26年1月来自港科大(广州)、同济大学和快手公司的论文"A Mechanistic View on Video Generation as World Models: State and Dynamics"。
大规模视频生成模型已展现出涌现的物理一致性,使其成为潜在的世界模型。然而,当代"无状态"视频架构与经典的以状态为中心世界模型理论之间仍存在差距。本文提出一种以状态构建和动态建模两大支柱为核心的分类体系,旨在弥合这一差距。状态构建分为隐式范式(上下文管理)和显式范式(潜压缩),并通过知识整合和架构重构来分析动态建模。此外,提倡将评估标准从视觉保真度转向功能基准,以测试物理持久性和因果推理能力。最后,指出两个关键前沿领域:通过数据驱动的记忆和压缩保真度增强持久性,以及通过潜因素解耦和推理先验整合来推进因果关系。通过应对这些挑战,该领域可以从生成视觉上逼真的视频发展到构建稳健的通用世界模拟器。
如图所示:
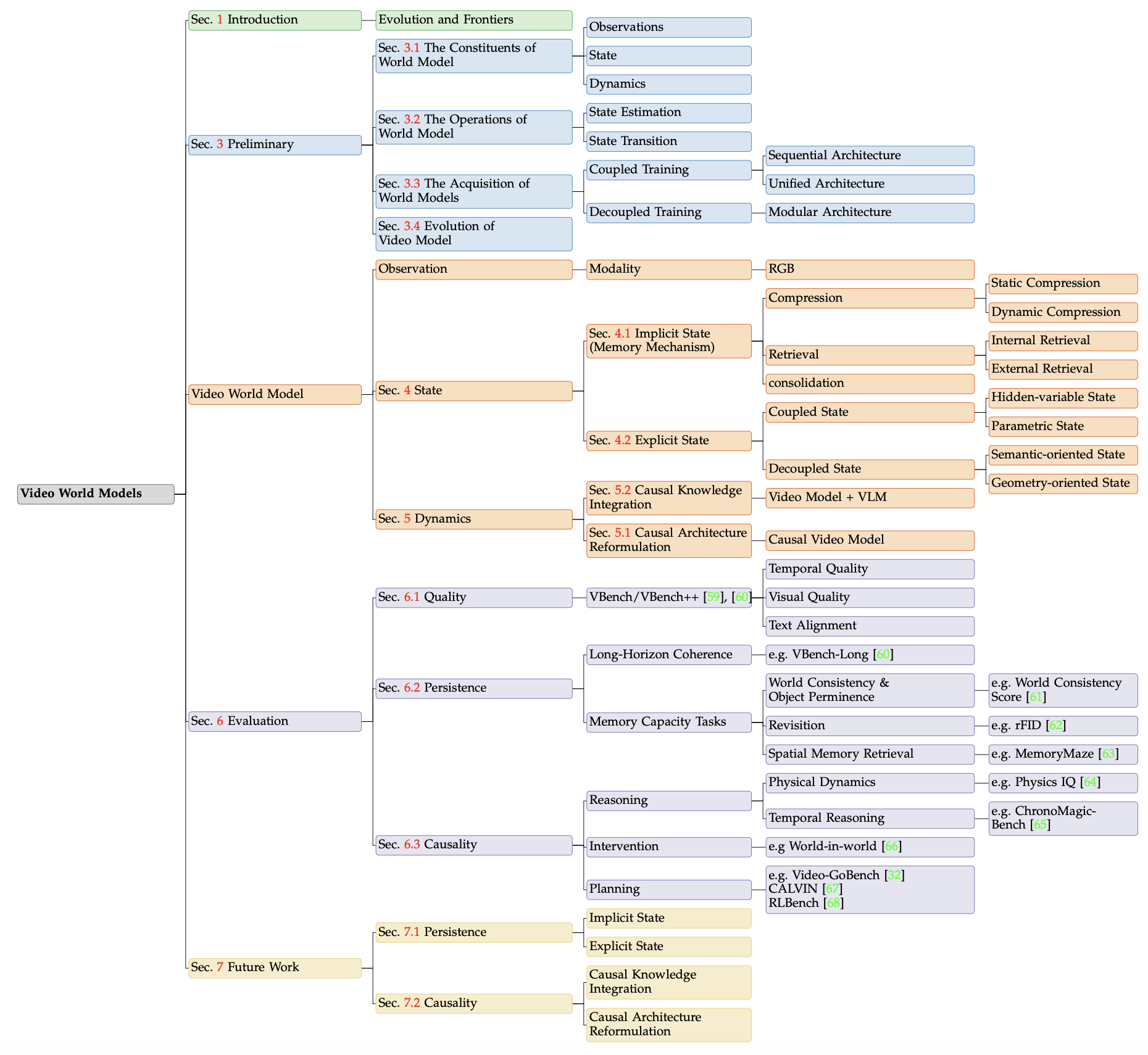
世界模型的构成要素:观察、状态和动态
世界模型的概念基础深深植根于认知科学35,它被定义为人类心理中构建的对现实的简化内部心理表征。
人类通过感知外部感官表现(观察)并将其提炼为抽象的内部概念(状态),利用这些内部表征在心理"沙箱"中模拟因果结果(动态)。这种内部模拟使个体能够在执行实际行动之前预测各种行为的潜在后果,从而成为主动决策和战略规划的基本认知基础。
在认知科学之外,控制理论中也出现一种密切相关的内部心理模拟形式化方法,其中被研究系统的行为通过状态空间表征进行建模3637。在这种范式中,概括系统状态的核心变量被选择并维护为内部状态x,它可以完整地描述系统而不会产生冗余。其动力学 ẋ(x 的导数)和观测值 y 可以通过微分方程导出,这些微分方程是利用物理定律人为预先定义的:
ẋ=f(x,u), y=g(x),
这种状态空间公式对状态到动力学和观测的映射关系给出数学上严谨的定义,从而能够进行前向仿真,用于系统的预测、规划和控制。
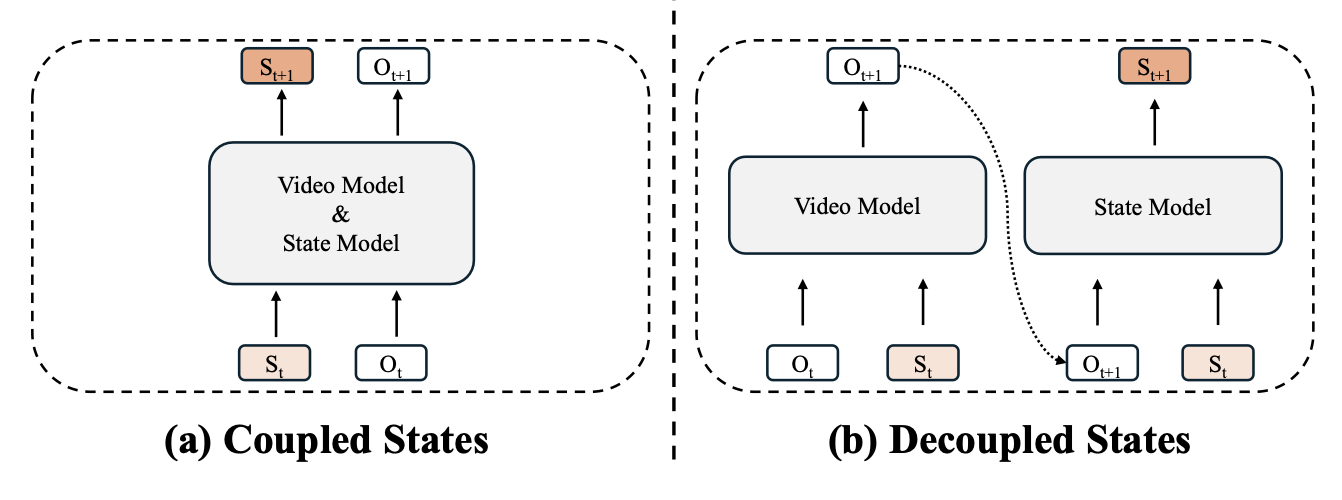
基于认知科学和控制论的洞见,MBRL 中的世界模型利用学习的潜状态空间表征来形式化内部心理模拟38、39、40、41、42、43、44、53、54、55、56、57。在该框架下,世界模型的运行也被提炼为观测、状态和动力学。具体而言,t 时刻的观测值(记为 O_t)捕获外部感觉信息,并且可以从控制论的角度解释为系统输出。在上下文中,O_t 通常以高维像素级视觉输入的形式出现,例如视频帧,仅提供底层环境的部分且间接的视图。为了弥合原始感知和内部推理之间的差距,引入状态 S_t 作为智体对环境的潜表征。该状态是对控制理论中经典系统状态的学习型高维泛化,概括预测和决策所需的所有任务相关信息。尽管其具体参数化在不同的架构中有所不同,但 S_t 始终作为世界状态的紧凑、抽象编码。最后,动力学控制着该状态在特定干预或动作 A_t(对应于控制输入)下的因果演化。这种演化通过学习的状态转移函数进行建模:
S_t+1 = f(S_t, A_t),
这与经典动力系统中的状态方程类似。这种预测机制使模型能够通过内化环境的客观物理定律来模拟未来状态,从而使智体能够在行动执行之前"预见"其后果。
综上所述,尽管域和形式有所不同,但世界模型的运行始终围绕三个紧密耦合的组成部分展开:
观测:这指的是来自环境的原始、可感知的数据。在视频模型中,观测通常是高维的、像素级的输入(视频帧),它们提供对世界的局部、间接的视图。
状态:状态是旨在全面解释当前环境的内部表征。为了建立准确的状态,模型必须从大量的观测历史中蒸馏和聚合信息。其主要目标是在过滤掉无关噪声和冗余信息的同时,保留所有与任务相关的变量。
动态:动态描述状态如何随时间演变,通常是在特定动作或干预的影响下发生的。通过对状态转移 S_t+1 = f(S_t, A_t) 进行建模,世界模型将环境的潜物理和因果规律内化。
世界模型操作:估计和预测
基于上述基本组件,世界模型通过两个核心过程运行:状态估计和状态转换。尽管它们的具体实现方式在不同的建模范式中存在显著差异,但这些过程共享一个共同的概念基础。如图所示:
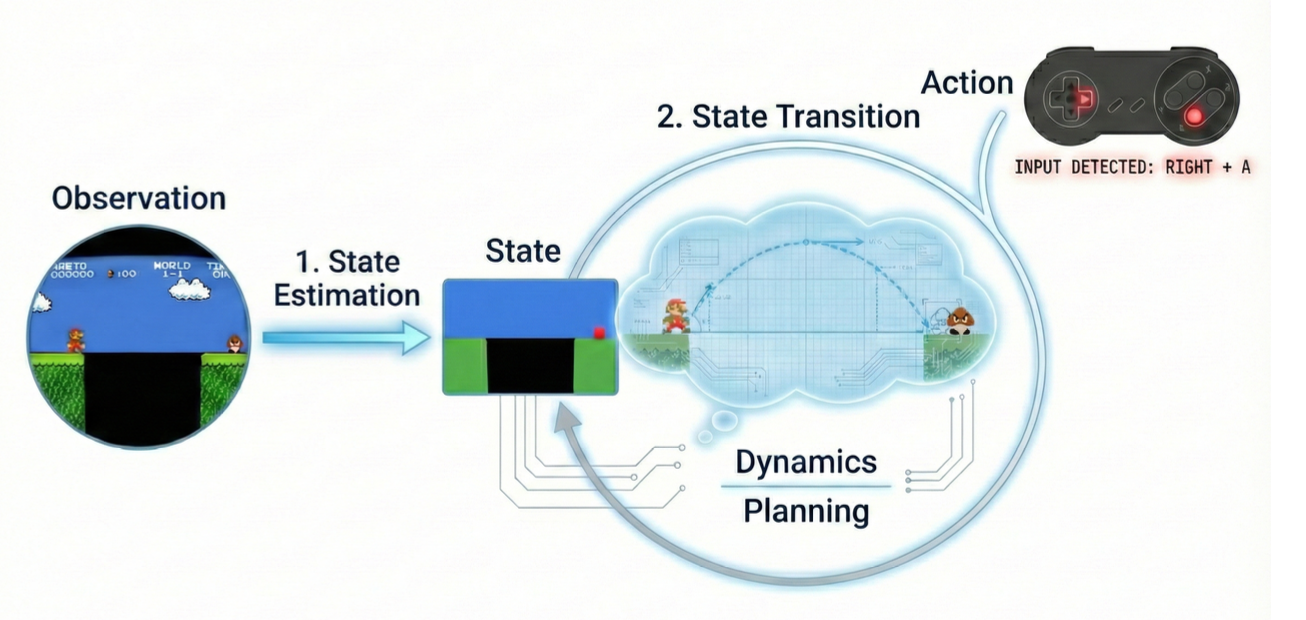
- 状态估计(理解世界)。状态估计作为模型的抽象机制,其目标是将高维的序列观测压缩成一个紧凑的表示,以捕捉环境的当前状态。
形式上,该过程近似于基于观测历史的后验潜状态分布:
S_t ∼ P_φ(S_t | O_1:t)
在有状态世界模型中(MBRL 方法 39、40、41、42、43、44 中常用),状态估计通常通过递归聚合机制实现。潜状态通过随时间推移整合新的观测和动作而增量更新:
S_t = Enc_φ(S_t−1, O_t, A_t−1)
这种递归公式使得模型能够编码非瞬时物理属性(例如速度、加速度和物体恒存性),而这些属性无法仅从单次观测中推断出来。
