OpenClaw 会话机制与记忆系统深度剖析
OpenClaw 会话机制与记忆系统深度剖析:文件源真理 + 混合检索驱动的持久化 Agent OS 架构
大家好,我是fishyue,这次分享的是 OpenClaw 会话机制与记忆系统。
因为最近一直在折腾openclaw,看了很多博客和视频都在刷屏它,通过了解它有一定的安全风险,所以我是在 win 10 平台下 安装VM虚拟机,然后在安装 centos 7 系统下 使用docker 安装openclaw。
这样安装是最效率也是最方便的,整个流程下来,半个小时解决战斗,麻烦的是,为解决这个大龙虾失忆的问题,也就延伸出我写以下这篇文章的原因,去理解Peter Steinberger是如何构建起这个大龙虾的。
每次启动后,都需要让他去读下MEMORY.MD他才会恢复之前的上下文内容。
然后我还使用QMD去记忆核心的事情,并且QMD能够解决"检索速度和质量"的问题,重要是他免费,而且节省龙虾token。
 当然也有解决每次/rest 或者新建对话框失忆的问题,这个我下次会分享。
当然也有解决每次/rest 或者新建对话框失忆的问题,这个我下次会分享。
以下是我对 OpenClaw 会话机制与记忆系统深度剖析:
2026 年的 Agent 浪潮中,LLM 的核心瓶颈不再是推理速度,而是状态持久化与上下文管理 。传统框架(如 LangChain Memory 或 MemGPT)要么依赖云端向量库(隐私风险 + 延迟),要么简单追加历史导致 token 爆炸。OpenClaw(前 Clawdbot/Moltbot,由 Peter Steinberger 开源)给出了极简却硬核的本地优先方案:一切记忆以纯 Markdown 文件为单一源真理(Source of Truth),模型仅读取磁盘上显式写入的内容。会话状态通过 JSONL append-only 日志 + 自动 compaction 管理,检索层采用 SQLite-vec 驱动的 hybrid(vector + BM25 + MMR + temporal decay)搜索。
本文结合官方文档(docs.openclaw.ai/concepts/memory)、Substack 架构解析(ppaolo)、Gitbook 深度笔记(snowan)、DEV.to/Medium 技术拆解,以及社区讨论(如 @indexsy 的高级内存套件提示、@ivaavimusic 的本地 embedding 启用),系统化拆解 OpenClaw 的会话生命周期、记忆分层架构、推理流水线及设计权衡。结合用户提供的 OpenClaw 生成内容,进行硬核技术扩展。
