如何使用Redis快速实现布隆过滤器?
先介绍一下什么是布隆过滤器:它是一种概率性数据结构,用来判断某个属于是否在集合中。
特点是:存在误判,但判断不在就一定不在
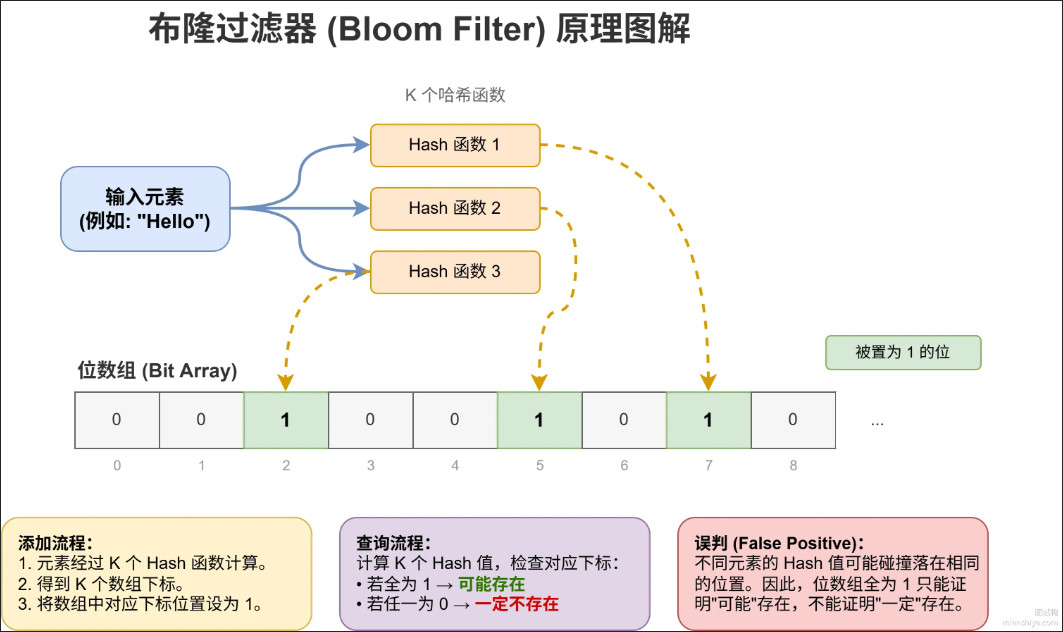
原理:
布隆过滤器由一个位数组和k个独立的哈希函数组成。
添加元素时 ,通过k个哈希函数将元素映射到数组的k个位置上,将这些位置设置为1。
检查元素是否存在时 :同样计算k个位置,乳沟所有位置都是1,说明元素可能存在;只要有一个位置是0,代表一定不存在。
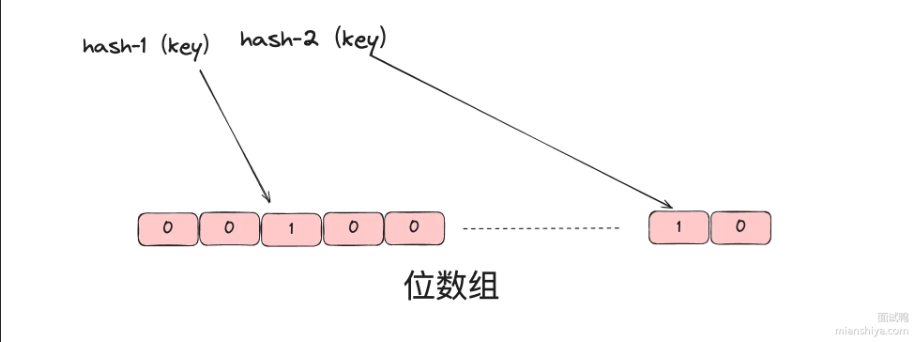
图为假设:某个key通过hash-1和hash-2两个哈希函数,定位到数组中的值都为1,则说明存在。
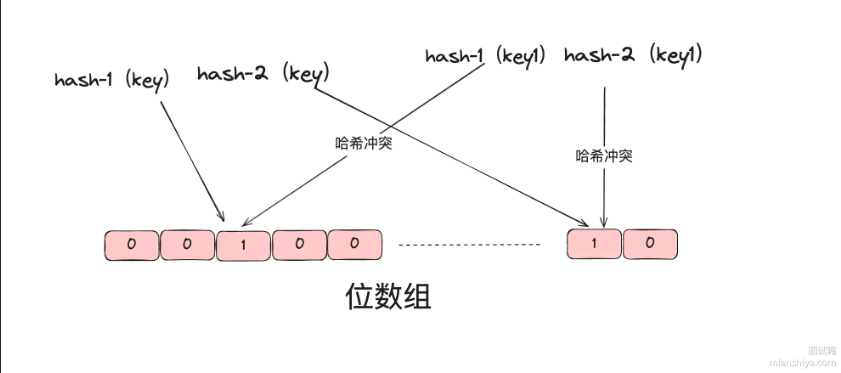
为什么会出现误判
如果布隆过滤器判断一个元素不存在集合中,那么这个元素一定不在集合中,如果判断元素存在集合中则不定是真的,因为哈希可能会存在冲突。因此布隆过滤器有误判的概率。
我们现在对布隆过滤器有了前置的理解,接下来回归正题,如何在Redis中快速实现布隆过滤器。
在Redis中实现布隆过滤器有两种方式:
- 位图手动实现
- 官方的RedisBloom模块
这两种方式的实现方式:
位图方式就是用Redis的SETBIT/GETBIT命令,自己管理哈希函数和位数组。添加元素时,用K个哈希函数算出K个位置,把这些位置都设成1;查询时同样算Κ个位置,只要有一个是0就说明元素肯定不存在,全是1就说明可能存在。