相比之下,许多近期基于Transformer的架构14、20、21、24、25、26、81、82、83、84、85、86、87、88采用无状态范式。这些模型不维护显式的循环隐藏状态。相反,潜表示直接从最近观测的固定时间窗口导出:
S_t ≈ O_t−k:t
这里,时间推理的负担从显式的状态更新转移到作用于观测序列的注意机制。
大规模生成式视频模型处于这一范式的极端。由于这些模型直接作用于视频帧------通常通过变分自编码器 (VAE) 实现,其潜空间保留精细的视觉细节------"状态"的概念得到简化。在这种情况下,潜状态通常等同于整个观测历史:
S_t ≡ O_1:t
在这种等式下,状态估计简化为维护观测流本身。因此,模型对世界的"理解"完全编码在过去感知的序列中,该序列被视为当前环境的充分统计量。后续的推理和模拟直接基于这种原始或半原始历史进行。
- 状态转换(预测世界)。状态估计捕捉环境的当前配置,而状态转换则模拟其随时间的因果演变。该过程充当内部模拟引擎,使世界模型能够预测未来的状态或观测结果。
在具有显式潜表示的有状态架构中39、40、41、42、43、44,状态转换由参数化的潜动力学模型控制:
S_t+1 ∼ P_θ(S_t+1 | S_t, A_t)
这种形式强制区分表征学习和动力学建模,从而能够在潜空间中实现高效的多步展开。
相比之下,在没有显式状态变量的无状态模型中14、20、21、24、25、26、81、82、83、84、85、86、87、88,状态转换通过观测序列的逐步扩展隐式地处理。
在恒等式 S_t ≡ O_1:t 下,动力学问题简化为一个基于动作的下一个-观测预测问题:
O_t+1 ∼ P_θ(O_t+1 | O_1:t, At)
在此公式中,"转换"对应于历史缓冲区的自回归更新。通过预测下一个高保真观测值 O_t+1 并将其添加到现有序列中,模型直接在观测空间中推进世界状态。通过重复应用此过程,该模型有效地转化为数据驱动的可视化模拟器。
世界模型的获取:耦合学习与解耦学习
由于世界模型主要用于辅助下游决策,因此可以根据其在学习过程中与策略模型的耦合程度对其进行分类。
-
闭环学习(耦合训练)。世界模型和策略模型联合训练,使得世界模型对策略目标表现出直接的梯度依赖性。这种范式可以进一步区分为两种结构形式。在顺序组合中,模型保持独立模块状态,但通过共享梯度流进行优化。例如,在"视频即世界模型"的研究中,如 UniPi 28 或 GAIA-1 27,采用逆动作模型从生成的视频序列中提取动作。如果提取的动作偏离原始指令,则将梯度反向传播到世界模型中,以强制生成"动作可执行"且物理上一致的动作。另一种方法是,统一架构将世界模型和策略集成到一个端到端的框架中,例如 WorldVLA 89,其中感知、预测和动作生成在一个整体系统中进行优化。
-
开环学习(解耦训练)。将世界模型视为一个独立的实体,主要通过被动观察大规模数据集来学习。在这种范式中,虽然策略模型可以在自身优化过程中利用世界模型进行内部"想象"(如经典的MBRL框架39、43所示),但世界模型本身的参数并不接收来自策略奖励信号或损失函数的梯度。这种解耦方法的典型例子是现代视频生成模型1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25。这些模型专注于从海量数据中掌握视觉动态的客观统计规律,从而提供一个稳健但固定的模拟基础,使其不受下游智体特定决策逻辑的影响。
视频模型的演进:迈向稳健的世界模拟器
现代视频生成模型已成为世界模型的有力候选者14、20、27、28、29、30、31、32。然而,尽管它们具有视觉保真度,但在几个关键方面与经典定义有所不同:
状态
大多数当代视频生成模型缺乏显式的、压缩的潜状态。相反,观测序列 O_1:t 本身充当隐状态。然而,这些序列不断扩展的特性带来巨大的计算负担和日益增长的内存占用。这种扩展使得长期时间推理变得越来越困难,因为模型必须关注越来越大的上下文,这通常会导致长时程模拟中持久性的丧失。因此,近期的文献主要集中于通过两种架构策略来增强持久性:
(1) 记忆机制:这些方法保持输入序列中状态的隐式性质,但引入专门的机制来更有效地管理时间数据。这些方法并非平等地处理所有过去的帧,而是执行选择性地存储、检索或压缩序列中元素的操作,从而优化模型处理扩展时间上下文的能力,而不会线性增加复杂性 90、91、92、93、94、95、96。
(2) 显式状态:与此相反,这些方法通过显式构建作为全局长期记忆结构的潜状态,摆脱对原始序列的依赖。通过将历史信息提炼成固定大小或层级式的潜在瓶颈,这些模型将推理复杂性与序列长度解耦,为在较长的时间范围内维持环境一致性提供了稳定的基础97、98、99、100、101、102、103、104、105。
动态
标准视频模型1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25通常利用双向注意机制,根据文本提示生成高保真视频。在生成过程中,视频模型主要作为"渲染器"运行,同时生成固定时长的视频片段,而不是在其视觉推理中展现明确的时间因果关系。为了解决固有的因果关系缺失问题,当前的研究主要遵循两种策略路径,以在视频生成中注入因果关系:
