"只要深入探究,万事万物皆有趣味。"------理查德·费曼
现代大语言模型系统之所以令人印象深刻,往往是因为它们的大量行为都隐藏在抽象层之后。输入一个提示词,输出一段回答------而在这中间,某个"智能"系统做出的决策既难以检视、更难调试,在规模化应用时几乎无法让人完全信任。本文将刻意反其道而行之:我们不把智能体、工具和模型当作黑箱魔法,而是层层拆解,追踪幕后真正发生的一切:LangChain/LangGraph 智能体如何推理、何时调用工具、基于 vLLM 部署的模型如何响应,以及 Arize Phoenix 如何将每一步都捕获为可观测、可度量的数据。通过深入追踪轨迹、Span、延迟与 Token 流向,我们将一个不透明的 LLM 工作流,转变为一套你能理解、可推理、且可放心迭代的系统。
在本指南中,我们将一步步搭建一套面向本地部署大模型应用的完整可观测技术栈。整套方案包含:
•
vLLM 部署通义千问代码模型(Qwen3-Coder-Next, FP8) ,直接运行在 双节点 NVIDIA DGX-Spark 系统 的其中一个节点上,对外暴露兼容 OpenAI 接口的本地 API。
•
LangChain/LangGraph 智能体,运行在同一套 DGX-Spark 系统中,调用本地 vLLM 服务端点,并集成 Tavily 实现联网搜索。
•
Arize Phoenix ,在 同一套双节点 DGX-Spark 系统 上基于 Kubernetes 自部署,后端使用 PostgreSQL 存储,用于捕获追踪数据并提供可观测性 UI。
我们会介绍各组件如何协同工作、如何通过 Kustomize 在 K8s 上部署 Phoenix(搭配 Postgres)、如何使用 OpenTelemetry 对智能体做埋点追踪,以及如何排查常见问题。现在开始!
🏗 架构总览:完全本地化运行在双节点 DGX-Spark 系统
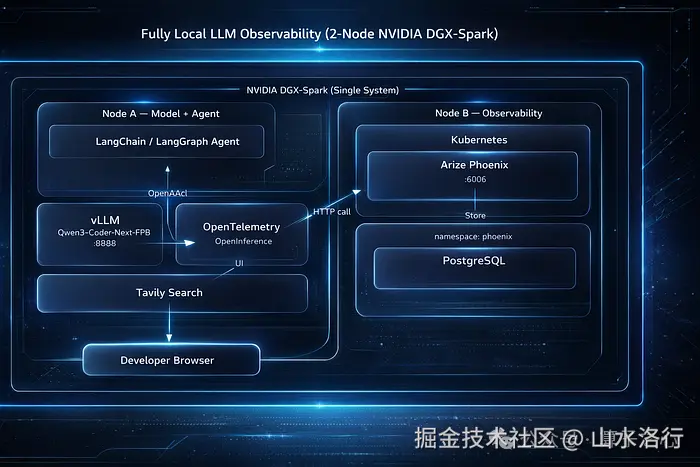
我们的目标是打造一套类生产环境 的 LLM 可观测架构,且整套系统完全运行在双节点 NVIDIA DGX-Spark 服务器内部。
**vLLM 模型服务(DGX-Spark 节点 A)**我们在其中一个 DGX-Spark 节点上运行 vLLM,托管一个大型代码专用模型(Qwen3-Coder-Next-FP8),对外提供兼容 OpenAI 的 REST API。vLLM 通过连续批处理与 FP8 量化实现高吞吐推理,暴露 /v1/chat/completions 等端点。在本方案中,vLLM 直接在 DGX-Spark 上启动,监听端口 8888。
**LangChain + LangGraph 智能体(DGX-Spark 节点 A)**LLM 智能体与模型服务运行在同一套 DGX-Spark 系统中,通常在 Jupyter 笔记本或 Python 运行环境中启动。它通过兼容 OpenAI 的接口调用本地 vLLM 端点,并集成 Tavily 作为实时联网搜索工具。从智能体视角看,这与调用 OpenAI 完全一致------唯一区别是所有流量都留在本地。
**Arize Phoenix + PostgreSQL(DGX-Spark 节点 B)**第二个 DGX-Spark 节点通过 Kubernetes 运行 Arize Phoenix 与 PostgreSQL。Phoenix 接收来自智能体的 OpenTelemetry 追踪数据,存入 Postgres,并对外提供 UI 界面,用于检视 LLM 调用、工具使用、延迟与推理步骤。尽管 Phoenix 部署在 Kubernetes 中,但它仍属于同一套 DGX-Spark 系统。
逻辑分离、物理一体------这让整套可观测闭环完全本地化、可复现、易于理解。
为什么选择这套架构?
