1、大模型种类
大模型工程师必须会的模型:
|-------------|-----------------------------------|--------------------------------------------------------------|
| 大模型的种类 | 特点 | 常用大模型 |
| 通用语音模型 | 通用能力强,文本推理,文本生成,深度思考等 | DeepSeek, Qwen3, kimi-k2, MiniMax-M2,GPT-4.5, Claude 3系列, 等等 |
| 多模态模型 | 多模态支持(文本/图像/音频/视频),跨媒体理解能力强 | GPT-4o, Qwen3-VL, Qwen3-Omni, GLM-4.5V等 |
| 文本嵌入模型 | 将文本转换成计算机能理解的数值向量,对文本进行降维处理。 | BGE系列(small, base, large),OpenAI Embedding, Qwen3-Embedding等 |
| 多模态嵌入模型 | 将文本、图像、音频、视频等不同模态的数据向量化,同一个向量空间中。 | GME-Qwen3-VL, openai-CLIP, Chinese-CLIP等 |
| 多模态解析模型 | 负责解析复杂结构的数据 | DeepSeek-OCR,Dolphin, Dots.OCR, MonkeyOCR, Unstructured等等 |
| 垂直领域大模型 | 专注于某一个领域的复杂问题,如蛋白质结构预测 | DeepMind-AlphaFold, 360安全大模型,讯飞星火4.0(医疗)等等 |
各种国内外的大模型Token购买:建议:不要买多 ,不要超过60元。
|-----------|---------------------------------------------------------------------------------------------------------------------------------------|-------------------|
| 名字 | 建议购买的地址 | 特点 |
| 百炼平台 | https://bailian.console.aliyun.com/ | 国内的模型很全面 |
| 智普AI | https://open.bigmodel.cn/ | 最新的4.5和4.6,还有搜索工具 |
| Xiaoai中转商 | https://xiaoai.plus/register?aff=3TIp | 国外的模型很丰富 |
| Kimi | https://platform.moonshot.cn/docs/overview | 月之暗面,有潜力,有搜索工具 |
2、Langchain-V1版本介绍
LangChain 于 2022 年 10 月左右由机器学习工程师 Harrison Chase 发起。最初是 Harrison 的一个副业,当时他大约写了 800 行代码,是一个体量不大的单文件 Python 包,于同年秋季发布到了他个人的 GitHub 账户上。在 2024 年初正式推出LangGraph:允许开发者以更底层的方式编排每一步智能体逻辑。
