本文汇总介绍几个资讯聚合平台,旨在告别信息过载焦虑,减轻信息碎片化痛点,同时又保持对行业动态的敏感度。
TrendRadar
开源(GitHub,47.1K Star,22.3K Fork)热点聚合神器,设置好感兴趣的关键词后,支持从知乎、抖音、微博等11家主流平台自动爬取实时热点,支持企业微信、飞书、钉钉、Telegram、邮件等推送渠道。在线体验。
使用方式:
- GitHub Actions:无需本地服务器,依托GitHub的自动化流水线,只需简单配置即可实现定时运行。特别适合希望零服务器维护的用户,全程在云端完成数据抓取与更新。
- Docker:借助容器技术实现环境隔离,一键启动即可运行,避免复杂的依赖配置问题。适合有服务器资源、希望本地化管理的团队或个人。
- Python:支持开发者调试和自定义修改。适合需要频繁调整代码逻辑的进阶用户。
语法
配置文件有3个:
config.yaml:配置frequency_words.txt:频率词,timeline.yaml:时间线,配置调度频率和模式
配置
最复杂的文件,但借助于官方站点,一切都可以变得容易上手
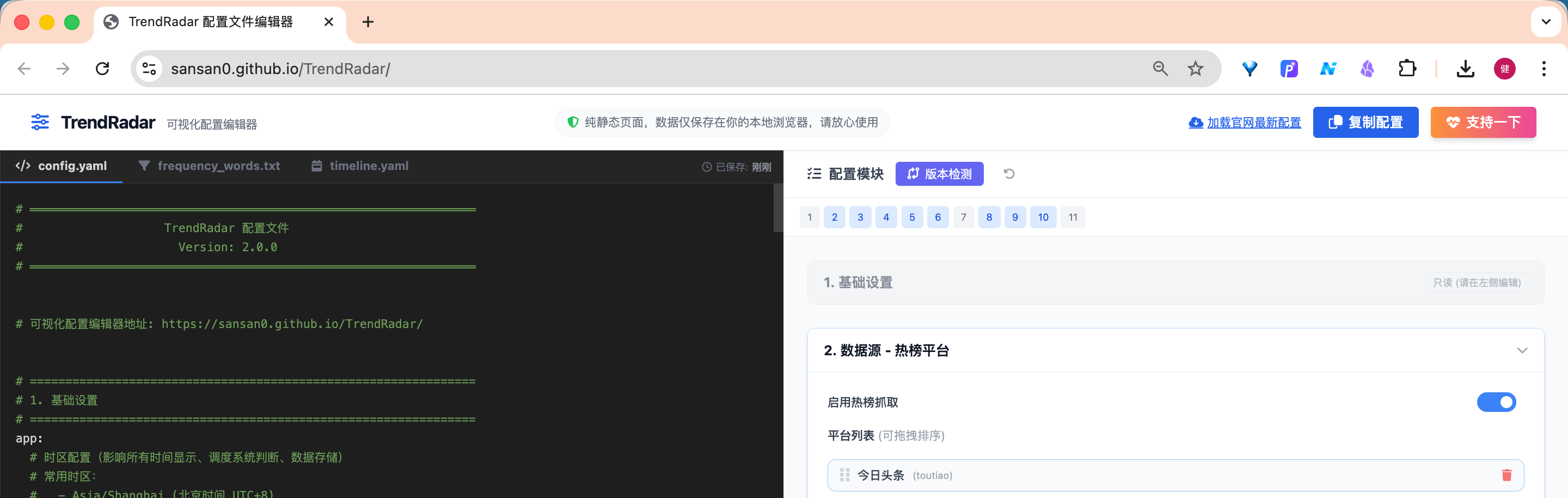
如上图,非常主流的双屏模式,左侧是编辑框,右侧可以实时渲染和预览。刚上手不熟悉语法,可在右侧拖拽式操作,左侧配置文件实时更新。
配置文件分为11个部分:
- 基础设置
- 数据源 - 热榜平台
- 数据源 - RSS 订阅
- 报告模式
- 推送内容控制
- 推送通知
- 存储配置
- AI模型配置
- AI分析功能
- AI翻译功能
- 高级设置
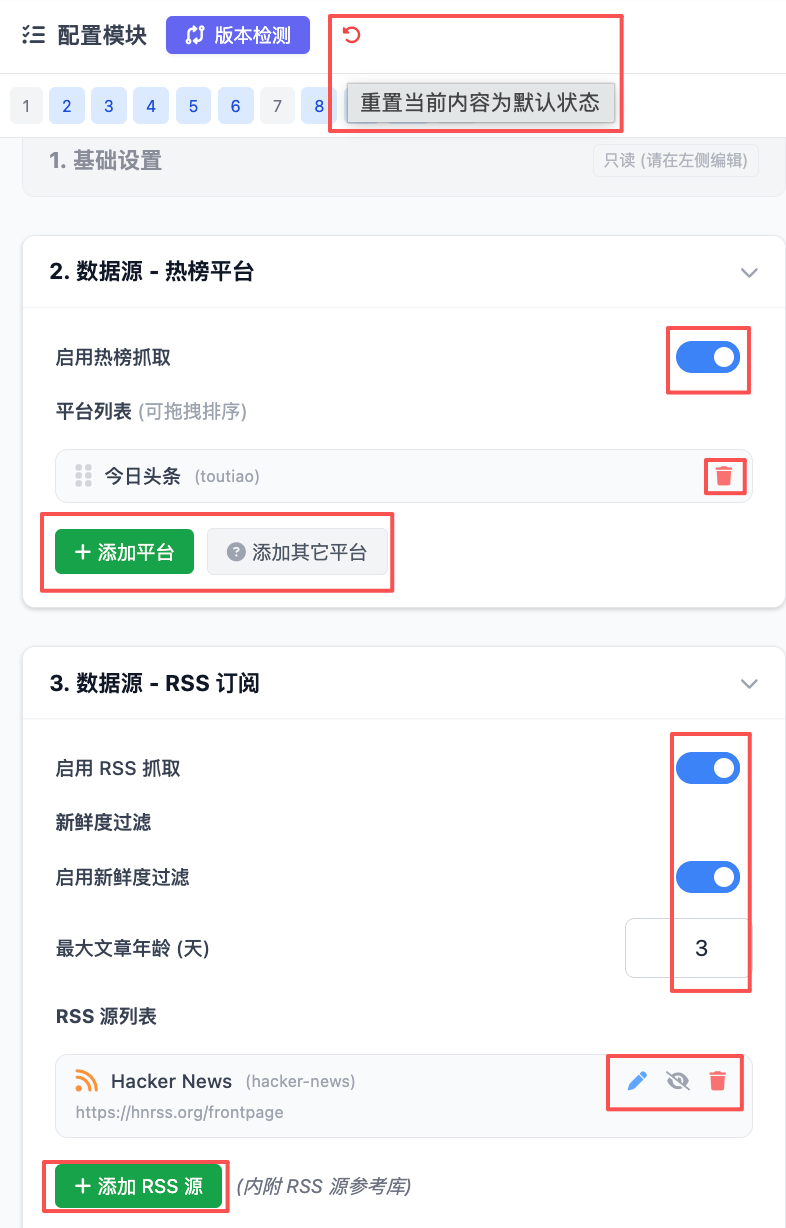
不再一一截图,右侧置灰的模块保持默认配置即可,熟悉语法规则后可编辑左侧的yaml文件。
config.yaml示例:
yml
app:
timezone: "Asia/Shanghai"
show_version_update: true # 显示版本更新提示
schedule:
enabled: true # 是否启用调度系统
preset: "custom"
platforms:
enabled: true # 是否启用热榜平台抓取