(1) 因果架构重构。这条路径侧重于根本性的架构转变或优化目标,以确保模型遵循时间顺序。研究人员通过训练或提炼视频模型使其真正具有自回归性,或采用因果掩码机制,旨在将生成过程从同步的"渲染"任务转变为顺序的"预测"任务106、107、108、109、110、111、112、113、114、115、116、117、118、119、120。
(2)因果知识集成。这条路径利用本身具有强大因果推理能力的外部模型(例如大型多模态模型(LMM))来指导生成过程。这种集成通常表现为两种形式:(1)顺序解耦:高级 LMM 作为"规划器"来确定场景的逻辑和动态,而视频模型作为下游"可视化器"来渲染像素121、122、123、124、125、126、127;(2)统一耦合:理解和生成能力在一个框架内融合128,其中 LMM 的因果推理和视频模型的生成能力被联合优化,以确保生成的动态基于逻辑世界知识。
摘要
关于其他维度,例如学习范式,当前的视频模型主要依赖于开环学习,即模型的优化独立于具体的智体策略。虽然目前的研究热点在于联合训练策略级信号对于实现更高的模型接地性和动作对齐性是否至关重要,但此类耦合学习的研究超出本文的范围。本文着重探讨视频生成作为世界建模基础的最新进展。具体而言,回顾状态表示(解决持久性和记忆方面的挑战)和因果动力学(解决从渲染到物理预测的过渡)方面的最新进展,旨在绘制出一幅通往更稳健世界模拟的全面技术路线图。如图所示:

为了探究视频生成模型如何演化为稳健的世界模型,首先分析其内部表征,尤其关注状态的构建。主要目标并非强制模型生成显式的状态变量,而是将"状态"的概念作为一种充分统计量纳入模型。通过将历史背景蒸馏到这种表征中,确保模型能够维持连贯的长期模拟。
隐状态 - 记忆机制
定义
在这种范式中,视频生成模型并不显式地构建一个紧凑的、抽象的潜变量来表示世界。相反,它依赖于隐状态构建,其中"状态"在功能上等同于对历史观察的管理背景。
在此,状态 S_t 并非固定大小的向量,而是基于观测历史 O_1:t 动态生成的信息集合。关键在于,S_t 并非直接等价于原始历史(否则计算量将难以处理),而是外部记忆机制 (M) 的结果。
该机制构成隐状态构建的功能骨架。借鉴认知记忆系统 129 的思路(后者依赖于编码来压缩信息、巩固来稳定存储以及检索来访问相关的历史信息),可以将 M 形式化为一个复合机制,它通过三个功能原语来应对视频生成的计算约束:
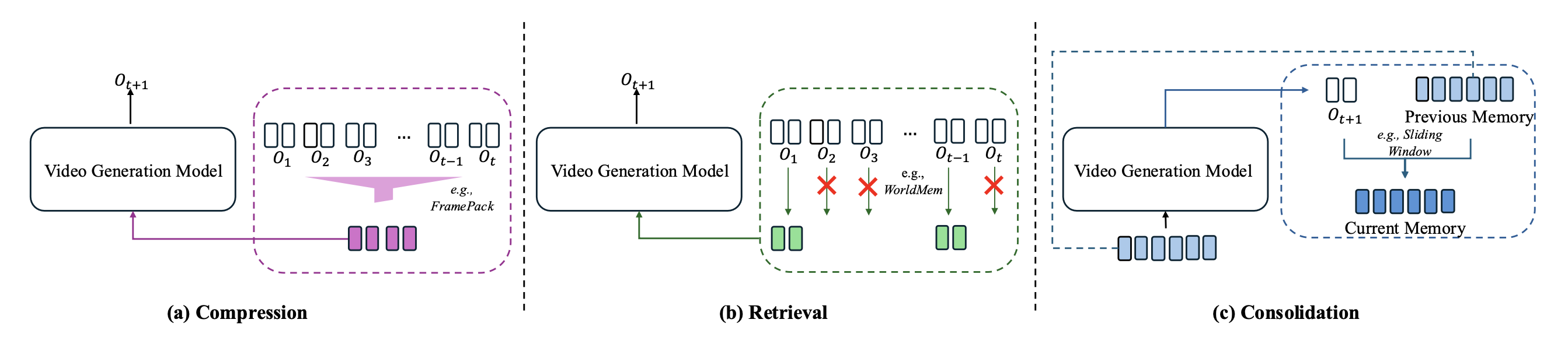
• 压缩:鉴于视频流中存在高度的时空冗余,存储原始历史效率低下。该机制将上下文 O_1:t 压缩成紧凑的表示形式(例如,通过词元合并或摘要向量),以保留高密度信息。
• 检索:并非所有历史信息对于生成下一帧都同等重要。该机制采用检索策略(例如,稀疏注意或KV查找)根据当前生成意图选择性地访问过去状态的特定片段。
• 整合:生成新内容时,记忆状态必须随之演化。更新机制决定如何整合新的观测结果,以及哪些过时的信息会被移除或重新加权,从而使模型能够支持无限流式传输。
根据此定义,"状态"代表视频模型的活动工作记忆,即生成下一帧所需的特定压缩和检索历史记录子集。
记忆机制 - 压缩
在视频生成的背景下,上下文压缩涉及将冗长的历史序列压缩成紧凑的表示形式,以缓解计算瓶颈。虽然这些方法通常优先考虑推理效率而非显式的动态建模,但它们是扩展世界模型的重要基础。通过降低注意机制的二次复杂度,压缩使得在更长的时间跨度内探索尺度规律成为可能。根据压缩的时机以及策略是内容自适应还是预定义,将这些机制分为动态压缩和静态压缩。
动态压缩,指的是在模型计算过程中实时合并或剪枝上下文,其压缩标准通常来源于语义相似性或注意得分。这种方法已在LLM中得到广泛验证,例如 ToMe 130、AdaptMerge 131、TokenFusion 132、MCTF 133 和 DiffRate 134 等方法。在视频领域,VidToMe 135 通过合并帧间的相似token来应用这些原理,从而增强时间一致性,同时降低工作量,使自注意模块能够处理更长的序列。此外,诸如 Sparse VideoGen (SVG) 136 等方法利用在线分析策略来捕获动态稀疏模式,通过实时跳过非必要的空间或时间路径来有效地压缩注意计算图。由于冗余是基于运行过程中的特征激活来识别的,因此这些方法通常无需训练,并且能够高度适应特定的视频内容。