•
允许你在本地环境快速迭代 LLM 应用
•
同时拥有完整可观测能力,无需将数据发送到外部服务。vLLM + Qwen 组合相当于你自己的"私有 AI 服务器",对标 OpenAI;Tavily 提供实时搜索能力;Phoenix 则提供类似 LangSmith 或 OpenAI 可观测平台的能力,但完全自托管 。你可以精准看到智能体每一步在做什么:生成了什么提示、每轮调用耗时多久、消耗了多少 Token 等。这对调试与优化复杂 LLM 智能体至关重要。
在动手实践前,我们先完成所需的基础设施准备。
🖥️ 基础设施:一套 DGX-Spark,两个节点
本次部署使用单套 NVIDIA DGX-Spark 系统,包含两个节点:
•
节点 A运行 vLLM 模型服务与 LangChain/LangGraph 智能体运行时。
•
节点 B运行 Kubernetes 工作负载:Arize Phoenix 与 PostgreSQL。
整套环境无外部 GPU 服务器 ,也无独立开发机。智能体、模型服务、可观测平台全部在同一套 DGX 环境内执行。
Kubernetes 仅在有明确价值的场景使用(Phoenix + Postgres)。vLLM 服务与智能体可直接运行在宿主机或容器中,但始终保持在 DGX-Spark 本地。网络通信全部在集群内部,Phoenix 可通过 Kubernetes LoadBalancer 或 kubectl port-forward 访问。
接下来,我们将在 K8s 集群中部署 Phoenix(含 Postgres 数据库),并根据环境做配置(命名空间、节点调度、存储等)。
🚀 在 Kubernetes 上部署 Arize Phoenix(通过 Kustomize 搭配 Postgres)
Arize 提供 Phoenix 的开源发行版,可直接部署在自有集群。我们使用官方 GitHub 仓库的 Kustomize 模板进行部署。默认情况下,Kustomize 会启动 Phoenix(服务端) 与 PostgreSQL,并创建持久化存储卷。我们会做少量定制:命名空间、节点亲和性、存储类。
步骤 1:克隆 Phoenix 仓库并创建命名空间首先克隆仓库,并为 Phoenix 创建命名空间:
bash
git clone https://github.com/Arize-ai/phoenix.git
cd phoenix
kubectl create namespace phoenix # 可自定义命名空间(如 "phoenix")默认 Kustomize 清单未指定命名空间,手动创建并指定可保持环境整洁。
步骤 2:(可选)自定义部署参数 我们可以通过 Kustomize 叠加层或补丁来定制部署。例如,将 Phoenix 与 Postgres 固定到指定节点,并使用 Longhorn 存储。创建文件(如 kustomize/local/patches.yaml),内容如下,可根据实际标签/名称调整:
bash
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: phoenix # 所有资源部署在 phoenix 命名空间
resources:
- ../base
# 自定义基础资源的补丁
patches:
# 将 Phoenix server 固定到指定节点(如 hostname 为 spark-ba63 的节点)
- target:
kind: Deployment
name: phoenix-server
patch: |-
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: spark-ba63 # 替换为你的节点名或使用标签
# 将 Postgres(假设 StatefulSet 名为 postgres)固定到同一节点
- target:
kind: StatefulSet
name: postgres
patch: |-
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: spark-ba63
# 为 Postgres PVC 使用 Longhorn 存储类(假设 PVC 名为 postgres-data)
- target:
kind: PersistentVolumeClaim
name: postgres-data
patch: |-
spec:
storageClassName: longhorn # 确保与你的 Longhorn SC 名称一致
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi # 可按需调整该叠加层实现三件事:所有资源部署在 phoenix 命名空间、将 Pod 调度到 spark-ba63 节点(可使用任意存在的标签或节点选择器)、强制 Postgres 数据 PVC 使用 Longhorn 存储(本例申请 10Gi 卷)。节点绑定是可选的;如果集群可将 Pod 调度到任意具备存储访问的节点,可跳过或使用反亲和性。Longhorn 存储类可确保 Postgres 数据具备副本能力并能在节点故障后恢复,而不是使用可能不支持持久化的默认存储。
