前段时间没断更,补基础去了,练了练C语言和上机,感觉收获还是很丰富的。本笔记更多还是抛砖引玉,很多东西我写的远不如大佬写的好,我会附上对应的链接,计划用四五篇笔记完成基本的内容,包括c语言基本语法,上机必记题目,简单项目案例分析,以及笔试相关内容
在结束c语言学习后,我会继续更新c语言实现数据结构的笔记,强化所学的知识,敬请期待
我学习用的教材是这一本:

mooc上搜索哈工大C语言有对应的课程,b站也能搜到,质量还是挺高的,难度曲线也不会很陡峭
b站链接
mooc链接
https://www.icourse163.org/course/HIT-69005?from=searchPage&outVendor=zw_mooc_pcssjg_
值得注意的是,如果买这本书的新书,那么后面有专门的练习网站sse,难度基本是leetcode的easy和mid的水平:
https://sse.hit.edu.cn/t/#/login
需要靠刮开书本后面的账号获得一年使用期,据说是给本科生以及考研本校的学生练习复试用,如果是二手书那么大概率是没有的
但是,在头歌平台上,我们也能找到这本书对应的练习题---------并且免费使用,我认为对于初学者来说还是很友好的,难度也不会特别大,非常推荐边看边学
https://www.educoder.net/paths/hzpy63sn
这本书还有本实验指导书,不过买不买区别不大
我还参照了一些其他的网课,b站的南京大学王慧妍老师公开了自己的上课视频,上课质量也很高,你其实可以找到对应的公开资料,但是这门课的作业网站等并不对外公布,需要申请。我尝试申请过但暂无回应。这门课的质量也很高,相对而言更适合科班学生的学习,除了c语言的基础内容还涉及了一些基础的数据结构,以及不少leetcode出现过的中档题,整体来说更有挑战性。尽管我没有完全跟着他的节奏走,但处于推荐还是放上来,感兴趣的同学也可以照着这个学习
王慧妍老师b站视频:
https://space.bilibili.com/49964811/lists/6367099?type=season
课程网站:
学习文档:
https://njusecourse.feishu.cn/wiki/A1HzwviAgiFnQwkfRUWcVjqunLf
不过考虑到初学者学习能力有限,就不做过多的安利了,总之质量也是非常高的,时间精力充沛的很建议学一学
导论
C 语言是一门贴近计算机底层的结构化编程语言,它的核心价值在于 "直接操控硬件级资源" 与 "高效编译执行"------ 而这一切,都围绕代码如何从文本变成可运行程序、程序如何在计算机中被执行这条主线展开。
从代码编写到运行,第一步是通过 GCC或 Clang、MSVC 等编译器完成 "翻译":我们手写的 C 语言代码比如包含变量、函数、结构体、指针的文本,会被 GCC 经过预处理、编译、汇编、链接四个阶段,转化为计算机能识别的二进制可执行文件。
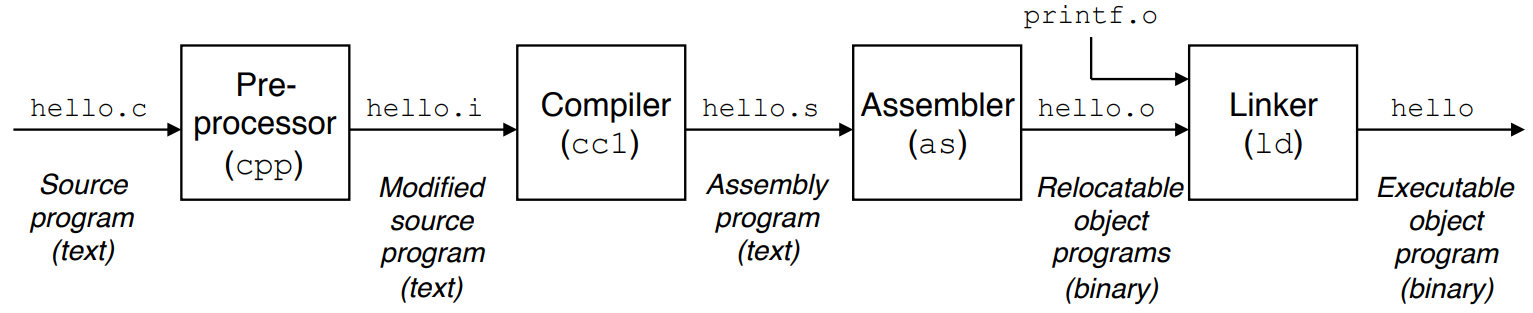 这个过程中,C 语言的核心概念,比如变量的类型、指针对内存地址的直接操作、结构体对数据的封装,会被编译器解析为具体的内存布局和机器指令,比如编译器会为
这个过程中,C 语言的核心概念,比如变量的类型、指针对内存地址的直接操作、结构体对数据的封装,会被编译器解析为具体的内存布局和机器指令,比如编译器会为 int a 分配 4 字节的内存空间,为 p->age 这类指针访问指令转化为 "先寻址、再取值" 的机器码,同时检查语法错误、优化执行效率。
当可执行文件被运行时,操作系统会为它创建一个独立的进程 ------ 进程是程序的运行实例,也是操作系统分配资源的基本单位。每个进程都拥有自己独立的虚拟内存空间,C 语言中我们接触的 "地址"比如 &a 获取的变量地址、指针存储的内存地址,本质上是这个虚拟空间内的编号,而非物理内存的真实地址,操作系统会通过内存映射这一机制,将虚拟地址转为物理地址。
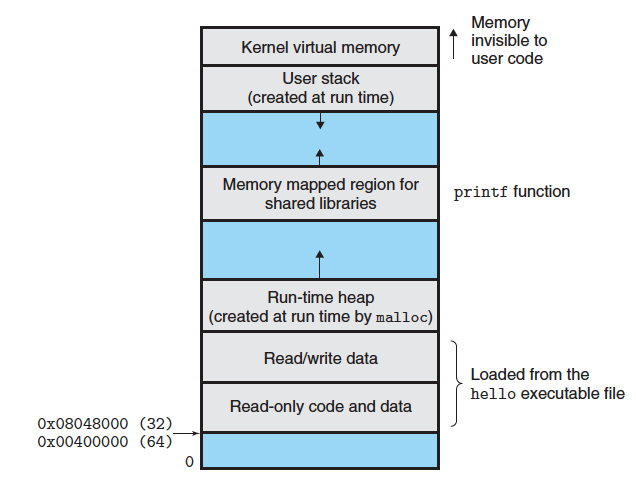
在进程的内存空间中,C 语言的各类概念对应着明确的内存分区:局部变量存在栈区、malloc 分配的内存存在堆区、全局变量存在数据区、函数的机器指令存在代码区;而指针的本质,就是存储这些内存地址的变量,通过指针我们能直接操作不同分区的内存,这也是 C 语言 "高效且灵活" 的核心原因。
简单来说,C 语言定义了 "如何描述对内存和计算的逻辑",GCC 负责将这些逻辑翻译成机器能执行的指令,进程为指令的运行提供独立的资源环境,而 "地址" 则是贯穿始终的核心 ------C 语言的所有操作(变量、函数、结构体、指针),最终都映射为对内存地址的读写,编译器和操作系统则共同保障这些地址操作的合法性与高效性。
以上这些概念如果完全没有接触过,第一次看一头雾水,建议先往下学习,操作一遍后再回来研究,加深印象。计算机毕竟是一门工科,如果没有丰富的实战,用"我理论丰富实践经验不足"作为理由显然解释不通,多敲代码才能学得快(当然,纯笔试的还是建议去看速成课吧)。
入门
对于初学者来说,光是下载IDE,配置环境等内容就已经非常折磨人了,但对于这些需要花不少时间才能研究明白的步骤,小白一定要自己被折磨一遍------折磨才能成长(bushi)
大致讲解一下这里面的关系,方便各位理解
前面提到了gcc,这是c语言核心,写出来的代码必须经过gcc编译才能得到可以点击就运行的程序。在早期,gcc与linux联系紧密,但在Windows 系统上是没法直接用 Linux 的 GCC 编译器的,因此我们需要下载MinGW ,它的作用是让 GCC 能在 Windows 上工作,把 C 代码编译成 Windows 可执行文件的工具
gcc是一个不需要界面的程序,因此使用cmd或者powershell就可以直接调用,但是这样编程没有高亮,也没有错误提示等,不适合小白进一步学习。
IDE比如 codeblocks,vscode等,是帮你更方便写代码、运行代码的可视化工具,不用手动敲复杂命令。(十分不推荐visual studio,对于新手而言这个十分笨重,远不如codeblocks或者clion等工具实用)
关于安装和配置,我并不想自己在赘述一遍,无论任何一个平台你都能轻松找到上万播放或者点赞的高浏览入门教程,再加上现在有ai,应该难不倒各位
vscode
devc++
我只说一点,无论是哪个软件,想要显示中文都或多或少的涉及到中文支持问题,总是会出现各种乱七八糟乱码,这是因为系统默认的识别只有ascii码------简单来说就是你的输入法调成英文模式下能输入的英文符号和标点,因此,无论是配置环境,设置安装路径,或者文件名和代码里的输入和输出,初学者建议尽可能全部用英文,顶多用英文下的下划线,这样会极大减少不必要的麻烦
如果能够让ai给你写一个稍微复杂的程序并在本地成功运行,那么基本上就算完成了。尽管在多数时候我更倾向于让各位在在线编程平台上编程,解决不必要的过程麻烦,但是这一步还是很有必要的。
如果你已经了解了相关的,可以搜索在线编程,随便哪一个平台,只要能正常输入输出就行,这样可以减少很多的障碍
这里推荐几个在线编程的网站:
我觉得很不错的网站
https://www.jyshare.com/compile/12/
总体使用体验尚可,但是貌似输入有点问题,不知道为什么,输出倒是没啥毛病
能看gcc生成的汇编代码,小白暂无必要
总之,即使你不懂复杂的编译中间过程和调试,你总能找到一个run按钮,点击后就能开始跑,这对于新手来说很是好用
如果条件允许,在编程训练过程可以使用在线网站跑代码,跑完了在本地用编辑器运行一遍,要是没啥问题就当保存自己的编程记录了,也方便自己做写笔记啥的
知乎有大佬推荐在github上用codespace,也就是github配置的linux环境用命令行编程,这个的好处是随时可以记录在github中留下痕迹,同时也训练自己的git和linux能力,这个有兴趣的可以自己折腾一下
学代码的时候一半的时间都在折腾配置和系统,有必要吗? - 子墨的回答 - 知乎
https://www.zhihu.com/question/8435690673/answer/98418700234
看到这里我默认你已经学会了,下一步我们初步分析第一个c语言程序helloworld
cpp
// Include standard input/output header (required for printf)
#include <stdio.h>
// Main function: entry point of all C programs
int main() {
// Print "Hello, World!" to the console (standard output)
printf("Hello, World!\n"); // \n = newline character (line break)
// Return 0 to indicate successful program execution
return 0;
}作为测试,可以把我这个代码丢进你自己的环境中看能不能运行
关于该程序,结合注释我们初步讲一下C语言的一些基本逻辑
首先,一个c语言程序最重要的一定是main函数,主体为
cpp
int main() {
//code
return 0;
}gcc在运行代码的时候始终会先进入main函数,从上往下运行相关的代码,最后运行到return 0的时候gcc判定已经运行完毕了,不再运行。编写或者调用函数的时候,写完了要放进main,程序运行的时候运行到对应的函数了就会跳转到对应的位置进行运行