静态压缩,是指在模型的核心计算开始之前,根据预定义或启发式策略来压缩上下文。虽然基于 LLM 的方法(例如 Learning to Compress 137、RAPTOR 138 和 Long 139)利用专门的结构来管理长程依赖关系,但以视频为中心的方法则明确地利用时空冗余。FramePack 140、Pyramidal Flow Matching 141 和 LoViC 142 基于时间重要性设计压缩比,其中下采样程度随时间线变化,通常对最近的帧保持较高的保真度,而对较远的历史帧进行更激进的压缩。RELIC 143 在KV缓存上采用经验空间下采样来适应更长的时间范围,而 TempoMaster 144 则实现一种由粗到精的时间策略,其中上下文首先通过低帧率的"蓝图"进行压缩,然后再以更高的帧率进行精细化。由于这些策略会改变输入分布或表示密度,因此通常需要对模型进行训练或微调,使其适应压缩后的潜上下文。
记忆机制 - 检索
外部检索,是指在将历史或外部上下文输入生成模型之前对其进行预选,其重点在于上下文相关性而非单纯的计算吞吐量。这种范式通常分为两类:通过历史记忆保持自洽性,以及通过外部参考增强来提升质量。为了保持时空一致性(通常被称为隐几何记忆),诸如 WorldMem 93、Context-as-Memory 94、VRAG 145 和 WorldPack 91 等方法使用低维物理状态(例如相机姿态、3D 坐标和方向)来查询历史帧。Ctrl-World 146 通过对历史帧进行采样来简化这一过程,从而减少上下文长度,而 MagicWorld 147 则利用 I2V 序列的第一帧作为视觉键,从历史缓存中检索相关数据。除了自身历史之外,另一研究分支侧重于参考增强生成,以注入"世界知识"或运动先验。Corgi 92 利用 T2I 生成的候选对象来指导模型,而 DiT-Mem 95、RAGME 148 和 MotionRAG 149 则利用基于 CLIP 的嵌入来检索外部视频片段或"运动示例",从而提供逼真的物理动态。最后,OneStory 96 通过引入可学习的检索模块进一步推进这一研究,证明外部控制器可以通过端到端地优化检索策略,从被动的搜索引擎演变为世界模拟器中主动的、具有意图感知能力的组件。
内部检索,将检索隐式地集成到注意机制中。这些方法不是在外部管理上下文缓冲区,而是将"检索"过程直接集成到注意计算阶段。为了解决长上下文建模的计算瓶颈,一种重要的范式将世界状态重新定义为动态检索的上下文,其中内部内存通过可学习或先验驱动的可见性算子进行管理。该类别中的早期方法,例如 MoC 150 和 MoBA 151,实现了可学习的路由引擎,将历史记录分割成内容对齐或连续的块,并利用均值池化键描述符进行顶-块(top-block)选择;MoC 强调镜头和帧等内容边界,而 MoBA 则侧重于通过 Online-Softmax 合并这些路由输出的数学一致性。为了保留稀疏选择中经常丢失的全局-觉察,VSA 152 引入一种几何对齐的双路径架构,该架构融合细粒度的局部检索和门控的粗粒度全局上下文;而 VMOBA 153 则通过 1D-2D-3D 逐层循环划分和全局阈值处理,针对扩散模型定制了这种多尺度视角。与纯粹学习路由不同,AdaSpa 154 和 Sparse VideoGen 136 利用结构先验,特别是去噪步骤中的注意稳定性以及头特定的时空角色,实现无需训练的推理-时稀疏化。MoGA 155 和 SVG2 156 进一步细化检索粒度,它们通过 k-means 聚类将token聚类成语义一致的组或记忆块,从而超越物理块边界,确保在不相交片段之间保持高保真度的身份保留。 BSA 157 和 ReSA 158 分别针对效率和鲁棒性进行改进。BSA 提出双向剪枝,以消除查询(Q)冗余和KV冗余;ReSA 158 则通过引入周期性密集校正来保护内存完整性,从而抵消累积近似误差和内存漂移。最后,Video-XL-2 159 和 Radial Attention 160 进一步细化检索逻辑。Video-XL-2 159 采用基于双层KV表示的任务-觉察混合分辨率策略;Radial Attention 160 则基于注意能量的自然指数衰减,在对数尺度内存访问之前施物理驱动的距离。
记忆机制 - 整合
记忆整合,是指在生成新内容后实时精简上下文缓冲区,以在保持计算量恒定的同时,维护长期一致性。而StreamingT2V 161 通过从生成块的最后 8 帧中提取特征作为短期窗口来实现这一点,同时将整个序列锚定到第一帧的全局语义。FreeLong 162 利用频谱混合操作,使用 3D FFT 从最近的窗口中分离并融合全局低频结构布局和局部高频细节。对于基于token的建模,Loong 164 对最后 5 帧进行像素-到-token的重新编码,以重置分布偏移,然后再丢弃先前的历史记录。相比之下,FAR 114 使用非对称的 patchify 内核将较远的历史帧聚合到 KV 缓存中的低分辨率token中。 WorldWeaver 165 通过将生成的深度线索存档到结构化记忆库中来扩展整合模式,从而限制几何漂移。最后,EgoLCD 163 引入一种基于重要性驱动的稀疏KV压缩的主动更新策略,根据注意分数过滤掉冗余tokens,仅保留高价值的语义特征。
总结:隐状态的功能原语
