一、前言
达梦数据库支持丰富的分区技术,包括范围分区、列表分区、哈希分区以及它们的组合。理论上,分区能够通过"分而治之"的方式减少数据扫描范围,提升查询性能。但是,分区在带来查询优势的同时,是否会对批量写入和更新造成额外的开销?一级分区与更复杂的二级分区在应对高频写入时,性能差异究竟有多大?如果不分区,在极端数据量下普通表的写入性能是否会急剧恶化?
为了解答这些疑问,本文设计了一组对比测试。我们将深入实地,在同一硬件与软件环境下,在DMDSC架构中,针对无分区(普通表)、一级分区以及二级分区三种表结构,进行大规模的批量插入与更新速度测试。
通过本次测试,我们不仅希望能直观展示不同分区策略下的性能数据,更期望能为读者在达梦数据库的表结构选型时提供一份有价值的参考。
二、环境准备和测试设计
2.1环境说明
|--------|-------------------------------------------------|
| 配置项 | 配置说明 |
| 操作系统版本 | X86_centos7.9 |
| 数据库版本 | dm8_20251023_x86_centos6_64_sec_8.1.4.116_pack8 |
2.2网络说明
|-------------|------|-------|
| IP地址 | 端口 | 说明 |
| 10.77.16.11 | 5237 | DSC01 |
| 10.77.16.12 | 5238 | DSC02 |
| 10.77.16.13 | 5239 | 备库 |
2.3测试设计
(1)数据准备
本次测试的数据集规模为 1000 万条记录,由 SQLark 工具生成。为模拟高并发写入场景并提升数据加载效率,我们使用 DTS 工具将数据拆分为 10 个独立的 TXT 文件,每个文件承载 100 万条数据,以便后续通过脚本进行并行读取与插入操作。
此外,考虑到测试环境基于 Linux/Unix 系统,而不同工具生成的文件可能存在格式差异,我们统一通过 vi 命令 :set ff=unix 对导出文件进行格式转换,确保换行符正确解析,避免因文件格式问题导致数据加载失败或解析异常。
(2)测试程序准备
本次测试工具使用的是一个很厉害的老师编写的并发读写测试程序,稍微修改一下就能实现并发的插入和更新操作,通过修改测试程序包中makefile中的OCI动态库的include和lib目录路径,编译后生成dmocidemo程序,并修改paralle_load.sh脚本中数据库和表的相关信息和参数选择来实现向表中插入和更新数据。
(3)不分区、一级分区、二级分区表的准备
不分区表:
包括create_date,datasource_id,id,meas_type四个关键字段以及V0015,V0030等等以15分钟为时间戳的字段来模拟正式业务,保证数据量较大
CREATE TABLE "SG_DEV_DBREAKER_H15_MEA_2025"
( "DATASOURCE_ID" VARCHAR(10) NOT NULL,
"CREATE_DATE" DATETIME(0) NOT NULL,
"MEAS_TYPE" VARCHAR(8) NOT NULL,
"ID" VARCHAR(18) NOT NULL,
"V0015" NUMBER(16,4),
"V0030" NUMBER(16,4),
"V0045" NUMBER(16,4),
"V0100" NUMBER(16,4),
"V0115" NUMBER(16,4),
"V0130" NUMBER(16,4),
"V0145" NUMBER(16,4),
"V0200" NUMBER(16,4),
"V0215" NUMBER(16,4),
"V0230" NUMBER(16,4),
"V0245" NUMBER(16,4),
"V0300" NUMBER(16,4),
"V0315" NUMBER(16,4),
"V0330" NUMBER(16,4),
"V0345" NUMBER(16,4),
"V0400" NUMBER(16,4),
"V0415" NUMBER(16,4),
"V0430" NUMBER(16,4),
"V0445" NUMBER(16,4),
"V0500" NUMBER(16,4),
"V0515" NUMBER(16,4),
......