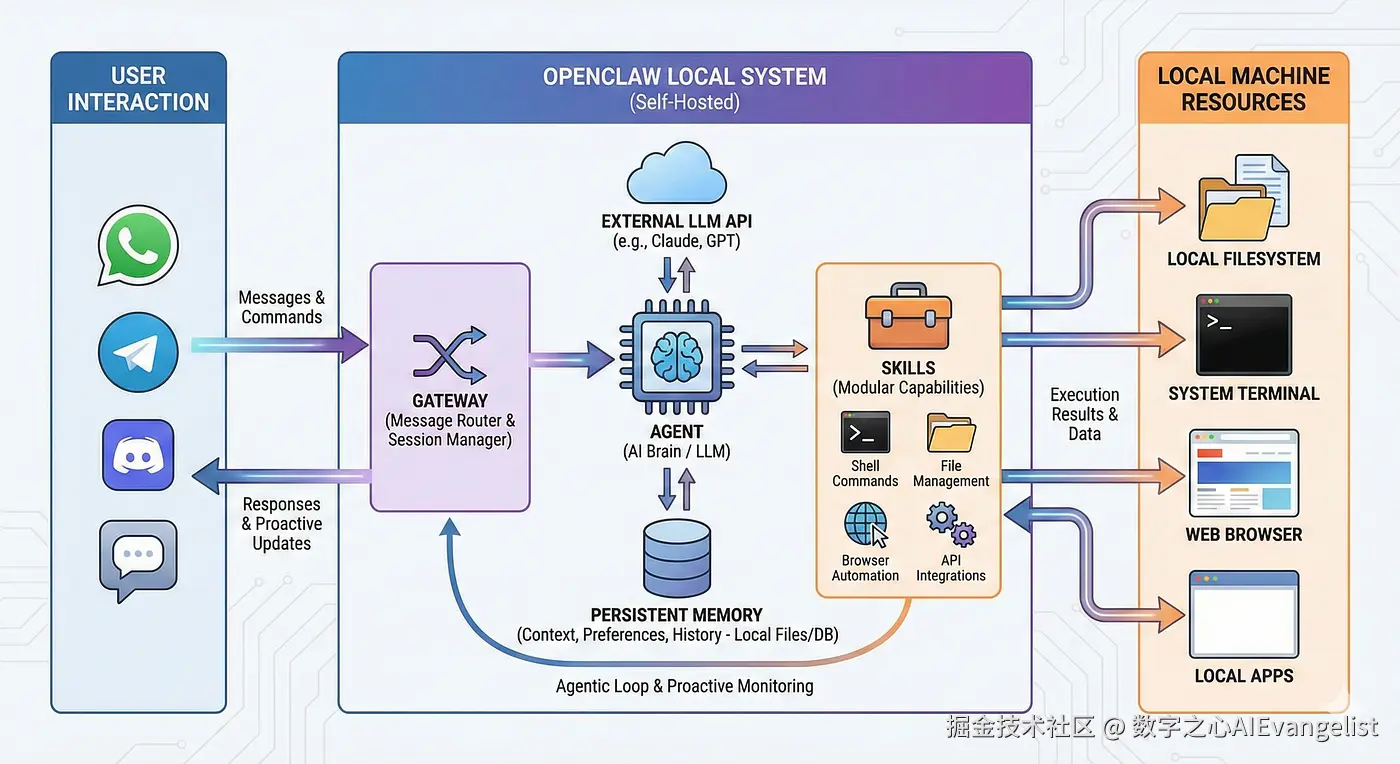 (图:OpenClaw 高层架构概览。Gateway 负责 Session Resolution 与消息路由,Agent Runtime 组装上下文(Session History + Workspace + Persistent Memory),Skills 通过 sandbox 执行,持久化内存以本地文件系统 + DB 为后盾。来源:Medium / Tech-Practice)
(图:OpenClaw 高层架构概览。Gateway 负责 Session Resolution 与消息路由,Agent Runtime 组装上下文(Session History + Workspace + Persistent Memory),Skills 通过 sandbox 执行,持久化内存以本地文件系统 + DB 为后盾。来源:Medium / Tech-Practice)
一、会话生命周期机制(Session Lifecycle):OS 进程隔离的 Agent 实现
OpenClaw 会话设计仿照操作系统进程模型,强调命名空间隔离、安全边界与状态持久化。
1.1 初始化与重置流程
-
• 新会话创建 :
/new或/reset命令触发 Gateway Session Resolution。新 Session ID 生成(格式:agent:<agentId>:<type>,如agent:main:telegram:dm:...或group:discord:...)。 -
• 上下文重置:短期内存(Session Context)清零,重新加载 workspace 根目录核心文件。
-
• 模型绑定:动态加载配置模型(我使用的是:longcat/LongCat-Flash-Thinking-2601,常通过 OpenRouter/Kimi 等)。
-
• 持久化存储 :所有对话以 append-only JSONL 形式落盘于
~/.openclaw/agents/<agentId>/sessions/,支持 branching(对话树 fork)与恢复。
1.2 记忆读取优先级(严格顺序)
-
- 当前会话实时历史(Session JSONL)------ 首选,保持连续性。