就比如这个printf,这是一个标准库的函数,
printf("Hello, World!\n"); // \n = newline character (line break)
运行到这一句的时候系统已经解析过,来自#include <stdio.h>的标准库包提供了函数printf,用于输出内容,也就是一串"helloworld\n",把它打在公屏上。\n相当于换行符,保证输入或者输出不会堆在一起。
继续观察还会发现:
语句之间要用;隔开,
函数的形状为:
函数返回类型 函数名(函数参数)
{
函数内容;
return 函数返回值;
}
以及最后的//是注释,该部分内容不会被gcc读入函数逻辑中
基本类型,IO
关于c语言的基本类型,我主要讲的是char,int,float等,更详细的可以看这篇:
https://blog.csdn.net/Black_Leopard/article/details/153206377?ops_request_misc=&request_id=&biz_id=102&utm_term=c%E8%AF%AD%E8%A8%80%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-153206377.142^v102^pc_search_result_base4&spm=1018.2226.3001.4187
cpp
#include <stdio.h>
#include <string.h> // For string operations like strlen
int main() {
// Basic data types
char ch;
short sh;
int in;
long int li;
float fl;
double db;
char str[50]; // String (character array)
// Corresponding pointers for each type
char *p_ch = &ch;
short *p_sh = &sh;
int *p_in = ∈
long int *p_li = &li;
float *p_fl = &fl;
double *p_db = &db;
char *p_str = str; // Pointer to string (points to first character of array)
// Prompt user to input data
printf("=== Enter Data for Different Types ===\n");
printf("Enter a single character: ");
scanf(" %c", &ch); // Space to skip newline character
printf("Enter a short integer (e.g., 123): ");
scanf("%hd", &sh);
printf("Enter an integer (e.g., 4567): ");
scanf("%d", &in);
printf("Enter a long integer (e.g., 890123): ");
scanf("%ld", &li);
printf("Enter a float number (e.g., 3.14): ");
scanf("%f", &fl);
printf("Enter a double number (e.g., 9.87654): ");
scanf("%lf", &db);
printf("Enter a string (no spaces, e.g., HelloWorld): ");
scanf("%s", str); // String input (automatically ends at whitespace)
// Output original values and pointer information
printf("\n=== Original Values and Pointer Details ===\n");
// Char and char pointer
printf("Char: %c | Char address: %p | Value via char pointer: %c\n", ch, &ch, *p_ch);
// Short and short pointer
printf("Short int: %hd | Short address: %p | Value via short pointer: %hd\n", sh, &sh, *p_sh);
// Int and int pointer
printf("Int: %d | Int address: %p | Value via int pointer: %d\n", in, &in, *p_in);
// Long int and long int pointer
printf("Long int: %ld | Long int address: %p | Value via long pointer: %ld\n", li, &li, *p_li);
// Float and float pointer
printf("Float: %.2f | Float address: %p | Value via float pointer: %.2f\n", fl, &fl, *p_fl);
// Double and double pointer
printf("Double: %.4f | Double address: %p | Value via double pointer: %.4f\n", db, &db, *p_db);
// String and string pointer
printf("String: %s | String base address: %p | First character via string pointer: %c\n", str, str, *p_str);
printf("String length: %zu | Last character of string: %c\n", strlen(str), *(p_str + strlen(str) - 1));
// Demonstrate pointer arithmetic (string pointer)
printf("\n=== Pointer Arithmetic Example (String) ===\n");
printf("String pointer + 1: %p | Character at this address: %c\n", p_str + 1, *(p_str + 1));
printf("String pointer + 3: %p | Character at this address: %c\n", p_str + 3, *(p_str + 3));
return 0;
}上述程序中,我们定义了若干变量,但没有给他们赋值,直到我们用scanf输入值后,该值才被赋给变量,最后得以展示出来
scanf详解:
printf详解:
我做一些总结
printf和scanf作为标准库最常用的输出输入函数,是每个学c的人必须掌握的,我们需要结合变量来做更详细的理解。
C 语言中printf用于输出数据到控制台,scanf用于从控制台读取数据到变量中,二者都依赖占位符 匹配变量类型:char(字符型)对应%c、short(短整型)对应%hd、int(整型)对应%d、long int(长整型)对应%ld、float(单精度浮点型)对应%f、double(双精度浮点型)输入用%lf、输出用%f,字符串(char[])则统一用%s
占位符是printf/scanf识别变量类型的 "标记",比如用printf("%d", num)输出整型变量num,用scanf("%f", &score)读取小数到浮点型变量score,必须保证占位符和变量类型一一对应,否则会出现输入输出错误。
printf对于初学者意义非凡,调试很多人不一定调的明白,但用printf逐步打印看哪里有异常,是初学者debug的首选
scanf的意义则更多的是在上机做题时的批量输入时接受数据
关于数据类型,由于int用32bit的01串进行存储,所以很直观的我们能想到,当运行结果超过32位时多余的位数在32bit中无法计算就会被舍弃,这会导致结果出现严重的错误,比如正数相加得到负数,或者复数相减得到整数
关于基本类型就讲到这里,指针部分需要结合函数做更详细的说明,可以看看这个视频
【【通俗C语言讲解】非常易懂!在宿舍教舍友指针实录】 https://www.bilibili.com/video/BV1MH4y1u7uE/?share_source=copy_web\&vd_source=f57a4eed38221b1b8a0ac66235a0e678
这是我目前看到的最简单直白的指针说明,对初学者来说绰绰有余,强烈推荐看看
基本运算
循环,跳转
我们结合代码具体分析,主要研究两种条件跳转:if-else,switch,以及三种循环语句:while,do-while,for
我们结合代码具体分析,建议读者不必完全跟着我的思路走,把代码复制到云心环境中自己试一试,同时充分运用ai工具,帮助自己理解和学习
