MongoDB 是什么?

文章目录
- [MongoDB 是什么?](#MongoDB 是什么?)
一、MongoDB 概述
MongoDB 是一个基于分布式文件存储 的开源 NoSQL 数据库系统,由 C++ 语言编写,旨在为 Web 应用提供可扩展的高性能数据存储解决方案。它由 MongoDB Inc.(原 10gen 公司)于 2009 年正式推出,是目前最流行、最成熟的文档型数据库之一。
MongoDB 的名字源于"humongous"(巨大的),寓意其能够处理海量数据。它采用了面向文档的数据模型,将数据存储在类似 JSON 的 BSON(二进制 JSON)文档中,使得数据结构更加灵活自然,非常适合现代应用开发。
二、核心概念与数据模型
MongoDB 的基本逻辑结构层次为:数据库 (Database) → 集合 (Collection) → 文档 (Document)。
| 概念 | 说明 | 类比 SQL |
|---|---|---|
| 数据库 (Database) | 物理容器,一个 MongoDB 实例可包含多个数据库。 | 数据库 (Database) |
| 集合 (Collection) | 一组文档,相当于关系型数据库中的表,但不强制定义文档结构。 | 表 (Table) |
| 文档 (Document) | 一条记录,由键值对组成,使用 BSON 格式(类似 JSON,支持更多数据类型如日期、二进制)。 | 行 (Row) |
| 字段 (Field) | 文档中的键,对应属性。 | 列 (Column) |
| 嵌入式文档 (Embedded Document) | 文档中嵌套另一个文档,实现一对一或一对多关系。 | 关联表(需 JOIN) |
| 数组 (Array) | 支持字段值为数组,可包含普通值或嵌入式文档。 | 通常需单独表存储 |
示例文档:
json
{
"_id": ObjectId("5f7b3b2e9d6b5a1a2c3d4e5f"),
"name": "张三",
"age": 28,
"address": {
"city": "北京",
"street": "长安街"
},
"hobbies": ["读书", "游泳", "编程"],
"scores": [
{ "subject": "数学", "score": 90 },
{ "subject": "英语", "score": 85 }
]
}_id是每个文档必须的唯一标识,默认自动生成 ObjectId 类型。
三、主要特性
-
灵活的模式(Schema-less)
集合中的文档可以有不同的字段,字段类型也可动态变化,非常适合迭代开发和多变的数据结构。
-
高性能
- 支持内嵌数据,减少关联查询,读写速度快。
- 提供丰富的索引支持(包括单字段、复合、多键、地理空间、文本索引等),优化查询性能。
- 支持内存映射存储引擎(WiredTiger),充分利用系统内存。
-
高可用性
通过**副本集(Replica Set)**实现自动故障转移和数据冗余。一个副本集包含多个数据节点(一个主节点、多个从节点),主节点故障时自动选举新主节点,保证服务持续可用。
