一个你每天都在做的操作
打开 Figma,或者启动蓝湖(Lanhu)查看标注,又或是打开 Lovart 开始绘图。
双指捏合,画布缩小了。两指一推,画布滑到了左边。点一下那个蓝色的矩形,选中了。
你每天都在做这三步。你从来没有觉得它们有什么值得思考的。
但我想请你回答一个问题:
这三步操作里,有几个坐标系在同时工作?
你大概会说:一个吧。就是画布的坐标系嘛,X 和 Y,所有东西都在里面。
不对。
答案是至少三个。而正是这个"至少三个",分开了"会用画布"和"理解画布"的两种人。
画布没有动过
我们来思考一个问题。
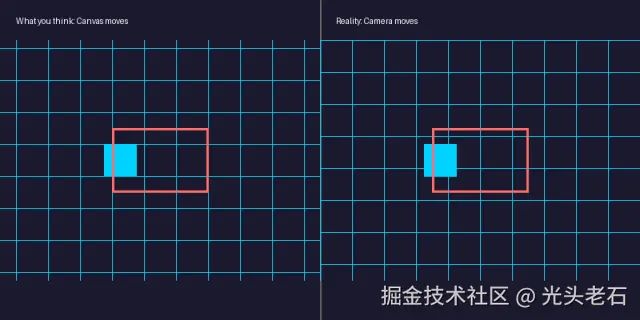
你在 Figma 里按住空格键拖动,画面跟着你的手指在移动。你管这叫"拖动画布"。
但请你换一个视角想想------
如果画布真的在动,画布上的那些矩形、文字、线条,它们的坐标变了吗?
答案是: 没有。
你给一个矩形定的位置是 (200, 300),无论你怎么拖、怎么缩放,这个矩形在画布世界里的坐标始终是 (200, 300)。没有任何东西移动了。
那到底什么在动?
你在动。
或者更准确地说------你的"摄像机"在动。
这不是一个比喻。这就是无限画布的字面原理。你的屏幕是一个取景框,画布世界是一个无限延伸的平面,你的每一次拖拽,不是在推动世界,而是在推动自己的视口。
如果你玩过超级马里奥 ------你对这件事不会陌生。马里奥往前跑的时候,屏幕跟着移动,但世界并没有向后走。世界始终在那里,移动的是摄像机。
无限画布的逻辑完全一样。
Coordinate System Animation
Google Maps 更直观。你在手机上滑动地图,你管它叫"移动地图",但地球显然没有动。你移动的是你的观测位置。
现在你可以理解为什么答案是"至少三个坐标系"了:
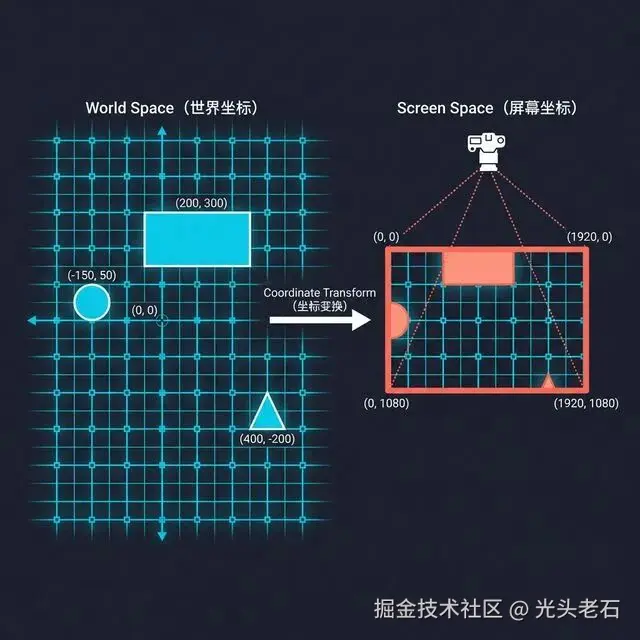
世界坐标系(World Space) :画布世界本身的坐标。一个矩形在 (200, 300),它就永远在那里,跟你的拖拽无关。这是物体存在的坐标。
屏幕坐标系(Screen Space) :你的显示器上的像素坐标。鼠标在屏幕上的 (500, 400),这是你手指触达的坐标。
局部坐标系(Local Space) :一个对象相对于它父级的坐标。一个文字节点在某个分组(Group)里面,它的位置是相对于那个分组的。这是对象相对存在的坐标。
三个坐标系,三套数字,每一次用户操作都要在它们之间做转换。
这才是无限画布做的事。
摄像机:一个被隐藏的核心概念
如果你做过 Canvas 白板开发,你可能写过类似这样的逻辑:
当用户拖拽时,你维护一对 offsetX / offsetY,然后在每帧渲染时,把所有元素的坐标都减去这个 offset 再画。
这就是一个摄像机。只不过你可能从来没有这么叫过它。
当用户缩放时,你维护一个 scale 变量,渲染时把所有坐标乘以这个 scale。
这也是摄像机的一部分------焦距。
把这些变量合在一起看,你有的是:
yaml
12345
Camera { x: number // 摄像机在世界中的 X 位置 y: number // 摄像机在世界中的 Y 位置 zoom: number // 缩放比例}这三个数字,定义了"你在世界中站在哪里、看多大范围"。
可能你之前从没有把 offsetX / offsetY / scale 想象成一台摄像机。但一旦你这么理解了,很多事情会突然变得清晰。
