文章目录
- 摘要
-
- [SQL 数据库(关系型数据库)](#SQL 数据库(关系型数据库))
- [NoSQL 数据库](#NoSQL 数据库)
- 5.1 SQL数据库
- 5.3 使用SQL还是NoSQL
- 5.4 Python数据库框架
-
- 对象关系映射器(ORM)。把面向对象的代码,自动转换为数据库操作
- 性能
- 可移植性
-
- 数据库管理系统:创建、管理和操作数据库的完整软件系统
- [数据库引擎(Database Engine):数据库系统中负责数据存储和查询执行的核心底层组件](#数据库引擎(Database Engine):数据库系统中负责数据存储和查询执行的核心底层组件)
- [数据库管理系统 vs 数据库 vs 数据库引擎](#数据库管理系统 vs 数据库 vs 数据库引擎)
-
- [Python对象 → ORM → 驱动 → DBMS → 存储引擎 → 磁盘文件](#Python对象 → ORM → 驱动 → DBMS → 存储引擎 → 磁盘文件)
- [在 Flask 项目中如何选择数据库框架](#在 Flask 项目中如何选择数据库框架)
-
- [Flask-SQLAlchemy 本质上是对 SQLAlchemy 的封装](#Flask-SQLAlchemy 本质上是对 SQLAlchemy 的封装)
-
- [SQLAlchemy 实际连接的是什么?](#SQLAlchemy 实际连接的是什么?)
- 5.5 使用Flask-SQLAlchemy管理数据库
-
- [Flask-SQLAlchemy 的数据库连接 URL(Database URL)格式](#Flask-SQLAlchemy 的数据库连接 URL(Database URL)格式)
-
- [什么是数据库 URL?一种用字符串描述"如何连接数据库"的标准格式](#什么是数据库 URL?一种用字符串描述“如何连接数据库”的标准格式)
- 通用格式,数据库类型://用户名:密码@主机名/数据库名
- [SQLAlchemy 通常还会指定驱动。数据库类型+驱动://用户名:密码@主机名/数据库名](#SQLAlchemy 通常还会指定驱动。数据库类型+驱动://用户名:密码@主机名/数据库名)
- [SQLALCHEMY_DATABASE_URI,告诉 Flask-SQLAlchemy 要连接哪个数据库](#SQLALCHEMY_DATABASE_URI,告诉 Flask-SQLAlchemy 要连接哪个数据库)
- SQLALCHEMY_TRACK_MODIFICATIONS
- 配置示例
-
- [db = SQLAlchemy(app)。把 Flask 应用和数据库系统绑定起来,并创建一个统一操作数据库的核心对象](#db = SQLAlchemy(app)。把 Flask 应用和数据库系统绑定起来,并创建一个统一操作数据库的核心对象)
-
- [为什么说"db 表示应用使用的数据库"?](#为什么说“db 表示应用使用的数据库”?)
- [SQLAlchemy(app) 只是"准备好连接数据库",真正的数据库连接通常发生在第一次实际数据库操作时。](#SQLAlchemy(app) 只是“准备好连接数据库”,真正的数据库连接通常发生在第一次实际数据库操作时。)
-
- [SQLite 是个特殊情况。没有网络连接。在第一次访问时打开文件。如果文件不存在会创建文件](#SQLite 是个特殊情况。没有网络连接。在第一次访问时打开文件。如果文件不存在会创建文件)
- [app.config 是 Flask 应用的"配置字典"。应用的全局设置中心。扩展通过它读取自己的配置](#app.config 是 Flask 应用的“配置字典”。应用的全局设置中心。扩展通过它读取自己的配置)
- db.init_app(app),先创建,再绑定
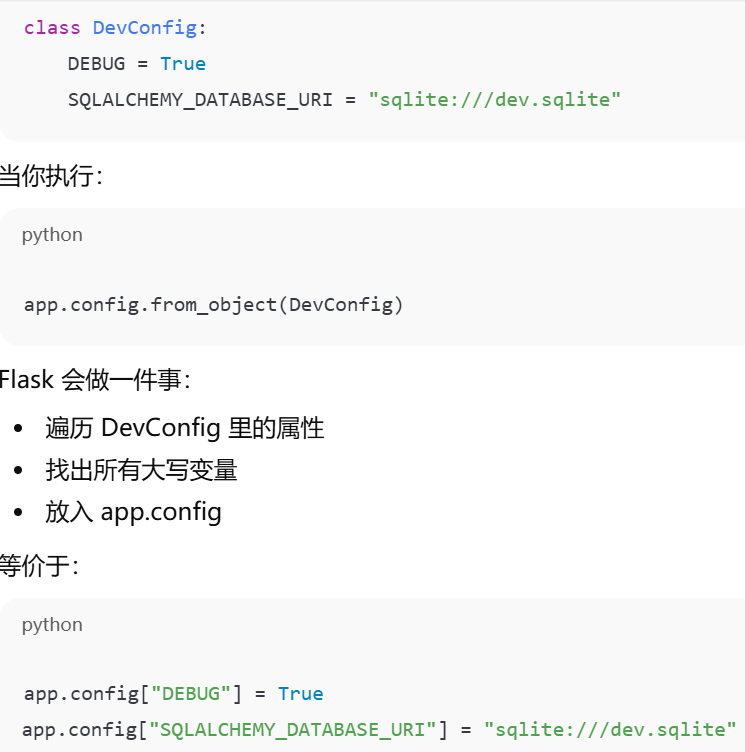
- [app.config.from_object(xx)加载对应配置类里的设置到 app.config字段](#app.config.from_object(xx)加载对应配置类里的设置到 app.config字段)
- [为什么 Flask 必须有 application context 才能访问数据库?](#为什么 Flask 必须有 application context 才能访问数据库?)
-
- [application context 是什么?每当有请求进入,自动创建应用的上下文](#application context 是什么?每当有请求进入,自动创建应用的上下文)
- 5.6 定义模型
-
- [模型 = 用 Python 类表示数据库表。模型就是用面向对象方式操作数据库表。在 ORM 里:一个类 → 一张表。类的属性 → 表的列。类的实例 → 表中的一行数据](#模型 = 用 Python 类表示数据库表。模型就是用面向对象方式操作数据库表。在 ORM 里:一个类 → 一张表。类的属性 → 表的列。类的实例 → 表中的一行数据)
-
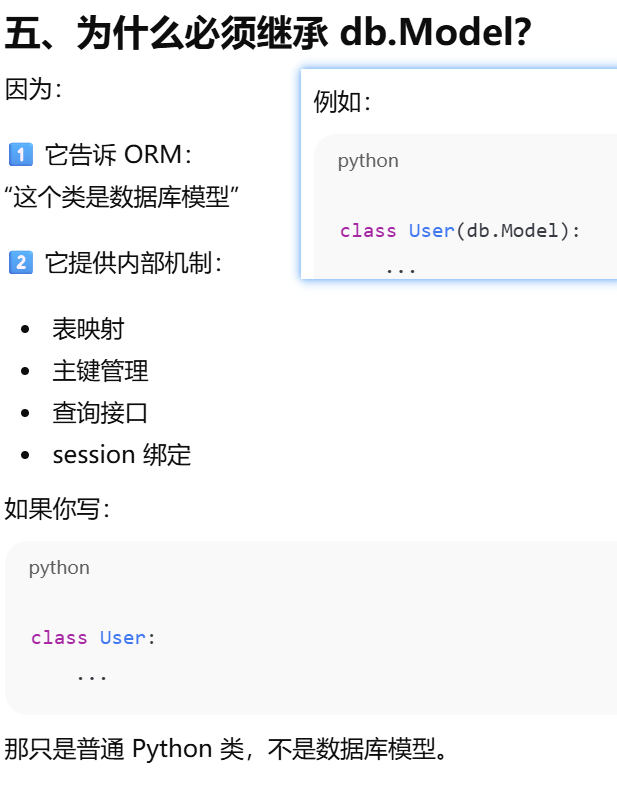
- [db.Model 是什么?所有模型类必须继承的基类](#db.Model 是什么?所有模型类必须继承的基类)
- 5.7 关系
-
- [relationship()是用来在 Python 里建立两个模型之间的联系](#relationship()是用来在 Python 里建立两个模型之间的联系)
-
- relationship参数
-
- 第一个参数是要关联的"目标模型"
- [back_populates 是:手动建立"双方都知道对方"的关系。](#back_populates 是:手动建立“双方都知道对方”的关系。)
-
- [back_populates 写的是:对方模型里 relationship 对应的变量名](#back_populates 写的是:对方模型里 relationship 对应的变量名)
- [backref ------ 自动创建"反向访问",在对方的模型里自动生成一个属性](#backref —— 自动创建“反向访问”,在对方的模型里自动生成一个属性)
-
- [如果你在父表里写了 backref,子表就不需要再手动写那个属性,ORM 会帮你自动创建](#如果你在父表里写了 backref,子表就不需要再手动写那个属性,ORM 会帮你自动创建)
- [primaryjoin ------ 指定怎么连接](#primaryjoin —— 指定怎么连接)
- [lazy ------ 决定访问关系属性时数据库什么时候发 SQL](#lazy —— 决定访问关系属性时数据库什么时候发 SQL)
- [uselist ------ 控制是不是列表](#uselist —— 控制是不是列表)
- [order_by ------ 排序](#order_by —— 排序)
- [secondary ------ 告诉 ORM:两张表之间要"通过第三张表连接"](#secondary —— 告诉 ORM:两张表之间要“通过第三张表连接”)
- [secondaryjoin ------ 多对多复杂连接](#secondaryjoin —— 多对多复杂连接)
- [primaryjoin / secondaryjoin](#primaryjoin / secondaryjoin)
- [靠外键建立联系。它根据 ForeignKey 自动推断 JOIN 条件](#靠外键建立联系。它根据 ForeignKey 自动推断 JOIN 条件)
- [relationship 返回的到底是什么?属性描述器](#relationship 返回的到底是什么?属性描述器)
- 返回值具体是什么?取决于关系类型
- 把外键和db.relationship()都放在"多"这一侧
- 连接数据库的工具:DBeaver (Community Edition)
- 5.8 数据库操作
-
- [5.8.1 创建表 db.create_all()](#5.8.1 创建表 db.create_all())
- 5.8.2 插入行
-
- 数据库Session(会话)。也称事务
- [为什么必须要有 session?](#为什么必须要有 session?)
- [为什么是 db.session?当前 Flask 应用绑定的数据库db,操作的会话](#为什么是 db.session?当前 Flask 应用绑定的数据库db,操作的会话)
-
- [session 是绑定在 SQLAlchemy 实例上的](#session 是绑定在 SQLAlchemy 实例上的)
- [Flask-SQLAlchemy session 的绑定规则.不同代码块的应用上下文,对应的session不一样](#Flask-SQLAlchemy session 的绑定规则.不同代码块的应用上下文,对应的session不一样)
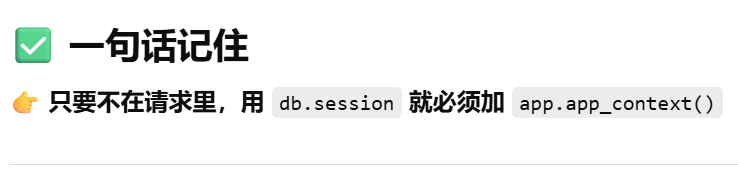
- [db.session = "当前请求专属的数据库会话"。只要不在请求里,用 db.session 就必须加 app.app_context()](#db.session = “当前请求专属的数据库会话”。只要不在请求里,用 db.session 就必须加 app.app_context())
- [db.session 依赖 Flask 的"应用上下文(app context)](#db.session 依赖 Flask 的“应用上下文(app context))
-
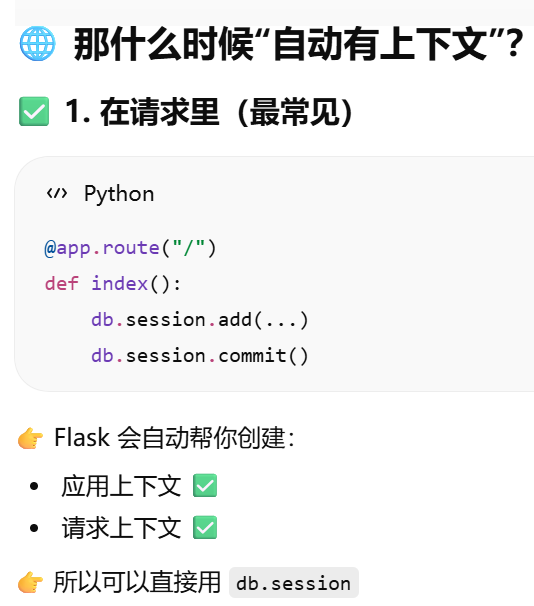
- 那什么时候"自动有上下文"?
- [没有上下文需要手动加上下文。只要不在请求里,用 db.session 就必须加 app.app_context()](#没有上下文需要手动加上下文。只要不在请求里,用 db.session 就必须加 app.app_context())
-
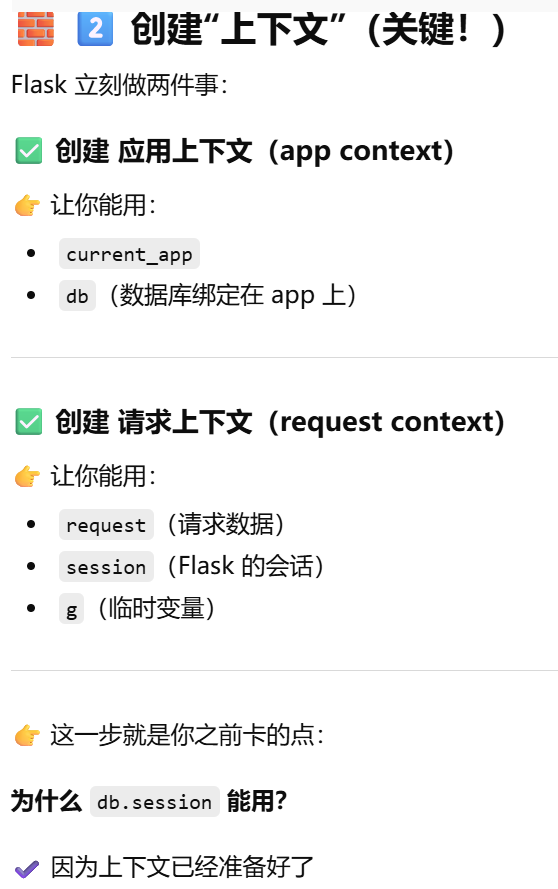
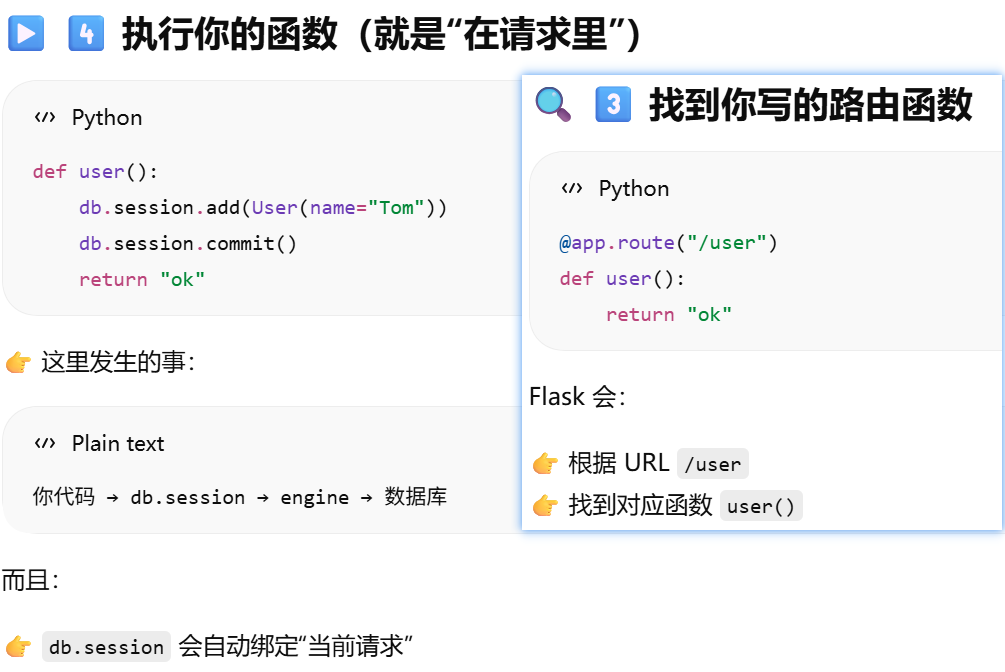
- [为什么"请求里"就可以用 db.session?处理请求flask会自动创建上下文](#为什么“请求里”就可以用 db.session?处理请求flask会自动创建上下文)
- ["请求来了之后,Flask 内部到底发生了什么?"](#“请求来了之后,Flask 内部到底发生了什么?”)
- [Flask 有两种上下文:请求时自动创建(最常见).你可以手动创建(app.app_context())](#Flask 有两种上下文:请求时自动创建(最常见).你可以手动创建(app.app_context()))
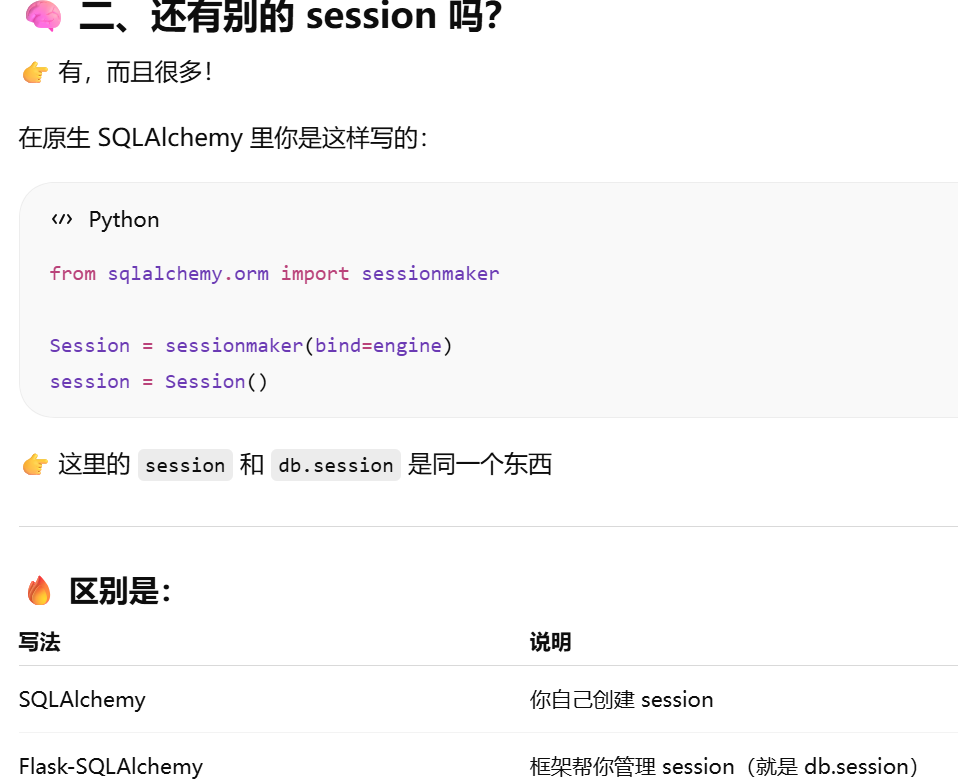
- [还有别的 session 吗?](#还有别的 session 吗?)
-
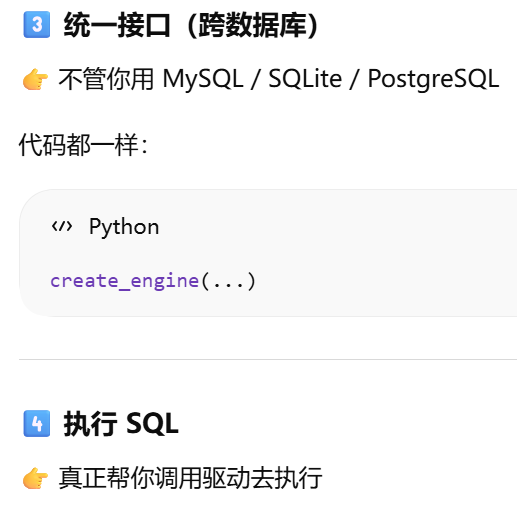
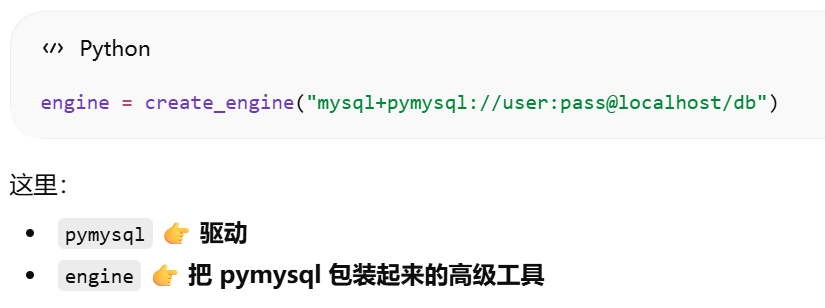
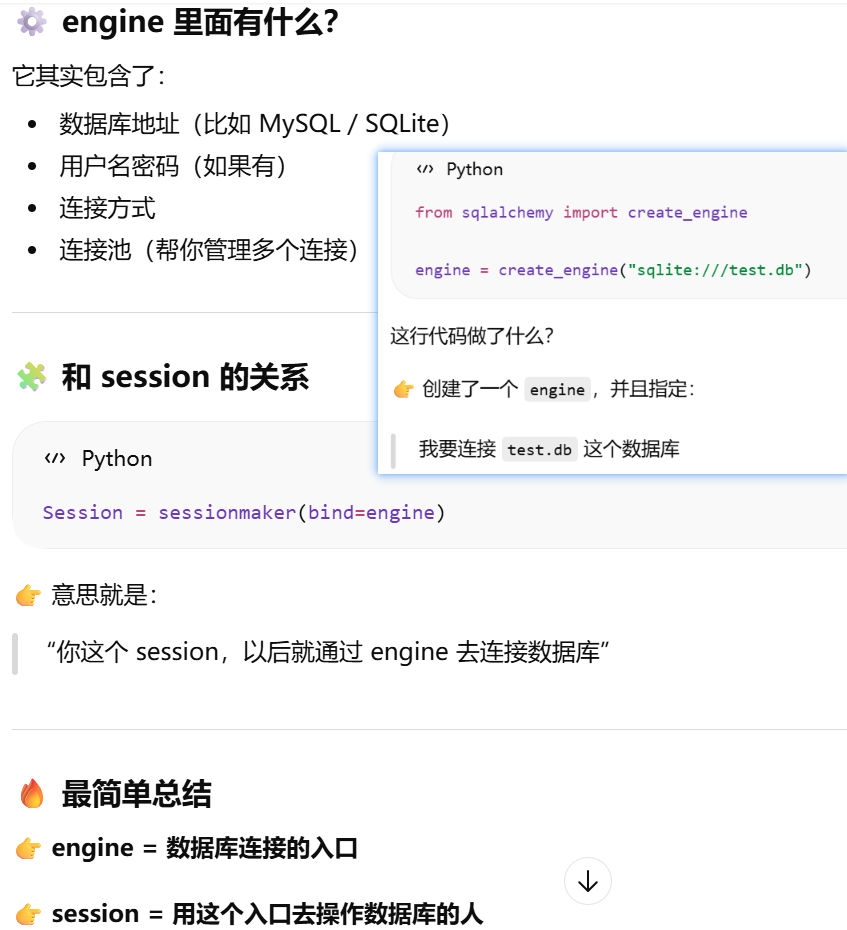
- [引擎:是 SQLAlchemy 在数据库驱动之上的一层封装](#引擎:是 SQLAlchemy 在数据库驱动之上的一层封装)
- [Flask-SQLAlchemy 已经自动创建了 engine 和 db.session,如果我想自己手动创建一个新的 session,但还是用这个 engine,该怎么操作?](#Flask-SQLAlchemy 已经自动创建了 engine 和 db.session,如果我想自己手动创建一个新的 session,但还是用这个 engine,该怎么操作?)
- [如果不是浏览器的请求,就不用db.session? 比如有定时任务,需要操作数据库,用什么session?](#如果不是浏览器的请求,就不用db.session? 比如有定时任务,需要操作数据库,用什么session?)
-
- [使用 db.session](#使用 db.session)
- [手动创建 session](#手动创建 session)
- 手动关闭session
- 事务=一组必须"要么全部成功,要么全部失败"的数据库操作。session是事务的容器
-
- [事务失败后 必须手动 db.session.rollback()](#事务失败后 必须手动 db.session.rollback())
- [user_john = User(username='john', role=admin_role)](#user_john = User(username='john', role=admin_role))
- [在 flask shell 里,其实已经自动帮你推入了 app context。所以你才能直接用:db.session.add(admin_role)而不报错。](#在 flask shell 里,其实已经自动帮你推入了 app context。所以你才能直接用:db.session.add(admin_role)而不报错。)
- add_all,参数是一个"可迭代对象"(iterable)
- 5.8.5 查询行
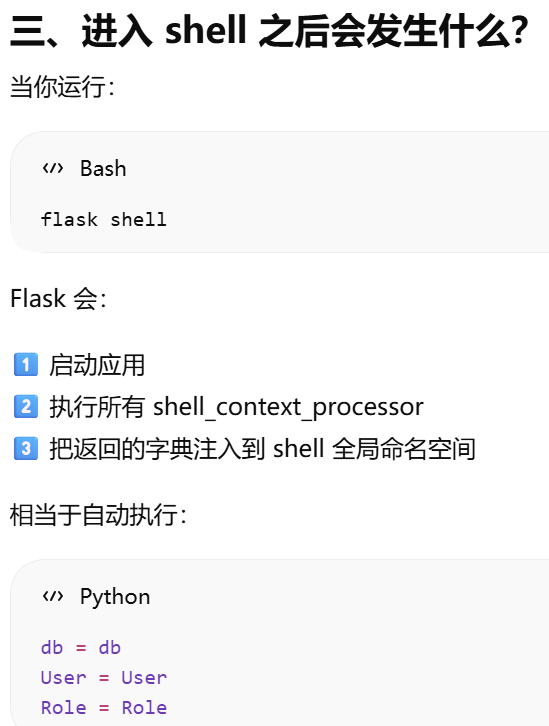
- [5.10 集成Python shell。shell_context_processor 是给 Flask shell 预加载变量用的](#5.10 集成Python shell。shell_context_processor 是给 Flask shell 预加载变量用的)
- 5.11 使用Flask-Migrate实现数据库迁移
-
- 5.11.1 创建迁移仓库
- 5.11.2 创建迁移脚本
-
- [Alembic 的 版本管理和迁移逻辑](#Alembic 的 版本管理和迁移逻辑)
- [flask db migrate -m "initial migration"](#flask db migrate -m "initial migration")
- 5.11.3 更新数据库
-
- [使用 flask db stamp 标记数据库](#使用 flask db stamp 标记数据库)
摘要
SQL 数据库(关系型数据库)

