本篇技术博文摘要 🌟
- 文章开篇回顾了构建稳定、高效的TensorFlow生产环境 所需的基础设施与依赖管理。核心部分深入探讨了模型优化 的三大关键技术:"量化" 以降低精度换取效率、"剪枝" 移除冗余参数、"知识蒸馏" 用大模型指导小模型,旨在缩小模型体积、提升推理速度。
- 随后,文章详述了部署架构 的选择,对比了不同服务模式并介绍了微服务架构的优势。
- 在性能优化章节,重点讲解了利用GPU/TPU 进行硬件加速的配置技巧与计算图优化 策略。为确保系统稳健运行,文章阐述了涵盖系统与模型两方面的关键监控指标 及A/B测试流程。
- 此外,文章强调了安全考虑 ,包括模型保护与输入验证。最后,文章介绍了持续集成与交付 在机器学习领域的实践,涉及ML Pipeline设计 与模型版本控制策略,形成从开发到上线的闭环。
引言 📘
- 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。
- 我是盛透侧视攻城狮,一个"什么都会一丢丢"的网络安全工程师,目前正全力转向AI大模型安全开发新战场。作为活跃于各大技术社区的探索者与布道者,期待与大家交流碰撞,一起应对智能时代的安全挑战和机遇潮流。

上节回顾
目录
[本篇技术博文摘要 🌟](#本篇技术博文摘要 🌟)
[引言 📘](#引言 📘)
[1.TensorFlow 生产环境](#1.TensorFlow 生产环境)
[7.1ML Pipeline设计](#7.1ML Pipeline设计)

1.TensorFlow 生产环境
TensorFlow 作为业界领先的机器学习框架,在从实验环境迁移到生产环境时需要考虑诸多因素。
本文将全面介绍 TensorFlow 在生产环境中的关键考虑点,帮助开发者构建稳定、高效的机器学习系统。

2.模型优化
2.1模型量化
python
# 训练后量化示例
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
- 8位整数量化:减少75%模型大小,提升3-4倍推理速度
- 16位浮点量化:GPU上性能提升,精度损失较小
- 动态范围量化:仅量化权重,推理时激活保持浮点

2.2模型剪枝
python
# 使用TensorFlow Model Optimization Toolkit进行剪枝
pruning_params = {
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(
initial_sparsity=0.50,
final_sparsity=0.90,
begin_step=0,
end_step=end_step)
}
model_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(
original_model, **pruning_params)
- 移除对输出影响小的神经元连接
- 典型可减少60%参数而不显著影响精度
- 需要微调以恢复部分精度损失

2.3模型蒸馏流程图
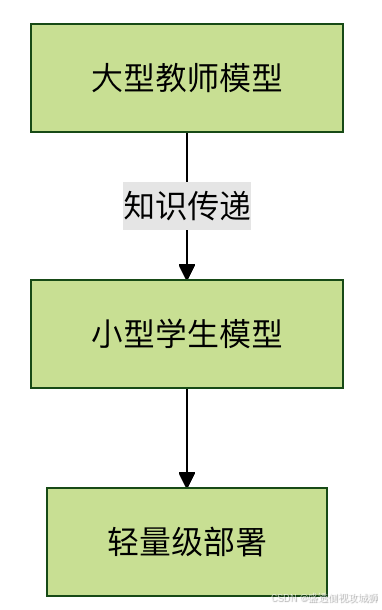
- 使用大型模型指导小型模型训练
- 保持 90% 以上精度同时减少 90% 参数量
- 特别适合边缘设备部署场景

3.部署架构
3.1服务模式对比
| 部署方式 | 延迟 | 吞吐量 | 资源使用 | 适用场景 |
|---|---|---|---|---|
| TensorFlow Serving | 中 | 高 | 中 | 云服务、高并发 |
| TFLite | 低 | 中 | 低 | 移动/IoT设备 |
| ONNX Runtime | 中 | 高 | 中 | 多框架统一部署 |
| 自定义gRPC服务 | 可调 | 可调 | 可调 | 特殊需求场景 |

3.2微服务架构
python
# 使用Flask构建的简单模型服务
from flask import Flask, request
import tensorflow as tf
app = Flask(__name__)
model = tf.keras.models.load_model('path/to/model')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json['data']
prediction = model.predict(data)
return {'prediction': prediction.tolist()}
- 容器化:推荐使用Docker打包模型和环境
- 服务发现:结合Kubernetes实现自动扩缩容
- 监控集成:Prometheus + Grafana监控体系

4.性能优化
4.1硬件加速
4.1.1GPU优化技巧
- 使用
tf.config.optimizer.set_jit(True)启用XLA编译- 批量处理输入数据(典型批量大小32-256)
- 使用混合精度训练(
tf.keras.mixed_precision)