缩放不是把对象放大,是把摄像机推近了。
这个区别不是语言游戏。当你"放大一个矩形"时,矩形的世界坐标和宽高没有变------(200, 300) 和 100×100 还是那些数字。改变的是摄像机的 zoom 值。当 zoom 从 1 变成 2,每个世界坐标映射到屏幕上的像素数翻倍了,所以你"看起来"矩形变大了。
这就是为什么缩放时所有元素保持相对位置不变------因为它们根本没动。动的是你看它们的方式。
如果你用 Fabric.js,你调用的 canvas.setViewportTransform() 本质上就在设置这台摄像机的参数。如果你用 Canvas 2D 原生 API,你调用的 ctx.setTransform() 或 ctx.translate() + ctx.scale() 也是在操纵这台摄像机。
你一直在用摄像机。只是没有人告诉过你。
坐标变换:整个系统的地基
有了摄像机的概念,一个核心问题浮现了:
用户点击屏幕上的 (500, 400),他到底点中了世界里的谁?
这是每一个画布系统都必须回答的问题。它的学名叫 Hit Testing(命中测试),但本质上,它是一个坐标变换问题。
从屏幕坐标到世界坐标的转换公式概念上很简单:
ini
12
worldX = (screenX - camera.x) / camera.zoomworldY = (screenY - camera.y) / camera.zoom屏幕上的点,减去摄像机的偏移量,再除以缩放比例,就得到了这个点在世界中的真实位置。
反过来也成立。你有一个世界坐标 (200, 300),想知道它在屏幕上画在哪里:
ini
12
screenX = worldX * camera.zoom + camera.xscreenY = worldY * camera.zoom + camera.y这两个公式是无限画布的心脏。 你做的每一件事------选中、拖动、缩放、对齐、吸附------都在使用它们的某种变体。
如果你用矩阵来表达,这就是一个仿射变换矩阵的正变换和逆变换。但关键不在于数学形式,而在于你是否意识到:
你的画布系统里,每一次用户输入和每一次渲染输出,中间都隔着一层坐标变换。 不理解它,你写的代码就是在黑暗中摸索;理解了它,所有后续的工程决策都有了一个统一的锚点。
这个模型解释一切
一旦你接受了"世界 + 摄像机"的理解模型,很多看似复杂的特性都变得顺理成章。
多人协作
Figma 的多人协同是怎么回事?多个用户在同一个画布上编辑,你能看到其他人的光标在你的屏幕上移动。
用摄像机模型来理解:世界只有一个,但每个用户有自己的摄像机。
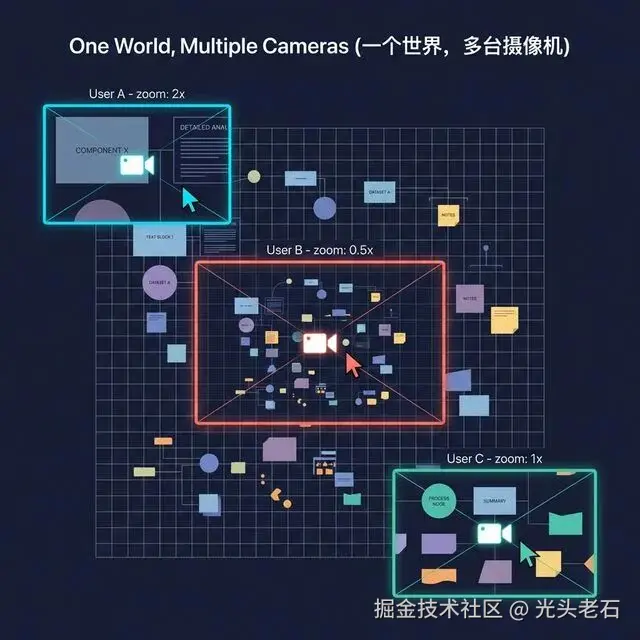
用户 A 可能正在看世界的左上角,zoom 是 1.5;用户 B 正在看右下角,zoom 是 0.5。他们操作的是同一个世界里的同一批对象,但"看到的画面"完全不同------因为他们的摄像机位置和焦距不同。
要在你的屏幕上显示其他人的光标,你需要做一步坐标转换:
把对方的世界坐标位置,经过你自己的摄像机变换,映射到你的屏幕上。
这就是为什么当你缩放自己的画布时,其他人的光标也会跟着缩放------因为你改变了自己的摄像机参数,同一个世界坐标映射到屏幕上的位置变了。
缩放到指定位置(Zoom to Point)
你有没有注意过:在 Figma 里双指缩放时,画布是围绕你手指中心点缩放的,而不是围绕画布中心?
