2.3、实现解析接口
java
@Operation(summary = "解析文件内容(支持上传各类文件)")
@PostMapping("/extractFileString")
public ResponseEntity<String> extractFileString(MultipartFile file) {
return ResponseEntity.ok(TikaUtil.extractTextString(file));
}1.2.4、测试解析能力
我们引入了文档测试工具,直接访问即可:
xml
<knife4j.version>4.3.0</knife4j.version>
<!-- 前后端分离中的后端接口测试工具 -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>${knife4j.version}</version>
</dependency>http://localhost:8080/doc.html#/-v3-api-docs/向量数据库实践/extractFileString
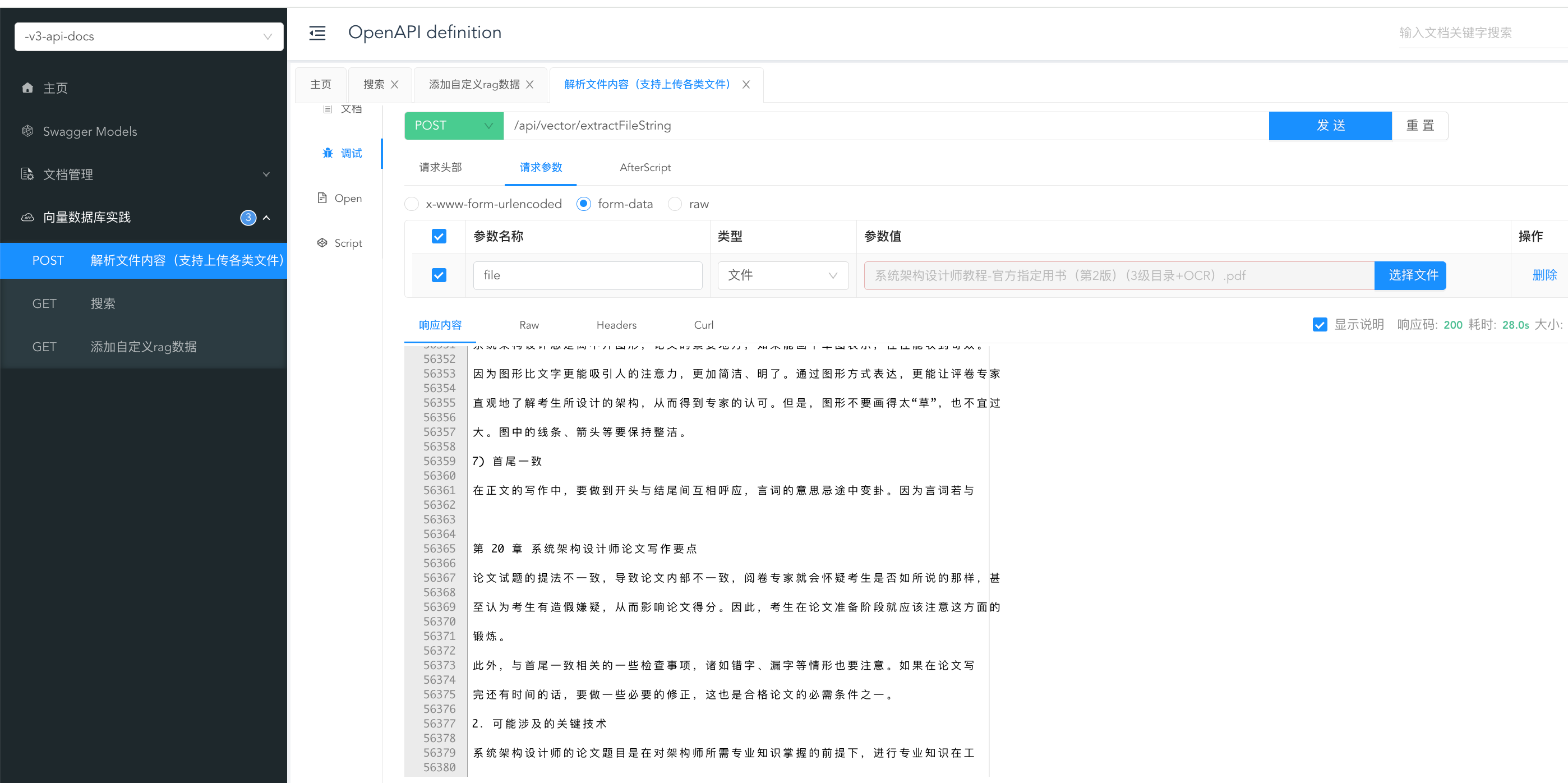
解析能力还可以。
如果上传文件过大的话配置项在application.yaml中配置:
yaml
spring:
servlet:
multipart:
max-file-size: 50MB
max-request-size: 100MB1.3、内容解析目的说明
想要实现知识库文档,我们首先需要能够识别各类文档,同时对其内容进行文档解析,目前借助Apache Tika能够实现不同文档类型的内容解析。但现在的问题是,一般的企业里相关文档内容都是比较多的。如果我们将解析出来的文本一股脑全往模型里塞,可能会导致上下文过长,达不到我们想要的效果。
为了解决这种情况,我们需要将文本分片,把内容切割成一个一个的文本块,再将文本块转换为向量表示存入向量数据库,这样大模型在检索的时候只需要将相关的文本块添加到上下文中,既能保证回答的准确性,也解决了上下文过长的问题。
二、文本分片(切割)
2.1、介绍文本分片的多种实现思路
如何将过长的文本内容分割成文本块,又要保证每块内容的语义完整,这就需要用到自然语言处理(NLP)技术,可以考虑使用以下几种方法和技术:
1、使用分词库
- Stanford NLP: 提供了丰富的工具集用于处理各种自然语言处理任务,包括中文分词、命名实体识别等。可以利用其提供的Java API进行文本分割。
- Jieba分词: 虽然Jieba最初是为Python设计的,但也有Java版本可用(如jieba-analysis)。它支持精确模式、全模式等多种分词模式,并且能够通过自定义词典来提高分词准确性。
- HanLP: HanLP是一个高效的中文处理工具包,支持多种语言和功能,包括分词、词性标注、命名实体识别等。HanLP提供了Java接口,非常适合需要对中文文本进行处理的场景。
2、基于机器学习的方法
- CRF (条件随机场): CRF是一种序列标注模型,广泛应用于分词、词性标注等领域。可以通过训练特定领域的数据集来提高分词准确性。
- 深度学习框架: 如TensorFlow、PyTorch等虽然主要以Python为主,但也可以通过调用它们的Java API或者通过RESTful服务的方式与Java程序集成,使用预训练的语言模型(例如BERT)来进行更复杂的文本分析任务,包括基于上下文感知的分词。
3、基于LangChain的文本分割工具
- LangChain4J 是一个用于开发语言模型应用的框架,Spring AI的直接竞争对手,它提供了多种工具和组件来处理文本数据,包括文档分割(Document Splitters)、文档分割器(DocumentSplitters)的主要目的是将大型文档分割成更小的块或片段,以便更有效地处理或分析。这些分割策略对于确保文本块适合于特定的语言模型输入限制(如最大token长度)非常重要。