布隆过滤器由一个位数组和k个哈希函数组成。添加元素时,通过K个哈希函数计算出K个位置,将这些位置设为1。查询时计算同样的k个位置,如果全为1则可能存在,只要有一个为0 则一定不存在。误判发生在不同元素的哈希值产生冲突时。
拓展
关于误判率和参数选择
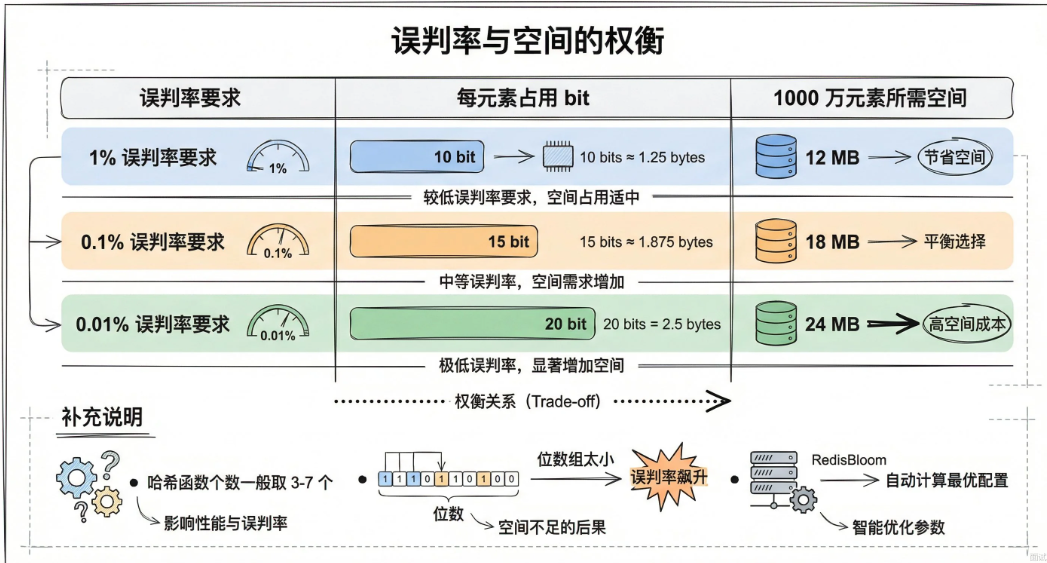
误判率取决于三个因素:位数组大小m,哈希函数个数k,已插入元素数量n。
理论最优哈希函数个数是k=(m/n)*ln2,大约是0.7倍的位数组于元素数量之比。
实际工程中,一般这样估算:
1)要求误判率 1%,每个元素大约需要 10 bit
2)要求误判率 0.1%,每个元素大约需要 15 bit
3)要求误判率 0.01%,每个元素大约需要 20 bit
比如要存 1000 万个元素,误判率控制在 1%,位数组大约需要1 亿 bit,也就是12MB 左右。
布隆过滤器的使用场景
场景特点:数据量大,允许小概率误判,只需要判断存在性。
1)爬虫URL去重:几亿个URL判断有没有爬过,误判了顶多漏爬一个页面
2)垃圾邮件过滤:黑名单地址判断,误判了可能误杀一封正常邮件,但概率可控
3)推荐系统去重:判断用户有没有看过某个内容,误判了顶多少推一条
4)分布式缓存层:HBase、Cassandra 都用布隆过滤器快速判断某个key 在不在某个HFile/SSTable里,减少磁盘10
如何使用Redis快速实现排行榜
