0. 简介
LLM:就是大语言模型,指参数量较大且具有较强生成能力的语言模型。
vLLM:功能完备的生产级大语言模型推理引擎。
nano-vllm:是vLLM的极简教学版实现,代码只有1200行左右。
作为算法和infra小白,希望通过nano-vllm的学习,学习了解大模型infra的相关知识。
1. 大模型推理过程

大语言模型的推理过程基本如上所示,大致分为四个阶段:
- 输入阶段: 用户输入一段文本,系统将这段文字分解为Token,每个Token可以映射到一个整数ID,一串Token就变成了模型可以处理的整数ID序列。
- 预填充阶段: 对整段输入做第一次完整的计算,生成首个输出Token。经过embedding,位置编码,attention,MLP,softmax等layer的处理,得到最终模型输出的logits。这个logits就是个概率分布,一般而言选取概率最大的预测token,当然这和设置的temperature有关。
- 自回归解码阶段: 每一次推理过程都是选取下一个token,然后拼接到已有序列的组成新的序列,作为下一次推理的输入,直到达到最大token限制或者生成特殊的 <eos> 结束符号。
- 输出阶段: 将模型输出的token ID转换为文字,返回给用户。当然,可以在第3步的解码阶段,每生成一个Token就进行一次输出阶段,以实现流式输出的效果,让用户可以直观感受模型的推理进展。
1.1 相关耗时指标
1.1.1 TTFT (Time To First Token)
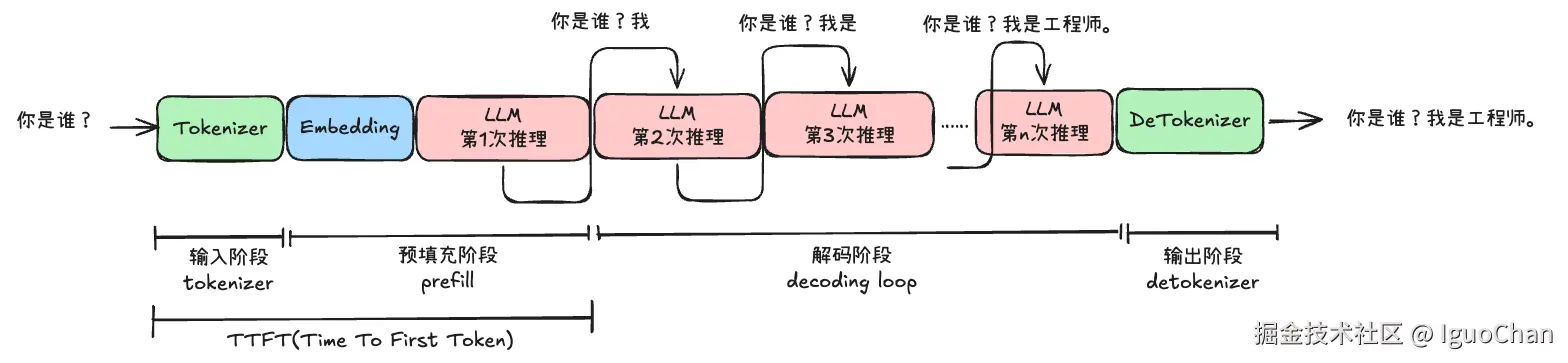
TTFT其实就是大模型说话前的思考时间 。模型进行一次完整的、并行的前向传播 。它需要为提示词中的每一个token 计算其隐藏状态,并尤其关键的是,需要为每一个token 计算并缓存其Key和Value向量,即初始化KV Cache。
其实TTFT主要就是prefill耗时,由于一次性读取完整的输入序列,对每一层transformer计算所有token的Q、K、V,并且完成完整的self-attention和前馈网络计算。所以说,在这个阶段是典型的计算密集型的。而上面每个token产生的K/V会被缓存下来,形成后续重复迭代使用的KV Cache。
1.1.2 TPOT (Time Per Output Token)