步骤 3:部署 Phoenix 与 Postgres应用 Kustomize 配置完成部署。如果使用上面的自定义叠加层,直接应用;否则可直接应用基础模板(记得单独指定命名空间):
bash
# 使用自定义叠加层
kubectl apply -k kustomize/local
# (备选)直接应用基础模板到 phoenix 命名空间
# kubectl apply -k kustomize/base -n phoenixKustomize 会创建 Phoenix Deployment、Postgres Deployment(或 StatefulSet)以及存储 PVC。验证 Pod 正常运行:
bash
kubectl get pods -n phoenix
NAME READY STATUS RESTARTS AGE
phoenix-dc8c8d9c-ktwdc 1/1 Running 2 (13h ago) 13h
postgres-0 1/1 Running 0 13h同时检查 Phoenix Service 是否存在。基础配置中默认是 ClusterIP 类型。如需外部访问,可暴露服务:
步骤 4:暴露 Phoenix UI如果集群有 LoadBalancer,可将 Service 类型改为 LoadBalancer:
bash
kubectl
patch
service
phoenix-server
-n
phoenix
-p
'
{"spec": {"type": "LoadBalancer"}}
'稍等片刻,执行 kubectl get svc -n phoenix phoenix-server 应能看到外部 IP(前提是已配置 MetalLB 或云厂商 LB)。注意 Phoenix 默认监听 6006 端口,同时提供 Web UI 与 HTTP 追踪采集服务。
如果没有 LoadBalancer,可按需使用端口转发:
bash
kubectl
port-forward
svc/phoenix-server
-n
phoenix
6006:6006这会让 Phoenix UI 在本地机器的 http://localhost:6006 可访问(同时也能向该端口发送 OTLP 追踪数据)。
至此,Phoenix 已部署完成,且(默认无鉴权)Web 界面已就绪。可打开浏览器访问 URL(LoadBalancer 地址或端口转发的 localhost:6006)测试,应能看到 Phoenix UI 加载成功,初始无数据属于正常。
**步骤 5:配置 Phoenix(Postgres 等)**Kustomize 部署已默认配置使用 Postgres 数据库(通过环境变量或 Phoenix 默认规则)。Phoenix 会使用 PHOENIX_SQL_DATABASE_URL 或单独的 Postgres 主机/用户/密码等环境变量。在我们的部署中,这些配置通常来自 ConfigMap 或直接在 Spec 中定义。如需调整(例如使用自定义 Postgres 实例),可设置:
bash
# 在 Phoenix 部署的 env 中
- name: PHOENIX_POSTGRES_HOST
value: <postgres-service-host>
- name: PHOENIX_POSTGRES_USER
value: <user>
# 密码、库名等同理使用内置 Postgres 时,默认配置即可(可查看 Phoenix 日志确认连接的是 SQLite 还是 Postgres)。Arize 文档提到:若未提供 SQL URL,Phoenix 默认使用文件型 SQLite。我们的 Kustomize 会覆盖该行为,指向 Postgres,实现追踪数据持久化。
Phoenix 部署完成!现在我们已经拥有一套本地可观测服务。接下来配置开发环境接入使用。
📦 配置智能体环境(LangChain + Phoenix 埋点)
在开发端(DGX-Spark ),我们需要安装智能体与可观测埋点所需的 Python 包。务必安装 Arize 官方的 Phoenix 客户端/SDK 与 OpenInference 埋点包,避免安装同名但无关的旧包导致冲突。
特别注意:不要安装 PyPI 上的旧版 phoenix==0.9.1 ------这并非 Arize 的 Phoenix,是另一个无关项目,会导致报错。请使用官方 arize-phoenix 系列库。
打开 Python 环境(可使用 conda 或 Jupyter 中的 venv)并安装:
bash
pip
install
arize-phoenix
arize-phoenix-otel
openinference-instrumentation-langchain
langchain-openai
langchain-core简单说明:
•
arize-phoenix --- Phoenix 平台客户端(含 CLI)库。仅发送追踪并非必须,但用于使用 Phoenix Python API 或 CLI 非常方便,同时确保子包版本匹配。
•