答:用Redis的Sorted Set 来实现。因为Sorted Set里每一个成员都绑定一个score分数,Redis回按照score来排序,而且底层用跳表实现,插入,删除,查排名等操作都是O(logN),百万级数据也能抗住。

核心有如下几个操作:
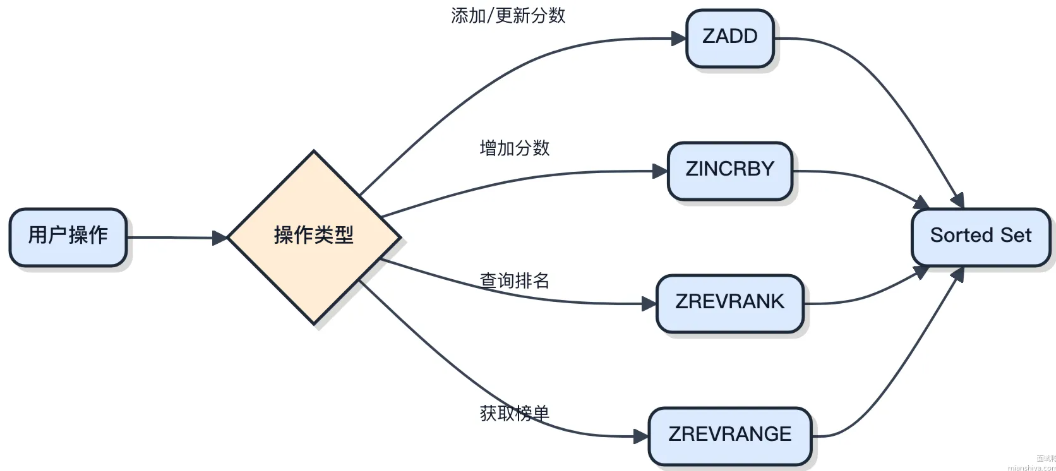
- ZADDleaderboard 1000user1添加用户和分数,用户已存在就更新分数
- ZREVRANKleaderboarduser1查某个用户排第几名,从0开始计数
- ZREVRANGEleaderboard09WITHSCORES 取前10名,连分数一起返回
- ZINCRBYleaderboard 500user1给用户加分,打游戏升级、签到加积分都用这个
java
// 游戏排行榜示例
Jedis jedis = new Jedis("localhost", 6379);
// 玩家打完一局,更新分数
jedis.zadd("game:rank:202601", 8500, "player_10086");
// 查自己排第几
Long rank = jedis.zrevrank("game:rank:202601", "player_10086");
System.out.println("当前排名:" + (rank + 1)); // 排名从0开始,+1显示
// 拉取前100名展示
Set<Tuple> top100 = jedis.zrevrangeWithScores("game:rank:202601", 0, 99);
for (Tuple t : top100) {
