萌新学习正则表达式不到一天时间,想速成直奔标题六!!
推荐正则学习网站regex101: build, test, and debug regex
欢迎各位rape me
一、快速阅览表
1、基本匹配
|---------|------------|---------------------|
| 格式 | 说明 | 案例 |
| 随意字符(串) | 直接匹配该字符(串) | hello 匹配hello n 匹配n |
2、字符类
|--------|-------------------------------|-----------------------------------------------------------|
| 格式 | 说明 | 案例 |
| . | 匹配除换行符之外任意单个字符 | . 一个文本文件里任意字符除换行符外都符合条件 |
| \[\] | 从括号里任选一个符合的字符 | abc 匹配 a、b 或 c 中的任意一个 a-b 匹配任意小写字母 0-9 匹配任意数字 |
| \^ | 从括号外任选一个符合的字符 | \^abc 匹配除a、b、c外任意一个字符 |
| \d | 数字,相当于 0-9 | |
| \D | 数字,相当于\^0-9 | |
| \w | 单词字符,相当于a-zA-z0-9_ | |
| \W | 非单词字符,相当于\^a-zA-z0-9_ | |
| \s | 匹配空白字符,相当于\\n\\t\\r\\f | |
| \S | 匹配非空白字符,相当于\^\\n\\t\\r\\f | |
3、量词
|-------|---------------|---------------------------------|
| 格式 | 说明 | 案例 |
| * | 匹配0或0个以上的先前字符 | .* 匹配任意字符,包括换行符 a* 匹配 0个或多个 a |
| ? | 匹配0或1个先前字符 | a? 匹配 0个或 1个 a |
| + | 匹配1或1个以上的先前字符 | a+ 匹配 1个或多个 a |
| {n} | 匹配n个先前字符 | {5}a 匹配aaaaa,即5个a |
| {n,m} | 匹配n到m个先前字符 | {3,5}a 匹配3到5个a |
| {n,} | 匹配n个或更多的先前字符 | {3,}a 匹配3个或更多的a |
4、位置匹配
|-----|---------------------|----------------------------------------------|
| 格式 | 说明 | 案例 |
| ^ | 字符串开头(或在多行模式下匹配行开头) | ^a 匹配以a开头的行 |
| | 字符串结尾(或在多行模式下匹配行结尾) | a 匹配以a结尾的行 |
| \b | 单词边界 | \bword\b i.e. 在my word中匹配 在myword中不匹配 |
| \B | 非单词边界 | \Bword\B i.e. 在123wordqwe中匹配 在hellword中不匹配 |
5、分组和引用
|------|---------------------------------|-----------------------------------------|
| 格式 | 说明 | 案例 |
| () | 捕获分组,作为一个整体,可以使用诸如\1或\2等来引用它们 | (abc){2} \1 abc用作捕获组,它匹配的字符串是abcabcabc |
| (?:) | 非捕获分组,不关心后续引用 | (?:abc){2} 不会捕获abc |
| | | 或、二选一 | a|b 匹配a或b |
| \n | 1、第n个分组引用 2、转义字符 | \1 引用第一个分组 \2 引用第二个分组 \. 即英文句号 . |
二、具体运用(ds老哥的活)
1、邮箱
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$解析:
-
^开始 -
[a-zA-Z0-9._%+-]+用户名部分(1个或多个字符) -
@必须有@符号 -
[a-zA-Z0-9.-]+域名部分 -
\.必须有.符号 -
[a-zA-Z]{2,}顶级域名(至少2个字母) -
$结束
2、中国手机号
^1[3-9]\d{9}$解析:
-
^1以1开头 -
[3-9]第二位是3-9 -
\d{9}后面9位数字
3、URL