-
- Workspace 核心文件 :
AGENTS.md(全局规范)、SOUL.md(人格/语气)、USER.md(用户画像)、TOOLS.md(工具使用指南)。
- Workspace 核心文件 :
-
- 条件加载 :
MEMORY.md+memory/YYYY-MM-DD.md需显式memory_get/memory_search(主私聊会话可配置自动注入部分;群聊永不加载,防敏感泄露)。
- 条件加载 :
这种显式读取避免了"自动过载",新会话启动默认仅读 today + yesterday 日志(<2000 tokens)。
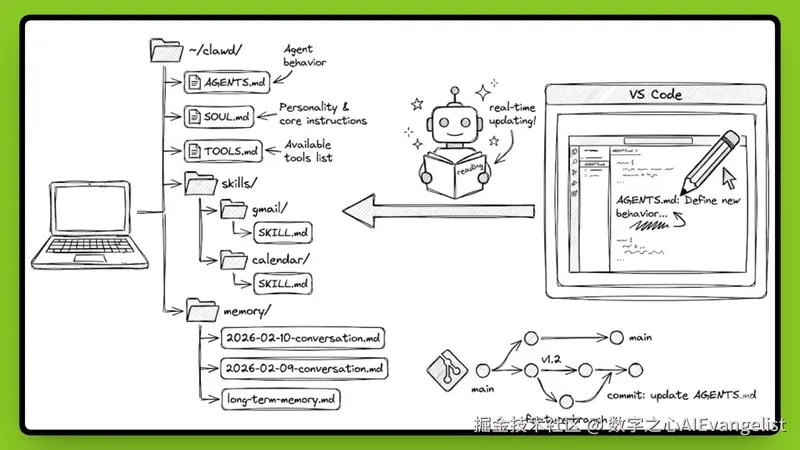 (图:手绘 OpenClaw workspace 文件结构示例。核心 MD 文件实时在 VS Code 中可见/可编辑,daily logs 自动归档。来源:DEV.to / entelligenceai)
(图:手绘 OpenClaw workspace 文件结构示例。核心 MD 文件实时在 VS Code 中可见/可编辑,daily logs 自动归档。来源:DEV.to / entelligenceai)
二、记忆分层架构:类 OS 内存层次的 Agent 实现
OpenClaw 将记忆拆为四层,完美平衡速度、容量、持久性与安全性(对比 Mem0 插件的云增强或 Obsidian 集成)。
2.1 L1:短期记忆(Session Context)
-
• 生命周期:仅当前会话。
-
• 内容:最近轮次对话 + tool call/results。
-
• 特点:volatile,compaction 后部分总结归档。
2.2 L2:工作空间记忆(Workspace Files)
-
• 配置文件 :
SOUL.md(人格)、USER.md(偏好)、AGENTS.md(规范)、TOOLS.md。 -
• 学习记录 :
memory/YYYY-MM-DD.md(append-only,每日自动创建,session start 加载 today + yesterday)。 -
• 扩展 :
skills/<name>/SKILL.md+ 子项目文件夹。
2.3 L3:长期记忆(MEMORY.md)
-
• 内容:核心事实、决策历史、lessons learned、用户偏好、active projects。
-
