文章目录
- Return回报
- [State-value function状态价值函数](#State-value function状态价值函数)
- [Bellman Equation贝尔曼方程](#Bellman Equation贝尔曼方程)
- [Action-value function动作价值函数](#Action-value function动作价值函数)
- BOE最优贝尔曼公式
Return回报
Return的意义
- Return是沿着某一路径的累积折扣奖励
- Return的作用:可用于评估当前策略的价值。





Return的计算公式
- 注意:全是随机变量,意味着可以使用期望消去
- R t R_t Rt与 R t + 1 R_{t+1} Rt+1都可以表示t时刻采取行动获得的即刻奖励,习惯使用后者。


State-value function状态价值函数
- 状态价值函数:给定当前状态,其平均回报 是什么?(不知道当前动作和未来的状态和动作 )


Bellman Equation贝尔曼方程
-
使用期望的加法性质拆分G_t

-
使用全概率公式 分别计算两项
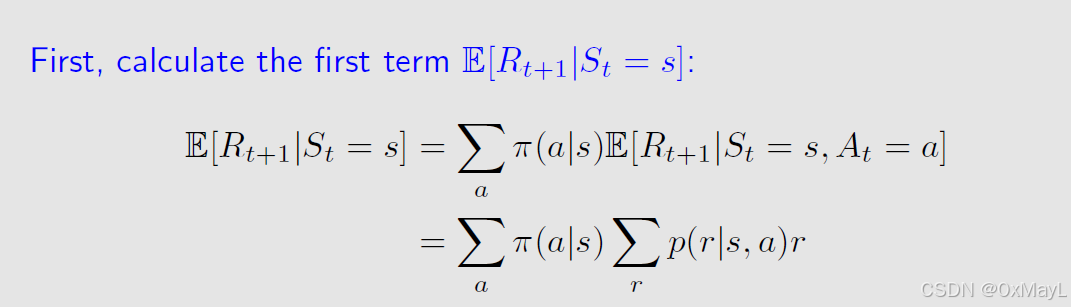

-
最终形式:

贝尔曼方程的理解
- 这是一种自举(bootstrapping)的方法 ,自己推导自己
- 对于所有的状态都适用,这一点很重要。
- 简化:如果所有策略都是确定性的,那么所有的求和符合都可以消去,只有一条轨迹。
贝尔曼方程的求解
- 特别的性质:贝尔曼方程对于所有状态都适用 ,如果我们知道策略,对于所有者状态都列举方程,可以通过求解线性方程组的形式求解贝尔曼方程。
贝尔曼方程的简化方式
- 当前状态的期望奖励和未来状态的期望奖励的总和。
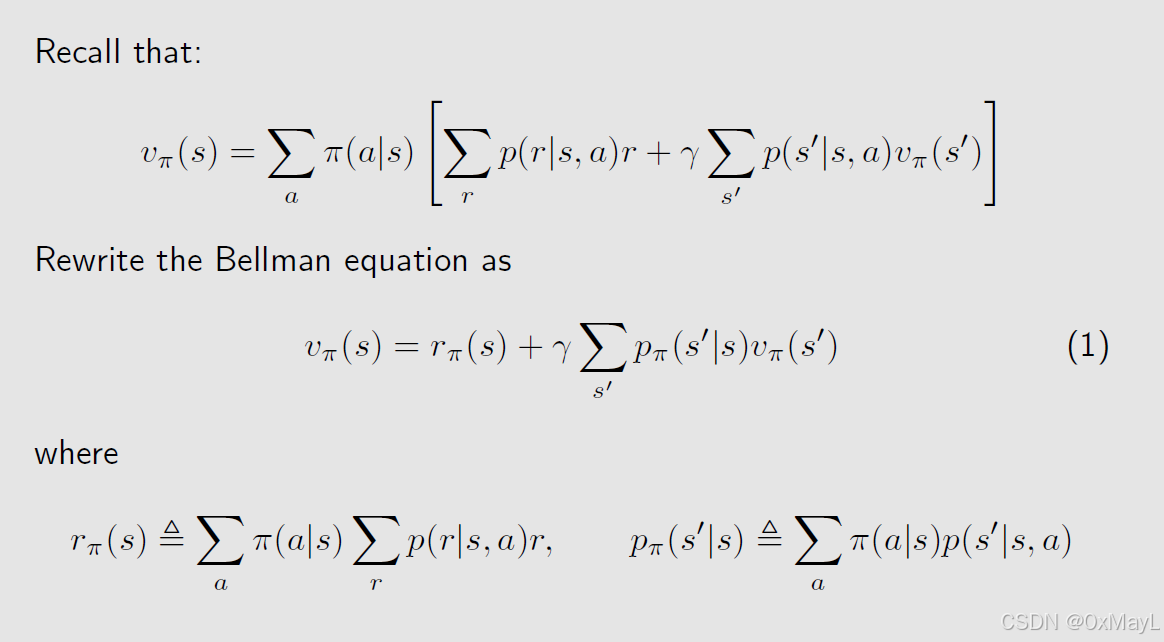
- 当前状态的期望奖励和状态转移概率可以提前计算出来
- r π ( s ) r_{\pi}(s) rπ(s)代表状态s下的期望即刻奖励,注意没有确定动作。
- P π P_{\pi} Pπ代表当前状态转移矩阵,维度为nxn。