在综合隐状态构建方法时,根据这些方法的操作逻辑和在管理计算约束和历史保真度之间权衡的功能角色对其进行分类(如表所示)。虽然这三种原语都有助于缓解处理原始历史的瓶颈(O_1:t),但它们在定义信息相关性的方式上存在根本差异。
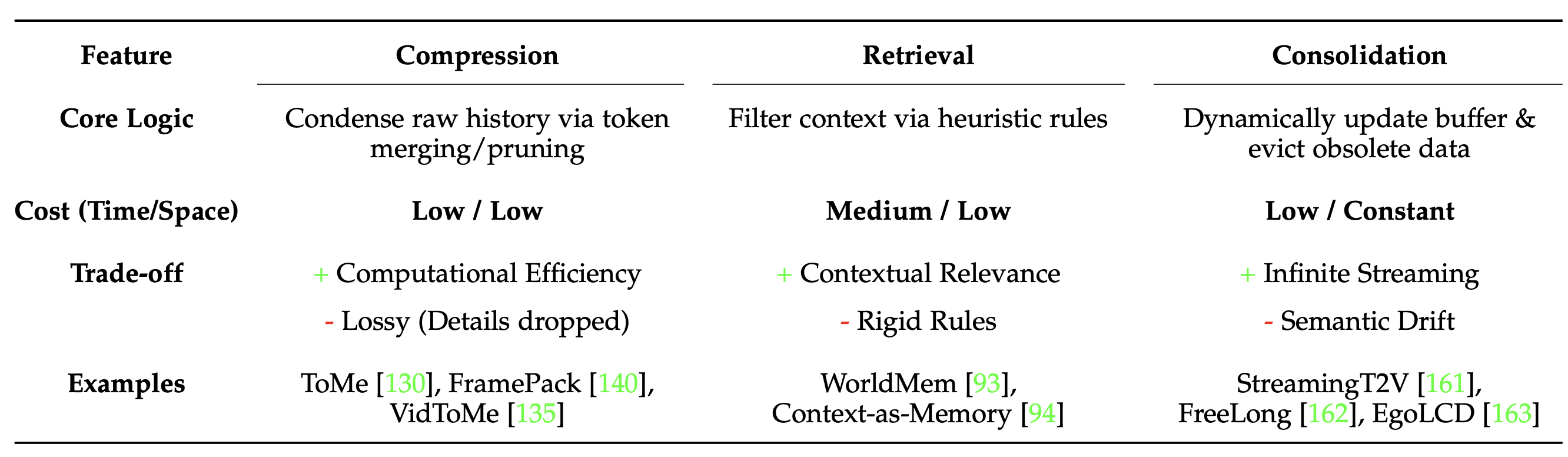
压缩作为一种信息消化机制,实施了一种"软平均"策略,无论具体的生成意图如何,都能系统地降低数据密度。相比之下,检索则充当主动输入选择过滤器。它并非对历史进行均匀的压缩,而是通过主动识别并路由基于启发式或学习先验知识的最相关上下文片段来优化信息流。最后,整合过程作为一种事后蒸馏过程运行。与检索的预选择性质不同,它专注于生成后对记忆缓冲区进行动态维护,清除冗余信息以支持无限流且不发生语义漂移。这些组件共同将静态的历史缓冲区转换为动态的工作记忆,确保隐状态始终保持对过去信息的蒸馏、高密度摘要。
如图所示:
显式状态
定义
与通过外部选择策略管理原始观测数据的"隐式状态"范式不同,显式状态范式通过内部压缩构建世界状态。这些方法并非维护不断增长的先前帧缓冲区,而是将历史上下文蒸馏成一个全局更新的潜变量,该变量作为视频演化的全面数学概括。
在此框架下,"状态"是一种抽象、紧凑的表示,其范围从瞬态激活向量和参数权重到通过正式转换过程演化的显式 3D 几何。至关重要的是,更新机制从启发式规则(例如先进先出或检索)转变为功能性转换映射,其中模型学习仅压缩和传播最显著的信息,以确保未来的一致性。根据这种转换函数与生成骨干网络之间的架构关系,将这些工作分为两个子范式:
• 耦合状态:转换函数内在地融合在生成骨干网络内部,使得模型能够作为一个同步状态转换系统运行。在这种范式下,状态可以表现为隐变量状态(例如,SSM 隐单元、LSTM 单元或线性注意缓冲区),也可以表现为参数状态,其中历史信息通过在线优化直接编码到模型权重的可塑性中。
• 解耦状态:状态在结构上与骨干网络的内部激活解耦,作为一个独立的表示存在,并被显式地更新。这包括面向语义的方法,这些方法利用独立的转换模型(例如,LLM)来演化潜世界描述;以及面向几何的方法,其中状态是一个显式的 3D 记忆(例如,点云或高斯分布),通过迭代空间融合和反投影进行更新。
如图所示:
耦合状态
至关重要的是,这些方法的递归更新性使得观测模型能够本质上作为状态转换模型运行,其中映射和新观测的生成由单个架构同步执行。在这种范式中,序列的"记忆"存储在模型本身中,表现为隐变量状态或参数状态。隐变量状态。这类状态通常由通过内部因果线性系统(例如状态空间模型 (SSM)、循环神经网络 (RNN) 或线性注意机制)维护和更新的隐激活向量组成。例如,MALT Diffusing 97 通过在模型层中维护一个固定大小的记忆潜向量来构建全局状态,从而将长程上下文压缩成紧凑的token,并使用循环注意机制从每个生成的片段中提取视觉特征。类似地,VideoSSM 102 利用基于 Mamba 的 SSM 分支,其中隐状态作为全局压缩记忆,用于捕获超出局部滑动窗口的依赖关系。SANA-Video 99 利用线性注意机制的累积特性来维持恒定记忆状态,并采用分块自回归方法,通过关联特性整合增量特征。为了解决遗忘问题,递归自回归扩散 (RAD) 101 将 LSTM 模块集成到扩散transformer中,使用隐状态和单元状态作为记忆载体,并通过 RNN 前向传播进行更新。架构特定的扫描方法进一步增强这些状态;LinGen 103 使用以"review token"初始化的 Mamba2 隐状态作为全局语义先验,并通过由旋转-主扫描 (RMS) 引导的线性扫描对其进行更新。其他代表性工作包括 Matten 104,它将全局状态嵌入到混合的 Mamba-Attention 潜变量中;以及 DiM 105,它采用双向 SSM 模块进行时空传播。最后,Po 98 将分块 SSM 状态与局部 KV 缓存相结合,使用空间优先/时间次要的扫描顺序,随新帧的到达,去线性地演化状态。
参数化状态。这种范式代表一种根本性的转变,它将模型参数的子集视为动态的、与输入相关的变量,而不是固定的常量。特定的权重不再将历史记录存储在激活缓冲区中,而是作为状态载体,根据输入流不断更新,从而有效地使模型能够"学习"并动态地巩固当前上下文的动态特性。 TTT-DiT 166 将全局状态参数化为测试-时训练 (TTT) 层中的权重矩阵,其中在线自监督梯度优化过程在推理过程中将长期历史信息直接"写入"参数空间。在此基础上,Titans 167 构建一个神经记忆模块,该模块利用基于动量的更新规则,在更新记忆权重时同时考虑过去的趋势和当前的"意外情况"。从理论角度来看,嵌套学习 (nested learning)168 将全局状态定义为嵌套优化问题的最优解,该优化问题旨在压缩序列的"上下文流",并将上下文提炼并固化为实时的多级状态表示。