在Java开发中,对于像Stanford NLP、HanLP这样的库,可以直接添加依赖项到你的pom.xml中,这样我们开发起来可以避开Python调用的繁杂过程。
2.2、集成HanLP案例
HanLP分词库还提供了语义分析、文本摘要、文本分类、情感分析等多种功能。
官方文档:HanLP | 在线演示
1)在pom.xml里添加相关依赖
xml
<!-- HanLP中文分词 -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.6</version>
</dependency>2)实现HanLP工具类实现分段
java
/**
* @description HanLP分词库工具类
* @author changlu
* @date 2025/6/7 16:23
*/
public class HanlpUtil {
// 目标段落长度(汉字字符数)
private static final int TARGET_LENGTH = 200;
// 允许的段落长度浮动范围(±20字)
private static final int LENGTH_TOLERANCE = 20;
/**
* 使用HanLP进行句子分割
*
* @param text 输入的大文本
* @return 段落列表,每个段落至少包含minLength个字符
*/
public static List<String> splitParagraphsHanLP(String text) {
List<String> paragraphs = new ArrayList<>();
if (text == null || text.isEmpty()) {
return paragraphs;
}
// 1. 使用 HanLP 分词并分句
List<String> sentences = splitSentences(text);
// 2. 动态合并句子到段落
paragraphs = mergeSentencesIntoParagraphs(sentences);
return paragraphs;
}
// 使用 HanLP 分词实现分句
private static List<String> splitSentences(String text) {
List<String> sentences = new ArrayList<>();
StringBuilder currentSentence = new StringBuilder();
List<Term> terms = HanLP.segment(text);
for (Term term : terms) {
currentSentence.append(term.word);
// 使用正则表达式匹配句子结束标点(支持中英文标点)
if (term.word.matches("[。!?;.!?;]+")) {
sentences.add(currentSentence.toString());
currentSentence.setLength(0);
}
}
// 添加最后一个句子(如果没有标点结尾)
if (!currentSentence.isEmpty()) {
sentences.add(currentSentence.toString());
}
return sentences;
}
// 动态合并句子到段落
private static List<String> mergeSentencesIntoParagraphs(List<String> sentences) {
List<String> paragraphs = new ArrayList<>();
StringBuilder currentParagraph = new StringBuilder();
int currentLength = 0;
for (String sentence : sentences) {
int sentenceLength = countChineseChars(sentence);
