1. 总览:同一个入口,不同解析器
当用户上传文件时,技术链路通常是:
- 接收文件并保存原件。
- 按扩展名选择对应的 Python 解析函数。
- 生成可预览数据。
- 前端展示原件与解析结果。
- 用户编辑后保存。
- 提供原件下载与编辑结果下载。
xlsx
docx
pdf
用户上传文件
Upload API
保存原件
按扩展名路由
Excel 处理器
Word 处理器
PDF 处理器
预览数据
预览数据
预览数据
前端预览与编辑
保存编辑结果
下载原件 / 下载编辑结果
2. 插件与依赖清单
先统一约定:本文里"插件"指第三方依赖包(Python 包 / 前端 npm 包)。
2.1 Python 端插件(后端)
| 插件 | 版本(示例) | 用途 | 是否必须 |
|---|---|---|---|
fastapi |
0.111.0 |
提供上传、预览、保存、下载 API | 必须 |
uvicorn |
0.29.0 |
启动 FastAPI 服务 | 必须 |
python-multipart |
0.0.9 |
支持 multipart/form-data 文件上传 |
必须 |
openpyxl |
3.1.2 |
解析/回写 Excel(xlsx) | Excel 必须 |
pandas |
2.2.2 |
Excel/表格辅助清洗(可选但常用) | 推荐 |
python-docx |
1.1.0 |
解析/生成 Word(docx) | Word 必须 |
pymupdf (fitz) |
1.24.9 |
PDF 文本、表格、分页信息提取 | PDF 必须 |
对应 import 写法(便于直接复制代码):
from fastapi import FastAPI, UploadFile, Filefrom openpyxl import load_workbookfrom docx import Documentimport fitz(来自pymupdf)
2.2 前端插件(预览与编辑)
| 插件 | 版本(示例) | 用途 | 是否必须 |
|---|---|---|---|
xlsx |
^0.18.5 |
浏览器端 Excel 预览(按 sheet 渲染) | Excel 预览必须 |
mammoth |
^1.11.0 |
浏览器端 Word 转 HTML 预览 | Word 预览必须 |
react-data-grid |
7.0.0-beta.59 |
表格编辑组件(Excel/Word 表格/PDF 表格修订) | 需要编辑时必须 |
2.3 可选插件(PDF OCR 兜底)
| 插件 | 用途 | 是否必须 |
|---|---|---|
pytesseract + Pillow |
PDF/图片 OCR 兜底 | 可选 |
paddleocr |
中文 OCR 兜底(效果通常更好) | 可选 |
2.4 可选插件(兼容旧格式)
| 插件/工具 | 用途 | 是否必须 |
|---|---|---|
xlrd |
仅当你要直接读取 .xls 时使用 |
可选 |
libreoffice (soffice) |
把 .doc 转成 .docx,再交给 python-docx 解析 |
可选 |
2.5 安装命令示例
bash
# Backend
pip install fastapi uvicorn python-multipart openpyxl pandas python-docx pymupdf
# Frontend
npm install xlsx mammoth react-data-grid
# Optional OCR fallback
pip install pytesseract pillow