https?://(?:www\.)?[a-zA-Z0-9-]+(\.[a-zA-Z]{2,})+(/[\w\-./?%&=]*)?解析:
-
https?http或https -
://固定部分 -
(?:www\.)?可选的www. -
[a-zA-Z0-9-]+域名主体 -
(/[\w\-./?%&=]*)?可选的路径和参数
4、日期
\d{4}[-/]\d{1,2}[-/]\d{1,2}5、匹配中文字符
[\u4e00-\u9fa5]6、密码强度验证
^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)(?=.*[!@#$%^&*])[A-Za-z\d!@#$%^&*]{8,}$解析:
-
(?=.*[A-Z])必须包含大写字母 -
(?=.*[a-z])必须包含小写字母 -
(?=.*\d)必须包含数字 -
(?=.*[!@#$%^&*])必须包含特殊字符 -
[A-Za-z\d!@#$%^&*]{8,}总长度至少8位
三、练习(以grep为例)
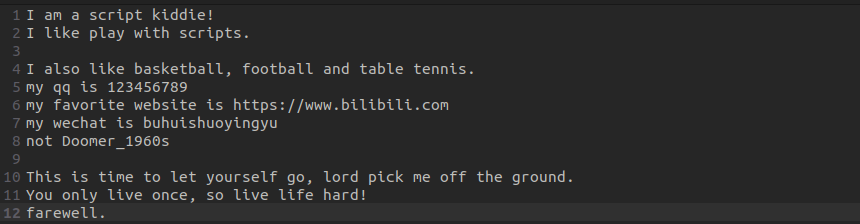
有文章如下:
1、过滤出以my为开头的行
2、过滤出以!为结尾的行
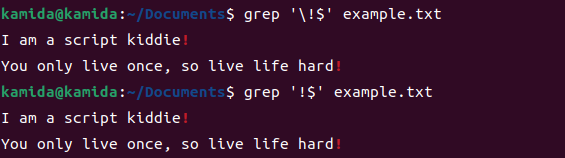
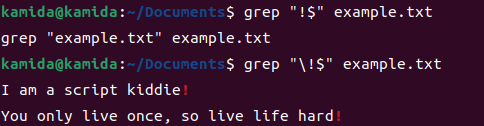
PS:额(⊙o⊙)... 貌似单引号和双引号都行啊。。。。。 我的linux版本是ubuntu22.04
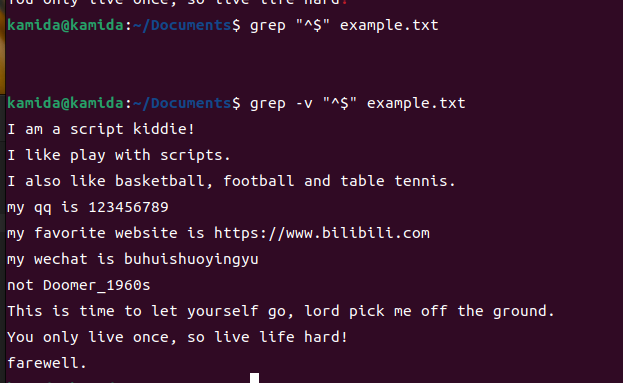
3、匹配空行以及过滤空行
4、过滤出以I为行首,英文句号.为结尾的行

四、在Golang中简单使用正则表达式(可以略过)
Go
package main
import (
"fmt"
"os"
"regexp"
)
func main() {
// 1.基本匹配
text1 := "Hello world! Welcome to Golang"
regGo, err := regexp.Compile(`Golang`)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Printf("Text '%s', matches 'Golang': %t\n", text1, regGo.MatchString(text1)) // true
// 2.数字匹配
text2 := "Products codes: X123, U114, X233"
rProductP := regexp.MustCompile(`X\d+`)
firstProduct :=rProductP.FindString(text2)
fmt.Println(firstProduct) // X123
// 3.多组数字匹配
allPProducts := rProductP.FindAllString(text2, -1)
fmt.Println(allPProducts) // [X123 X233]
}输出:
Text 'Hello world! Welcome to Golang', matches 'Golang': true
X123
X123 X233
五、劝退应用(ds老哥辅助小萌新)
1. 贪婪 vs 非贪婪
<.*> # 贪婪匹配:匹配 <div>aaa</div><p>bbb</p> 整个字符串
<.*?> # 非贪婪匹配:分别匹配 <div>aaa</div> 和 <p>bbb</p>
2. 正向预查和负向预查
Windows(?=95|98|NT) # 匹配后面跟着95/98/NT的Windows
Windows(?!95|98|NT) # 匹配后面不跟着95/98/NT的Windows
(?<=Win)95 # 匹配前面是Win的95
(?<!Win)95 # 匹配前面不是Win的95
3. 常见模式优化
查找重复单词
\b(\w+)\s+\1\b
匹配IPv4地址
\b(?:250-5|20-4\d|1\d{2}|1-9?\d)(?:\.(?:250-5|20-4\d|1\d{2}|1-9?\d)){3}\b
提取颜色值(十六进制)
#(0-9a-fA-F{3}|0-9a-fA-F{6})\b
六、常用的正则表达式速记
\d = 数字
\w = 字母数字下划线
\s = 空白
. = 任意字符(除换行)
* = 0或多个
- = 1或多个
? = 0或1个
^ = 开头
$ = 结尾
| = 或