代码核心介绍
这份 C 语言代码实现了一个交互式数字猜谜游戏(Number Guessing Game),核心目标是让用户在 10 次机会内猜出程序随机生成的 1-100 之间的整数,游戏支持重新开始,全程通过英文交互提示。
1. 核心功能
随机生成 1-100 的整数作为谜底,每次运行 / 重启游戏都会生成新数字;
限制用户最多 10 次猜测机会,每次猜测后给出 "猜大(Too high)""猜小(Too low)" 或 "猜对" 的反馈;
处理非法输入(如字母、符号),确保仅接受 1-100 的整数;
支持游戏结束后选择 "重新开始" 或 "退出",且 "重新开始" 的询问至少执行一次。
2. 关键技术点(控制流)
代码核心是展示 C 语言 5 种基础控制流语句的典型用法:
for 循环:控制 10 次猜测机会,猜对可提前终止;
while 循环:校验用户输入有效性,直到输入合法整数;
do while 循环:确保 "是否重启游戏" 的询问至少执行一次;
if-else if-else:多条件判断(输入越界、猜大 / 猜小 / 猜对);
switch:匹配用户 "重启(1)/ 退出(0)" 的选择,处理无效输入。
3. 执行流程
初始化随机数→生成谜底→提示游戏规则;
进入 10 次猜测的for循环,每次循环校验输入、判断猜测结果;
10 次机会用完 / 猜对后,通过do while询问是否重启;
若选 "重启",重置谜底和状态并重复猜测流程;若选 "退出",结束程序。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
// Initialize random number seed to ensure different random numbers each run
srand((unsigned int)time(NULL));
// Generate a random number between 1 and 100 as the secret number
int secret_number = rand() % 100 + 1;
int guess = 0; // Store the user's guessed number
int attempts = 0; // Record the number of guess attempts
int game_continue = 1; // Flag to control the main game loop
printf("===== Number Guessing Game =====\n");
printf("Rules: I have generated a random number between 1 and 100. Try to guess it!\n");
printf("You have 10 chances. After each guess, I will tell you if it's too high or too low.\n\n");
// 1. for loop: Limit to maximum 10 guess attempts
for (int i = 1; i <= 10 && game_continue; i++) {
printf("Attempt %d: Please enter your guess: ", i);
// Check if input is valid (must be an integer)
while (scanf("%d", &guess) != 1) {
// 2. while loop: Handle invalid input until valid integer is entered
printf("Invalid input! Please enter an integer between 1 and 100: ");
// Clear input buffer to avoid infinite loop
while (getchar() != '\n');
}
attempts++; // Increment attempt count for each input
// 3. if-else if-else branch: Judge the guess result
if (guess < 1 || guess > 100) {
printf("Please enter a number between 1 and 100! This attempt is not counted.\n\n");
i--; // Roll back count for invalid input (no chance consumed)
} else if (guess < secret_number) {
printf("Too low! Try a bigger number.\n\n");
} else if (guess > secret_number) {
printf("Too high! Try a smaller number.\n\n");
} else {
printf("Congratulations! You guessed it right! The secret number is %d!\n", secret_number);
printf("You took %d attempts in total.\n", attempts);
game_continue = 0; // End for loop after correct guess
}
}
// If 10 chances are used up without correct guess
if (game_continue) {
printf("\nSorry, you've used all 10 chances! The secret number was %d.\n", secret_number);
}
int choice = 0;
// 4. do-while loop: Execute at least once (ask to restart game)
do {
printf("\nWould you like to restart the game? (1-Yes, 0-No): ");
while (scanf("%d", &choice) != 1) {
printf("Invalid input! Please enter 1 or 0: ");
while (getchar() != '\n');
}
// 5. switch branch: Execute different operations based on user choice
switch (choice) {
case 1:
// Regenerate random number and reset game state
secret_number = rand() % 100 + 1;
attempts = 0;
game_continue = 1;
printf("\n===== New Game Started =====\n");
printf("I've generated a new random number between 1 and 100. Start guessing!\n");
// Re-run the 10-attempt for loop
for (int i = 1; i <= 10 && game_continue; i++) {
printf("Attempt %d: Please enter your guess: ", i);
while (scanf("%d", &guess) != 1) {
printf("Invalid input! Please enter an integer between 1 and 100: ");
while (getchar() != '\n');
}
attempts++;
if (guess < 1 || guess > 100) {
printf("Please enter a number between 1 and 100! This attempt is not counted.\n\n");
i--;
} else if (guess < secret_number) {
printf("Too low!\n\n");
} else if (guess > secret_number) {
printf("Too high!\n\n");
} else {
printf("Congratulations! You guessed it right! The secret number is %d, and you took %d attempts.\n", secret_number, attempts);
game_continue = 0;
}
}
if (game_continue) {
printf("You've used all chances. The secret number was %d.\n", secret_number);
}
break; // Exit case 1 and return to do-while loop
case 0:
printf("Game over! Thanks for playing, see you next time!\n");