# or
pip install paddleocr
# Optional legacy-format support
pip install xlrd3. 通用基础:上传、存储、路由
3.1 上传接口示例
python
from pathlib import Path
from fastapi import APIRouter, UploadFile, File
router = APIRouter()
@router.post("/api/files/upload")
async def upload(files: list[UploadFile] = File(...)):
items = []
for f in files:
suffix = Path(f.filename).suffix.lower()
raw_path = save_raw_file(f) # 保存原件
if suffix == ".xlsx":
file_id = process_excel(raw_path)
file_type = "excel"
elif suffix == ".docx":
file_id = process_word(raw_path)
file_type = "word"
elif suffix == ".pdf":
file_id = process_pdf(raw_path)
file_type = "pdf"
else:
items.append({"filename": f.filename, "error": "unsupported file type"})
continue
items.append({"file_id": file_id, "type": file_type, "filename": f.filename})
return {"items": items}说明:
openpyxl主流场景是.xlsx,python-docx主流场景是.docx。如果必须支持
.xls/.doc,建议先做"格式转换"再进入本文解析流水线。
3.2 原件下载接口(通用)
python
from fastapi.responses import FileResponse
@router.get("/api/files/{file_id}/download/raw")
def download_raw(file_id: str):
path = locate_raw_file(file_id)
return FileResponse(path, filename=path.name)4. Excel:解析、处理、预览、编辑保存、下载
本章用到的插件:openpyxl、pandas(可选)、xlsx、react-data-grid。
Excel 的特点是天然二维网格,所以处理策略是"保留 sheet + 保留行列"。
4.1 解析(Python)
python
from openpyxl import load_workbook
def parse_excel(path: str) -> dict:
wb = load_workbook(path, data_only=True)
sheets: dict[str, list[list[str]]] = {}
for sheet_name in wb.sheetnames:
ws = wb[sheet_name]
rows: list[list[str]] = []
for row in ws.iter_rows(values_only=True):
rows.append(["" if c is None else str(c) for c in row])