2025年10月20日,LangChain 团队正式发布 LangChain 1.0 与LangGraph 1.0------这是这两大框架的首个主要版本,标志着 AI Agent 开发正式进入"工程化"阶段。
Harrison 本人曾这样定义:"LangChain 是一个构建 LLM 应用程序的框架,但这说法很模糊,也不够具体。我认为部分原因在于 LangChain 的功能实在太丰富了,所以很难用一句话具体说明。
LangChain本质上是一个用于构建大模型驱动应用的开源框架,它通过标准化的接口将大语言模型(LLM)与外部工具、数据存储、工作流逻辑等组件串联起来,让开发者无需从零搭建复杂的集成架构,就能快速构建具备"思考、记忆、行动"能力的智能体(Agent)。
不同于直接调用LLM API的简单开发模式,LangChain的核心价值在于解决了大模型的三大痛点:一是"信息孤岛"问题 ,通过检索模块连接私有数据、互联网信息等外部资源,弥补大模型知识库的局限性;二是"行动能力缺失"问题 ,通过工具调用机制让模型能够操作数据库、执行代码、发送邮件等实际任务;三是"上下文断裂"问题,通过记忆模块保存对话历史和中间状态,支持复杂的多轮交互和长期任务。
LangChainV1.0 vs LangGraphV1.0:分工与定位
- LangChain :构建 AI 智能体的最快方式。提供标准的工具调用架构、供应商无关设计和可插拔的中间件系统,让开发者高效构建通用 Agent。
- LangGraph :一个底层运行时框架,专为需要长期运行、可控且高定制化的生产级智能体设计。
LangChainV1.0的Agent是构建在 LangGraph 之上,以提供持久的执行、流、人机交互、持久性等。

3、LangChain 1.0重大革新
LangChain 1.0的更新并非简单的功能叠加,而是基于生产级应用需求的底层重构。其核心革新可以概括为"更统一、更可控、更生产就绪"三大特性,具体体现在以下几个方面:
一、核心入口:create_agent() 统一Agent构建流程
在LangChain 1.0之前,开发者构建Agent主要依赖create_react_agent()方法,该方法需要手动配置提示词模板、工具列表、执行器等多个组件,且不同类型的Agent(如React Agent、Self-Ask Agent)有着不同的构建接口,学习成本高且代码复用性差。
1.0版本彻底重构了Agent层,推出了create_agent()作为构建智能体的标准入口,其核心优势在于:
- 底层封装LangGraph执行机制:create_agent()默认基于LangGraph引擎实现,将"模型调用→工具决策→工具执行→结果整合"的闭环流程封装为高阶接口,开发者无需关注底层的图执行逻辑,只需传入核心组件即可快速构建Agent。这种设计不仅简化了代码,还提升了流程的稳定性和可扩展性,支持复杂的分支逻辑和循环执行。