break; // Exit case 0
default:
// Prompt for non-1/0 input
printf("Invalid choice! Please enter 1 (Restart) or 0 (Quit).\n");
break;
}
} while (choice != 0); // Repeat until user selects 0
return 0;
}为了充分理解代码,应该先学习如下语法:
for循环
while
do while
if-else
建议自行剖析其中的语句,判断其中的逻辑,最好多printf一下,打印其中的过程,看变量在这个过程中做了什么变化,是否符合自己的预期,对于临界可能出现的边界情况需要着重分析,数组越界,循环错位等都是很常见的错误。
接下来,我按代码的执行流程和功能模块,分 6 个核心段落逐一概述
段落 1:头文件引入与变量初始化
cpp
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
srand((unsigned int)time(NULL));
int secret_number = rand() % 100 + 1;
int guess = 0;
int attempts = 0;
int game_continue = 1; 核心作用:
- 引入程序必需的头文件(输入输出、随机数、时间相关);
- 初始化随机数种子(保证每次运行生成不同随机数),生成 1-100 的随机数作为谜底;
- 定义核心变量:存储用户猜测数、记录猜测次数、控制游戏循环的标志位。
段落 2:游戏规则提示
printf("===== Number Guessing Game =====\n");
printf("Rules: I have generated a random number between 1 and 100. Try to guess it!\n");
printf("You have 10 chances. After each guess, I will tell you if it's too high or too low.\n\n");核心作用:
- 向用户打印游戏名称、规则(猜 1-100 的数、共 10 次机会、有高低提示),完成交互初始化。
段落 3:第一轮猜数核心循环(for+while+if-else)
cpp
for (int i = 1; i <= 10 && game_continue; i++) {
printf("Attempt %d: Please enter your guess: ", i);
while (scanf("%d", &guess) != 1) {
printf("Invalid input! Please enter an integer between 1 and 100: ");
while (getchar() != '\n');
}
attempts++;
if (guess < 1 || guess > 100) {
printf("Please enter a number between 1 and 100! This attempt is not counted.\n\n");
i--;
} else if (guess < secret_number) {
printf("Too low! Try a bigger number.\n\n");
} else if (guess > secret_number) {
printf("Too high! Try a smaller number.\n\n");
} else {
printf("Congratulations! You guessed it right! The secret number is %d!\n", secret_number);
printf("You took %d attempts in total.\n", attempts);
game_continue = 0;
}
}核心作用:
- 用
for循环控制 10 次猜数机会,猜对则通过game_continue提前终止循环; - 用
while循环校验输入有效性(仅接受整数,清空非法输入缓冲区避免死循环); - 用
if-else if-else判断猜测结果:输入越界则不计次数、猜小 / 猜大给出提示、猜对则输出结果并终止循环。
段落 4:第一轮游戏结束提示(10 次机会用完)
cpp
if (game_continue) {
printf("\nSorry, you've used all 10 chances! The secret number was %d.\n", secret_number);
}核心作用:
- 若 10 次机会用完且未猜对(
game_continue仍为 1),向用户提示谜底,完成第一轮游戏收尾。
段落 5:重启游戏交互(do-while+switch)
cpp
int choice = 0;
do {
printf("\nWould you like to restart the game? (1-Yes, 0-No): ");
while (scanf("%d", &choice) != 1) {
printf("Invalid input! Please enter 1 or 0: ");
while (getchar() != '\n');
}
switch (choice) {
case 1:
secret_number = rand() % 100 + 1;
attempts = 0;
game_continue = 1;
printf("\n===== New Game Started =====\n");
printf("I've generated a new random number between 1 and 100. Start guessing!\n");
// 重新执行10次猜数循环(逻辑同段落3)
for (int i = 1; i <= 10 && game_continue; i++) { ... }
if (game_continue) {
printf("You've used all chances. The secret number was %d.\n", secret_number);
}
break;
case 0:
printf("Game over! Thanks for playing, see you next time!\n");
break;
default:
printf("Invalid choice! Please enter 1 (Restart) or 0 (Quit).\n");
break;
}
} while (choice != 0);核心作用:
- 用
do-while循环确保至少询问一次 "是否重启游戏",直到用户输入 0 退出; - 用
while校验重启选择的输入有效性(仅接受 1/0); - 用
switch处理用户选择:选 1 则重置游戏状态(新谜底、清零次数)并重新执行 10 次猜数循环;选 0 则输出结束提示;其他输入则提示无效。
段落 6:程序收尾
cpp
return 0;
}核心作用:
- 主函数返回 0,标识程序正常结束。
总之,代码整体分为 "初始化→规则提示→第一轮猜数→第一轮收尾→重启交互→程序结束"6 个核心段
建议各位读懂代码逻辑后自己敲一遍,最起码不完全借助ai的情况下自己把它调试明白
数组
一维数组
数组是同一类型数据的有序集合,一维数组是最基础的线性结构,核心是 "初始化" 和 "访问":
(1)初始化方式
// 1. 完全初始化:指定长度,给所有元素赋值
int arr1[5] = {1, 2, 3, 4, 5};
// 2. 部分初始化:未赋值的元素默认补0
int arr2[5] = {1, 2}; // 实际是 {1,2,0,0,0}
// 3. 省略长度:编译器根据初始化元素个数自动确定长度
int arr3[] = {1, 2, 3}; // 长度为3
// 4. 字符数组初始化(特殊):可直接用字符串,末尾自动加'\0'
char str1[] = "hello"; // 长度为6(包含'\0')
char str2[5] = "hello"; // 错误:"hello"占6个位置,超出长度(2)核心特性
- 下标从 0 开始,比如
arr1[0]是第一个元素,arr1[4]是最后一个; - 数组名
arr1本质是数组首元素的地址 (但不是普通变量指针,有常量属性,不能直接arr1++); - 用
sizeof(arr1)可获取数组总字节数,sizeof(arr1)/sizeof(arr1[0])能计算元素个数。
二维数组
二维数组是 "数组的数组",可理解为行 + 列的表格,初始化需关注 "行 / 列" 的对应关系:
(1)初始化方式
// 1. 完全初始化:按行分组赋值
int arr1[3][4] = {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}};
// 2. 部分初始化:未赋值的元素默认补0
int arr2[3][4] = {{1,2}, {5}, {9}}; // 第一行{1,2,0,0},第二行{5,0,0,0},第三行{9,0,0,0}
// 3. 省略行号(列号不能省):编译器自动算行数
