01. 什么是 Nginx?它为解决什么而生?
Nginx(发音为 "engine X")是一个开源的、高性能的 HTTP 和反向代理服务器,同时也是一个 IMAP/POP3 邮件代理服务器。它由俄罗斯程序员 Igor Sysoev 于 2004 年发布。
它诞生的历史使命:解决 C10K 问题。 在千禧年初期,传统的 Web 服务器(如早期的 Apache)使用的是"同步阻塞"模型,也就是来一个客户端请求,服务器就分配一个进程或线程去处理。当同时在线的连接数达到 10,000(C10K)时,服务器的内存和 CPU 就会因为海量的进程切换而瞬间崩溃。
Nginx 就是为了打破这个性能瓶颈而生的。凭借极其优秀的底层架构,Nginx 单机轻松支撑 数万甚至十万级 的并发连接,同时内存消耗极低。
02. Nginx 的核心灵魂:它为什么这么快?
面试中常问:"Nginx 为什么并发能力那么强?"核心就在于它的架构设计:Master-Worker 进程模型 + 异步非阻塞的事件驱动机制 (epoll)。
1. Master-Worker 多进程模型
Nginx 启动后,会在后台运行两种进程:
-
Master 进程(大管家): 通常只有一个。它不直接处理网络请求,而是负责读取和解析配置文件、管理 Worker 进程(如果某个 Worker 死了,Master 会迅速拉起一个新的)。
-
Worker 进程(打工人): 通常有多个(数量一般配置为与 CPU 核心数相同)。它们是真正负责处理客户端请求的进程。各个 Worker 之间相互独立,争抢执行。
2. 异步非阻塞 & Event-Driven (事件驱动)
为了方便理解,我们可以打个比方:
-
传统模型(同步阻塞): 餐厅里一个服务员(线程)专门服务一桌客人。客人看菜单选菜时,服务员就只能傻站着等(阻塞),什么也干不了。客人越多,需要的服务员就越多,餐厅(服务器)很快就发不出工资(内存耗尽)了。
-
Nginx 模型(异步非阻塞 epoll): 餐厅里只有一个超级服务员(Worker 进程)。他把菜单递给客人 1 后,立刻转身去给客人 2 点单。哪桌客人决定好要点菜了,就会按铃(触发事件),超级服务员听到铃声立刻过去记录。这样一个服务员就能同时高效照顾几百桌客人!
03. Nginx 的三大核心"武功"
虽然 Nginx 模块极其丰富,但它在生产环境中最常扮演三个角色:
武功一:极速的静态 Web 服务器
虽然 Nginx 处理 PHP、Java 等动态请求的能力一般(通常交给后端的 Tomcat/PHP-FPM 去做),但它处理 HTML、CSS、JS、图片、视频等静态资源的速度堪称无敌。很多动静分离的架构中,Nginx 会把静态文件直接缓存在本地,极速响应给用户。
武功二:反向代理 (Reverse Proxy)
-
正向代理(代理的是客户端): 比如你用的 VPN,你通过代理服务器去访问外网。服务器不知道真实的你是谁。
-
反向代理(代理的是服务端): 客户端去访问 Nginx(客户端以为 Nginx 就是真正的网站),Nginx 悄悄把请求转发给内网深处的真实业务服务器,拿到结果后再返回给客户端。作用:保护了内网安全,隐藏了真实服务器 IP。
武功三:七层负载均衡 (Load Balancing)
既然 Nginx 可以做反向代理,那它自然可以把流量代理给一群后端服务器。Nginx 工作在 OSI 的第七层(应用层),这意味着它可以非常"聪明"地根据 HTTP 域名、URL 路径、甚至客户端的浏览器类型,将流量精准调度到不同的后端集群上(这就是比 LVS 四层调度更细腻的地方)。
04. 什么是 Tomcat?它与 Nginx 有何不同?
如果说 Nginx 是餐厅里极其高效的"前台接待"和"传菜员",那么 Tomcat 就是后厨里真正负责"炒菜"的大厨。
Tomcat 是由 Apache 软件基金会开发的核心开源项目。它不仅仅是一个 Web 服务器,它更核心的身份是 Java Servlet 和 JSP 容器。
-
Nginx 的局限: Nginx 虽然并发极高,但它是个"偏科生"。它只懂 HTTP 协议,只能处理静态文件(HTML、CSS、图片等),它看不懂也无法执行任何 Java、PHP 等后端的动态代码。
-
Tomcat 的专长: Tomcat 就是为了运行 Java 代码而生的。当用户在网页上发起登录请求、查询数据库、或者提交表单时,这些需要复杂逻辑计算的"动态请求",全靠 Tomcat 内部的 Java 引擎(Catalina)来解析和执行。
05. 业界经典架构:"Nginx + Tomcat" 动静分离
面试官经常会问:"既然 Tomcat 也能当 Web 服务器,为什么前面还要挡一层 Nginx?" 答案就是四个字:动静分离。
把它们结合起来,就是一套完美的"扬长避短"架构:
-
抗并发与安全防护: Nginx 挡在最外层(暴露 80/443 端口),直接面对海量的互联网请求,抵御恶意的并发攻击。Tomcat 藏在内网(默认 8080 端口),非常安全。
-
静态资源 Nginx 秒发: 当用户请求网页界面的图片、JS、CSS 样式时,Nginx 直接从本地磁盘读取并瞬间返回,根本不打扰 Tomcat,极大地减轻了 Tomcat 的压力。
-
动态业务 Tomcat 专精: 当用户点击"购买"或"登录",触发了具体的业务 API(例如
.jsp或/api/*路径),Nginx 会立刻化身为反向代理,把这部分动态请求精准打包,扔给后端的 Tomcat 集群去执行 Java 代码。 -
横向扩展: 后端可以挂载几十台 Tomcat 组成集群,Nginx 负责根据权重和健康状态,将流量均匀地调度(负载均衡)给这些 Tomcat。
06. 庖丁解牛:Tomcat 的两大核心引擎
为了让博客显得更有深度,我们需要简单拆解一下 Tomcat 的内部结构。Tomcat 之所以能高效处理请求,全靠它的两大核心组件相互配合:
-
Connector (连接器):负责"对外揽客"。 它是 Tomcat 的"耳朵和嘴巴"。负责监听网络端口(最常见的是监听 HTTP 的 8080 端口,以及与 Nginx 内部通信的 AJP 8009 端口),接收外部发来的请求,把网络字节流翻译成 Tomcat 能懂的 Request 对象,最后把大厨做好的 Response 对象转回给客户端。
-
Container (容器,代号 Catalina):负责"内部炒菜"。 它是 Tomcat 的"大脑"。当 Connector 揽到活儿之后,会把请求交给 Container。Container 里面装载了我们写好的各种业务代码(Servlet)。它负责调用你的 Java 逻辑,去数据库查数据,最后生成动态的页面或 JSON 数据交还给 Connector。
07. 经典对比:Nginx vs Apache vs Tomcat 的三足鼎立
在梳理 Web 架构时,很多新手容易把这三者混为一谈,觉得它们"都能打开网页"。但实际上,它们在企业架构中扮演着截然不同的角色。
简单来说:Nginx 和 Apache 是"Web 服务器"(更擅长处理 HTTP 协议和静态文件),而 Tomcat 是"应用服务器"(更擅长处理复杂的 Java 动态业务逻辑)。
为了让你一目了然,我们用一张多维度的表格来拆解这"三剑客":
| 对比维度 | Nginx (极速前台) | Apache (老牌管家) | Tomcat (后厨大厨) |
|---|---|---|---|
| 核心定位 | 高性能 HTTP 及反向代理服务器 | 传统、功能丰富的 Web 服务器 | Java Servlet / JSP 应用服务器 (容器) |
| 底层架构 | 异步非阻塞 (epoll),事件驱动 | 同步阻塞 (select/poll),多进程/多线程 | 基于 JVM 的线程池架构 (支持 NIO 等) |
| 并发与资源 | 极强。 几兆内存即可支撑数万并发,是应对"高并发"的王者。 | 一般。 进程/线程切换开销大,海量并发时容易吃光内存。 | 受限于 JVM。 并发过高时会导致频繁 GC (垃圾回收),需针对性调优。 |
| 静态处理能力 (HTML, 图片, CSS) | 宇宙天花板级别。 速度极快,自带高效缓存。 | 很强。 极其稳定可靠。 | 较弱。 虽然也能发静态文件,但属于"大材小用",严重浪费 JVM 资源。 |
| 动态处理能力 (执行业务代码) | 无法直接处理。 它看不懂代码,只能把请求打包转发给后端的 Tomcat 或 PHP-FPM。 | 较强。 通过内置加载各种模块(如 mod_php)可直接解析脚本。 | 绝对领域。 专为解析 Java 代码而生,拥有强大的数据库连接池和事务处理能力。 |
| 企业最佳实践 | 挡在架构最前端:做负载均衡、反向代理、静态资源缓存。 | 承载遗留的老旧系统,或需要其极度复杂的重型模块支持的业务。 | 藏在内网深处:专心致志地执行被 Nginx 转发过来的复杂 Java 业务代码。 |
08.实验讲解
一、Nginx源码编译安装
很多新手会问:"既然 dnf install nginx 一行命令就能搞定,为什么还要费时费力去源码编译?" 在企业生产环境中,源码编译是必须掌握的核心技能。因为通过 dnf 安装的 Nginx 版本往往比较旧,更重要的是,源码编译允许我们按需定制 Nginx 的功能模块(比如只开启 SSL 和状态监控,去掉不需要的模块以极致压缩体积),这是包管理器做不到的。
1. 实验架构与准备
-
测试机 (Client):
172.25.254.100(母机/测试机) -
Nginx 服务器: 假设 IP 规划为
172.25.254.10(RHEL 9.6)
首先,在 **Nginx 服务器(172.25.254.10)**上完成基础环境配置:关闭防火墙和 SELinux,以防它们拦截 80 端口。
bash
# 临时并永久关闭 SELinux
setenforce 0
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 关闭并禁用 Firewalld
systemctl stop firewalld
systemctl disable firewalld2. 安装编译依赖包 (C 语言环境)
Nginx 是用纯 C 语言编写的,所以在编译之前,我们必须给系统装上"翻译官"(编译器)和一些支撑模块(正则解析、压缩处理、加密等)。
在 Nginx 服务器上执行:
bash
# RHEL 9 推荐使用 dnf
dnf install -y gcc make pcre-devel zlib-devel openssl-devel-
gcc & make: C 语言核心编译器和构建工具。
-
pcre-devel: 使 Nginx 支持正则表达式解析(配置伪静态、重写 URL 时必用)。
-
zlib-devel: 提供数据压缩能力(开启 gzip 压缩加速网页必用)。
-
openssl-devel: 提供加密算法支持(配置 HTTPS 证书必用)。
3. 下载并解压 Nginx 源码
我们去 Nginx 官网获取稳定的 Mainline 或 Stable 版本(这里以非常经典的 1.24.0 稳定版为例,如果你想用更新的也可以替换版本号)。
bash
# 切换到通常存放源码包的目录
cd /usr/local/src
# 下载 Nginx 源码包
wget http://nginx.org/download/nginx-1.24.0.tar.gz
# 解压并进入源码目录
tar -zxvf nginx-1.24.0.tar.gz
cd nginx-1.24.04. 创建运行用户 (安全基线)
为了极致的安全,Nginx 的工作进程(Worker)绝对不能以 root 权限运行。我们需要在系统里创建一个专门的"虚拟人"来运行它,并且不给他登录系统的权限。
bash
# 创建一个名为 nginx 的系统用户,不创建家目录,且禁止登录 Shell
useradd -s /sbin/nologin -M nginx5. 配置与编译 (Configure & Make)
这是源码编译中最核心的一步!通过 ./configure 脚本,我们可以告诉编译器要把 Nginx 安装到哪里,以及要开启哪些超能力模块。
第一步:执行 configure 配置参数
bash
./configure \
--prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--with-http_ssl_module \
--with-http_v2_module \
--with-http_realip_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-pcre
(参数解释:将 Nginx 安装到 /usr/local/nginx 目录;指定运行用户为刚才创建的 nginx;开启 SSL 支持、HTTP/2 支持、真实 IP 获取模块、状态监控模块以及 GZIP 静态压缩模块。)配置完成后,屏幕最后会打印出 Nginx 的路径配置汇总,如果没有报
error,就可以进行下一步了。
第二步:编译并安装
bash
# 开始编译,并且安装到指定目录 (-j2 表示使用 2 个 CPU 核心加速编译,根据你虚拟机的配置调整)
make -j2 && make install6. 善后工作与启动服务
编译安装完之后,Nginx 所有的文件都安静地躺在 /usr/local/nginx 目录下。
1). 配置环境变量 (为了敲命令方便)
如果不配置,每次启动都要敲超长的绝对路径 /usr/local/nginx/sbin/nginx。
bash
# 将 Nginx 的执行路径追加到系统 PATH 中
echo 'export PATH=$PATH:/usr/local/nginx/sbin' >> /etc/profile
source /etc/profile2). 检查安装版本与模块
现在你可以直接敲 nginx 命令了。用大写的 -V 查看我们刚才编译进去的模块:

3). 启动 Nginx
bash
# 直接敲命令即可启动
nginx
# 检查 80 端口是否已经被监听
ss -antlupe | grep 80
7. 客户端验证
回到你的母机/测试机(172.25.254.100) ,打开浏览器,或者直接在终端使用 curl 命令访问刚才的 Nginx 服务器:
bash
curl http://172.25.254.10如果你看到终端输出了一大串包含
Welcome to nginx! 的 HTML 代码,或者在浏览器里看到了经典的 "Welcome to nginx!" 欢迎页面,恭喜你,你的企业级 Nginx 已经由你亲手从 C 语言代码编译成高性能的二进制服务了!
二、Nginx启动脚本编写
在上一节骤中,我们通过手动敲击 nginx 命令启动了服务。但在真正的企业生产环境中,没有任何运维工程师会手动去启动核心服务。如果服务器意外重启,手动拉起的 Nginx 是不会自动启动的,这会导致严重的业务中断。
在 RHEL 9.6 环境下,标准做法是将源码编译的 Nginx 托管给系统的"大管家"------Systemd 。这样我们就能使用熟悉的 systemctl start/stop/reload nginx 以及 systemctl enable nginx(开机自启)来优雅地管理它了。
1. 扫清障碍:停掉手动启动的进程
在交接给 Systemd 管理之前,我们必须先把上一个实验中手动启动的 Nginx 关掉,否则 Systemd 会因为 80 端口被占用而启动失败。
在 Nginx 服务器上执行:
bash
# 优雅地停止当前正在运行的 Nginx
/usr/local/nginx/sbin/nginx -s stop
# 检查一下是否真的停掉了 (确保没有任何 nginx 进程存在)
ps -ef | grep nginx2. 编写 Systemd 启动脚本 (Unit 文件)
在 RHEL 9 系统中,用户自定义的系统级服务脚本通常存放在 /lib/systemd/system/ 目录下。
创建并编辑 Nginx 的服务脚本:
bash
vim /lib/systemd/system/nginx.service将以下标准化启动脚本粘贴进去:
(注意:这里的所有路径 /usr/local/nginx/... 都必须与你上一步 ./configure 编译时指定的 --prefix 路径完全一致)
bash
[Unit]
Description=The NGINX HTTP and reverse proxy server
After=network.target remote-fs.target nss-lookup.target
[Service]
# Nginx 是后台运行的多进程服务,所以类型必须是 forking
Type=forking
# 指定 PID 文件的位置 (Nginx 默认会把主进程号写到这里)
PIDFile=/usr/local/nginx/logs/nginx.pid
# 启动前,先检查配置文件语法是否正确 (非常关键的防呆设计!)
ExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf
# 启动命令
ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
# 平滑重载命令 (修改配置后,不中断当前连接重新加载)
ExecReload=/usr/local/nginx/sbin/nginx -s reload
# 停止命令
ExecStop=/usr/local/nginx/sbin/nginx -s stop
# 分配独立的临时空间,提升安全性
PrivateTmp=true
[Install]
# 表示在多用户命令行模式下开机自启
WantedBy=multi-user.target3. 重新加载并接管服务
你刚刚给 Systemd 增加了一份新的"工作说明书",必须要让它重新读取并认领这份工作。
1). 重载 Systemd 守护进程:
bash
systemctl daemon-reload2). 启动 Nginx 并设置开机自启:
bash
systemctl enable --now nginx
3). 查看服务的状态:
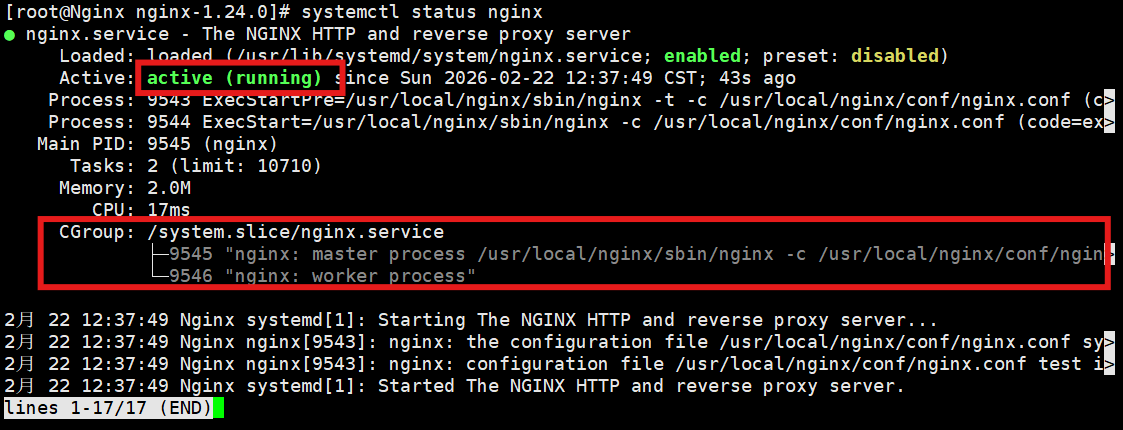
bash
systemctl status nginx预期结果: 你会看到绿色的 Active: active (running),并且下面会清晰地列出 Nginx 的 Master 主进程和 Worker 工作进程的树状结构!
附言:
为什么脚本一定要写 ExecStartPre=/usr/local/nginx/sbin/nginx -t? 因为在生产环境中,运维人员经常会修改 Nginx 配置文件。如果在配置写错(比如漏了一个分号)的情况下贸然执行 systemctl restart nginx,Nginx 会瞬间死亡且无法启动,直接导致线上事故。 加了这一行后,Systemd 在启动/重启前会先执行 -t 语法测试。如果测试不通过,Systemd 会拒绝重启,从而保住了正在运行的旧 Nginx 进程。
三、Nginx 的版本管理与平滑升级
在企业中,网站是绝对不允许因为"升级服务器软件"而断网一分钟的。Nginx 极其优秀的架构设计,允许我们在不中断任何一个正在访问的用户的连接的情况下,偷偷把底层的核心程序换成新版本(或者增加新的功能模块)。
1. 核心理论:平滑升级是怎么做到的?
Nginx 能做到不停机升级,全靠它的 Master-Worker 多进程架构 和 信号机制。
整个魔术的过程就像"新老交替":
-
备用接管: 我们向旧的 Master 进程发送一个特殊的信号(
USR2),它会立刻拉起一个全新的 Master 进程(带着新的 Worker 们)。此时,新老 Nginx 同时运行,共同接收用户的请求。 -
优雅退休: 我们再向旧的 Master 发送另一个信号(
WINCH),命令它把手下的旧 Worker 们"优雅地辞退"。旧 Worker 会把手里正在处理的请求处理完再下班,而新的请求全部交由新 Worker 处理。 -
彻底卸任: 确认新版本运行完美后,最后发送信号(
QUIT)让旧 Master 彻底退出。升级完成!如果在第 2 步发现新版本有 Bug,我们随时可以唤醒旧 Worker,实现秒级回滚。
2. 实战演练:从 1.24.0 平滑升级到 1.26.1
假设我们目前运行的是刚编译的 1.24.0,现在官方出了 1.26.1,我们需要进行热升级。
第一步:获取新版本源码
保持 Nginx 处于运行状态,在服务器(172.25.254.10)上下载新版源码:
bash
cd /usr/local/src
wget http://nginx.org/download/nginx-1.26.1.tar.gz
tar -zxvf nginx-1.26.1.tar.gz
cd nginx-1.26.1第二步:携带原有参数重新编译
为了保证升级后以前的配置依然有效,必须使用和旧版本完全一样的 ./configure 参数。(如果你是为了新增模块,就在原有的参数后面加上新模块参数)。
你可以通过 nginx -V (大写 V) 查看之前的编译参数,然后原样复制过来:
bash
./configure \
--prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--with-http_ssl_module \
--with-http_v2_module \
--with-http_realip_module \
--with-http_stub_status_module \
--with-http_gzip_static_module \
--with-pcre
# 开始编译
make -j2【高危警告】 :此时千万千万不能敲 make install !一旦敲了,它会强行覆盖线上正在运行的配置文件和目录,直接导致惨烈的线上事故。我们只要 make 编译出新的二进制核心文件即可。
第三步:备份旧版本,替换新内核
编译完成后,新版本的 Nginx 核心程序躲在当前目录的 objs/ 文件夹下。
bash
# 1. 把正在运行的旧版 nginx 二进制文件改名备份 (极其重要,为了回滚)
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old
# 2. 把刚刚编译好的新版 nginx 拷贝过去
cp objs/nginx /usr/local/nginx/sbin/nginx
# 3. 检查一下新版本的语法是否正常
/usr/local/nginx/sbin/nginx -t(注意:此时虽然文件替换了,但内存里跑的还是旧版本的进程。)

第四步:发送信号,执行平滑交接
现在,我们将通过向进程发送信号来指挥新老交替。
1. 查出旧 Master 的进程号 (PID):
bash
cat /usr/local/nginx/logs/nginx.pid
# 假设输出的 PID 是 12345,根据个人情况调整2. 唤醒新版本 (发送 USR2 信号):
bash
kill -USR2 12345此时立刻敲 ps -ef | grep nginx 查看,你会发现,系统里同时存在两个 Master 进程和两批 Worker 进程。
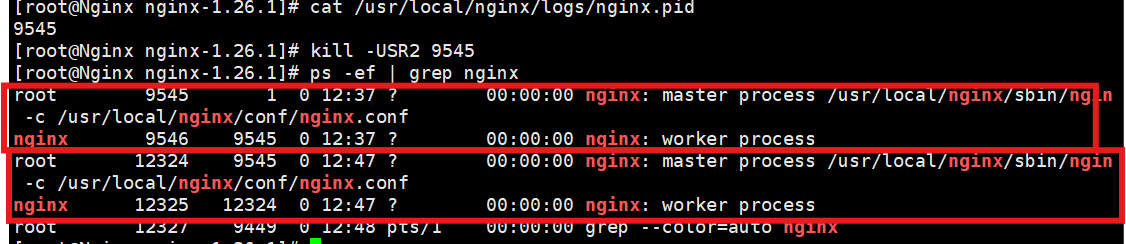
3. 优雅关闭旧 Worker (发送 WINCH 信号):
bash
kill -WINCH 12345再次敲 ps -ef | grep nginx,你会发现旧的 Worker 都不见了,只剩下孤零零的旧 Master,以及生龙活虎的新 Master 和新 Worker。此时,所有的流量都已经无缝切换到 1.26.1 版本了!