arize-phoenix-otel --- Phoenix OpenTelemetry SDK。提供 phoenix.otel 模块与便捷的 register() 函数用于初始化追踪。可理解为面向 Phoenix 优化的 OpenTelemetry 快捷配置。
•
OpenInference 埋点包 --- 我们安装 openinference-instrumentation-langchain 用于追踪 LangChain。如果设置 auto_instrument=True,Phoenix OTEL SDK 会自动激活已安装的 OpenInference 埋点器,从而实现 LangChain 内部细节的完整追踪。(Phoenix/OpenInference 还支持 OpenAI API、LlamaIndex 等框架,可按需安装。)
•
LangChain 包 --- 安装 langchain-openai 与 langchain-core,对应 LangChain v1.x 新的模块化架构(OpenAI 等厂商适配已拆分为独立子包)。这让我们能使用 ChatOpenAI 与智能体工具。也可直接安装 langchain,但拆分安装更精准。如果计划直接使用 LangGraph,建议一并安装。
安装完成后,验证没有装错 Phoenix 包:
bash
import phoenix
print(phoenix.__version__)
# 例如 12.33.1版本号应 ≥ 1.x(或最新如 0.13.x 及以上,Phoenix 已从 0.9 大版本升级)。如果显示 0.9.1,卸载并重新安装 arize-phoenix。
📝 埋点与创建 LangChain 智能体
依赖就绪后,我们编写智能体代码。整体流程:
1
优先注册 Phoenix 追踪器,确保后续所有导入与调用都被埋点。
2
将 OpenAI API 基础地址指向本地 vLLM 服务(让 ChatOpenAI 调用流向 Qwen)。
3
定义智能体------包含所需工具(Tavily 搜索等)------使用 LangChain create_agent 或 LangGraph create_react_agent。
4
运行智能体,并在 Phoenix 中观测追踪数据。
逐段代码说明:
bash
import os
from phoenix.otel import register
# 1. 初始化 Phoenix 追踪
tracer_provider = register(
project_name="local-llm-app",
auto_instrument=True
)register() 调用会连接 Phoenix 实例并配置 OpenTelemetry。默认情况下,除项目名外无其他参数时,会从环境变量读取采集端地址。我们需要明确告诉它追踪数据发往何处。如果 Phoenix 本地端口转发运行,默认地址 http://localhost:6006 会自动生效。为清晰起见,显式设置:
bash
# 在 Shell 或笔记本环境中设置
export PHOENIX_COLLECTOR_ENDPOINT="http://localhost:6006"该环境变量会被 register() 读取,用于将追踪数据发送到 Phoenix 采集器。如果使用 LoadBalancer IP 或域名,替换为对应地址(如 http://<phoenix_host>:6006)。注意 :自托管实例默认关闭认证,无需 API Key;如果使用 Phoenix Cloud,则需同时设置 PHOENIX_API_KEY。
设置 auto_instrument=True 后,Phoenix SDK 会自动激活 所有已安装的相关 OpenInference 埋点器。这意味着我们导入 LangChain 或 OpenAI 库时,会自动被补丁并输出遥测数据。(底层等价于手动执行 LangChainInstrumentor().instrument() 等,但无需手动操作。)
接下来,配置 OpenAI 聊天模型指向我们的 vLLM Qwen 端点:
bash
from langchain_openai import ChatOpenAI
# 2. 配置 OpenAI API 使用本地 vLLM 服务
os.environ["OPENAI_API_KEY"] = "not-needed" # vLLM 不需要,但 SDK 可能要求存在该变量
llm = ChatOpenAI(
model_name="Qwen/Qwen3-Coder-Next-FP8", # vLLM 加载的模型名称
temperature=0,
openai_api_base="http://localhost:8888/v1", # vLLM 端点,非本地需调整主机
openai_api_key="unused"
)这里我们创建 ChatOpenAI 实例,指向 localhost:8888/v1(vLLM 服务地址)。model_name 传入 Qwen/Qwen3-Coder-Next-FP8,与 vLLM 启动时加载的模型一致(请求中会使用该标识)。如果启动 vLLM 时使用了不同名称或别名,以实际为准。openai_api_base 包含 /v1 路径,完整模拟 OpenAI API URL。我们设置一个虚拟 API Key 满足客户端要求;vLLM 默认不需要认证,任意字符串(甚至空)均可。现在 llm 对象就像一个代理,将请求转发到本地模型。