NoSQL 数据库


什么是反规范化(Denormalization)?



5.1 SQL数据库
实体关系图,ER图
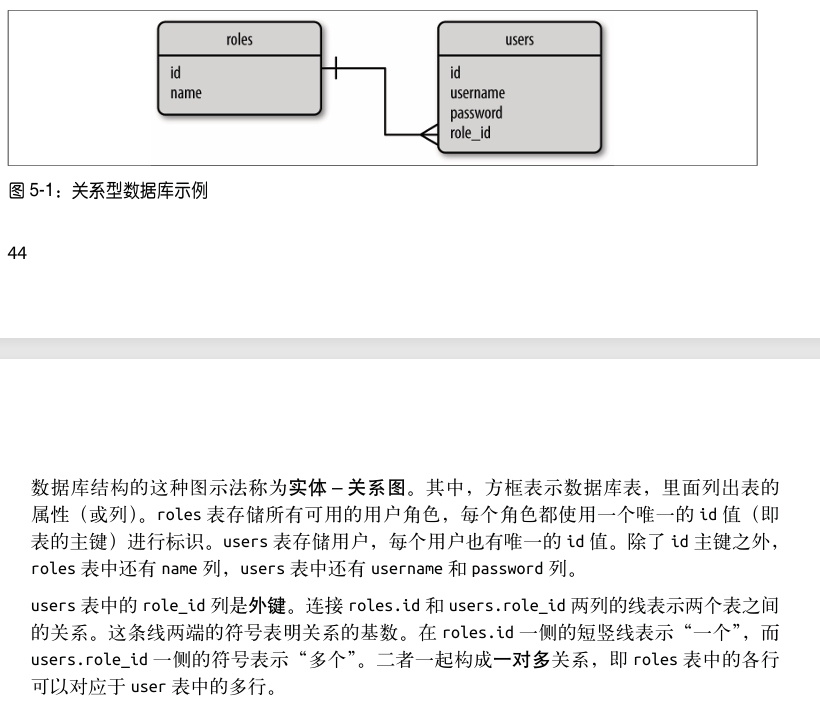
5.3 使用SQL还是NoSQL
ACID的范式






5.4 Python数据库框架
对象关系映射器(ORM)。把面向对象的代码,自动转换为数据库操作


数据库驱动




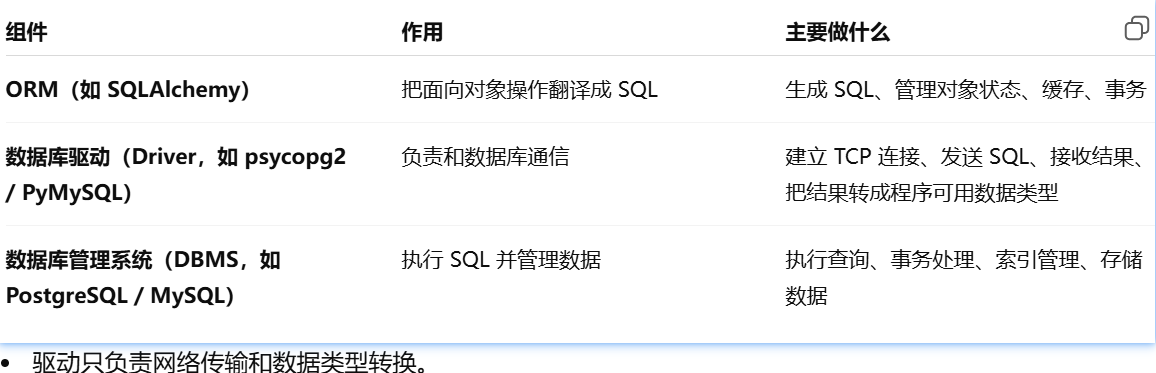
数据类型转换就是把程序里的数据类型,转换成数据库能理解的格式,或者把数据库返回的数据转换回程序的数据类型
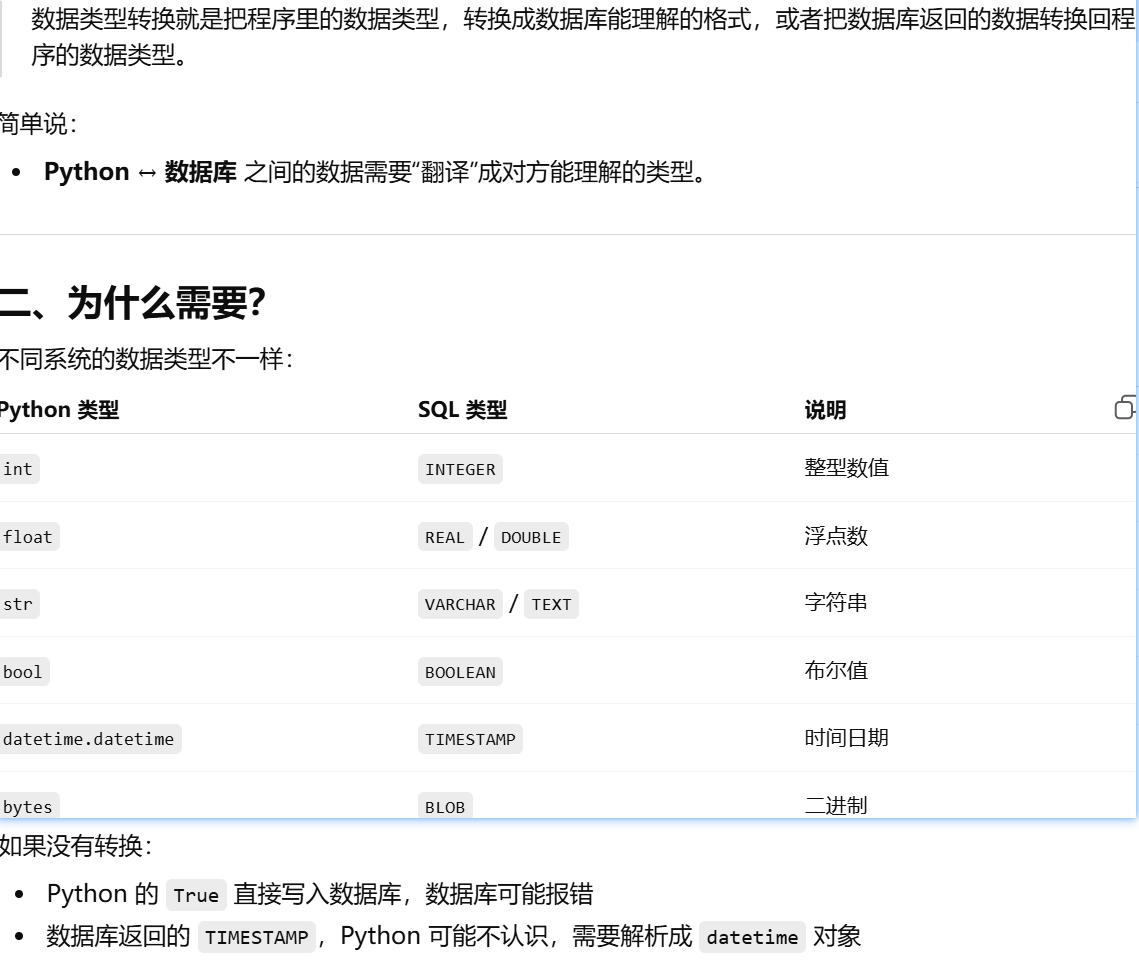
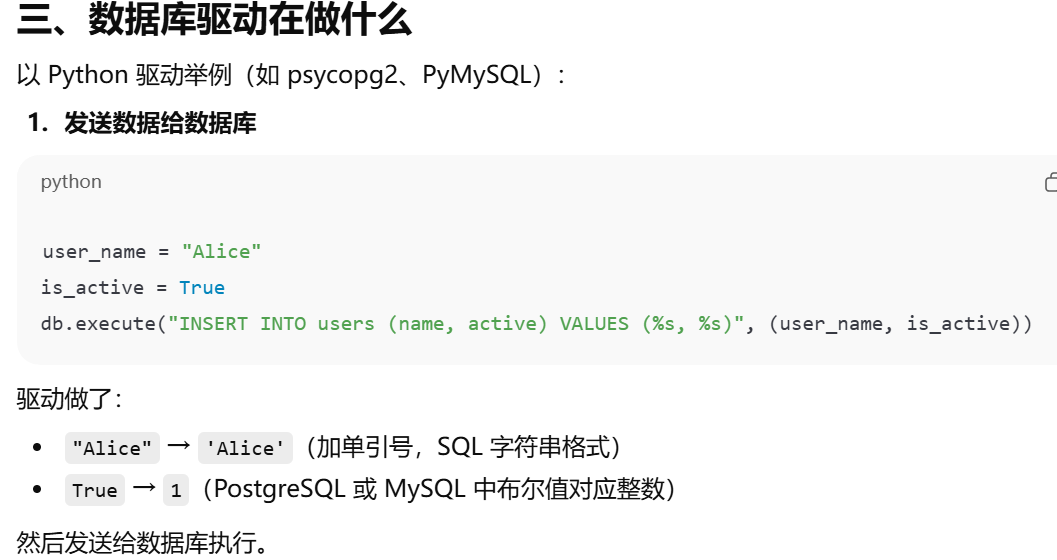



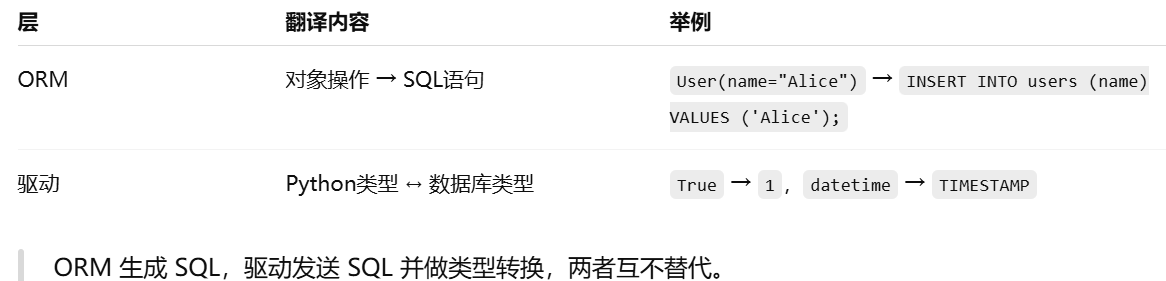
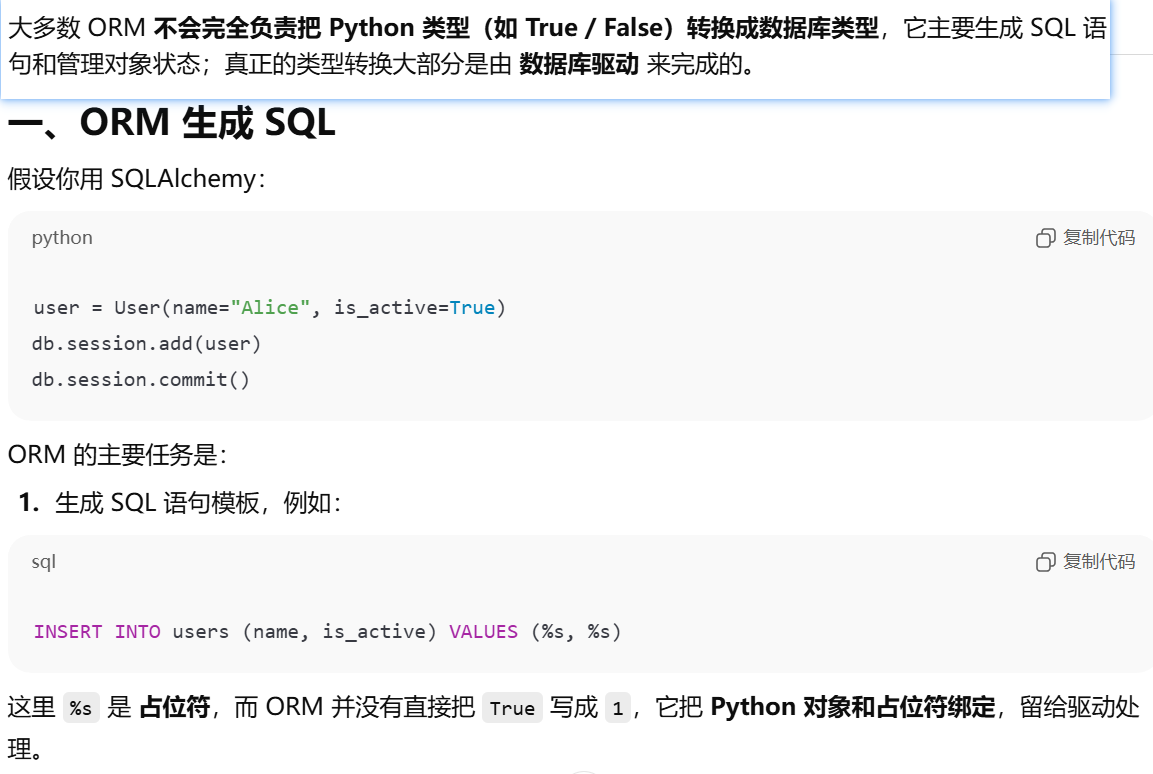



