先看一组真实的生产数据。
一个有1000家门店的连锁企业,订货系统下单接口的峰值TPS是20。一个有2亿用户的平台,大促期间下单接口的TPS是2000。同一个平台的商品系统,整个域的峰值QPS是70万,分摊到单台机器大约3万多。
大多数系统的实际并发量,比你想象中低得多。
这组数据抛出来,很多人的第一反应是:那我们系统TPS才个位数,是不是不用考虑并发了?
这个想法,每年都在制造线上事故。
两个概念别混在一起
行业里经常把两件事搅在一起说:一件是「高并发架构」,另一件是「并发控制」。
高并发架构解决的是性能问题:系统能不能扛住大流量。缓存、分库分表、读写分离、异步削峰,这些技术的目的是让系统在大流量下不崩溃。流量不大的系统,确实不需要急着上这些东西。
并发控制解决的是正确性问题:多个请求同时操作同一份数据,结果对不对。锁、事务隔离级别、幂等设计,这些技术的目的是保证数据不出错。
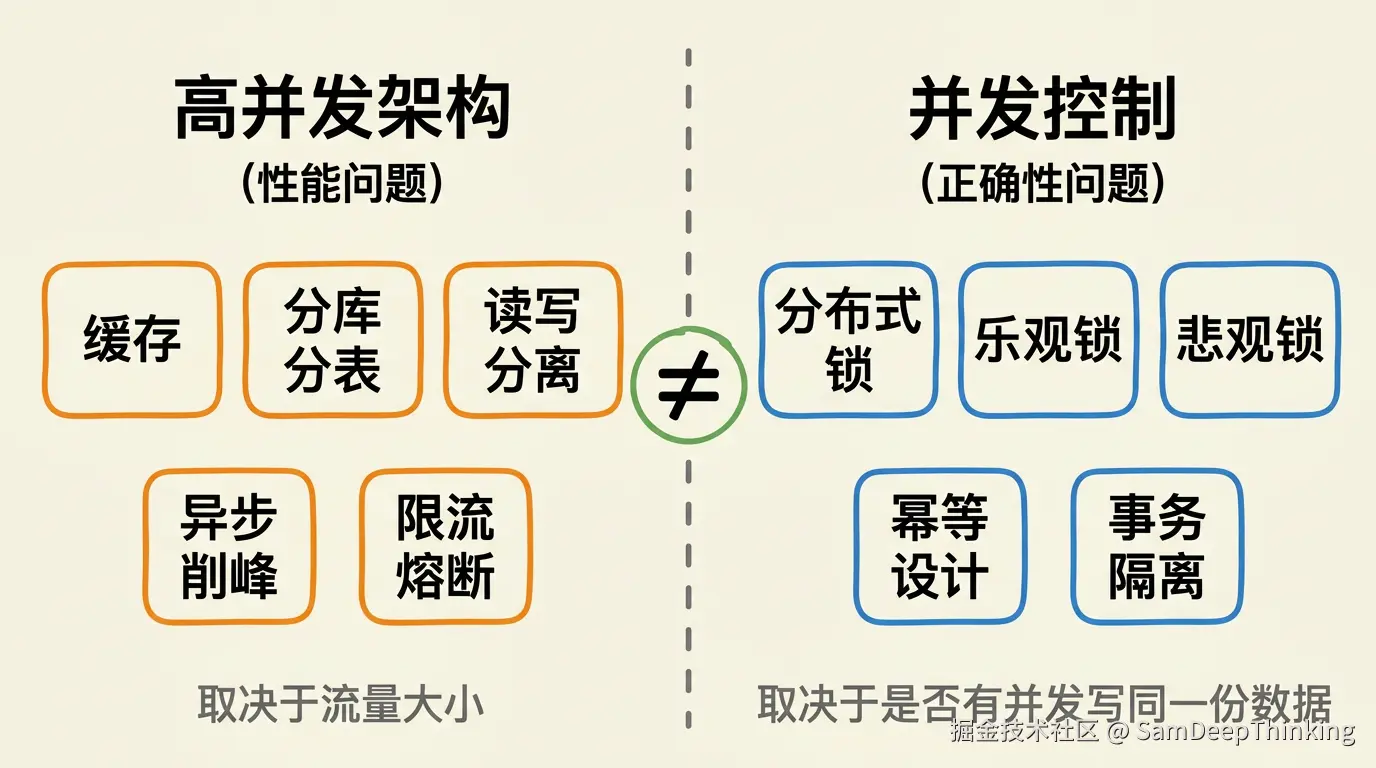
这两件事的驱动力完全不同。高并发架构取决于流量大小,并发控制取决于「有没有两个请求可能同时改同一份数据」。
一个TPS只有20的系统,如果两个请求在同一毫秒内修改了同一条记录,数据照样会错。并发控制保护的是数据正确性,跟TPS是20还是20万没关系。
有人可能会说:TPS才20,两个请求同时到达的概率极低,实际不太会出问题。
这个想法很危险。概率低不等于不会发生。线上事故有个规律:小概率事件一定会发生,而且往往在你最不方便处理的时候发生。业务规则被打破、数据被写坏、资金出现差异,排查一次这种问题花的时间,远超提前写几行锁代码的成本。
下面用三个真实的业务场景说明,为什么并发量再低,该加的控制一个都不能省。
门店下单:分布式锁防重复提交
场景是这样的:一个连锁企业的订货系统,业务规定每家门店每天只能提交一张订货单。1000家门店,TPS峰值20,分摊到单个门店几乎没有并发。
问题出在「几乎」两个字上。
门店A有两个店员,张三和李四,都有下单权限。某天下午两点,张三在电脑上点了提交,李四在手机上也点了提交。两个请求间隔不到1秒。
代码里的逻辑通常长这样:先查今天有没有订单,没有就插入。
Java
// 查询今天是否已下单
Order existing = orderMapper.selectByStoreAndDate(storeId, today);
if (existing != null) {
throw new BusinessException("今天已经下过单了");
}
// 插入新订单
orderMapper.insert(newOrder);两个请求几乎同时执行到查询那一步,都查到「今天没单」,然后都走到插入逻辑,两张订单都写进去了。一天只能下一单的业务规则,就这么被打破了。
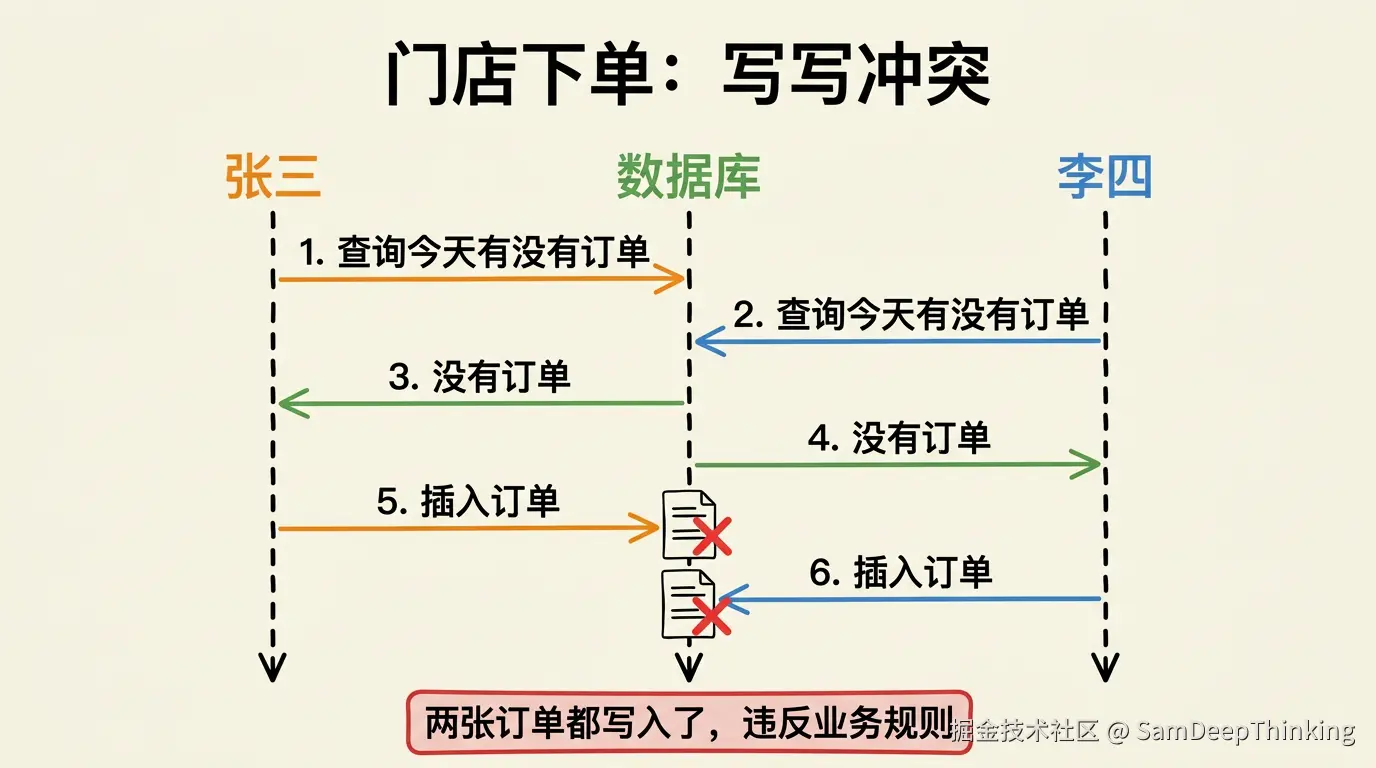
这跟TPS高不高没关系。只要两个请求的执行时间窗口有重叠,问题就会出现。
有人会想到用数据库唯一索引来兜底:给门店ID + 日期建一个唯一索引,第二条插入自然会报错。在这个场景下,唯一索引确实能防住。