• 安全:仅 main/private session 加载(group 上下文永不注入)。
-
• 人类可控:直接用编辑器 curation,每周 review distill daily logs。
2.4 L4:检索加速层(Hybrid Search Index)
-
• 存储 :每 agent 独立
~/.openclaw/memory/<agentId>.sqlite(sqlite-vec 虚拟表)。 -
• 索引策略:Markdown chunking(~400 tokens/chunk + 80 overlap),SHA-256 dedup + embedding cache。
-
• 混合检索:70% vector (cosine) + 30% BM25 (FTS5) → weighted fusion → MMR rerank (λ=0.7) → temporal decay (halfLife=30 days)。
-
• 高级:QMD backend(实验,更强本地搜索引擎)、session transcripts 索引(experimental.sessionMemory)。
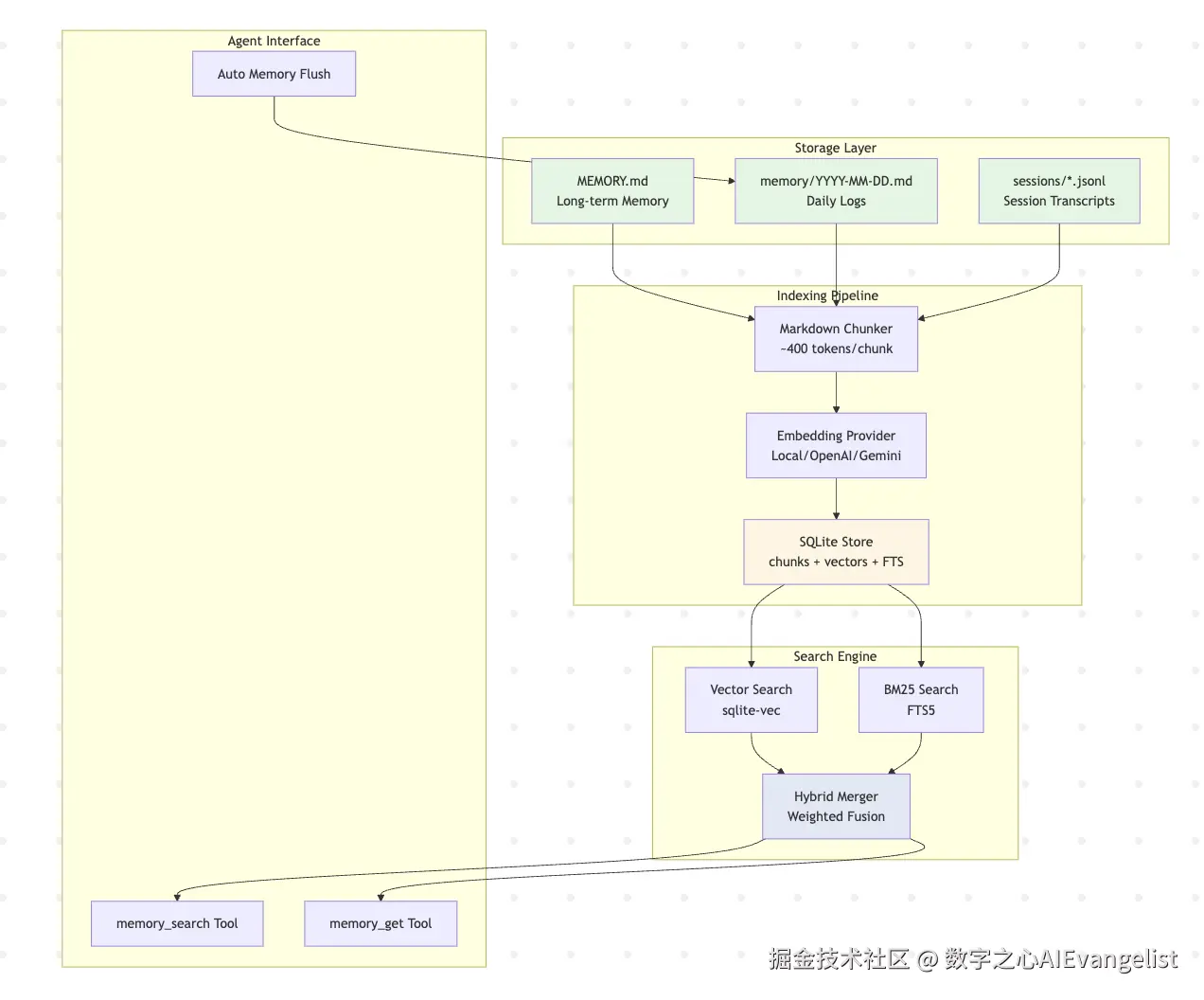 (图:OpenClaw 记忆系统完整数据流。Storage Layer → Indexing Pipeline(chunk + embed)→ SQLite(files/chunks + vec/fts)→ Search Engine(hybrid + tools)。Auto Memory Flush 从 Agent Interface 触发。来源:snowan Gitbook)
(图:OpenClaw 记忆系统完整数据流。Storage Layer → Indexing Pipeline(chunk + embed)→ SQLite(files/chunks + vec/fts)→ Search Engine(hybrid + tools)。Auto Memory Flush 从 Agent Interface 触发。来源:snowan Gitbook)

(图:清晰 workspace 树状结构。MEMORY.md、memory/ daily logs、skills/ 目录一目了然。来源:Towards AI)
三、当前会话回答流水线(End-to-End Inference Pipeline)
严格 执行以下4 步:
Step 1: 初始化检测