性能

可移植性

数据库管理系统:创建、管理和操作数据库的完整软件系统



数据库引擎(Database Engine):数据库系统中负责数据存储和查询执行的核心底层组件
数据库引擎(Storage Engine)是数据库管理系统(DBMS)里的一个组件,它负责实际存储和读取数据。







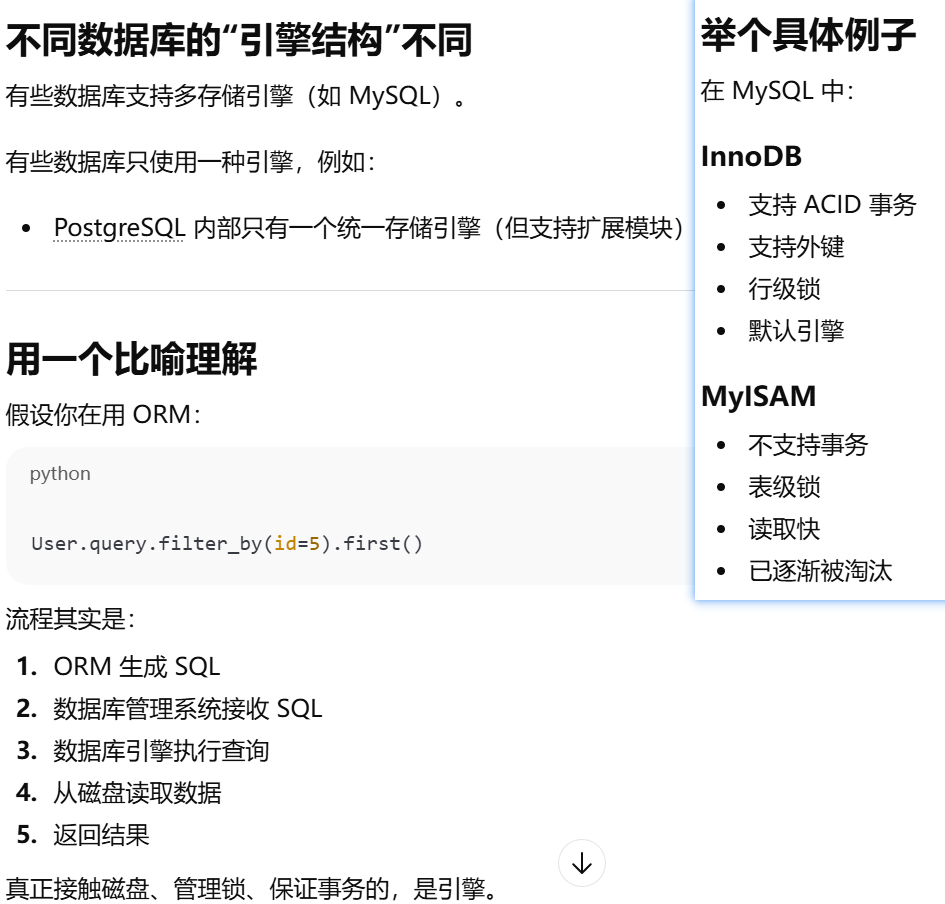

数据库管理系统 vs 数据库 vs 数据库引擎

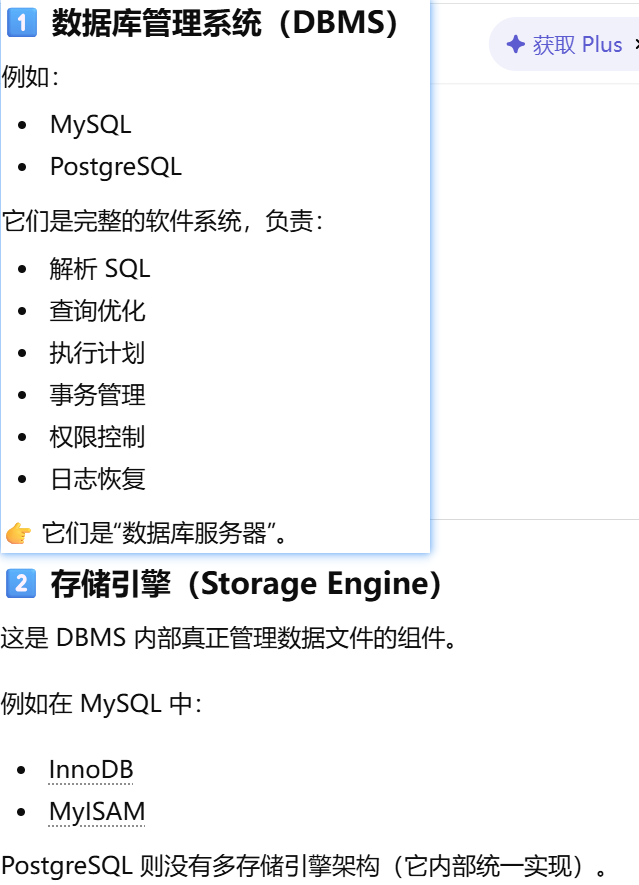
Python对象 → ORM → 驱动 → DBMS → 存储引擎 → 磁盘文件


在 Flask 项目中如何选择数据库框架

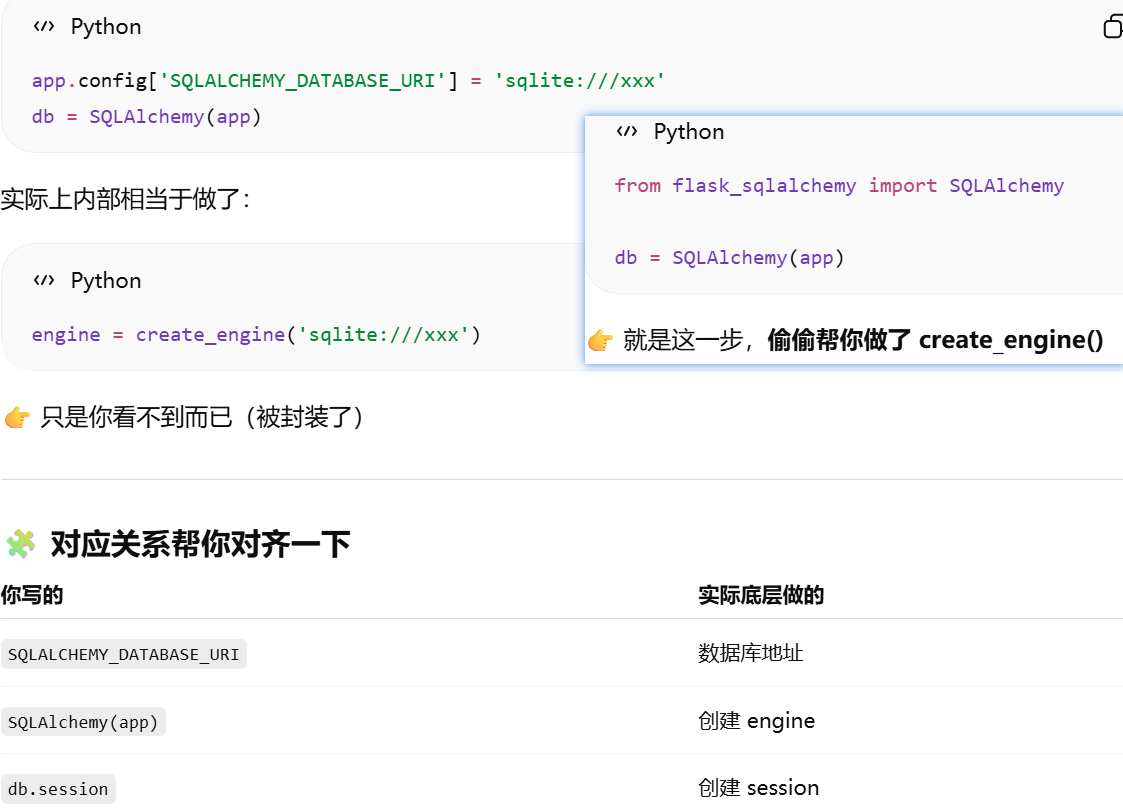
Flask-SQLAlchemy 本质上是对 SQLAlchemy 的封装
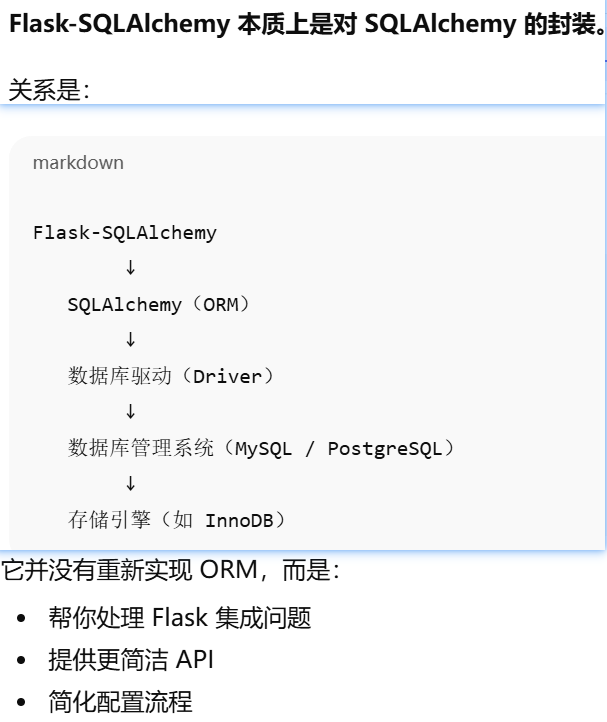



SQLAlchemy 实际连接的是什么?

5.5 使用Flask-SQLAlchemy管理数据库
Flask-SQLAlchemy 的数据库连接 URL(Database URL)格式
什么是数据库 URL?一种用字符串描述"如何连接数据库"的标准格式

通用格式,数据库类型://用户名:密码@主机名/数据库名

mysql,postgresql,sqlite示例
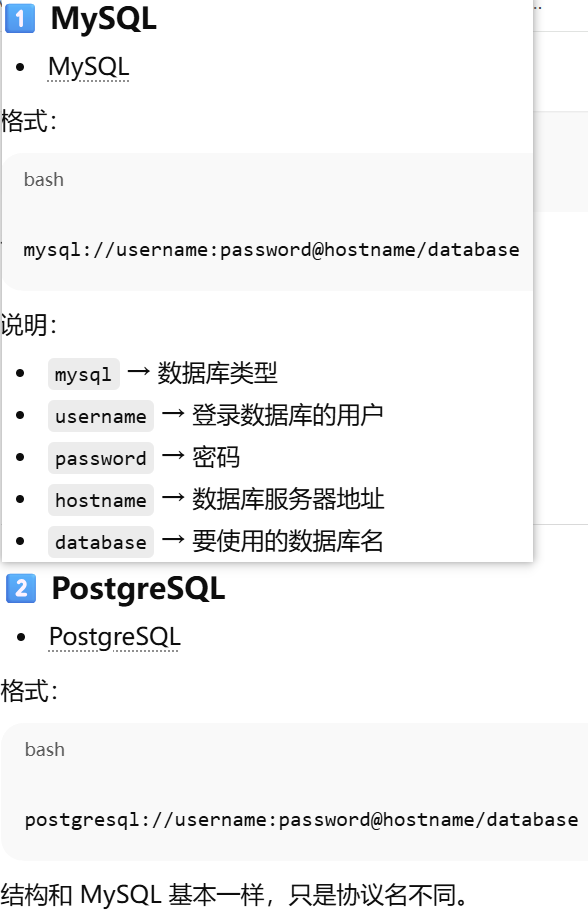
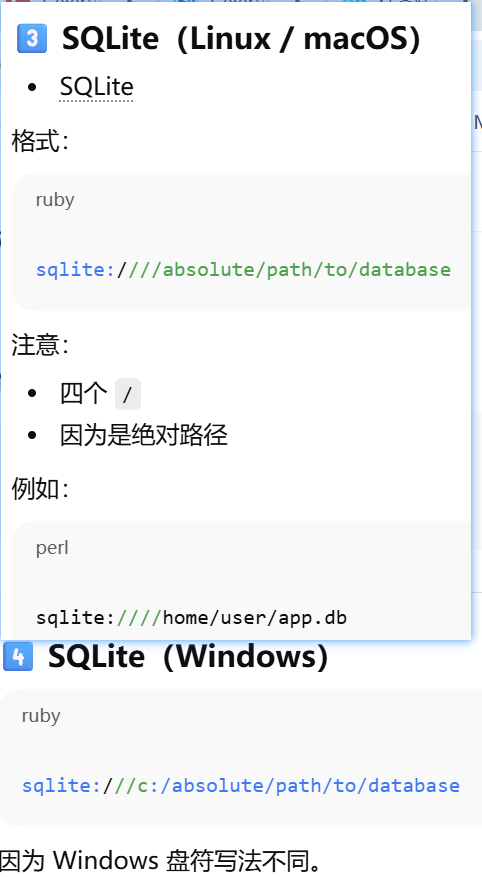


SQLAlchemy 通常还会指定驱动。数据库类型+驱动://用户名:密码@主机名/数据库名

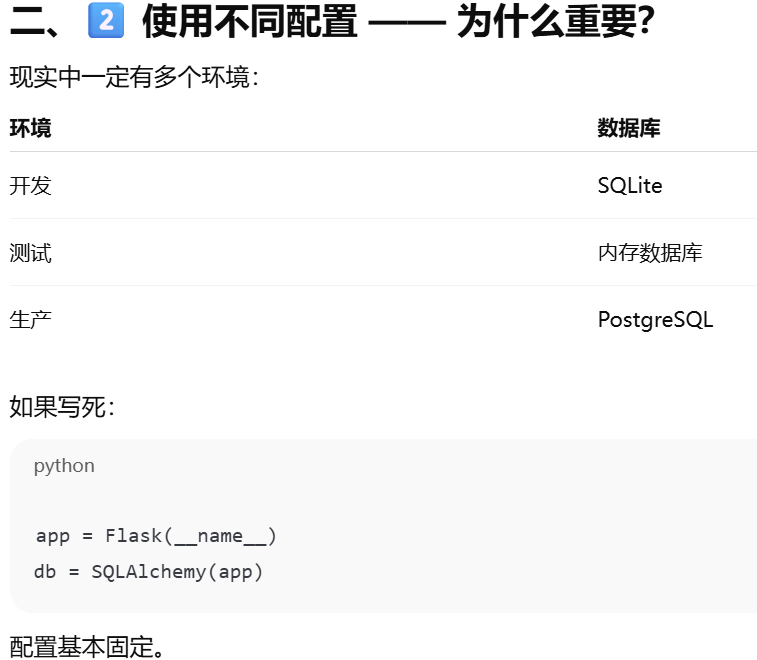
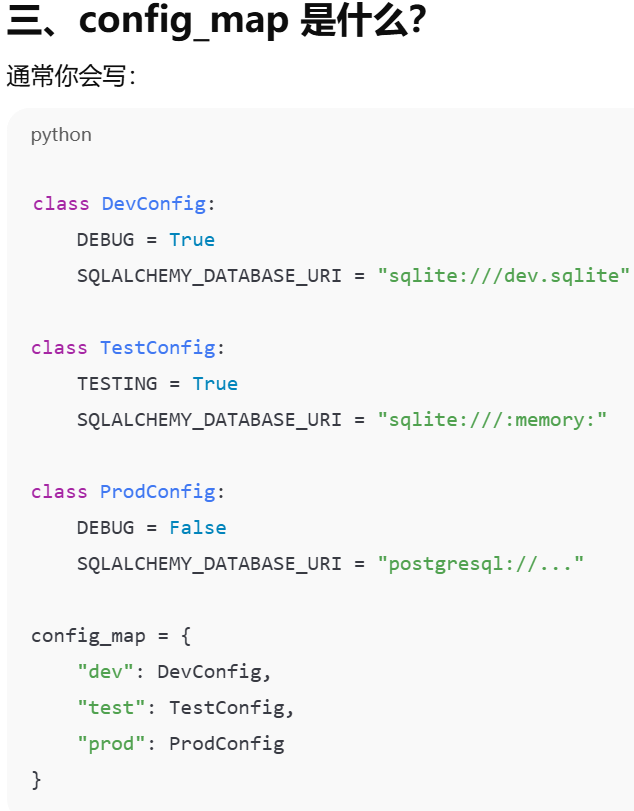
SQLALCHEMY_DATABASE_URI,告诉 Flask-SQLAlchemy 要连接哪个数据库

SQLALCHEMY_TRACK_MODIFICATIONS

配置示例

db = SQLAlchemy(app)。把 Flask 应用和数据库系统绑定起来,并创建一个统一操作数据库的核心对象
db 对象是SQLAlchemy 类的实例,表示应用使用的数据库.

详情见本章引擎章节

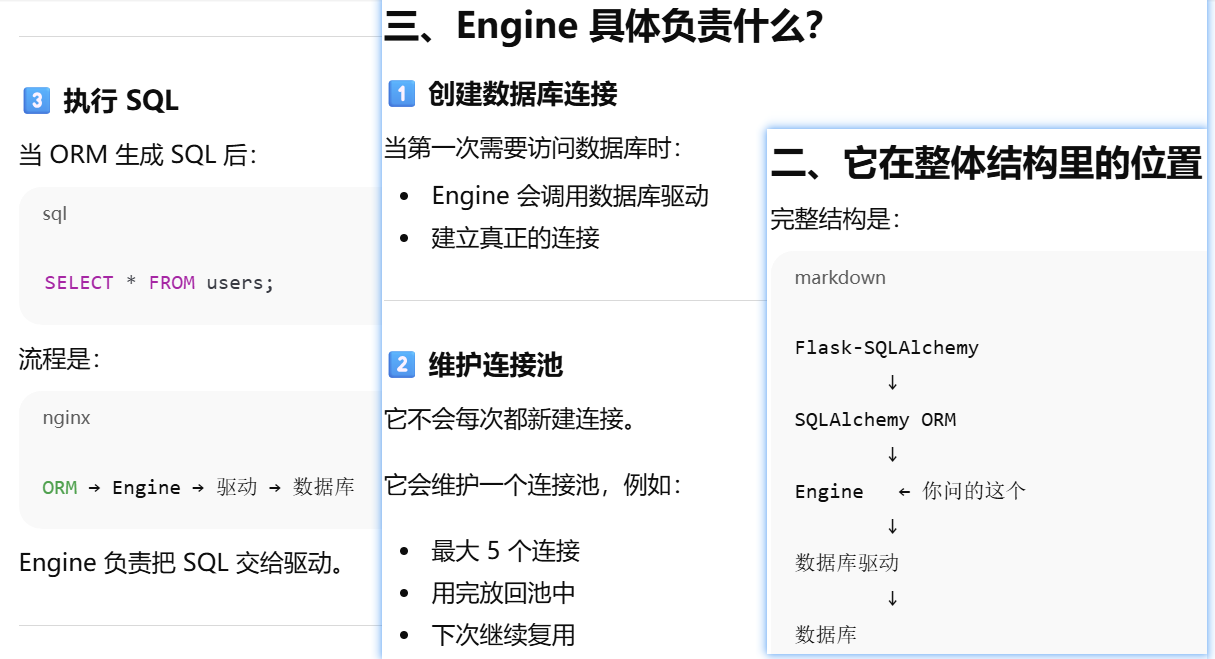


为什么说"db 表示应用使用的数据库"?