4. 彻底告别旧时代 (发送 QUIT 信号):
在企业环境中,经过一段时间的运行,确认新版本没有任何 Bug 后,我们就可以彻底杀掉旧 Master。
bash
kill -QUIT 12345此时使用nginx -v(小写)验证,可以看到nginx版本已经升级到1.26.1

第五步:附加内容-出现bug时的回滚:
如果在第 3 步(旧 Master 还在,但旧 Worker 停了)时发现新版本报错,我们需要立刻退回 1.24.0:
我在演示这一步时重新安装了1.24.0,所以pid有所不同,重点关注此时执行完WINCH后版本为1.26.1
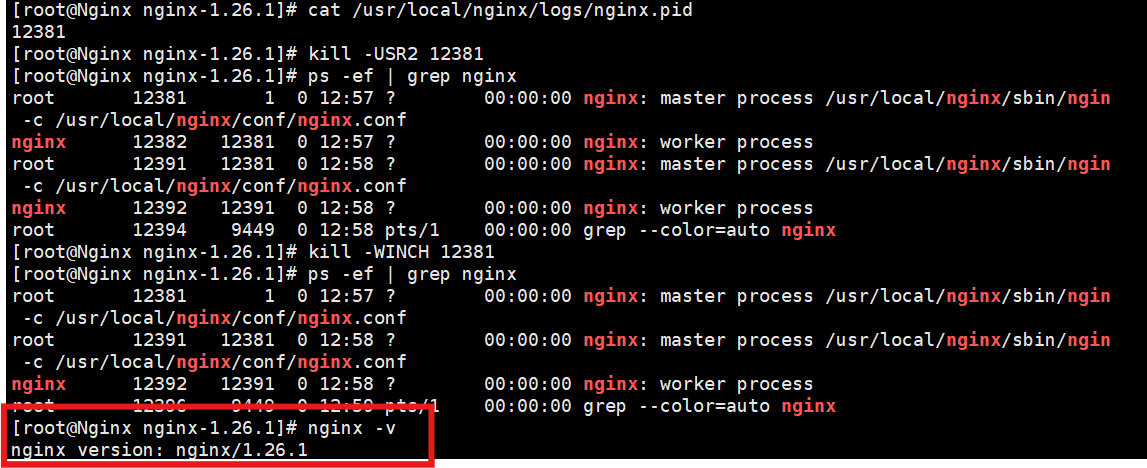
1).紧急唤醒旧版本 (1.24.0) 的 Worker 进程:
我们给还在休眠的旧 Master 发送 HUP(挂起/重启配置)信号,它会立刻重新拉起属于它的旧 Worker 开始接管流量。
bash
kill -HUP PID(OLD)此时再 ps -ef | grep nginx,你会看到新老版本的 Worker 都在处理流量,兵力瞬间翻倍。

2). 优雅干掉惹祸的新版本 (1.26.1) Master 进程
我们要让新版本的 Master 带着它的手下"体面地离开":
bash
# 新版本启动后,占用了默认的 nginx.pid 文件
kill -QUIT PID(NEW)
(新 Worker 会处理完手里最后一个请求,然后集体自杀,新 Master 随之消亡。)3). 抹除新版本的痕迹,还原旧版二进制文件
将我们最初备份的 nginx.old 恢复原位,防止下次重启时误拉起新版本。
bash
# 强制覆盖回去
mv -f /usr/local/nginx/sbin/nginx.old /usr/local/nginx/sbin/nginx4). 验证版本
bash
nginx -v预期输出:nginx version: nginx/1.24.0

整个回滚过程在毫秒间完成,外网的用户甚至感觉不到任何卡顿,只知道刚才那个报错的页面刷新一下又好了
四、Nginx性能调优
Nginx 默认的配置文件 (nginx.conf) 是极其保守的,它为了兼容最差的硬件环境,并没有把性能拉满。在真实的生产环境中,如果不进行参数优化,当并发量突然飙升时,Nginx 可能会出现响应缓慢甚至拒绝服务的情况。
这部分的博客,我们可以按照**"从底层到应用层"**的逻辑,把 Nginx 优化的核心参数彻底打通。
1. 全局配置层:榨干 CPU 与突破连接限制
这是决定 Nginx 并发上限的最核心区域。打开配置文件:
bash
vim /usr/local/nginx/conf/nginx.conf在文件的最外层(非 http 块内),我们需要优化以下参数:
1). 绑定 CPU 核心 (Worker 进程优化)
bash
# 将 Worker 进程数设置为等于服务器的 CPU 核心数 (设为 auto 会自动检测)
worker_processes auto;
# 【高阶技巧:CPU 亲和性】
# 强制将不同的 Worker 进程绑定到不同的 CPU 核心上,极大地减少 CPU 上下文切换的损耗!
worker_cpu_affinity auto;2). 突破系统文件描述符限制
在 Linux 中,每一个网络连接都是一个"文件"。系统默认限制一个进程只能打开 1024 个文件,这对于 Nginx 来说远远不够。
bash
# 将 Nginx 进程能打开的最大文件数直接拉到 65535 (甚至 100000)
worker_rlimit_nofile 65535;2. Event 事件层:极限网络 I/O 模型
进入 events 块,这里配置的是 Nginx 处理网络连接的工作模式。
bash
events {
# 明确指定使用 Linux 性能最强的 epoll 异步非阻塞模型
use epoll;
# 每个 Worker 进程允许的最大并发连接数
# 理论最大总并发 = worker_processes * worker_connections
worker_connections 65535;
# 让 Nginx 尽可能多地接收请求,而不是一次只接收一个
multi_accept on;
}3. HTTP 传输层:零拷贝、长连接与压缩
进入 http 块,这里的优化能够显著降低网络延迟,提升用户的网页加载速度。
1). 高效文件传输 (零拷贝技术)
bash
# 开启高效传输模式 (Zero-Copy)
# 文件数据直接从内核空间的磁盘读取并发送到网卡,不经过用户空间,极大地节省 CPU 资源
sendfile on;
# 必须和 sendfile 配合使用。让数据包凑满了一个 MSS 再发,减少网络小包的数量,提升吞吐量
tcp_nopush on;
# 禁用 Nagle 算法,让数据有的话立刻发出去,降低网页的延迟感
tcp_nodelay on;2). HTTP Keep-Alive 长连接
bash
# 保持客户端连接的超时时间 (秒)。
# 不要设得太大 (通常 60 左右),否则恶意连接会长期占用服务器资源;设得太小会导致频繁重连消耗 CPU。
keepalive_timeout 65;3). GZIP 网页压缩
bash
# 开启 gzip 压缩,能大幅压缩 HTML/CSS/JS 文件体积,极大提升前端加载速度
gzip on;
# 只有超过 1KB 的文件才压缩 (太小的文件压缩后反而变大)
gzip_min_length 1k;
# 压缩级别 (1-9)。通常选 4 或 5,再高的话非常消耗 CPU,但体积减小不明显
gzip_comp_level 5;
# 指定需要压缩的文件类型
gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
# 增加 Vary: Accept-Encoding 响应头
# 告诉前端的 CDN 节点或代理服务器:"我这个文件是按 gzip 压缩的",防止 CDN 把压缩版发给不支持解压的老古董浏览器
gzip_vary on;
# 禁用老旧浏览器的压缩支持 (比如 IE6,它对 gzip 的解压有 Bug)
gzip_disable "MSIE [1-6]\.";4). 安全优化:隐藏版本号
bash
# 关闭 Nginx 响应头中的版本号 (例如去掉 Server: nginx/1.24.0)
# 防止黑客利用特定版本的已知漏洞发起精准攻击
server_tokens off;修改完配置文件后,别忘了检查一下语法:
bash
/usr/local/nginx/sbin/nginx -t
# 如果显示 syntax is ok,就可以重载了:
systemctl reload nginx
五、alias和root的区别
在正式开始进阶实验前,我们先讲清楚alias和root在配置中的区别。
简单来说,root 和 alias 都是用来定义**"当用户访问某个 URL 时,Nginx 应该去服务器的哪个目录找文件"**。
但它们拼接真实文件路径的核心逻辑截然不同:
-
root是"追加"(Append): 真实路径 =root目录 + 完整的 URI。 -
alias是"替换"(Replace): 真实路径 =alias目录 + (完整的 URI -location匹配的路径)。
为了把这个知识点写透,我们直接用最直观的例子来对比:
1. root 的工作逻辑:全量追加
当你使用 root 时,Nginx 会把你请求的整个 URL 路径 ,直接拼接到 root 定义的目录后面。
配置示例:
bash
location /static/ {
root /usr/local/nginx/html/;
}解析过程: 当用户在浏览器访问 http://172.25.254.10/static/image.jpg 时:
-
Nginx 匹配到了 /static/ 这个 location。
-
Nginx 开始拼接真实路径:将
root定义的 /usr/local/nginx/html/ 和用户请求的 URI /static/image.jpg 拼接在一起。 -
最终服务器查找的磁盘路径是: /usr/local/nginx/html/static/image.jpg。
(注意:服务器的磁盘上必须真实存在一个叫 static 的文件夹,否则会报 404 错误。)
2. alias 的工作逻辑:狸猫换太子
当你使用 alias 时,Nginx 会把 URL 中和 location 匹配上的那部分路径**"丢弃掉"** ,只把剩下的部分拼接到 alias 定义的目录后面。这就是所谓的"别名"。
配置示例:
bash
location /static/ {
alias /usr/local/nginx/html/;
}解析过程: 当用户同样访问 http://172.25.254.10/static/image.jpg 时:
-
Nginx 匹配到了 /static/。
-
Nginx 开始拼接真实路径:它会把 URL 里的 /static/ 替换 成
alias定义的 /usr/local/nginx/html/。 -
最终服务器查找的磁盘路径是: /usr/local/nginx/html/image.jpg。
(注意:此时磁盘上不需要有 static 文件夹,文件直接放在 html 目录下即可。)
3. 核心避坑
在实际使用中,这两个指令还有两个极其重要的区别,建议一定要写进你的实战笔记里:
1). 作用域不同:
-
root可以写在 http、server、location 甚至 if 块中。它是全局生效或者向下继承的。 -
alias只能 写在 location 块中!它是一个专门为了改变特定 URL 映射逻辑而存在的指令。
2). 结尾斜杠 / 的神坑:
-
对于
root来说,目录结尾带不带/都无所谓,Nginx 会自动处理(例如root /var/www和root /var/www/效果一样)。 -
对于
alias来说,极其严格!如果你的location结尾带了/,那么你的alias结尾也必须带/! 否则拼接路径时会少一个斜杠,导致 404 甚至更严重的安全越权漏洞。
如果请求的 URI 和磁盘上的目录层级完全一致,就用 root。 如果你想把某个特定的 URI(比如 /download/)强行映射到一个名字完全无关的磁盘目录(比如 /data/files/),就用 alias,并且永远记得加上结尾的斜杠
六、Nginx长连接优化
在默认情况下,HTTP 协议是"无状态"的。如果没有长连接(Keep-Alive),用户每请求一个网页上的图片、CSS 或 JS 文件,浏览器和 Nginx 之间都要经历一次完整的 TCP 三次握手 (建立连接)和 四次挥手 (断开连接)。 在高并发场景下,这种频繁的建连和断连会极其严重地消耗 CPU 资源,并且会在服务器上产生海量的 TIME_WAIT 状态连接,最终把端口耗尽。
在 Nginx 的企业级架构中,长连接优化其实分为两个完全不同的方向:
-
前端长连接: 客户端(浏览器) <---> Nginx
-
后端长连接(极易被忽略): Nginx <---> Upstream(如 Tomcat)
我们把这两个方向的优化一次性打通!
1. 前端长连接优化:Client <---> Nginx
这部分的配置主要写在 http 或 server 块中,目的是让用户的浏览器复用同一个 TCP 连接来拉取多个文件。
bash
vim /usr/local/nginx/conf/nginx.conf
bash
http {
# ... 其他配置 ...
# 1. 核心参数:保持连接的超时时间 (单位:秒)
# 默认是 75s。建议设为 60-65。太短起不到复用效果,太长会导致恶意连接长期占用服务器内存。
keepalive_timeout 65;
# 2. 进阶参数:一个长连接上最多允许发送多少个请求
# 默认是 100。在现代高并发 Web 业务中(尤其是单页面应用 Vue/React),一个页面动辄几十个请求,建议直接调大!
keepalive_requests 1000;
}
bash
/usr/local/nginx/sbin/nginx -t
#每次配置修改完成后,记得检查2. 后端长连接优化:Nginx <---> Tomcat (绝密大招)
这往往是很多新手乃至老兵都会踩的超级大坑!
当 Nginx 作为反向代理时,它默认使用 HTTP/1.0 去连接后端的 Tomcat。而 HTTP/1.0 默认是不支持长连接的(Connection: close) ! 这意味着,即便前端浏览器和 Nginx 保持了长连接,但 Nginx 每次向 Tomcat 转发请求时,依然会重新发起 TCP 三次握手。这就导致前端虽然爽了,但内网的 Nginx 和 Tomcat 却因为频繁建连被彻底拖垮。
要彻底打通这条"任督二脉",我们需要在 upstream 和 location 块中同时发力:
第一步:在 upstream 块中开启长连接池
bash
upstream tomcat_servers {
server 172.25.254.11:8080 weight=1;
server 172.25.254.12:8080 weight=1;
# 【核心】:设置每个 Worker 进程与后端服务器保持的空闲长连接的最大数量。
# 注意:这并非最大并发数,而是保留在连接池里的"闲置"连接数,随用随取,省去了握手时间。
keepalive 100;
}第二步:在 location 块中强制使用 HTTP/1.1 并清除 close 头
bash
server {
listen 80;
server_name localhost;
charset utf-8;#添加此行避免后续中文乱码
location /api/ {
proxy_pass http://tomcat_servers;
# 【核心 1】:强制 Nginx 使用 HTTP/1.1 协议与 Tomcat 沟通(1.1 默认支持长连接)
proxy_http_version 1.1;
# 【核心 2】:清除客户端可能传过来的 "Connection: close" 请求头,
# 并将其替换为空,从而告诉 Tomcat:"我们要保持连接!"
proxy_set_header Connection "";
# 传递真实 IP 等常规反代参数
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}把这两端都配置好之后,你的架构就实现了真正的 "全链路长连接"。 Nginx 就像一个超级快递中转站:它不仅让外面的快递车(客户端)不用每次进门都重新登记,还在内部专门修了一条直达后厨(Tomcat)的高速传送带。这样,即使并发流量再翻几倍,CPU 的负载也会稳如泰山。

七、Location 的匹配规则与优先级
在 Nginx 中,location 块是整个路由转发的"灵魂"。当 Nginx 接收到一个用户的 URL 请求时,就是靠 location 及其后面的正则表达式 和修饰符,来决定把这个请求交给谁处理(是直接返回本地图片,还是转发给后端的 Tomcat)。
1. Nginx location 的五大修饰符
Nginx 的 location 匹配分为两大类:普通前缀匹配 和 正则匹配 。控制它们行为的,是紧跟在 location 后面的符号:
| 修饰符 | 含义 | 类型 | 示例 | 说明 |
|---|---|---|---|---|
= |
精确匹配 | 普通 | location = /login |
URL 必须一字不差,多一个斜杠都不行。速度最快。 |
^~ |
前缀匹配 (排斥正则) | 普通 | location ^~ /static/ |
匹配以特定字符串开头的 URL。关键特性: 一旦匹配成功,Nginx 就会立刻停止向下搜索正则表达式! |
~ |
正则匹配 (区分大小写) | 正则 | `location ~ .(JPG | PNG)$` |
~* |
正则匹配 (不区分大小写) | 正则 | `location ~* .(jpg | png)$` |
| 无 | 普通前缀匹配 | 普通 | location /admin/ |
匹配所有以 /admin/ 开头的 URL。优先级最低。 |
2. 核心大坑:令人窒息的"匹配优先级"
千万记住:Nginx 并不是按你配置文件里写的上下顺序来匹配的! 它有一套极其严苛的优先级顺位。当一个 URL 过来时,Nginx 的大脑是这样运转的:
终极优先级排序:
=>^~>~或~*> 普通前缀匹配
详细的内审流程:
-
先查"精确匹配": 如果有
=并且完全匹配,立刻执行,结束搜索。 -
再查"普通前缀": 找出所有匹配的普通前缀(包括带
^~和不带符号的),记住匹配路径最长的那一个。-
如果这个最长的前缀带有
^~,好,立刻执行它,结束搜索! -
如果不带
^~,Nginx 会把它当个"备胎"先放着,继续往下走。
-
-
接着查"正则匹配": Nginx 开始从上到下查找
~和~*的正则规则。只要匹配到一个正则表达式,立刻执行,抛弃之前的备胎! (注意:正则匹配是按配置文件里的物理顺序,谁在上面谁优先) -
最后用"备胎": 如果所有的正则表达式都没匹配上,Nginx 才会回头去执行刚才在第 2 步留下的那个"最长前缀备胎"。
3. 动静分离的终极实战范例
在我们的"Nginx + Tomcat"动静分离架构中,location 正则匹配是这样大显身手的:
bash
server {
listen 80;
server_name localhost;
charset utf-8;
# 1. 最高优先级:首页精确匹配
# 只要用户访问 http://172.25.254.10/,立刻命中这里,速度极快
location = / {
root html;
index index.html;
}
# 2. 动静分离核心:拦截所有静态图片/资源 (不区分大小写的正则)
# 只要 URL 结尾是这些后缀,Nginx 直接去本地磁盘找,绝不打扰 Tomcat
location ~* \.(gif|jpg|jpeg|png|css|js|ico)$ {
root /usr/local/nginx/html/static_resources;
# 顺便给静态资源加上浏览器缓存过期时间 (7天),提升性能
expires 7d;
}
# 3. 强力前缀匹配:后台管理系统隔离
# 因为有 ^~,所以就算访问 /admin/logo.jpg,也会被拦截在这里,不会去匹配上面的图片正则
location ^~ /admin/ {
root /usr/local/nginx/html/secure_admin;
# 可以在这里做 IP 白名单限制等安全策略
}
# 4. 兜底与动态转发:通用代理 (普通的 /)
# 所有的 .jsp、.do、或者 /api/ 接口请求,因为匹配不到上面的任何规则,最终都会落到这里
location /tomcat/ {
# 将请求狠狠地扔给后端的 Tomcat 集群
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}八、目录访问用户认证
我们经常会部署一些内部系统(比如后台管理面板、Kibana 日志查看器、Prometheus 监控看板等),这些页面如果没有自带的登录系统,直接暴露在外网是非常危险的。
这时候,Nginx 的 auth_basic(基础身份认证) 就派上大用场了。它可以强制用户在访问某个特定目录时,必须先弹出一个框,输入正确的账号密码才能看到内容。
1. 准备武器:安装密码生成工具
Nginx 本身是不带密码生成工具的,业界最标准的做法是借用 Apache 的 htpasswd 工具来生成经过加密的密码文件。
在 Nginx 服务器上执行以下命令安装工具:
bash
dnf install httpd-tools -y2. 创建加密的密码文件
我们需要在 Nginx 的配置目录下创建一个文件(比如叫 htpasswd),用来专门存放允许访问的账号和密码。
假设我们要创建一个账号叫 admin:
bash
# -c 参数代表 Create(创建新文件)。注意:如果以后要追加第二个用户,千万别加 -c,否则会清空旧数据!
htpasswd -c /usr/local/nginx/conf/htpasswd admin执行后,系统会提示你连续输入两次密码(比如输入
123456)。

验证一下:
敲击 cat /usr/local/nginx/conf/htpasswd
你会看到类似 admin:$apr1... 的乱码,这就说明密码已经被单向加密保存好了,非常安全。