真实业务里,下单往往不只是往一张表插一条记录。可能还涉及校验库存、锁定配送额度、生成物流预约单等多步操作。唯一索引只能保证单表单字段组合的唯一性,保证不了一串业务操作的互斥执行。
这种场景需要的是分布式锁。用Redis的SET命令带NX和EX参数,在业务逻辑执行前获取锁,执行完释放锁。
Java
// 锁的key按门店ID+日期粒度
String lockKey = "order:lock:" + storeId + ":" + today;
// 尝试获取锁,超时时间30秒
Boolean acquired = redisTemplate.opsForValue()
.setIfAbsent(lockKey, requestId, 30, TimeUnit.SECONDS);
if (!acquired) {
throw new BusinessException("有其他人正在提交订单,请稍后再试");
}
try {
// 查询今天是否已下单
Order existing = orderMapper.selectByStoreAndDate(storeId, today);
if (existing != null) {
throw new BusinessException("今天已经下过单了");
}
// 执行完整的下单逻辑
orderMapper.insert(newOrder);
} finally {
// 释放锁前确认是自己持有的
if (requestId.equals(redisTemplate.opsForValue().get(lockKey))) {
redisTemplate.delete(lockKey);
}
}锁的粒度选在门店ID + 日期这一层,不同门店之间互不影响。释放锁的时候要校验requestId,防止一种情况:A请求的锁超时自动释放了,B请求拿到了新锁,A执行完把B的锁给删了。
这里的释放锁操作(先GET再DELETE)不是原子的,严格场景下应该用Lua脚本保证原子性。在门店下单这种TPS极低的场景,概率已经很小了,但如果你的团队有规范要求,用Lua脚本是更稳妥的做法。
这段代码加上也就多了十几行。不加的话,一旦出了重复订单,排查数据、通知门店、人工干预,花的时间远超写这几行代码。
库存扣减:乐观锁防超卖
库存扣减是另一个典型场景。商品库存100件,两个用户同时下单各买1件,扣完应该剩98件。
不做任何并发保护的代码:
Java
// 查询当前库存
int stock = goodsMapper.selectStock(goodsId);
if (stock < quantity) {
throw new BusinessException("库存不足");
}
// 扣减库存
goodsMapper.updateStock(goodsId, stock - quantity);两个请求同时读到库存是100,各自算出100-1=99,两次UPDATE都把库存写成了99。卖出了2件,库存只减了1。
这个问题在并发量为2的时候就能触发。
这种场景跟门店下单不太一样。门店下单是互斥操作,同一时间只能有一个请求通过。库存扣减是竞争操作,多个请求都可以扣,只是结果不能算错。