System.out.println(t.getElement() + " : " + t.getScore());
}拓展
大规模排行榜分片
当用户数据量达到上亿,或者需要支持多维度的排行榜,就得考虑分片,大致可分为三类:
- 时间:每天每周每月各一个key,比如rank:daily:20260115、 rank:weekly:202603
- 区间:分数0-1000一个key,1000-10000一个key,查总榜时聚合
- 用户:对用户ID取模分到不同key,适合不关心全局排名只看附近排名的场景
关于Sorted Set 底层的跳表解释
Sorted Set 底层的跳表是一种多层链表结构,通过建立索引实现类似二分查找的效果,从而让有序数据的插入,查找和范围查找达到O(log n)的效率
Redis为什么这么快
三个核心原因:
- 纯内存操作
- 单线程+IO多路复用
- 高效的数据结构
内存与磁盘
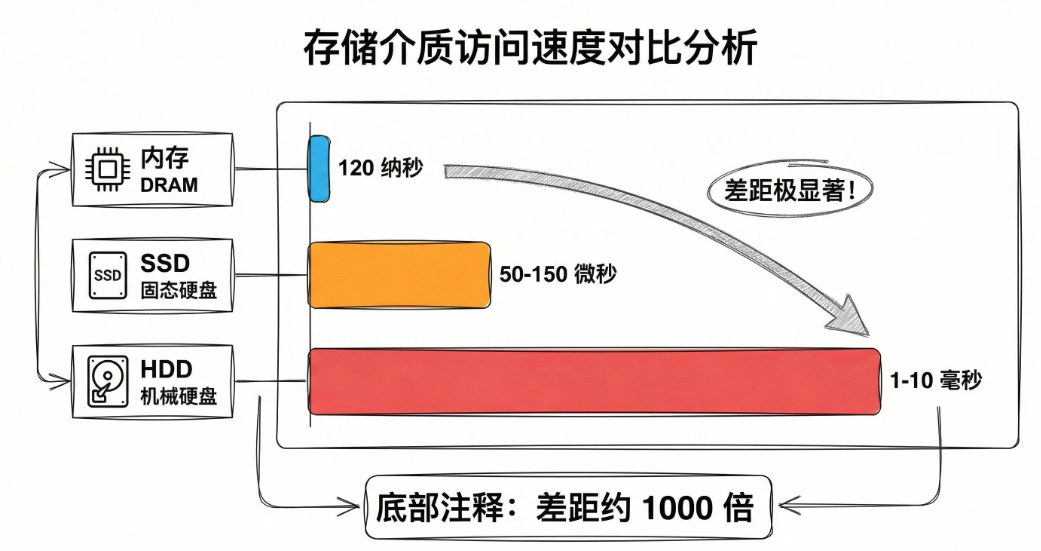
内存较磁盘的范文速度快了1000倍。Redis讲数据全部放在内存中,除了持久化,基本不跟磁盘打交道
单线程+IO多路复用
Redis用单线程执行核心命令,没有了锁竞争,没了上下文切换。网络IO用epoll多路复用,一个线程就能同时盯着几万个socket连接,哪个连接有数据旧处理哪个,不用傻等。
高效的数据结构
Redis的数据结构都是为了快而生。String的底层是SDS,O(1)获取长度;Hash小数据量用ziplist省内存,大数据用hashtable保证O(1)查询;ZSet用调表,插入查询都是O(logN)。