SQLAlchemy(app) 只是"准备好连接数据库",真正的数据库连接通常发生在第一次实际数据库操作时。
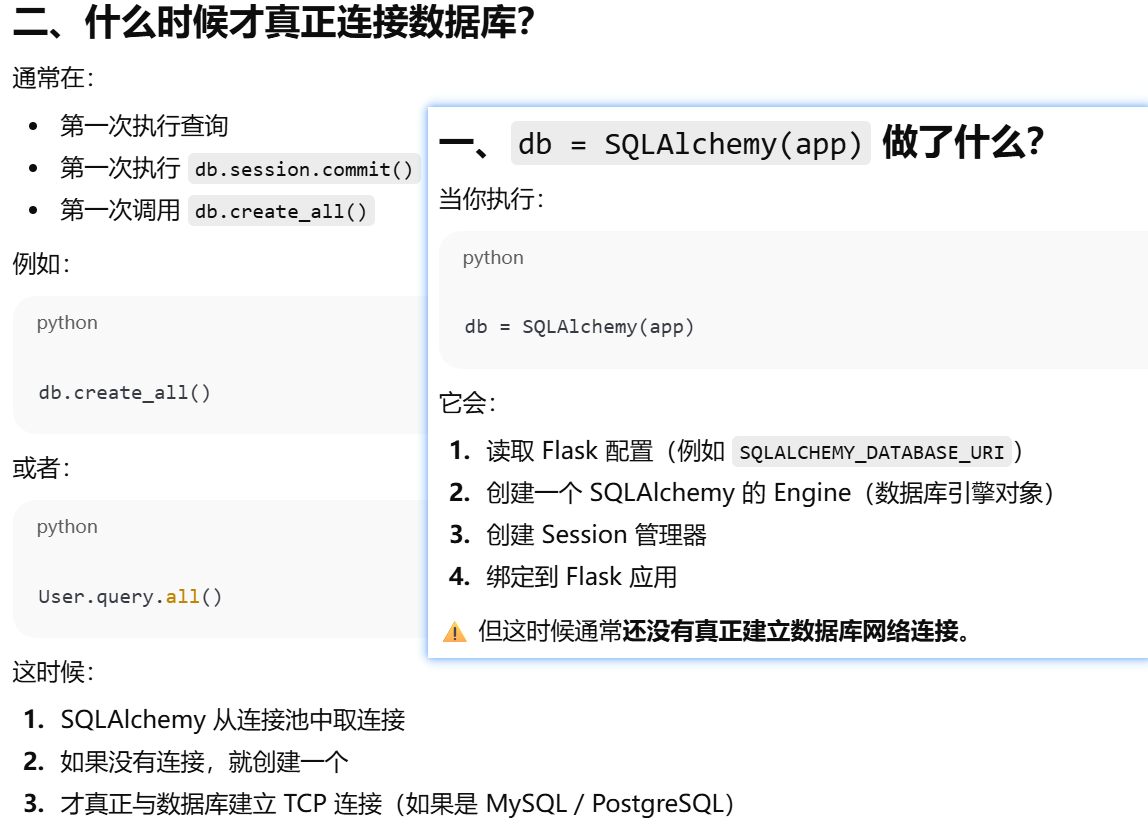
SQLite 是个特殊情况。没有网络连接。在第一次访问时打开文件。如果文件不存在会创建文件
app.config 是 Flask 应用的"配置字典"。应用的全局设置中心。扩展通过它读取自己的配置






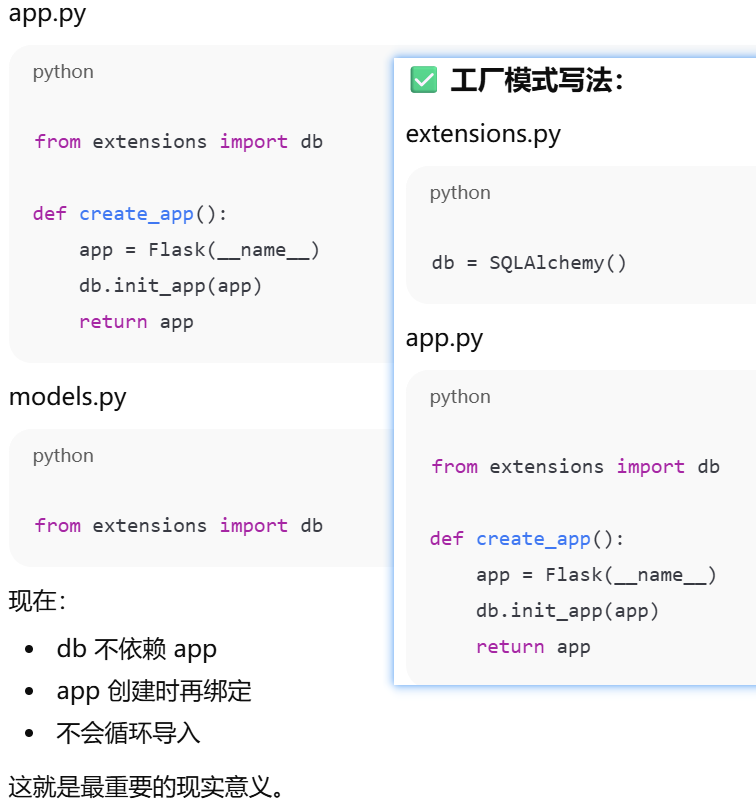
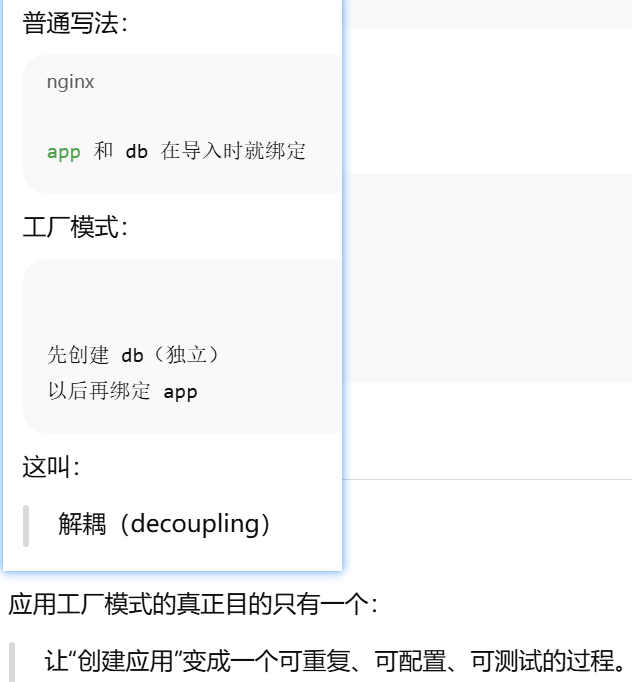
db.init_app(app),先创建,再绑定




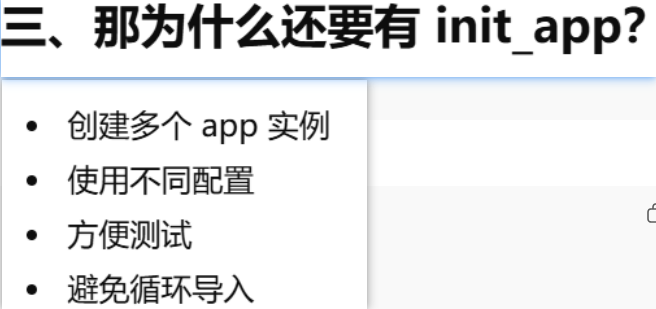
p
def create_app(config_name):
app = Flask(__name__)
app.config.from_object(config_map[config_name])
db.init_app(app)
return app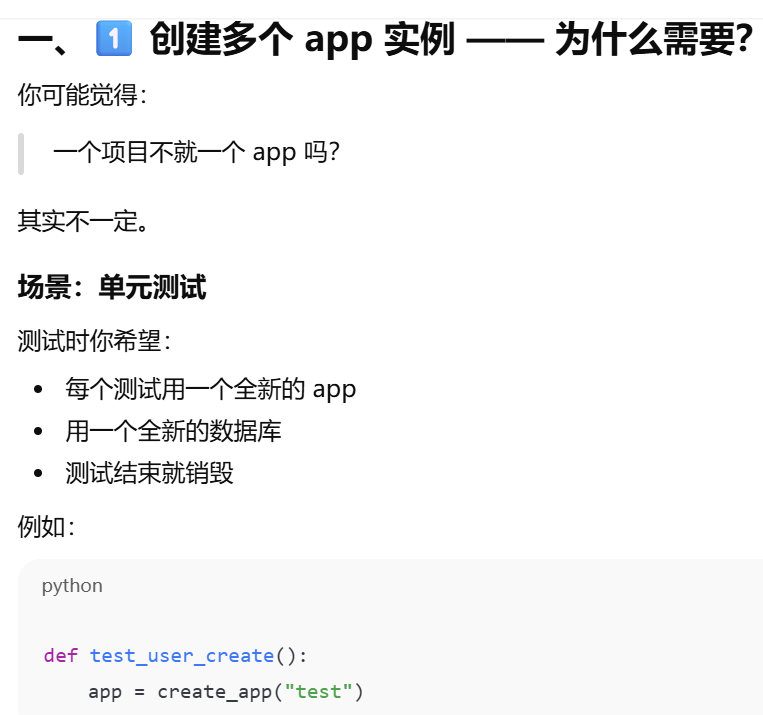








app.config.from_object(xx)加载对应配置类里的设置到 app.config字段




为什么 Flask 必须有 application context 才能访问数据库?

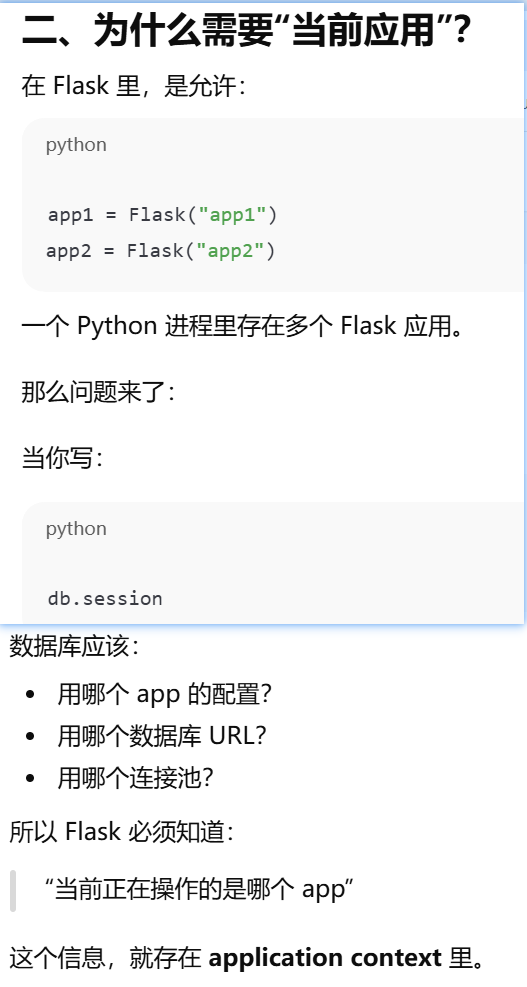
application context 是什么?每当有请求进入,自动创建应用的上下文



5.6 定义模型
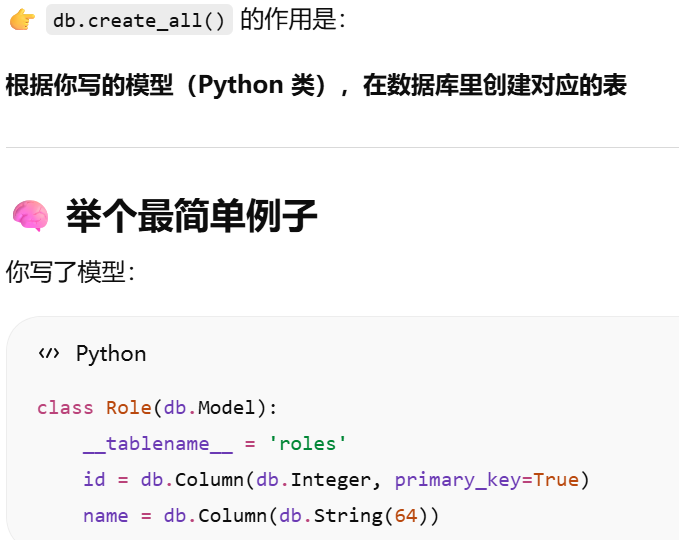
模型 = 用 Python 类表示数据库表。模型就是用面向对象方式操作数据库表。在 ORM 里:一个类 → 一张表。类的属性 → 表的列。类的实例 → 表中的一行数据


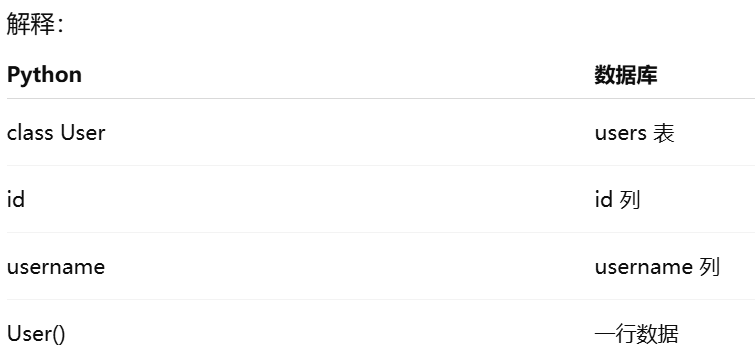

db.Model 是什么?所有模型类必须继承的基类



5.7 关系
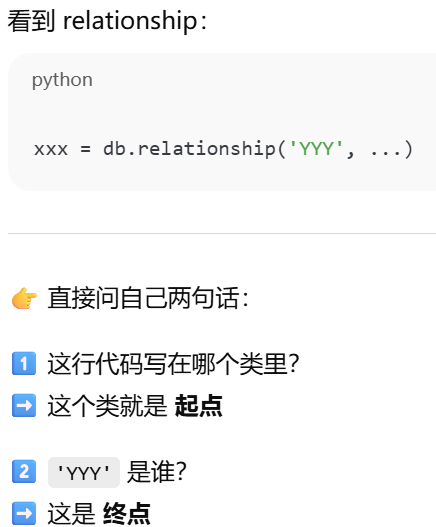
relationship()是用来在 Python 里建立两个模型之间的联系


relationship参数
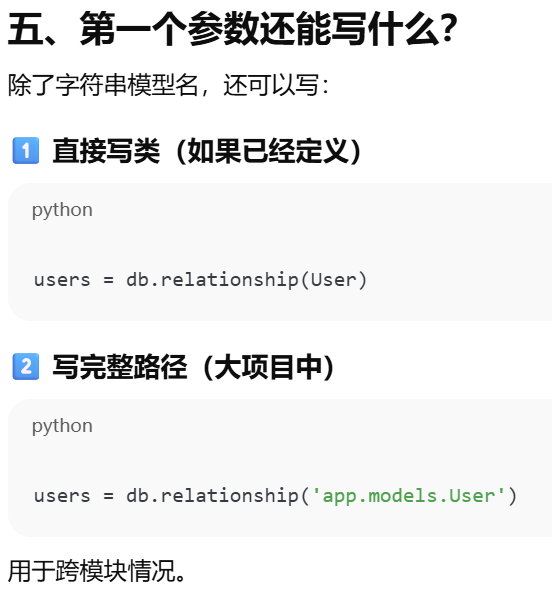
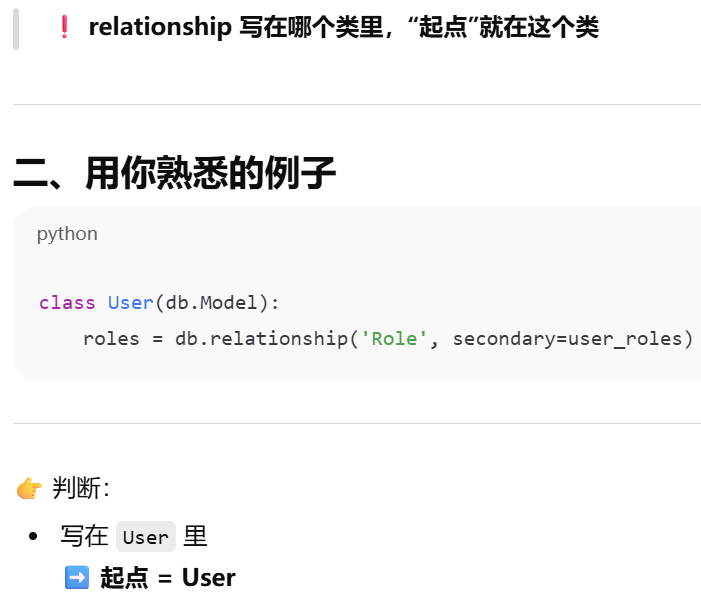
第一个参数是要关联的"目标模型"



back_populates 是:手动建立"双方都知道对方"的关系。


backref也有这个同步的功能







back_populates 写的是:对方模型里 relationship 对应的变量名



backref ------ 自动创建"反向访问",在对方的模型里自动生成一个属性

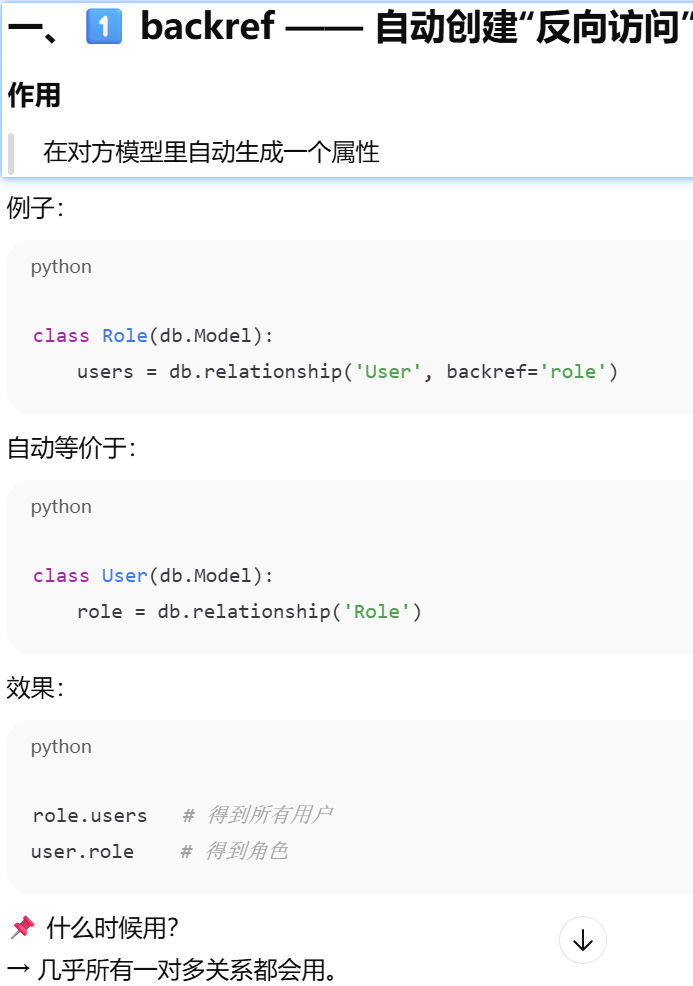
如果你在父表里写了 backref,子表就不需要再手动写那个属性,ORM 会帮你自动创建