int arr3[][] = {1,2,3,4,5,6}; // 错误:列数必须明确
int arr4[][4] = {1,2,3,4,5,6}; // 正确:自动识别为2行4列,{1,2,3,4}, {5,6,0,0}(2)核心特性
- 访问格式
arr[i][j]:i是行下标,j是列下标,比如arr1[1][2]是第二行第三个元素(值为 7); - 二维数组在内存中是连续存储的(先存第一行,再存第二行),本质还是一维数组的嵌套。
数组指针
数组指针是 "指向整个数组的指针",不是指向单个元素的指针,核心是 "定义格式" 和 "初始化匹配":
(1)定义与初始化
// 第一步:先定义一个普通一维数组
int arr[5] = {1,2,3,4,5};
// 第二步:定义数组指针(指向"包含5个int的数组")
int (*p)[5]; // 括号不能省,否则变成"指针数组"
// 第三步:初始化:让p指向整个数组arr(arr是数组首地址,匹配p的类型)
p = &arr;
// 访问元素:*p等价于arr,所以(*p)[0] = arr[0] = 1
printf("%d\n", (*p)[0]); // 输出1(2)核心区分(避免和 "指针数组" 混淆)
- 数组指针:
int (*p)[5]→ 指向数组的指针(变量是 p,p 指向一个 5 个 int 的数组); - 指针数组:
int *p[5]→ 装指针的数组(变量是数组 p,数组里有 5 个 int * 类型的指针)。
数组传参 & 指针退化
数组传参的核心问题是 "指针退化":数组名作为参数传递时,会丢失 "数组长度" 属性,退化成指针,初始化 / 定义时要注意匹配:
(1)一维数组传参
// 错误示范:试图在函数内通过sizeof获取数组长度
void func1(int arr[]) {
// 这里arr已退化成int*,sizeof(arr)是指针大小(比如8字节),不是数组总长度
int len = sizeof(arr)/sizeof(arr[0]); // 结果错误
}
// 正确写法:单独传递数组长度
void func2(int arr[], int len) {
for(int i=0; i<len; i++) {
printf("%d ", arr[i]);
}
}
int main() {
int arr[5] = {1,2,3,4,5};
func2(arr, 5); // 传数组名(首元素地址)+ 长度
return 0;
}(2)二维数组传参
// 错误:列数省略,编译器无法识别数组指针类型
void func3(int arr[][]) {}
// 正确:列数必须明确,arr退化成int (*arr)[4](指向4个int的数组指针)
void func4(int arr[][4], int rows) {
for(int i=0; i<rows; i++) {
for(int j=0; j<4; j++) {
printf("%d ", arr[i][j]);
}
}
}
int main() {
int arr[3][4] = {{1,2}, {5}, {9}};
func4(arr, 3); // 传数组名 + 行数
return 0;
}总结
- 一维数组初始化可指定长度 / 省略长度,二维数组初始化列数不能省,未赋值元素默认补 0;
- 数组指针是指向整个数组的指针,定义时
(*p)[n]的括号不能省,需和数组长度匹配; - 数组传参发生指针退化:一维数组退化成元素指针,二维数组退化成指向行的数组指针,必须额外传递长度 / 行数。
数组传参,这个写的还挺好的
总之,定义和初始化数组的本质是在内存空间中划分一片连续的空间,而一旦确定了划分空间的大小就不能再修改了,除非你用的是malloc和realloc的扩容方法,这是定义大小maxsize要用define而不是声明变量的原因之一。如果是二维数组,那么基于数组按行存储的特性,你可以不规定一共有多少行,但不可以规定一行的大小,否则编译器无法评估你的矩阵存放情况
此外,数组作为参数传参时,传递的本质是该矩阵的第一个元素的指针
这里有一个很隐藏的考虑,如果编译器知道这是"数组",那么他不仅知道数组的大小,也同时会直到数组的元素类型
而指针则意味着编译器此时不再知道该数组的具体信息,只知道这个具体元素的位置,因此尽管我们可以使用*(arr+i)来访问一维数组arr后面的第i个元素,但我们是没有办法使用sizeof(arr)/sizeof(arr0)来获得数组长度的,理由是编译器的视角里这个arr不再是arrN而是int *arr,N 不再被记录
进而,对于二维数组arrMN ,举个例子arr32={1,2,3,4,5,6},按照按行存储,这个记录方式本质上是
arr={
{1,2},
{3,4},
{5,6}
}
那么,当数组名作为参数传递时,
arr退化为指向数组第一个元素的指针,而二维数组本质上可以视为是存储了一维数组的数组,因此arr指向的不是元素,而是一个作为二维数组的单元的一维数组,也就是arr【0】------也就是{1,2}这个小数组,所以arr退化为指向数组的指针,也就是数组指针
这段话非常绕,希望读者好好理清思路
进一步,我们有arr0指的就是{1,2}这个小数组,同理这会发生退化,传递数组会退化为指向数组第一个元素的指针,也就是退化为arr【0】的第一个元素的指针,指向1
arr00则没有什么异议,指向的是1这个元素
如果上面这段话你能自用自己的话讲得通顺,自己也明白,那你其实已经会的差不多了
字符串
字符串分析
字符串在笔试中重要程度可能也就体现在一个KMP上,其他的重点不在这上面,但是在机考中,字符串的地位还是十分重要的
首先,C 无字符串类型,因此字符串本质是 以'\0'结束符结尾的 char 数组;
我们来看一些合法的形式定义形式:
char s[] = "abc";该字符串长度为4,他的本质是{'a','b','c','\0'}这样的有终止的字符数组,用""括号包裹起来时,末尾的\0可以不写,但编译器视角里你必须有这个句号,因此这个终止符也算一个字节的长度。总长度为4
由上面的说法,我们不难发现{'a','b','\0'}:手动加'\0'才是字符串,不加仅为字符数组;
这样的定义也是合法的:char s[10];定义后赋值需手动补'\0',不能直接s = "abc";理由是后面的区域并不确定,或者长度待定时就不要再定义时规定字符串的最大长度,尽管有编译器的层层检查,越界带来的后果往往是灾难性的。
其中,最最最重要的一点是,缺'\0'会乱码 / 越界,在编译器试图读取一个字符串的时候会默认要找种植符,因此{'a','b','c'}这样的写法并不合理,编译器可能会无法识别正确的终止位置,而是在'c'之后继续便利直到找到'\0',从而导致输出的字符串不止包含abc,后面可能会有意想不到的乱码。
通常情况下,我们用sizeof算总长度(含'\0'),strlen算有效长度(不含);
接下来我们将重点探讨字符串相关的函数,笔试可以不太重视,但机考这些绝对需要花点时间好好记忆
字符串重要函数
注意下列函数基本都需要使用函数头文件#include<string.h>
strcpy
原型:char *strcpy(char *dst, const char *src);
作用:把源字符串src完整拷贝到目标字符数组dst(包含 '\0'),要求dst空间足够大,否则会内存越界;
strcat
原型:char *strcat(char *dst, const char *src);
作用:将源字符串src拼接到目标字符串dst末尾(覆盖dst原有的 '\0',拼接后自动补 '\0'),需保证dst有足够拼接空间;
strlen
原型:size_t strlen(const char *src);
作用:计算字符串src的有效长度,只统计 '\0' 之前的字符数,不包含 '\0',和 sizeof(计算数组总字节数)有本质区别;
strcmp
原型:int strcmp(const char *str1, const char *str2);
作用:按 ASCII 码值逐字符比较str1和str2,返回 0 表示两字符串相等,返回负数表示str1小于str2,返回正数表示str1大于str2(不是比较长度);
strchr原型:char *strchr(const char *src, int c);
作用:在字符串src中查找字符c首次出现的位置,找到则返回该位置的指针,找不到返回 NULL;
putchar
原型:int putchar(int c);
作用:向控制台输出单个字符c,无缓冲区问题,直接打印;
getchar
原型:int getchar(void);
作用:从控制台读取单个字符(包括回车、空格),返回字符的 ASCII 码值,读取失败 / 结束时返回 EOF(值为 -1),需清理输入缓冲区残留字符;
gets
原型:char *gets(char *dst);
作用:从控制台读取一整行字符串到字符数组dst(自动丢弃换行符,末尾加 '\0'),无长度限制,极易导致dst数组越界,现已被 C 标准废弃;
puts
原型:int puts(const char *src);
作用:向控制台输出字符串src,会自动在字符串末尾追加换行符,输出到 '\0' 为止,需确保src有结束符;
fgets
原型:char *fgets(char *dst, int n, FILE *stream);
作用:从指定输入流stream(如 stdin)读取最多n-1个字符到dst,能避免越界,读取后会保留换行符,需手动替换为 '\0'。