Gateway 接收 WebSocket 消息 → Session Resolution(根据 channel/user 决定 main/dm/group)→ 加载基础配置文件。
Step 2: 上下文分析与组装
解析意图 → 检查 session history → 决定是否触发 memory_search。
System Prompt = AGENTS.md + SOUL.md + USER.md + retrieved chunks + personality injection。
Step 3: 记忆检索与 Flush
-
• 需要历史 →
memory_search(semantic)或memory_get(targeted)。 -
• Pre-Compaction Memory Flush(核心创新):token 接近阈值(contextWindow - reserve - softThreshold)时,silent agent turn 触发模型"立即将关键信息写入 daily/MEMORY.md",回复 NO_REPLY。避免 compaction 丢失信息(其他框架常见痛点)。
Step 4: 生成与持久化
LLM 生成 + Tool Calls(Docker sandbox)→ 流式响应 → 更新 JSONL + 异步 reindex。
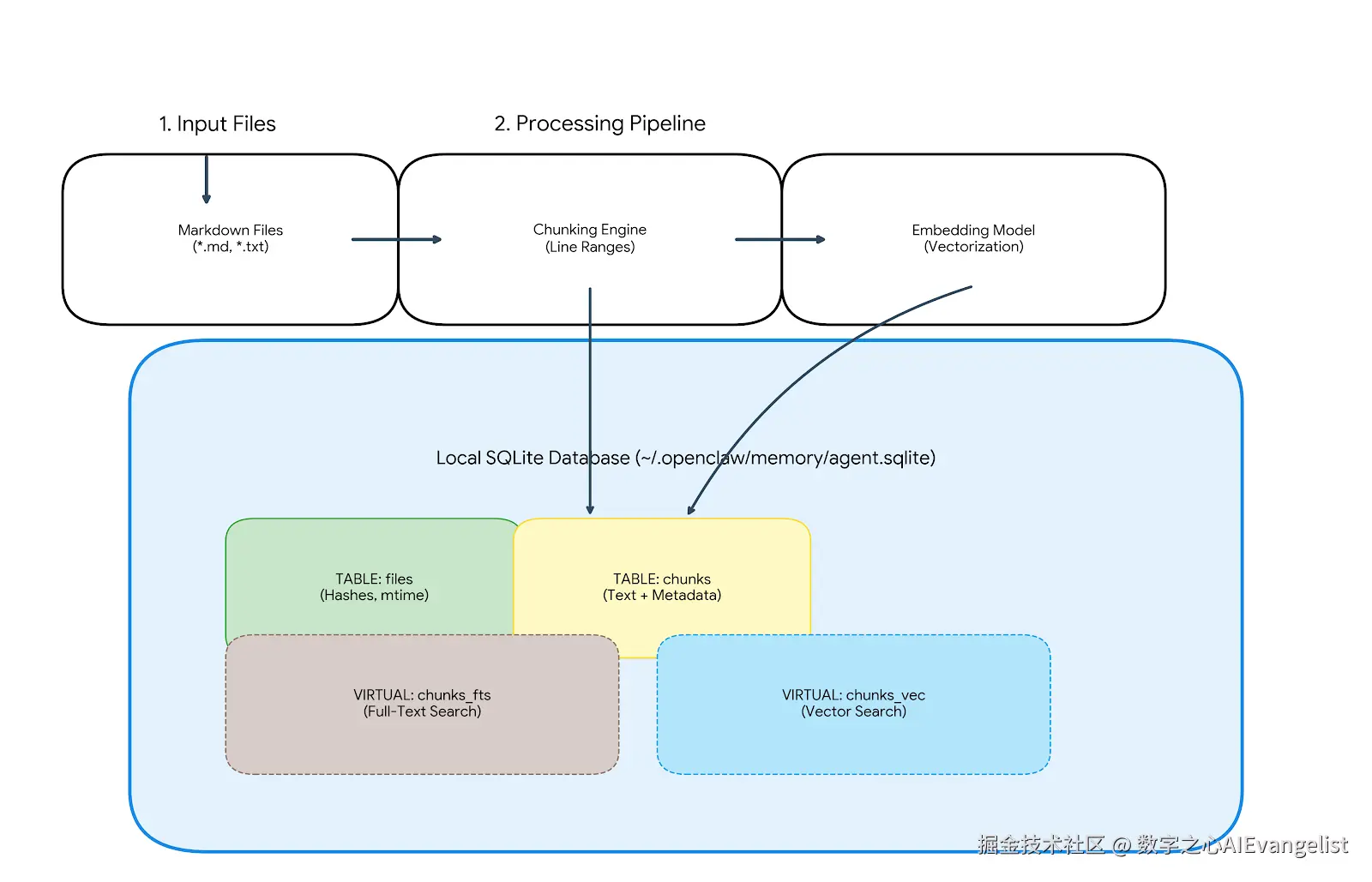
(图:SQLite 处理流水线 + schema。Input MD → Chunking → Embed → Local DB(files + chunks + vec/fts)。来源:PingCAP Blog)
四、设计哲学与技术权衡(Why This Architecture Wins)
技术原因(引用 docs & ppaolo Substack):
-
• 性能:静态全加载 = O(N) token 浪费;按需 hybrid search = O(log N) + 70% 相关性提升。
-
• 安全性:Filesystem trust boundary + per-session sandbox + MEMORY.md private-only。
-
• 可观测性与可维护性:Markdown 可 Git 版本化,人类直接 edit(X 上无数开发者吐槽"终于能看懂 Agent 在想什么")。
-