3. 修改 Nginx 配置,给目录加锁
现在我们要告诉 Nginx,把哪一把"锁"挂在哪个"门"上。
打开你的 Nginx 配置文件: vim /usr/local/nginx/conf/nginx.conf
在 server 块中,找一个你想保护的目录(比如我们要保护 /admin/ 目录):
bash
server {
listen 80;
server_name localhost;
charset utf-8;
# 普通用户的公开访问区域
location / {
root html;
index index.html index.htm;
}
# 核心防线:保护 /admin/ 目录
location /admin/ {
root html; # 真实物理路径 (最终会去 html/admin/ 找文件)
index index.html;
# 开启基础认证,这里的提示文字在某些浏览器上会显示在弹窗里
auth_basic "Restricted Access! Please Login:";
# 指定刚才生成的密码文件绝对路径
auth_basic_user_file /usr/local/nginx/conf/htpasswd;
}
}
bash
# 在开始这个实验前把这段旧的删掉或者注释掉,否则会冲突
# location ^~ /admin/ {
# root /usr/local/nginx/html/secure_admin;
# }4. 准备测试页面并重启验证
为了看到效果,我们需要在系统里真正造一个 /admin/ 目录和页面。
1). 创建测试页面:
bash
mkdir -p /usr/local/nginx/html/admin
echo '<h1 style="color:red;">Welcome to Top Secret Admin Panel!</h1>' > /usr/local/nginx/html/admin/index.html
chmod 755 /usr/local/nginx/html/admin/index.html2). 检查语法并重载 Nginx:
bash
/usr/local/nginx/sbin/nginx -t
systemctl reload nginx3). 验证结果:
现在,回到你的母机(172.25.254.100),打开浏览器访问: http://172.25.254.10/admin/
预期效果: 浏览器会立刻弹出一个经典的账号密码输入框!
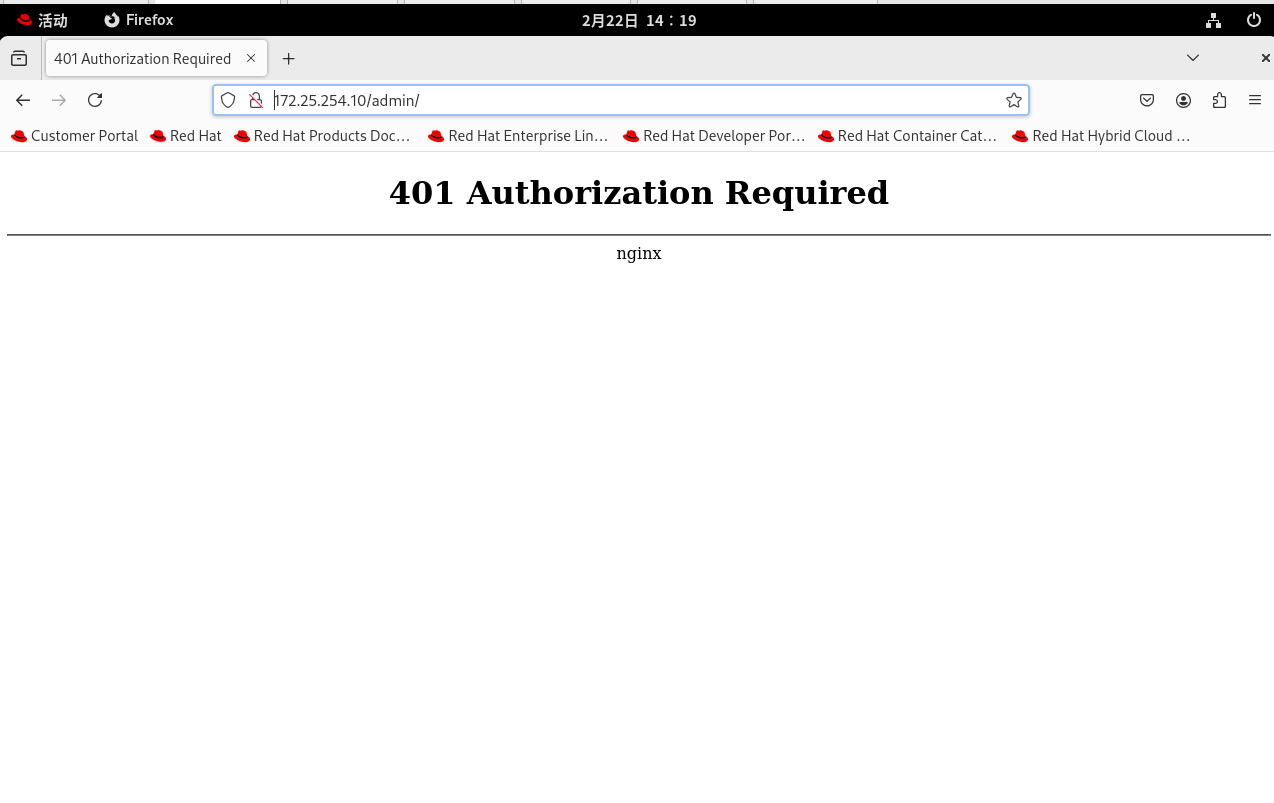
如果你点取消或者乱输,页面会直接无情地报
401 Unauthorized(未授权)。只有输入账号
admin和刚才设置的密码,才能看到红色的欢迎语!
如果你想在终端里用命令测试,可以加上 -u 参数:
bash
curl -u admin:123456 http://172.25.254.10/admin/
九、自定义错误界面和错误日志
在默认情况下,如果用户访问了不存在的页面,Nginx 会弹出一个极其简陋的白底黑字 404 Not Found 页面,并且还会附带上 Nginx 的版本号(这就存在泄露服务器信息的安全隐患)。而默认的日志格式虽然够用,但缺少了排查性能瓶颈最关键的指标:请求耗时。
1. 自定义错误页面 (Error Page):提升用户体验
我们要把冰冷无情的报错,换成我们自己设计的温馨提示页面。
第一步:修改 Nginx 配置文件 打开配置文件:vim /usr/local/nginx/conf/nginx.conf
在你的 server 块里面,加入 error_page 指令:
bash
server {
listen 80;
server_name localhost;
charset utf-8;
# ... 其他 location 配置 ...
# 1. 指定遇到 404 错误时,内部跳转到 /404.html 这个 URI
error_page 404 /404.html;
# 2. 专门为 /404.html 写一个 location,告诉 Nginx 去哪里找这个实体文件
location = /404.html {
root html; # 去 /usr/local/nginx/html/ 目录下找
}
# 3. 你也可以把 500、502 等服务器内部错误统一指向一个 50x 页面
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}第二步:创建错误页面实体文件
bash
echo '<h1 style="color:orange; text-align:center;">Oops! 404 - 你要找的页面被外星人劫持了!</h1>' > /usr/local/nginx/html/404.html
echo '<h1 style="color:red; text-align:center;">50X - 服务器正在抢修中,请稍后再试...</h1>' > /usr/local/nginx/html/50x.html第三步:重载验证
systemctl reload nginx 后,去浏览器里故意访问一个不存在的路径(比如 http://172.25.254.10/abcde/),你就能看到刚才设计的橙色 404 页面了!
2. 自定义访问日志 (Access Log):打造鹰眼监控
Nginx 的访问日志是排查被黑客攻击(比如恶意刷接口)、分析用户画像、以及定位网站卡顿原因的最核心资产。
默认的日志格式没有记录**"这个请求花了多长时间"**,在后续接入 Tomcat 后,这是极其致命的(因为你不知道是 Nginx 慢还是 Tomcat 慢)。
第一步:在 http 块中定义极其详尽的日志格式
打开配置文件,在 http { ... } 块里面(注意,必须在 server 块的外面),定义一个名为 main 的日志格式:
bash
http {
include mime.types;
default_type application/octet-stream;
# 定义名为 main 的日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" '
'req_time=$request_time up_time=$upstream_response_time';
# 开启访问日志,并指定使用刚才定义的 main 格式
access_log logs/access.log main;
# ... 其他优化配置 ...
}解析:这些变量是什么意思?
-
$remote_addr:访问者的真实 IP。
-
$request:他请求了什么 URL(比如
GET /admin/ HTTP/1.1)。 -
$status:返回状态码(200 成功,403 拒绝,404 没找到)。
-
$http_user_agent:他用的是什么浏览器或手机型号。
-
$request_time:(极其重要) Nginx 处理这个请求花费的总秒数。
-
$upstream_response_time:(为 Tomcat 预留) Nginx 把请求发给后端 Tomcat,到 Tomcat 处理完返回结果花费的秒数。这能帮你瞬间甩锅:"不是我的网络慢,是你 Java 代码跑得太慢!"
第二步:重载并实时观察
保存并重载:systemctl reload nginx
现在,打开你的终端,使用 tail -f 实时监控日志文件:
bash
tail -f /usr/local/nginx/logs/access.log然后去浏览器里随便刷新几次页面。你会看到终端里实时滚动的日志,最后面清晰地记录着 req_time=0.000(因为我们现在是静态文件,几乎是 0 毫秒响应)。