总结:隐变量状态在工程可行性和快速架构迭代方面具有显著优势,尤其是在将无状态 Transformer 模块与因果线性系统相结合的混合设计中。然而,如何有效地平衡状态容量和记忆更新频率仍然是一个关键挑战,值得在长时程建模中进一步研究。相比之下,参数状态在理论上比隐变量状态拥有更大的容量和表征能力。然而,它们的实现涉及大量的工程开销和复杂的优化要求,并且当前视频生成文献中的实证研究仍处于起步阶段。
解耦状态
此类方法维护一个显式状态,该状态在结构上与视觉生成主干的内部激活解耦。这些方法并非将动态信息融合到模型的权重或隐藏层中,而是保留一个独立的状态表示,其范围从抽象的潜变量到随新观测结果产生而演化的显式 3D 几何。状态演化的机制取决于系统的取向:语义导向的方法通常使用独立的转换模型来映射随时间变化的状态,而几何导向的方法则将 3D 表示本身视为状态,并通过迭代空间融合对其进行更新。
语义导向的状态。语义导向的方法侧重于维护对象标识、场景逻辑和叙事进程的高级一致性。通过将历史背景抽象为符号或潜语义表示,这些方法确保视频的"故事"在长时间内保持连贯性,即使视觉细节发生变化。例如,Owl-1 121 通过维护一个独立于视频主干之外的紧凑潜世界状态来实现独立的过渡模型;在每个片段渲染之后,多模态 LLM (MLLM) 将观察的动态总结为自然语言描述,并将当前状态映射到下一个状态以指导后续生成。类似地,Pack 和 Force 169 采用 MemoryPack 机制,其中 SemanticPack 模块充当外部循环网络。它通过压缩历史片段并将其与全局文本-图像指导对齐来迭代更新长期记忆向量,从而有效地将分钟级背景封装在一个独立的循环状态变量中。
几何导向的状态。几何导向的方法优先考虑空间一致性、视角不变性和物理结构。这种范式的一个显著特征是,3D 表示本身充当状态,作为一种持久的、不断演化的记忆,而非静态资产。在该框架下,诸如点云 170、171、172、173、174、175、176、3D 高斯分布 177、178、网格 179 或隐式场 180 等 3D 结构会在生成过程中逐步细化。状态的更新并非依赖于学习的转换模型,而是通过直接融合新的观测数据来实现。该过程通常始于基于稀疏观测数据估计的粗略重建,随后进行迭代的渲染-生成-更新循环:从新的视角渲染当前的 3D 记忆以识别缺失区域;生成模型合成新视角;随后,合成图像被反投影并融合到三维表示中,以更新几何形状、外观和可见性。这种迭代改进使系统能够随时间积累场景知识,从而确保多视图预测的严格结构完整性。
总结:解耦状态提供极大的灵活性,允许研究人员选择针对特定任务需求的专用状态空间和转换模型。面向语义的状态有助于在高度抽象的LLM驱动的语义空间中进行转换,这些空间擅长叙事逻辑,但可能缺乏细粒度的空间推理能力。相反,面向几何的状态利用显式的三维表示来确保严格的空间一致性和结构完整性,但它们在建模丰富且流畅的时间动态时常常遇到困难。
摘要:世界建模中的隐式状态与显式状态
综合状态构建范式(如表所示),从四个关键维度分析隐式和显式状态之间的差异:机制、逻辑、持久性和可扩展性。
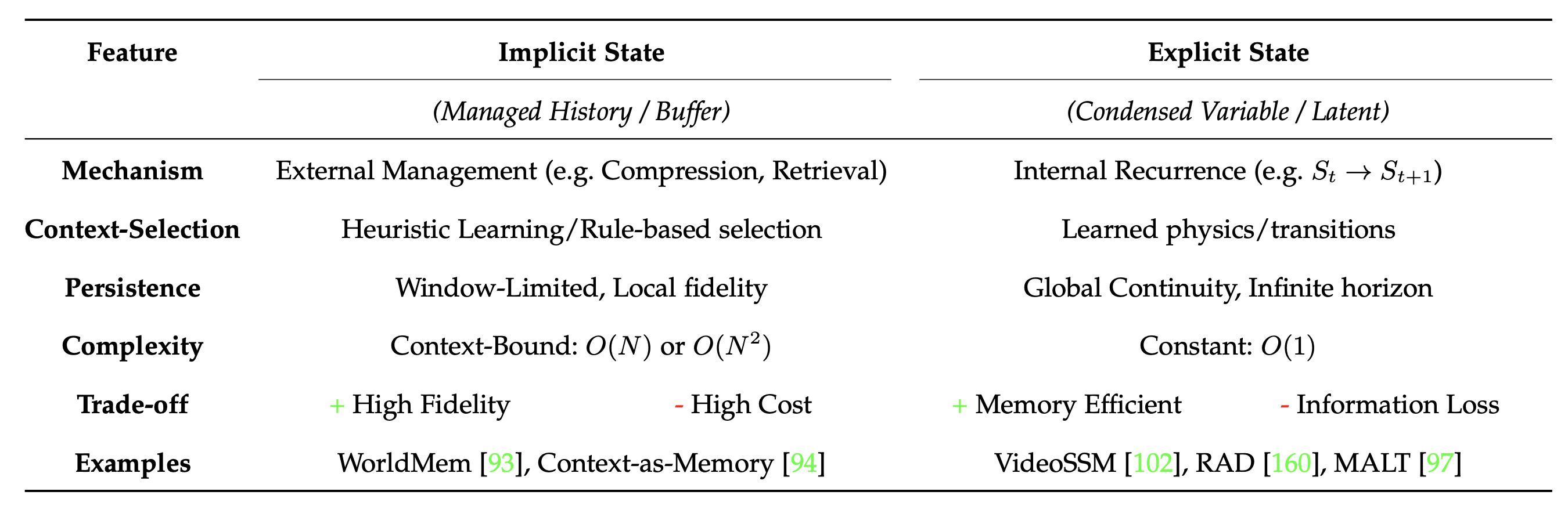
机制与持久性。二者的根本区别在于历史的存储方式。隐式状态作为一种受管理的历史,利用外部管理机制来维护原始观测数据的缓冲区。虽然这种方式通过保留真实token来保持较高的视觉保真度,但却导致了窗口限制的持久性,即模型一旦超出上下文窗口就容易遗忘。相反,显式状态采用内部递归,通过递归更新将历史提炼成一个紧凑的潜变量(S_t)。这种公式实现全局连续性,理论上支持无限的视域,但激进的压缩可能会导致"信息衰减",并随着时间的推移丢失精细的细节。
逻辑与因果关系。从因果关系的角度来看,这两种范式对信息相关性的定义不同。隐式状态主要由启发式驱动,依赖于人为设计的规则(例如,相似性匹配或时间接近性)来选择上下文。相比之下,显式状态由动力学驱动。通过要求模型自主学习状态转换函数(S_t → S_t+1),这些系统超越了模式匹配,将世界的底层物理规律内化,从而更符合世界模拟器的理论定义。
可扩展性和权衡。最后,计算可扩展性决定了部署的可行性。隐式状态受上下文限制,其推理成本随历史长度呈线性或二次方增长(O(N) 到 O(N²))。而显式状态则具有恒定可扩展性(O(1)),无论模拟时长如何,计算量都保持不变。最终,选择哪种状态是一种权衡:隐式状态目前是实现高保真视频合成的最可靠途径,而显式状态则代表了能够进行长期推理的高效自主智体的前沿发展方向。
为了有效地模拟现实世界,视频模型必须具备一定的推理能力。具体而言,模型必须内化潜在的因果规律,以确保其时间演化在物理上合理且逻辑一致。目前旨在增强视频模型因果性的研究主要遵循两种策略。
因果架构重构