"V2230" NUMBER(16,4),
"V2245" NUMBER(16,4),
"V2300" NUMBER(16,4),
"V2315" NUMBER(16,4),
"V2330" NUMBER(16,4),
"V2345" NUMBER(16,4),
"V2400" NUMBER(16,4),
CONSTRAINT "PK_SG_DEV_DBREAKER_H15_MEA_2025" PRIMARY KEY ("DATASOURCE_ID", "CREATE_DATE", "MEAS_TYPE", "ID") );
一级分区表:
以datasource_id做一个分区,假设该字段一共有11种值,分别代表浙江各地市
PARTITION BY LIST("DATASOURCE_ID")
( PARTITION "P3301" VALUES('0021330100') STORAGE(ON "MAIN", CLUSTERBTR),PARTITION "P3302" VALUES('0021330200') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3303" VALUES('0021330300') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3304" VALUES('0021330400') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3305" VALUES('0021330500') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3306" VALUES('0021330600') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3307" VALUES('0021330700') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3308" VALUES('0021330800') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3309" VALUES('0021330900') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3310" VALUES('0021331000') STORAGE(ON "MAIN", CLUSTERBTR),
PARTITION "P3311" VALUES('0021331100') STORAGE(ON "MAIN", CLUSTERBTR) )
STORAGE(HASHPARTMAP(1), ON "MAIN", CLUSTERBTR);