一些
strcpy 的安全替代:
strncpy
原型:char *strncpy(char *dst, const char *src, size_t n);
用法要点:指定最大拷贝长度n(建议设为sizeof(dst)-1),且手动补 '\0'(strncpy 可能不自动加结束符),
例:strncpy(dst, src, sizeof(dst)-1); dst[sizeof(dst)-1] = '\0';
strcat 的安全替代:
strncat
原型:char *strncat(char *dst, const char *src, size_t n);
用法要点:指定最大拼接长度n,基于dst当前长度计算剩余空间,
例:strncat(dst, src, sizeof(dst)-strlen(dst)-1);
gets 的安全替代:fgets
(机考完全替代 gets,上面已经写过,不再赘述)
以上函数都是很重要的,我们用一个具体例子加以说明
cpp
#include <stdio.h>
#include <string.h>
int main() {
char dst[20] = "hello"; // Target character array
const char src[] = "world";// Source string (protected by const)
char buf[20]; // Temporary buffer
char ch;
// 1. Basic functions: strlen/get string length, strcmp/compare strings
printf("1. len(dst)=%lu, cmp=%d\n", strlen(dst), strcmp(dst, src));
// 2. Safe copy: strncpy (replace unsafe strcpy)
strncpy(buf, dst, sizeof(buf)-1);
buf[sizeof(buf)-1] = '\0'; // Manually add '\0' (strncpy may not add it)
printf("2. strncpy: %s\n", buf);
// 3. Safe concatenation: strncat (replace unsafe strcat)
strncat(dst, src, sizeof(dst)-strlen(dst)-1);
printf("3. strncat: %s\n", dst);
// 4. Character search: strchr (find first occurrence of character)
char *pos = strchr(dst, 'w');
printf("4. strchr: %s\n", pos ? pos : "not found");
// 5. Input/Output: putchar/output single char, getchar/read single char
printf("5. Enter a single character: ");
ch = getchar();
putchar(ch);
while (getchar() != '\n'); // Clear input buffer to avoid residual characters
printf("\n");
// 6. Safe line input: fgets (replace deprecated gets)
printf("6. Enter a line of string: ");
fgets(buf, sizeof(buf), stdin);
buf[strcspn(buf, "\n")] = '\0'; // Remove newline character retained by fgets
printf("fgets: %s\n", buf);
// 7. String output: puts (automatically add newline)
puts("7. puts: test");
return 0;
}这个难度不大,观察即可,基益起来也不会很复杂,总之要多练习,后面算法等遇到题目才能轻松作答,灵活运用
函数
函数的封装体现了模块化思想,由于相关的组成逻辑能够从main移动到具体的函数内部,能够减少单个模块debug定位错误的难度,减少遇到的阻碍
函数基本形式
这是写函数的基础,核心是 "声明 / 定义 + 调用"
cpp
// 无返回值函数(void)
void 函数名(参数类型1 参数名1, 参数类型2 参数名2) {
函数体(要执行的代码);
// void类型不需要return,或只写return;
}
// 有返回值函数
返回值类型 函数名(参数类型1 参数名1) {
函数体;
return 对应类型的值; // 返回值类型必须和定义的一致
}一个简单示例
#include <stdio.h>
// 函数声明(如果定义在main之后,必须声明;定义在main前可省略)
int add(int a, int b);
int main() {
// 函数调用:实参(5,3)和形参(a,b)类型/数量/顺序一致
int res = add(5, 3);
printf("和:%d\n", res); // 输出:和:8
return 0;
}
// 函数定义(实现逻辑)
int add(int a, int b) {
return a + b; // 返回值类型是int,所以return整数
}变量作用域
代码中变量主要两类:
- 局部变量(函数内定义)
只在定义它的函数 / 代码块内有效;
运行时存在栈中,默认值随机(必须初始化)。
- 全局变量(函数外定义)
整个程序所有函数都能用;
默认值为 0,运行时存在静态区。
更具体来说,全局变量作用域整个c文件,局部变量作用域在函数内部,而像for循环之类里面临时定义的变量,我们可以简单粗暴理解为他作用域在一对{}之间
#include <stdio.h>
int global = 10; // 全局变量,所有函数能用
void test() {
int local = 20; // 局部变量,只有test函数能用
printf("全局变量:%d,局部变量:%d\n", global, local);
}
int main() {
test(); // 输出:全局变量:10,局部变量:20
// printf("%d", local); // 报错!local是test的局部变量,main用不了
return 0;
}这篇文章写的还可以,但是相对初学者来说难度不小,可以结合ai进行探究
参数传递
上机只需要掌握这两种核心传递方式:
- 值传递(默认)
实参把值复制给形参,形参修改不影响实参;
适合只需要用参数值、不需要修改原变量的场景。
#include <stdio.h>
void change(int a) {
a = 100; // 只修改形参a,和实参x无关
}
int main() {
int x = 10;
change(x);
printf("x = %d\n", x); // 输出:x = 10
return 0;
}- 地址传递(指针)
传递变量的地址(& 变量名),形参用指针接收,能修改实参;
适合需要修改原变量的场景(比如交换两个数)。
#include <stdio.h>
void change(int *a) {
*a = 100; // *a表示取指针指向的变量,修改的是实参x
}
int main() {
int x = 10;
change(&x); // &x是取x的地址
printf("x = %d\n", x); // 输出:x = 100
return 0;
}递归
递归是函数调用自身,写递归只抓两个关键点:
终止条件:必须有,否则无限递归(程序崩溃);
递推公式:把问题拆成更小的同类问题,调用自身。
我们以阶乘为例展示一下,阶乘因为很容易越界,n稍微大一些就可能涉及溢出,哪怕是改成最长的long long int也没法容忍很大的n
但我们主要是一个思想,斐波那契数列等的实现也是差不多的。这些问题在算法上一般被归为动态规划问题,最终都能归结为最小单元(比如对f(1)的计算)
递归在动态规划等问题上用起来很方便,但实际上为了简化函数调用带来的巨大的空间和时间代价,很多函数会选择使用变量迭代或者数组等方式来解决这样的问题,这些不在第一次课的范围内,就不详细展开了
#include <stdio.h>
// 计算n的阶乘:n! = n*(n-1)!,终止条件:0! = 1
int fact(int n) {
// 1. 终止条件(必须先写)
if (n == 0) {
return 1;
}
// 2. 递推公式:调用自身,问题规模缩小
return n * fact(n - 1);
}
int main() {
printf("5! = %d\n", fact(5)); // 输出:5! = 120
return 0;
}用一个综合的示例
cpp
#include <stdio.h>
// Global variable
int global_num = 0;
// Function declarations
void test_scope();
void value_pass(int a);
void address_pass(int *a);