用分布式锁也能解决,把所有扣减请求排成队,一个一个来。代价是同一商品的所有下单请求变成了串行执行,在库存充足的正常情况下,这种排队完全没必要。
乐观锁更适合这种「冲突概率低,但必须保证正确」的场景。
实现方式是给库存表加一个version字段,每次更新的时候把当前version带上:
SQL
UPDATE goods
SET stock = stock - #{quantity}, version = version + 1
WHERE id = #{goodsId}
AND version = #{currentVersion}
AND stock >= #{quantity}如果两个请求同时读到version=1,先执行的那个更新成功,version变成2。后执行的那个发现version已经不是1了,UPDATE影响行数为0,表示这次扣减没生效。

更新失败的请求需要重试:重新查一次最新的库存和version,再尝试扣减。通常重试2到3次就够了,因为在库存充足的情况下冲突概率本来就低。
Java
int maxRetry = 3;
for (int i = 0; i < maxRetry; i++) {
Goods goods = goodsMapper.selectById(goodsId);
if (goods.getStock() < quantity) {
throw new BusinessException("库存不足");
}
// 带version的扣减
int affected = goodsMapper.decreaseStock(
goodsId, quantity, goods.getVersion()
);
if (affected > 0) {
return;
}
// affected为0说明有并发修改,重试
}
throw new BusinessException("系统繁忙,请重试");SQL里同时带了 stock >= #{quantity} 这个条件,值得说一下原因。version只能防止并发覆盖,不能防止库存扣成负数。假设库存只剩1件,两个请求同时来扣,第一个扣减成功后库存变成0,第二个重试时如果不检查库存够不够,就会把库存扣成-1。
乐观锁和悲观锁的选择有一个判断标准:冲突频率 。冲突少的时候用乐观锁,大多数请求一次就成功,偶尔重试一下。冲突多的时候用悲观锁(SELECT ... FOR UPDATE),直接排队反而比大面积重试的效率高。秒杀场景、热点账户的余额变更,这些冲突概率很高的操作,悲观锁更合适。
热key缓存失效:并发读也要加锁
前面两个场景都是写冲突。再看一个纯读的场景。
商品系统里有些热key,比如首页推荐的爆款商品,访问频率很高,数据放在本地缓存里。某一刻这个key的缓存过期了,恰好有2个读请求同时进来。两个请求都发现本地缓存里没有数据,都去查数据库,都拿到结果往缓存里写。
并发量只有2,问题已经出现了:数据库被查了两次,其中一次完全多余。单个key多查一次好像没什么,但热key过期不会只影响一个key。如果系统里几十个热key在同一时间段过期,每个key都有2到3个请求穿透到数据库,加起来就是上百次不必要的查询,数据库压力瞬间上来。