- 告别繁琐的提示词模板:旧版本需要从LangChain Hub导入大段的提示词模板,包含工具调用格式、对话历史注入等复杂配置,且模型容易出现格式输出错误。1.0版本中,开发者只需传入简洁的system_prompt(系统提示词),LangChain会自动结合工具信息、对话上下文生成完整的提示词,大幅降低了提示词设计的难度。
- 兼容Function Calling标准:create_agent()原生支持OpenAI定义的Function Calling格式,能够自动将工具信息转化为结构化的函数描述,传递给支持该格式的LLM。在国内模型中,通义千问对这一特性的适配性最佳,这也是很多开发者选择其作为LangChain默认模型的重要原因。
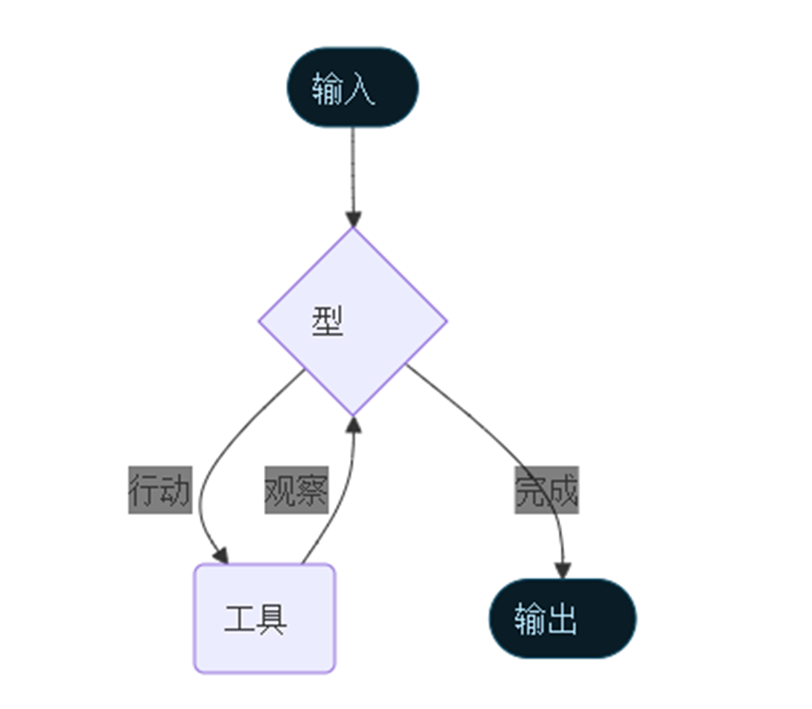
二、扩展了middleware(中间件)
旧版本中,开发者若想自定义Agent的执行逻辑(如添加日志记录、敏感信息过滤、用户确认步骤等),需要修改核心代码或通过复杂的钩子函数(Hook)实现,不仅难度大,还容易破坏原有流程的稳定性。LangChain 1.0引入的middleware(中间件)机制,彻底解决了这一问题。
中间件的作用:
中间件本质上是一组可插拔的钩子函数,能够嵌入到Agent的执行流程中,对每个步骤进行自定义处理,且无需修改Agent的核心逻辑。其工作原理类似于Web开发中的中间件,通过"链式调用"的方式依次处理请求和响应,实现功能的灵活扩展。

内置的中间件:
LangChain 1.0提供了多个内置中间件,覆盖生产环境中的常见需求:
- 人机交互中间件:在工具执行前暂停流程,让用户批准、编辑或拒绝工具调用请求,适用于涉及敏感操作(如转账、发送邮件)的场景,提升应用的安全性。
- 脱敏中间件:自动识别并遮盖对话中的电子邮件、电话号码、身份证号等敏感信息,确保符合数据隐私法规,避免用户信息泄露。
- 记忆优化中间件:自动裁剪过长的对话历史,防止令牌溢出错误,同时保持关键信息不丢失,提升长期运行会话的性能。
自定义中间件:
开发者也可以自定义中间件,通过连接到Agent循环中的多个节点(如before_model、wrap_tool_call、after_tool等),实现个性化需求。例如,自定义一个日志中间件,记录每次工具调用的参数、结果和执行时间,用于后续的性能分析和问题排查。
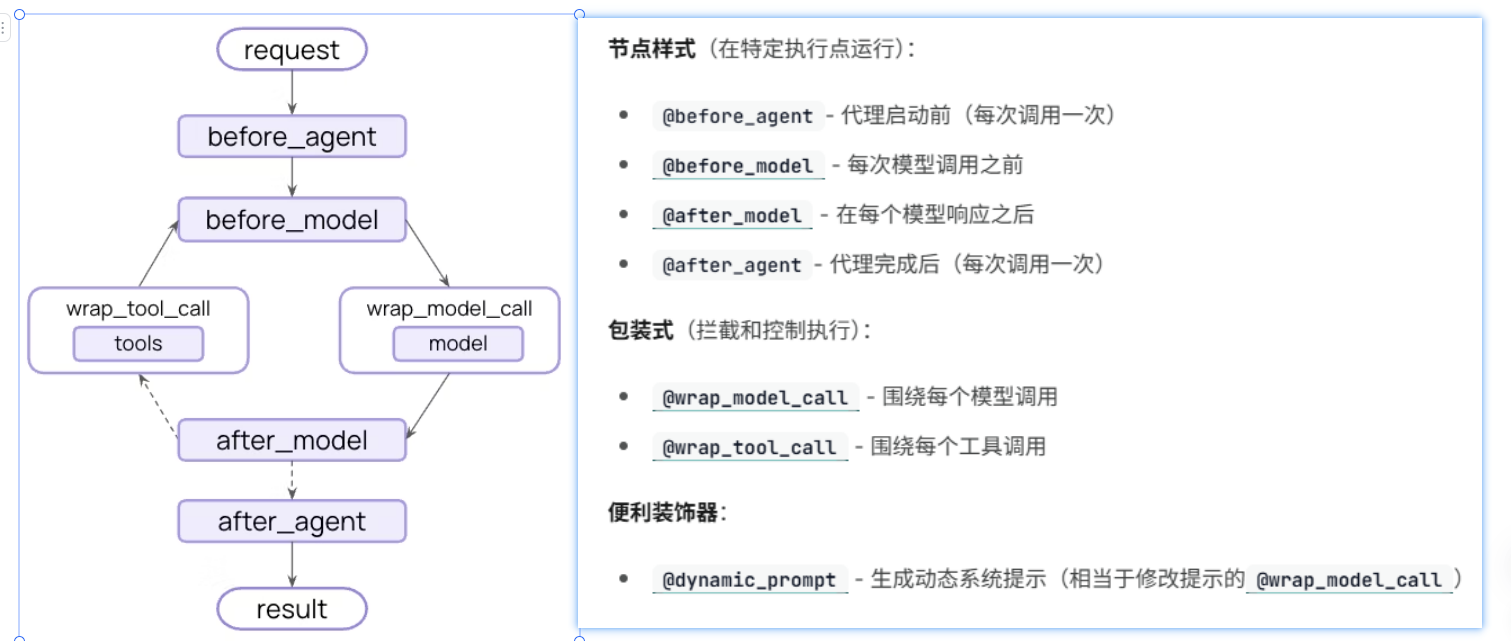
三、标准化和旧版本兼容
- 标准化内容块:所有LLM输出(文本、工具调用、引用、推理轨迹)统一为.content_blocks结构,无论使用哪个厂商的模型,输出格式保持一致,彻底解决了跨模型开发中的格式兼容问题。
- 结构化输出集成:将JSON Schema等结构化输出能力直接集成到主循环中,无需额外的LLM调用,不仅降低了延迟和成本,还提升了结构化输出的准确性。
- 向后兼容与功能迁移:为了照顾旧版本用户,LangChain将create_react_agent()、LLMChain、ConversationBufferMemory等旧功能迁移至langchain-classic包中,开发者可以逐步迁移代码,避免一次性重构的风险。