sources:
- id: "toutiao"
name: "今日头条"
report:
mode: "current"
notification:
enabled: true
channels:
feishu:
webhook_url: ""
storage:
backend: "auto"
formats:
sqlite: true # 主存储,必须启用
txt: false # 是否生成TXT快照
html: true # 是否生成HTML报告,邮件推送或者需要看网页版报告必须设为true
ai:
model: "deepseek/deepseek-chat"
api_key: ""
api_base: ""
timeout: 120
ai_analysis:
enabled: true
ai_translation:
enabled: false # 是否启用翻译功能
# 翻译目标语言
language: "中文"
# 提示词配置文件路径,相对于config目录
prompt_file: "ai_translation_prompt.txt"频率词
官方将词组分为4种类型

语法规则
| 语法类型 | 符号 | 作用 | 示例 | 匹配逻辑 |
|---|---|---|---|---|
| 普通词 | 无 | 基础匹配 | 华为 |
包含任意一个即可 |
| 必须词 | + |
限定范围 | +手机 |
必须同时包含 |
| 过滤词 | ! |
排除干扰 | !广告 |
包含则直接排除 |
| 数量限制 | @ |
控制显示数量 | @10 |
最多显示10条新闻 |
| 全局过滤 | [GLOBAL_FILTER] |
全局排除指定内容 | 10分钟上手 |
任何情况下都过滤 |
| 正则表达式 | /pattern/ |
精确匹配模式 | /\bai\b/ |
使用正则表达式匹配 |
| 显示名称 | =>备注 |
自定义显示文本 | /\bai\b/=>AI相关 |
推送和HTML显示备注名称 |
不会写配置文件,体验地址提供在线编辑和渲染能力:
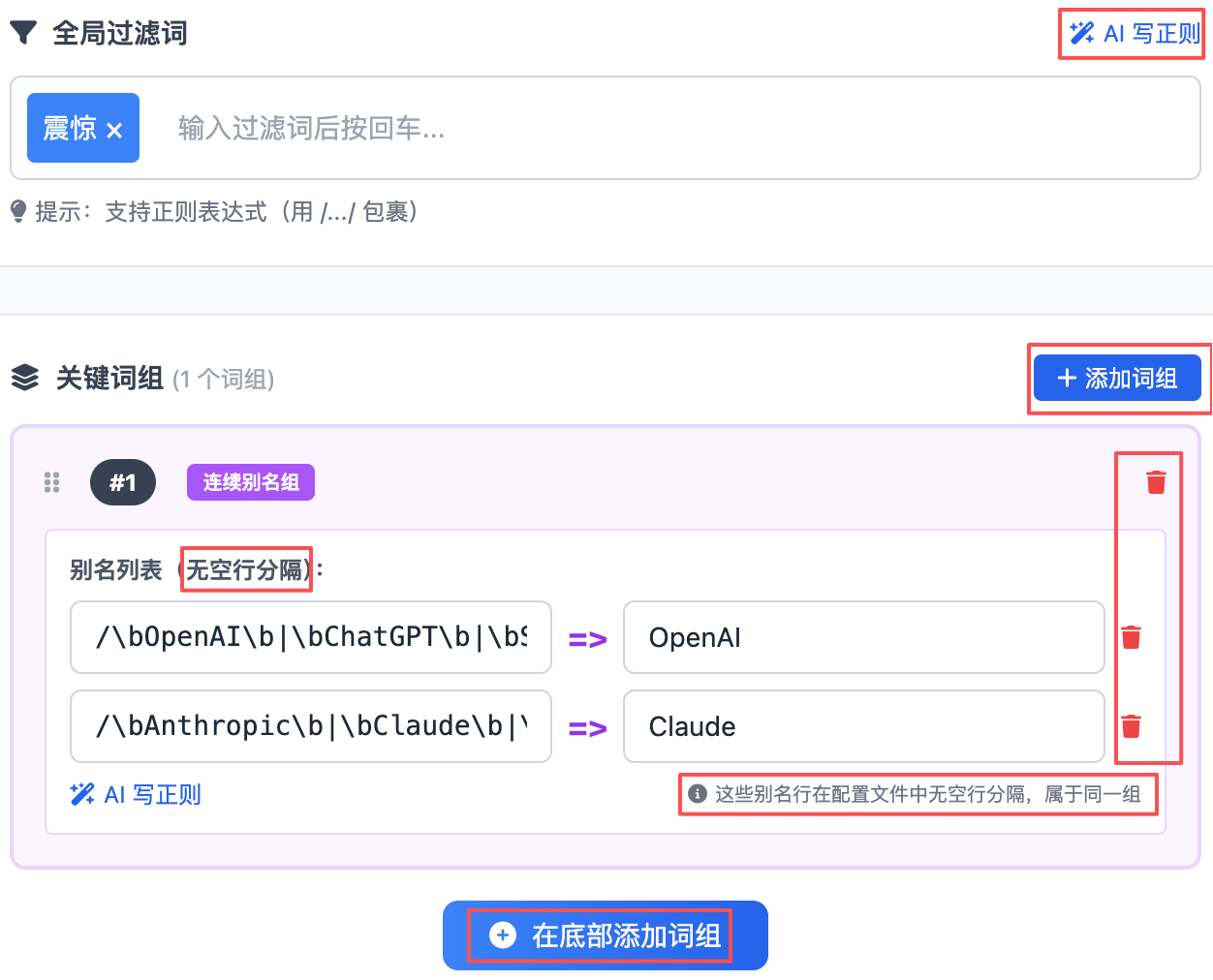
frequency_words.txt示例:
yml
[GLOBAL_FILTER]
# 过滤标题党
震惊
[WORD_GROUPS]
/\bOpenAI\b|\bChatGPT\b|\bSora\b|\bDALL-E\b|\bSam Altman\b|\bGreg Brockman\b/ => OpenAI
/\bAnthropic\b|\bClaude\b|\bDario Amodei\b/ => Claude时间线
源码
BettaFish
微舆,一个纯Python开源(GitHub,35.7K Star,6.8K Fork)多Agent舆情分析神器,能7×24小时监控30+国内外社媒、数百万条评论,自动破除信息茧房、还原舆情原貌、预测未来走向,最后生成专业级PDF报告。
核心能力:一句话触发全自动深度分析,聊天输入Query,系统立刻启动AI爬虫集群,自动抓取微博、小红书、抖音、快手、B站、Twitter、YouTube等30+平台数据,深入评论区,3-5分钟出具20+页PDF报告。
功能特性:
- 全域监控:AI爬虫永不眠,实时+历史双管齐下
- 多步骤思考:让Agent反复调用LLM,根据任务逻辑自动拆解步骤,直到完成目标
- 工具调用:内置简单的工具执行机制,可让LLM主动调用Python函数、访问API、处理文件、执行指令等,并将结果再次反馈给模型
- 状态管理:记录当前步骤、工具输出、历史对话、下步决策等,让整个推理链路透明、可调试
- 复合引擎:5类专业Agent+微调模型+统计模型协同作战
- 多模态解析:视频内容也能精准提取情绪、关键帧、弹幕
- Agent论坛机制:不同Agent带不同工具,像圆桌辩论一样碰撞出高质量结论
- 公私域融合:支持安全接口对接企业内部数据库
- 极致轻量:纯Python模块化,一条命令本地部署
技术亮点
- 零框架依赖,全手写爬虫+解析+LLM调度
- 论坛主持人模型负责协调辩论,避免单模型偏见
- 多模态卡片提取(天气、日历、股票)无缝融入分析链
- 所有Agent都有独立工具箱:情感分析、主题聚类、因果推断、风险分级...
架构图
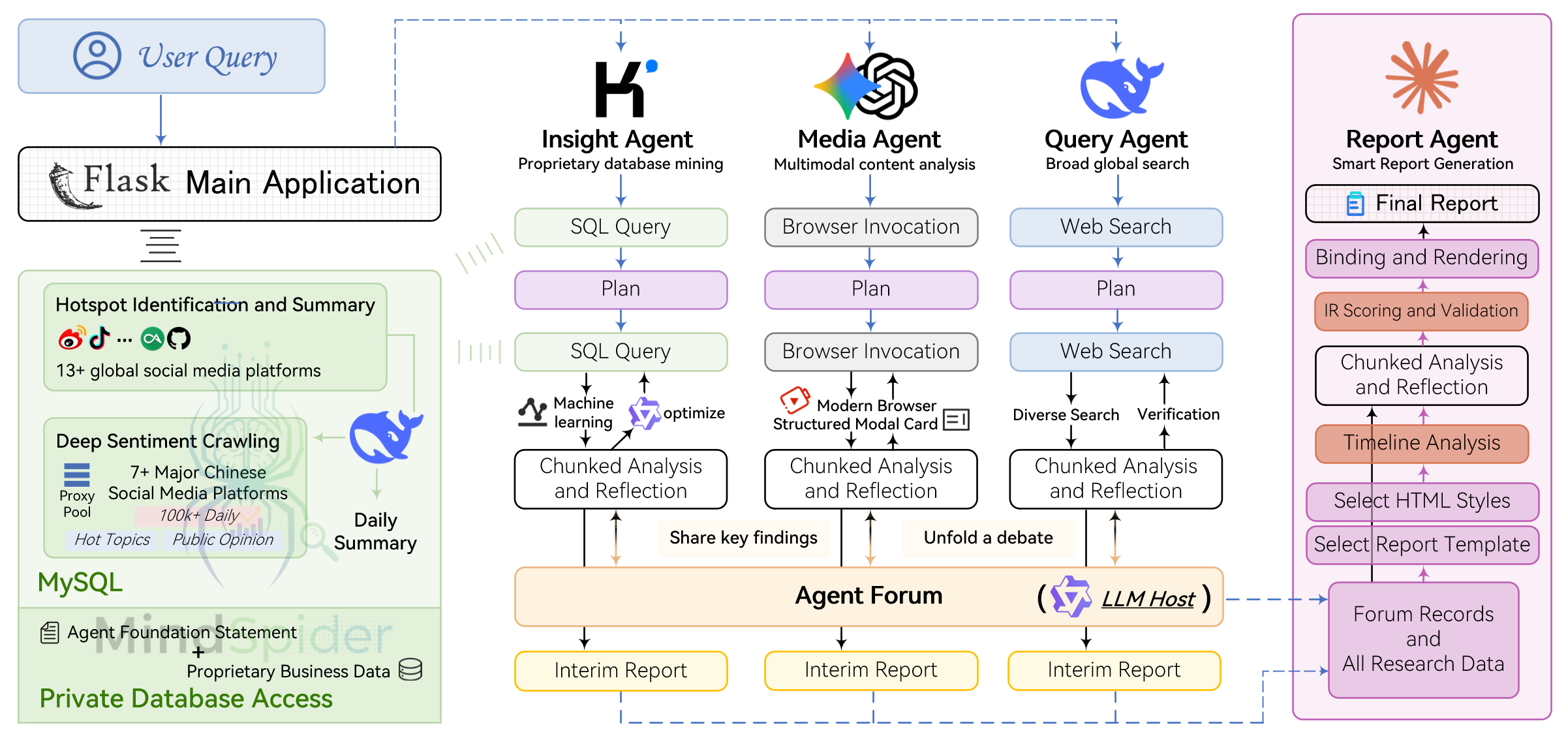
解读:
- Insight Agent:私有数据库挖掘,私有舆情数据库深度分析AI代理
- Media Agent:多模态内容分析,具备强大多模态能力的AI代理
- Query Agent:精准信息搜索,具备国内外网页搜索能力的AI代理
- Report Agent:智能报告生成,内置模板的多轮报告生成AI代理
安装
多种部署方式:
- Docker或Docker Compose
- 源码
源码部署:
bash
git clone https://github.com/666ghj/BettaFish.git
cd BettaFish
pip install -r requirements.txt
python main.pyPython SDK:
py
from betta import BettaFish, tool
@tool
def add(a, b):
return a + b
agent = BettaFish(tools=[add])
agent.run("计算 17 + 25 的结果")NewsNow
开源(GitHub,18.1K Star,5.2K Fork)热榜聚合阅读器,将微博、知乎、B站等平台热榜整合到统一界面。
核心亮点:支持GitHub登录同步、30分钟智能缓存、自适应抓取(最小2分钟)。
技术栈采用React+TS+Vite前端搭配Nitro Server后端,工程结构清晰,每个数据源独立适配器,前后端共享类型定义。项目具备PWA特性,支持CloudFlare/Vercel多平台部署,集成MCP协议,可作为AI工作流的数据源。适合打造个人热榜仪表盘或全栈学习项目,既解决信息碎片化痛点,又保留"能部署、可扩展"的实用基因。
实时新闻/热榜聚合阅读器,重点在阅读体验和聚合能力:
- 多数据源聚合:科技、社区、视频、资讯等热榜都能接入
- GitHub OAuth登录:登录后可以做跨设备数据同步
- 默认缓存:30分钟缓存,登录用户可以手动强刷
- 自适应抓取间隔:按不同数据源更新频率动态调整,最小2分钟
- PWA+SEO:
sw.js、sitemap.xml、robots.txt、OG/Twitter Card都有 - 部署兼容:Cloudflare Pages、Vercel、Docker等
