在生成式 AI 的浪潮中,我们见证了从 Stable Diffusion 到 FLUX、Qwen-Image 等大规模扩散模型的画质飞跃。然而,这种飞跃并非没有代价。为了从纯噪声中 "雕刻" 出清晰的图像,这些模型通常需要进行 40 到 100 步(NFE)的迭代去噪。这种延迟使得模型很难真正应用于实际的实时生成或大规模服务。
于是,"少步生成"(Few-step Generation)成为了必争之地。对于原本教师模型曲折的生成轨迹,目前的少步加速方案(如 Progressive Distillation, Distribution Matching 等)都在试图做同一件事:把弯路拉直,一步到达终点。
然而,原本高维空间的生成轨迹极其复杂,强行 "拉直" 会导致轨迹上的几何失配(Geometric Mismatch)。这直接导致了少步生成时的结构崩坏和细节丢失。
有没有一种方法,既能快,又能顺应原本蜿蜒的生成轨迹?
复旦大学与微软亚洲研究院带来的 ArcFlow 给出了答案:如果路是弯的,那就学会 "漂移",而不是把路修直。

一、 困境:为什么 "走直线" 难以学习?
在扩散模型中,教师模型(Pre-trained Teacher)的生成过程本质上是在高维空间中求解微分方程并进行多步积分。由于图像流形的复杂性,教师模型原本的采样轨迹通常是一条蜿蜒的曲线,其切线方向(即速度场)随时间步不断变化。
为了加速,现有的蒸馏方法(如 Progressive Distillation, Instaflow 等)尝试将这个轨迹压缩成一步直线抵达。它们的逻辑是:既然走曲线慢,那就训练学生模型,把起点(噪声)和终点(图像)之间连成一条直线。如果学生能学会走这条直线,那推理不就只需要一步了吗?
这种策略带来了两个致命问题:
-
几何失配(Geometric Mismatch):教师模型原本的权重是基于曲线轨迹训练出来的。强行让学生模型去拟合一条直线,相当于让它 "背叛" 教师原本的生成先验。这种几何上的不匹配,导致学生模型很难学,或者学出来的东西结构崩坏。
-
学习成本高:为了强行扭转轨迹,学生模型往往需要进行全参数微调(Full Fine-tuning)。这不仅训练慢、显存开销大,而且容易导致 "灾难性遗忘",破坏大模型原本优秀的泛化能力。
所以我们经常看到:很多蒸馏后的模型,虽然速度快了,但生成质量不稳定,甚至对复杂的 Prompt 理解能力下降。
如果不强制拉直,我们还能怎么快起来?
二、 洞察:速度场不是随机的,它是连续的