// 处理超长句子(强制分割)
if (sentenceLength > TARGET_LENGTH + LENGTH_TOLERANCE) {
if (currentLength > 0) {
paragraphs.add(currentParagraph.toString());
currentParagraph.setLength(0);
currentLength = 0;
}
// 按标点二次分割超长句
List<String> subSentences = splitLongSentence(sentence);
paragraphs.addAll(subSentences);
continue;
}
// 合并到当前段落的条件
if (currentLength + sentenceLength <= TARGET_LENGTH + LENGTH_TOLERANCE) {
currentParagraph.append(sentence);
currentLength += sentenceLength;
} else {
// 当前段落达到长度,保存并重置
paragraphs.add(currentParagraph.toString());
currentParagraph.setLength(0);
currentParagraph.append(sentence);
currentLength = sentenceLength;
}
}
// 添加最后一个段落
if (currentLength > 0) {
paragraphs.add(currentParagraph.toString());
}
return paragraphs;
}
// 处理超长句子:按逗号、分号等二次分割
private static List<String> splitLongSentence(String sentence) {
List<String> validParts = new ArrayList<>();
StringBuilder current = new StringBuilder();
int currentLength = 0;
// 按标点分割句子
String[] parts = sentence.split("[,;;,]");
for (String part : parts) {
int partLength = countChineseChars(part);
if (currentLength + partLength > TARGET_LENGTH + LENGTH_TOLERANCE) {
// 当前部分过长,保存并重置
validParts.add(current.toString());
current.setLength(0);
currentLength = 0;
}
// 补回分割符号
current.append(part).append(",");
currentLength += partLength;
}
// 添加最后一个部分
if (!current.isEmpty()) {
validParts.add(current.toString());
}
return validParts;
}
// 统计中文字符数(忽略标点、英文)
private static int countChineseChars(String text) {
return (int) text.chars()
.filter(c -> Character.UnicodeScript.of(c) == Character.UnicodeScript.HAN)
.count();
}
}3)实现controller接口
java
@Operation(summary = "解析文件内容-HanLP分片")
@PostMapping("/splitParagraphsHanLP")