-
水平可扩展性
通过**分片(Sharding)**将数据分布到多个服务器上,支持海量数据存储和吞吐量扩展。分片基于片键(Shard Key)自动划分数据块,对应用透明。
-
丰富的查询语言
支持 CRUD、聚合管道、地理空间查询、全文检索、MapReduce 等,满足复杂分析需求。
-
聚合框架(Aggregation Pipeline)
提供类似 Unix 管道的数据处理机制,可对文档进行过滤、分组、转换、排序等操作,用于数据分析和报表生成。
-
GridFS
用于存储和检索超过 16MB 限制的大文件(如图片、视频),自动将文件分割成块存储。
-
多存储引擎
- WiredTiger(默认):支持文档级并发控制、压缩和检查点。
- In-Memory:纯内存存储,提供极高吞吐量。
- 也支持加密存储引擎等。
-
强大的生态系统
支持几乎所有主流编程语言的驱动,提供 MongoDB Compass(图形化管理工具)、Cloud Manager、Atlas(云托管服务)等。
四、架构组件
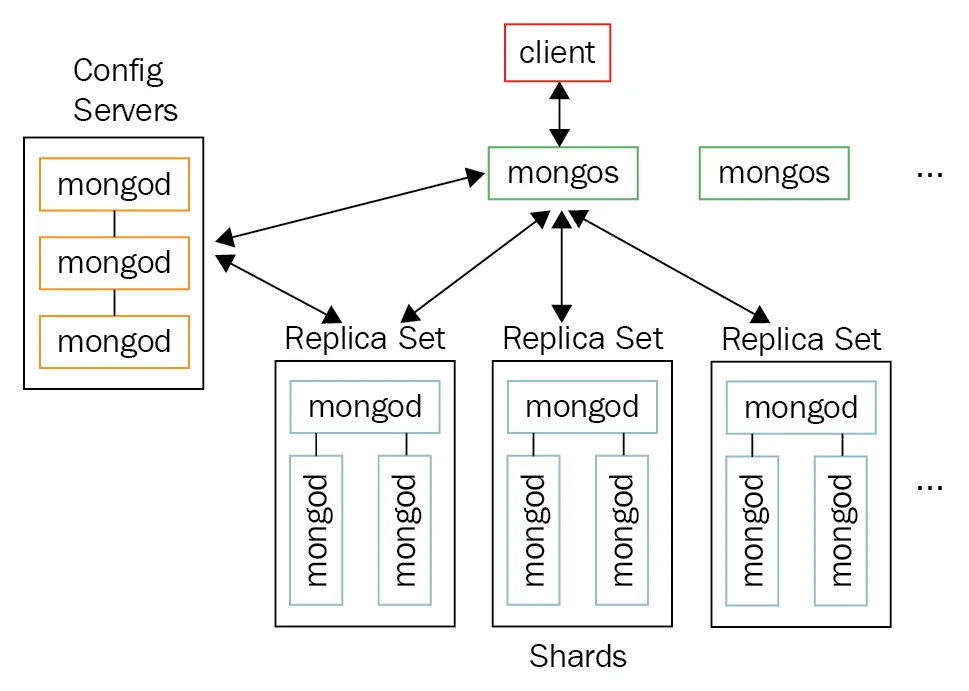
-
mongod:MongoDB 核心进程,负责数据存储、处理请求。在副本集或分片集群中扮演不同角色。
-
mongos:路由服务,用于分片集群,接收客户端请求,将请求路由到正确的分片,聚合结果返回给客户端。
-
配置服务器(Config Server):存储分片集群的元数据(分片和块的路由信息)。
-
副本集(Replica Set):一组 mongod 实例构成的高可用单元,包含一个主节点(Primary)和多个从节点(Secondary)。
-
分片(Shard):每个分片是一个副本集或单个 mongod,负责存储整体数据的一个子集。
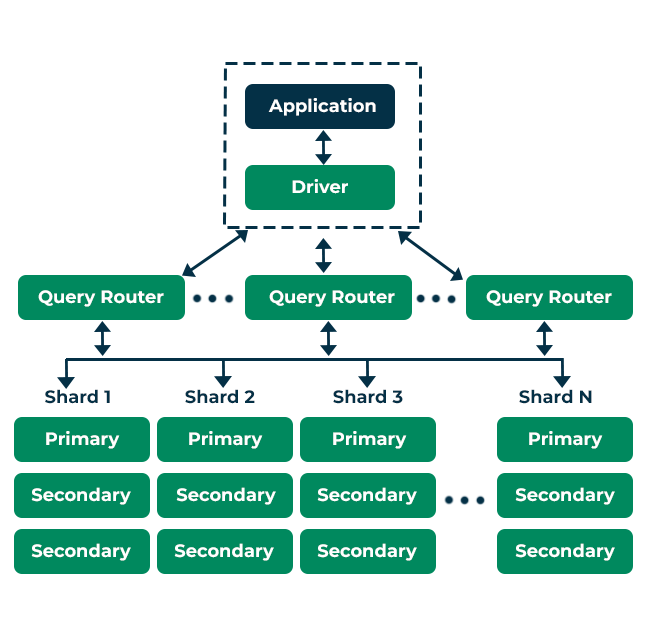
分片与主从架构如图所示:
五、适用场景
适用场景:
- 内容管理/博客/CMS:数据结构多变,文档模型直接对应文章、评论等。
- 实时数据分析/日志系统:高写入吞吐量,聚合框架适合实时计算。
- 物联网:设备数据量大、格式多样,需要快速写入和查询。
- 移动应用:后端灵活适应客户端版本迭代,支持 JSON 数据直接存储。
- 产品目录/用户资料:属性多变,内嵌数组/文档方便存储多值属性。
不适用场景:
- 高度事务性系统(如金融交易):MongoDB 早期缺乏多文档事务,4.0 版本后支持副本集内多文档 ACID 事务,但性能开销较大,复杂事务仍不如传统关系型数据库。
- 复杂关联查询 :虽然支持
$lookup类似左外连接,但频繁关联会影响性能,适合反范式设计。 - 强一致性要求极高的系统:默认读关注/写关注可调,但分布式环境下可能存在短暂不一致。
六、与关系型数据库(如 MySQL)的对比
| 维度 | MongoDB | MySQL |
|---|---|---|
| 数据模型 | 文档型(BSON),支持嵌套、数组 | 关系型,二维表,严格模式 |
| Schema | 动态模式,同一集合可存不同结构文档 | 固定表结构,需预先定义列 |