int simple_recursion(int n);
int main() {
printf("===== 1. Variable Scope Test =====\n");
test_scope();
printf("\n===== 2. Parameter Passing Test =====\n");
int num = 10;
printf("Original value: num = %d\n", num);
value_pass(num);
printf("After value passing: num = %d\n", num);
address_pass(&num);
printf("After address passing: num = %d\n", num);
printf("\n===== 3. Simple Recursion Test =====\n");
int n = 5;
printf("%d! = %d\n", n, simple_recursion(n));
return 0;
}
// Test variable scope
void test_scope() {
int local_in_test = 99; // Local variable
global_num++;
printf("Global variable: global_num = %d\n", global_num);
printf("Local variable: local_in_test = %d\n", local_in_test);
}
// Test value passing
void value_pass(int a) {
a = 100; // Modify formal parameter only
printf("Inside value pass function: a = %d\n", a);
}
// Test address passing
void address_pass(int *a) {
*a = 200; // Modify actual parameter
printf("Inside address pass function: *a = %d\n", *a);
}
// Calculate factorial with recursion
int simple_recursion(int n) {
if (n == 0 || n == 1) { // Termination condition
return 1;
}
return n * simple_recursion(n - 1); // Recursive formula
}我们主要关注这里面的变量的传递,调用时的值的变化
稍微讲一下,为什么直接赋值传递参数不会变化呢?
这里涉及形参和实参的问题
这一篇用栈帧的角度来分析,写的还行
其中,栈就是本文开头那张栈的地址空间中的stack部分,尽管增长方向不一样,但本质差不多
也就是说,调用一个新函数,把原有的值传进去的本质是把目前变量值复制一份传给新函数,当函数返回后原有的修改不会被保留------毕竟你操作的只是复制品
而传递指针时,函数操作会顺着指针找到变量存放的位置,操作的不是副本,自然修改得以被保留
这里面的关系需要读者自己思考清楚,才能研究的透彻,当然最简单粗暴的方法是所有变量都不重名,这在上机的百八十行代码中还能实现,但在复杂的工程中显然是不可行的
指针,结构体
一、指针(Pointer)
1. 基础定义与核心操作
- 本质 :存储内存地址的变量,类型决定解引用时操作的内存字节数(
char*=1,int*=4,float*=4,double*=8)。 - 核心运算符 :
&:取地址符,获取变量的内存地址(如&a);*:解引用符,通过地址访问 / 修改对应内存的值(如*p = 10)。
- 空指针与野指针 :
NULL:值为 0 的指针(int *p = NULL),机试中必须先判断指针非空再操作;- 野指针:未初始化 / 指向已释放内存的指针,机试中需严格避免(初始化 / 释放后置
NULL)。
2. 指针与数组 / 字符串
- 数组与指针等价性 :数组名是不可修改的首元素指针,
arr[i] ≡ *(arr+i);指针可移动(p++/p--)遍历数组,机试中常用此写法简化代码。 - 字符串与指针 :字符串常量(
"hello")本质是const char*,指针操作字符串比数组更灵活(如char *s = "test")。
3. 指针的算术运算
p + n/p - n:按指针类型移动内存(如int* p移动n*4字节);p1 - p2:计算两个同类型指针的内存偏移(仅适用于同一数组 / 内存块)。
4. const 指针(机试数据保护)
const int* p:指针指向的值不可改(*p = 10报错),指针本身可改(p = &b合法);int* const p:指针本身不可改(p = &b报错),指向的值可改(*p = 10合法);const int* const p:指针和指向的值都不可改。
5. 二级指针(多维数据 / 指针数组)
- 定义 :
int** p,存储指针的地址,机试中用于动态二维数组、指针数组批量操作。 - 核心场景:动态分配二维数组(机试处理可变行数 / 列数数据)。
6. 函数指针(回调 / 菜单逻辑)
- 定义格式 :
返回值类型 (*指针名)(参数类型列表)(如int (*calc)(int, int)); - 用途 :机试中用于回调函数(如
qsort的比较函数)、菜单功能映射。
7. 指针与函数
- 指针传参:传地址可修改主函数变量(机试改值必用),传值仅拷贝(无法改原值);
- 指针作为返回值 :仅返回堆内存(
malloc分配)地址,禁止返回栈内存(局部变量)地址。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 1. Function pointer (callback)
int add(int a, int b) { return a + b; }
int mul(int a, int b) { return a * b; }
// 2. Const pointer & string operation
void printStr(const char *str) { // Protect string from modification
while (*str != '\0') printf("%c", *str++);
}
// 3. Double pointer (dynamic 2D array)
int** create2DArr(int rows, int cols) {
int **arr = (int**)malloc(rows * sizeof(int*));
for (int i=0; i<rows; i++) {
arr[i] = (int*)malloc(cols * sizeof(int));
for (int j=0; j<cols; j++) arr[i][j] = i*cols + j;
}
return arr;
}
int main() {
// Basic pointer operation
int a = 10, *p = &a;
*p = 20;
printf("a = %d\n", a); // Output: 20
// Array & pointer
int arr[] = {1,2,3};
int *ap = arr;
for (int i=0; i<3; i++) printf("%d ", *(ap+i)); // Output: 1 2 3
printf("\n");
// Function pointer
int (*func)(int, int) = add;
printf("5+3=%d\n", func(5,3)); // Output: 8
func = mul;
printf("5*3=%d\n", func(5,3)); // Output: 15
// Double pointer (2D array)
int **dp = create2DArr(2,3);
for (int i=0; i<2; i++) {
for (int j=0; j<3; j++) printf("%d ", dp[i][j]);
free(dp[i]); // Free row memory
printf("\n");
}
free(dp); // Free pointer array
// String & pointer
char *s = "machine test";
printStr(s); // Output: machine test
return 0;
}二、结构体(Struct)
1. 基础定义与内存特性
- 本质 :自定义复合类型,仅定义结构体(
struct Stu)不占内存,定义变量(struct Stu s)才分配内存。 - 内存对齐 :编译器按 "成员最大类型大小" 对齐(如
struct { char a; int b; }占 8 字节),机试中计算结构体大小、动态分配内存时必须考虑。 - typedef 简化 :
typedef struct Stu Stu;,机试中减少代码冗余(无需重复写struct)。
2. 成员访问与初始化
- 普通变量 :
stu.name(.操作符); - 指针访问 :