public ResponseEntity<List<String>> splitParagraphsHanLP(MultipartFile file) {
return ResponseEntity.ok(HanlpUtil.splitParagraphsHanLP(TikaUtil.extractTextString(file)));
}2.3、集成langchain4j案例
1)引入pom.xml依赖
xml
<!-- HanLP中文分词 -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.6</version>
</dependency>2)引入Langchain4j工具类
java
public class Langchain4jUtil {
// 目标段落长度(汉字字符数)
private static final int TARGET_LENGTH = 200;
// 允许的段落长度浮动范围(±20字)
private static final int LENGTH_TOLERANCE = 20;
/**
* 使用langchain4j的分段工具
*
* @param content 输入的大文本
* @return 段落列表,每个段落至少包含minLength个字符
*/
public static List<String> splitParagraphsLangChain(String content) {
DocumentSplitter splitter = DocumentSplitters.recursive(TARGET_LENGTH, LENGTH_TOLERANCE, new OpenAiTokenizer());
List<TextSegment> split = splitter.split(Document.document(content));
return split.stream().map(TextSegment::text).toList();
}
}3)实现controller接口
java
@Operation(summary = "解析文件内容-LangChina分片")
@PostMapping("/splitParagraphsLangChain")
public ResponseEntity<List<String>> splitParagraphsLangChain(MultipartFile file) {
return ResponseEntity.ok(Langchain4jUtil.splitParagraphsLangChain(TikaUtil.extractTextString(file)));
}2.4、测试HanLP、LangChain4j的文本切分
测试文本:
txt
服务器异常高负载问题排查报告
近期监测到主服务器节点(10.0.2.15)持续出现CPU负载超过90%的告警,峰值时段达到98%。初步排查时间范围:2023-11-01 09:00至2023-11-03 17:00 UTC。
1. 资源监控分析
通过Prometheus采集数据发现:
内存使用率稳定在65%(未触发阈值)
磁盘IOPS在高峰时段飙升至1200(正常基线为400)
网络流量同比增加230%,主要来自TCP 443端口
2. 进程追踪
使用top -c命令锁定三个异常进程:
PID 28763(JAVA)持续占用47% CPU
PID 29841(python3)存在内存泄漏迹象
PID 30112(/usr/bin/node)产生大量僵尸子进程
3. 日志关联
检查/var/log/nginx发现大量502错误:
upstream timed out (110: Connection timed out)
对应时间戳与Kafka消费者延迟报警匹配(滞后12.7万条消息)
4. 临时解决方案
重启异常Java服务(v2.1.4→回退至v2.1.2)
扩容Kafka消费者组从3→5个实例
添加临时交换分区8GB
待办事项
□ 完整堆栈分析(需采集Heap Dump)