这不是简单地修改 zoom 值。如果你只改 zoom,画面会围绕摄像机的原点缩放,效果会很怪。正确的做法是:在改变 zoom 的同时,调整摄像机的 x 和 y,使得手指所在的那个世界坐标点在缩放前后映射到屏幕上的同一个像素。
这又是一个坐标变换问题。如果你没有摄像机模型,你很可能会写一大堆看起来能用但自己也说不清为什么的补偿代码。有了这个模型,逻辑是干净的。
图层(Layer)
你可能习惯了 CSS 的 z-index。在画布世界里,图层是另一件事。
画布中的图层不是 DOM 层级的概念。它是世界空间中的 Z 轴排序------哪个对象"在上面",哪个"在下面"。这个顺序是画布世界数据的一部分,跟渲染层级没有直接关系。
Canvas 2D 的渲染是画家算法(Painter's Algorithm):后画的覆盖先画的。所以图层顺序直接决定了你的绘制顺序。你改变了图层,不是在改变某个 CSS 属性------你在改变世界的一部分。
视口裁剪(Viewport Culling)
当你的画布上有 10 万个元素,但你的屏幕只能看到其中 200 个时,你不需要渲染全部 10 万个。
你需要做的是:用摄像机的位置和 zoom 计算出当前视口在世界空间中覆盖的矩形范围,然后只渲染落在这个范围内的元素。
这就是视口裁剪。又是一个纯坐标变换问题。没有摄像机模型,你甚至不知道从哪里开始思考这个优化。
你以为的 vs 实际的
让我把这些放在一起,做一个对比:
| 你以为的 | 实际上 |
|---|---|
| 拖动了画布 | 移动了摄像机 |
| 放大了元素 | 改变了摄像机焦距 |
| 画布是有边界的 | 世界是无限的,有限的是视口 |
| 图层是 CSS 概念 | 图层是世界空间的 Z 排序 |
| 点击选中了某个元素 | 屏幕坐标经坐标逆变换后做命中测试 |
| 多人协作是同步画面 | 多台摄像机观察同一个世界 |
| 缩放是视觉效果 | 缩放是摄像机的空间变换 |
如果你做过画布项目,你现在可以回头重新审视自己的代码。那些 offsetX、offsetY、scale、translateX ------它们不是零散的状态变量。它们是一台摄像机的参数。你的渲染函数不是在"画东西",它是在"拍摄世界"。
这不是一个更好的术语,而是一个更好的心智模型。 心智模型决定了你能优雅地解决多少问题,以及在多少问题前一脸茫然。
为什么这很重要
你可能会想:这就是个模型上的区别,代码还是那些代码啊。
不一样。
当你用 DOM 思维去做画布,你会不自觉地把每一个需求当成独立问题去"打补丁":这里加个 offset,那里乘个 scale,在某个角落补一个不知道为什么 work 的反向偏移。
但当你用"世界 + 摄像机"思维做画布,你有一个统一的框架可以推导:
- • 需要做选中?→ 先把屏幕坐标变换到世界坐标,再做碰撞检测。
- • 需要做缩放到点?→ 求解摄像机参数在变换前后的约束方程。
- • 需要做多人协作?→ 不同摄像机看同一个世界,坐标变换是桥梁。
- • 需要做视口裁剪?→ 用摄像机参数计算视口在世界中的矩形范围。
每一个问题都回到同一个地基。 这就是心智模型的威力------它不给你答案,但它给你一致的推理起点。
这也是为什么有些人做画布做了两年,代码里还全是看不懂的 magic number 和 workaround;而另一些人做了三个月,系统干净得像教科书。区别不在编码水平,在于脑子里有没有一个足够好的模型。
不理解坐标系统的人,写出的画布代码永远是在打补丁。
无限画布的一句话定义
写到这里,我可以给你一个你在别处看不到的定义:
无限画布 = 一个无限世界 + 一台摄像机 + 一套坐标变换规则
世界负责"有什么"------对象、位置、层级。摄像机负责"看什么"------偏移、缩放。坐标变换负责"如何翻译"------用户输入到世界位置,世界位置到屏幕像素。
这三个部分耦合得极紧,但职责完全不同。理解了这个结构,你才算理解了无限画布的第零步------在谈论渲染技术、交互系统、协同架构之前,你首先需要理解的那个东西。
下一篇
如果你接受了"画布世界 + 摄像机" 这个理解模型,下一个问题是:
谁来负责渲染这个世界?
下一篇,我们来聊无限画布的渲染技术。