数值例子
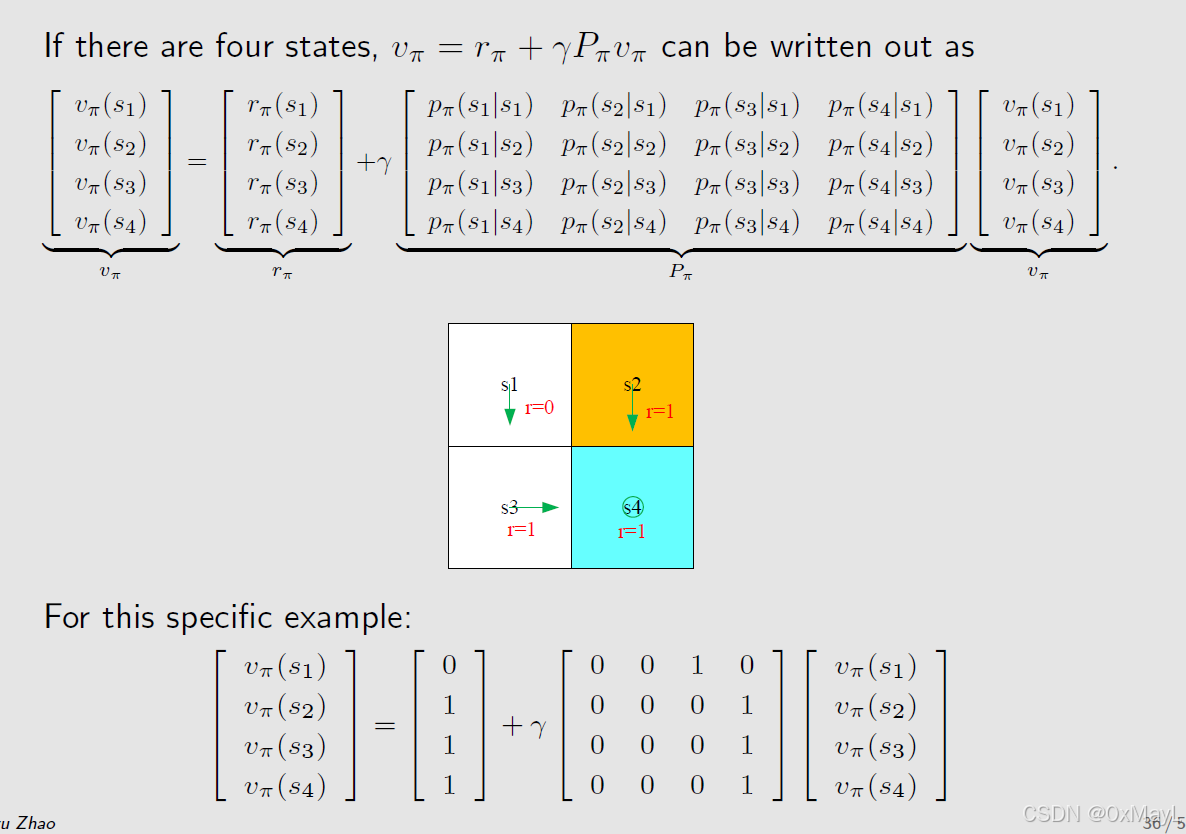
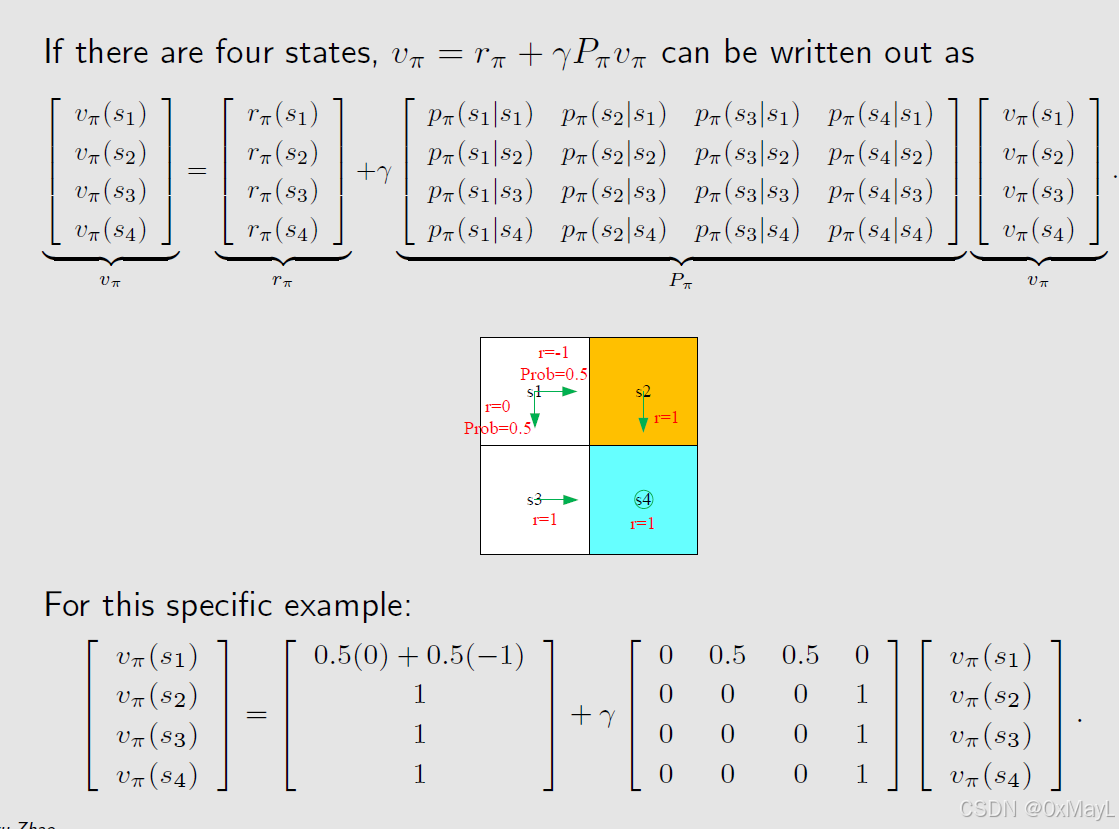
- 通常求解线性方程组或者迭代方式可以求解