□ 验证数据库连接池泄漏问题
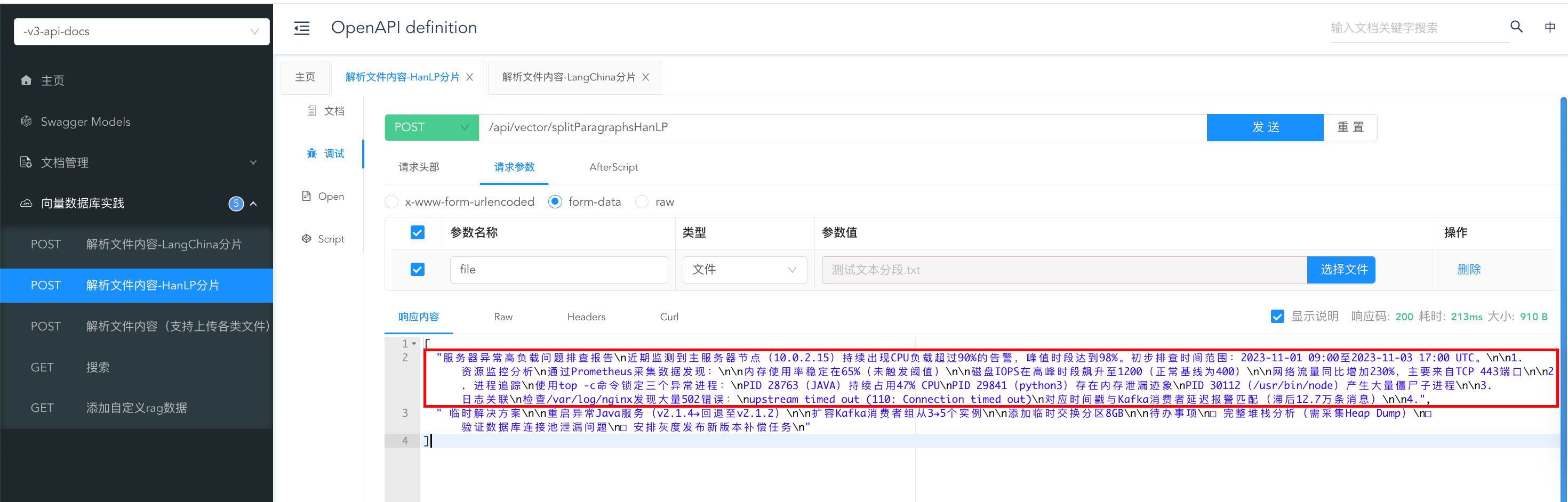
□ 安排灰度发布新版本补偿任务hanlp测试分为了两段:
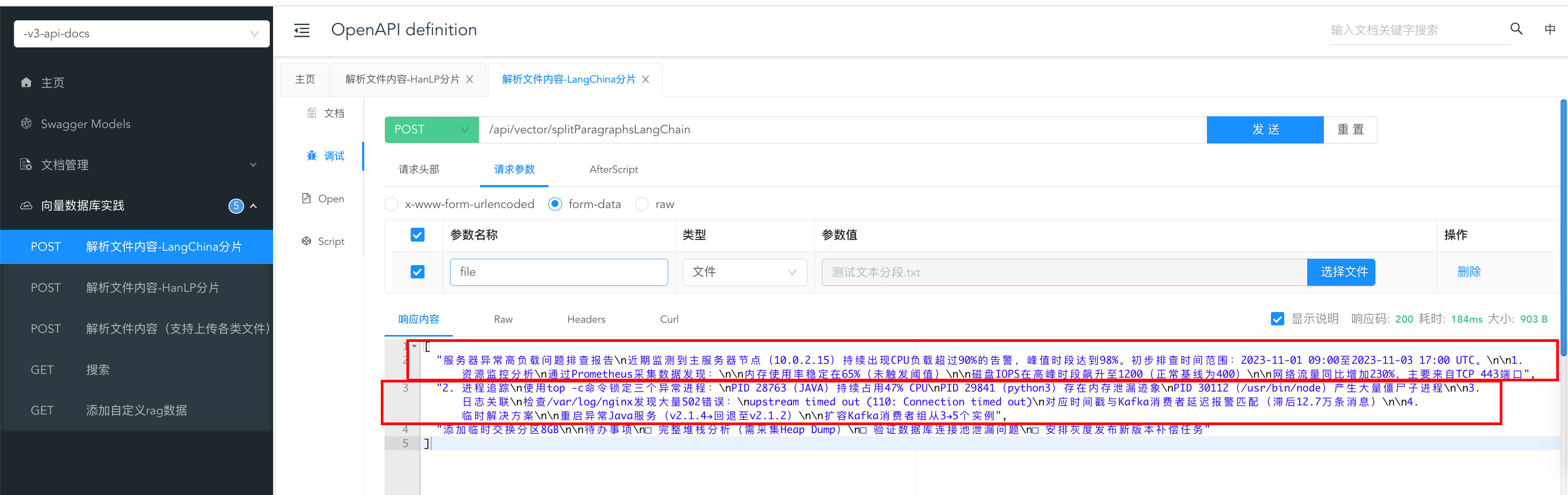
langchain4j分为了三段:
结论如下:这里引用博客:https://blog.csdn.net/wanganui/article/details/145919410
LangChain分割结果特点:
-
项目阶段划分清晰:LangChain能够很好地识别并分割出"项目正式启动前"、"项目正式启动"、"项目完工后"以及"项目回访"这几个主要阶段,并且每个阶段都有明确的开始和结束标志。
-
细节内容保留完整:对于每一个工作职责和负责人的描述,LangChain都能准确地进行分段,保持了原文档中信息的完整性。
格式一致性好:在整个分割过程中,LangChain维持了原始文档的结构化格式,使得阅读和理解变得容易。
HanLP分割结果特点:
- 部分阶段混合:HanLP在某些情况下未能完全将不同阶段的内容区分开来,例如"项目正式启动"部分内容与前面或后面的内容有所混杂。
- 细节处理较为精细:虽然在大段落分割上不如LangChain清晰,但HanLP在处理具体的工作职责细分时表现出了较好的细节捕捉能力,比如对"概算、招标控制价、成本分析"的进一步细分处理得比较细致。
- 格式略有不一致:相较于LangChain,HanLP生成的部分段落开头可能缺少明确的阶段标识,导致在快速浏览时不容易立即分辨出当前段落属于哪个阶段。
总结:
- 如果需要一个清晰、结构化的输出,尤其是当文档包含多个明显不同的章节或阶段时,LangChain可能是更好的选择。
- 对于那些更关注于文本内部细节而非整体结构的应用场景,HanLP可能会提供更加细腻的分割结果。
三、上传文档到向量数据库
接下学习如何将分割后的文本转换为向量表示后存入向量数据库中,上一章节仅仅只是去将一个文本段存入到了向量数据库中。
这里则是会将指定文档去存入到向量数据库里,存入之前会进行分割文档内容,再将分割之后的文本内容依次向量计算后存储到向量数据库里。
3.1、实现MilvusService批量插入接口
 。
。
java
/**
* 批量插入数据
*
* @param vectorParam 向量参数
* @param text 文本
* @param metadata 元数据
* @param fileName 文件名
*/
InsertResp batchInsert(List<float[]> vectorParam, List<String> text, List<String> metadata, List<String> fileName);MilvusServiceImpl.java:实现批量插入接口
java
/**
* 批量插入数据
*
* @param vectorParam 向量参数
* @param text 文本
* @param metadata 元数据
* @param fileName 文件名
*/
@Override
public InsertResp batchInsert(List<float[]> vectorParam, List<String> text, List<String> metadata, List<String> fileName) {
if (vectorParam.size() == text.size() && vectorParam.size() == metadata.size() && vectorParam.size() == fileName.size()) {
List<JsonObject> jsonObjects = new ArrayList<>();
for (int i = 0; i < vectorParam.size(); i++) {
JsonObject jsonObject = new JsonObject();
