1 cgroup子系统
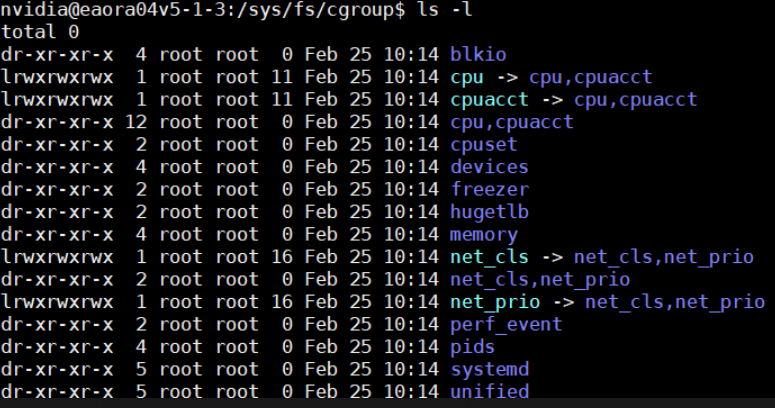
这是 cgroup v1 的子系统目录,每个目录对应一个资源控制器,用于对进程组进行资源限制、统计和隔离。下面逐一说明它们的作用:
🔧 核心子系统详解
| 子系统 | 作用 | 典型用途 |
|---|---|---|
| blkio | 块设备 I/O 限制,控制对硬盘、SSD 等块设备的读写带宽和 IOPS | 防止某个进程耗尽磁盘 I/O,影响其他服务 |
| cpu | CPU 时间分配,通过权重或硬配额控制进程的 CPU 使用 | 保证关键服务的 CPU 资源,限制后台任务的占用 |
| cpuacct | CPU 使用统计,记录 cgroup 内进程的 CPU 消耗 | 用于监控和计费,分析服务的 CPU 使用情况 |
| cpuset | CPU 和内存节点绑定,将进程绑定到特定的 CPU 核心和 NUMA 节点 | 提升多核/多 NUMA 场景下的性能,减少缓存失效 |
| devices | 设备访问控制,通过白名单/黑名单限制进程对设备节点的访问 | 增强安全性,防止容器或进程访问敏感设备 |
| freezer | 冻结/解冻 cgroup,暂停或恢复组内所有进程 | 用于容器的 checkpoint/restore,或系统维护时暂停服务 |
| hugetlb | 大页内存限制,控制进程使用的大页(HugeTLB)数量 | 保证数据库等对大页有强依赖的应用的资源 |
| memory | 内存资源限制,控制内存、swap 使用和 OOM 行为 | 防止内存泄漏的进程拖垮整个系统,实现内存隔离 |
| net_cls | 网络流量分类,给 cgroup 内的数据包打上标签,供 tc 等工具识别 | 实现网络带宽控制和 QoS 策略 |
| net_prio | 网络优先级,设置 cgroup 内流量的优先级 | 优先保证关键业务的网络数据包传输 |
| perf_event | 性能事件监控,允许 perf 工具对 cgroup 内进程进行性能分析 | 对特定服务或容器进行细粒度的性能调优 |
| pids | 进程数限制,控制 cgroup 内可创建的最大进程/线程数 | 防止 fork bomb 攻击,限制服务的并发规模 |
| systemd | systemd 专用控制器,用于管理系统服务的资源和生命周期 | 与 systemd 集成,实现服务的资源管理和依赖控制 |
| unified | cgroup v2 的挂载点,代表新一代统一的 cgroup 架构 | 用于迁移到 cgroup v2,提供更简洁、一致的资源管理接口 |
💡 补充说明
- 图中的
cpu -> cpu,cpuacct、net_cls -> net_cls,net_prio等符号链接,是因为在 cgroup v1 中,这些子系统经常被挂载在同一个层级下,方便统一管理。 - 这些子系统是 Linux 容器技术(如 Docker、Kubernetes) 的核心基础,通过它们实现了容器之间的资源隔离和限制。
- 现在主流 Linux 发行版正逐步从 cgroup v1 迁移到 cgroup v2(unified),后者提供了更统一、更强大的资源管理能力。
2 blkio
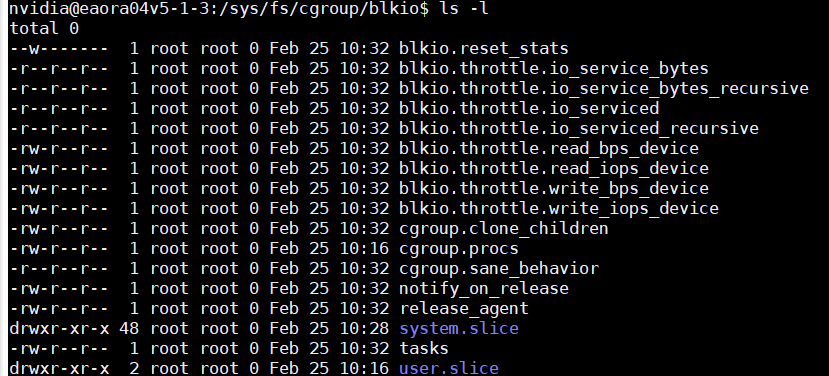
这张图片展示的是 cgroup v1 中 blkio(块设备 I/O)子系统 的控制文件和子目录,主要用于对进程组的块设备 I/O 进行限制和统计。下面为你详细解读:
(1) 核心控制文件作用
| 文件 | 权限 | 作用 |
|---|---|---|
blkio.reset_stats |
-w------- |
重置当前 cgroup 的所有 I/O 统计数据,需要 root 权限写入。 |
blkio.throttle.io_service_bytes |
-r--r--r-- |
记录按设备统计的 I/O 服务字节数(读/写总量)。 |
blkio.throttle.io_service_bytes_recursive |
-r--r--r-- |