接下来定义智能体的工具 。我们集成 Tavily Search ,让智能体可获取实时信息。Tavily 提供 API;假设我们已在 TAVILY_API_KEY 中设置密钥。LangChain 目前暂无官方 Python 封装(类似 JS 版本),我们通过简单 requests 调用或 Tavily SDK 实现自定义工具。示例如下:
bash
import requests
from langchain_core.tools import Tool
TAVILY_API_KEY = os.environ.get("TAVILY_API_KEY", "<your Tavily key>")
def tavily_search(query: str) -> str:
"""使用 Tavily API 获取查询结果。"""
url = "https://api.tavily.com/search"
params = {"query": query, "max_results": 5, "topic": "general"}
headers = {"x-api-key": TAVILY_API_KEY}
resp = requests.get(url, params=params, headers=headers)
if resp.status_code == 200:
data = resp.json()
# 将结果简化为 LLM 可使用的字符串
results = [item.get("snippet", "") for item in data.get("results", [])]
return " ; ".join(results) # 拼接摘要返回
else:
return f"搜索错误(状态码 {resp.status_code})"
# 包装为 LangChain Tool
tavily_tool = Tool.from_function(
func=tavily_search,
name="TavilySearch",
description="使用 Tavily 联网搜索获取最新信息"
)以上为基础示例。实际使用中,可使用 LangChain 或 LangGraph 的 @tool 装饰器更优雅地创建工具。同时需考虑限流与异常处理------查询过于宽泛时 Tavily 可能需要特殊处理。
我们还可添加其他工具。例如 LangGraph 的 create_react_agent 会自动添加一些基础工具(如计算器等)。为聚焦核心,本智能体只使用 Tavily 工具。
现在创建智能体。有两种选择:
•
使用 LangChain 新版 create_agent 函数(内部使用 LangGraph 构建基于图的智能体)。
•
直接使用 LangGraph create_react_agent(效果非常接近)。
我们选择更常用的 LangChain create_agent。可按需为智能体行为编写系统提示词。
bash
from langchain.agents import create_agent
SYSTEM_PROMPT = "你是一个具备联网搜索能力的研究助手,需要时使用工具查找信息,然后给出详细回答。"
# 3. 创建智能体
agent = create_agent(
model=llm,
tools=[tavily_tool],
system_prompt=SYSTEM_PROMPT
)完成!我们现在拥有了一个使用本地 Qwen 模型(llm)、并能在合适时机调用 Tavily 搜索工具的智能体。该智能体本质实现 ReAct 循环:它会决定是否/何时使用 TavilySearch 工具,然后使用模型生成最终答案。
在 LangChain v1.x 中,智能体通过 invoke() 方法执行查询。我们用一个简单问题测试:
bash
# 4. 运行智能体,示例问题
user_question = "Python 最新发布版本是什么?主要新特性有哪些?"
result = agent.invoke({"messages": [
{"role": "user", "content": user_question}
]})
print(result["messages"][-1]["content"])我们按照预期格式传入用户查询(包含 messages 列表的字典,指定用户角色与内容)。智能体会执行完整推理:模型大概率决定使用搜索工具(Tavily)查询最新 Python 版本信息,通过 tavily_search 执行搜索、获取结果,然后继续对话生成答案。
关键在于 :因为我们在最开始注册了追踪器与埋点,所有步骤都会被自动追踪 。LangChain 的 OpenInference 埋点会自动为智能体的每一步创建 Span。每一次向 Qwen 的 LLM 调用(通过 ChatOpenAI)都会生成一个 Span,每一次工具调用(TavilySearch)也会生成 Span------包含工具的输入与输出。Phoenix 会实时捕获这些信息。