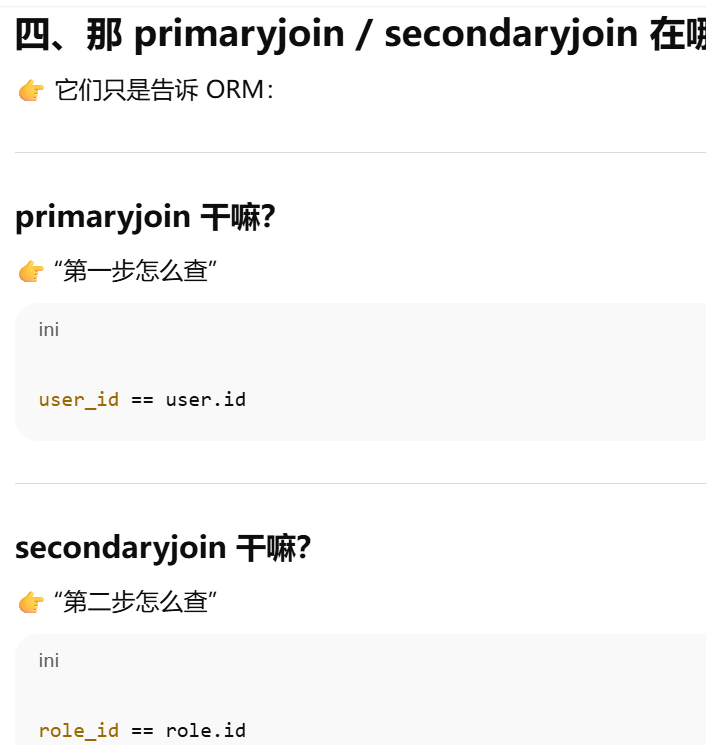
primaryjoin ------ 指定怎么连接

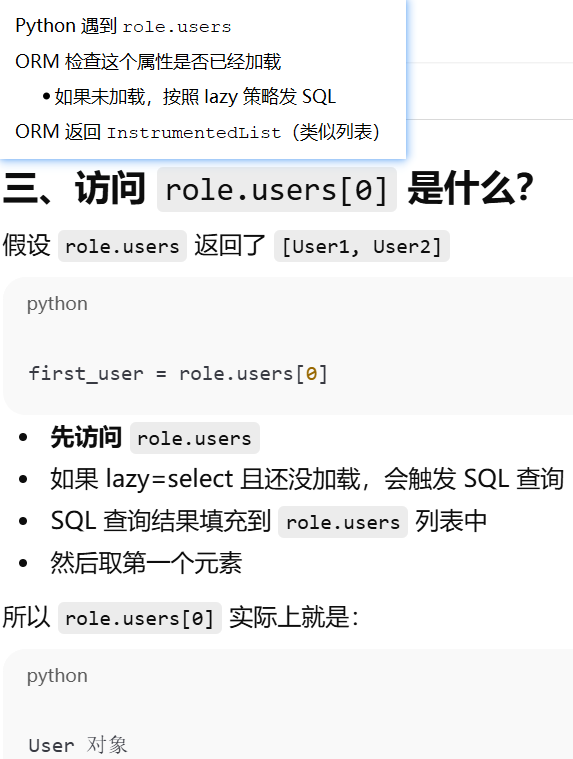
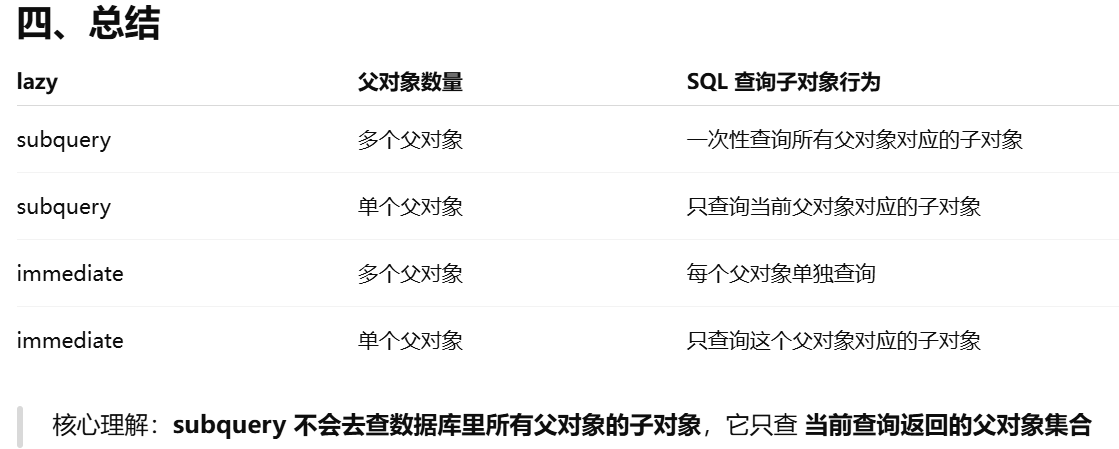
lazy ------ 决定访问关系属性时数据库什么时候发 SQL


| 值 | 含义 | 小白理解 |
|---|---|---|
select |
默认,首次访问时查询 | 惰性加载:你不访问 users,不发 SQL;访问时发一次 SQL |
joined |
使用 JOIN 一次查出 | 查询 Role 时,顺便 join 查出所有 User |
subquery |
使用子查询 | 查询 Role 后再发子查询查 users,一次加载但分两步 |
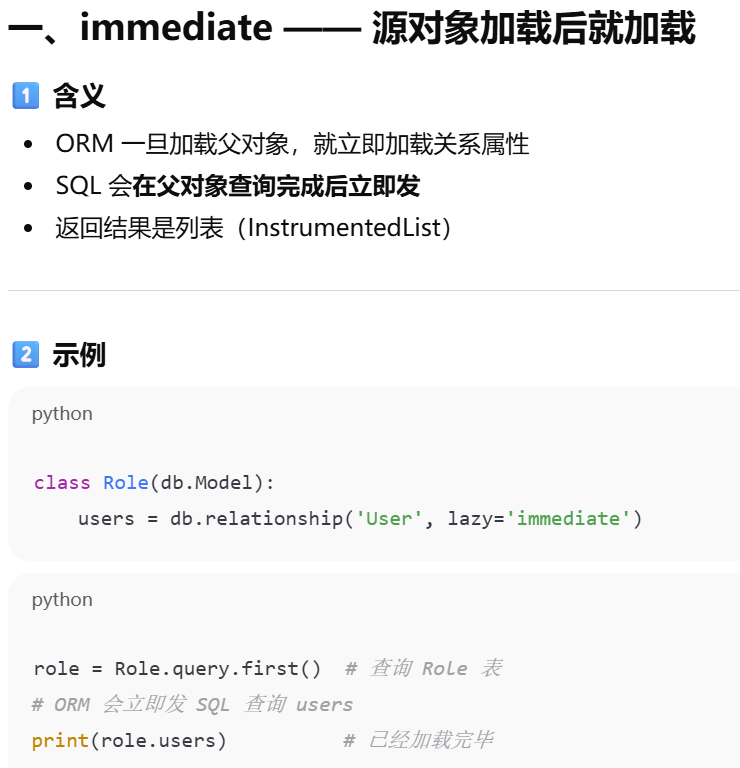
immediate |
主对象加载完就加载 | 一创建 Role,就查 users |
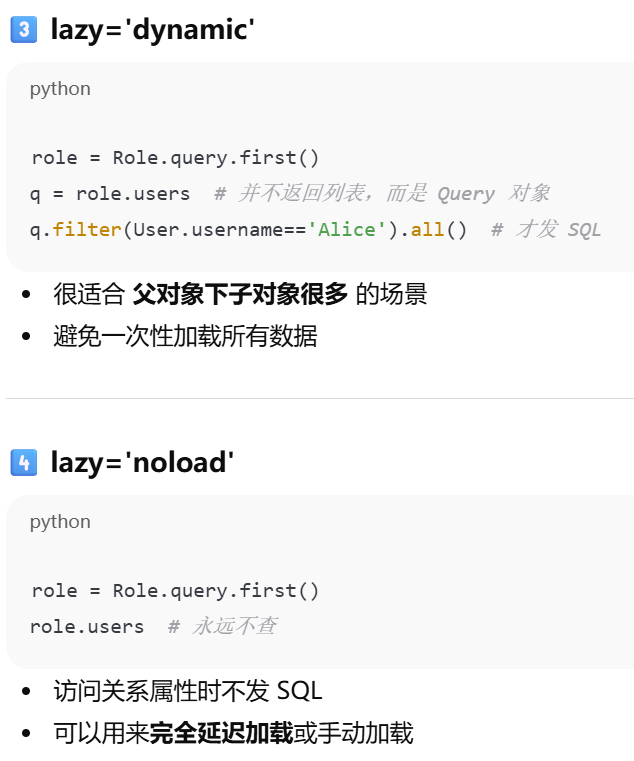
noload |
永远不加载 | 不管访问不访问,永远不查用户 |
dynamic |
不返回列表,而返回查询对象 | 不加载 users,只返回 query,可以继续 filter、order_by |







uselist ------ 控制是不是列表






order_by ------ 排序

secondary ------ 告诉 ORM:两张表之间要"通过第三张表连接"



















secondaryjoin ------ 多对多复杂连接


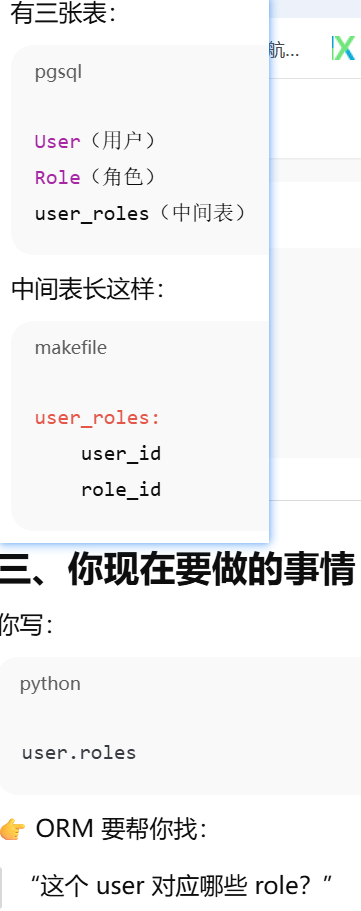




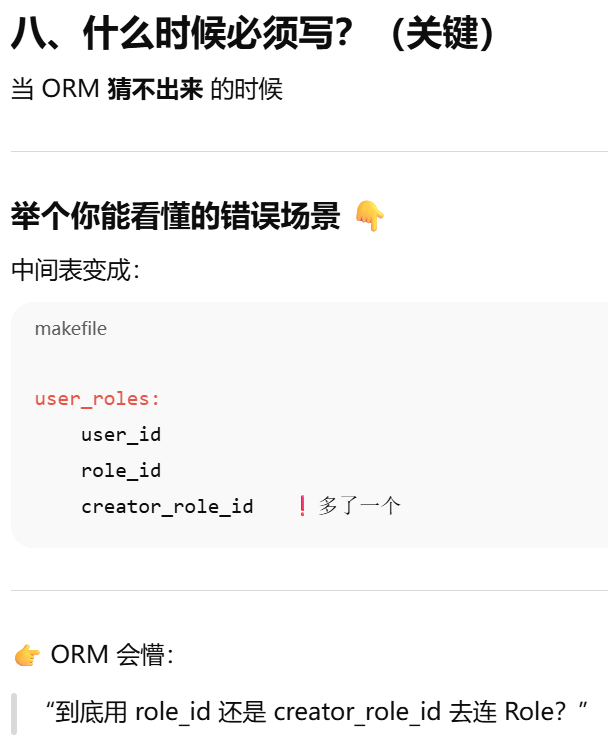


primaryjoin / secondaryjoin

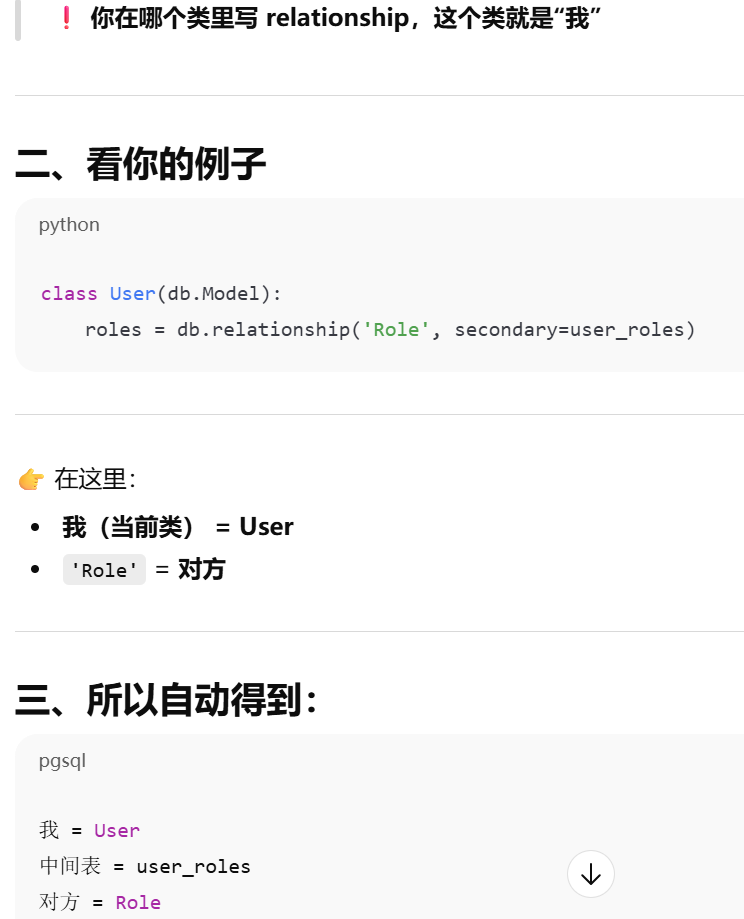



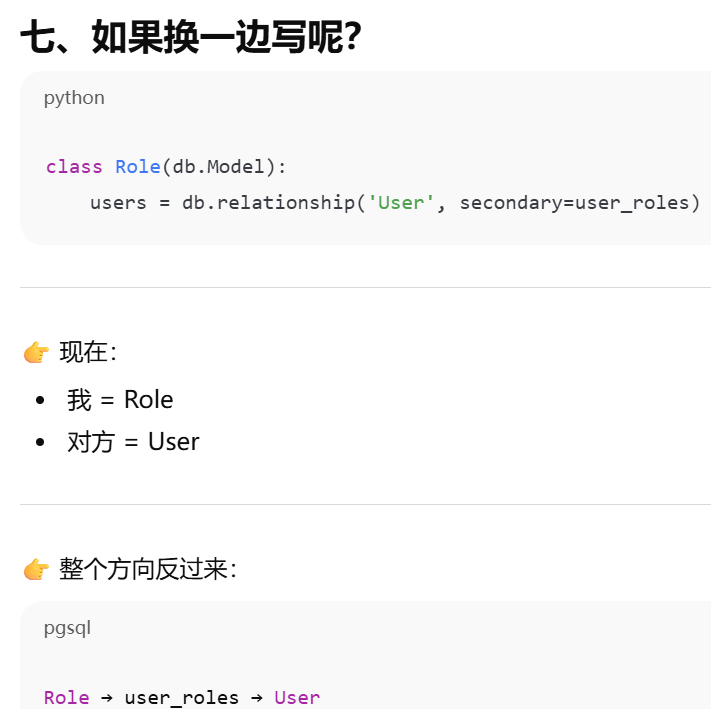

primaryjoin 是指 第一段连接,不一定是怎么和中间表连,只有多对多才是怎么和第一张表连,一对多就是怎么 和对方连。secondaryjoin = 第二段连接(只有多对多才有)


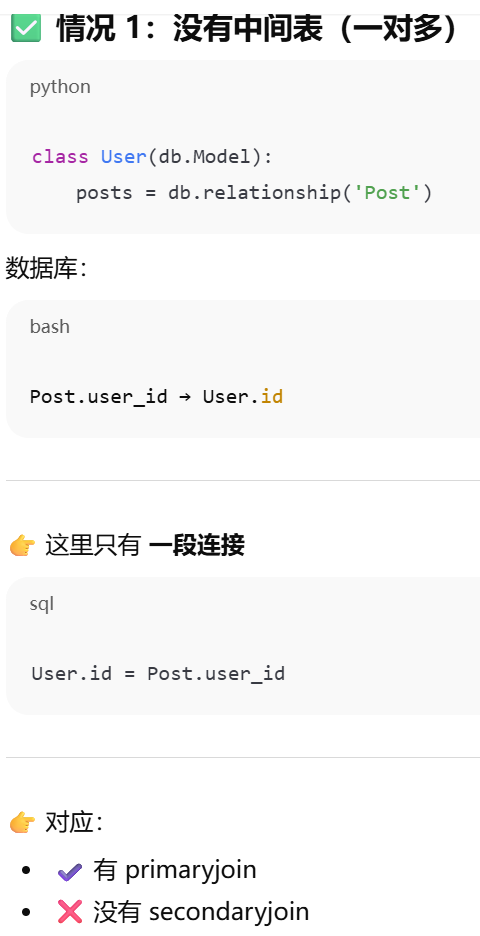

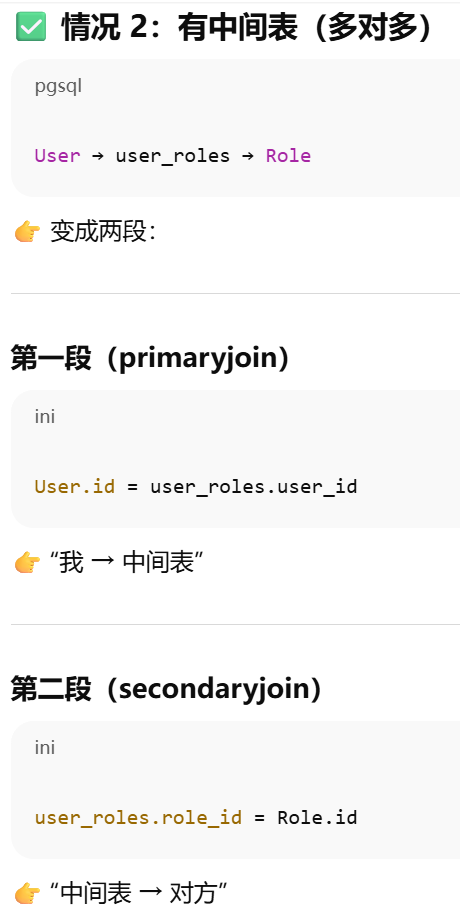


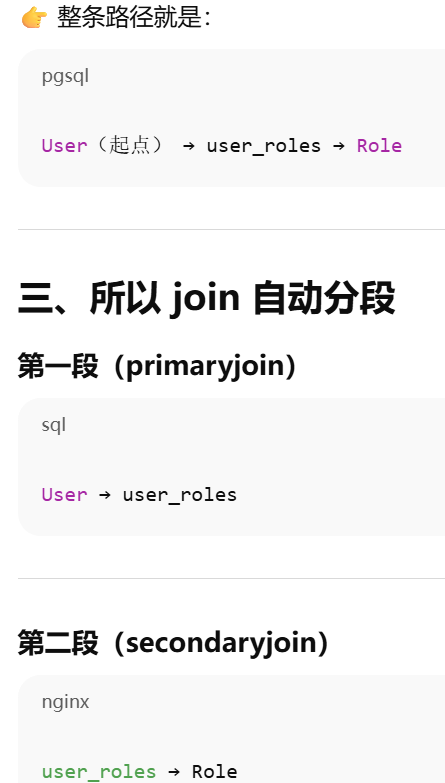

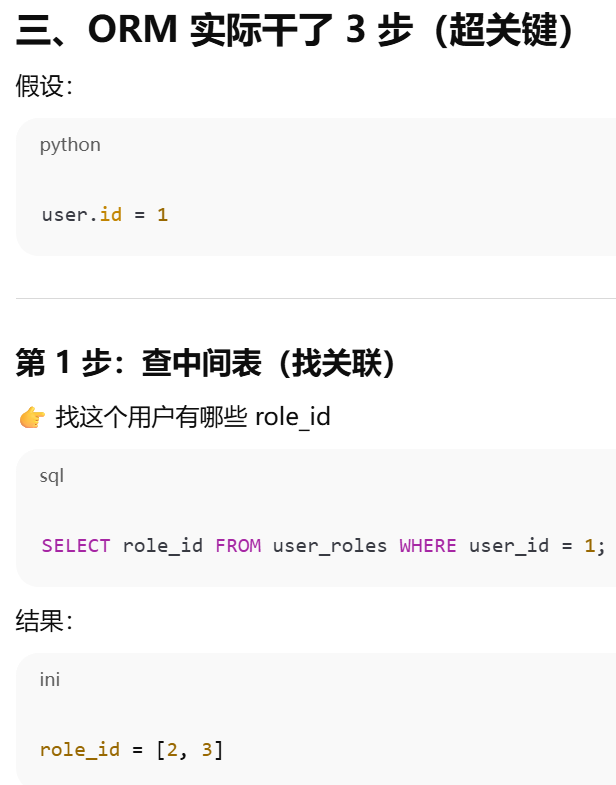

靠外键建立联系。它根据 ForeignKey 自动推断 JOIN 条件




relationship 返回的到底是什么?属性描述器


返回值具体是什么?取决于关系类型
父对象的 relationship 属性是列表,列表里是单个子对象
子对象的 relationship 属性是单个父对象



怎么知道是一对多还是多对一的关系?看外键在哪一边

把外键和db.relationship()都放在"多"这一侧




连接数据库的工具:DBeaver (Community Edition)