拓展
我们来对上述三个要点进行更加详细的介绍 :
为什么内存这么快
CPU访问内存走的是总线,数据直接从内存条的DRAM芯片读到CPU缓存,整个过程是电信号传输,纳秒级别。
磁盘:机械硬盘需要等磁头寻道,盘片旋转,物理动作旧很慢。SSD虽然没有机械部件,但要经过主控芯片、闪存颗粒的寻址,还有PCle 或 SATA总线的协议开销,怎么都比内存慢一个数量级。
Redis及那个热数据放在内存,冷数据放在磁盘。
IO多路复用原理
传统的阻塞IO,一个线程只能盯一个连接,连接多了必须开多个线程,线程切换开销大。
**IO多路复用是让一个线程同时监听多个文件描述符。**linux下常用的是epoll:
- 把监听到的socket注册到epoll实例
- 调用epoll_wait阻塞等待
- 有时间就绪时,epoll_wait返回就绪的socket列表
- 挨个处理这些socket的读写
Redis 在Linux下用epoll,macOS下用kqueue,Windows下用select。底层实现不一样,但思路都是样的:用事件驱动替代线程轮询。
单线程为什么不是瓶颈
Redis的瓶颈不在CPU,在网络带宽和内存带宽。一条简单的GET/SET命令,CPU执行时间时微妙级,网络返回才是主要的。
单线程的好处:
- 没有锁,代码简单
- 没有线程切换,上下文切换一次要几微妙
- CPU缓存命中率高,数据结构不会被别的线程修改
数据结构的高效设计