// 数组转换成JsonElement
jsonObject.add(MilvusArchiveConstant.Field.FEATURE, new Gson().toJsonTree(vectorParam.get(i)));
jsonObject.add(MilvusArchiveConstant.Field.TEXT, new Gson().toJsonTree(text.get(i)));
jsonObject.add(MilvusArchiveConstant.Field.METADATA, new Gson().toJsonTree(metadata.get(i)));
jsonObject.add(MilvusArchiveConstant.Field.FILE_NAME, new Gson().toJsonTree(fileName.get(i)));
jsonObjects.add(jsonObject);
}
InsertReq insertReq = InsertReq.builder()
// 集合名称
.collectionName(MilvusArchiveConstant.COLLECTION_NAME)
.data(jsonObjects)
.build();
return milvusClientV2.insert(insertReq);
}
return null;
}3.2、TikaVo.java:实现分片转换后的对象
任何一个文档最终都会返回一个TikaVo.java:
java
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;
import lombok.experimental.Accessors;
import java.io.Serializable;
import java.util.List;
/**
* @description tika返回对象
* @author changlu
* @date 2025/6/7 17:06
*/
@Accessors(chain = true)
@Schema(description = "tika返回对象")
@Data
public class TikaVo implements Serializable {
@Schema(description = "文本内容")
private List<String> text;
@Schema(description = "元数据")
private List<String> metadata;
}3.3、解析文档+分片方法实现
这里文档分片选择使用langchain4j。
java
/**
* 文件内容提取
*
* @param file 上传的文件
* @return 文件内容
*/
public static TikaVo extractText(MultipartFile file) {
try {
// 创建解析器--在不确定文档类型时候可以选择使用AutoDetectParser可以自动检测一个最合适的解析器
Parser parser = new AutoDetectParser();
// 用于捕获文档提取的文本内容。-1 参数表示使用无限缓冲区,解析到的内容通过此hander获取
BodyContentHandler bodyContentHandler = new BodyContentHandler(-1);
// 元数据对象,它在解析器中传递元数据属性---可以获取文档属性
Metadata metadata = new Metadata();
// 带有上下文相关信息的ParseContext实例,用于自定义解析过程。
ParseContext parseContext = new ParseContext();
parser.parse(file.getInputStream(), bodyContentHandler, metadata, parseContext);
// 获取文本