递归统计当前 cgroup 及其所有子 cgroup 的 I/O 服务字节数。 |
blkio.throttle.io_serviced |
-r--r--r-- |
记录按设备统计的 I/O 操作次数(读/写次数)。 |
blkio.throttle.io_serviced_recursive |
-r--r--r-- |
递归统计当前 cgroup 及其所有子 cgroup 的 I/O 操作次数。 |
blkio.throttle.read_bps_device |
-rw-r--r-- |
用于设置每个块设备的读带宽限制(bytes per second),写入格式为 major:minor limit_bytes。 |
blkio.throttle.read_iops_device |
-rw-r--r-- |
用于设置每个块设备的读 IOPS 限制(operations per second)。 |
blkio.throttle.write_bps_device |
-rw-r--r-- |
用于设置每个块设备的写带宽限制。 |
blkio.throttle.write_iops_device |
-rw-r--r-- |
用于设置每个块设备的写 IOPS 限制。 |
cgroup.clone_children |
-r--r--r-- |
控制子 cgroup 是否继承父 cgroup 的配置。 |
cgroup.procs |
-r--r--r-- |
列出当前 cgroup 中所有进程的 PID。 |
cgroup.sane_behavior |
-r--r--r-- |
启用 cgroup 的"合理行为"模式,修复一些历史遗留的不一致行为。 |
notify_on_release |
-r--r--r-- |
当 cgroup 变为空时,是否触发 release_agent。 |
release_agent |
-rw-r--r-- |
指定当 cgroup 为空时执行的脚本路径。 |
tasks |
-r--r--r-- |
列出当前 cgroup 中所有线程的 TID。 |
(2) 子目录说明
system.slice:这是 systemd 管理系统服务的 cgroup 子目录,所有系统服务(如systemd-*、sshd等)的 I/O 限制和统计都在这里。user.slice:这是 systemd 管理用户会话的 cgroup 子目录,所有用户进程(如你的 shell、桌面应用等)的 I/O 限制和统计都在这里。
(3) 典型使用场景
-
限制某个服务的磁盘 I/O
例如,限制
nginx服务对/dev/sda的读带宽为 10MB/s:bash# 找到 nginx 所在的 cgroup systemctl show -p ControlGroup nginx # 进入该 cgroup 目录并写入限制 echo "8:0 10485760" > /sys/fs/cgroup/blkio/system.slice/nginx.service/blkio.throttle.read_bps_device -
监控 I/O 使用情况
查看
user.slice中所有用户进程的 I/O 统计:bashcat /sys/fs/cgroup/blkio/user.slice/blkio.throttle.io_service_bytes
3 cpu (含实践)
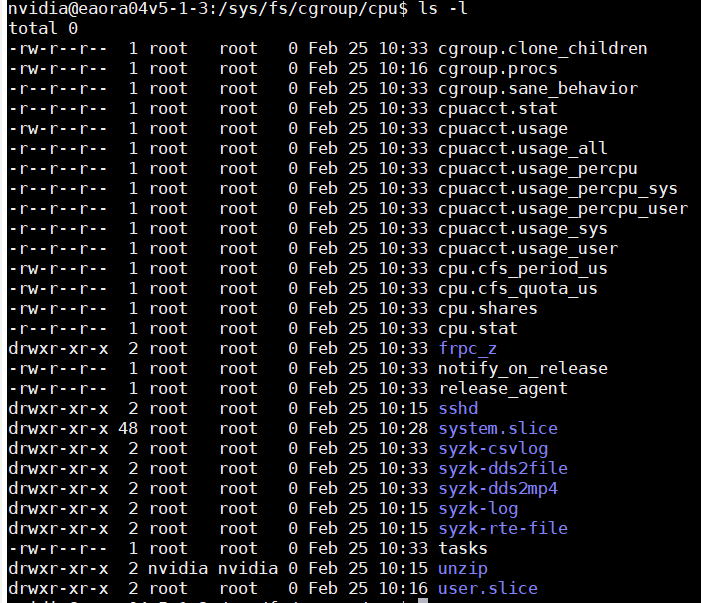
这张图片展示了 cgroup v1 中 cpu,cpuacct 联合子系统 的根目录结构。该目录是 Linux 系统中最核心的 CPU 资源管理入口,结合了 CPU 调度控制(cpu) 和 CPU 使用率统计(cpuacct) 两大功能。
从截图中可以清晰看到系统采用 systemd 统一管理 结合 自定义进程隔离 的模式。以下是结构化的深度解读:
(1) 核心功能文件分类解读
这些文件分为 控制类 (设置限制)和 统计类(查看消耗),是调试 CPU 瓶颈的关键。
| 类别 | 关键文件 | 核心作用 | 运维场景 |
|---|---|---|---|