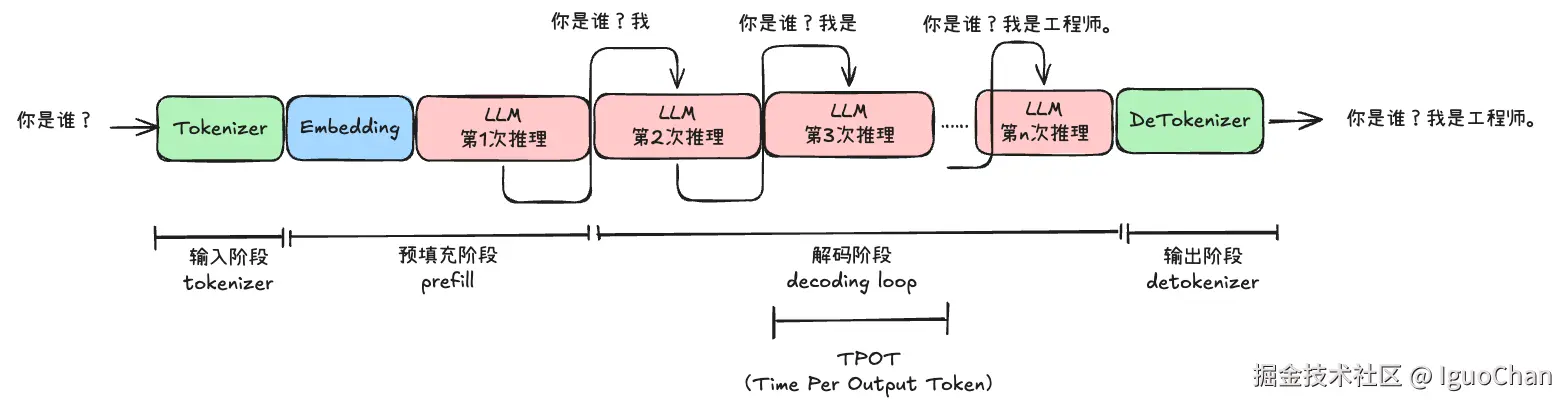
从前面可以看出来,在自回归解码阶段,每次推理产生一个token,而这个过程中,每次吐出一个token的时间就是TPOT:大模型说一个词的时间。
在decode阶段,由于KV Cache的机制,无需重复计算之前的大量的token,GPU的利用率较低,而占用的显存较多。
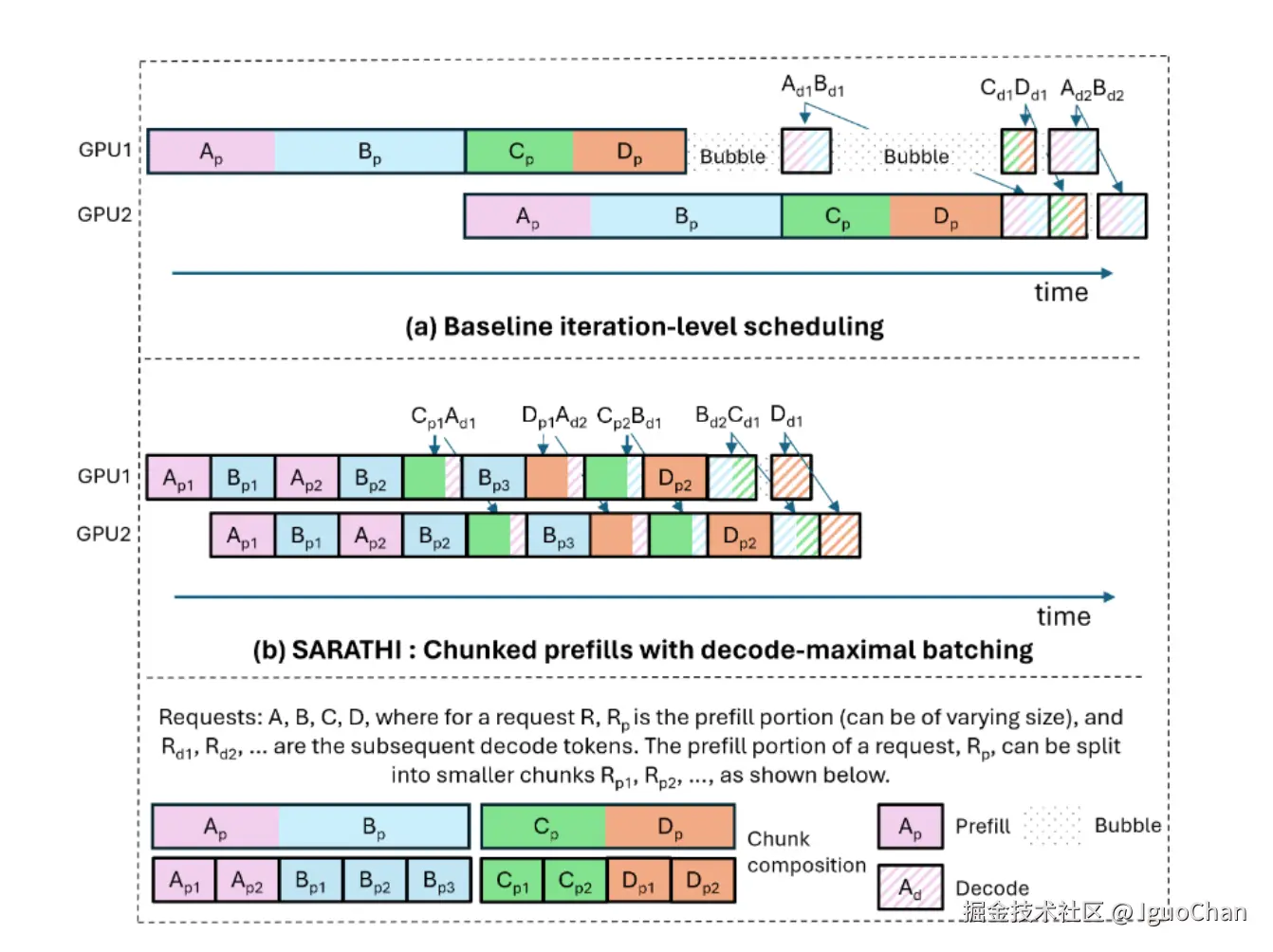
在传统的推理框架中,如上,prefill和decode中间有一条非常明显的边界,只有当全部的输入token完成prefill之后,decode才开始。而Chunked Prefill的出现,就是为了打破这个边界,顾名思义,其会将prefill变成可流水线的过程。打个比较通俗的比喻就就是,prefill阶段可以搭载decode阶段未被充分利用的算力,提升整体的利用率。
1.1.3 ITL (Inference Time Latency)
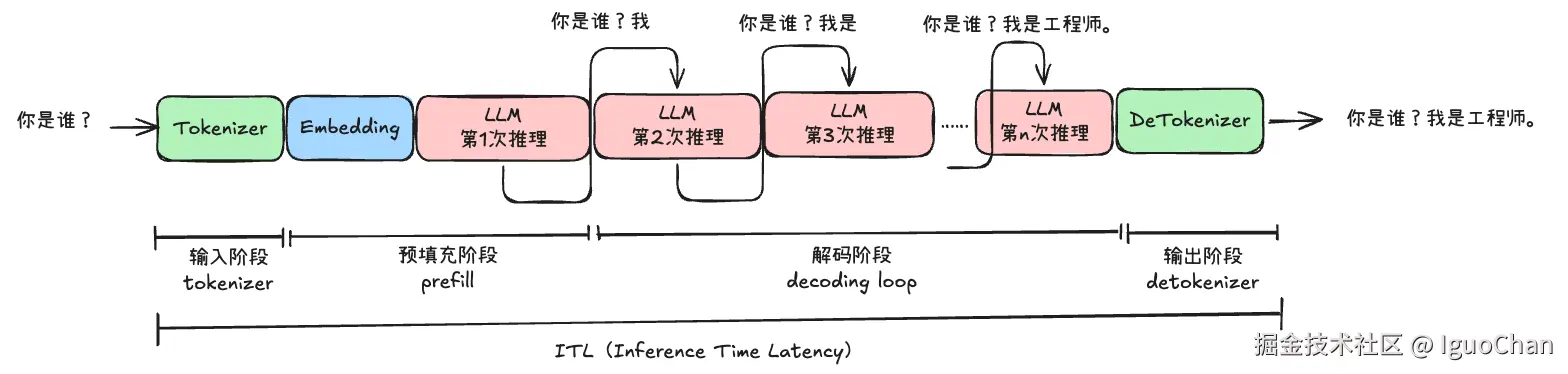
总的时间
ITL=TTFT+n×TPOT
2. nano-vllm
nano-vllm是社区开源的一个非常轻量级的vLLM实现,其隐藏了底层的cuda代码,是新手入门的完美选择。其代码量只有1200行,却实现了推理框架核心的技术原型。下面,我们就先通过一个例子来入门。
python
import os
from nanovllm import LLM, SamplingParams
from transformers import AutoTokenizer
def main():
path = os.path.expanduser(
"~/.cache/huggingface/hub/models--Qwen--Qwen3-0.6B/snapshots/c1899de289a04d12100db370d81485cdf75e47ca")
tokenizer = AutoTokenizer.from_pretrained(path) # 加载tokenizer
llm = LLM(path, enforce_eager=True, tensor_parallel_size=1) # 加载LLM
sampling_params = SamplingParams(temperature=0.6, max_tokens=256) # 采样参数设置