十、自定义Nginx下载服务器及文件检测功能
打造一个专属的 Nginx 下载服务器(类似于 FTP 的网页版目录浏览),是企业内网分享工具、安装包或共享文件的极佳方案。
Nginx 天生就是处理静态文件的"王者"。凭借极其优异的 I/O 性能,它不仅能轻松应对大并发下载,还能通过内置的 Autoindex 模块实现极其优雅的目录文件检测与展示。
我们将这个实战分为两步:开启目录浏览 和 高阶文件控制(限速与强制下载)。
1. 基础搭建:开启 Autoindex 目录浏览
默认情况下,如果你访问一个 Nginx 目录而该目录下没有 index.html,Nginx 会出于安全考虑直接给你报 403 Forbidden。 要把它变成下载服务器,我们需要让 Nginx 遇到目录时,自动列出里面的文件清单。
第一步:创建下载存放的专属目录和测试文件
在你的 Nginx 服务器上敲击这些命令,咱们伪造几个不同类型的文件用来测试:
bash
# 创建下载目录
mkdir -p /usr/local/nginx/html/download
# 制造几个空文件作为下载诱饵
dd if=/dev/zero of=/usr/local/nginx/html/download/CentOS-9.iso bs=1M count=10 # 伪造一个 10MB 的镜像文件
touch /usr/local/nginx/html/download/使用说明.txt
touch /usr/local/nginx/html/download/内部工具.zip第二步:修改 Nginx 配置,植入灵魂指令
打开配置文件:vim /usr/local/nginx/conf/nginx.conf
在你的 server 块中,新增一个专门针对 /download/ 的 location:
bash
server {
listen 80;
server_name localhost;
charset utf-8; # 确保这里有全局的 utf-8,否则中文文件名会乱码!
# ... 其他的 location ...
# 专属下载服务器配置
location /download/ {
root html; # 真实物理路径为 /usr/local/nginx/html/download/
# 【核心功能】:开启目录文件列表展示
autoindex on;
# 【细节优化 1】:显示人性化的文件大小 (例如 10M、2G,而不是一长串字节数)
autoindex_exact_size off;
# 【细节优化 2】:显示服务器当前的本地时间,而不是格林威治时间
autoindex_localtime on;
}
}第三步:重载验证
bash
/usr/local/nginx/sbin/nginx -t
systemctl reload nginx现在,打开浏览器访问 http://172.25.254.10/download/
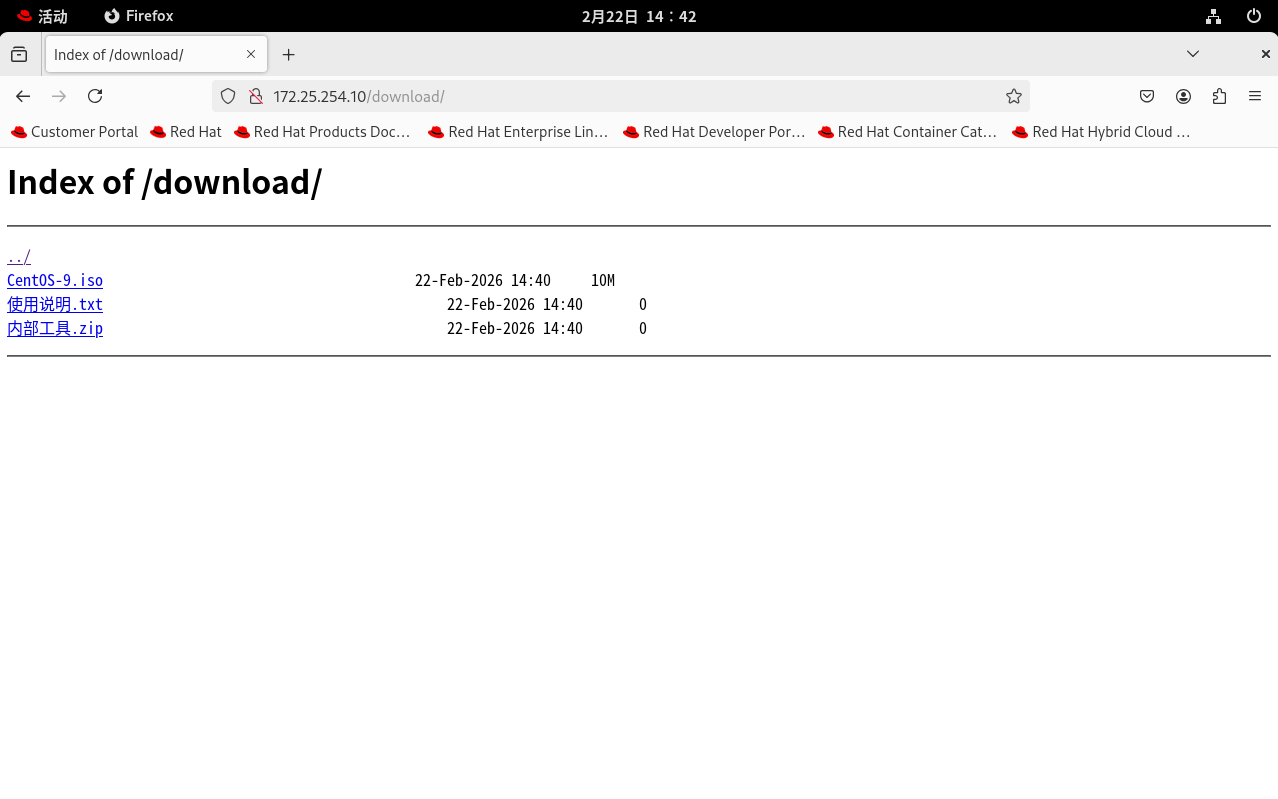
你会立刻看到一个极具极客风格的网页目录列表!里面清晰地列出了你刚才创建的
.iso、.txt和.zip文件,大小和修改时间一目了然,点击就能直接访问或下载。
2. 高阶玩法:文件检测与精细化控制
仅仅列出文件还不够专业。在实际企业环境中,下载服务器通常会面临两个痛点:带宽被跑满 和 某些文件在浏览器里直接打开了(比如 txt、pdf、图片),而不是弹窗下载。
我们继续完善那个 location /download/,加入这两项杀手锏:
技能一:防止恶意占用带宽(单连接限速)
如果你不限速,局域网里的一个人用迅雷下载你的大文件,瞬间就会把服务器的千兆网卡跑满,导致其他人的业务全卡住。
bash
location /download/ {
root html;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
# 【限速防刷】:限制每个连接的最高下载速度为 1MB/s
limit_rate 1m;
# 【高级限速】:前 5MB 不限速,超过 5MB 后开始降速到 500KB/s
# limit_rate_after 5m;
# limit_rate 500k;
}技能二:文件检测与强制下载防线
Nginx 内部有一个 mime.types 字典,它通过文件后缀名来"检测"文件类型。
-
遇到
.zip、.iso,它知道是二进制数据,会让浏览器弹窗下载。 -
遇到
.txt、.jpg、.pdf,它会让浏览器直接在网页里预览打开。
如果你的下载服务器希望不管什么文件,点击后统统强制弹窗下载,我们要给响应头加点料:
bash
location /download/ {
root html;
autoindex on;
autoindex_exact_size off;
autoindex_localtime on;
limit_rate 1m;
# 【强制下载】:匹配所有文件,如果请求的是一个具体文件(而不是目录),就强制触发下载行为
if ($request_filename ~* ^.*?\.(txt|pdf|jpg|png)$) {
# 告诉浏览器:这是一个附件,请把它下载下来,不要打开!
add_header Content-Disposition "attachment";
}
}保存、-t 测试语法、systemctl reload nginx
接着,去刷新刚刚的下载界面:
-
试着点击那个
使用说明.txt,原本会直接在浏览器里显示文字,现在应该直接触发浏览器的下载框了! -
试着下载那个 10MB 的
CentOS-9.iso,你会发现速度被稳稳地压制在了 1MB/s 左右!
十一、Nginx状态页
还记得我们在最开始源码编译 Nginx 时,敲下的那个 --with-http_stub_status_module 参数吗?当时埋下的伏笔,现在终于派上大用场了!
这个模块可以让我们实时看到 Nginx 当前的并发连接数、处理了多少请求等极其硬核的性能指标。
1. 开启状态页并配置"白名单"防线
状态页包含了服务器的核心运行数据,绝对不能暴露给公网的所有人! 如果被黑客看到,他们就能轻易摸清你服务器的并发极限,从而发起精准的 DDoS 攻击。
因此,我们在开启它的同时,必须利用 Nginx 的访问控制指令(allow 和 deny)给它加把锁,只允许你的母机(172.25.254.100)和本机访问。
第一步:修改 Nginx 配置文件
打开 vim /usr/local/nginx/conf/nginx.conf,在你的 server 块中加入一个全新的 location:
bash
server {
listen 80;
server_name localhost;
charset utf-8;
# ... 其他的 location (下载服务器、错误页等) ...
# 【核心】:开启 Nginx 状态监控仪表盘
location /status {
# 激活状态页模块
stub_status on;
# 访问状态页通常是监控脚本高频抓取,没必要记录到访问日志里浪费磁盘 I/O
access_log off;
# 【安全防线】:IP 白名单访问控制 (注意执行顺序是从上往下匹配)
allow 127.0.0.1; # 允许本机访问 (方便本地脚本抓取)
allow 172.25.254.100; # 允许你的物理母机访问
deny all; # 拒绝其他所有 IP 访问!
}
}第二步:重载生效
bash
/usr/local/nginx/sbin/nginx -t
systemctl reload nginx2. 查看状态页与核心指标破译(面试必考)
现在,回到你的母机浏览器(或在终端用 curl),访问: http://172.25.254.10/status
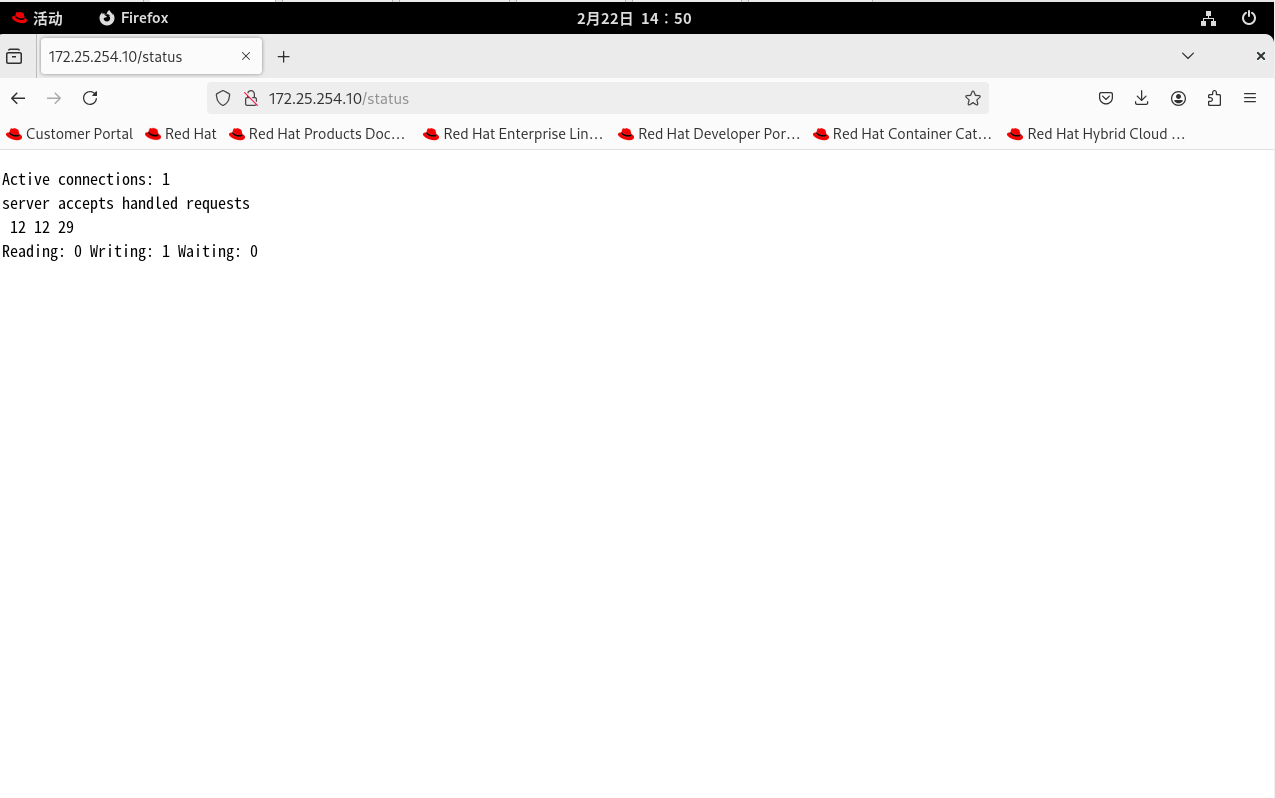
你会看到一个非常极简、只有纯文本的页面,大概长这样:
页面解析:
第一行:实时兵力
Active connections(活跃连接数): 当前 Nginx 正在处理的活动连接数(包括正在等待的)。如果这个数字逼近了你配置的worker_connections,说明 Nginx 马上就要被压垮了!
第二/三行:历史战绩 (从 Nginx 启动到现在的累计值)
-
accepts(接收连接数): Nginx 总共接收了多少个客户端的 TCP 连接(这里是 15)。 -
handled(处理连接数): Nginx 成功处理了多少个 TCP 连接(这里也是 15)。注意:通常 accepts 会等于 handled,如果 handled 小于 accepts,说明服务器达到了资源瓶颈,开始丢弃连接了! -
requests(总请求数): Nginx 总共处理了多少个 HTTP 请求(这里是 28)。因为我们配置了长连接 (Keep-Alive),一个 TCP 连接里可以跑多个 HTTP 请求,所以这个数字通常大于上面的连接数。
第四行:连接的具体状态画像 (核心抓取指标) 这三个数字加起来,通常等于第一行的 Active connections。
-
Reading(读取中): Nginx 正在读取客户端发送来的 HTTP 请求头的数量。 -
Writing(写入中): Nginx 正在处理请求,或者正在把响应数据(比如那个 10M 的 ISO 文件)往回发给客户端的数量。这个数字越大,说明服务器当前的业务越繁忙。 -
Waiting(等待中): 开启 Keep-Alive 后,客户端请求已经处理完,但 TCP 连接还没断,Nginx 正在"空闲等待"下一次请求的连接数。这个数字如果特别大,说明前端长连接保持得很好,但也可能占用过多内存。
3.实战升华:如何模拟并发看数据变化?
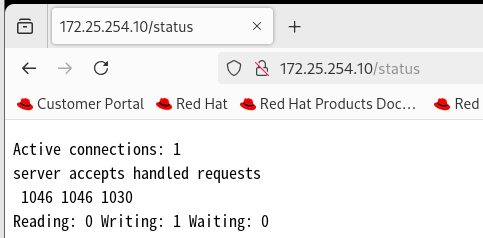
可以用母机(172.25.254.100)上的 ab 工具(Apache Benchmark,可以通过 dnf install httpd-tools 安装)对 Nginx 发起一波小规模压测:
bash
# 在母机上发起 1000 个请求,并发量 100
ab -n 1000 -c 100 http://172.25.254.10/压测结束后再去刷新 /status 页面,你会发现中间那行的数字瞬间飙升了 1000 多
十二、Nginx的压缩功能和变量
压缩功能 (Gzip) 是帮你老板省下天价网络带宽费、让用户网页"秒开"的物理外挂;而 Nginx 变量 (Variables) 则是你编写复杂路由规则、实现精准流量控制的灵魂引擎。
1. 榨干网络带宽的终极魔法:Gzip 压缩功能
在 Web 传输中,最大的瓶颈往往不是 CPU,而是网络带宽。一个包含了大量 HTML、CSS 和 JS 脚本的现代网页动辄几 MB。Nginx 的 Gzip 模块可以在服务器端把这些纯文本文件"压缩"后再发给客户端,浏览器收到后再"解压"渲染。
这个过程虽然会稍微消耗一点点服务器的 CPU,但能换来高达 60%~80% 的体积缩减!网页加载速度直接起飞。
核心配置详解
打开你的 Nginx 配置文件 vim /usr/local/nginx/conf/nginx.conf,在 http { ... } 块中加入这套企业级标准配置(如果你在前面的优化实验中已配置可忽略):
bash
http {
# ... 其他配置 ...
# 1. 开启 gzip 压缩引擎
gzip on;
# 2. 触发压缩的最小文件门槛 (太小的文件,压缩后的字典开销可能比原文件还大,得不偿失)
# 建议设置为 1k 或 2k
gzip_min_length 1k;
# 3. 压缩级别 (1-9)
# 1 压缩率最低,消耗 CPU 最少;9 压缩率最高,极其消耗 CPU。
# 业界公认的黄金甜点位是 4 或 5,兼顾了速度与压缩率!
gzip_comp_level 5;
# 4. 指定需要被压缩的文件类型 (MIME type)
# 【高危避坑】:千万不要把图片 (jpg/png) 和视频放进来!它们本身已经是高度压缩格式,强行 gzip 不仅体积减不下来,还会把服务器 CPU 跑满!只压缩纯文本类型即可。
gzip_types text/plain text/css application/javascript application/json application/xml text/javascript image/svg+xml;
# 5. 增加 Vary: Accept-Encoding 响应头
# 告诉前端的 CDN 节点或代理服务器:"我这个文件是按 gzip 压缩的",防止 CDN 把压缩版发给不支持解压的老古董浏览器
gzip_vary on;
# 6. 禁用老旧浏览器的压缩支持 (比如 IE6,它对 gzip 的解压有 Bug)
gzip_disable "MSIE [1-6]\.";
}在此之前,给网页注入一些内容,增大体积,超过我们前面所设置的1k阈值:
bash
cat /etc/passwd >> /usr/local/nginx/html/index.html配置好并 systemctl reload nginx 后,在你的母机(172.25.254.100)终端里用 curl 模拟浏览器发个请求:
bash
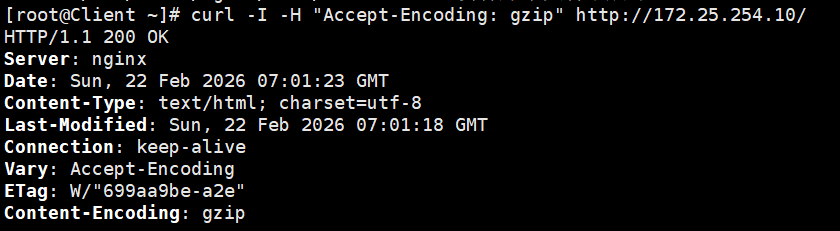
# -I 只看响应头,-H 告诉 Nginx "我的浏览器支持 gzip 解压"
curl -I -H "Accept-Encoding: gzip" http://172.25.254.10/如果你在返回结果里看到了 Content-Encoding: gzip 这一行,恭喜你,压缩生效了!
2. Nginx 的"超能力"引擎:核心内置变量
Nginx 之所以能像编程语言一样写出极其复杂的 if 判断和流量调度,全靠它内部自带的几十个 内置变量 (Built-in Variables)。
只要请求一到达 Nginx,这些变量就会瞬间被赋予当前请求的各种属性。在博客里,我们可以重点列出实战中最常用的核心变量:
必背的 Nginx 内置变量全景图
| 变量名 | 代表的含义 | 实战应用场景举例 |
|---|---|---|
$remote_addr |
客户端的真实 IP 地址 | 日志记录、IP 黑白名单拦截 (deny $remote_addr;) |
$host |
用户请求的域名或 IP | 反向代理时传递给后端 (proxy_set_header Host $host;) |
$request_uri |
包含请求参数的完整 URL | 页面重定向 (return 301 https://$host$request_uri;) |
$document_root |
当前请求命中的 root 物理路径 |
调试文件找不到的问题 |
$http_user_agent |
用户的浏览器、操作系统标识 (UA) | 拦截恶意爬虫、区分手机和电脑访问 |
$args |
URL 中 ? 后面的参数部分 |
针对特定的搜索条件进行缓存拦截 |
实战演练:利用变量"手撕"恶意爬虫
很多初学者觉得变量很抽象,咱们直接在 server 块里写一段基于变量的防爬虫策略。
打开你的配置文件,加入这段代码:
bash
server {
listen 80;
server_name localhost;
# 【实战】:如果 Nginx 发现请求头里的 User-Agent 包含 "curl" 或 "Scrapy"(恶意爬虫常用的工具)
if ($http_user_agent ~* (curl|Scrapy|python-requests)) {
# 毫不留情地返回 403 拒绝访问!
return 403;
}
location / {
root html;
index index.html;
}
}重载 Nginx ,进行测试:
在母机终端用浏览器访问 http://172.25.254.10/,一切正常。 但是如果你在终端敲入 curl http://172.25.254.10/,Nginx 会瞬间识别出你的工具,并当场甩回一个 403 Forbidden
高阶玩法:自定义变量
除了内置的,你还可以自己创造变量!使用 set 指令:
- 把测试代码写进配置文件:
bash
location /test {
# 告诉浏览器/终端:这只是纯文本,直接显示出来,千万别当成文件下载!
default_type text/plain;
# 创造一个叫 $my_var 的变量,赋值为 "Hello, Nginx Super Hacker!"
set $my_var "Hello, Nginx Super Hacker!";
# 直接把 HTTP 状态码 200 和一段拼接了变量的字符串打回给客户端
return 200 "====== Nginx Variable Test ======\nMy Custom Variable:$my_var\nYour Client IP: $remote_addr\nRequested URI: $request_uri\n=================================\n";
}- 测试并重载
bash
/usr/local/nginx/sbin/nginx -t
systemctl reload nginx- 见证奇迹:发起测试请求
现在,回到你的测试机/母机(172.25.254.100),打开终端,直接用 curl 访问这个特定的路径(记得删除或注释前面的防爬虫代码):
bash
curl http://172.25.254.10/test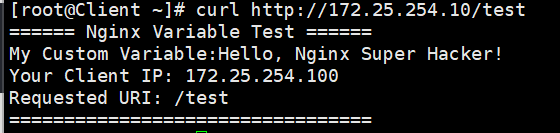
十三、Rewrite(重写)模块及全站加密
如果说反向代理是 Nginx 的躯干,那么 Rewrite 模块就是 Nginx 的"灵魂路由器"。无论是做 SEO 优化、隐藏真实后台路径、还是强制 HTTPS 加密,全靠它来变魔术。
1. 核心原理解析:Rewrite 模块指令语法
Nginx 的 URL 重写主要依赖于 ngx_http_rewrite_module 模块。它的核心指令语法其实非常简单,就像一个翻译公式:
rewrite <regex> <replacement> flag;
关键字 正则表达式 替换成的新路径 执行动作(可选)
公式拆解:
-
regex(正则表达式): 用来匹配用户当前请求的 URL(比如提取里面的文件名或目录)。 -
replacement(替换路径): 匹配成功后,你想把它改成什么样的新 URL。 -
flag(动作标志位): 决定了重写后的后续动作(是直接跳走,还是继续往下匹配)。
实战小例子: 老板说:"我们的网站 URL 以前是 /article/123.html,现在系统升级了,真实路径变成了 /post?id=123,但你要保证用户访问老链接依然有效!" 你只需写下:rewrite ^/article/([0-9]+).html /post?id=1 last;
(解析:用括号 () 把数字抓出来,在后面用 $1 引用它,神不知鬼不觉地完成了内部偷换!)
2. 四大天王:网页重写动作 (Flags) 深度对比
很多新手在写 rewrite 时,最后那个 flag 参数全凭感觉瞎抄,导致经常出现"死循环"或者"重定向次数过多"。
面试官最爱考的就是这四大动作的区别。我们按照**"内部处理"** 和**"外部跳转"**把它们彻底分清:
【内部隐藏式重写】(浏览器地址栏不会变)
用户根本不知道服务器内部发生了路径替换,这通常用于伪静态。
-
last(最常用,重新匹配):-
动作: 停止执行当前的 rewrite 指令集,拿着替换后的新 URL ,重新在所有的 location 块中走一遍匹配流程。
-
比喻: 你去前台找 A 部门,前台说"A 部门改名叫 B 部门了,你重新去大厅看一眼 B 部门在哪吧"。
-
-
break(直接执行,不回头):-
动作: 停止执行当前的 rewrite 指令集,拿着新 URL 直接去当前所在的物理目录下找文件,不再 重新去匹配其他 location。
-
比喻: 你去前台找 A 部门,前台说"A 部门改名了,别到处跑了,他们就在这扇门后面,直接推门进去吧"。
-
【外部暴露式跳转】(浏览器地址栏会发生变化)
服务器直接告诉浏览器:"你要找的东西搬家了,你自己去新地址找吧"。
-
redirect(302 临时重定向):-
动作: 返回 302 状态码。告诉浏览器和搜索引擎:"这只是临时搬家,下次你还是先来老地址看看"。
-
场景: 网站临时维护、活动页面临时跳转。
-
-
permanent(301 永久重定向):-
动作: 返回 301 状态码。告诉浏览器和搜索引擎:"我永久搬家了,以后请直接去新地址,顺便把老地址的 SEO 权重全部转移给新地址!"
-
场景: 域名更换(老域名跳新域名)、全站 HTTP 强制跳转 HTTPS。
-
3. 终极实战:利用 Rewrite 实现全站 HTTP 到 HTTPS 强制加密
在现在的互联网环境下,网站没有 HTTPS(小绿锁)是不可想象的。但很多用户习惯性地直接在浏览器敲域名(默认是 HTTP 80 端口)。
我们要做的,就是用 rewrite 和 permanent,把所有来到 80 端口的流量,无情地"一脚踹到" 443(HTTPS)端口去!
打开你的 Nginx 配置文件: vim /usr/local/nginx/conf/nginx.conf
在你的配置里,我们需要配置两个 server 块。一个是负责接收 80 端口的门卫,一个是真正处理 443 业务的内场:
bash
# ==========================================
# 门卫:监听 80 端口 (HTTP),专职负责把流量踹到 443
# ==========================================
server {
listen 80;
server_name localhost; # 也可以写 172.25.254.10
# 【核心魔法】:全站强制 HTTPS 重写!
# 只要你敢从 80 端口进来,我立刻甩你一个 301 永久重定向,让你去 https:// 的同名路径
rewrite ^/(.*)$ https://$host/$1 permanent;
}
# ==========================================
# 内场:监听 443 端口 (HTTPS),真正的业务大厅
# ==========================================
server {
listen 443 ssl;
server_name localhost;
charset utf-8;
# 【挂载证书】:告诉 Nginx 你的公钥和私钥藏在哪里
ssl_certificate /usr/local/nginx/conf/ssl/server.crt;
ssl_certificate_key /usr/local/nginx/conf/ssl/server.key;
# 【高级 SSL 优化】:提升加密性能和安全性
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
# 你的主页配置
location / {
root html;
index index.html index.htm;
}
# ... 你之前配置的 /status 或者 /admin 都可以搬到这里面来 ...
}创建密钥与证书 (OpenSSL)
我们需要在 Nginx 的配置目录下建一个专门存放证书的安全文件夹,然后用一条极其硬核的命令同时生成私钥 (.key) 和公钥证书 (.crt)。
在你的 Nginx 服务器 (172.25.254.10) 终端执行:
bash
# 1. 创建专门存放证书的目录
mkdir -p /usr/local/nginx/conf/ssl
cd /usr/local/nginx/conf/ssl
# 2. 一键生成 10 年有效期的 RSA 2048 位自签名证书
# -subj 参数是为了帮你自动填好国家(CN)、省份、组织名等信息,免去了一步步手动输入的麻烦
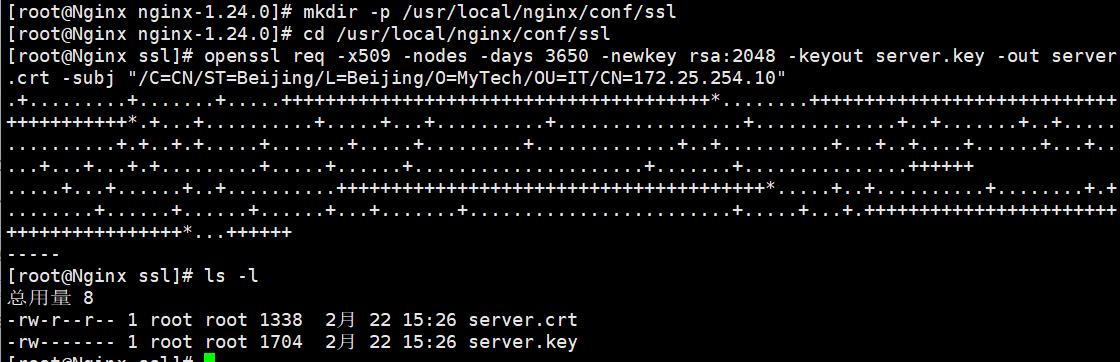
openssl req -x509 -nodes -days 3650 -newkey rsa:2048 -keyout server.key -out server.crt -subj "/C=CN/ST=Beijing/L=Beijing/O=MyTech/OU=IT/CN=172.25.254.10"
# 3. 检查一下是否生成成功
ls -l看到 server.crt 和 server.key 这两个文件,咱们的加密武器就准备好了*(注意:
.key是绝对机密,在企业里泄露了是要开除的;.crt是公开给浏览器看的身份证明。)*
重载验证:
bash
/usr/local/nginx/sbin/nginx -t
systemctl reload nginx现在,回到你的母机/测试机 (172.25.254.100),用 curl 模拟浏览器的访问行为:
第一回合:测试 80 端口的强制跳转
bash
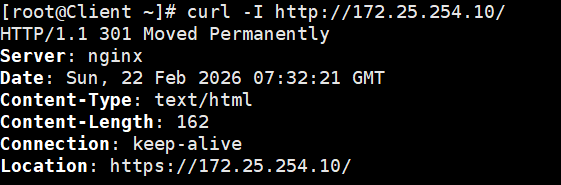
# -I 只看响应头
curl -I http://172.25.254.10/预期输出: 你会清晰地看到 HTTP 状态码变成了 HTTP/1.1 301 Moved Permanently,并且下面有一行极其关键的指令:Location: https://172.25.254.10/
第二回合:测试 443 端口的 SSL 握手
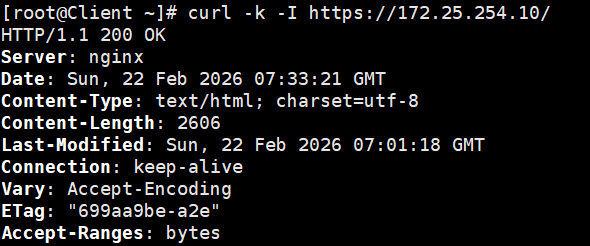
因为我们是自签名证书(没交保护费,不被国际根证书机构信任),所以如果直接用 curl 会报证书不安全的错。我们需要加一个 -k 参数,告诉 curl "我知道这是自签名的,放行吧":
bash
curl -k -I https://172.25.254.10/预期震撼输出: 你会看到令人心安的 HTTP/1.1 200 OK
如果你用母机的浏览器 去访问 http://172.25.254.10,你会发现地址栏瞬间闪烁,自动变成了 https://172.25.254.10(浏览器会提示"您的连接不是私密连接",这是因为自签名的原因,点击"高级" -> "继续前往"即可看到你的 Nginx 网页)。
十四、Nginx的四大神技
前面我们给 Nginx 做的所有强化(性能调优、HTTPS、压缩、限速),都是为了给今天这一步打基础。当单台 Tomcat(或者任何后端程序)扛不住海量用户的访问时,Nginx 就会化身为"超级调度员"。我们直接用一个**"全套实战配置"**,把这四大神技一次性全部打通。
1. 核心理论:四大神技的本质
-
反向代理 (Reverse Proxy): 客户端不知道真实的后端服务器是谁。Nginx 就像饭店的"前台接待",用户只管把请求交给 Nginx,Nginx 去后厨(Tomcat)拿结果,再转交给用户。这就隐藏了后端的真实 IP,保障了内网安全。
-
动静分离 (Dynamic/Static Separation): Nginx 处理静态文件(图片、CSS、JS、HTML)的速度极其恐怖,而 Tomcat 处理静态文件很慢,但擅长处理 Java 逻辑。动静分离就是:静态资源 Nginx 自己直接返回,动态接口(如
.jsp或/api/)才丢给 Tomcat 处理。 各司其职,榨干硬件性能。 -
负载均衡 (Load Balancing): 当后厨(Tomcat)有两个以上的厨师时,Nginx 负责把用户的订单公平地分发给他们,避免一个人累死,另一个人闲死。
-
缓存加速 (Proxy Cache): 如果大量用户都在请求同一个动态接口(比如"查询今日热榜"),Nginx 会把 Tomcat 第一次返回的结果"缓存"在自己本地。接下来几分钟内的相同请求,Nginx 直接把缓存扔给用户,根本不打扰 Tomcat。
2. 终极实战:Nginx 配置文件大融合
打开你的 Nginx 配置文件 vim /usr/local/nginx/conf/nginx.conf。为了实现这四大神技,我们需要在 http 块和 server 块中分别布阵,在开始之前,最好清理一下之前的配置:
第一步. 伪造"后厨":准备两个不同的动态接口数据
用 Nginx 自己的本地目录伪造两个"动态 API 返回值"。
在你的 172.25.254.10 服务器终端执行:
bash
# 创建两个伪装的后端目录
mkdir -p /usr/local/nginx/html/backend1
mkdir -p /usr/local/nginx/html/backend2
# 伪造后端接口数据 (我们用纯文本假装它是 API 返回的 JSON 或 JSP)
echo "【动态接口响应】: 我是节点一 (端口 8081)" > /usr/local/nginx/html/backend1/api.txt
echo "【动态接口响应】: 我是节点二 (端口 8082)" > /usr/local/nginx/html/backend2/api.txt
# 创建一个用于测试动静分离的静态文件
mkdir -p /usr/local/nginx/html/static
echo "我是纯静态文件,直接由 Nginx 80 端口返回,没走代理!" > /usr/local/nginx/html/static/logo.txt第二步.编写 Nginx "自导自演"的终极配置文件
打开 Nginx 配置文件 vim /usr/local/nginx/conf/nginx.conf。 为了避免干扰,你可以把 http 块里的内容清空,直接粘贴下面这套三位一体的纯净版配置:
bash
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
charset utf-8;
# ==========================================
# 1. 缓存加速池配置
# ==========================================
proxy_cache_path /usr/local/nginx/cache levels=1:2 keys_zone=my_cache:10m max_size=1g inactive=60m use_temp_path=off;
# ==========================================
# 2. 负载均衡集群配置 (把流量分给本机的 8081 和 8082 端口)
# ==========================================
upstream mock_tomcat_cluster {
server 127.0.0.1:8081 weight=1;
server 127.0.0.1:8082 weight=1;
}
# ==========================================
# 3. 前台门卫:监听 80 端口,负责调度和动静分离
# ==========================================
server {
listen 80;
server_name localhost;
# 【动静分离】:访问 /static/ 下的文件,Nginx 直接本地处理
location /static/ {
root /usr/local/nginx/html;
expires 1h;
}
# 【反向代理 + 负载均衡 + 缓存】:访问 /api/ 的请求,全部转发给伪装后厨
location /api/ {
proxy_pass http://mock_tomcat_cluster/;
# 缓存配置
proxy_cache my_cache;
proxy_cache_key $host$request_uri;
proxy_cache_valid 200 10m;
add_header X-Cache-Status $upstream_cache_status;
}
}
# ==========================================
# 4. 伪装后厨 1:监听 8081 端口
# ==========================================
server {
listen 8081;
location / {
root /usr/local/nginx/html/backend1;
}
}
# ==========================================
# 5. 伪装后厨 2:监听 8082 端口
# ==========================================
server {
listen 8082;
location / {
root /usr/local/nginx/html/backend2;
}
}
}第三步.测试重载
配置写好后,先创建缓存目录并重载:
bash
mkdir -p /usr/local/nginx/cache
/usr/local/nginx/sbin/nginx -t
systemctl reload nginx现在,我们在终端用 curl 充当浏览器,开始测试:
测试一:动静分离
我们去访问前台 (80端口) 的静态目录:
bash
curl http://172.25.254.10/static/logo.txt瞬间输出"我是纯静态文件...",这证明 Nginx 根本没把请求发给代理集群,直接从本地磁盘交货了