sheets[sheet_name] = rows
return {
"sheet_names": wb.sheetnames,
"sheets": sheets,
}4.2 处理(可选)
常见的通用处理:
- 去掉尾部空行。
- 统一行长度(短行补空字符串)。
- 把非字符串安全转成字符串,避免前端渲染异常。
python
def normalize_excel_rows(rows: list[list[str]]) -> list[list[str]]:
if not rows:
return [[""]]
width = max(len(r) for r in rows)
normalized = []
for r in rows:
row = ["" if c is None else str(c) for c in r]
if len(row) < width:
row += [""] * (width - len(row))
normalized.append(row[:width])
return normalized4.3 前端预览
前端展示方式:
- Sheet 名作为 tab。
- 当前 sheet 用 table 或 DataGrid 渲染。
- 支持切换 sheet。
4.4 编辑保存
http
PUT /api/excel/{file_id}/edit
json
{
"sheet_name": "Sheet1",
"rows": [["A1", "B1"], ["A2", "B2"]]
}后端可把编辑结果保存成:
excel_edits.json(便于二次编辑)。edited.xlsx(便于下载)。
4.5 下载
- 原件:
GET /api/excel/{file_id}/download/raw - 编辑版:
GET /api/excel/{file_id}/download/edited
python
@router.get("/api/excel/{file_id}/download/edited")
def download_excel_edited(file_id: str):
edited_path = build_edited_excel(file_id) # 根据保存的 rows 重建 xlsx
return FileResponse(edited_path, filename=edited_path.name)存储 后端 前端 用户 存储 后端 前端 用户 上传 Excel POST /upload 保存 raw.xlsx parse_excel sheet_names + sheets 编辑单元格 PUT /excel/{file_id}/edit 保存 excel_edits.json / edited.xlsx 下载编辑版 GET /excel/{file_id}/download/edited edited.xlsx
5. Word:解析、处理、预览、编辑保存、下载
本章用到的插件:python-docx、mammoth、react-data-grid。
Word 的天然结构是"段落 + 表格",不建议简单压平为纯二维表。
5.1 解析(Python)
python
from docx import Document
def parse_word(path: str) -> dict:
doc = Document(path)
blocks: list[dict] = []
# 段落块
for p in doc.paragraphs:
text = p.text.strip()
if text:
blocks.append({"type": "paragraph", "text": text})