prompts = [
"你是谁?",
"list all prime numbers within 100",
]
# 应用聊天模板
prompts = [
tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
for prompt in prompts
]
outputs = llm.generate(prompts, sampling_params)
for prompt, output in zip(prompts, outputs):
print("\n")
print(f"Prompt: {prompt!r}")
print(f"Completion: {output['text']!r}")
if __name__ == "__main__":
main()可以看出,以上是一段离线推理的代码,其中nanovllm作为离线库使用,如果需要支持HTTP服务化接口,需要自行封装。运行结果如下:
vbnet
/home/iguochan/miniconda3/envs/nano-vllm-env/bin/python /home/iguochan/workspace/github/nano-vllm/example.py
`torch_dtype` is deprecated! Use `dtype` instead!
Generating: 100%|██████████| 2/2 [00:04<00:00, 2.25s/it, Prefill=50tok/s, Decode=78tok/s]
Prompt: '<|im_start|>user\n你是谁?<|im_end|>\n<|im_start|>assistant\n'
Completion: '<think>\n好的,用户问我是谁。首先,我需要确认用户的身份,但根据问题本身,用户是直接提问的。作为AI助手,我需要以专业的态度回答,同时保持友好和自然的交流方式。\n\n接下来,我应该明确说明我是AI助手,提供一些基本信息,比如我的功能和能力。同时,可以简要介绍自己的工作内容,让用户了解我的用途。此外,保持回答简洁明了,避免冗长,让用户感到轻松愉快。\n\n在回答中,我应该强调我的能力,比如可以提供帮助、回答问题、协助完成任务等。同时,可以提到我可能存在的局限性,让用户知道我在特定领域可能无法提供详细信息,但可以尽力帮助解决问题。\n\n最后,确保整个回答符合用户的需求,保持积极和友好的语气,让用户感到被重视和支持。\n</think>\n\n我是AI助手,可以为您提供帮助和支持。如果您有任何问题或需要协助,请随时告诉我!<|im_end|>'
Prompt: '<|im_start|>user\nlist all prime numbers within 100<|im_end|>\n<|im_start|>assistant\n'
Completion: "<think>\nOkay, so I need to list all the prime numbers between 100. Let me start by recalling what a prime number is. A prime number is a number greater than 1 that has no positive divisors other than 1 and itself. So, first, I need to check numbers starting from 100 upwards and see which ones meet the criteria.\n\nStarting with 100. Let me check if 100 is prime. Well, 100 is even, so it's divisible by 2, right? And since 100 is greater than 2, that means it's not prime. So 100 is out.\n\nNext number is 101. Let me check if 101 is prime. Hmm, 101... Well, 101 divided by 2 is 50.5, so not divisible by 2. Divided by 3? Let me do 3*33=99, so 101-99=2, so no. 5? Ends with 1, so no. 7? Let's see, 7*14=98, 101-9"
进程已结束,退出代码为 0接下来的学习中,我们就将通过学习nano-vllm来一步步的探索大语言模型的推理原理和推理框架的运行原理。