


专栏:Java数据结构秘籍
个人主页:手握风云
目录
[一、LRU Cache 的概念](#一、LRU Cache 的概念)
[二、LRU Cache 的实现](#二、LRU Cache 的实现)
[三、JDK 中类似 LRUCahe 的数据结构 LinkedHashMap](#三、JDK 中类似 LRUCahe 的数据结构 LinkedHashMap)
[四、LRU Cache 中的 OJ](#四、LRU Cache 中的 OJ)
[4.1. LRU 缓存](#4.1. LRU 缓存)
一、LRU Cache 的概念
LRU Cache 是 Least Recently Used 的缩写,意为"最近最少使用",它是一种经典的 Cache(缓存)替换算法 。广义上的 Cache 指的是位于速度差异较大的两种硬件之间(例如 CPU 与主存、内存与硬盘、甚至硬盘与网络之间)用于协调数据传输速度差异的结构 。由于 Cache 的容量是有限的,当存储空间耗尽且又有新内容需要添加时,系统就必须依据特定的策略挑选并舍弃原有的部分内容,以腾出空间来存放新的数据 。
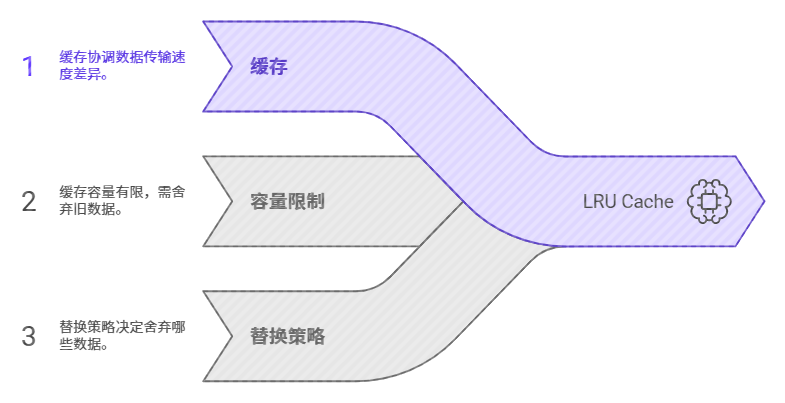
LRU 算法的核心替换原则是将最近一段时间内"最久没有使用过"的内容替换掉 。虽然字面意思是"最近最少使用",但将其理解为"最久未使用"往往更为形象,因为该算法的判断标准是基于最后一次访问的时间远近,优先淘汰那些长时间未被访问的数据 。
二、LRU Cache 的实现
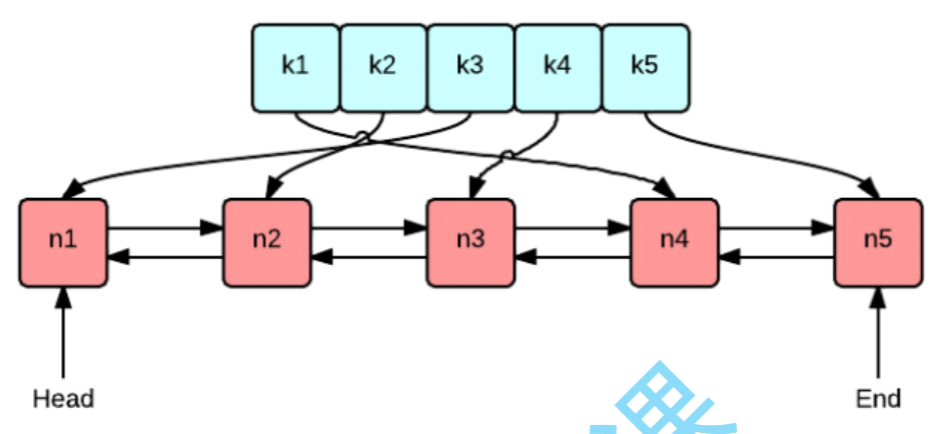
在数据结构实现方面,为了保持高效并实现 时间复杂度的 `put`(存入)和 `get`(读取)操作,经典的 LRU Cache 实现通常采用**双向链表**搭配**哈希表**的组合 。使用哈希表是因为其增删查改的时间复杂度为 ,可以快速定位数据;而使用双向链表则是因为它支持在任意位置进行 的插入和删除,适合动态维护数据的访问顺序 。在这种结构中,数据被访问或新插入后通常会被移动到链表的尾部(代表最近被使用),而当缓存容量达到上限时,链表头部(代表最久未使用)的数据则会被优先移除 。
三、JDK 中类似 LRUCahe 的数据结构 LinkedHashMap
Java 中的 LinkedHashMap 是一个继承自 HashMap 并实现 Map 接口的类,它是一个有序的哈希表,能够根据插入顺序或访问顺序维护键值对的顺序。LinkedHashMap 的主要特性包括:1.LinkedHashMap 会记住元素的插入顺序,并按照插入顺序进行迭代;2.LinkedHashMap 提供了一种访问顺序模式,可以根据访问顺序而不是插入顺序进行迭代。默认情况下,LinkedHashMap 使用插入顺序模式,但如果在构造时将 accessOrder 参数设为 true,则会启用访问顺序模式。在这种模式下,每次调用 get() 或 put() 方法访问已存在的键时,对应的节点会被移动到链表尾部,使最近访问的元素始终位于最后。
java
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
java
// 指定初始容量和负载因子
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 指定初始容量的构造方法。允许自定义初始容量,其他参数使用默认值
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 使用默认的访问顺序(插入顺序),初始容量为16,负载因子为0.75
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
// 指定初始容量、负载因子和访问顺序
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
java
package lru;
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache {
public static void main(String[] args) {
LinkedHashMap<String, Integer> map =
new LinkedHashMap<>(16, 0.7f, true);
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
map.put("four", 4);
System.out.println(map);
System.out.println("获取元素:" + map.get("two"));
System.out.println(map);
}
}如果访问顺序标志设为 true,则按照 LRU 算法进行排列,最近最少使用的值靠前。
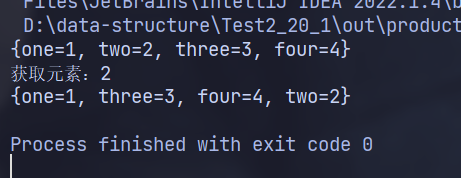
如果没有指定访问顺序标志,默认为 false,只按照插入顺序排列。
java
package lru;
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache {
public static void main(String[] args) {
LinkedHashMap<String, Integer> map =
new LinkedHashMap<>(16, 0.7f);
map.put("one", 1);
map.put("two", 2);
map.put("three", 3);
map.put("four", 4);
System.out.println(map);
System.out.println("获取元素:" + map.get("two"));
System.out.println(map);
}
}
四、LRU Cache 中的 OJ
4.1. LRU 缓存