| 查询语言 | 基于 JSON 的丰富查询语法 | SQL |
| 事务 | 4.0+ 支持多文档 ACID 事务(副本集内),但有限 | 成熟的事务支持,ACID 特性强 |
| 扩展方式 | 原生水平分片(自动数据分布) | 垂直扩展为主,水平需借助中间件 |
| 索引 | 支持各种索引,包括地理空间、文本 | 标准 B-Tree 索引,支持全文索引(有限) |
| JOIN | 不推荐,通过内嵌或 $lookup 实现 | 通过 JOIN 实现复杂关联 |
| 适用场景 | 大数据量、高并发、灵活数据结构 | 传统应用、金融、强一致性需求 |
七、基本操作示例(以 mongo shell 语法)
javascript
// 切换到数据库
use mydb
// 插入一条文档到 users 集合
db.users.insertOne({ name: "李四", age: 30, tags: ["developer"] })
// 插入多条
db.users.insertMany([ { name: "王五", age: 25 }, { name: "赵六", age: 35 } ])
// 查询所有文档
db.users.find()
// 条件查询(年龄大于 30)
db.users.find({ age: { $gt: 30 } })
// 更新文档(设置年龄 + 添加标签)
db.users.updateOne({ name: "李四" }, { $set: { age: 31 }, $push: { tags: "lead" } })
// 删除文档
db.users.deleteOne({ name: "赵六" })
// 聚合管道示例:按年龄分组统计人数
db.users.aggregate([ { $group: { _id: "$age", count: { $sum: 1 } } } ])八、优缺点总结
优点:
- 开发效率高:无模式变更痛苦,快速迭代。
- 扩展性强:分片集群易于横向扩展。
- 高可用:副本集自动故障转移。
- 性能优秀:特别是读多写少、海量数据场景。
- 丰富的查询和索引功能。
缺点:
- 事务支持较弱(尽管已改进)。
- 无 JOIN 操作,设计上需要反范式化,可能造成数据冗余。
- 内存占用较大(依赖内存映射)。
- 复杂的聚合操作可能性能不佳。
九、版本演进
- 1.x - 2.x:基础功能,引入分片、副本集。
- 3.x:WiredTiger 成为默认存储引擎(3.2),支持文档校验、部分索引。
- 4.x:支持多文档事务(4.0),分布式事务(4.2),增强聚合能力。
- 5.x - 6.x:进一步优化性能,增加时间序列集合、加密查询、可重试读写等。
十、总结
MongoDB 以其灵活的数据模型、强大的水平扩展能力和易用性,在现代应用开发(尤其是 Web、移动、IoT 和大数据领域)中占据了重要地位。它并非要取代传统关系型数据库,而是提供了一种针对特定场景更优的解决方案。选择 MongoDB 时,需根据业务特性权衡其优缺点,设计合理的数据模型(合理内嵌、引用),才能充分发挥其优势。