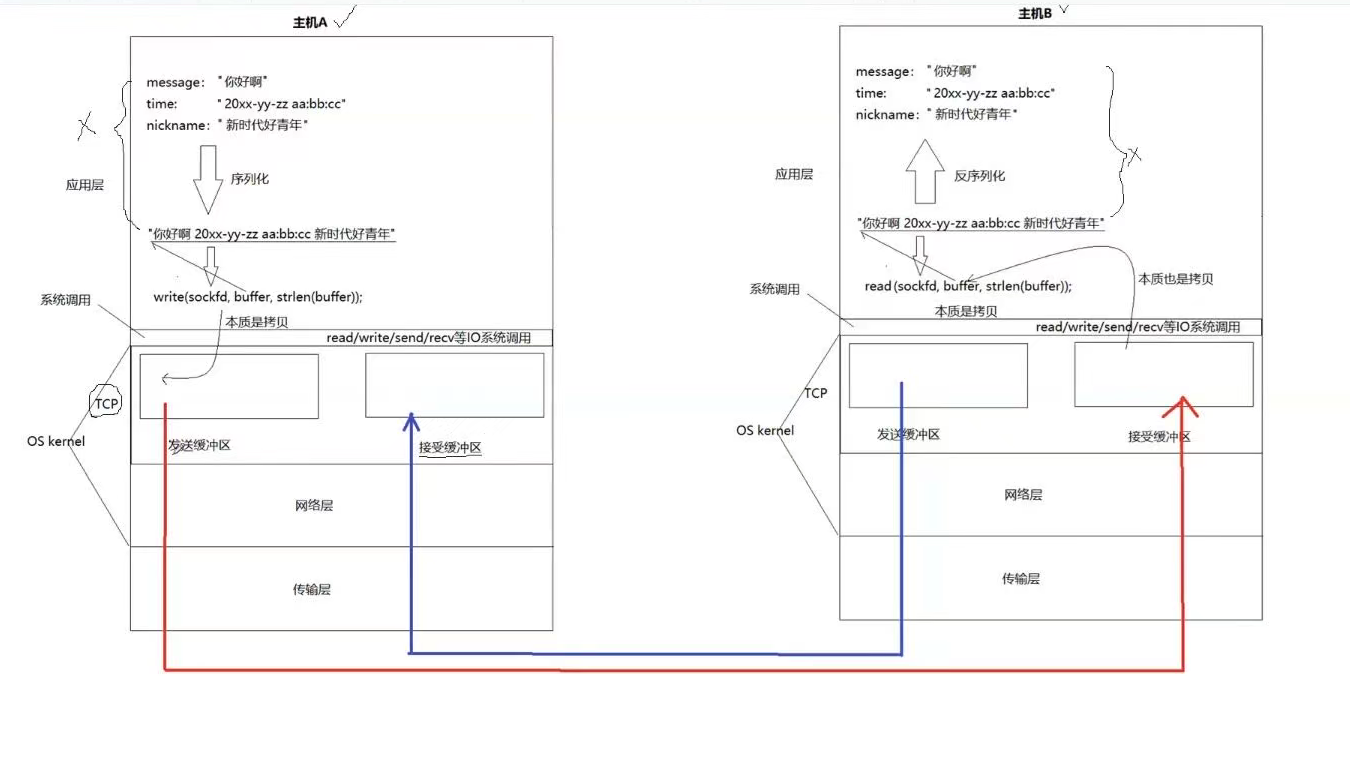
- write的本质不是发送数据到网络,本质是一个拷贝函数
- 发送缓冲区什么时候发,发多少,完全有TCP自主控制
- TCP网络发送数据,本质是把数据从发送缓冲区通过网络拷贝到对端的接受缓冲区
- 我们任务,在每一个发送单元,都是一个CP问题,是用户和内核之间进行生产和消费
- 缓冲区发送和收取的时候根本就不在乎数据到底是不是在一起的所以我们需要序列化
网络版本计算机
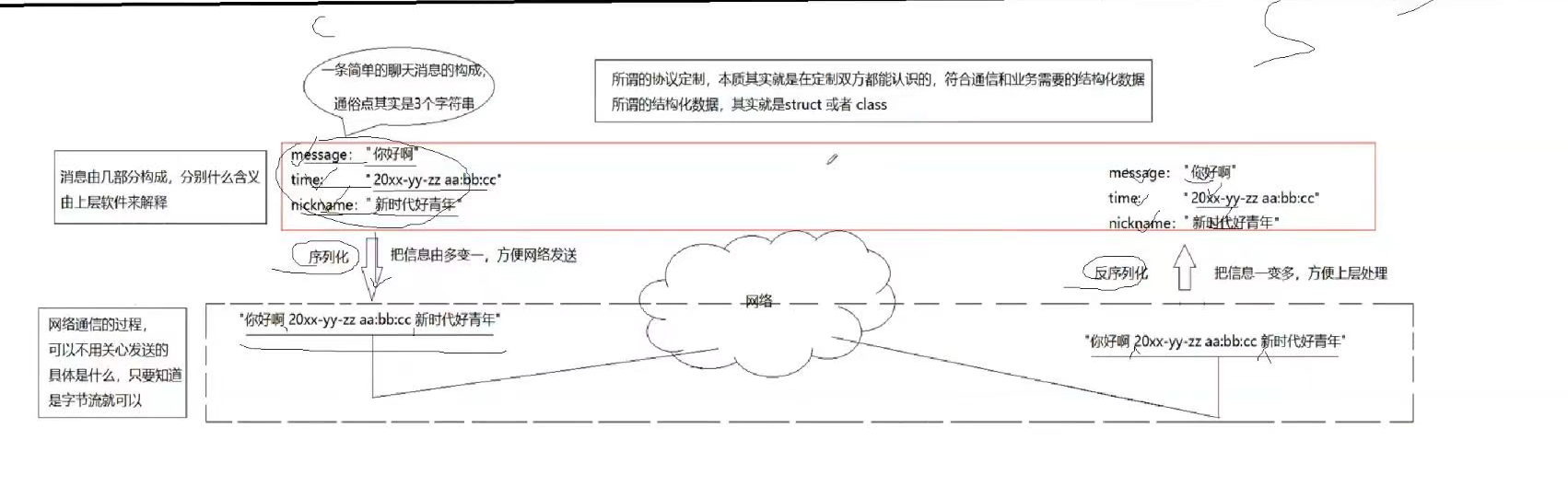
一、什么是序列化
发送数据时将这个结构体按照一个规则转化成字符串,接收到数据的时候再按照相同的规则把字符串转化回结构体
二、为什么要进行序列化
1、方便网络发送
2、方便协议的可扩展性,和可维护性
为什么要进行反序列化
方便上层处理