- MCP支持:能直接当数据源用
技术栈
- 前端:React+TS+Vite,样式用Tailwind CSS、Uno CSS
- 路由:TanStack Router,会生成
routeTree.gen.ts - 状态管理:Jotai:原子化,栏目、搜索、主题、同步、Toast都拆得细
- 服务端:Nitro Server,Nuxt的服务端框架,用来承载API与数据库交互
- 抓取与解析:myFetch+Cheerio(解析HTML),部分源走JSON API
- 数据库:db0 connectors;生产推荐CloudFlare D1,本地用better-sqlite3
- 工程化:pnpm、ESLint、GitHub Actions、Docker
server/sources/:
每个站点一个适配器。新增源的步骤参考CONTRIBUTING.md:注册元信息→写抓取解析→返回统一NewsItem[]。
shared/types.ts:前后端共享类型,前后端联调类项目最常见的Bug就是接口字段不统一或单侧改动;共享类型能让这类问题更早暴露。
proxySource代理机制,用于处理部分数据源受限的现实情况。
配置文件示例:
json
{
"mcpServers": {
"newsnow": {
"command": "npx",
"args": ["-y", "newsnow-mcp-server"],
"env": {
"BASE_URL": "https://newsnow.busiyi.world"
}
}
}
}ClawFeed
AI驱动的开源(GitHub,347 Star, 46 Fork)新闻摘要工具。
理念:把成千上万的信息源聚合起来,用AI筛选出真正重要的内容。
不仅可以独立使用,还可作为OpenClaw或Zylos的技能来运行,集成到其他AI代理系统中。
功能特性
- Google OAuth:支持多用户访问个人书签和来源
- Feed输出:任何人都可通过RSS或JSON Feed订阅他人ClawFeed摘要
- 多语言:支持英文和中文界面,中文友好
- 深色/浅色模式:支持主题切换,用
localStorage持久化保存个人偏好 - Web仪表盘:单页应用的Web界面,可浏览和管理摘要