# 表格块
for table_index, table in enumerate(doc.tables):
rows = []
for row in table.rows:
rows.append([cell.text.strip() for cell in row.cells])
blocks.append({"type": "table", "table_index": table_index, "rows": rows})
return {"blocks": blocks}5.2 处理(可选)
- 清理连续空段落。
- 表格行列补齐。
- 对超长文本做安全截断(仅显示时,不改原文)。
5.3 前端预览
Word 常见做法是双视图:
- 原件预览:
mammoth转 HTML,阅读体验更接近原文档。 - 编辑视图:
- 段落块用文本编辑器。
- 表格块用 DataGrid。
5.4 编辑保存
http
PUT /api/word/{file_id}/edit
json
{
"blocks": [
{"type": "paragraph", "text": "Updated paragraph"},
{"type": "table", "table_index": 0, "rows": [["Header1", "Header2"], ["V1", "V2"]]}
]
}后端可以:
- 保存
word_edits.json。 - 用
python-docx生成edited.docx。
5.5 下载
- 原件:
GET /api/word/{file_id}/download/raw - 编辑版:
GET /api/word/{file_id}/download/edited
python
@router.get("/api/word/{file_id}/download/edited")
def download_word_edited(file_id: str):
edited_docx = build_edited_word_docx(file_id)
return FileResponse(edited_docx, filename=edited_docx.name)6. PDF:解析、处理、预览、编辑保存、下载
本章用到的插件:pymupdf(可选 OCR:pytesseract/paddleocr)、react-data-grid。
PDF 的关键是"按页处理",因为页面是它的天然单位。
6.1 解析(Python)
python
import fitz
def parse_pdf(path: str) -> dict:
pages = []
with fitz.open(path) as doc:
for i in range(doc.page_count):
page = doc.load_page(i)
text = page.get_text("text") or ""
tables = []
finder = page.find_tables()
if finder and finder.tables:
for t in finder.tables:
tables.append([[str(c or "").strip() for c in row] for row in t.extract()])
pages.append({
"page_no": i + 1,
"text": text,
"tables": tables,
"width": float(page.rect.width),
"height": float(page.rect.height),
})