SDS :比c语言原生字符串多存了一个len字段,获取长度O(1)还支持二进制安全,能存图片,序列化对象。
ziplist:紧凑的连续内存结构,省内存但查询是O(N)。Hash、List、ZSet在数据量小的时候都用它。
quicklist:Redis 3.2 之后List 的底层实现,把多个ziplist 用双向链表串起来,兼顾内存和性能。
skiplist:ZSet的底层之一,查询、插入、删除都是O(logN),实现比红黑树简单,范围查询更方便。
为什么在6.0版本引入了多线程
在上面我们讲到了Redis是单线程操作的。好处是:没有锁竞争;没有上下文切换的开销。一个线程配合IO多路复用。
单线程的瓶颈不是在CPU,而是在内存和网络IO 。
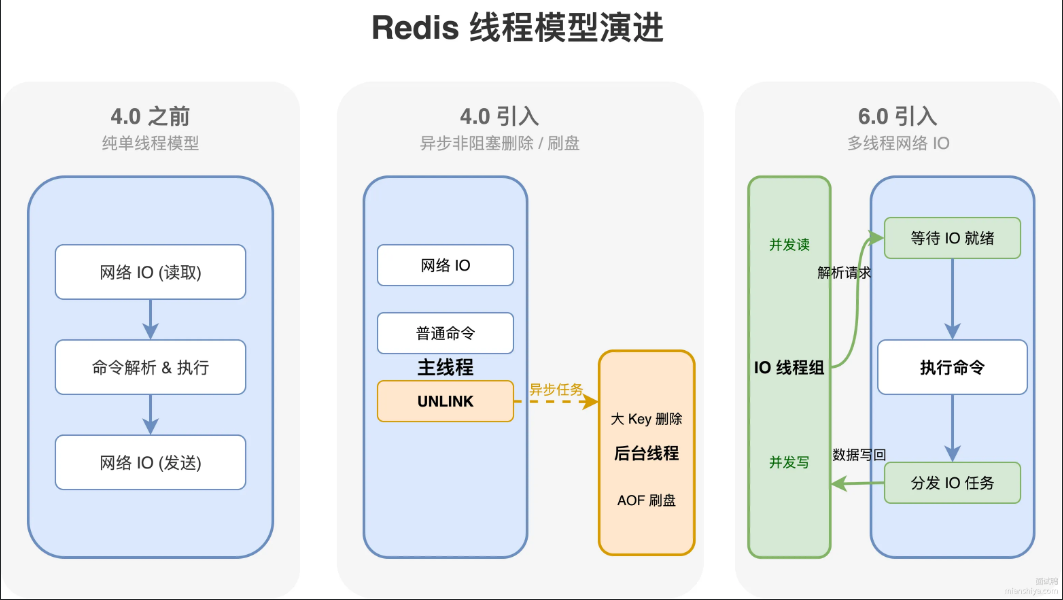
我们来看不同版本对线程的更新操作:
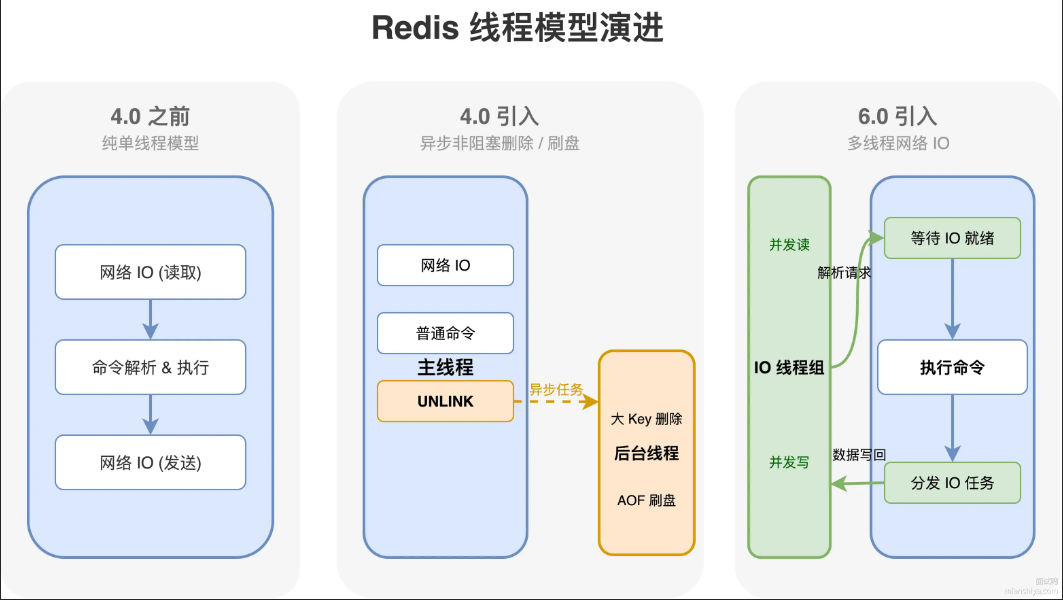
4.0 之前:纯单线程,网络IO、命令执行都在主线程
4.0 引入:后台线程处理大 key 删除、AOF 刷盘这些耗时操作
6.0 引入:多线程处理网络1O,主线程只负责执行命令
拓展
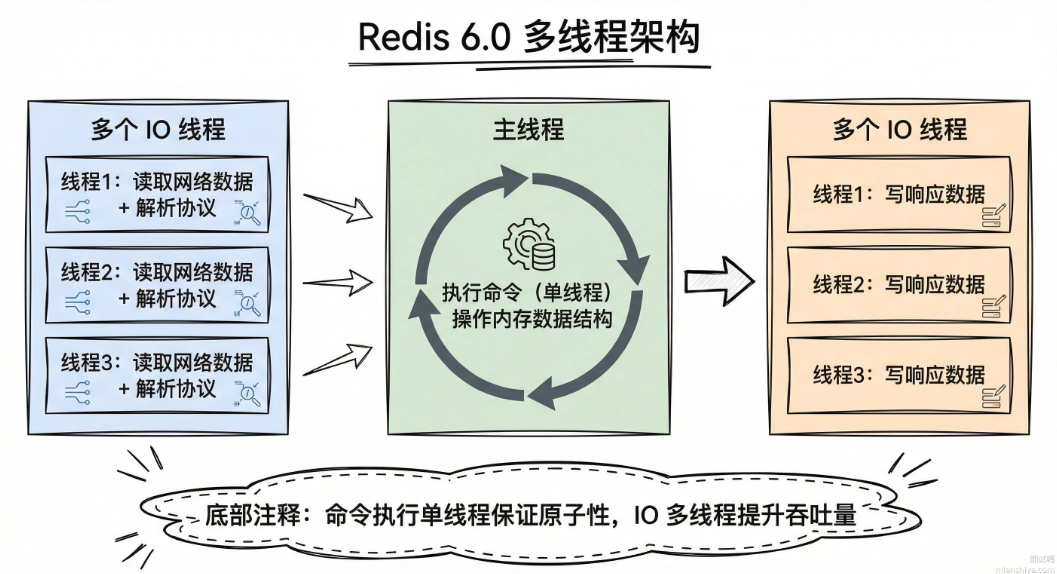
6.0多线程的工作原理
总结:
多线程只用于网络IO,命令执行还是单线程
具体流程:
- 主线程来接收到客户端连接,把待读的socket分配给IO线程
- IO线程并行读取网络数据,解析成Redis命令
- 主线程单线程执行所有命令
- 执行完毕后,IO线程并行写响应数据