处理方式是加一把锁:缓存没命中时,只放一个请求去查数据库,其他请求等着。等第一个请求把数据塞进缓存后,后面的请求直接从缓存读。
Java
// 按商品ID粒度加锁,不同商品之间互不影响
private final Map<Long, Object> lockMap = new ConcurrentHashMap<>();
public Goods getGoods(Long goodsId) {
// 先查本地缓存
Goods goods = localCache.get(goodsId);
if (goods != null) {
return goods;
}
Object lock = lockMap.computeIfAbsent(goodsId, k -> new Object());
synchronized (lock) {
// 拿到锁之后再查一次缓存,可能已经被前一个请求加载好了
goods = localCache.get(goodsId);
if (goods != null) {
return goods;
}
// 缓存确实没有,查数据库并回填
goods = goodsMapper.selectById(goodsId);
localCache.put(goodsId, goods);
}
return goods;
}拿到锁的请求去查数据库并回填缓存,没拿到锁的请求在 synchronized 这里等着。等前一个请求执行完,后面的请求进来后先查一次缓存,发现已经有了,直接返回,根本不会再查数据库。
小结
回到开头那个问题:TPS和QPS到多少才算高并发?
问题本身就偏了。高并发是个相对的概念,对你的系统来说处理不过来就是高并发,跟绝对数字无关。更关键的是,很多人把「高并发架构」和「并发控制」画了等号,觉得流量不大就可以不做防护。
实际项目里,大部分线上事故不是系统扛不住流量崩掉的,而是数据在某个不起眼的并发窗口被写坏了。重复订单、库存超卖、余额对不上,这些问题的根源都是并发控制缺失,跟流量大小无关。
我见过不少团队在技术方案评审的时候,一听到TPS不高,并发相关的设计就直接跳过了。这种省事的代价,往往是在某个深夜被叫起来排查数据问题。加几行锁的代码成本很低,排查一次数据不一致的成本很高。从投入产出比来看,并发控制应该是代码里的标配,不是等出了事再补的可选项。
最近在知乎出了「应付6000万会员的秒杀系统专栏」和「几亿用户,百万并发的C端商品系统实战」专栏,感兴趣的可以订阅一下。至于知识星球的,可以搜:
- 老码头的技术浮生录
它是一个能实际帮你解决难题的星球。有问题的,找知心的Sam哥,支持无限次语音一对一解决你遇到的难题。「另外后续我新写的所有对外的付费专栏,在星球内都是免费的,且可以拿到所有源代码。」
知识星球内后续将推出20+个付费专栏,覆盖电商全链路:
| 选购线 | 用户会员营销线 | 中后台 |
|---|---|---|
| 购物车服务 | 营销系统 | 订单系统 |
| 商品服务 | 用户系统 | 支付系统 |
| 菜单服务 | 结算服务 |
从前台选购到中后台结算,星球成员全部免费,后续新增也不额外收费。
我的知乎账号:
- SamDeepThinking