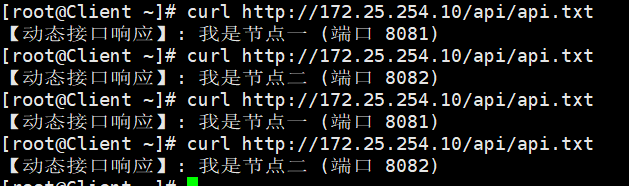
测试二:反向代理与负载均衡
现在我们去访问模拟的动态接口 /api/api.txt(注意,在这个测试前,我们先临时关掉缓存 ,否则你只能看到第一次的缓存结果,看不到负载均衡的轮询。你可以先把配置文件里的 proxy_cache my_cache; 注释掉并 reload 一下):
bash
curl http://172.25.254.10/api/api.txt明明访问的是 80 端口,但 Nginx 在背后无比公平地把请求交替扔给了 8081 和 8082,说明反向代理和负载均衡完美生效
测试三:缓存加速
现在,把刚才注释掉的 proxy_cache my_cache; 放开,重载 Nginx。 我们用带有 -I(查看响应头)的 curl 来测试:
第一次访问(打透代理,生成缓存):
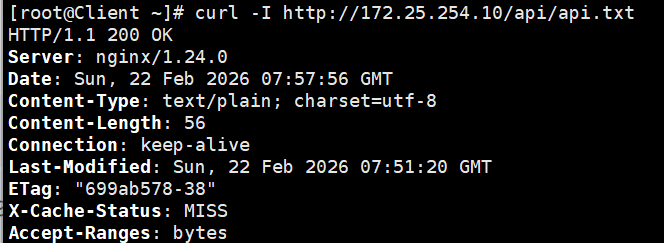
bash
curl -I http://172.25.254.10/api/api.txt注意看响应头: X-Cache-Status: MISS(未命中缓存,Nginx 去找后厨拿的数据)。
第二次访问(瞬间命中缓存):
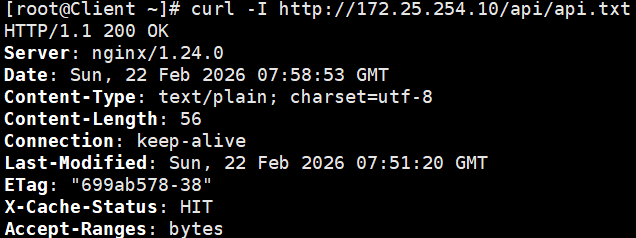
bash
curl -I http://172.25.254.10/api/api.txt注意看响应头: X-Cache-Status: HIT(命中缓存!后厨根本没动,Nginx 直接把刚存好的数据扔给你了)。由于缓存的存在,你在接下来的 10 分钟内,不管怎么刷新,看到的永远是同一个节点的返回内容,负载均衡"失效"了,因为请求被缓存层直接拦截了!
额外讲解:Nginx的负载均衡算法
由于Nginx中所采用的负载均衡算法与先前写过的LVS高度相似,这里不作具体演示,只做讲解
轮询 (Round Robin) ------ 【默认算法】
这是 Nginx 默认的统帅方式。顾名思义,就是**"排排坐,吃果果"**。
-
运行机制: Nginx 会把客户端的请求,按时间顺序逐一分配给后端的服务器。1号给A,2号给B,3号给C,4号又回到A......
-
适用场景: 后端集群中,所有服务器的硬件配置和性能完全一样。大家干活能力相同,绝对公平。
-
配置语法: (什么都不用写,默认就是它)
加权轮询 (Weight) ------ 【最符合企业现状】
在真实的企业机房里,机器往往是分批采购的。老机器可能只有 4 核 8G,新机器是 16 核 32G。如果还用普通轮询,老机器会被瞬间压垮,而新机器还在闲置。
-
运行机制: 给每一台服务器打上一个"权重值"。权重越高,被分配到的请求比例就越大。
-
适用场景: 后端服务器性能参差不齐的情况。能者多劳!
-
配置语法: 使用 weight 参数。
IP 哈希 (IP_Hash) ------ 【解决登录状态丢失的救星】
这是早期 Web 架构中解决 Session(会话)共享问题的最经典方案。 假设你登录了淘宝,Nginx 把你的登录请求发给了 A 服务器,A 记住了你。但你点开购物车时,普通的轮询算法把请求发给了 B 服务器,B 不认识你,直接让你重新登录!这体验极其崩溃。
-
运行机制: Nginx 会提取客户端的真实 IP 地址,算出一段 Hash 值,然后固定映射到某一台后端服务器。只要你的 IP 不变,你永远只会被分配到那一台固定的服务器上。
-
适用场景: 需要保持用户状态(Session 粘性),且系统没有引入 Redis 这种集中式缓存中间件的旧架构。
-
配置语法: 加入 ip_hash
;指令。
最少连接数 (Least Connections) ------ 【智能防拥堵】
前面的算法都有点"死脑筋",不关心后端机器现在的实际负载情况。如果某个请求是下载大文件,A 服务器卡了半天没处理完,轮询算法还是会继续往 A 服务器塞新请求。
-
运行机制: Nginx 就像一个绝顶聪明的交警,它实时监控后端的每一台机器。谁当前手里积压的"活跃连接数"最少,Nginx 就把新请求发给谁。
-
适用场景: 用户的请求处理时间长短不一的场景(比如有的接口秒回,有的接口需要做极其复杂的数据库运算)。
-
配置语法: 加入 least_conn
;指令。
十五、php源码编译并与Nginx整合
在开始Tomcat讲解之前,我们先额外了解一下php。
PHP 和 Java 不同。Java 是自己起一个 Tomcat 服务器监听端口;而 PHP 源码编译后,通常是通过 PHP-FPM(FastCGI 进程管理器) 作为一个独立的服务运行(默认监听 9000 端口),Nginx 则作为反向代理,把 .php 的请求通过 FastCGI 协议"扔"给 PHP-FPM 去解析。
1.安装编译依赖
源码编译 PHP 最容易卡在各种依赖库报错上(比如找不到 libxml、sqlite 等)。 在你的 Nginx 服务器(172.25.254.10)上,先用一条命令把这些底层 C/C++ 库全部打满:
bash
# 启用 CRB 仓库 (CentOS/RHEL 9 必须开启,否则有些开发包找不到)
dnf config-manager --set-enabled crb
# 安装 EPEL 扩展源
dnf install epel-release -y
# 安装 PHP 编译必备的终极依赖包
dnf install gcc gcc-c++ make cmake libxml2-devel sqlite-devel openssl-devel curl-devel libpng-devel libjpeg-devel freetype-devel oniguruma-devel -y如果以上代码你不能正常运行,说明你使用的是试用版的系统,改为运行下列代码:
bash
cat << 'EOF' > /etc/yum.repos.d/rocky9-aliyun.repo
[rocky9-baseos]
name=Rocky Linux 9 - BaseOS
baseurl=https://mirrors.aliyun.com/rockylinux/9/BaseOS/x86_64/os/
gpgcheck=0
enabled=1
[rocky9-appstream]
name=Rocky Linux 9 - AppStream
baseurl=https://mirrors.aliyun.com/rockylinux/9/AppStream/x86_64/os/
gpgcheck=0
enabled=1
[rocky9-crb]
name=Rocky Linux 9 - CRB
baseurl=https://mirrors.aliyun.com/rockylinux/9/CRB/x86_64/os/
gpgcheck=0
enabled=1
EOF
#它会自动帮你创建一个指向阿里云的 Rocky Linux 9 仓库配置文件(包含了 BaseOS、AppStream 以及我们苦苦寻找的 CRB 仓库)
bash
dnf clean all
dnf makecache
# 此时安装 EPEL 扩展源就毫无压力了
dnf install epel-release -y
#删除原系统冲突旧包
dnf swap openssl-fips-provider-so openssl-fips-provider -y
#安装编译环境依赖
dnf install gcc gcc-c++ make cmake libxml2-devel sqlite-devel openssl-devel curl-devel libpng-devel libjpeg-devel freetype-devel oniguruma-devel -y 2.下载并解压 PHP 8.3 源码包
我们先进入专门存放源码的目录,然后用 wget 把官方的 PHP 压缩包拉取下来:
bash
cd /usr/local/src
wget https://www.php.net/distributions/php-8.3.4.tar.gz
tar -zxvf php-8.3.4.tar.gz
cd php-8.3.43.执行 ./configure 环境监测与配置
这是整个编译过程中最核心、最长的一条命令。它会检查你的系统环境,并根据你传递的参数,定制化生成编译清单(Makefile)。
直接复制下面这一整块(注意最后的反斜杠 \ 代表换行,直接全部复制粘贴到终端回车即可):
bash
./configure \
--prefix=/usr/local/php \
--with-config-file-path=/usr/local/php/etc \
--enable-fpm \
--with-fpm-user=nginx \
--with-fpm-group=nginx \
--with-mysqli \
--with-pdo-mysql \
--with-openssl \
--with-zlib \
--with-curl \
--enable-mbstring核心参数解析:
-
--prefix:指定安装的绝对路径,以后想卸载 PHP,直接删这个文件夹就行,极其干净。 -
--enable-fpm:重中之重! 开启 FastCGI 进程管理器。没有它,Nginx 就无法和 PHP 通信。 -
--with-fpm-user/group=nginx:让 PHP-FPM 以nginx用户的身份运行,保证权限的统一和安全。 -
--with-mysqli/--with-pdo-mysql:为后面连接 MySQL 数据库提前打好驱动基础。
(敲下回车后,屏幕会疯狂滚动检查环境。只要最后没有出现 error 报错,并提示类似于 Thank you for using PHP. 的字样,就说明配置完美成功!)
4.开始编译与安装
bash
# -j2 代表调用 2 个 CPU 核心同时参与编译,能大幅缩短时间
make -j2
# 编译完成后,将程序写入到指定的安装目录
make install出现Build complete后,即可执行make install

5.与Nginx整合
1)配置并启动 PHP-FPM
在终端依次执行这些命令(确保你现在还在 /usr/local/src/php-8.3.4 这个源码目录下):
bash
# 1. 拷贝 PHP 核心配置文件 (决定了 PHP 的时区、内存限制等基本属性)
cp php.ini-production /usr/local/php/etc/php.ini
# 2. 拷贝 PHP-FPM 主配置文件 (决定了 FPM 的全局运行模式)
cp /usr/local/php/etc/php-fpm.conf.default /usr/local/php/etc/php-fpm.conf
# 3. 拷贝 PHP-FPM 进程池配置文件 (里面写明了监听 127.0.0.1:9000,以及运行用户是 nginx)
cp /usr/local/php/etc/php-fpm.d/www.conf.default /usr/local/php/etc/php-fpm.d/www.conf
# 4. 启动 PHP-FPM!
/usr/local/php/sbin/php-fpm使用netstat -tulnp | grep 9000查看是否成功运行

2)Nginx 网关配置
现在去改 Nginx 的配置,让它认识 PHP。
打开 Nginx 配置文件:vim /usr/local/nginx/conf/nginx.conf
找到你负责监听 80 端口的那个核心 server 块,做两处关键修改:
修改一:在默认首页里加上 index.php
bash
location / {
root html;
index index.php index.html index.htm; # 把 index.php 加在最前面
}修改二:加入 FastCGI 拦截规则(重点)
在上面的 location / 块下面,找个空行,原封不动地把这段配置贴进去:
bash
# 只要请求的文件名以 .php 结尾,就触发这个路由
location ~ \.php$ {
root html;
# 把请求通过 FastCGI 协议,转发给本机 9000 端口的大厨
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
# 【绝世天坑预警】:很多新手死在这里,导致报 File not found 错误!
# 这一行是告诉 PHP 你的网页文件在服务器磁盘上的绝对路径是什么
# 必须写成 $document_root$fastcgi_script_name
fastcgi_param SCRIPT_FILENAME /usr/share/nginx/html$fastcgi_script_name;
# 引入 Nginx 自带的 FastCGI 标准变量字典
include fastcgi_params;
}测试重载:
bash
/usr/local/nginx/sbin/nginx -t
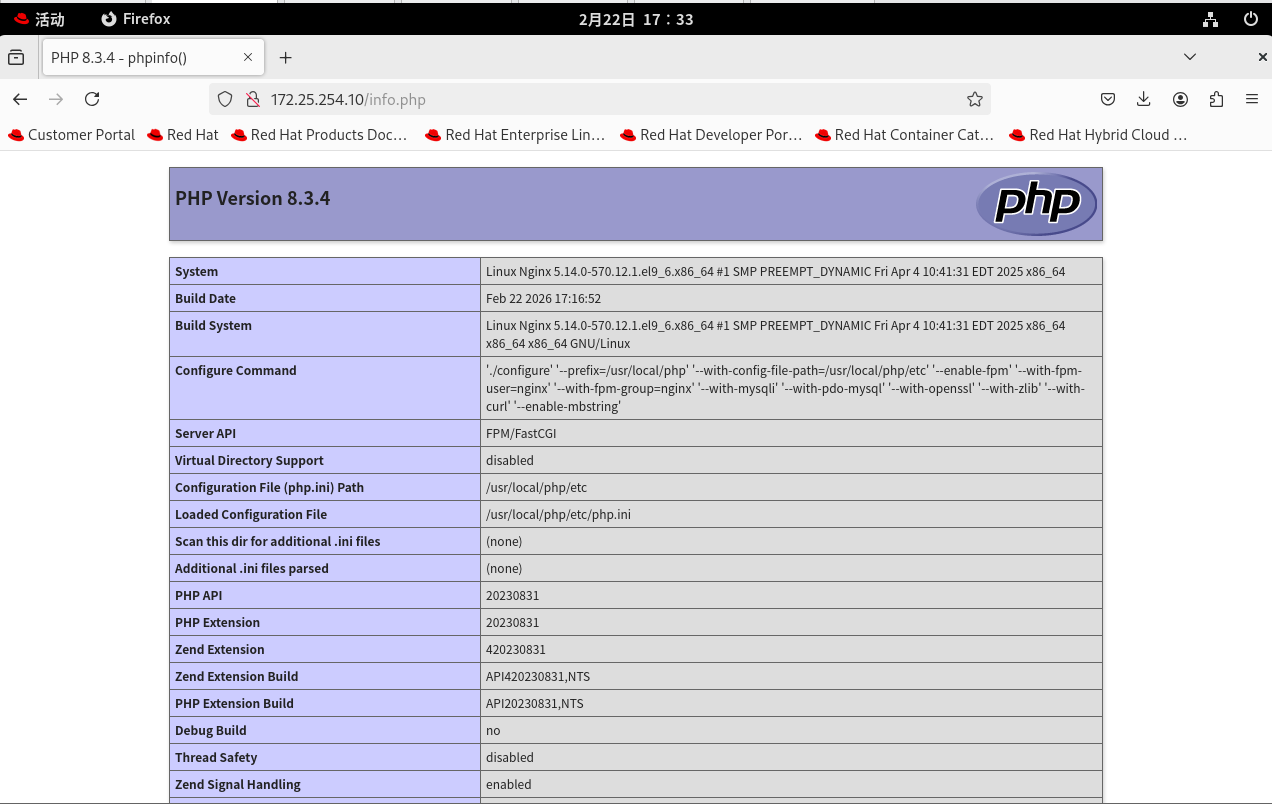
systemctl reload nginx3)写一个探针文件,进行测试:
bash
echo "<?php phpinfo(); ?>" > /usr/local/nginx/html/info.php进入测试机浏览器,输入:http://172.25.254.10/info.php
十六、利用Memcache加速
在开始实验之前,我们首先对Memcache进行简要介绍:
Memcached 是一款高性能的分布式内存对象缓存系统,通常用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站的访问速度。
在Web架构中,利用Memcache加速通常分为两个层次:
-
应用层加速(标准Memcache加速):
-
原理: 缓存逻辑由应用程序(如PHP、Java、Python)处理。当用户发起请求时,程序先查询Memcache中是否有缓存数据。如果有,直接返回;如果没有,程序再查询数据库(如MySQL),将结果返回给用户,并同时将数据写入Memcache以备后用。
-
优势: 极大地降低了数据库(MySQL)的读写压力。
-
瓶颈: 请求依然需要经过Web服务器(如Nginx)和解释器(如PHP-FPM)。
-
-
Web服务器层加速(Memcache前置加速):
-
原理: 将缓存的读取操作提前到Web服务器层(如Nginx)。Nginx直接与Memcached通信。当请求到达时,Nginx直接去Memcache里找数据,如果命中,直接由Nginx返回数据给客户端,完全不经过PHP等应用层。只有当缓存未命中时(返回404),Nginx才将请求转发给后端的PHP,PHP处理完后将页面结果写入Memcache。
-
优势: 绕过了应用层的解析和处理,极大减少了PHP-FPM的并发压力,响应速度达到极致(相当于直接吐静态页面)。
-
安装基础服务:
Apache Bench(压测工具,方便测试)
bash
dnf install httpd-tools -y实验一、 验证与压测:应用层加速 (PHP + Memcached)
在这种模式下,请求依然要穿透 Nginx 到达 PHP-FPM,只是 PHP 不再查询数据库,而是从 Memcache 拿数据。1.创建应用层加速测试文件 (app_cache.php)
1.准备工作:
编译Memcached PHP拓展(3.3.0):
bash
#定位你的编译工具路径,如与后续不同自行修改
find / -name "phpize" -type f -executable
find / -name "php-config" -type f -executable
bash
cd /usr/local/src
wget https://pecl.php.net/get/memcached-3.3.0.tgz
tar -zxvf memcached-3.3.0.tgz
cd memcached-3.3.0
#下载phpize依赖工具
dnf install autoconf automake libtool -y
# 1. 使用你的绝对路径执行 phpize (请替换为你刚才查到的路径)
/usr/local/php/bin/phpize
# 2. 配置编译参数,绑定你的 php-config (请替换为你刚才查到的路径)
./configure --with-php-config=/usr/local/php/bin/php-config --disable-memcached-sasl
# 3. 编译并安装
make && make install上面这个目录就是memcached.so所在位置,记下这行目录位置

修改Nginx配置文件:
bash
# 定义测试路径
location /test_frontend {
default_type text/html;
charset utf-8;
# 1. 告诉 Nginx 用什么作为 Key 去查找内存
set $memcached_key $uri;
# 2. 直接连接 Memcached 服务端 (仓库)
memcached_pass 127.0.0.1:11211;
# 3. 如果内存里没有这个 Key (返回 404),则丢给后端的 @fallback 处理
error_page 404 = @fallback;
}
# 当缓存未命中时的处理方案
location @fallback {
# 内部重定向到刚才写的 PHP 生成器
rewrite ^ /backend_gen.php last;
}找出 php.ini 配置文件路径:
bash
php --ini看输出里 Loaded Configuration File
:后面的路径
用vim编辑这个文件,在最后一行加上刚刚得到的memcached.so路径:
bash
extension=/usr/local/php/lib/php/extensions/no-debug-non-zts-20230831/
memcached.so下载编译Memcached 服务端(1.6.24):
bash
# 1. 回到源码存放目录
cd /usr/local/src
# 2. 下载 Memcached 服务端源码 (注意版本号和刚才那个 3.3.0 不同)
wget https://memcached.org/files/memcached-1.6.24.tar.gz
tar -zxvf memcached-1.6.24.tar.gz
cd memcached-1.6.24
# 3. 安装服务端必备的 libevent 依赖 (RHEL 9)
dnf install libevent-devel -y
# 4. 编译安装到指定目录
./configure --prefix=/usr/local/memcached
make && make install如果你使用的是上面源码编译的php,在此之前还需要进行一些设置,因为手动编译的php可能不会自动加载ini文件:
请复制整段执行(这会自动帮你找出 memcached.so 的绝对路径并强行加载):
bash
# 自动寻找编译好的 memcached.so
EXT_PATH=$(find /usr/local/php/lib/php/extensions -name "memcached.so" 2>/dev/null | head -n 1)
# 如果找到了,就强行加载并测试
if [ -n "$EXT_PATH" ]; then
echo "找到扩展库: $EXT_PATH"
/usr/local/php/bin/php -d extension=$EXT_PATH -r '$m = new Memcached(); echo "\n--- 扩展加载 绝对成功!---\n";'
else
echo "没找到 memcached.so,是不是刚才 make install 失败了?"
fi重启 PHP-FPM:
bash
killall php-fpm
# 这里替换成你实际启动 php-fpm 的绝对路径,通常在 sbin 目录下
/usr/local/php/sbin/php-fpm创建测试用网站:
bash
# 确保目录存在
mkdir -p /usr/share/nginx/html/
# 把我们测试用的 3 个文件统统写进去
echo '<?php echo "PHP is alive!"; ?>' > /usr/share/nginx/html/test_php.php
cat << 'EOF' > /usr/share/nginx/html/app_cache.php
<?php
$memcache = new Memcached();
$memcache->addServer('127.0.0.1', 11211) or die ("Could not connect");
$key = "user_data_123";
$data = $memcache->get($key);
if ($data) {
echo "<h1>Data from Memcached:</h1>";
echo $data;
} else {
echo "<h1>Data from Database (Simulated):</h1>";
$data = "This is a heavy database query result generated at: " . date('Y-m-d H:i:s');
$memcache->set($key, $data, 10);
echo $data;
}
?>
EOF
cat << 'EOF' > /usr/share/nginx/html/backend_gen.php
<?php
$memcache = new Memcached();
$memcache->addServer('127.0.0.1', 11211);
$key = $_SERVER['REQUEST_URI'];
$content = "<h2>This is Frontend Accelerated Page</h2>";
$content .= "<p>Generated by PHP at: " . date('Y-m-d H:i:s.u') . "</p>";
$memcache->set($key, $content, 15);
echo $content;
?>
EOF
# 给个权限防误杀
chmod 644 /usr/share/nginx/html/*.php2. 逻辑验证:
在终端连续执行两次 curl 命令:
bash
curl http://172.25.254.10/app_cache.php第一次看到 Data from Database...(因为刚超过 10 秒缓存失效了),第二次瞬间看到 Data from Memcached
:,且时间戳和第一次一模一样!这证明应用层缓存生效。