4.1.2TPU配置
python
resolver = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.TPUStrategy(resolver)4.2图优化
python
# 会话配置优化
config = tf.compat.v1.ConfigProto()
config.graph_options.optimizer_options.global_jit_level = tf.compat.v1.OptimizerOptions.ON_1
config.gpu_options.allow_growth = True
session = tf.compat.v1.Session(config=config)
- 常量折叠
- 操作融合
- 死代码消除
- 内存优化

5.监控与维护
5.1关键监控指标
5.1.1系统指标
- GPU/CPU利用率
- 内存使用量
- 请求延迟(P50/P90/P99)
5.1.2模型指标
- 预测置信度分布
- 输入数据分布偏移
- 模型衰减指标
5.2A/B测试框架流程图
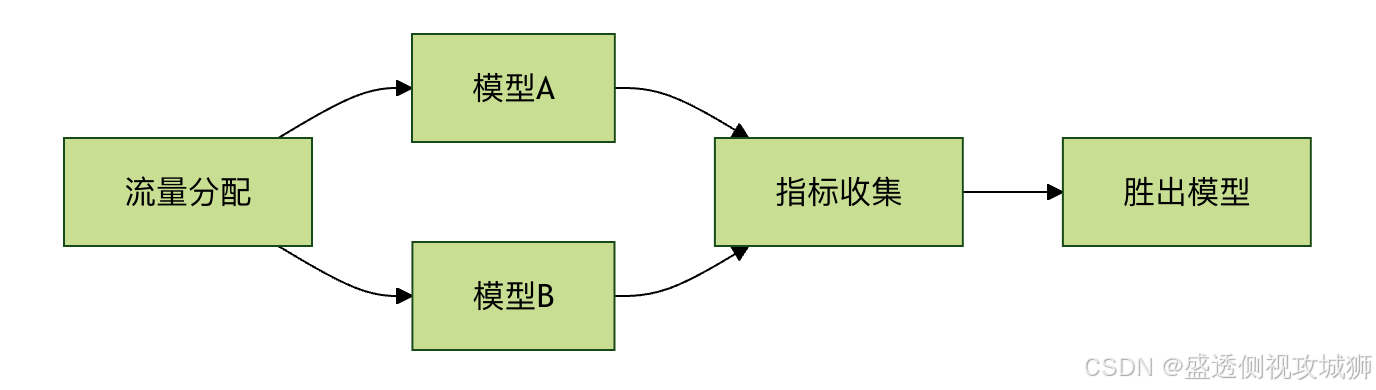
- 逐步流量切换(5% → 50% → 100%)
- 多维度指标对比(业务指标+技术指标)
- 自动回滚机制

6.安全考虑
6.1模型保护
- 使用
tf.saved_model.save加密模型- 实现模型水印技术
- 定期轮换部署密钥
6.2输入验证
python
# 输入数据验证示例
def validate_input(input_data):
if not isinstance(input_data, np.ndarray):
raise ValueError("Input must be numpy array")
if input_data.shape != EXPECTED_SHAPE:
raise ValueError(f"Shape must be {EXPECTED_SHAPE}")
if np.isnan(input_data).any():
raise ValueError("Input contains NaN values")
- 数据类型检查
- 数值范围验证
- 异常输入过滤
7.持续集成与交付
7.1ML Pipeline设计
python
# 使用TFX构建的简单pipeline
from tfx.components import Trainer
from tfx.proto import trainer_pb2
trainer = Trainer(
module_file=module_file,
transformed_examples=transform.outputs['transformed_examples'],
schema=infer_schema.outputs['schema'],
train_args=trainer_pb2.TrainArgs(num_steps=10000),
eval_args=trainer_pb2.EvalArgs(num_steps=5000))
- 自动化模型训练
- 自动化模型评估
- 自动化模型部署
7.2版本控制策略
- 模型版本与代码版本绑定
- 数据快照保存
- 完整的实验记录
欢迎各位彦祖与热巴畅游本人专栏与技术博客
你的三连是我最大的动力
点击➡️指向的专栏名即可闪现
➡️计算机组成原理****
➡️操作系统
➡️****渗透终极之红队攻击行动********
➡️ 动画可视化数据结构与算法
➡️ 永恒之心蓝队联纵合横防御
➡️****华为高级网络工程师********
➡️****华为高级防火墙防御集成部署********
➡️ 未授权访问漏洞横向渗透利用
➡️****逆向软件破解工程********
➡️****MYSQL REDIS 进阶实操********
➡️****红帽高级工程师
➡️红帽系统管理员********
➡️****HVV 全国各地面试题汇总********