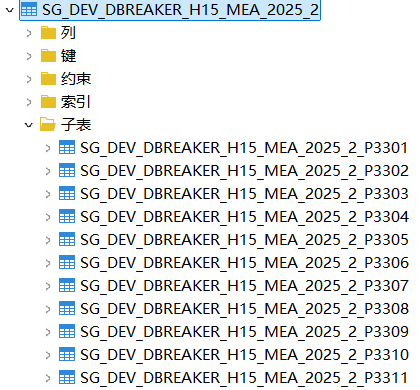
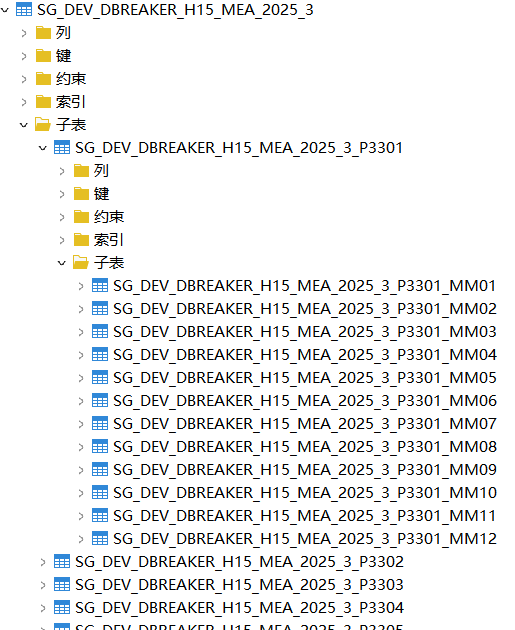
二级分区表:
在原有一级列表分区基础上增加以 CREATE_DATE为二级分区键的 RANGE分区(从2025年1月到2025年12月按月份划分)
SUBPARTITION BY RANGE("CREATE_DATE") SUBPARTITION TEMPLATE
(SUBPARTITION "MM01" VALUES LESS THAN(DATETIME'2025-02-01 00:00:00') STORAGE(ON "MAIN"), SUBPARTITION "MM02" VALUES LESS THAN(DATETIME'2025-03-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM03" VALUES LESS THAN(DATETIME'2025-04-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM04" VALUES LESS THAN(DATETIME'2025-05-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM05" VALUES LESS THAN(DATETIME'2025-06-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM06" VALUES LESS THAN(DATETIME'2025-07-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM07" VALUES LESS THAN(DATETIME'2025-08-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM08" VALUES LESS THAN(DATETIME'2025-09-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM09" VALUES LESS THAN(DATETIME'2025-10-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM10" VALUES LESS THAN(DATETIME'2025-11-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM11" VALUES LESS THAN(DATETIME'2025-12-01 00:00:00') STORAGE(ON "MAIN"),