• 灵活性:插件生态(Mem0、momo-memory、sovereign-ICP、QMD)零侵入扩展。
与社区对比:
-
• @indexsy 高级提示套件:一键创建 AGENTS/SOUL/USER/MEMORY/HEARTBEAT,解决"新会话失忆"。
-
• @ivaavimusic 本地 ollama embedding:零成本 768-dim 向量,隐私优先。
-
• 痛点解决:默认 amnesia → 插件/配置即永恒记忆。
五、正确使用 MEMORY.md 与最佳实践(整合用户 OpenClaw 生成内容)
主动读取策略:
最佳实践示例 :
"让我们继续昨天的技术写作项目"
Agent:检测需历史 → 调用 memory_search / memory_get 读取 MEMORY.md + yesterday.md → 基于上下文无缝继续。
进阶:
-
启用 compaction.memoryFlush(softThresholdTokens=4000)。
-
结合 HEARTBEAT.md 实现 proactive 回顾。
-
第二大脑系统,agent 自动 distill daily → MEMORY.md。
OpenClaw 是 Agent 的"本地操作系统"
OpenClaw 不是又一个聊天机器人,而是用文件系统 + 智能分页检索构建的 Agent OS。会话隔离保证安全,记忆分层实现"无限"上下文,预压缩 flush + hybrid search 解决工程痛点。结合社区插件,它已从"有趣玩具"进化成可生产力落地的个人/团队 Jarvis。
立即在 workspace 编辑 SOUL.md,让 OpenClaw 真正"记住"你------这才是 2026 年 AI 的正确打开方式。实践后,欢迎分享你的 MEMORY.md 结构优化!
如果这篇文章对你有价值:
-
• 点个赞,给我一些支持和鼓励,谢谢!
-
• 关注我,持续更新 AI × 工业系统深度实践
-
• 转发给正在研究 AI 编程的朋友
我会持续输出真正有实战价值的内容。
如果你:
-
想把 AI 编程真正落地到团队
-
想构建自己的 Agent 工作流
-
想构建自己的记忆Agent 系统的话
可以私信我交流。
技术的意义,不是炫技。
是让复杂系统变得更简单。
作者:fishyue。文章内容或图片如果存有侵权,请留言联系我,我会第一时间进行处理。
🔗 Connect With Me | 联系我
微信公众号:数字之心AI-Evangelist