| CPU 限制 (CFS) | cpu.cfs_period_us cpu.cfs_quota_us |
核心限流机制 。 period:调度周期(默认100ms)。 quota:周期内允许运行的时间。 例:quota=-1 表示无限制。 |
限制进程最大 CPU 使用率。 如限制为 1 核:quota=100000。 |
| CPU 权重 | cpu.shares |
相对竞争机制 。 默认值 1024。值越大,竞争到的 CPU 时间越多。 | 保证核心服务(如 sshd)在高负载下优先获得 CPU。 |
| 统计核心 | cpuacct.stat cpuacct.usage |
全量统计 。 stat:区分用户态/内核态时间。 usage:总消耗时间(纳秒)。 |
精准核算进程的 CPU 成本,用于计费或性能分析。 |
| 精细化统计 | usage_percpu* usage_all |
拓扑级统计 。 按每个 CPU 核心统计消耗。 | 排查 CPU 核心绑定 或 负载不均衡 问题。 |
| 进程管理 | cgroup.procs tasks |
归属控制 。 写入 PID/TID 可将进程移入该 cgroup。 | 手动将失控进程加入限制组,快速降载。 |
(2) 目录结构与系统状态分析
截图中的目录揭示了当前系统的 cgroup 管理架构:
-
Systemd 标准切片(Slice)
system.slice:系统服务(如sshd),权限为root。user.slice:用户会话,截图中出现了unzip子目录,权限为nvidia:nvidia,说明当前有用户正在执行解压操作,且被 systemd 自动纳入了资源管理。
-
自定义/应用级 cgroup
sshd、frpc_z:独立的 cgroup 目录。这表明系统可能除了 systemd 外,还有其他管理工具(如容器运行时或自定义脚本)手动创建了 cgroup,用于单独限制特定服务。syzk-*系列目录:疑似为 Syzkaller(内核模糊测试工具)的相关进程组,通常用于内核开发或安全测试场景。
(3) 关键操作与故障排查示例
基于此目录,针对 C++ 后端开发或运维常见的 CPU 问题,提供直接可执行的操作:
1. 紧急限制 CPU 占用率(如某个进程跑满 100%)
假设需限制 unzip 进程(PID 12345)使用不超过 50% 的 CPU 核心:
bash
# 进入目标 cgroup(以 unzip 为例)
cd /sys/fs/cgroup/cpu/user.slice/unzip
# 设置限制:周期 100ms 内,最多运行 50ms
echo 50000 > cpu.cfs_quota_us
echo 100000 > cpu.cfs_period_us
# 将进程移入该组
echo 12345 > cgroup.procs2. 查看某进程的用户态/内核态耗时
bash
# 查看 cpuacct.stat,区分 sys 和 user 时间
cat /sys/fs/cgroup/cpu/user.slice/unzip/cpuacct.stat- 现象 :
sys时间过高 → 可能存在频繁的系统调用(如网络/磁盘 I/O 密集)。 - 现象 :
user时间过高 → 可能存在算法效率问题(如死循环、大量计算)。
3. 检查 CPU 核心负载均衡
bash
# 查看进程在每个核心上的消耗
cat /sys/fs/cgroup/cpu/cpuacct.usage_percpu- 若某几个核心数值极高,而其他为 0,说明存在 线程绑定 或 亲和性(affinity) 设置不当。
(4) 安全与迁移提示
- 权限注意 :截图中
unzip目录归属于nvidia:nvidia,普通用户可修改自己 cgroup 内的限制,但无法修改system.slice等系统目录,这是正常的安全隔离。 - v2 迁移影响 :在 cgroup v2 中,
cpu.cfs_quota_us等文件将被替换为cpu.max,统计功能也会合并。若未来迁移,需注意配置文件的写法变化。
(5) system.slice / user.slice