return {"page_count": len(pages), "pages": pages}6.2 处理(可选)
- 当
find_tables()抽不到表时,回退到page.get_text("words")做词块聚合。 - 对文本进行页级摘要(便于快速预览)。
- 对识别结果增加
warnings字段(纯技术提示)。
6.3 前端预览
建议双层:
- 原件:iframe/objectURL 直接预览 PDF。
- 解析结果:按页展示
text + tables。
6.4 编辑保存
http
PUT /api/pdf/{file_id}/edit
json
{
"page_no": 1,
"table_index": 0,
"rows": [["Col1", "Col2"], ["A", "B"]],
"notes": "manual correction"
}后端可保存:
pdf_edits.jsonedited.pdf(可选实现:加批注页、嵌入修订信息)
6.5 下载
- 原件:
GET /api/pdf/{file_id}/download/raw - 编辑版 PDF:
GET /api/pdf/{file_id}/download/edited - 编辑记录 JSON(可选):
GET /api/pdf/{file_id}/download/edits-json
存储 后端 前端 用户 存储 后端 前端 用户 上传 PDF POST /upload 保存 raw.pdf parse_pdf(分页提取) pages/meta 修订表格 PUT /pdf/{file_id}/edit 保存 pdf_edits.json / edited.pdf 下载编辑版 GET /pdf/{file_id}/download/edited edited.pdf
7. API 清单(示例)
| 类型 | 预览接口 | 保存接口 | 下载接口 |
|---|---|---|---|
| Excel | GET /api/excel/{file_id}/preview |
PUT /api/excel/{file_id}/edit |
download/raw / download/edited |
| Word | GET /api/word/{file_id}/preview |
PUT /api/word/{file_id}/edit |
download/raw / download/edited |
GET /api/pdf/{file_id}/preview |
PUT /api/pdf/{file_id}/edit |
download/raw / download/edited |
说明:这三组接口可以由同一个服务实现。本文拆开写,仅用于按文件格式独立说明技术实现细节。
8. 工程落地建议(纯技术)
- 原件一定要保存,不要只存解析结果。
- 编辑结果建议落 JSON,再按需导出编辑版文件。
- 下载接口统一加
Content-Disposition: attachment。 - 所有预览数据都做空值与类型兜底,前端会省很多判断。
- 文件名建议带时间戳,例如:
report_edited_20260224_1530.xlsxdoc_edited_20260224_1530.docxscan_edited_20260224_1530.pdf
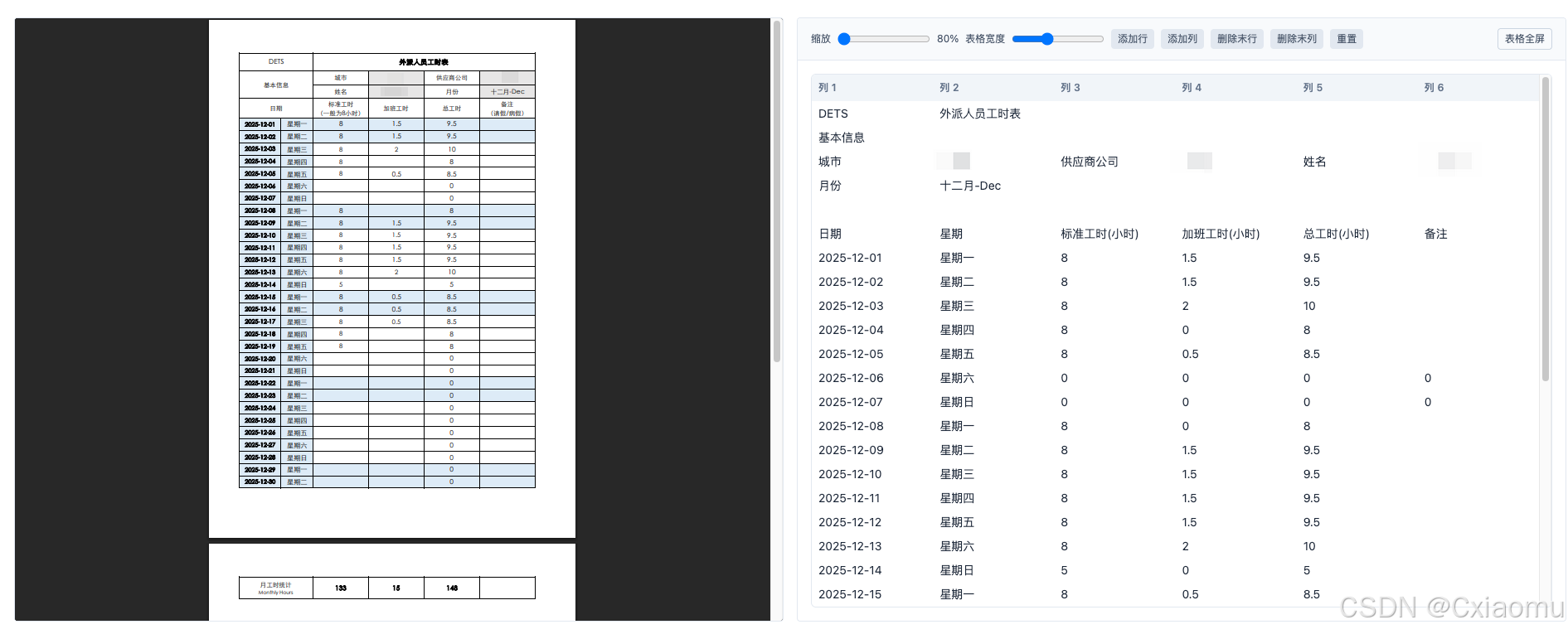
9. 效果
excel预览效果
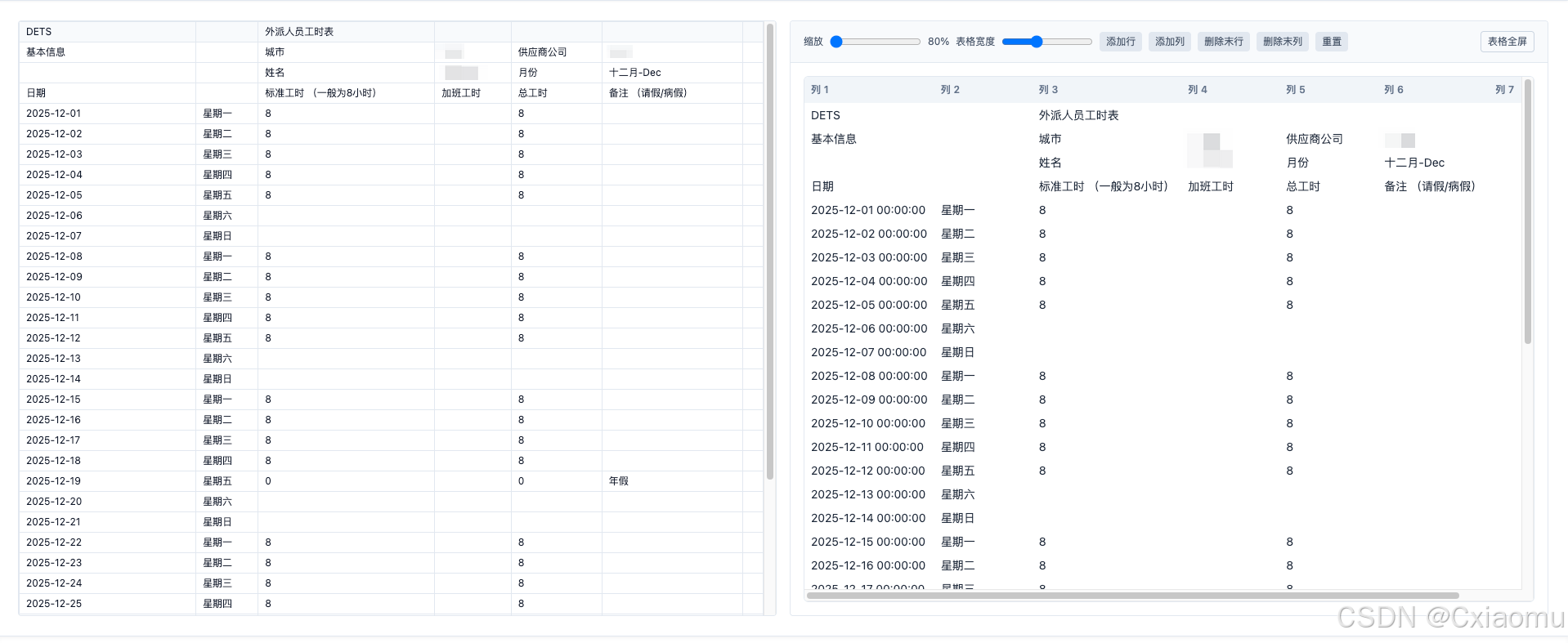
word预览效果
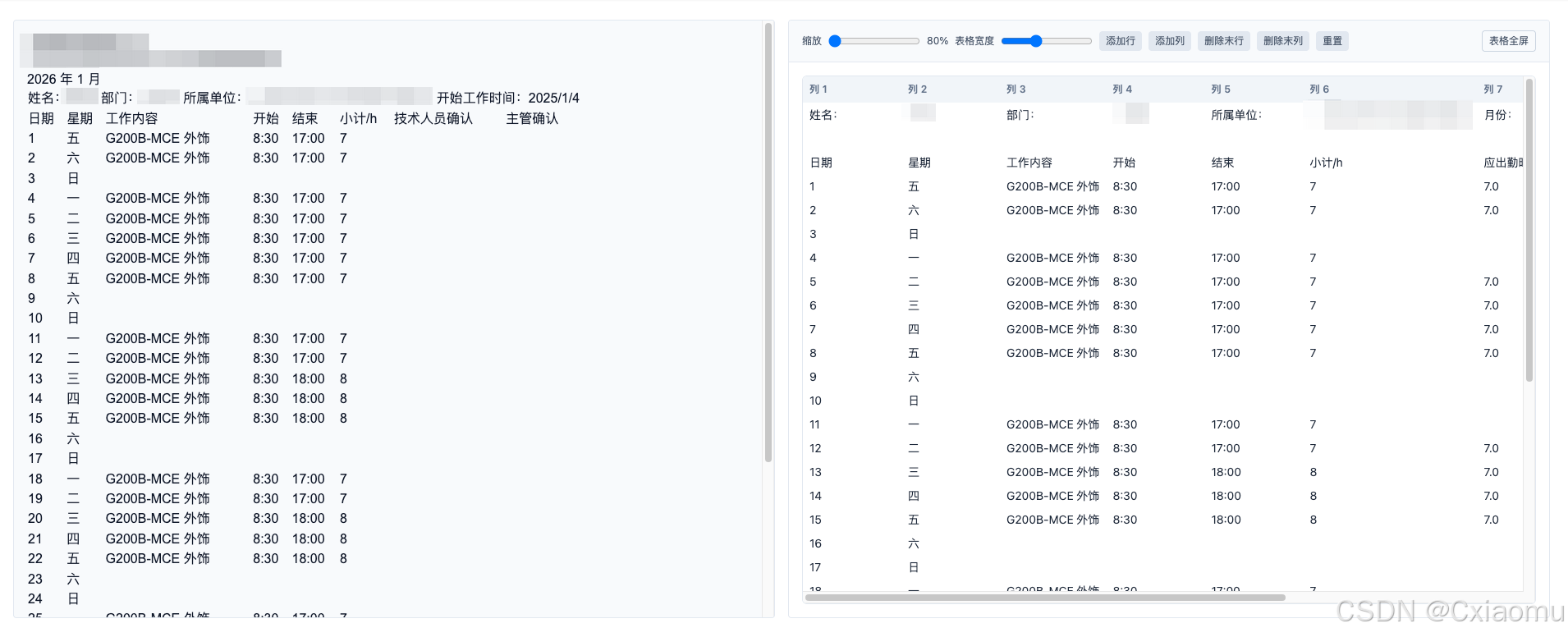
pdf 预览效果