第一种解法:我们可以通过继承 LinkedHashMap 类,通过重写里面的 get()、removeEldestEntry()、put() 3个方法,从而实现 LRU 算法。
java
class LRUCache extends LinkedHashMap<Integer, Integer> {
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
@Override
public Integer get(Object key) {
// 调用父类的 getOrDefault() 方法,如果不存在对应的 key,返回-1
return super.getOrDefault(key, -1);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
// 如果当前大小超过容量,返回 true,表示需要移除最老的条目
return size() > capacity;
}
@Override
public Integer put(Integer key, Integer value) {
return super.put(key, value);
}
}第二种解法:我们利用自己创建的双向链表与集合框架中的 HashMap 来实现。为了防止在对双向链表的插入与删除操作出现空指针异常,我们可以引入虚拟头节点和虚拟尾节点。
java
import java.util.HashMap;
import java.util.Map;
public class LRUCache {
static class DLinkNode {
public int key;
public int val;
public DLinkNode prev;
public DLinkNode next;
public DLinkNode() {
}
public DLinkNode(int key, int val) {
this.key = key;
this.val = val;
}
@Override
public String toString() {
return "{key=" + key + ", val=" + val + '}';
}
}
public DLinkNode head; // 双向链表的头节点
public DLinkNode tail; // 双向链表的尾节点
public int usedSize; // 双向链表中有效的节点个数
public Map<Integer, DLinkNode> cache;
public int capacity;
public LRUCache(int capacity) {
this.head = new DLinkNode();
this.tail = new DLinkNode();
head.next = tail;
tail.prev = head;
cache = new HashMap<>();
this.capacity = capacity;
}
public void put(int key, int val) {
}
public int get(int key) {
}
}对于 put() 方法,我们需要先判断 key 是否已经存储过。如果没有存储过,就把 key 和节点一起存放进 HashMap 里,节点也需要存储在链表的尾巴中,并且我们还需要判断链表中有效节点的个数,如果大于容量,则需要移除头部的节点。
java
public void put(int key, int val) {
// 一、先检查 key 是否已经存储过
DLinkNode node = cache.get(key);
// 二、没有存储过
if (node == null) {
DLinkNode dLinkNode = new DLinkNode(key, val);
cache.put(key, dLinkNode);
addToTail(dLinkNode);
usedSize++;
// 三、存储过
if (usedSize > capacity) {
DLinkNode remNode = removeHead();
cache.remove(remNode.key);
usedSize--;
}
} else {
// 三、如果存储过
node.val = val;
moveToTail(node);
}
}
/**
* 将指定节点移动到链表尾部
* @param node 需要移动的节点
*/
private void moveToTail(DLinkNode node) {
removeNode(node); // 先移除
addToTail(node); // 再将节点移动到尾部
}
private void removeNode(DLinkNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private DLinkNode removeHead() {
DLinkNode delNode = head.next;
head.next = delNode.next;
delNode.next.prev = head;
return delNode;
}
/**
* 将节点添加到双向链表的尾部
* @param node 要添加的节点
*/
private void addToTail(DLinkNode node) {
tail.prev.next = node;
node.prev = tail.prev;
tail.prev = node;
node.next = tail;
}关于 get() 方法,如果 key 不存在于缓存中,返回 -1。如果存在,直接返回对应的 val,并将该节点移动到链表尾部。
java
public int get(int key) {
DLinkNode node = cache.get(key);
if (node == null) {
return -1;
}
// 最近使用最多的节点移动到链表的尾巴
moveToTail(node);
return node.val;
}