String text = bodyContentHandler.toString();
// 元数据信息
String[] names = metadata.names();
// 将元数据转换成JSON字符串
Map<String, String> map = new HashMap<>();
for (String name : names) {
map.put(name, metadata.get(name));
}
return splitParagraphs(text);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 使用langchain4j的分段工具
*
* @param content 文本内容
*/
private static TikaVo splitParagraphs(String content) {
DocumentSplitter splitter = DocumentSplitters.recursive(Langchain4jUtil.TARGET_LENGTH, Langchain4jUtil.LENGTH_TOLERANCE, new OpenAiTokenizer());
List<TextSegment> split = splitter.split(Document.document(content));
return new TikaVo()
.setText(
split.stream()
.map(TextSegment::text)
.toList()
).setMetadata(
split.stream()
.map(textSegment -> JSON.toJSONString(textSegment.metadata()))
.toList()
);
}3.4、实现文档分片上传数据库
java
@Operation(summary = "上传知识库")
@PostMapping("/uploadFile")
public ResponseEntity<InsertResp> uploadFile(MultipartFile file) {
// 获取文件内容
TikaVo tikaVo = TikaUtil.extractText(file);
if (tikaVo != null && Objects.nonNull(tikaVo.getText())) {
List<String> textList = tikaVo.getText();
List<String> metadataList = tikaVo.getMetadata();
// 存储计算得到的向量结果 & 文件名
List<float[]> embedList = new ArrayList<>();
List<String> fileNameList = new ArrayList<>();
for (String s : tikaVo.getText()) {
embedList.add(ollamaEmbeddingModel.embed(s));
fileNameList.add(file.getOriginalFilename());
}
return ResponseEntity.ok(milvusService.batchInsert(embedList, textList, metadataList, fileNameList));
}
return ResponseEntity.ok(null);
}测试
上传一个测试文本文档:
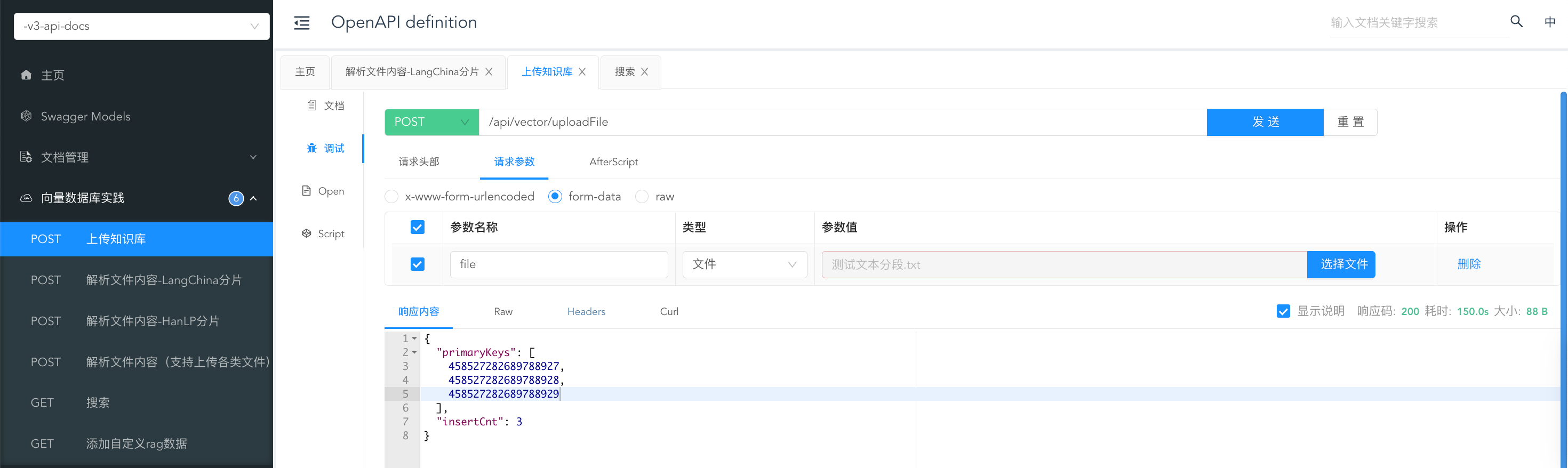
可以看到最后分片了三个文档,最终上传到了mivlus数据库:
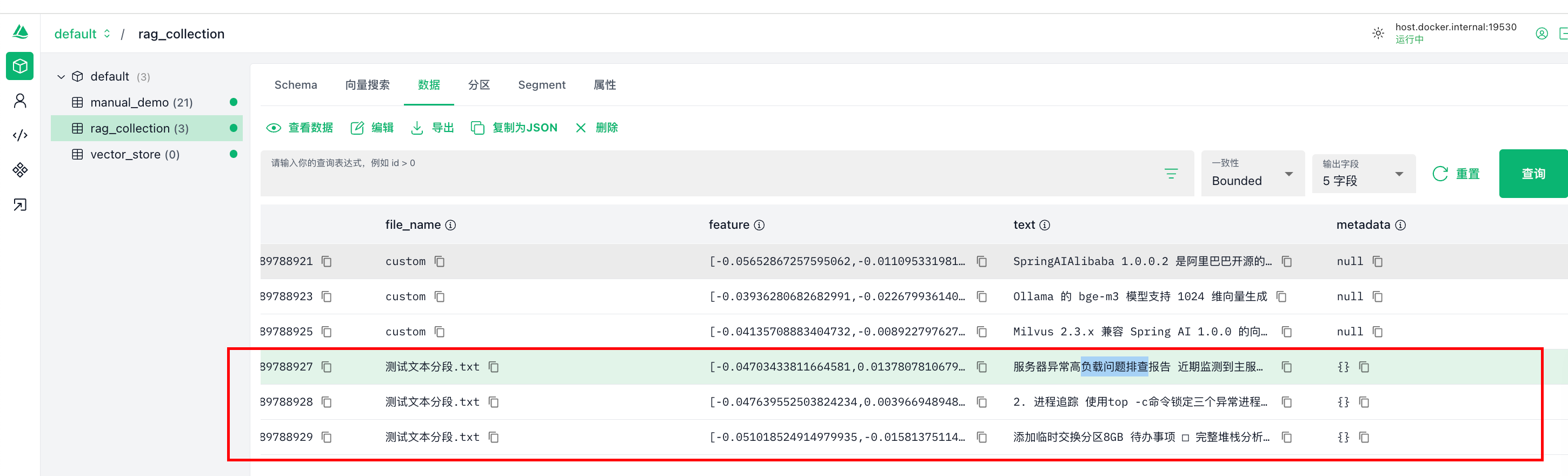
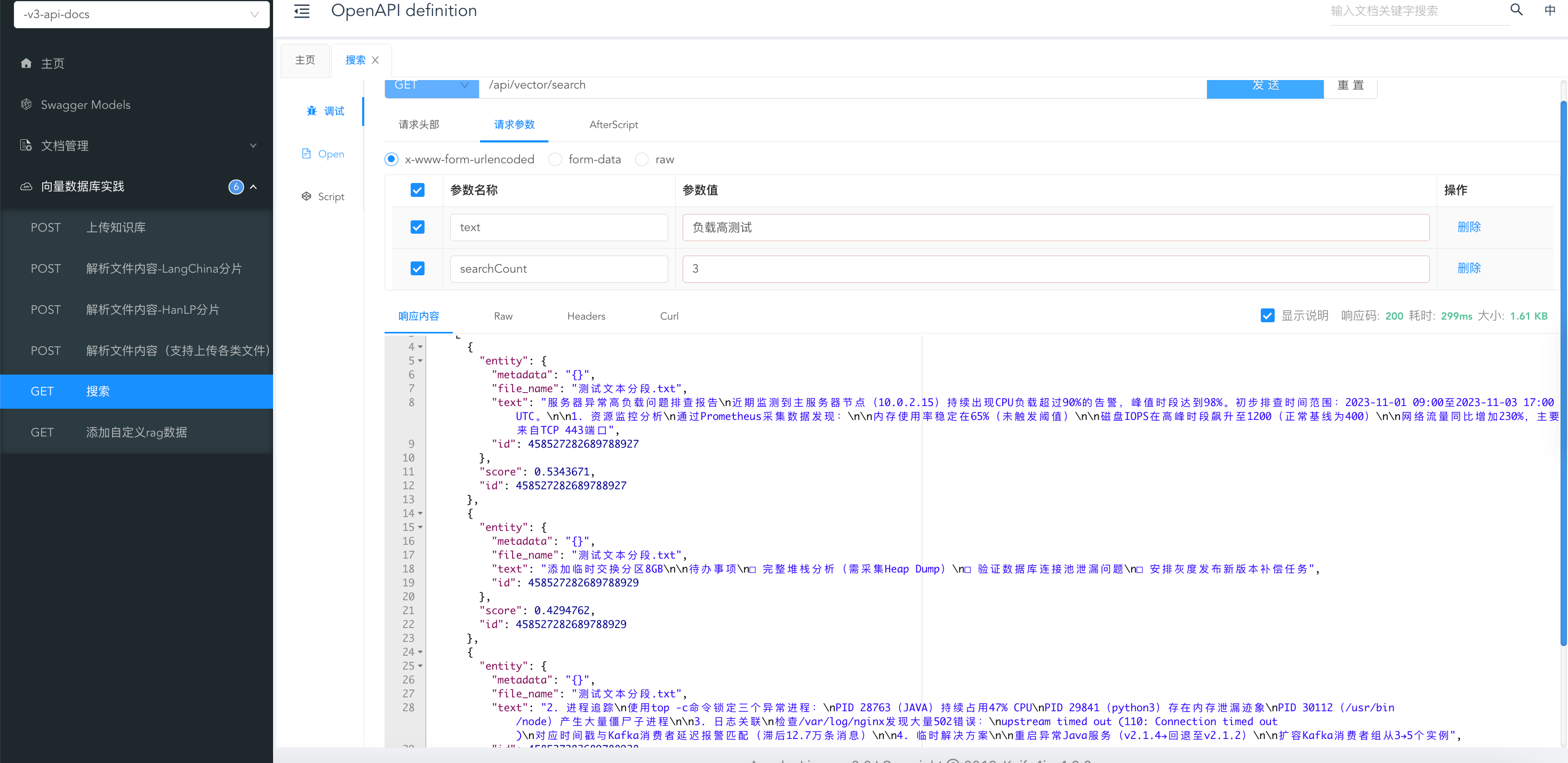
测试下查询命令:我这里去查询负载高测试,查询出来匹配的三个文档
四、实现RAG+大模型检索增强