为了内化潜在的因果规律并确保时间演化在物理上合理,目前的研究重点在于因果架构重构,主要是通过将降噪器重新设计为严格的因果结构来实现。因果掩码视频扩散108、109、110的初步研究通过消除未来到过去的信息泄漏,弥合了渲染和预测之间的差距。 AR-Diffusion 108 和 MAGI-1 109 等方法通过异步或单调的逐帧噪声调度来强制执行方向依赖性,而 Self-AR (NOVA) 110 和 Video-MAR 111 则整合逐帧因果注意掩码和下一帧扩散损失,以基于完整的先前上下文预测被掩码的tokens。Video-GPT 112 和 FAR 114 进一步扩展这种自回归范式。Video-GPT 112 通过片段级因果掩码预测序列视频片段,而 FAR 114 则使用非对称的 patchify 核来压缩远距离历史并保持长上下文因果关系。 VideoPoet 115 和 NOVA 116 将生成过程重新表述为使用离散或非量化tokens的下一个token或下一帧预测任务,而 Lumos-1 117 和 ART-V 118 则通过token依赖策略和短期上下文条件来实现严格的帧间因果关系。除了架构之外,诸如 Diffusion Forcing 119 等最新技术利用渐进式噪声水平和因果掩码,而 CausVid 181 则采用因果蒸馏来提高效率。为了减轻曝光偏差,Self-Forcing 182 及其衍生方法(例如 LongLive 183、Self-Forcing++ 106 和 Rolling Forcing 107)使用自生成内容或扩展上下文来训练模型,而 Resampling Forcing 184 则通过在退化上下文上训练来模拟推理时的错误,从而提供一种无需教师的替代方案。摘要。这些方法的核心在于将因果注意掩码集成到基于扩散的框架中,并采用多样化的噪声水平调度来强制执行严格的时间依赖性。通过各种强制策略模拟推理时间挑战(例如误差累积和曝光偏差),这些方法有效地缓解了训练与推理之间的差异,从而确保在长时程时间展开过程中保持稳健的物理一致性和逻辑合理性。
因果知识集成
为了增强视频模型的因果推理能力,一个重要的研究方向是因果知识集成。该范式将高层动态和规划委托给大型多模态模型(LMM),同时主要将视频模型用作高保真"渲染器"。在这些解耦的顺序框架中,诸如 Owl-1 121 和 VLIPP 125 之类的模型利用VLM作为运动规划器------通常通过链式推理------来确保物理上的合理性,然后再由视频模型生成最终像素。这种"导演式"方法在 VIDEODIRECTORGPT 122、LVD 124 和 DirectorLLM 123 中得到了进一步体现,它们采用诸如 GPT-4 或微调后的 Llama 3 之类的LLM来执行复杂的时空规划、结构化布局生成或人体姿态模拟,从而减轻视觉生成器的因果推理负担。
超越简单的顺序执行,更高级的框架通过基于梯度的优化或统一的系统指导引入更紧密的集成。例如,CSVC 126 使用基于 VLM 的文本梯度迭代优化文本提示,以生成因果一致的反事实;而 UniVideo 127 利用 MLLM 指导多模态 DiT (MMDiT) 在统一的流程中进行理解和生成。类似地,SemanticGen 185 通过将过程解耦为高级语义规划和低级细节细化阶段来保持长期一致性。最终,最复杂的实现实现了深度架构耦合,如 BAGEL 128 所示。BAGEL 采用具有共享自注意机制的无瓶颈混合 Transformer-Experts 架构,将多模态理解和生成统一在一个系统中,通过规划和仿真的整体融合,使涌现的世界建模能力和复杂推理得以蓬勃发展。
评估从视频生成到世界模拟的飞跃需要不同的基准。传统指标(例如,IS、FVD)主要量化被动观看下短片段的感知真实感,但一个可用的世界模型必须:(i) 生成高质量的观测结果;(ii) 在较长的时间跨度内保持持久状态;(iii) 遵循因果/物理结构------尤其是在干预的情况下。
围绕三个核心维度进行评估:质量(帧级保真度、短程时间一致性和条件对齐)、持久性(长期一致性、重访性和记忆依赖性连续性)以及因果性(时间推理、反事实响应和动作一致性动态)。
质量
评估视频模型的生成质量需要一种多方面的方法,这种方法超越简单的逐帧真实感,涵盖视觉保真度、时间动态和语义对齐。传统的指标,例如 Inception Score (IS) 和 Fre ́chet Inception Distance (FID),用于衡量单个帧的真实性,而 Fre ́chet Video Distance (FVD) 186 则将其扩展到短片段,以捕捉基本的时空一致性。然而,由于这些指标通常会忽略较长序列中细微的时间误差或漂移,研究人员利用 Fre ́chet Video Motion Distance (FVMD) 187 等专门的指标来惩罚不自然的运动,并利用基于光流的指标来确保帧间平滑度。为了统一这些维度,像 VBench 59 这样的综合测试套件将质量分层分解为运动平滑度、主体身份和空间关系等特定方面,并使用预训练模型自动对每个方面进行评分。VBench++ 60 进一步扩展了这一框架,涵盖了更广泛的生成任务,并在严格的文本对齐评估之外引入了可信度维度。文本对齐尤为关键;现代基准测试工具,例如 WorldModelBench 30,超越了简单的 CLIP 相似性检查,加入了指令执行测试,确保模型不仅能生成逼真的画面,还能严格遵守输入提示中定义的语义约束和叙事细节。