⏱️ 在 Phoenix 中观测追踪数据
智能体执行一次或多次查询后,打开 Phoenix UI(6006 端口的 Web 界面)。你应能在主页看到追踪列表 ------每一条追踪对应一次智能体调用(一次 agent.invoke)。例如执行上面的示例问题后,会出现一条追踪记录。
每条追踪包含追踪 ID、项目名(如 local-llm-app)、时间戳等元数据。点击某条追踪打开追踪详情页 。在这里你会看到智能体完整执行流程,以 Span 树形式展示(通常以时间线/甘特图或层级列表呈现):
•
顶层 Span 对应整次智能体运行(通常标记为智能体或链名称)。
•
下层会看到每一步的 Span:例如 LLM 思考步骤 Span、TavilySearch 工具调用 Span(含搜索查询)、处理工具结果的 LLM 调用 Span,以及最终答案生成 Span。
•
每个 Span 可点击查看详情:
•
输入:发送给模型的提示词或工具入参。
•
输出:模型生成内容或工具返回值。
•
延迟:该次调用耗时(Span 持续时间)。
•
属性:模型名称、Token 数量等元数据(Phoenix 会追踪 Token 用量,支持的厂商还会计算费用)。
因为我们安装了 LangChain 埋点,Phoenix 使用 OpenInference 语义约定对这些 Span 做有意义的标记(能区分工具与 LLM 等)。例如,智能体每一步、工具执行、最终响应都会自动追踪到 Phoenix。你应能在追踪中看到我们的工具名称(如 TavilySearch)。展开 Span 可查看 input.value 包含工具调用的 JSON(Phoenix UI 会友好格式化),output.value 为工具结果。LLM Span 中可看到提示词与模型原始响应。如果 vLLM 返回相关信息,Phoenix 还会展示 Token 使用量。
此外,Phoenix UI 支持筛选、搜索、对比追踪等功能。例如以表格展示所有追踪,包含延迟、总 Token 等列,可排序发现异常值。这是一套强大的 AI 可观测工具集,提供类似微服务 APM(应用性能监控)的能力,但专门为 LLM 应用定制。
我们现在实际上拥有了自己的、自托管的类 OpenAI 开发者控制台------可以实时观察提示词与工具的运行表现。
单次查询追踪在 Phoenix 中应呈现的内容简要回顾:
•
追踪时间线:按时间顺序展示动作(如"LLM: 思考"、"工具: TavilySearch"、"LLM: 回答")。
•
Span 详情:点击动作查看内容。Tavily 搜索 Span 中可看到智能体构造的搜索查询(可能包含原始问题或优化版本)与返回的置顶结果。LLM Span 中可看到提示词(含对话上下文、系统提示等)与模型输出。
•
性能指标:每个 Span 的耗时可见,顶层可看到整次追踪总时间。使用 OpenAI 时还会显示 Token 与成本;vLLM 需额外埋点才可展示,但延迟已可用。
•
项目与会话信息 :注册时设置 project_name="local-llm-app",Phoenix 会按项目归类追踪。可使用多个项目(如 dev vs prod)。我们未手动设置会话 ID,但如果提供 session_id,Phoenix 可对多轮对话分组。
这种可见性让我们能够调试与优化智能体:
•
查看智能体是否不必要或过于频繁地调用工具。
•
对比模型推理耗时与工具调用耗时。
•
发现模型提示词与预期不一致(例如系统提示未正确生效或工具说明需要优化)。
•
某步骤失败时(工具异常等),追踪会在对应 Span 标记错误状态。
🛠️ 运维技巧与辅助脚本
管理这套环境会涉及一些重复操作,这里提供几个实用脚本/命令与技巧:
•
部署/更新脚本 :如需重新部署 Phoenix(如更新版本或修改配置),可创建 deploy_phoenix.sh:
bash
#!/bin/bash
kubectl apply -k path/to/phoenix/kustomize/local -n phoenix这会重新应用 Kustomize 配置。由于我们为 Postgres 使用持久化存储,重新部署 Phoenix(甚至删除 Pod)不会丢失数据。
•
删除脚本 :如需销毁部署,可创建 delete_phoenix.sh:
bash
kubectl delete -k path/to/phoenix/kustomize/local -n phoenix
# 如需彻底删除命名空间:
# kubectl delete namespace phoenix注意:这也会删除 PVC(取决于 Kustomize 配置与回收策略),如需保留追踪数据请谨慎操作。
•
端口转发:无 LB 时快速访问:
bash
kubectl port-forward svc/phoenix-server -n phoenix 6006:6006 >/dev/null 2>&1 &
echo "Phoenix UI 已启动:http://localhost:6006"& 会后台运行。使用完毕记得关闭端口转发进程。