策略评估
- 贝尔曼方程可以用于策略评估
- 对于好策略,状态价值函数的值普遍较大,


Action-value function动作价值函数
- 核心思想与状态价值函数一致:都是未来期望的累积折扣奖励,在此基础上给定了某个状态和采取的动作 。

贝尔曼方程,状态价值函数和动作价值函数的关系
- 贝尔曼方程的右半部分等价于动作价值函数 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a)


BOE最优贝尔曼公式
最优策略的定义
- 这个策略得到了每一个状态价值函数 都比其他策略要高

最优贝尔曼公式的定义
-
就是要求出最优的策略,就是 max π \max_{\pi} maxπ

-
向量形式:

最优贝尔曼公式的求解

最优策略
- 简单来说,最优策略就是选择使Q-value最大时的动作。
- 原因很简单,贝尔曼方程可以简化为Q-value的加权和,我们只需要让Q-value最大的权重为1就能实现最优策略( π ( a ∣ s ) = 1 when Q ( s , a ) is maximum \pi(a|s)=1 \text{ when }Q(s,a) \text{ is maximum} π(a∣s)=1 when Q(s,a) is maximum) 。


求解最优贝尔曼公式
- 简单来说满足求解以下公式的不动点
- 通过迭代的形式求解不动点。
算法原理
- 前提:状态转移函数,奖励函数已知。
- 初始化Q-value为0和策略为随机
- 首先根据初始策略计算Q-value,
- 然后根据Q-value更新策略和V-value