下载安装
5.8 数据库操作
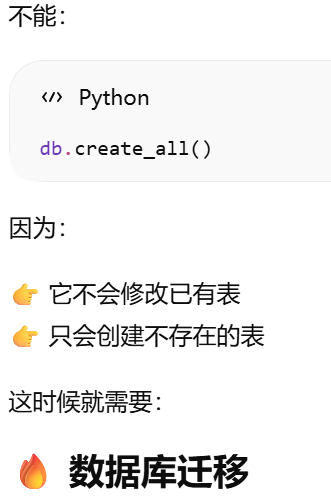
5.8.1 创建表 db.create_all()
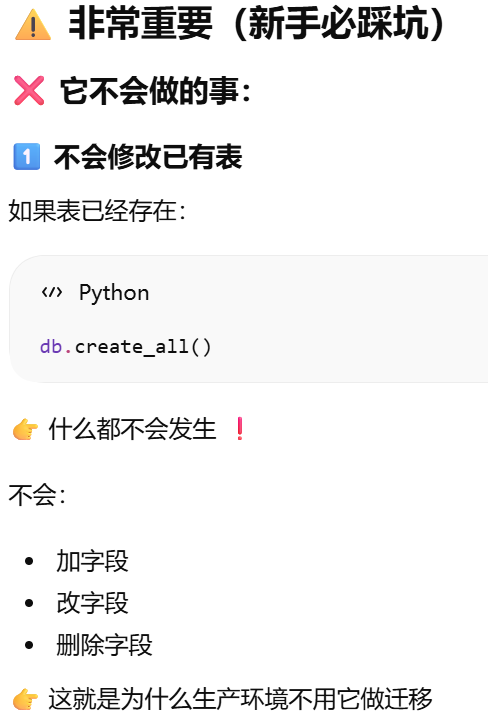
db.create_all()不会重新创建或者更新相应的表






5.8.2 插入行
数据库Session(会话)。也称事务

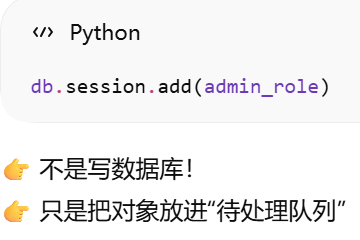
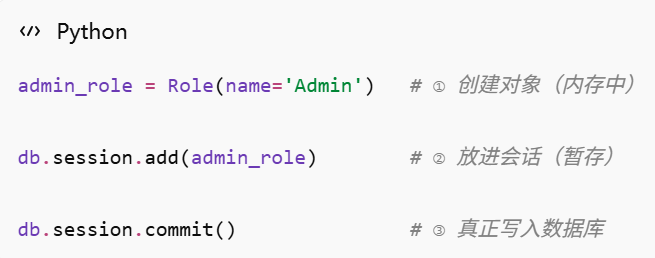
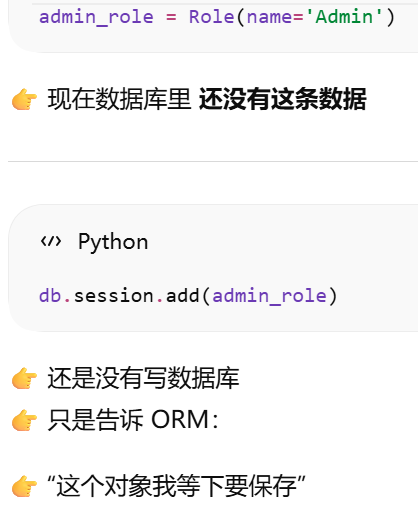

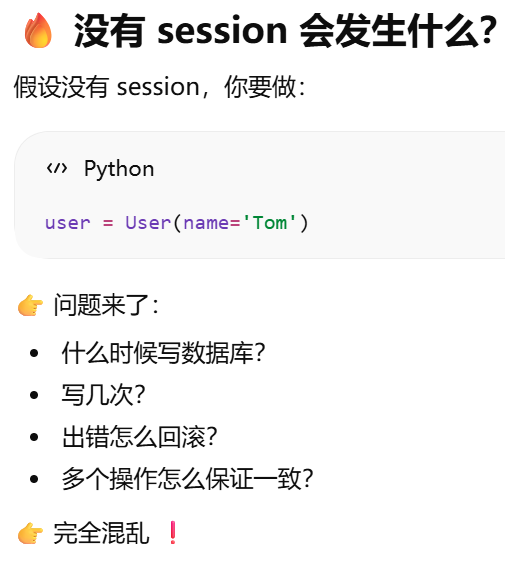
为什么必须要有 session?

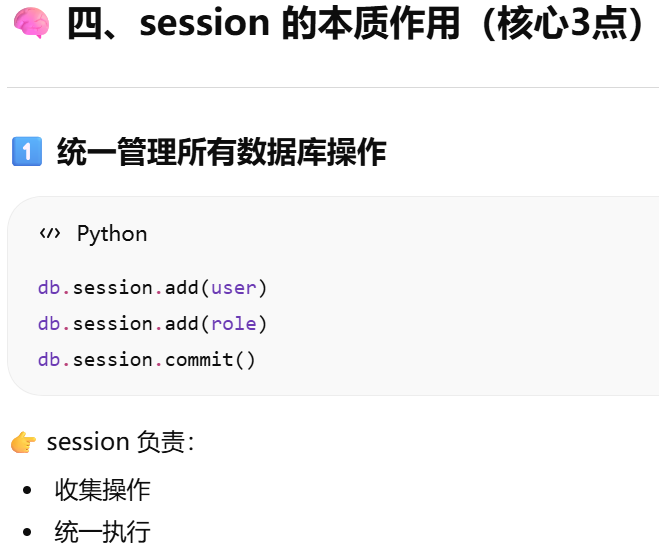


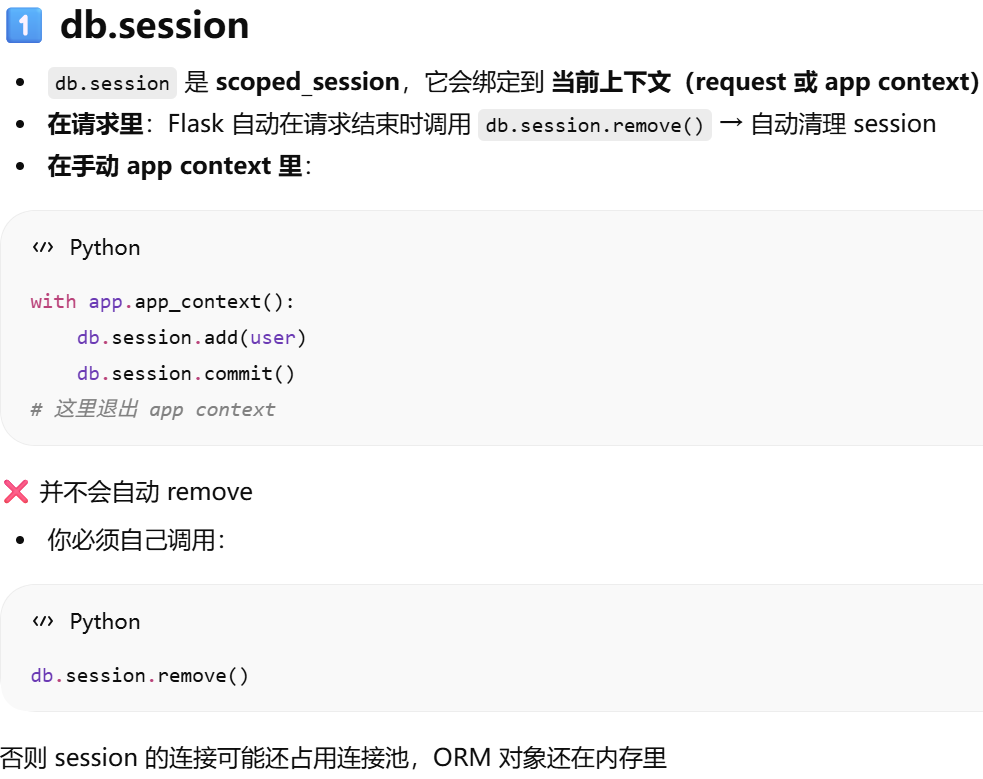
为什么是 db.session?当前 Flask 应用绑定的数据库db,操作的会话

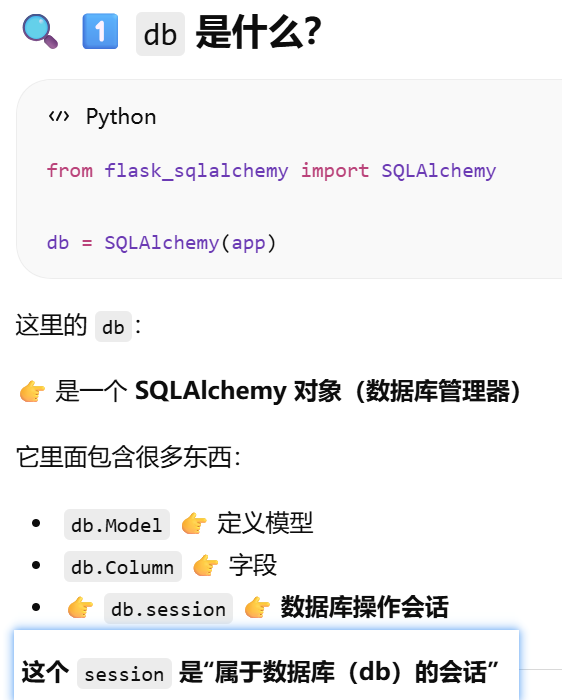
session 是绑定在 SQLAlchemy 实例上的

Flask-SQLAlchemy session 的绑定规则.不同代码块的应用上下文,对应的session不一样

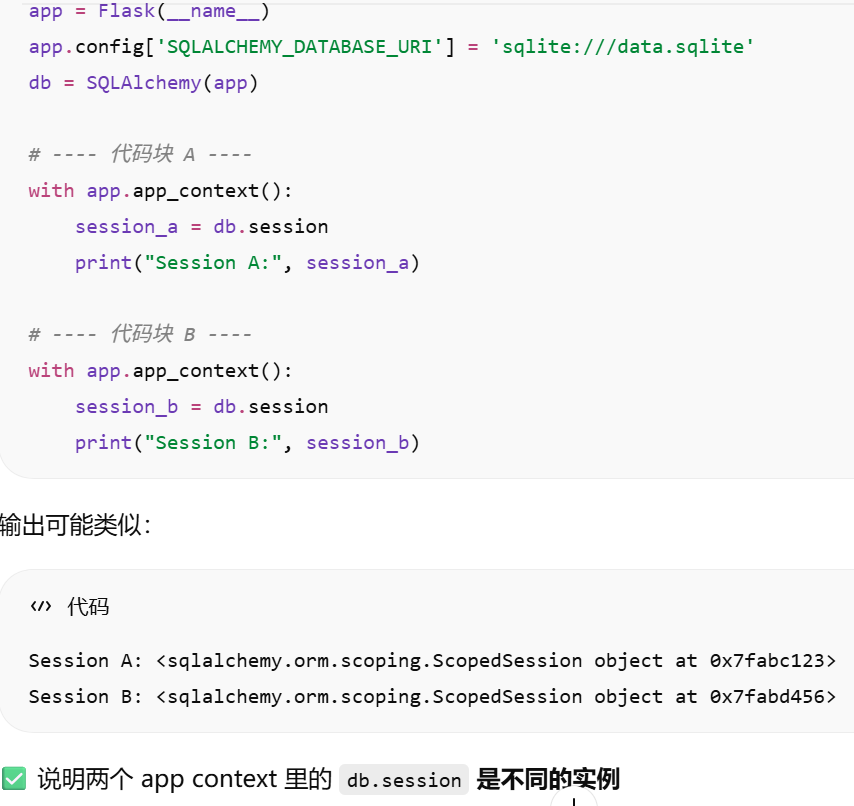


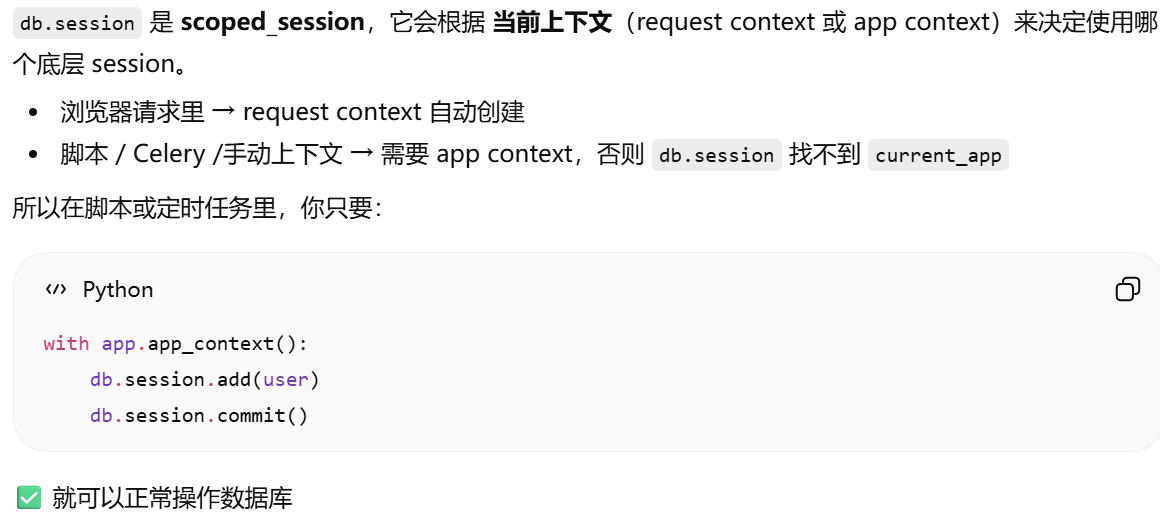
db.session = "当前请求专属的数据库会话"。只要不在请求里,用 db.session 就必须加 app.app_context()
一个请求 = 一个 session
浏览器请求 → Flask → db.session → 数据库 请求结束:
👉 session 自动清理


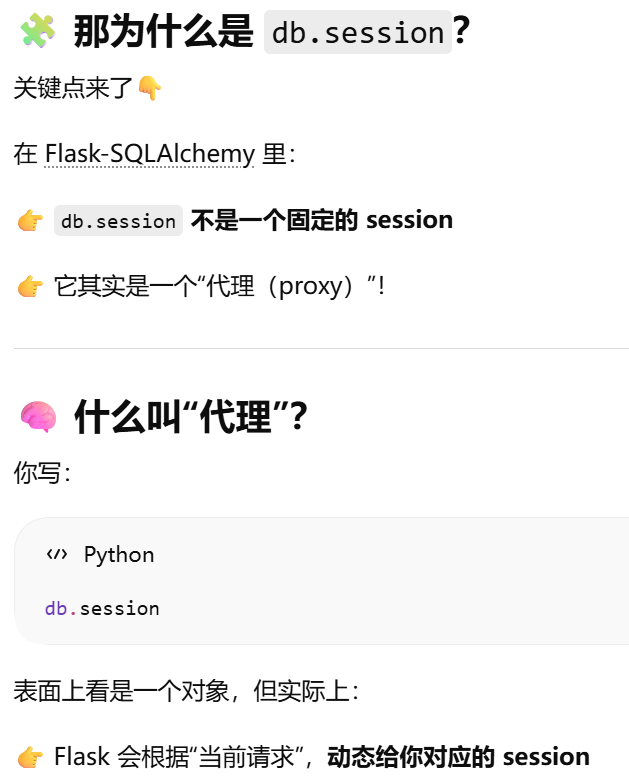


db.session 依赖 Flask 的"应用上下文(app context)


那什么时候"自动有上下文"?
没有上下文需要手动加上下文。只要不在请求里,用 db.session 就必须加 app.app_context()




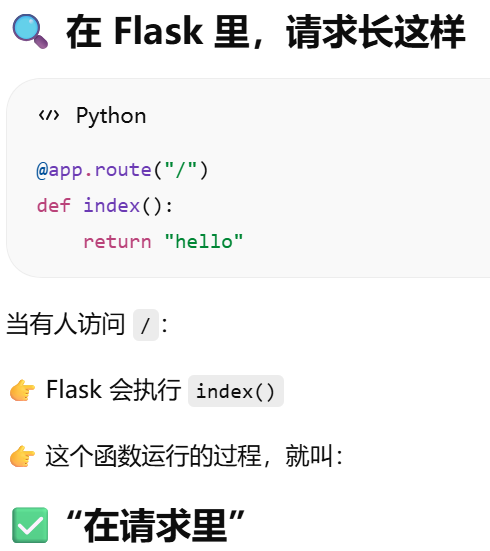

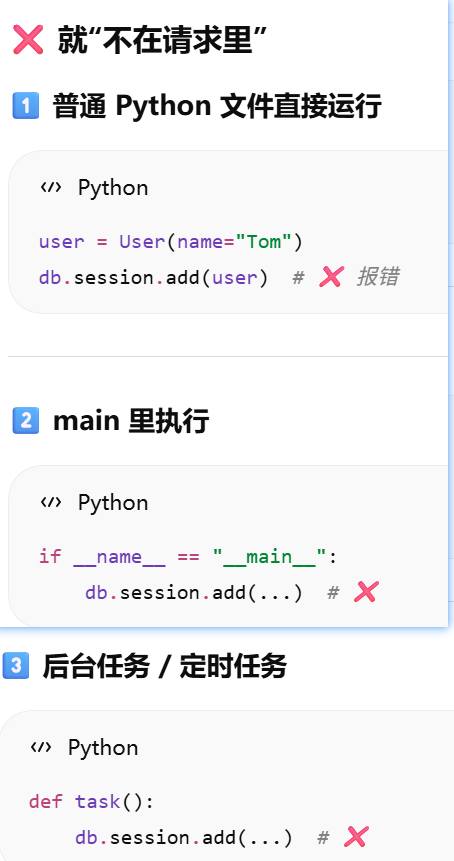
为什么"请求里"就可以用 db.session?处理请求flask会自动创建上下文

"请求来了之后,Flask 内部到底发生了什么?"