3.并发压测(获取性能基准):
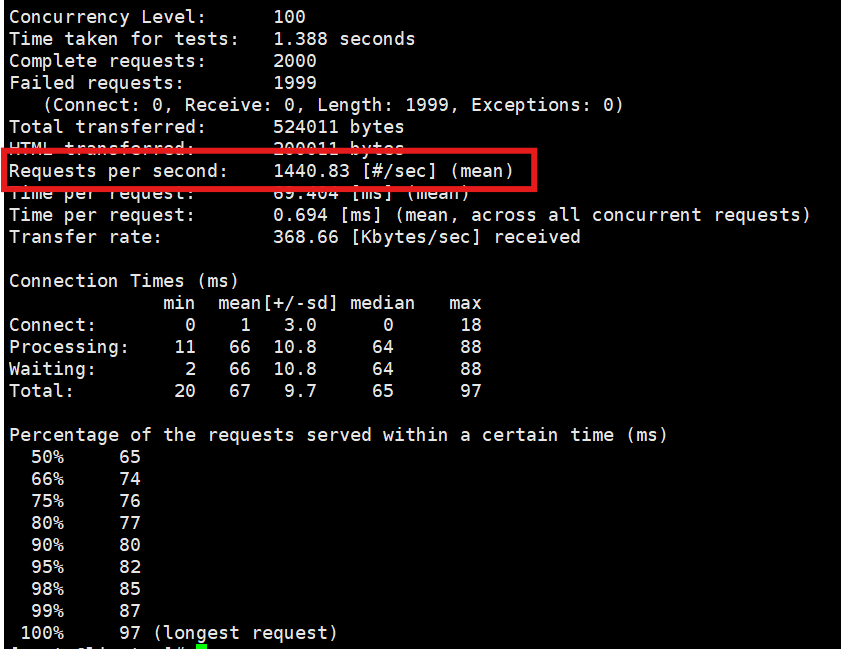
bash
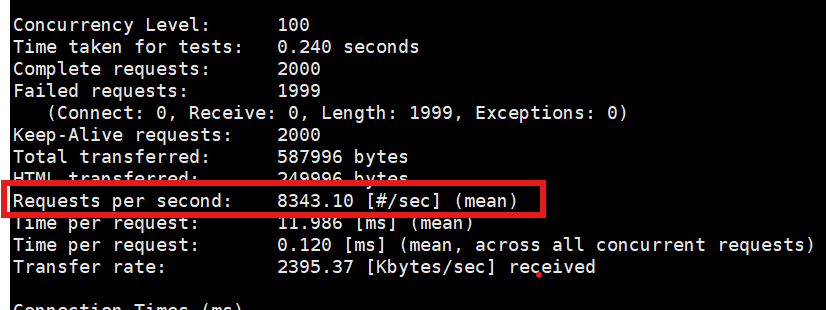
ab -n 2000 -c 100 http://172.25.254.10/app_cache.php跑完后,在输出结果中找到 Requests per second (每秒处理请求数,即 QPS)。记下这个数值
实验二:验证 Memcache 前置加速 (Nginx 直读 Memcached)
这是高并发架构中的"王炸"。请求到达 Nginx 后,Nginx 直接去 Memcached 内存里拿数据吐给 Client,后端的 PHP 甚至连请求都收不到。
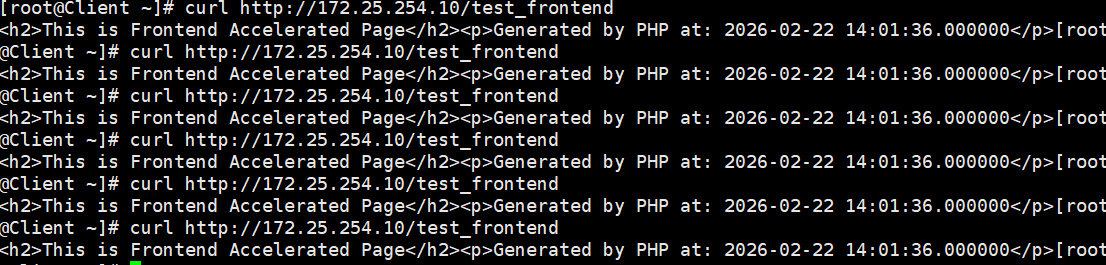
1. 逻辑验证(时间戳冻结)
连续执行两次请求测试前置加速接口:
bash
curl http://172.25.254.10/test_frontend预期现象: 你会看到带有毫秒级时间戳的页面输出。在 15 秒内反复执行,这个毫秒级的时间戳是绝对静止的。

2. 极限抗灾测试(拔掉后端网线) 为了证明 PHP 此时真的处于"休假"状态,请登录到 Nginx 服务器 (172.25.254.10),强行杀掉 PHP-FPM:
bash
pkill -9 php-fpm然后立刻回到 Client 端 再次执行:
bash
curl http://172.25.254.10/test_frontend预期现象: 依然秒回数据!即使后端动态语言彻底宕机,只要缓存没过期,Nginx 依然能挡住洪峰,过一段时间再去curl,发现缓存丢失,无法打开网页。(测试完后,记得在 Nginx 服务器上用 /usr/local/php/sbin/php-fpm把 PHP 救回来)

3. 并发压测
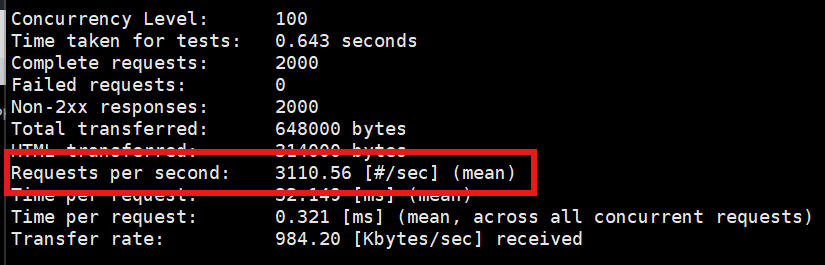
在Client端执行:
bash
ab -n 2000 -c 100 http://172.25.254.10/test_frontend再次查看 Requests per second
,数值明显提高,说明前置加速起作用了
十七、Nginx的四层负载
一、 核心知识点讲解:Nginx 的四层负载均衡
在构建高可用架构时,你可能已经非常熟悉处于系统内核态的 LVS(极高的转发性能),或者专门做多层代理的 HAProxy。其实,Nginx 从 1.9.0 版本开始,也正式加入了四层负载均衡的战场。
1. 什么是四层负载?
-
七层负载 (HTTP/HTTPS): 也就是 Nginx 最常用的功能。它工作在 OSI 模型的应用层,能够"拆开"数据包,看懂里面的 URL、Cookie、HTTP 请求头,然后根据这些信息决定把请求发给哪个后端。
-
四层负载 (TCP/UDP): 它工作在 OSI 模型的传输层。它完全不关心也不认识 数据包里面的具体内容(不管是 HTTP、MySQL 协议、SSH 还是 Redis)。它只看两样东西:IP 地址 和端口号。它就像一个纯粹的管道,直接把客户端和后端的 TCP/UDP 连接对接起来。
2. 为什么用 Nginx 做四层? 虽然极致的四层性能首推 LVS(DR/NAT 模式直接在内核层转发),但 Nginx 的四层负载有着极佳的易用性。如果你已经在使用 Nginx 处理 Web 流量,顺手用它的 stream 模块来代理一下后端的 MySQL、Redis、Memcached 或者是 SSH 端口,架构会非常统一,配置也极其简单。
二、 避坑指南:源码编译的"隐藏关卡"
我们的 Nginx 是全手工从源码编译的,这里有一个 100% 会踩的坑:Nginx 默认是不编译四层负载模块的!
Nginx 的四层负载依赖于 stream 模块。需要先检查一下你之前编译时有没有加上它。在 Nginx 服务器 (172.25.254.10) 上执行:
bash
/usr/local/nginx/sbin/nginx -V如果输出里没有--with-stream,进行下列操作:
bash
cd /usr/local/src/nginx-1.24.0
./configure --prefix=/usr/local/nginx ......#加上你原有的参数,并在最后补充:--with-stream
make
# 绝杀注意:只 make,千万别 make install!
# 然后把新编译出来的 nginx 二进制文件替换过去
mv -f /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old
cp ./objs/nginx /usr/local/nginx/sbin/
/usr/local/nginx/sbin/nginx -t
pkill -9 nginx
# 平滑重启
/usr/local/nginx/sbin/nginx再次检查,出现 --with-stream 模块

三、 实战配置:利用 Nginx 代理 TCP 流量
假设我们现在要用 Nginx (172.25.254.10) 做四层负载,代理后端的两个 MySQL 数据库或者我们刚刚建好的 Memcached 节点。这里以代理 Memcached (11211 端口) 为例,演示纯 TCP 转发。
打开你的 Nginx 主配置文件:
bash
vim /usr/local/nginx/conf/nginx.conf极其重要的一点: stream 模块和 http 模块是平级的!绝不能 把 stream 写在 http { ... } 里面。
bash
# 全局配置...
worker_processes 1;
# ----------------- 新增的四层负载配置 -----------------
stream {
# 1. 定义后端的服务器池 (Upstream)
upstream backend_memcached {
# 这里可以是其他的内网 IP,这里为了实验先用本机演示
server 127.0.0.1:11211 weight=1 max_fails=3 fail_timeout=30s;
# server 192.168.1.100:11211 weight=1; # 如果你有第二台机器可以加在这里
# 也可以配置负载均衡算法,比如 hash $remote_addr consistent;
}
# 2. 定义四层虚拟主机 (Server)
server {
# Nginx 监听一个新的端口,用来接收客户端的 TCP 请求
listen 11222;
# 将到达 11222 端口的纯 TCP 流量,无脑转发给上面的 backend_memcached 池
proxy_pass backend_memcached;
# 四层专属的一些超时设置
proxy_connect_timeout 5s;
proxy_timeout 10m;
}
}
# -----------------------------------------------------
# 下面是你原有的七层 Web 配置
http {
include mime.types;
default_type application/octet-stream;
# ... 你的其他配置
}保存退出后,测试配置并重载 Nginx:
bash
/usr/local/nginx/sbin/nginx -t
systemctl reload nginx四、 验证四层代理是否生效
现在,Nginx 已经化身为一个四层路由器,监听着 11222 端口。任何打到 11222 的请求,都会被完整地按字节流转发给底层的 Memcached (11211 端口)。
在你的 Client 端 ,我们用 telnet 或者 nc 来直接发起纯 TCP 请求测试(因为四层负载不区分 HTTP,浏览器测试就不合适了):
bash
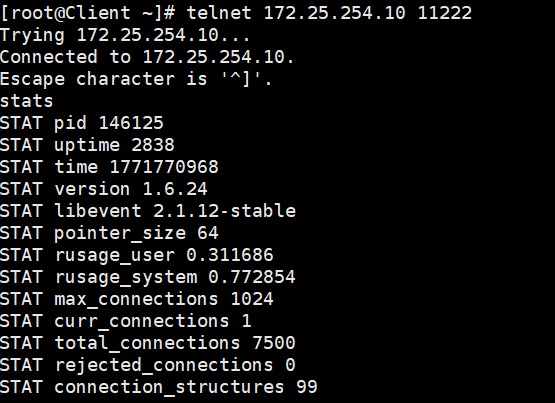
# 连接 Nginx 的四层代理端口
telnet 172.25.254.10 11222如果你看到屏幕上哗啦啦吐出一大堆 STAT pid ... 的 Memcached 状态信息,那么恭喜你,四层 TCP 负载均衡彻底打通了!
十八、openResty
如果说原生的 Nginx 是一把极其锋利的纯物理长刀,那么 OpenResty 就是一把自带智能锁定和附魔的激光剑。
结合刚才做的 Memcached 前置加速实验,我们来深入剖析一下 OpenResty 为什么是 Nginx 生态的"终极形态"。
一、 OpenResty 到底是个什么怪物?
简单来说,OpenResty = Nginx + LuaJIT(极速的 Lua 运行环境) + 大量高质量的 C/Lua 库。
它的核心缔造者是章亦春(章郎虫)。他做了一件极其疯狂且伟大的事情:把 Lua 语言的虚拟机,深深地嵌进了 Nginx 的核心工作进程(Worker)里。
这意味着什么?
-
过去(你刚才的实验): Nginx 虽然性能无敌,但它"太傻了"。它只能做简单的条件判断、静态文件代理。一旦涉及复杂的业务逻辑(比如查数据库、复杂的缓存判断),它就必须把请求通过 FastCGI 抛给 PHP-FPM。进程间的通信(Socket/TCP)本身就是巨大的性能损耗。
-
现在(OpenResty): 你可以直接在 Nginx 的
nginx.conf配置文件里写 Lua 代码!Nginx 自己就能执行复杂的业务逻辑,自己去连接 Redis、Memcached 甚至 MySQL。完全不需要后端的 PHP、Python 或 Java 参与。
二、 降维打击:用 OpenResty 重做你的缓存实验
回想一下你刚刚做的"Nginx 直读 Memcached"实验:
-
Nginx 尝试去 Memcached 拿数据。
-
拿不到(404),交给
@fallback。 -
转发给 PHP-FPM。
-
PHP 连接 Memcached 写入数据,再吐给浏览器。
如果用 OpenResty 来做,架构会变得极其简洁且暴力:
1.干掉原生Nginx:
bash
killall -9 nginx2.安装 OpenResty 的专属编译依赖:
bash
dnf install -y pcre-devel openssl-devel gcc curl zlib-devel readline-devel3.下载并编译 OpenResty 源码:
bash
cd /usr/local/src
wget https://openresty.org/download/openresty-1.25.3.1.tar.gz
tar -zxvf openresty-1.25.3.1.tar.gz
cd openresty-1.25.3.1
# 1. 配置编译参数(默认会安装到 /usr/local/openresty)
./configure
# 2. 编译并安装(这步因为要编译 LuaJIT,可能需要一两分钟,耐心等待)
make && make install4.修改配置:
我们直接打开它的配置文件,写下你的第一行基于 Nginx 内存运行的 Lua 代码
bash
vim /usr/local/openresty/nginx/conf/nginx.conf找到 server { ... } 块,把 location / { ... }替换成下面这样:
bash
server {
listen 80;
server_name localhost;
# 感受一下在 Nginx 里直接写代码的暴力美学
location / {
default_type text/html;
content_by_lua_block {
ngx.say("<h1>Hello, OpenResty!</h1>")
ngx.say("<p>这是由 Nginx 内置的 Lua 引擎直接生成的页面,没有任何 PHP 参与!</p>")
}
}
}5.验证结果:
保存退出后启动:
bash
/usr/local/openresty/nginx/sbin/nginx现在,马上切回你的 Client 端,在终端里敲下:
bash
curl http://172.25.254.10/
6.进阶实验:
在之前的实验中,Nginx 必须依赖后端的 PHP-FPM 来连接 Memcached 写入数据。而现在,Nginx(OpenResty)自己就是全栈! 它将直接用 Lua 语言去和 Memcached 对话,中间没有任何额外的进程开销。
请在你的 Nginx 服务器 (172.25.254.10) 上执行以下操作:
第一步:注入 Lua 缓存核心逻辑
打开 OpenResty 的配置文件:
bash
vim /usr/local/openresty/nginx/conf/nginx.conf在刚才那个 server { ... } 块里面,咱们新增一个强大的 location。把下面这段配置直接粘贴进去(可以放在刚才那个 / 的 location 下面):
注意:OpenResty的content中的注释为--而不是#
bash
# 自动匹配服务器的 CPU 核心数,满血输出
worker_processes auto;
events {
# 把单 Worker 的最大连接数放大
worker_connections 10240;
}
location /lua_cache {
default_type 'text/html';
charset utf-8;
content_by_lua_block {
-- 1. 引入 OpenResty 官方的高性能 memcached 库
local memcached = require "resty.memcached"
local memc, err = memcached:new()
if not memc then
ngx.say("<h2>实例化 Memcached 失败: ", err, "</h2>")
return
end
-- 2. 设置超时并直连你之前手工编译的 Memcached 仓库
memc:set_timeout(1000)
local ok, err = memc:connect("127.0.0.1", 11211)
if not ok then
ngx.say("<h2>连接 Memcached 失败 (仓库没开?): ", err, "</h2>")
return
end
local key = "openresty_key_1"
-- 3. 极速查询:尝试从内存中获取数据
local res, flags, err = memc:get(key)
if res then
-- 命中缓存:直接在 Nginx 内存中吐出数据,没有任何转发!
ngx.say("<h1>Data from Memcached (OpenResty 极速版):</h1>")
ngx.say("<p>", res, "</p>")
else
-- 未命中缓存:Nginx 自己模拟耗时的数据库查询,并存入缓存
ngx.say("<h1>Data from DB (OpenResty 模拟生成):</h1>")
local db_data = "这段高价值数据由 Lua 引擎生成于: " .. ngx.localtime()
ngx.say("<p>", db_data, "</p>")
-- 写入 Memcached,设置 10 秒过期
memc:set(key, db_data, 10)
end
-- 4. 极致优化:把用完的连接扔回连接池,供下一个高并发请求复用
memc:set_keepalive(10000, 100)
}
}第二步:重载 OpenResty 使魔法生效
bash
/usr/local/openresty/nginx/sbin/nginx -t
/usr/local/openresty/nginx/sbin/nginx -s reload第三步:见证真正的"全栈 Nginx"
现在,请回到你的 Client 端,像之前一样连续执行两次请求:
bash
# 第一次:触发 Lua 脚本生成数据并存入 Memcached
curl http://172.25.254.10/lua_cache
echo ""
# 第二次:直接从 Memcached 内存中极速读取
curl http://172.25.254.10/lua_cache可以逻辑和之前完全一样(第一次是 Database,第二次是 Memcached),但底层架构已经发生了天翻地覆的变化! 你的服务器上,PHP-FPM 现在连一丁点 CPU 都没有消耗。
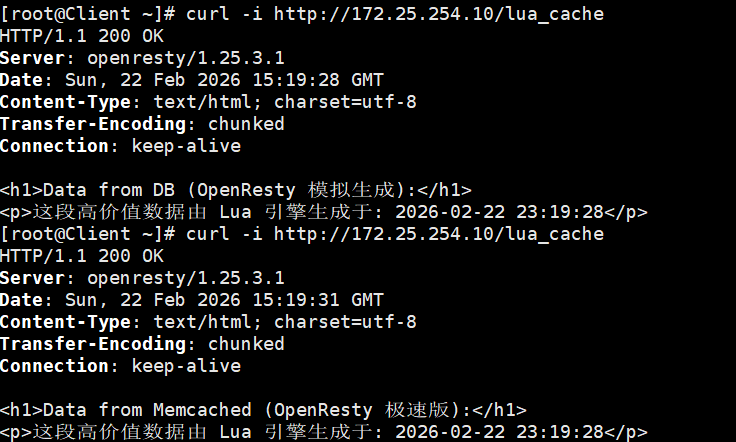
接下来我们将进行验证:
bash
ab -n 2000 -c 100 http://172.25.254.10/lua_cache得到的QPS远高于之前的php架构
十九、Tomcat部署
架构升级:为什么我们需要 Nginx + Tomcat?
在真实的企业生产环境中,Tomcat 虽然处理 Java 代码天下第一,但它处理静态文件(图片、CSS、JS)和抗并发的能力远不如 Nginx。
所以,经典的架构玩法叫做 "动静分离" (Dynamic/Static Separation) 和 "反向代理" (Reverse Proxy):
-
Nginx(或者你刚装的 OpenResty)作为前台接待: 霸占 80 端口,扛住所有并发连接。遇到静态文件自己直接光速秒回。
-
Tomcat 作为后台车间: 藏在 8080 端口。Nginx 一旦发现用户请求的是动态 Java 页面(比如
.jsp或者 Java API),就把请求"往后抛"给 Tomcat,Tomcat 算完后把结果给 Nginx,Nginx 再转交给用户。
安装Tomcat:
第一步:安装 Java 运行环境 (JDK)
bash
dnf install java-17-openjdk java-17-openjdk-devel -y安装完成后,你可以输入 java -version 确认一下,只要输出了 openjdk 17 的字样,引擎就装好了。

第二步:下载并解压 Tomcat
我们去 Apache 官方的归档库下载非常主流的 Tomcat 9,并把它安顿到系统的 /usr/local/ 目录下:
bash
# 1. 进入存放源码包的目录
cd /usr/local/src
# 2. 下载 Tomcat 9 的二进制压缩包 (使用官方归档链接,确保不会 404)
wget https://archive.apache.org/dist/tomcat/tomcat-9/v9.0.87/bin/apache-tomcat-9.0.87.tar.gz
# 3. 解压并移动到最终的工作目录,顺便改个清爽的名字
tar -zxvf apache-tomcat-9.0.87.tar.gz
mv apache-tomcat-9.0.87 /usr/local/tomcat第三步:启动 Tomcat
Tomcat 的所有控制脚本都在 bin 目录下,不需要 make,直接运行启动脚本即可:
bash
/usr/local/tomcat/bin/startup.sh正常情况下,屏幕上会闪过几行环境变量,最后一行显示 Tomcat started.