- SQLite存储:使用SQLite作为数据库,快速、便携、零配置,不需要额外安装数据库服务
核心亮点
- 多频率摘要:可选择4小时、每日、每周、每月等不同频率的摘要
- 4小时摘要:适合需要实时追踪行业动态的人,如做投资、做媒体的
- 每日摘要:大多数人的选择,每天早上花10分钟就能了解前一天的重要信息
- 每周/每月摘要:适合时间比较紧张,或想做周期性回顾的人
- 支持的信息源非常丰富:
- Twitter/X:可关注用户、列表
- RSS/Atom:任何RSS源都可以添加
- HackerNews:首页、热门等
- Reddit:可订阅任意子版块
- GitHub Trending:可按语言筛选
- 网站抓取:直接输入网址就能抓取内容
- 自定义 API:支持接入自定义数据源
- 其他用户的摘要:可订阅别人的ClawFeed摘要
- Source Packs:把精心挑选的一组信息源打包成
Source Pack,分享给社区。其他人可一键安装,直接订阅。 - Mark & Deep Dive:看到感兴趣内容后标记下来,让AI进行深度分析。
- 智能筛选:支持配置内容过滤规则,可自定义感兴趣内容,噪音(不感兴趣话题)。还会根据
feed的质量分析,推荐应该关注或取消关注的内容源,持续优化信息质量。
实战
官方提供在线体验站点,另外支持本地安装。
安装方式
- ClawHub:
clawhub install clawfeed - OpenClaw Skill:
bash
cd ~/.openclaw/skills/
git clone https://github.com/kevinho/clawfeed.gitOpenClaw会自动检测SKILL.md并加载这个技能,代理即可通过cron生成摘要、提供仪表盘、处理书签命令。
- Zylos Skill
bash
cd ~/.zylos/skills/
git clone https://github.com/kevinho/clawfeed.git- 独立部署
bash
git clone https://github.com/kevinho/clawfeed.git
cd clawfeed
npm install