Flask 有两种上下文:请求时自动创建(最常见).你可以手动创建(app.app_context())
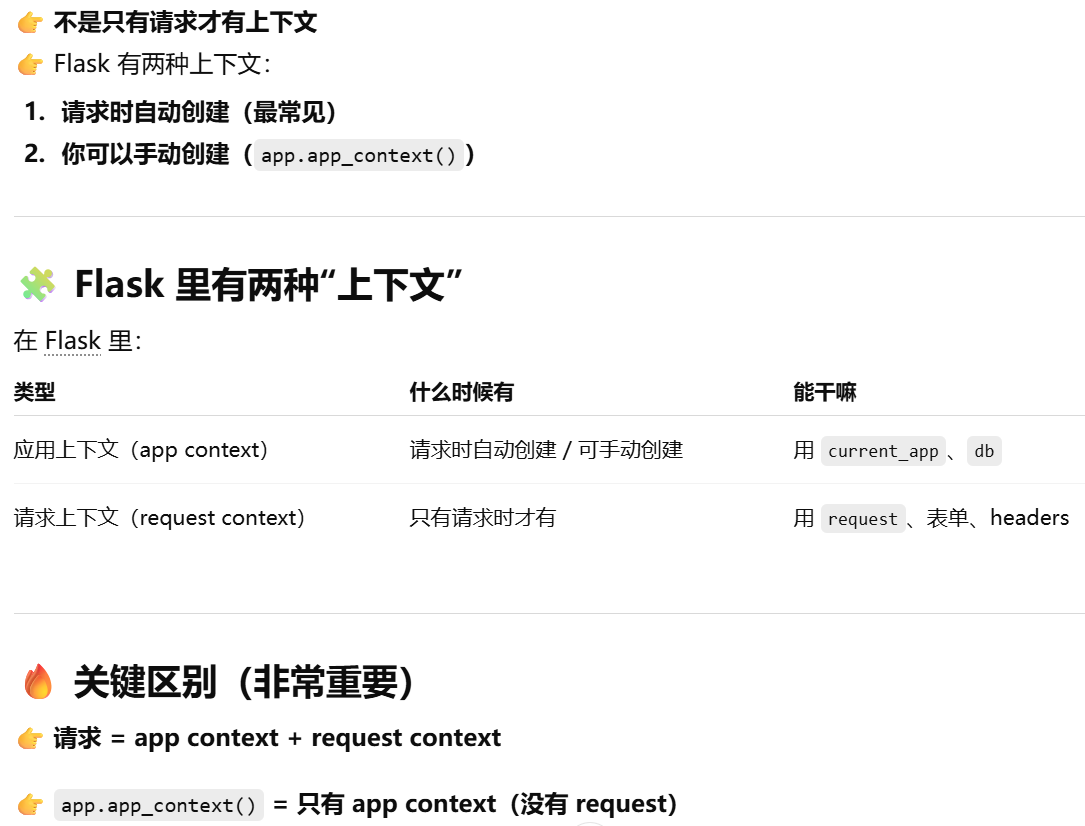
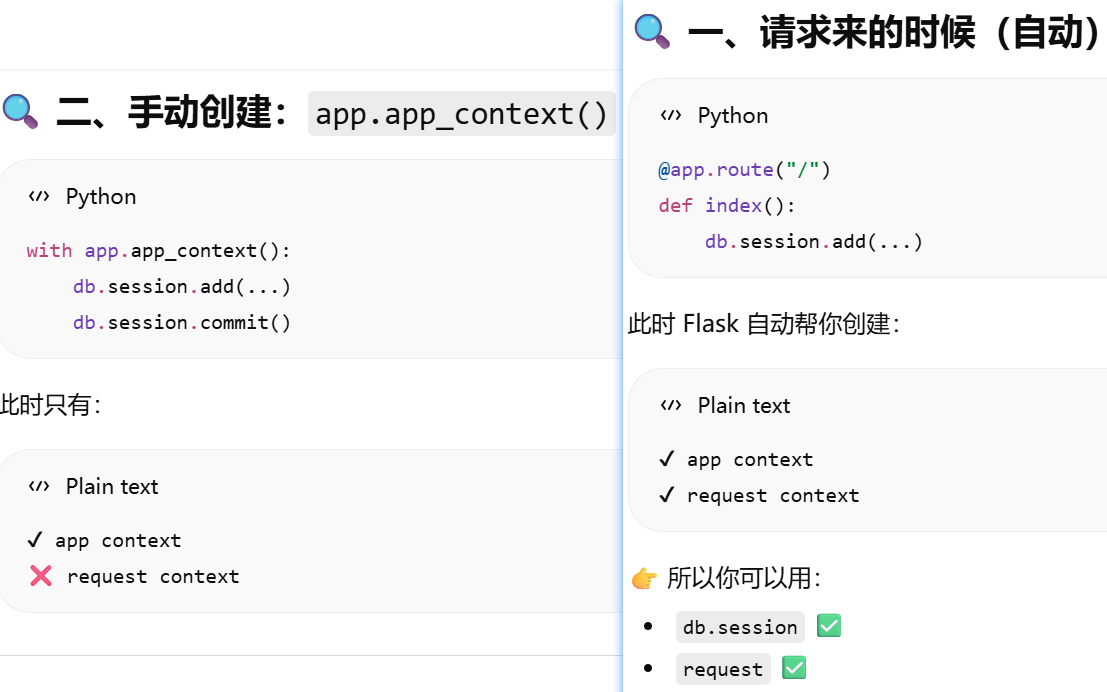

为什么要有app.app_context()?给flask提供在哪个应用里操作,这样session等可以工作






还有别的 session 吗?

引擎:是 SQLAlchemy 在数据库驱动之上的一层封装



Flask-SQLAlchemy 已经自动创建了 engine 和 db.session,如果我想自己手动创建一个新的 session,但还是用这个 engine,该怎么操作?





如果不是浏览器的请求,就不用db.session? 比如有定时任务,需要操作数据库,用什么session?
Web 请求
Flask 自动:
创建 context → 提供 db.session → 自动销毁
⚙️ 定时 任务
你自己:
创建 context → 使用 db.session → 手动控制
使用 db.session






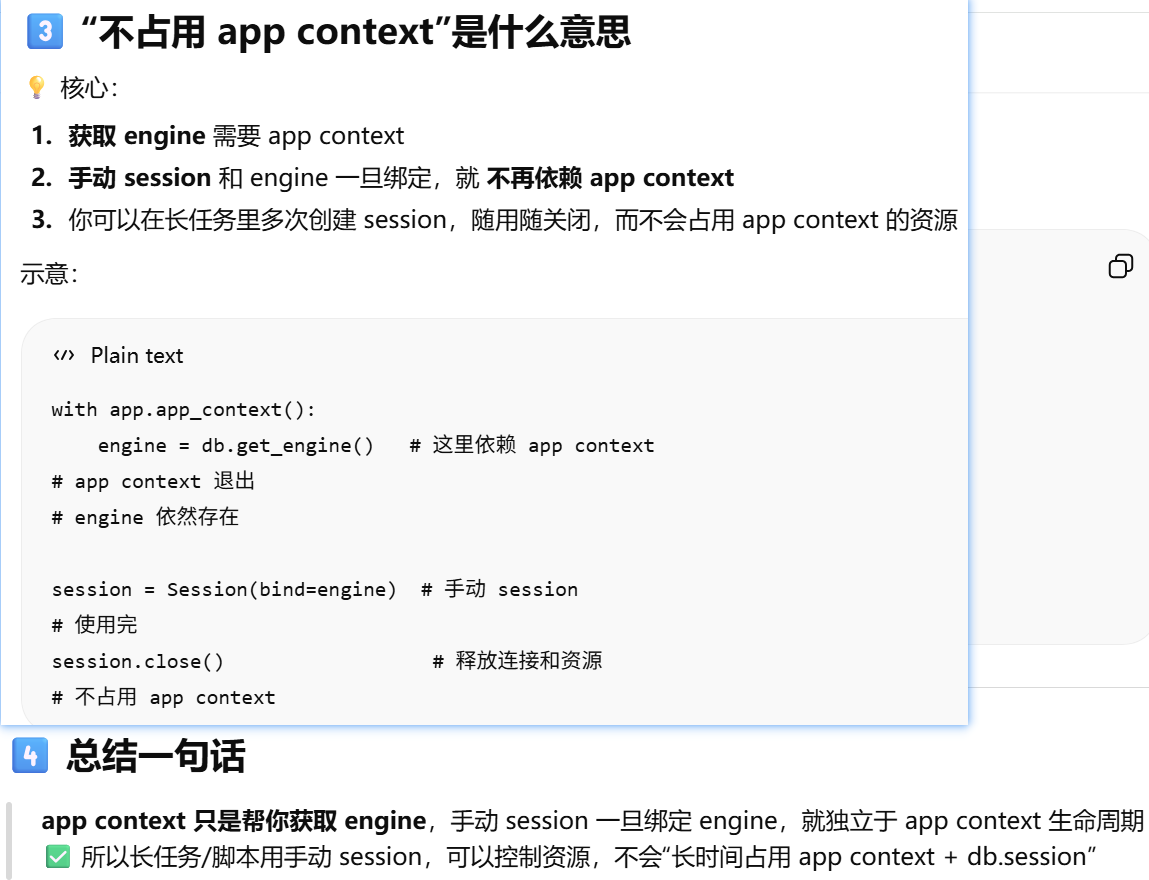

手动创建 session

p
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy.orm import sessionmaker
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///data.sqlite'
db = SQLAlchemy(app)
with app.app_context():
engine = db.get_engine()
Session = sessionmaker(bind=engine)
def celery_task():
session = Session()
try:
user = User(name="Alice")
session.add(user)
session.commit()
except Exception:
session.rollback()
raise
finally:
session.close()手动关闭session







事务=一组必须"要么全部成功,要么全部失败"的数据库操作。session是事务的容器




事务失败后 必须手动 db.session.rollback()









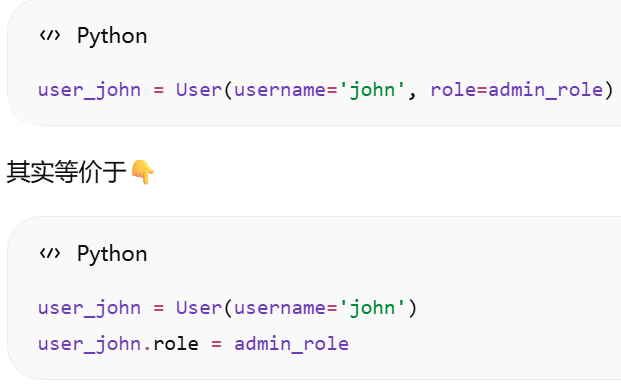
user_john = User(username='john', role=admin_role)

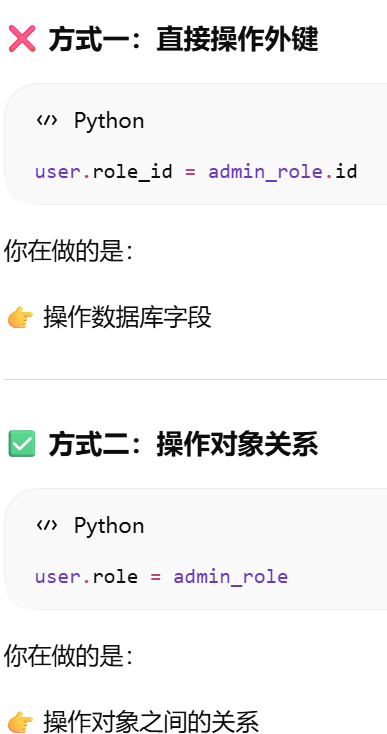

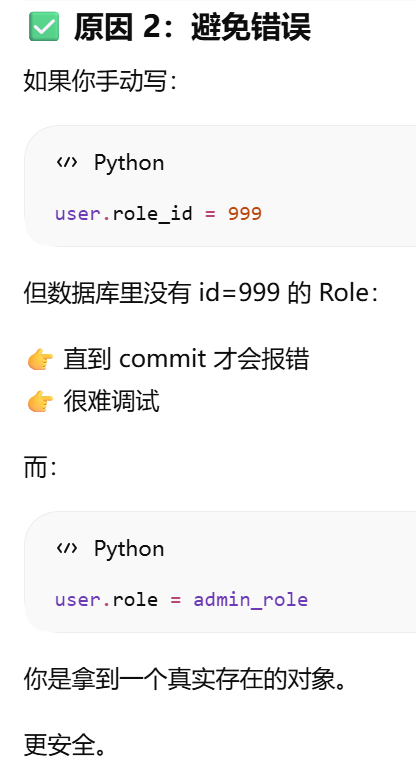
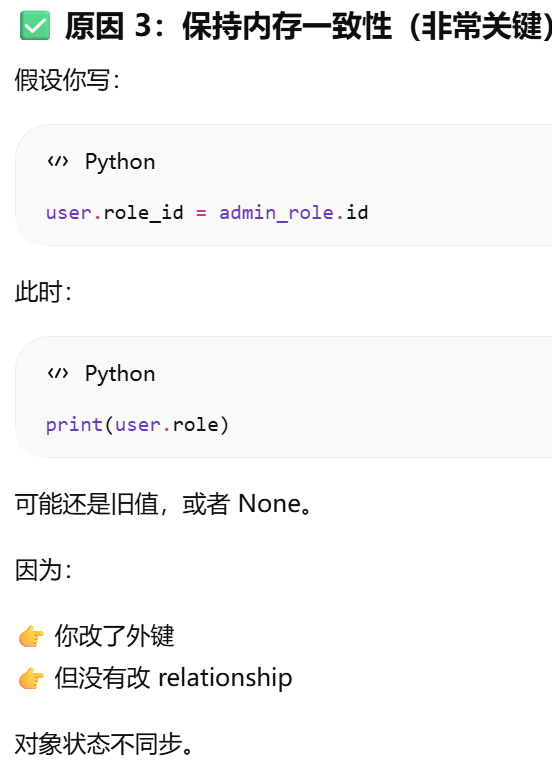

在 flask shell 里,其实已经自动帮你推入了 app context。所以你才能直接用:db.session.add(admin_role)而不报错。




add_all,参数是一个"可迭代对象"(iterable)



5.8.5 查询行
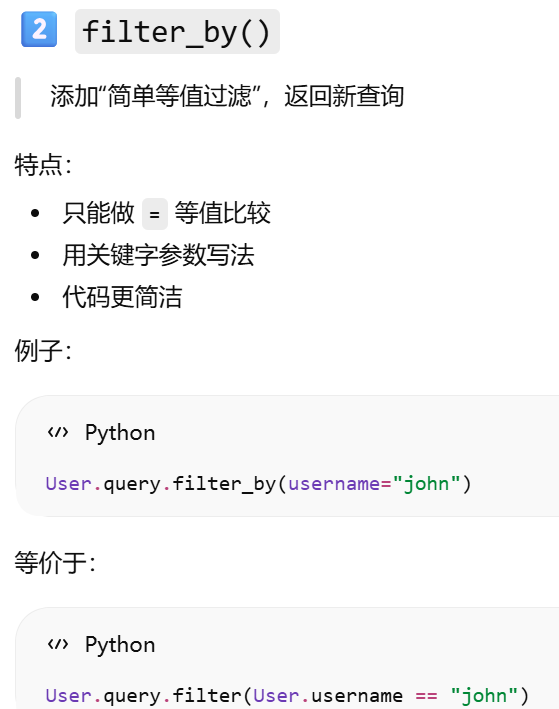
filter_by(...)
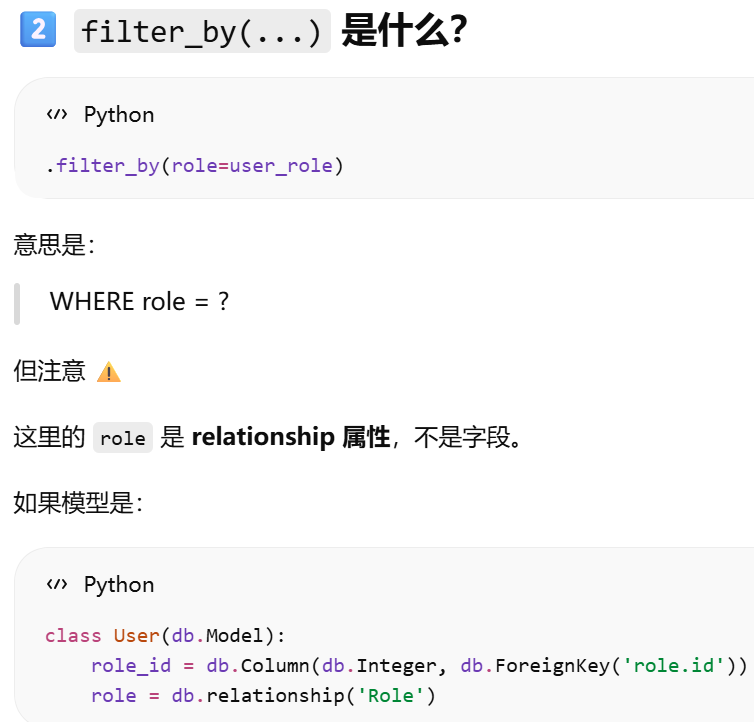




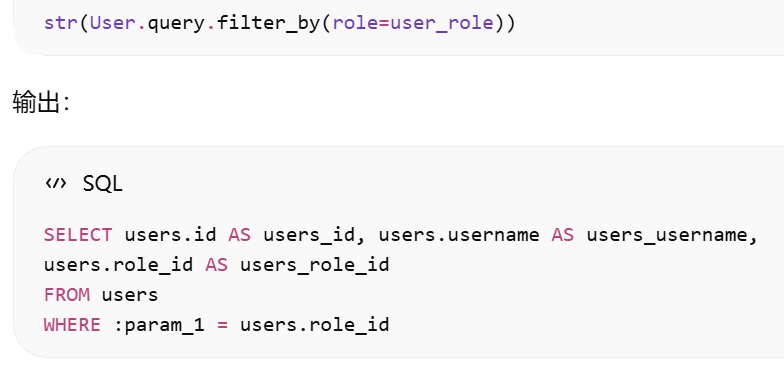
若想查看SQLAlchemy为查询生成的原生SQL查询语句,只需把query对象转换成字符串










filter()


filter_by()

limit(n)

offset(n)

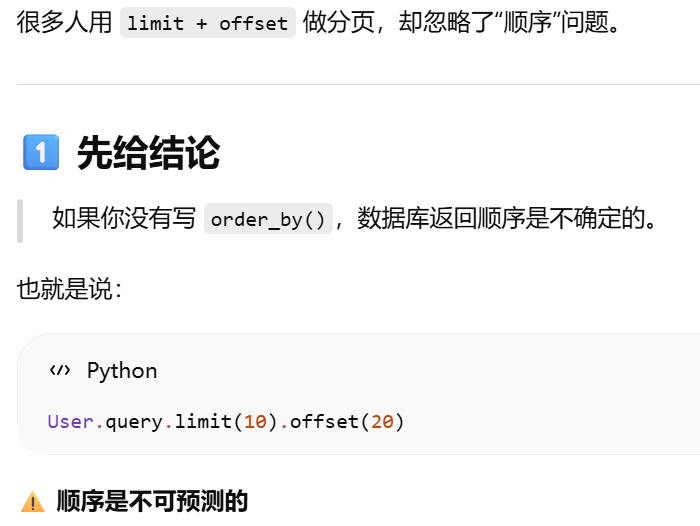

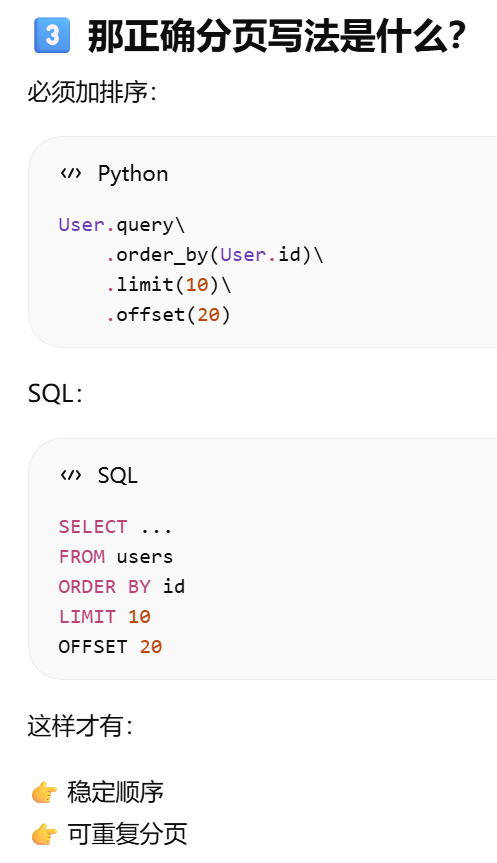

order_by()

group_by()