ArcFlow 团队重新审视了教师模型的轨迹,根据 ODE 的理论规律,在相邻的时间步之间,去噪的速度方向并不是跳跃式变化的,而是存在极强的相关性。这就像一辆赛车在过弯道,下一秒的方向和速度,很大程度上取决于当前秒的状态和惯性。既然教师模型的轨迹本身就是连续变化的,为什么我们不直接去建模这种 "变化规律",而不是强行把它改成直线呢?
如果我们能找到一种参数化方法,能够描述这种 "弯曲" 的趋势,那么学生模型就不需要费力去把路拉直,而是可以顺着教师的势能,用极少的步数 "滑" 向终点。
基于这个核心洞察,ArcFlow 诞生了。
三、 ArcFlow 的三大杀手锏
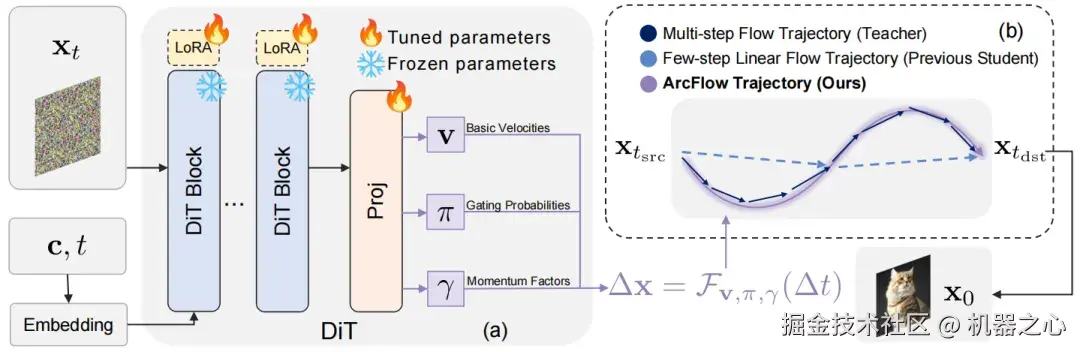
- 动量参数化(Momentum Parameterization):给生成过程加个 "惯性"
为了捕捉上述的 "速度连续性",ArcFlow 引入了物理学中经典的 "动量"(Momentum)概念。
在传统方法中,模型在每个时间步独立预测速度。而在 ArcFlow 中,我们将速度场建模为多个连续动量过程的混合。通俗来说,模型不仅预测当前的 "速度",还预测了一个 "动量因子"(Momentum Factor)。这个因子描述了速度随时间衰减或增强的趋势。这就好比我们知道了物体的初速度和受力情况(动量),哪怕不看中间过程,我们也能通过物理公式直接预判它未来的轨迹是弯曲的还是笔直的。
这一设计让 ArcFlow 能够显式地构建非线性轨迹。在 2-4 步的极少步数下,这种非线性轨迹比生硬的直线能更精确地贴合教师模型的原始路径。
- 解析求解器(Analytic Solver):数学层面的 "零误差"
既然已经用 "动量公式" 完美定义了速度随时间的演变规律,那么这条轨迹的积分就是可解析的。
也就是说,我们可以推导出一个闭式解(Closed-form Solution)。
这意味着,ArcFlow 不需要像传统求解器那样通过离散步去拟合轨迹。它只需要一次前向传播,就能通过数学公式,精确无误地计算出任意时间间隔后的终端状态。
这种数学层面上的 "零误差" 积分,是 ArcFlow 能够实现高精度流匹配的关键。它消除了传统蒸馏方法中的离散化噪声,让生成的图像细节清晰。
- 极简训练策略:<5% 参数的 LoRA 微调
这是最让开发者兴奋的一点。
正如前文所说,传统方法因为要 "强行拉直" 轨迹,不得不重写整个模型的参数。而 ArcFlow 选择 "顺势而为",它的非线性轨迹天然契合教师模型的预训练分布。