第四步:验证端口是否存活
bash
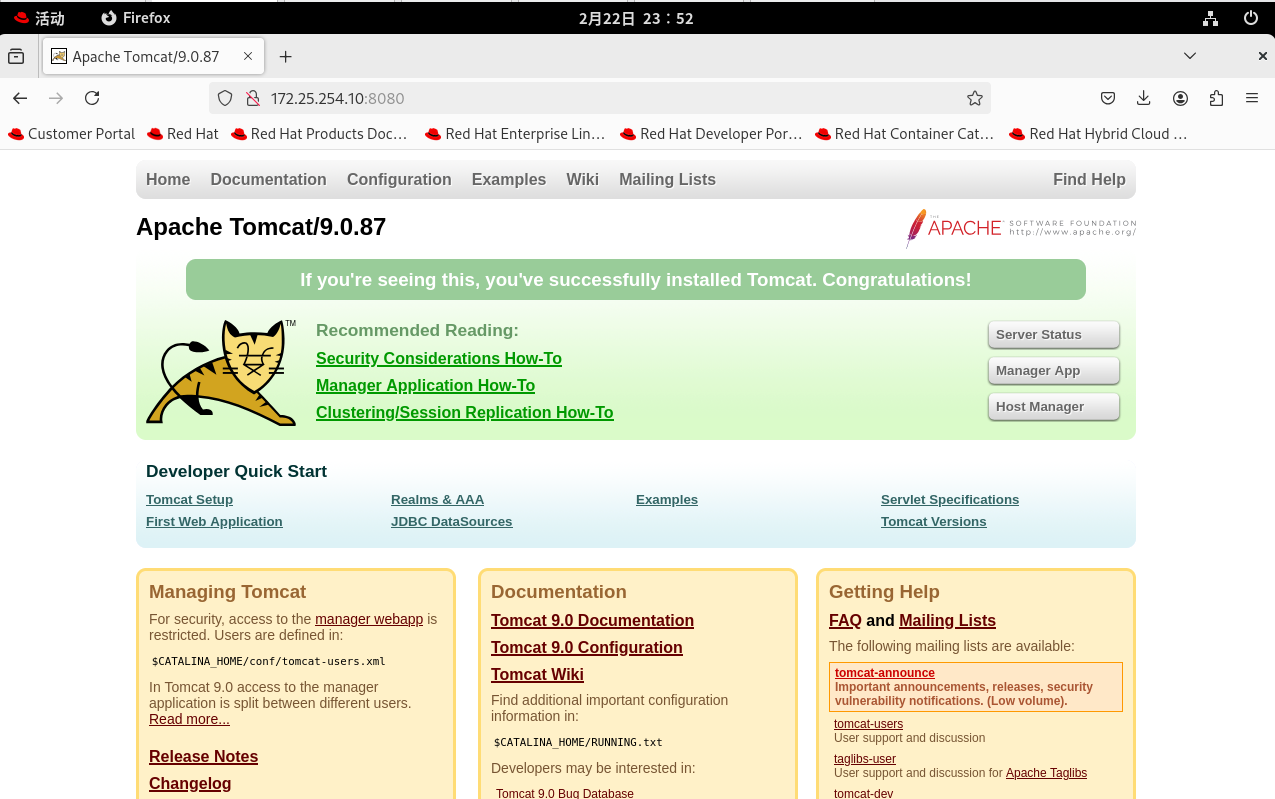
ss -tulnp | grep 8080如果看到
8080端口处于LISTEN状态,那么这台 Java 服务器就已经在后台静静地运转了。
进入浏览器,成功看到tomcat界面

进阶实验:
还记得前面做过的"动静分离"和 Nginx 反向代理吗,在安装Tomcat后,我们可以利用其对这两个实验进行不一样的写法。
第一步:在 Tomcat 里写个带"动态时间"的页面
bash
cat << 'EOF' > /usr/local/tomcat/webapps/ROOT/test.jsp
<%@ page contentType="text/html;charset=UTF-8" %>
<html>
<head><title>Nginx + Tomcat 动静分离测试</title></head>
<body style="text-align:center; margin-top: 50px;">
<h1 style="color: #0056b3;">太强了!请求已成功穿透 Nginx,到达 Tomcat 内部!</h1>
<h2>当前 Tomcat 处理的动态时间是: <span style="color: red;"><%= new java.util.Date() %></span> </h2>
</body>
</html>
EOF第二步:配置 OpenResty 开启反向代理
现在,我们要教 OpenResty 怎么把 .jsp 结尾的请求转发给 Tomcat。 打开你现在的主力配置文件:
bash
vim /usr/local/openresty/nginx/conf/nginx.conf在 server { ... } 块里面(可以放在你之前写的 /lua_cache 的下面),加入这段配置:
bash
# 只要请求的 URL 是以 .jsp 结尾的,全都不自己处理,交给 Tomcat
location ~ \.jsp$ {
# 1. 代理到本地的 Tomcat 8080 端口
proxy_pass http://127.0.0.1:8080;
# 2. 把客户端真实的 IP 和域名带给 Tomcat,防止 Tomcat 以为是 Nginx 在访问它
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}完成后测试并重载
bash
/usr/local/openresty/nginx/sbin/nginx -t
/usr/local/openresty/nginx/sbin/nginx -s reload第三步:见证架构打通!
回到Client端,在浏览器中输入
bash
http://172.25.254.10/test.jsp
我们访问的是 80 端口 (OpenResty),没有加 8080
如果你在输出结果里看到了红色的 Java 动态时间,这就证明 Nginx 成功把请求转发到了后方的 Tomcat,并将结果返回给了你!