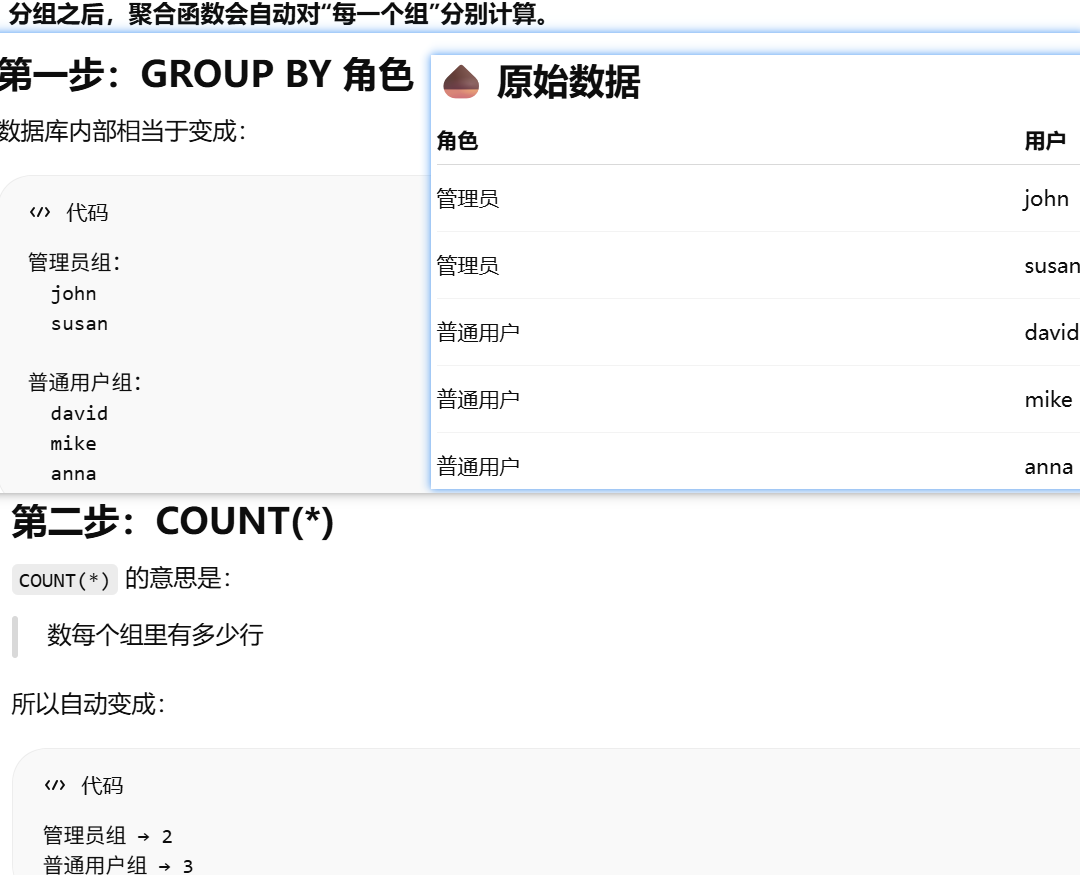
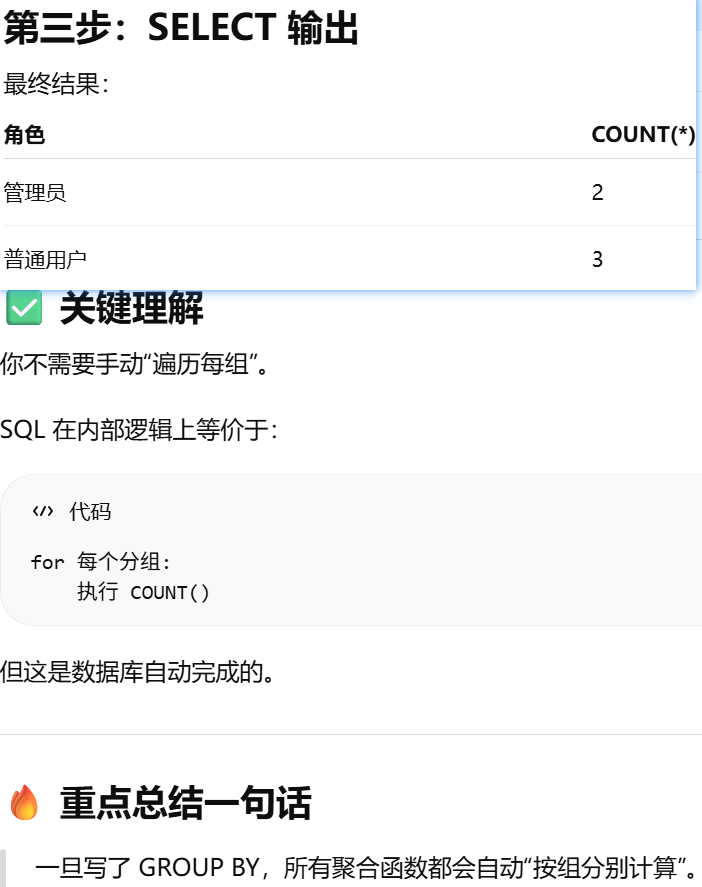
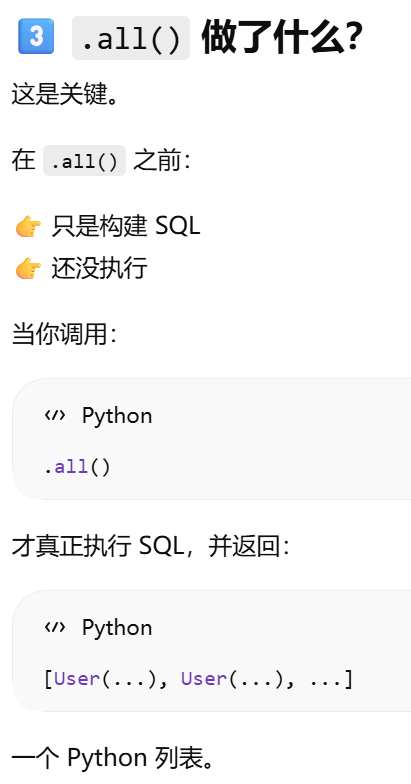
真正"执行查询"并返回结果的方法


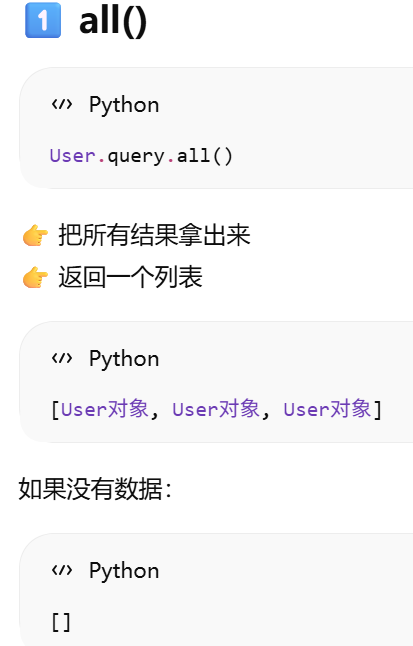
all
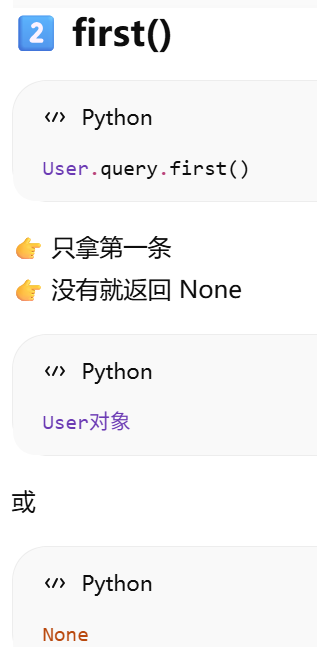
first
first_or_404

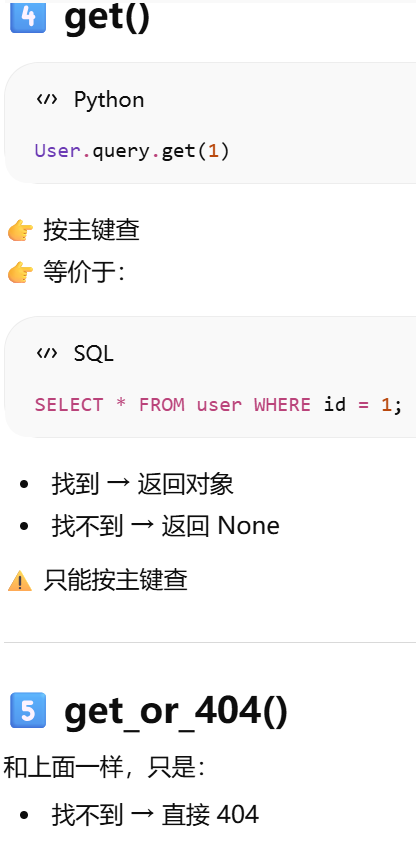
get

get_or_404
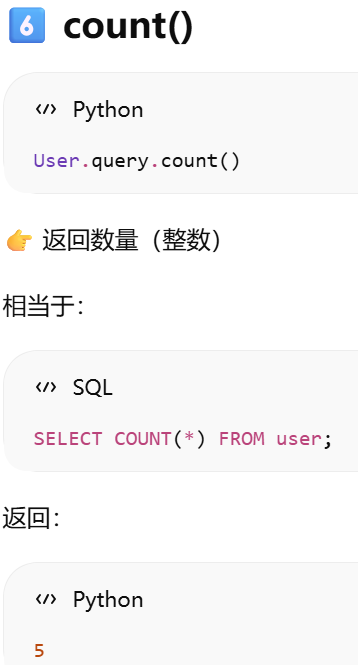
count
paginate





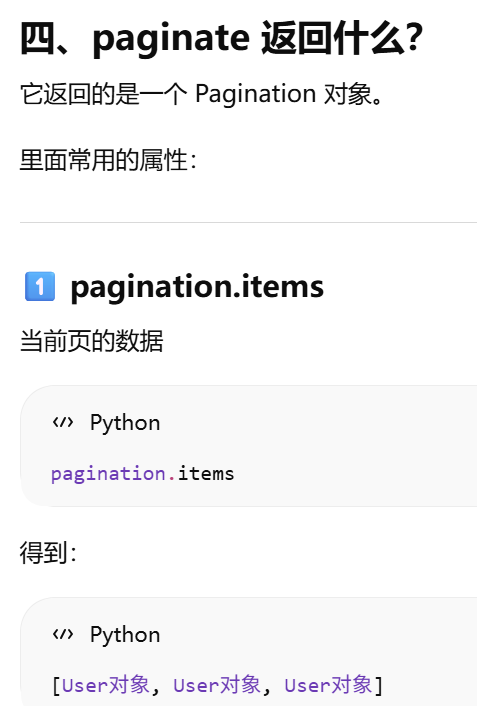


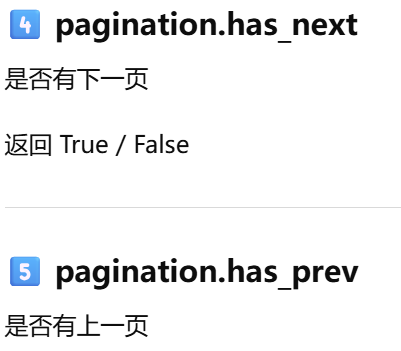




5.10 集成Python shell。shell_context_processor 是给 Flask shell 预加载变量用的








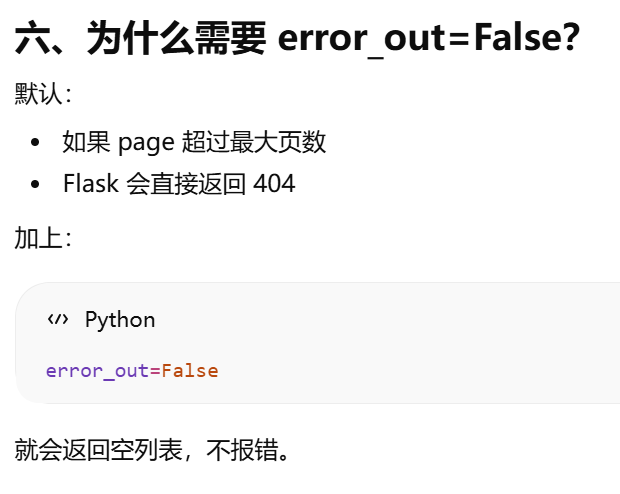
5.11 使用Flask-Migrate实现数据库迁移
5.11.1 创建迁移仓库
migrate = Migrate(app, db)把 Flask 应用 和 SQLAlchemy 数据库 绑定到 Flask-Migrate。

什么是数据库迁移?

flask db init 初始化 Alembic(迁移引擎)


正常迁移流程







5.11.2 创建迁移脚本
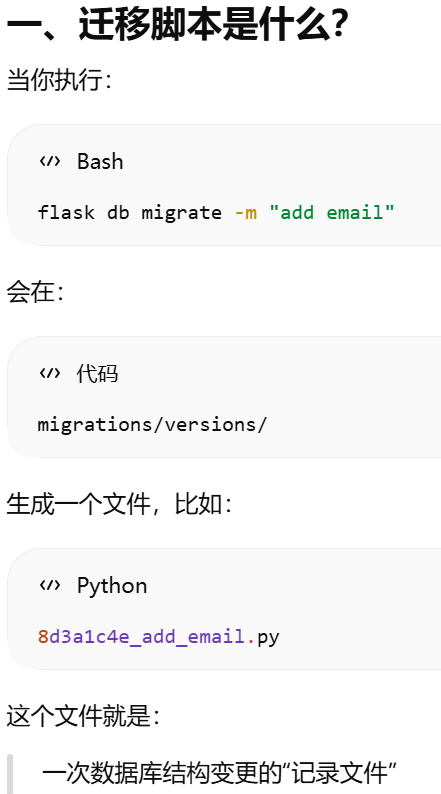





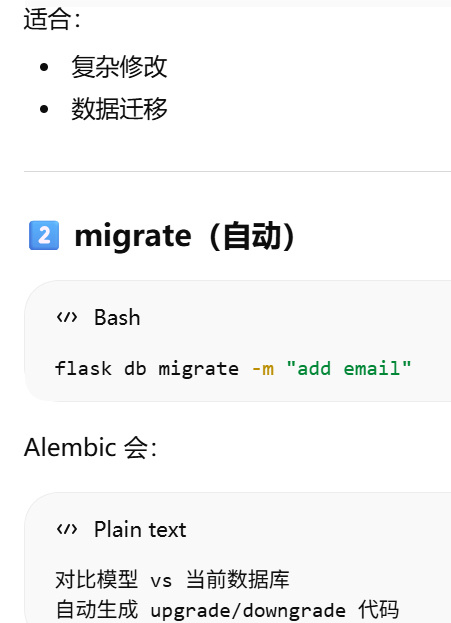





Alembic 的 版本管理和迁移逻辑
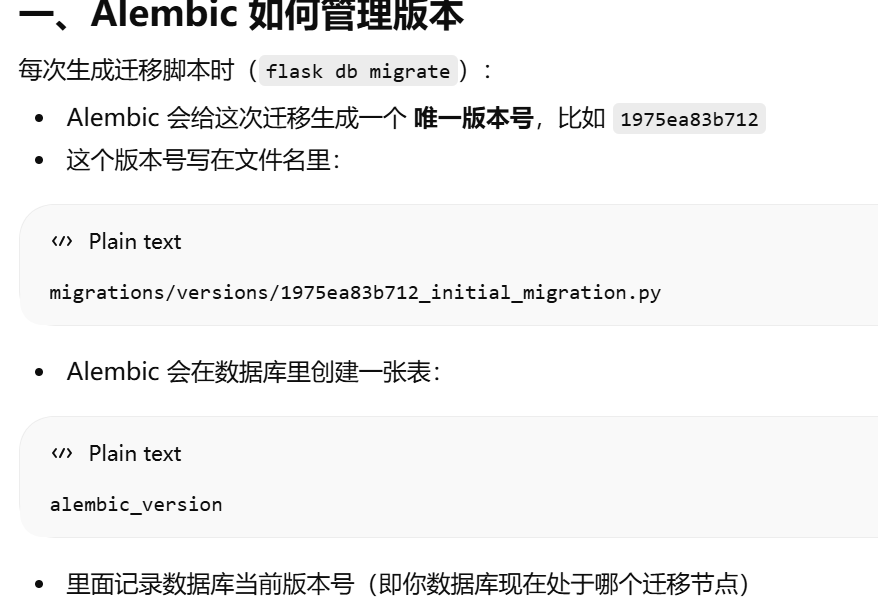
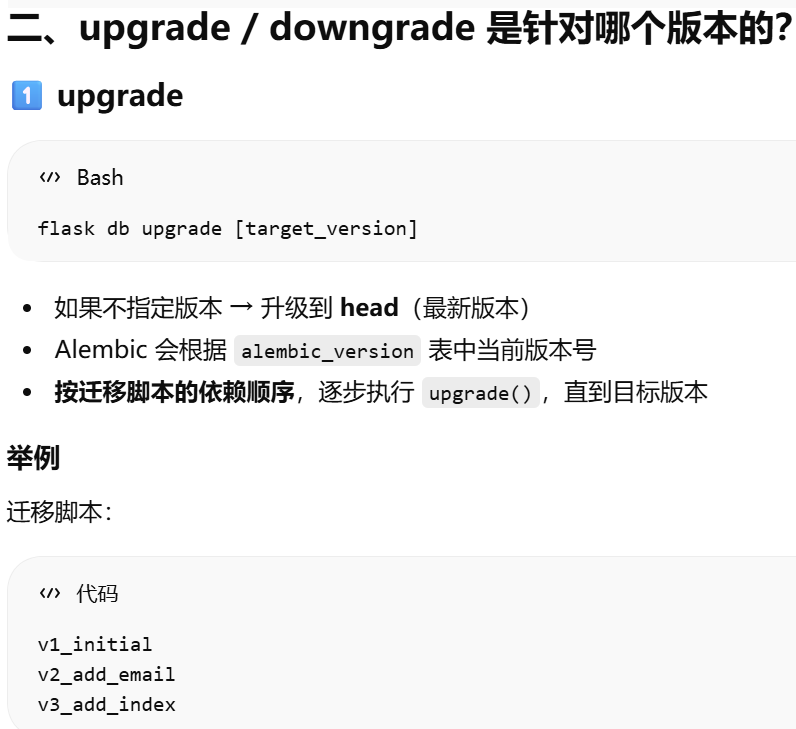









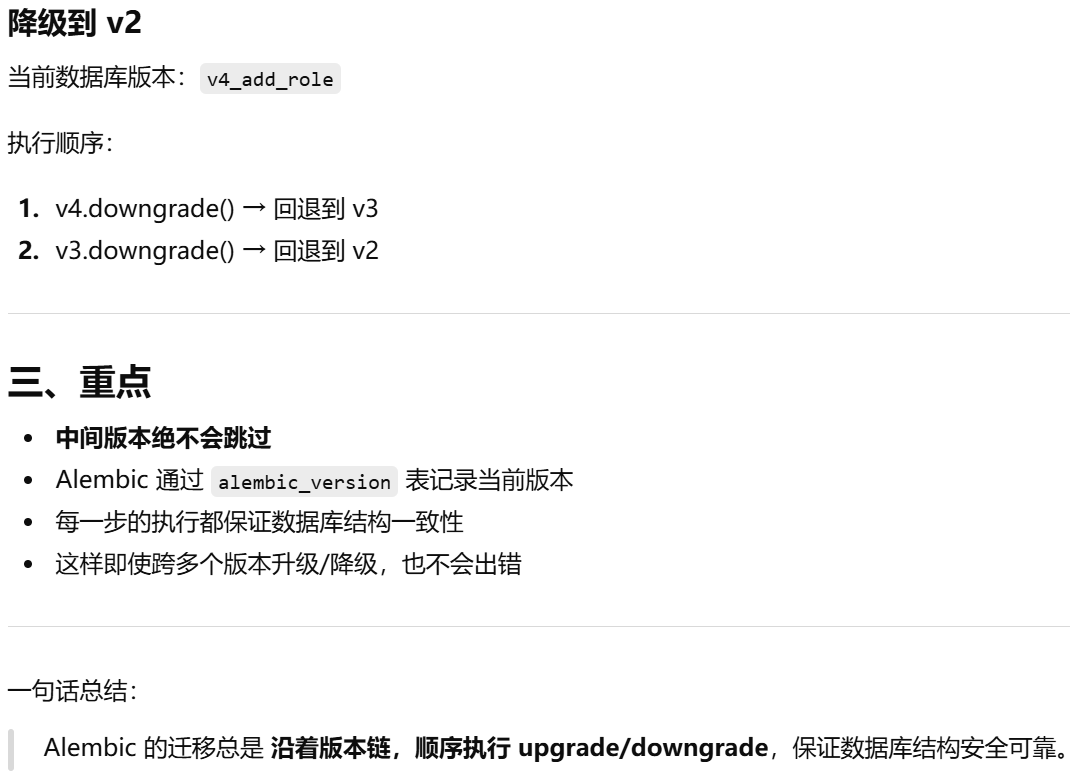
flask db migrate -m "initial migration"


5.11.3 更新数据库
使用 flask db stamp 标记数据库