SUBPARTITION "MM12" VALUES LESS THAN(DATETIME'2026-01-01 00:00:00') STORAGE(ON "MAIN") )
三、测试流程及结果
3.1数据准备
首先,利用 SQLark 工具与 DTS 工具生成 10 个数据文件,每个文件包含 100 万条记录,格式为 TXT。具体的方法就不详细介绍了,就是SQLark往表DMTEST中直接生成1000万行数据,然后DTS选择将查询语句查到的数据写入TXT文件中来实现数据文件生成,每100万一查,查询语句如下:
SELECT * FROM DMTEST LIMIT 1000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 1000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 2000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 3000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 4000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 5000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 6000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 7000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 8000000;
SELECT * FROM DMTEST LIMIT 1000000 OFFSET 9000000;
为确保文件在 Linux/Unix 环境下能正常解析,随后通过 vi 编辑器执行 :set ff=unix 命令,将所有文件的格式统一转换为 Unix 格式。

3.2测试程序编写
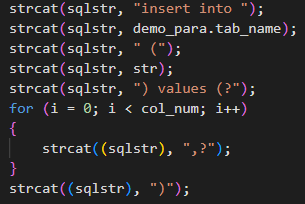
插入和更新操作的实现需要编辑OciLoadData.c中的内容,完整代码就不放出来了,太多了,关键的是我们实际需要执行的SQL语句,在程序中体现如下:

程序会解析由 DTS 工具生成的 TXT 数据文件。解析过程中,程序根据文件中的逗号(作为列分隔符)和换行符(作为行分隔符)对数据进行拆分。完成解析后,程序将根据 paralle_load.sh 脚本中指定的目标表名,将数据批量写入到对应的数据库表中。