4.1、普及知识,认识Advisors API
4.1.1、认识RAG检索增强
怎么来实现检索增强生成呢?
- 通俗来说就是将用户的问题先转换为向量表示,再从向量数据库中搜索相关文本块,然后将搜索结果组装到用户会话的上下文中传递给大语言模型,大模型再根据这些内容做出准确的回答。
这个逻辑的前两步我们已经实现了,那么如何将文本块添加到聊天上下文呢,这就需要使用到Spring AI的Advisors API,我们来学习一下这门技术。
在Spring AI 的官网中是这样介绍的:Spring AI 的Advisors API 提供了一种灵活而强大的方法来拦截、修改和增强 Spring 应用程序中 AI 驱动的交互。通过利用Advisors API,开发人员可以创建更复杂、可重用和可维护的 AI 组件。
主要优势包括封装重复出现的生成式 AI 模式、转换发送到和来自语言模型 (LLM) 的数据,以及提供跨各种模型和用例的可移植性。
说的通俗一点你可以理解为它就是AOP,只不过是专注于 AI 模型交互的上下文处理。
4.1.2、Advisors 的核心功能与设计目标
1)请求/响应拦截与修改
- Advisors 通过链式结构拦截并动态修改发送给 AI 模型的请求(AdvisedRequest)和模型返回的响应(AdvisedResponse)。例如,可以增强输入数据的上下文或过滤敏感内容。
2)功能模块化与复用
- 封装重复逻辑:如日志记录、历史会话管理(MessageChatMemoryAdvisor)或敏感词校验(SafeGuardAdvisor)等通用功能可封装为可复用的 Advisor。
3)数据转换:优化输入数据格式(如提示词模板化)或后处理输出结果(如 JSON 结构化)。
- 跨模型兼容性
- 通过抽象接口(如 CallAroundAdvisor 和 StreamAroundAdvisor),Advisors 可适配不同 AI 模型(如 OpenAI、HuggingFace),提升代码可移植性。
4.1.3、内建 Advisors 的分类与用途
Spring AI 提供多种预置 Advisors,覆盖常见 AI 交互场景:
1)上下文记忆管理
-
MessageChatMemoryAdvisor:将用户与模型的对话历史添加到请求的 messages 参数中,需模型支持多轮对话,可参考博客:https://blog.csdn.net/wanganui/article/details/145593518?spm=1011.2415.3001.5331
-
PromptChatMemoryAdvisor:将历史记录封装到系统提示词(systemPrompt),适用于不直接支持 messages 参数的模型。
2)检索增强生成(RAG)
- QuestionAnswerAdvisor:在用户提问时,从向量数据库检索相关文档片段并附加到输入中,提升回答准确性(本次将要用到的技术)。
3)安全与日志
- SafeGuardAdvisor:拦截包含敏感词的请求,阻止调用 AI 模型。
- SimpleLoggerAdvisor:记录请求与响应的日志,便于调试。
4)长期记忆存储
- VectorStoreChatMemoryAdvisor :将对话历史存储到向量数据库,支持通过
chat_memory_conversation_id关联会话,需注意避免因 ID 管理不当导致数据冗余。
4.14、示范:自定义 Advisors 的实现
用户可通过实现 CallAroundAdvisor 或 StreamAroundAdvisor 接口创建自定义逻辑。以下是一个 Re-Reading(Re2)Advisor 的示例,用于在请求前重复用户问题以提升模型理解:
整理者:长路 时间:2025.6.7
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue---校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