因此,ArcFlow 不需要破坏教师模型原本的参数。实验证明,仅需通过 LoRA 微调不到 5% 的参数(主要是为了适应新的动量预测头),就能实现完美的轨迹对齐。
这种策略带来了两大红利:
-
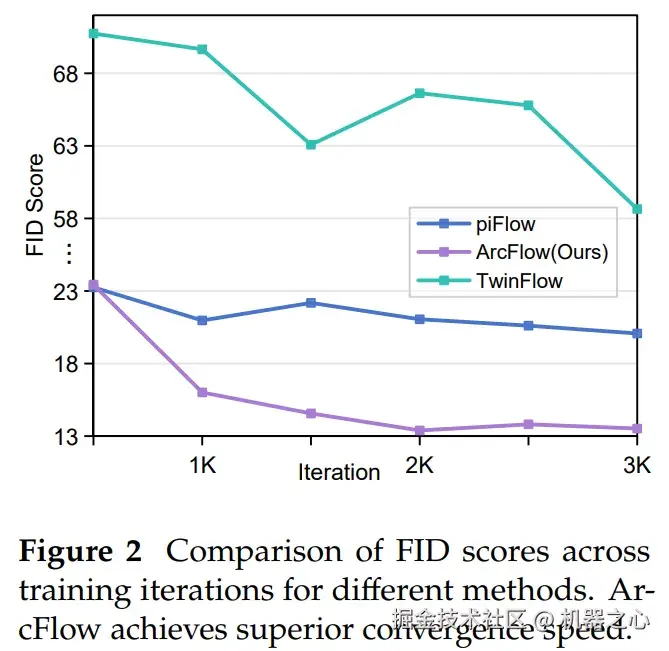
训练收敛极快:相比 TwinFlow 等全量微调方法,ArcFlow 的收敛速度快了超过 4 倍。
-
保留教师先验:最大程度继承了 FLUX/Qwen 原本庞大的知识库,不像其他蒸馏模型那样容易出现崩坏或画质劣化。
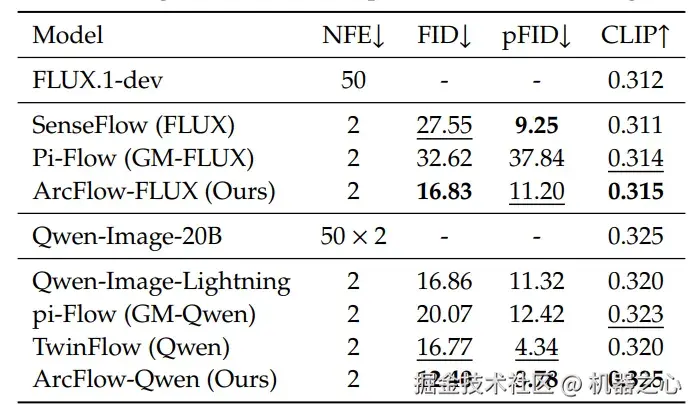
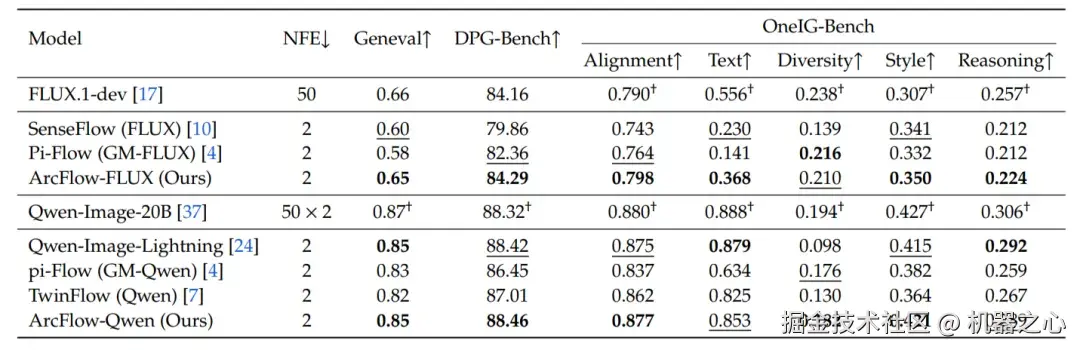
四、 实验数据
团队在 Qwen-Image-20B 和 FLUX.1-dev 这两个目前最强的开源模型上进行了验证。结果表明,ArcFlow 在速度、质量和效率上实现了的平衡。
- 推理速度
从原始的 50-100 步迭代,直接压缩至 2 步(2 NFE)。在相同硬件上,实现了超过 40 倍加速。
- 画质表现
在 Geneval、DPG-Bench 等基准测试中,ArcFlow 在 2 步设定下的 FID 和语义一致性得分大部分优于或持平目前的 SOTA 方法。
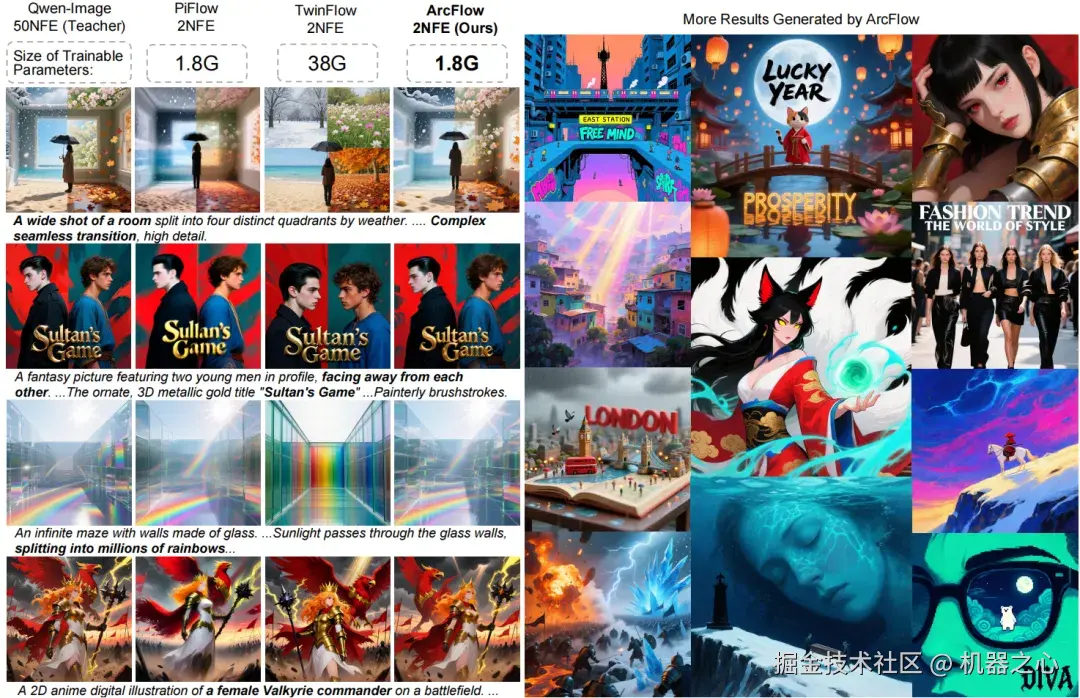
视觉对比:
从论文展示的效果图来看,在同样的 2 步推理下,其他线性蒸馏方法生成的图像容易出现背景模糊、物体结构扭曲(如折断 / 重影的剑、模糊的背景),尤其是在不同的初始噪声下,其他方法容易出现生成模式相似、多样性坍缩的情况。而 ArcFlow 生成的图像不仅清晰度高,而且保留了教师模型原本的丰富细节和画面多样性。

- 训练效率
得益于更精准的轨迹拟合和 LoRA 策略,ArcFlow 的训练曲线令人赏心悦目。在相同迭代步数下,ArcFlow 的 FID 分数和画面质量大幅领先。对于没有大规模算力的实验室或个人开发者来说,这大大降低了复现和定制的门槛。

- 更多效果展示



五、 总结
ArcFlow 提出了一种新的少步蒸馏的解决思路:相较于 "把曲线拉直" 的 "蛮力",不如顺应原本的模型特征空间,用参数去描述其复杂性。通过动量参数化和解析求解器,ArcFlow 避免了不稳定的对抗性目标函数和全参数训练,从而实现了更快的收敛速度和更高效的蒸馏过程。这为未来的高效生成模型研究提供了一个极具潜力的方向。