更新操作则是根据where条件判断将TXT文件中的行和表中行进行匹配,然后更新paralle_load.sh 脚本中指定的目标列数据,在这里的where判断中,首要判断条件选择了DATASOURCE_ID和CREATE_DATE,刚好是创建一级分区和二级分区的字段,得益于分区列在筛选条件中的高过滤性,更新效率较高。
编译完成后会生成dmocidemo程序,然后修改paralle_load.sh脚本中的并行参数以适配当前环境的CPU核心数,确保每个线程独立操作不同的数据文件。同时配置LD_LIBRARY_PATH指向达梦OCI库路径,保证dmocidemo程序正常调用。
paralle_load.sh脚本内容如下:
插入:
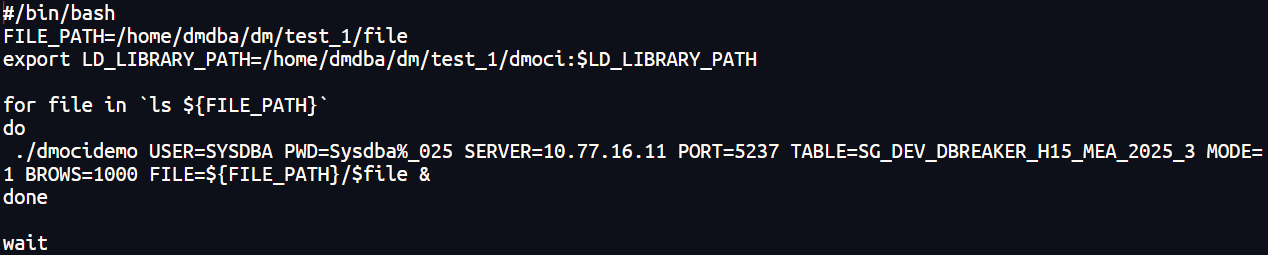
更新:
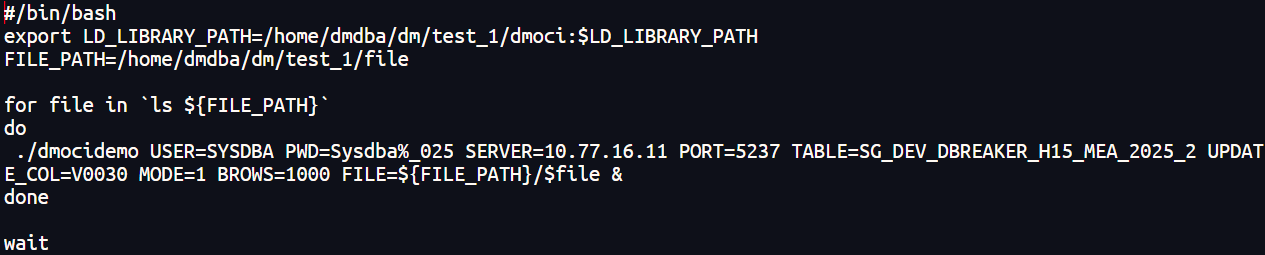
3.3 测试结果
准备工作就绪后,我们正式进入测试环节。通过分别在不分区 、一级分区 和二级分区 三种表结构上执行 paralle_load.sh 脚本,我们收集到了以下关键性能数据:
(1)不分区
插入耗时:
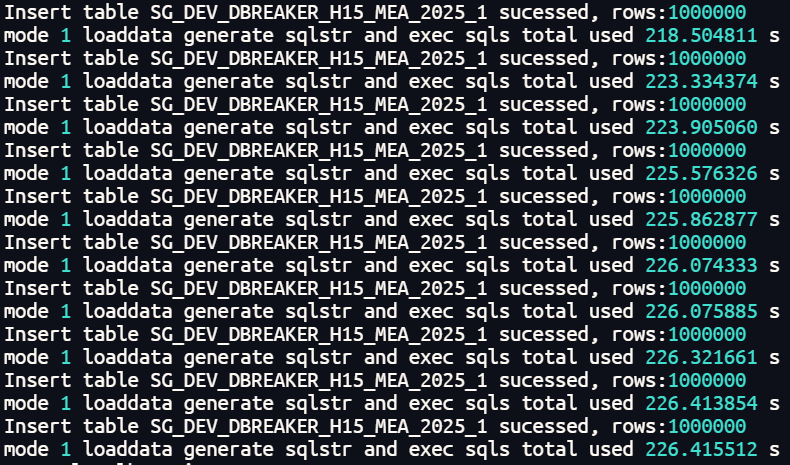
不分区的普通表并行插入1000万行数据总体耗时在225秒左右。
更新耗时:
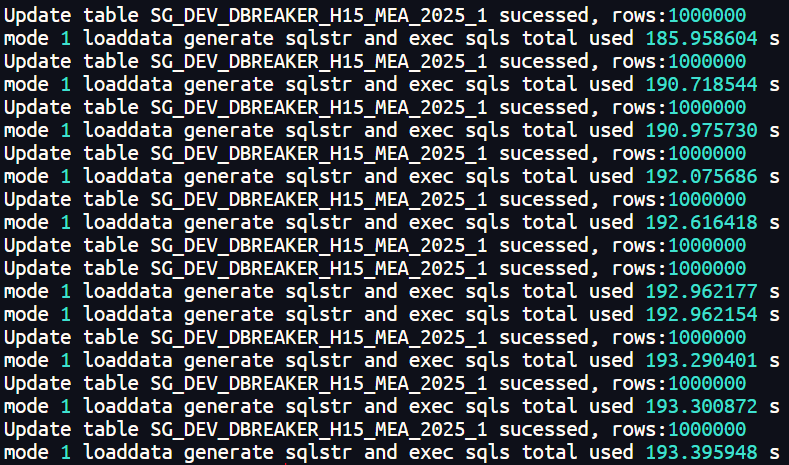
不分区的普通表并行更新1000万行数据总体耗时在193秒左右。
(2)一级分区
插入耗时:
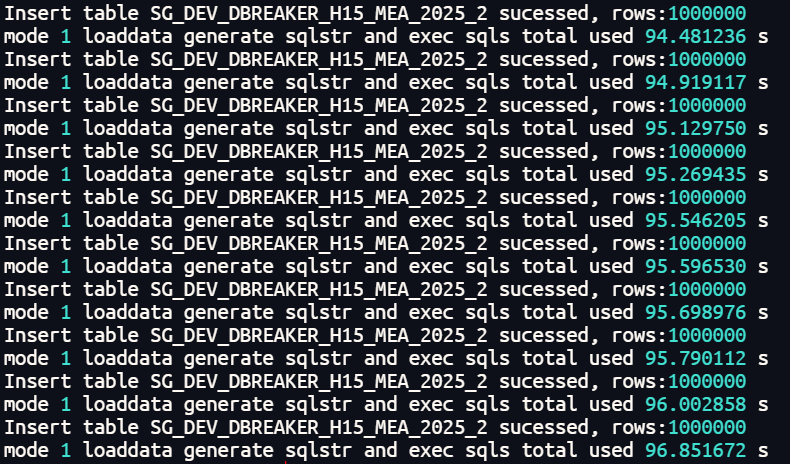
一级分区表并行插入1000万行数据总体耗时在95秒左右。
更新耗时:
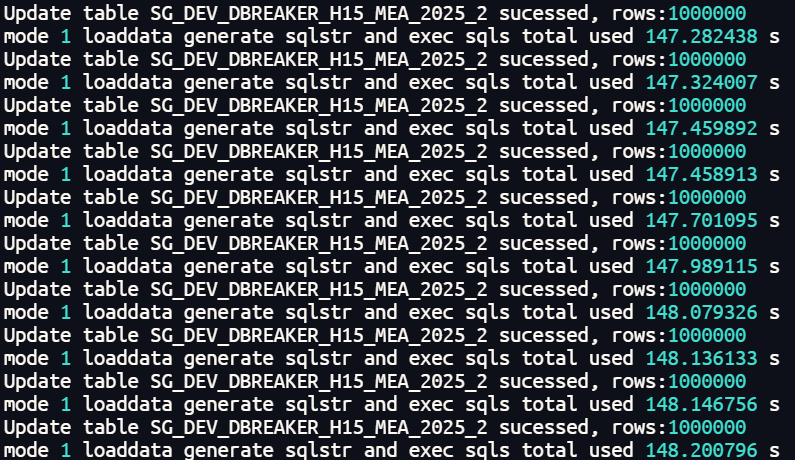
一级分区表并行更新1000万行数据总体耗时在148秒左右。
(3)二级分区
插入耗时:
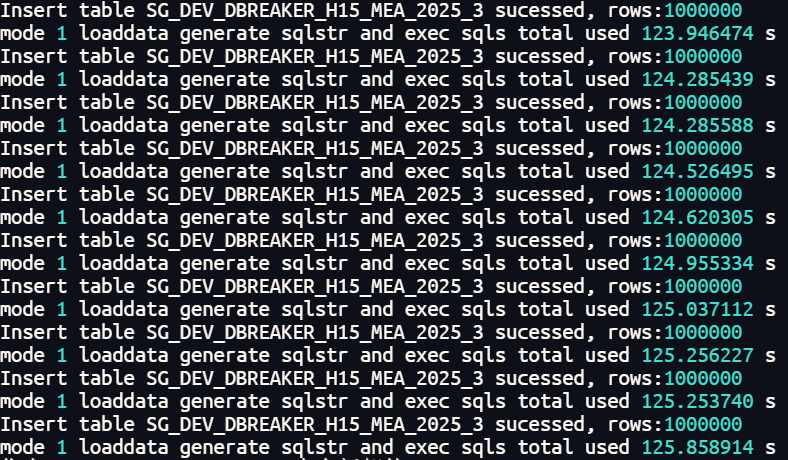
二级分区表并行插入1000万行数据总体耗时在125秒左右。
更新耗时:
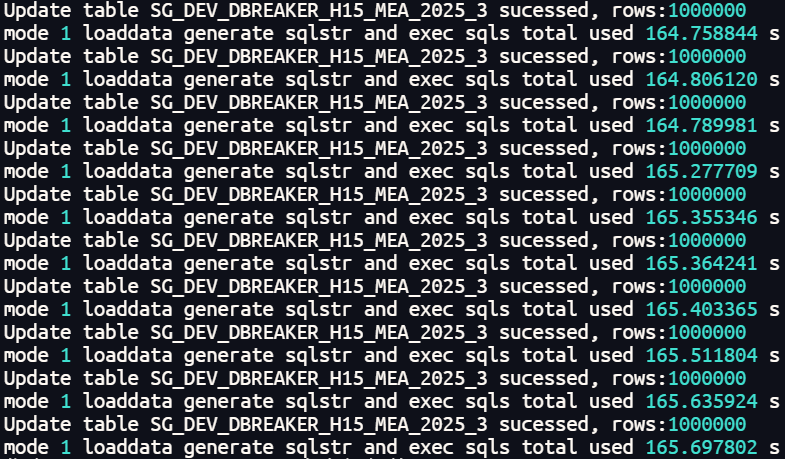
二级分区表并行更新1000万行数据总体耗时在165秒左右。
四、测试结论
|----|------|-------|-------|
| | 普通表 | 一级分区表 | 二级分区表 |
| 插入 | 225s | 95s | 125s |
| 更新 | 193s | 148s | 165s |
基于上述对比测试,我们可以得出以下结论:
1.批量插入性能:在百万级数据批量写入场景下,一级分区表表现最优,写入速度最快;二级分区表次之;而无分区表性能最差,耗时最长。这表明合理的分区设计能够有效提升数据写入效率。
2.批量更新性能:在批量更新场景下,性能排序与插入测试保持一致:一级分区表 > 二级分区表 > 无分区表。分区表得益于数据组织的结构性优势,在更新操作中同样展现出更好的性能表现。