stu_ptr->name(->操作符,等价于(*stu_ptr).name); - 初始化 :
- 直接赋值:
Stu s = {"Tom", 101, 90.5};; - 逐个赋值:字符串成员需用
strcpy(如strcpy(s.name, "Tom"))。
- 直接赋值:
3. 结构体数组(批量数据处理)
- 定义 :
Stu stus[100];,机试中处理多组数据(如班级学生、商品列表)的核心方式; - 核心场景 :结合
qsort按指定字段排序(机试必考)。
4. 结构体嵌套(复杂数据)
- 结构体可嵌套其他结构体、枚举(
enum)、共用体(union):- 枚举:限定取值范围(如
enum Gender {MALE, FEMALE}); - 共用体:复用内存(同一内存块存不同类型数据,机试中节省内存)。
- 枚举:限定取值范围(如
5. 结构体与函数
- 传参方式 :
- 传值:拷贝整个结构体(开销大,机试少用);
- 传指针:仅传地址(效率高,机试首选);
- 返回值:可返回结构体 / 结构体指针(指针需返回堆内存)。
6. 结构体浅拷贝问题
- 若结构体含指针成员(如
char *name),直接赋值(s2 = s1)会导致两个指针指向同一内存,释放时重复释放崩溃;机试中需手动实现深拷贝(重新分配内存)。
c
运行
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 1. Typedef + nested struct/enum/union
typedef enum Gender { MALE, FEMALE } Gender;
typedef union Score { // Reuse memory
int total;
struct { float math, eng; } detail;
} Score;
typedef struct Student {
char name[20];
int id;
Gender g;
Score sc;
} Stu;
// 2. Compare func for qsort (sort struct array)
int cmpByScore(const void *a, const void *b) {
Stu *sa = (Stu*)a, *sb = (Stu*)b;
return sa->sc.detail.math - sb->sc.detail.math; // Asc order
}
// 3. Deep copy (avoid shallow copy issue)
void copyStu(Stu *dest, const Stu *src) {
strcpy(dest->name, src->name);
dest->id = src->id;
dest->g = src->g;
dest->sc = src->sc; // Union copy
}
int main() {
// Struct initialization
Stu s1 = {"Alice", 101, FEMALE, {.detail={92.5, 88.0}}};
Stu s2;
copyStu(&s2, &s1); // Deep copy
printf("s2: %s, math=%.1f\n", s2.name, s2.sc.detail.math); // Output: Alice, 92.5
// Struct array + qsort (machine test core)
Stu stus[] = {
{"Bob", 102, MALE, {.detail={85.0, 90.0}}},
{"Leo", 103, MALE, {.detail={78.0, 82.0}}},
{"Amy", 104, FEMALE, {.detail={95.0, 91.0}}}
};
int len = sizeof(stus)/sizeof(Stu);
qsort(stus, len, sizeof(Stu), cmpByScore);
printf("Sorted by math:\n");
for (int i=0; i<len; i++) {
printf("%s: %.1f\n", stus[i].name, stus[i].sc.detail.math);
}
// Struct memory size (alignment)
printf("Stu size: %zu\n", sizeof(Stu)); // Output: 32 (20+4+4+4, aligned)
return 0;
}三、指针 + 结构体
1. 动态结构体(malloc/free)
- 用
malloc动态分配结构体内存(机试处理可变数量数据),必须搭配free释放,避免内存泄漏。
2. 结构体链表(机试核心压轴题)
- 节点定义 :
typedef struct Node { int val; struct Node *next; } Node;; - 核心操作:创建节点、头插 / 尾插、遍历、删除、查找(机试必考)。
3. 结构体指针数组(动态数据管理)
- 定义:
Stu *stu_arr[100];,存储多个结构体地址,适用于动态添加 / 删除 / 排序数据。
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 1. Struct linked list (machine test final question)
typedef struct Node {
int data;
struct Node *next;
} Node;
// Create node (dynamic struct)
Node* createNode(int val) {
Node *n = (Node*)malloc(sizeof(Node));
if (n == NULL) return NULL; // Check malloc success
n->data = val;
n->next = NULL;
return n;
}
// Insert node at tail
void insertTail(Node **head, int val) {
Node *newNode = createNode(val);
if (*head == NULL) {
*head = newNode;
return;
}
Node *p = *head;
while (p->next != NULL) p = p->next;
p->next = newNode;
}
// Traverse list
void traverseList(Node *head) {
Node *p = head;
while (p != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
// Free list memory
void freeList(Node *head) {
Node *p = head, *tmp;
while (p != NULL) {
tmp = p;
p = p->next;
free(tmp);
}
}
// 2. Struct pointer array
typedef struct Student {
char name[20];
int id;
} Stu;
int main() {
// Linked list operation
Node *head = NULL;
insertTail(&head, 1);
insertTail(&head, 2);
insertTail(&head, 3);
printf("Linked list: ");
traverseList(head); // Output: 1 2 3
freeList(head);
head = NULL; // Avoid wild pointer
// Struct pointer array
Stu *stu_arr[2];
// Dynamic allocate struct
stu_arr[0] = (Stu*)malloc(sizeof(Stu));
strcpy(stu_arr[0]->name, "Tom");
stu_arr[0]->id = 101;
stu_arr[1] = (Stu*)malloc(sizeof(Stu));
strcpy(stu_arr[1]->name, "Jerry");
stu_arr[1]->id = 102;
for (int i=0; i<2; i++) {
printf("Stu%d: %s, id=%d\n", i+1, stu_arr[i]->name, stu_arr[i]->id);
free(stu_arr[i]); // Free struct memory
}
return 0;
}总结
- 指针核心 :掌握
&/*操作、数组 / 字符串的指针等价性、const 指针 / 二级指针 / 函数指针,空指针判断和内存释放是机试避坑关键; - 结构体核心:熟悉内存对齐、typedef 简化、结构体数组 + qsort 排序,嵌套枚举 / 共用体、深拷贝是进阶考点;
- 组合核心:动态结构体(malloc/free)、结构体链表(增删改查)是机试压轴题核心,需熟练掌握节点操作和内存管理。
暂时写到这里,知识点够多了,下一部分写一些具体的上机必记的东西,帮助理解
复试成绩快要出来了,祝各位初始大捷,复试顺利,机考AC,加油!