•
环境配置 :开发环境中,可将 PHOENIX_COLLECTOR_ENDPOINT 写入 .env 或 Jupyter 内核启动脚本,避免每次设置。也可在代码中通过 register(endpoint="http://<host>:6006") 显式指定,不依赖环境变量。Phoenix 文档两种方式均支持;环境变量通常更简洁。
•
项目命名 :可在 register() 中使用不同 project_name 逻辑分离追踪(如 my-llm-app-dev 与 my-llm-app-prod)。Phoenix UI 支持按项目筛选。本地开发可统一使用一个名称。
🐛 故障排查与常见问题
即使指南再完善,实际部署仍可能遇到问题。以下是本方案的常见排查思路:
•
Phoenix UI 无追踪数据 :能打开 UI 但运行智能体后无数据,首先确认智能体代码在 register() 之后才真正执行。如果已执行,大概率是网络连通问题。检查 PHOENIX_COLLECTOR_ENDPOINT 是否正确设置为可访问的 Phoenix 地址。使用端口转发时应为 http://localhost:6006(无需 /v1/traces,SDK 会自动拼接路径)。使用 LoadBalancer 时为 http://<LB-IP>:6006。可在开发机器上测试连通性:
bash
curl -X POST http://
<
phoenix_host
>
:6006/v1/traces -H "Content-Type: application/x-protobuf" --data-binary @/dev/null无有效数据不会完全正常,但应返回 400 类状态码,证明能访问端点。同时查看 Phoenix 服务端日志(kubectl logs phoenix-server)确认是否收到追踪数据或报错。端点错误或防火墙拦截都会导致数据无法到达。显式设置环境变量通常能解决地址不匹配问题。
•
安装了错误的 phoenix 包 如前所述,如果误执行 pip install phoenix(会安装 2013 年的 0.9.1 版本),会出现报错(尤其 Python 3.11+)。解决方法:卸载旧版,安装 arize-phoenix。始终使用带 arize- 前缀的官方包。
•
版本不匹配 确保 arize-phoenix-otel 与 openinference-instrumentation-langchain 版本兼容。这些库更新较快,如果分时段安装,新版 Phoenix 可能依赖新版埋点。建议一起更新:
bash
pip
install
-U
arize-phoenix
arize-phoenix-otel
openinference-instrumentation-langchain•
LangChain 版本问题 本文智能体代码使用 LangChain v1.x 风格 API(create_agent、agent.invoke)。确保安装 langchain>=1.0.0。旧版 0.xx 无 create_agent。langchain-openai 子包通常会依赖 LangChain 1.x core。如遇问题,可显式安装指定版本:
bash
pip
install
langchain==1.2.x同时注意 LangChain v1 调整了导入路径(如使用 langchain_openai)。出现导入错误时,检查子包是否正确安装。
•
Tavily API 问题 智能体搜索结果不佳或报错,可能是 Tavily 集成问题。确保 API Key 有效且未超限。可在测试时打印/记录 tavily_search 函数行为。这是第三方工具调用,智能体默认不会自动重试;失败会以错误 Span 传播。Phoenix 会标记异常 Span,可在属性或日志中查看详情。
•
Kubernetes/Phoenix 问题
•
Phoenix Pod 崩溃或无法启动:查看日志。常见问题是无法连接 Postgres(如 Postgres 尚未就绪)。Kustomize 应能处理启动顺序,如未生效可重新应用或确保 Postgres 先运行。Phoenix 会短暂重试,数据库长期不可达可能退出。Postgres 运行后重启 Phoenix Pod 即可。
•
Postgres Pod 崩溃循环:进入容器或查看日志排查密码问题。默认配置可能使用空密码或默认用户。Kustomize 基础模板可能通过 Secret 创建随机密码。确保 Phoenix 使用相同配置。开发环境最简单方式是使用默认凭证或设置无密码。如需自定义密码,需同时更新 Postgres 与 Phoenix 部署。
•
PVC 处于 Pending 状态 :存储类名称不匹配或 Longhorn 未设为默认。核对 storageClassName: longhorn(根据实际名称调整)。执行 kubectl get storageclass 查看可用存储类。可按需补丁 PVC 或存储类。Longhorn 安装时通常会自动设为默认(除非手动修改)。
•