持久性
世界模拟器的一个关键特征是持久性:即在较长时间内保持内部状态一致性的能力。主要通过两个方面来评估这种能力:长期一致性和特定记忆容量任务。
长期一致性
这一方面评估模型在生成周期增加时的稳定性,确保模拟不会随着时间的推移而崩溃、发散或漂移。由于诸如 FVD 之类的标准指标通常是在短窗口内计算的,无法捕捉长期劣化,研究人员采用诸如 VBench-long 60 之类的协议(VBench 的扩展,专为更长的视频设计)来监测数百帧内"主体外观变化"和"背景连续性"的趋势。对 StreamingT2V 161 和 SANA-Video 99 等架构的研究强调了这种评估的必要性,表明虽然简单的模型通常在大约 600 帧后就会出现质量下降或身份转换,但专门构建的持久性架构可以在长达一分钟(约 1800 帧以上)的序列中保持具有竞争力的 FVD 和一致的场景元素。
记忆容量任务
除了保持视觉一致性之外,持久性还要求模型"记住"特定的状态、因果逻辑和空间布局,这需要通过不同的记忆任务进行评估。世界一致性评分 (WCS) 61 提供一种整体性的、无需参考的指标,用于检查生成的"世界"的内部逻辑完整性,具体而言,它监控对象持久性、关系稳定性以及因果一致性,以确保实体不会消失或行为异常。为了测试特定的环境记忆,场景重访测试 93 要求摄像机返回到之前的位置;性能使用重建 FID (rFID) 62 进行量化,其中低分表明模型有效地检索了正确的潜在状态,而不是凭空产生新的细节。最后,持久性通过诸如记忆迷宫 63 或 VR-Bench 188 中的基准测试等功能性导航任务进行压力测试,在这些任务中,模型必须生成穿越复杂环境且无冗余循环的路径,以展示能够指导未来帧生成的隐式空间记忆。
因果性
评估的第三个关键维度是因果性:生成模型在多大程度上内化并遵循模拟环境的物理定律和逻辑进程。一个稳健的世界模型必须超越单纯的视觉合理性,以满足支配现实世界事件的因果约束。这些评估分为三个递进的层次:推理、干预和规划。
时间推理和物理有效性
正确处理事件顺序和物理交互是理解因果关系的基础。ChronoMagic-Bench 65 通过关注需要严格单调顺序的转换(例如生物衰老或物体制造)来评估长程时间推理能力。模型会因语义混乱而受到惩罚------例如,将一棵完全成熟的树还原成幼苗。诸如变形进程评分和时间一致性评分等指标量化了这些时间轨迹的真实性。高分表明对"时间之箭"的隐式表征,从而将因果模拟与时间无关的视频生成区分开来。
同时,物理一致性通过诸如 Physics-IQ 测试套件 64 等基准测试进行评估。该协议使用包含确定性物理事件(例如碰撞、流体动力学、重力)的短视频提示来训练模型,并将生成的展开结果与真实情况进行比较。准确性通过四个互补指标来衡量:空间 IoU(动作定位)、时空 IoU(时间和位置精度)、加权空间 IoU(运动幅度)和像素级均方误差 (MSE)。这些指标被汇总为归一化的 Physics-IQ 分数,其中 100% 表示完美的物理变异复制。当前最先进的模型得分低至 24%,凸显了表面视觉真实感与底层物理动力学建模之间存在显著差距。
干预与评估
对因果建模的严格检验在于其对干预的响应:即在初始条件或动作改变时,能否生成连贯一致的展开结果。系统性测试包括生成在特定控制点(例如,物体被推动与保持静止)处出现分歧的孪生序列。一个有效的世界模型必须为每次干预产生不同的、逻辑一致的结果,且不会在不相关的场景元素中引入伪影。
为了形式化这一点,World-in-World 66 引入一个统一的智体在环评估平台。与被动的开环基准测试不同,该框架将视频生成器与具身智体耦合在一起。世界模型充当模拟器,通过生成新的帧来响应智体的动作。主要评价指标从视觉保真度转变为在导航和操作场景中的任务成功率。结果表明,视觉质量并不能保证功能效用;具有更高一致性和可预测性的模型通常能够带来更高的任务成功率。这凸显了"以干预为中心"的评估的必要性,在这种评估中,模型的价值由其作为交互式环境的可靠性来定义。
规划与具身任务表现
世界模型的最终验证在于其在规划和决策中的效用。该领域的评估借鉴机器人学,衡量在生成的世界中运行的策略的性能。关键指标包括成功率 (SR)。此外,归一化遗憾值将生成模型中的智体性能与真实模拟器中的预言策略进行比较,量化由模型不准确导致的性能下降。
为了诊断故障根源,研究人员测量可控性:即在相同的动作序列下,模型预测的动力学与真实世界物理规律的一致性。形式上,对于动作序列 a_1:T,可控性得分 Ctrl(a_1:T) 定义如下。最后,近期研究探索视频生成模型中涌现的规划能力。例如,VideoWorld 32 证明,大规模视频预训练使得模型能够作为复杂任务的规划器,例如 CALVIN 67 和 RLBench 68 中的围棋或机器人操作,而无需显式的强化学习。这些面向决策的基准测试的成功表明,足够先进的生成模型能够有效地内化环境的因果结构,使其不仅能够作为渲染器,还能作为可操作的世界模型。