二十、session会话保持优化
当你只有一台 Tomcat 时,用户登录状态存放在这台 Tomcat 的内存里,一切安好。但如果你有两台或更多 Tomcat(比如 8080 和 8081),Nginx 默认会采用**轮询(Round Robin)**的方式把请求均匀分发。
灾难场景: 用户在 Tomcat A 上登录成功,Session 存在 A 的内存里。用户刷新了一下页面,Nginx 把这第二次请求发给了 Tomcat B。Tomcat B 的内存里根本没有这个用户的 Session,于是......用户被迫下线,重新登录。
为了解决这个问题并做到极致优化,业界通常有以下三个段位的玩法。
青铜段位:Nginx 原生 ip_hash (源地址哈希)
这是最快、最简单的"土办法"。它的逻辑是:Nginx 对客户端的 IP 地址进行哈希计算。只要你是同一个 IP 来的请求,Nginx 就死死地把你绑定(Sticky)在同一台 Tomcat 上。
-
优点: 配置极简,零成本。
-
致命缺点(为什么需要进一步优化): 如果一个公司的几百号人通过同一个公网出口 IP 访问你的网站,Nginx 会把这几百人全部分发给同一台 Tomcat,导致负载严重失衡。而且,如果 Tomcat A 宕机,绑定在 A 上的用户 Session 依然会全部丢失。
白银段位:Nginx Sticky Cookie 模块
不认 IP,而是认 Cookie。Nginx 在用户第一次访问时,给用户浏览器植入一个特殊的 Cookie(比如叫 route=tomcat_A)。下次用户再来,Nginx 看到这个 Cookie,就把他准确送回 Tomcat A。
-
优点: 完美解决了
ip_hash带来的负载不均问题(即使几百人共用一个 IP,他们的浏览器 Cookie 也是不同的)。 -
缺点: 开源版 Nginx 默认不带此模块,需要重新编译加入第三方模块(如
nginx-sticky-module)。同样,如果 Tomcat 宕机,Session 依然会丢失。
王者段位:Redis 集中式 Session 共享(业界标配)
这是目前所有大厂都在用的终极优化方案。彻底抛弃 Nginx 层面的会话绑定,Nginx 直接无脑轮询(Round Robin)追求最高吞吐量。
核心逻辑: Tomcat 不再把 Session 存在自己的本地内存里,而是全部存进后端的 Redis 内存数据库中。
-
用户请求打到 Tomcat A,Tomcat A 产生 Session,存入 Redis。
-
用户再次请求被 Nginx 轮询打到了 Tomcat B。
-
Tomcat B 去本地内存找,没找到,于是去 Redis 里一查,发现了该用户的 Session,完美接力!
- 优点: 1. 真正的无状态: Tomcat 变成了完全无状态的计算节点,随时可以横向扩容加机器。 2. 高可用(抗灾): 就算 Tomcat A 物理机烧了,用户的登录状态依然安稳地躺在 Redis 里,Tomcat B 接管时用户毫无感知!
实验一:ip哈希
第一步:克隆出第二台 Tomcat (Tomcat 2)
我们不需要重新下载,直接把现有的 Tomcat 复制一份,并修改它的核心端口,防止和第一台(8080)冲突。
bash
# 1. 完整复制 Tomcat 目录
cp -r /usr/local/tomcat /usr/local/tomcat2
# 2. 一键修改 Tomcat2 的端口 (8005改为8006, 8080改为8081, 8009改为8010)
sed -i 's/port="8005"/port="8006"/g' /usr/local/tomcat2/conf/server.xml
sed -i 's/port="8080"/port="8081"/g' /usr/local/tomcat2/conf/server.xml
sed -i 's/port="8009"/port="8010"/g' /usr/local/tomcat2/conf/server.xml第二步:编写"会话追踪"测试页
为了能肉眼分辨出当前是哪台 Tomcat 在提供服务,并且观察 Session ID 是否发生了变化,我们分别给两台 Tomcat 写入专属的测试页。
写入 Tomcat 1 (8080) 的测试页:
bash
cat << 'EOF' > /usr/local/tomcat/webapps/ROOT/session.jsp
<%@ page contentType="text/html;charset=UTF-8" session="true" %>
<html>
<body style="text-align:center; margin-top: 50px; background-color: #f0f8ff;">
<h1>我是 <span style="color: blue;">Tomcat 1 (端口 8080)</span></h1>
<h2>当前 Session ID: <span style="color: red;"><%= session.getId() %></span></h2>
</body>
</html>
EOF写入 Tomcat 2 (8081) 的测试页:
bash
cat << 'EOF' > /usr/local/tomcat2/webapps/ROOT/session.jsp
<%@ page contentType="text/html;charset=UTF-8" session="true" %>
<html>
<body style="text-align:center; margin-top: 50px; background-color: #fff0f5;">
<h1>我是 <span style="color: green;">Tomcat 2 (端口 8081)</span></h1>
<h2>当前 Session ID: <span style="color: red;"><%= session.getId() %></span></h2>
</body>
</html>
EOF第三步:启动 Tomcat 2
bash
/usr/local/tomcat2/bin/startup.sh
第四步:配置 Nginx 负载均衡(先不加会话保持)
为了制造"Session 丢失"的灾难现场,我们先用最基础的轮询策略。打开 OpenResty 的配置文件:
bash
vim /usr/local/openresty/nginx/conf/nginx.conf在 http { ... } 块的顶层(注意别写进 server 里面),定义集群:
bash
upstream my_tomcat_cluster {
# 暂时不写 ip_hash,让它默认轮询
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}在你的 server { ... } 块中,修改.jsp 的反向代理指向集群:
bash
location ~ \.jsp$ {
# 把原本写死的 127.0.0.1:8080 换成刚刚定义的集群名字
proxy_pass http://my_tomcat_cluster;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}保存并重载:
bash
/usr/local/openresty/nginx/sbin/nginx -t
/usr/local/openresty/nginx/sbin/nginx -s reload第五步:见证灾难与修复
现在,请在你的 Client 端 使用浏览器 (强烈建议用浏览器,因为 curl 默认不保存 Cookie,无法模拟真实用户的 Session)访问:
http://172.25.254.10/session.jsp
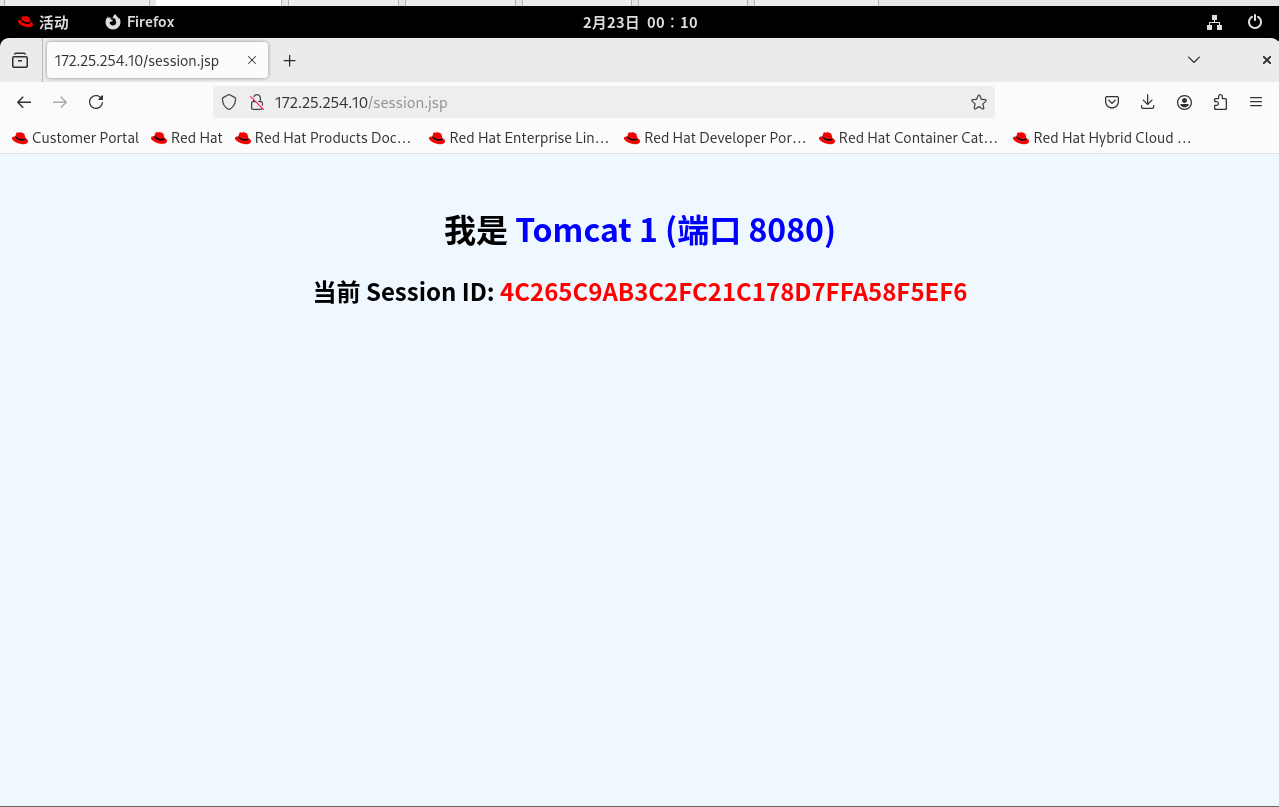
1. 灾难现场(轮询): 疯狂按 F5 刷新页面。你会发现页面在蓝色 (Tomcat 1) 和绿色 (Tomcat 2) 之间疯狂横跳。更致命的是:每次横跳,红色的 Session ID 都在变! 这就意味着,如果这是一个登录系统,用户每点一个按钮就会被强迫重新登录一次。
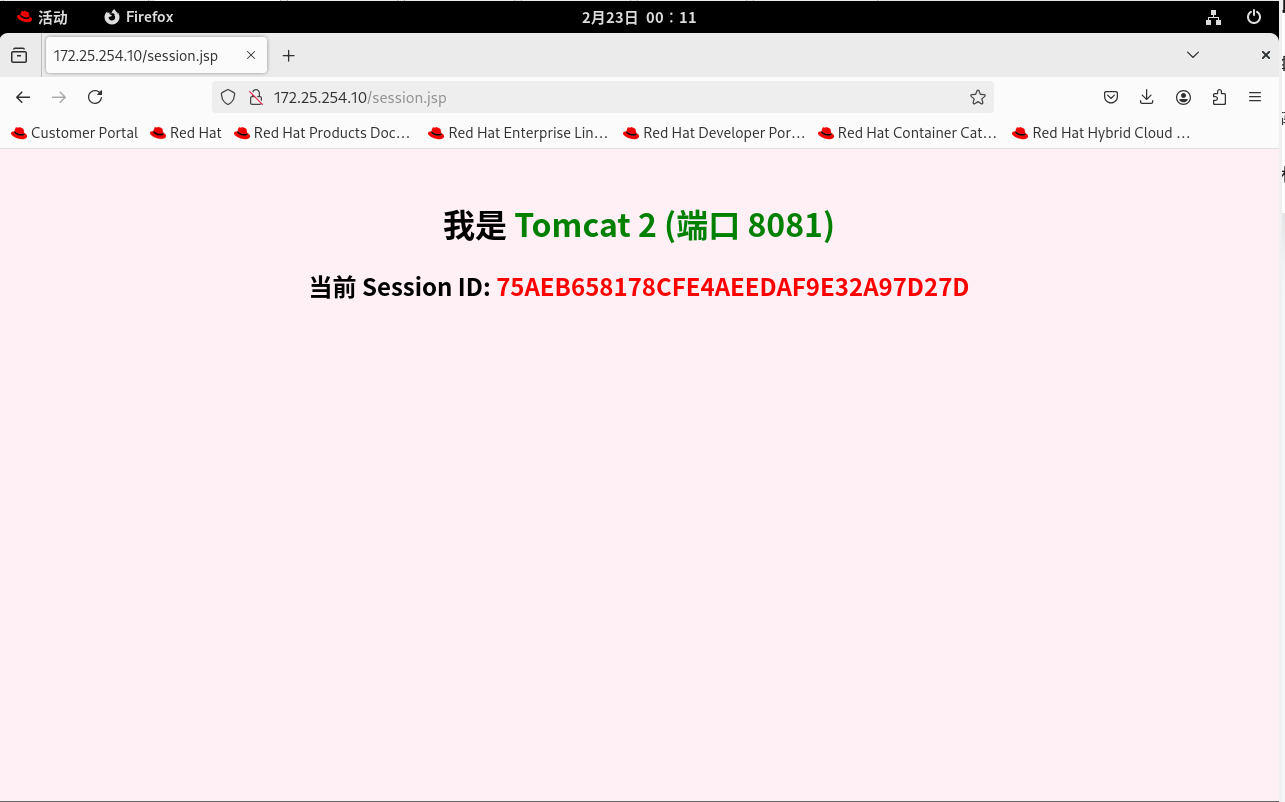
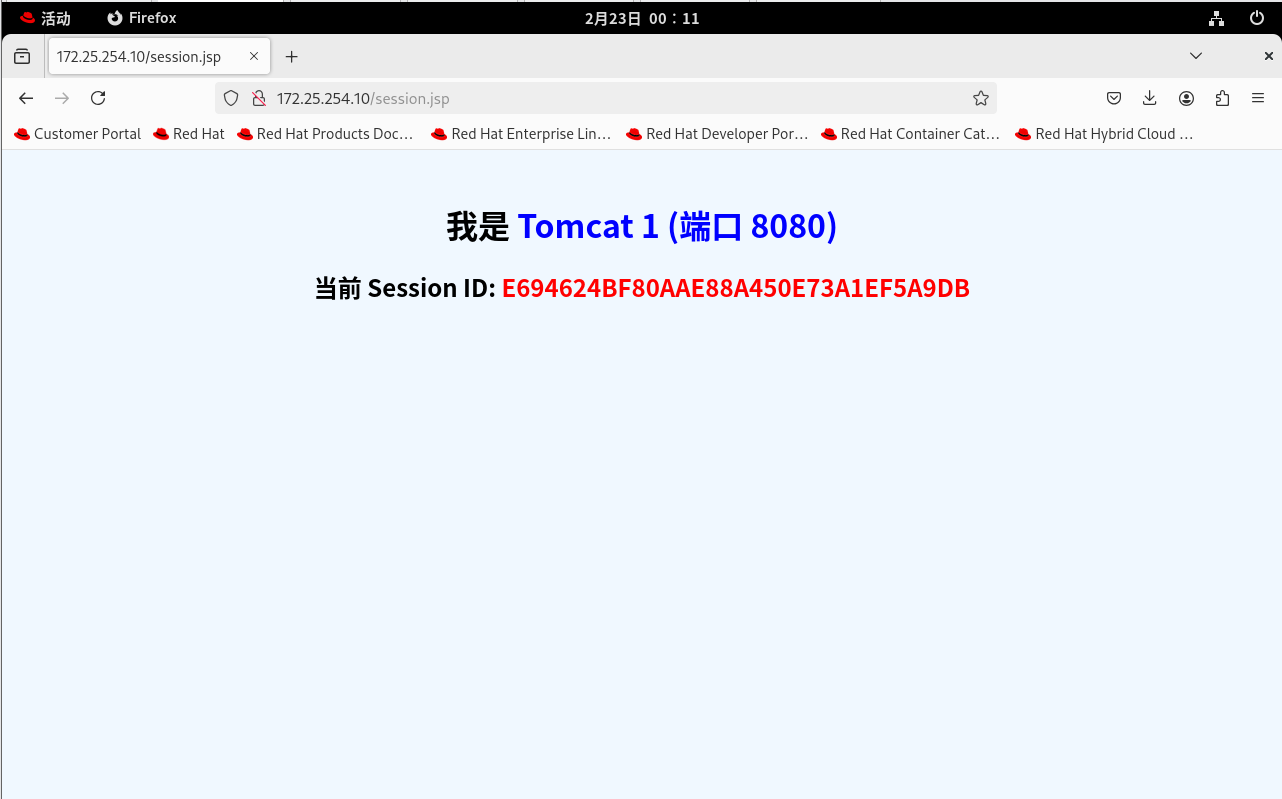
2. 实施修复(青铜段位优化): 回到 Nginx 服务器,再次打开配置文件,在 upstream 里面加上那句咒语:
bash
upstream my_tomcat_cluster {
ip_hash; # 加上这一行开启源地址绑定
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}重载 Nginx (nginx -s reload)。
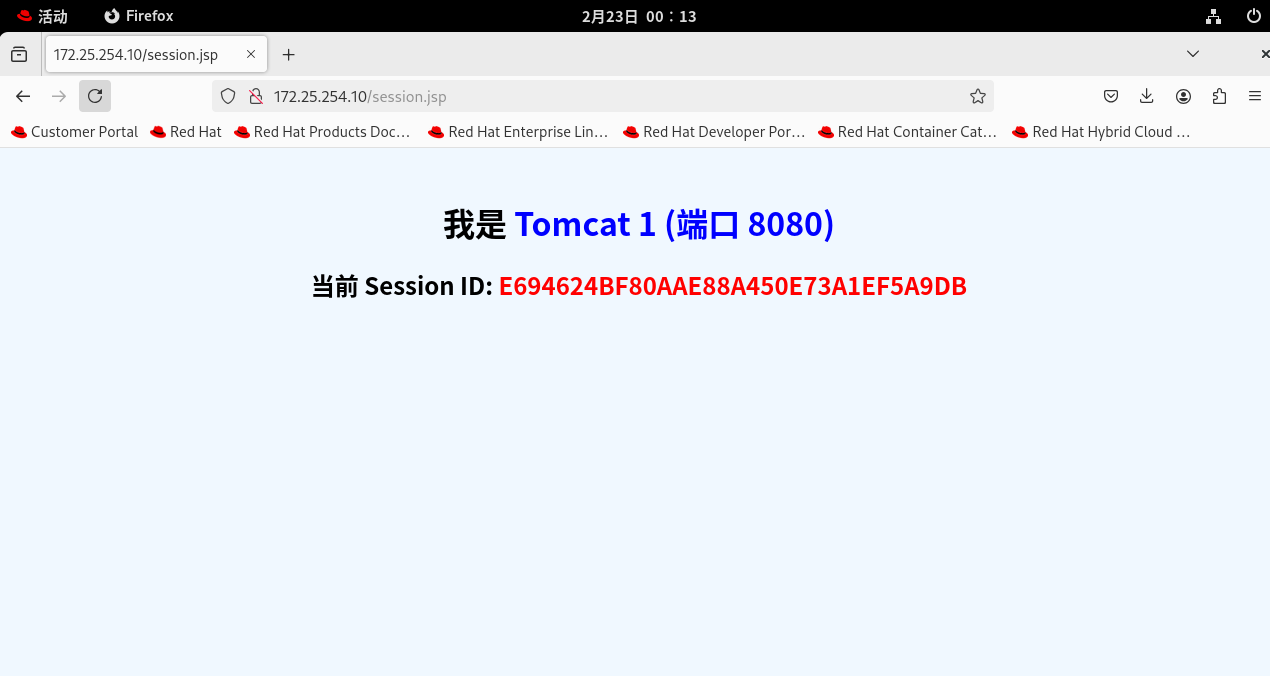
3. 见证奇迹:
回到浏览器,再次疯狂按 F5 刷新。你会发现:无论你怎么刷新,页面都死死地钉在某一个 Tomcat 上,而且 Session ID 彻底冻结,不再变化了!
实验二:Nginx Sticky Cookie
第一步:修改 Nginx 集群配置
打开你的 OpenResty 配置文件:
bash
vim /usr/local/openresty/nginx/conf/nginx.conf找到之前定义的 upstream 块,把 ip_hash 换成针对 Tomcat Cookie 的哈希策略:
bash
upstream my_tomcat_cluster {
# 1. 注释掉或删掉之前的 ip_hash
# ip_hash;
# 2. 开启基于 Tomcat JSESSIONID 的一致性哈希
hash $cookie_JSESSIONID consistent;
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}
(注:consistent 参数表示开启一致性哈希算法。这样即使你未来加了第三台 Tomcat,也只会影响一小部分用户的路由,不会导致全局 Session 大面积失效。)保存并重载:
bash
/usr/local/openresty/nginx/sbin/nginx -t
/usr/local/openresty/nginx/sbin/nginx -s reload第二步:见证"认 Cookie 不认 IP"的奇迹
为了证明这次它真的不再依赖 IP 了,我们需要用到浏览器的**"隐私模式"** 或"多开浏览器"来测试(因为你的电脑只有一个 IP,如果只用一个浏览器,看不出它和 ip_hash 的区别)。
请在你的 Client 端 按以下方式测试:
1. 浏览器 A 测试(模拟用户 A): 打开 Chrome,访问 http://172.25.254.10/session.jsp。 疯狂按 F5 刷新。你会发现它死死地钉在某一台 Tomcat 上(比如一直是绿色的 Tomcat 2),且 Session ID 绝对不变。
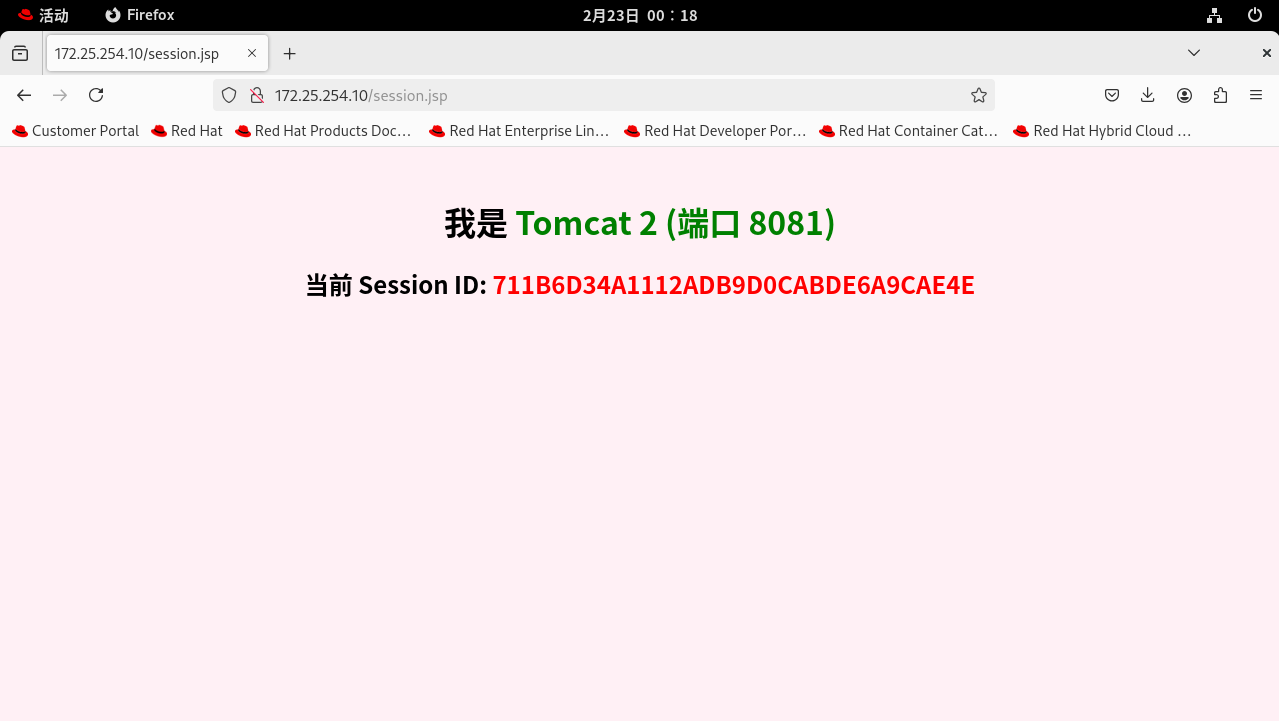
2. 浏览器 B 测试(模拟同 IP 下的用户 B): 不要关掉刚才的浏览器。新打开一个 Edge 浏览器(或者浏览器的无痕/隐私模式),同样访问 http://172.25.254.10/session.jsp。 这个时候,你会惊喜地发现:
-
这个新窗口大概率被分配到了蓝色的 Tomcat 1!
-
在这个新窗口里疯狂按
F5,它也死死地钉在 Tomcat 1 上,Session ID 也绝对不变。
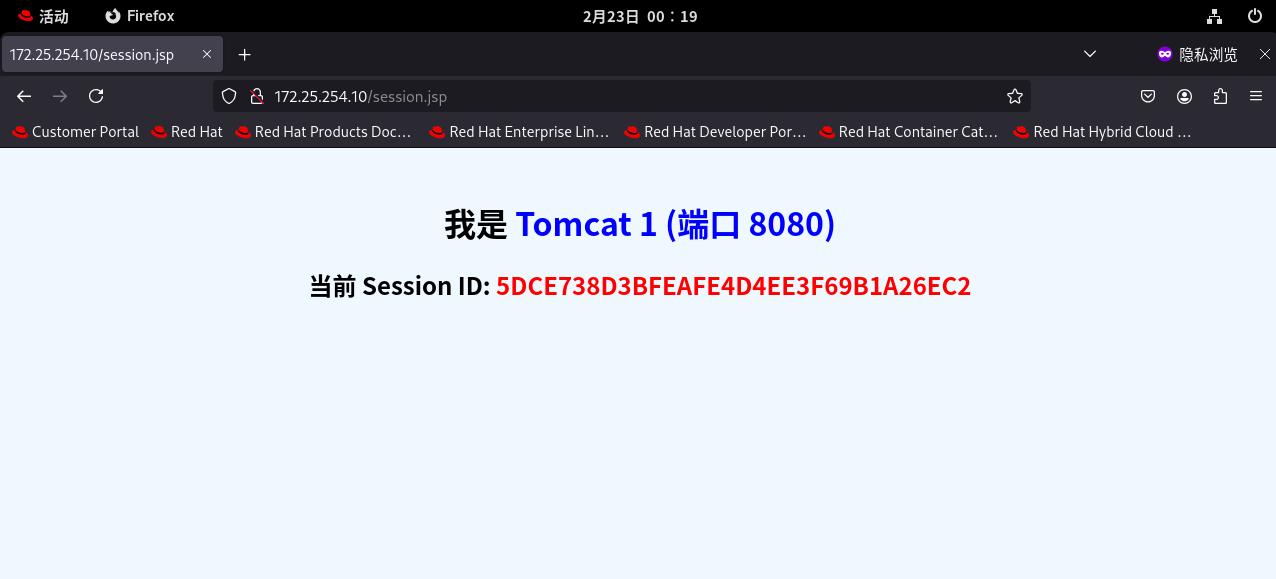
得出结论: 你的 Nginx 成功实现了在同一个源 IP 下,通过识别不同浏览器的 JSESSIONID Cookie,将请求精准分发并"黏住"在不同的后端节点上。负载均衡的颗粒度从"粗犷的 IP 级"精确到了"细腻的用户级"
当你把这个实验做成功时,你可能会发现一个极其微小的"Bug": 在第一次打开页面时,可能会发生一次极其短暂的"跳跃",然后才彻底稳定下来。
为什么会这样? 因为用户第一次 请求时,浏览器里还没有 JSESSIONID。Nginx 对一个空的 Cookie 做了哈希,把它分配给了 Tomcat A。Tomcat A 生成了 Session ID 返回给浏览器。 第二次请求时,浏览器带上了这个 Session ID。Nginx 对这串具体的字母数字做哈希,算出来的结果可能指向了 Tomcat B!于是请求跳到了 B,B 没找到 Session,重新生成了一个新的 Session ID 再次返回。从第三次开始,哈希值彻底稳定,再也不跳了。
这就是所有基于负载均衡层的 Session 保持技术(无论是 ip_hash 还是 Cookie Hash)共同面临的终极痛点:只要节点发生宕机或扩容,或者哈希计算出现偏差,用户的登录状态就会面临断裂的风险。
这也是为什么大厂最终都走向了"王者段位"------彻底抛弃在 Nginx 层做会话黏滞,把 Session 统一交由后端的内存数据库(Redis)来掌管。
实验三:引入 Redis 实现集中式 Session 共享
王者架构逻辑: 我们废弃 Nginx 层的 Cookie 绑定,让 Nginx 恢复最纯粹、最高效的无脑轮询(Round Robin)。同时,我们给 Tomcat 装上一个"外挂(Redisson)",让这两台 Tomcat 都不再把 Session 存在自己的本地内存里,而是统一存到后端的 Redis 数据库中。
这样一来,无论 Nginx 把请求扔给 Tomcat 1 还是 Tomcat 2,它们都会去同一个 Redis 里读取用户的 Session。真正的无状态、绝对的高可用。
第一步:安装并启动 Redis 数据库
bash
# 1. 安装 Redis
dnf install redis -y
# 2. 启动并设置开机自启
systemctl enable --now redis
# 3. 确认 6379 端口已开启
ss -tulnp | grep 6379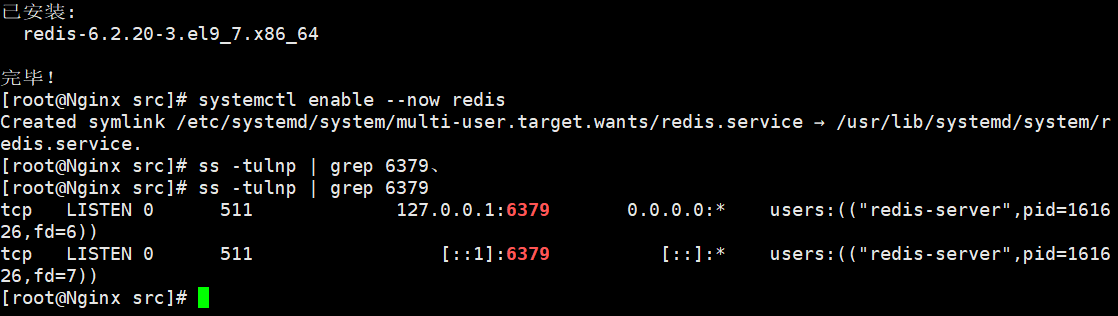
第二步:给 Tomcat 装备"Redisson 外挂"
Tomcat 原生不支持直连 Redis,我们需要借助鼎鼎大名的 Redisson 组件。把相关的 jar 包下载并放入两台 Tomcat 的库目录中:
bash
# 1. 进入下载目录
cd /usr/local/src
# 2. 下载 Redisson 核心包和 Tomcat9 适配包 (直接从 Maven 中央仓库拉取)
wget https://repo1.maven.org/maven2/org/redisson/redisson-all/3.29.0/redisson-all-3.29.0.jar
wget https://repo1.maven.org/maven2/org/redisson/redisson-tomcat-9/3.29.0/redisson-tomcat-9-3.29.0.jar
# 3. 把这两个外挂包分别拷贝到两台 Tomcat 的 lib 目录下
cp redisson-*.jar /usr/local/tomcat/lib/
cp redisson-*.jar /usr/local/tomcat2/lib/第三步:配置 Tomcat 连接 Redis
我们需要告诉 Tomcat 怎么连 Redis,以及接管 Session。
创建 Redis 连接配置文件:
bash
# 生成 Tomcat 1 的配置
cat << 'EOF' > /usr/local/tomcat/conf/redisson.yaml
singleServerConfig:
address: "redis://127.0.0.1:6379"
EOF
# 直接拷给 Tomcat 2 一份
cp /usr/local/tomcat/conf/redisson.yaml /usr/local/tomcat2/conf/注入全局 Context 配置(接管 Session):
bash
# 修改 Tomcat 1
sed -i 's|</Context>| <Manager className="org.redisson.tomcat.RedissonSessionManager" configPath="${catalina.base}/conf/redisson.yaml" />\n</Context>|g' /usr/local/tomcat/conf/context.xml
# 修改 Tomcat 2
sed -i 's|</Context>| <Manager className="org.redisson.tomcat.RedissonSessionManager" configPath="${catalina.base}/conf/redisson.yaml" />\n</Context>|g' /usr/local/tomcat2/conf/context.xml重启两台 Tomcat 使外挂生效:
bash
/usr/local/tomcat/bin/shutdown.sh
/usr/local/tomcat2/bin/shutdown.sh
/usr/local/tomcat/bin/startup.sh
/usr/local/tomcat2/bin/startup.sh第四步:解放 Nginx (回归轮询)
既然 Session 已经交给 Redis 统一管理了,Nginx 就不需要再辛辛苦苦做 Cookie 绑定了。
打开 OpenResty 配置文件:
bash
vim /usr/local/openresty/nginx/conf/nginx.conf找到 my_tomcat_cluster,删掉或者注释掉 hash $cookie_JSESSIONID consistent; 这一行,让它回归最纯粹的上下平分轮询:
bash
upstream my_tomcat_cluster {
# 删掉 hash 这一行,彻底解放 Nginx
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}保存并重载:
bash
/usr/local/openresty/nginx/sbin/nginx -s reload第五步:见证大厂级高可用架构的诞生
现在,你的架构已经完全蜕变。请回到 Client 端 的浏览器,访问 http://172.25.254.10/session.jsp。
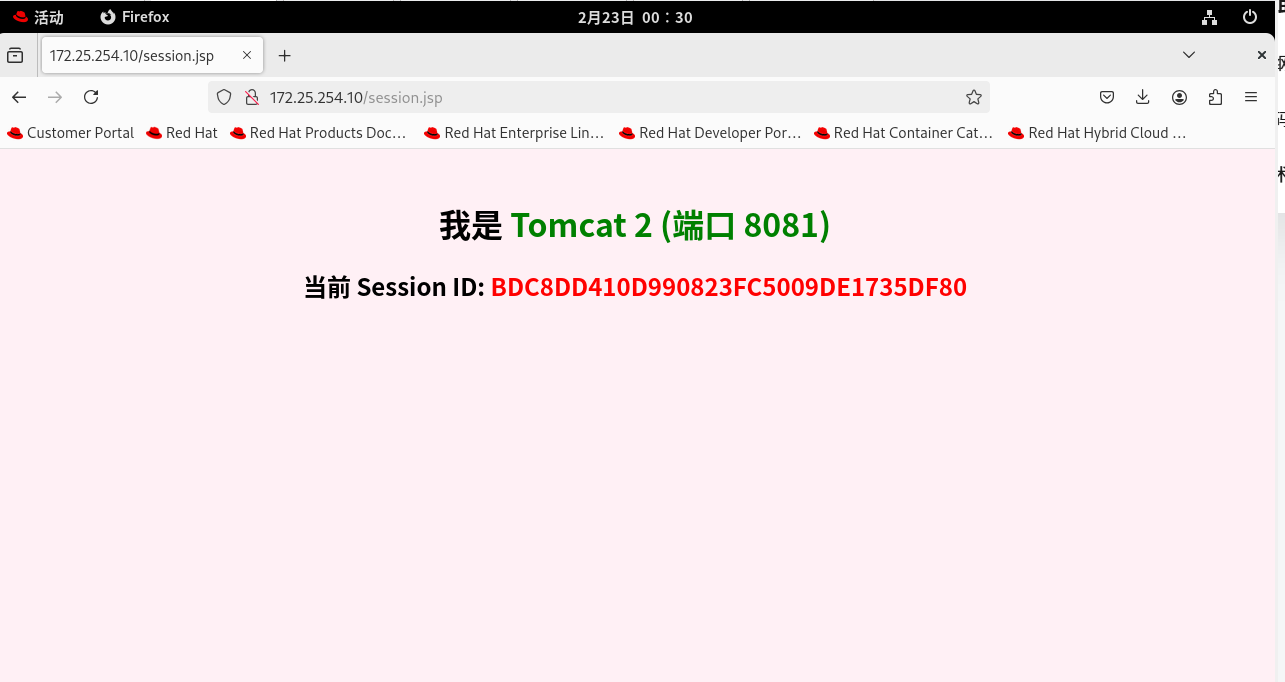
测试: 疯狂按 F5 刷新页面! 你会看到一个无比极其神奇且极度舒适的现象: 文字在蓝色 (Tomcat 1) 和 绿色 (Tomcat 2) 之间疯狂交替闪烁,证明请求被 Nginx 均匀地打到了两台机器上。但是!下面红色的 Session ID 稳如泰山,连一个字母都不带变的!
这说明 Tomcat 1 和 Tomcat 2 现在就像是没有记忆的打工人,它们每次收到请求,都会乖乖去后台同一个 Redis 老板那里取你的 Session 档案。
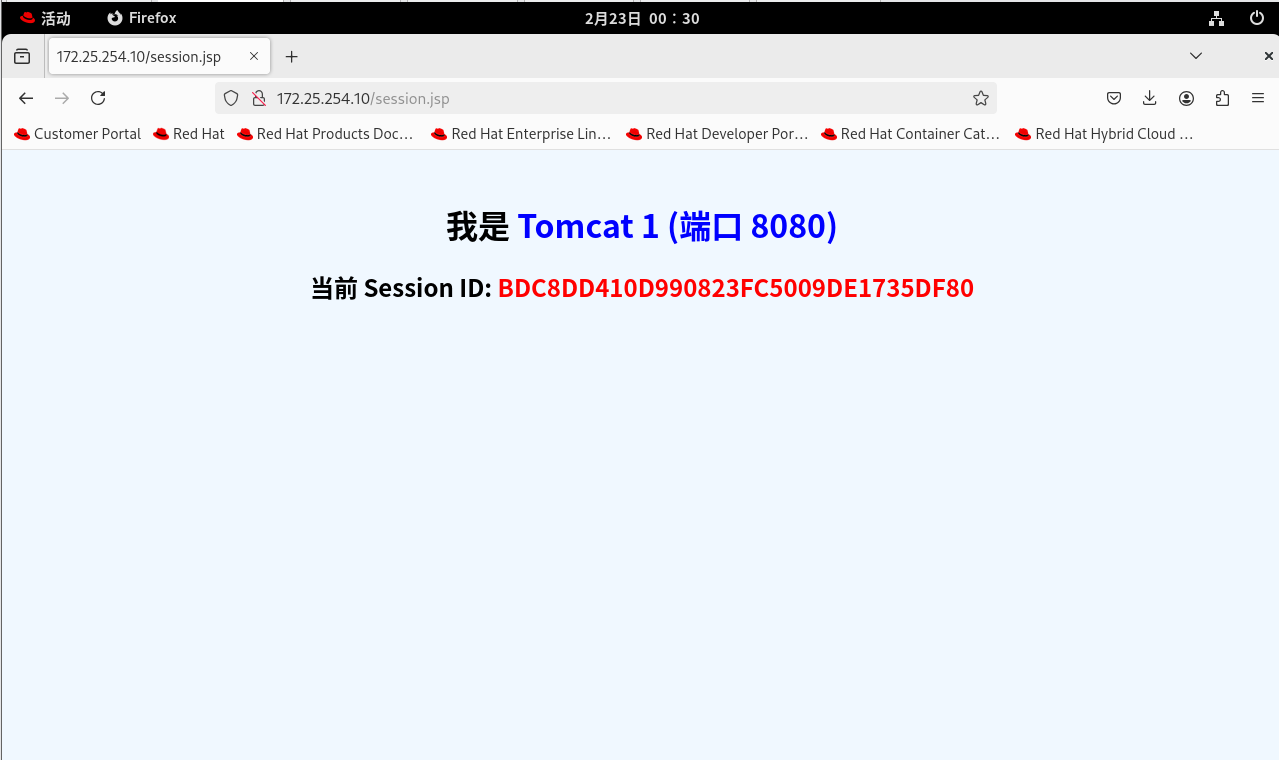
结语:
至此,我们的 Nginx 探索之旅终于画上了一个圆满的句号。
回望这整整二十个核心章节,我们从最原始的 C 语言源码编译起步,一步步为其编写脚本、平滑升级、极限调优;我们摸透了 Location 的匹配规则,跨越了七层与四层代理的界限,玩转了复杂的 Rewrite 重写与 HTTPS 全站加密。
随后,我们的版图不断扩张:整合 PHP 解释器、挂载 Memcached 内存加速、手握 OpenResty 激光剑直连缓存,最终更是成功构建了 Tomcat 双节点集群,并彻底攻克了高可用架构的终极难关------分布式 Session 会话保持。
这不仅是一份枯燥的配置文档,而是一套从零成长为高级架构师的实战推演。这一路走来,坑多且深,但每一次 500 Internal Server Error 或端口冲突的报错,最终都化作了掌控底层流量的底气。
技术之路永无止境,但有了这套坚如磐石的底层架构基石,无论未来面对多凶猛的洪峰流量,相信我们都能从容应对。江湖路远,我们下一个架构专栏再见!