LoadBalancer 外部 IP 未分配 kubectl get svc phoenix-server 显示外部 IP 为 <pending>,说明集群未安装 LoadBalancer 插件。裸金属环境需要安装并配置 MetalLB 与 IP 池。如未配置,可使用端口转发或 NodePort Service 作为替代方案。
•
OpenTelemetry 数据量如果大量生成追踪(如循环执行多次查询),注意内存与存储。Phoenix 会将追踪数据存入 Postgres------文本数据可能快速增长。开发环境无压力(Phoenix UI 支持筛选与导出),但数万条追踪时需关注存储,可分配更大 Postgres 存储空间或清理旧数据。Phoenix 支持数据保留配置(默认无限保留),可通过环境变量调整。
•
性能考虑 在 vLLM 上运行 Qwen FP8 模型非常消耗资源。如果智能体响应慢,通常是 Qwen 本身较大导致------约 43 token/s 是纯生成速度,提示词较长或多步推理会增加耗时。这在单 GPU 运行 7B+ 模型时属于正常现象。可观测性埋点开销极小(OpenTelemetry 非常轻量),如怀疑性能影响,可在 register() 中关闭批处理或切换为 gRPC 协议。默认 HTTP/protobuf 对开发环境足够。
最后请记住:可观测性是迭代优化的助力。通过 Phoenix 追踪,你可能发现某个提示词导致智能体无效循环,或某个工具耗时过长。然后优化系统提示或代码,重新部署(Phoenix 无需改动),再次测试。Phoenix 会捕获新追踪,方便前后对比。这种快速闭环能显著加速 LLM 应用调试------否则它们往往像黑盒一样难以理解。
🧪 演示:运行智能体 + 在 Phoenix 中查看追踪(端到端)
本节提供实用"完整性验证演示",确认全链路正常工作:
智能体(LangChain/LangGraph)→ vLLM(Qwen)→ Tavily 工具调用 → OpenTelemetry Span → Phoenix UI
1)使用可直接运行的 Jupyter 笔记本与依赖清单
我在 GitHub 维护了一套可复现的演示笔记本(含 requirements.txt):
在 DGX-Spark 节点(或智能体运行环境)克隆:
bash
git clone https://github.com/dorangao/article-scripts.git
cd article-scripts/arize创建环境并安装依赖(任选一种方式):
bash
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt2)设置环境变量(vLLM + Phoenix + Tavily)
bash
export OPENAI_API_KEY="unused" # vLLM 不需要,但 SDK 通常要求存在
export OPENAI_BASE_URL="http://localhost:8888/v1"
export PHOENIX_COLLECTOR_ENDPOINT="http://localhost:6006" # 或 http://<phoenix-lb-ip>:6006
export TAVILY_API_KEY="<your_tavily_key>"如果 Phoenix 运行在 Kubernetes 且未使用 LoadBalancer,在另一个终端启动端口转发:
bash
kubectl
port-forward
svc/phoenix-server
-n
phoenix
6006:60063)运行演示笔记本
打开笔记本,从上到下依次执行单元格。你应能看到:
•
至少一个 LLM Span(vLLM 调用)
•
至少一个 工具 Span(Tavily 搜索)
•
每次智能体调用对应一条追踪
4)在 Phoenix UI 中验证
打开 Phoenix:
•
http://localhost:6006(端口转发),或
•
http://<LB-IP>:6006(LoadBalancer)
在追踪视图中,点击某条追踪并确认能看到:
•
智能体执行步骤
•
LLM 请求/响应
•
Tavily 工具输入/输出
•
每个 Span 的耗时
🎉 总结
我们已经搭建了一套健壮的本地 LLM 可观测技术栈:
•
vLLM 服务托管强大的开源模型
•
集成实时搜索的 LangChain/LangGraph 智能体
•
Arize Phoenix 追踪每一步执行
这套方案让 MLOps 工程师与 LLM 开发者能够在本地或私有化环境自由实验,同时对智能体行为与性能保持完全可见。
我们介绍了各组件的架构与作用(vLLM 用于本地模型服务、Tavily 用于知识增强、Phoenix 用于追踪与评估),完成了基础设施部署(通过 Kustomize 在 K8s 上部署 Phoenix + Postgres),使用基于 OpenTelemetry 的现代工具完成代码埋点,并演示了如何执行查询与检视追踪数据。
按照本指南操作,你可以搭建属于自己的"类 OpenAI 开发栈" ,且完全自包含。你不仅能回答"模型输出了什么?",还能清晰知道"为什么这样输出?为了得到答案做了哪些步骤?"------一切都在本地环境完成。
祝你链路观测愉快!🚀