system.slice 和 user.slice 是 systemd 资源管理(cgroup) 架构中的两个核心顶层切片(Slice),它们将系统进程划分为两大阵营,实现了清晰的资源隔离和优先级管理。
a. system.slice:系统服务的大本营
核心作用:
- 管理所有由 systemd 启动的系统服务 (System Services),例如
sshd、nginx、docker、systemd-journald等后台守护进程。 - 这些服务通常由
root用户运行,是维持操作系统核心功能的基础。
典型子目录:
- 每个
.service文件(如sshd.service)都会在system.slice下创建一个对应的子目录,用于隔离和限制该服务的资源。 - 例如:
system.slice/sshd.service、system.slice/docker.service。
资源管理特点:
- 默认拥有较高的资源优先级,以保证系统核心服务的稳定运行。
- 管理员可以通过修改其 cgroup 配置(如 CPU 权重、内存限制),防止某个服务耗尽系统资源,影响其他服务。
b. user.slice:用户会话的容器
核心作用:
- 管理所有用户会话 (User Sessions)相关的进程,包括你登录后的 shell(bash/zsh)、桌面环境、以及你手动启动的所有应用程序(如
unzip、firefox、vim)。 - 每个登录的用户(UID)都会在
user.slice下创建一个子目录,例如user-1000.slice(UID 1000),用于隔离不同用户的资源。
典型子目录:
user-<UID>.slice:特定用户的顶层切片。user-<UID>.slice/app.slice:该用户启动的图形应用程序。user-<UID>.slice/background.slice:该用户的后台任务。- 你截图中的
unzip目录,就是当前用户(UID 1001, nvidia)启动的解压任务所归属的 cgroup。
资源管理特点:
- 默认资源优先级通常低于
system.slice,确保在系统高负载时,用户进程不会抢占关键系统服务的资源。 - 可以通过
systemd-logind或loginctl命令管理用户会话,例如终止某个用户的所有进程。
c. 两者的核心区别与意义
| 维度 | system.slice |
user.slice |
|---|---|---|
| 管理对象 | 系统守护进程、后台服务 | 用户登录会话、应用程序 |
| 运行身份 | 通常为 root |
对应用户的 UID(如 nvidia) |
| 优先级 | 默认较高,保障系统稳定 | 默认较低,避免抢占系统资源 |
| 典型应用 | sshd, nginx, docker |
bash, firefox, unzip |
| 故障影响 | 故障可能导致系统瘫痪 | 故障通常只影响当前用户会话 |
d. 实际应用场景
- 资源隔离 :当你在
user.slice中启动一个消耗大量 CPU 的编译任务时,system.slice中的sshd服务依然能获得足够的 CPU 时间,保证你可以远程登录并管理系统。 - 故障排查 :如果系统负载过高,你可以通过查看
system.slice和user.slice下的资源统计,快速定位是哪个服务或哪个用户的进程导致了问题。 - 权限控制 :普通用户可以管理自己
user.slice下的进程和资源限制,但无法修改system.slice中的系统服务配置,这是一种重要的安全隔离机制。
4 cpuset
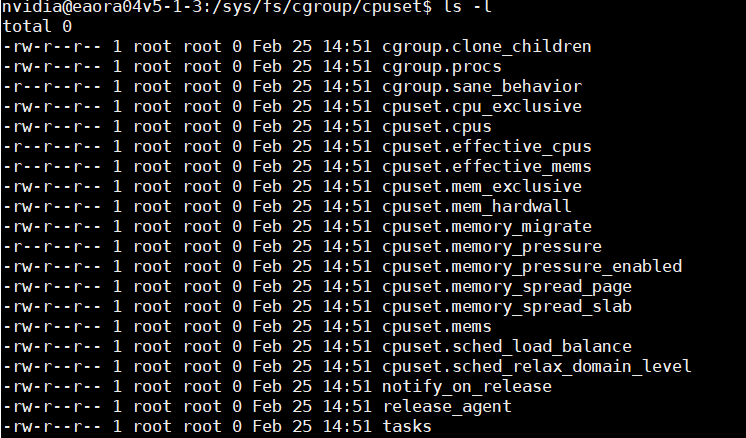
这张图片展示的是 cgroup v1 中 cpuset 子系统 的控制文件,它的核心作用是将进程组绑定到特定的 CPU 核心和内存节点(NUMA 节点),从而实现 CPU 亲和性和内存本地化,提升性能。
(1) 核心控制文件作用
| 文件 | 权限 | 核心作用 |
|---|---|---|
cpuset.cpus |
-rw-r--r-- |
指定该 cgroup 内进程可以使用的 CPU 核心列表(如 0-3,5)。 |
cpuset.effective_cpus |
-r--r--r-- |
实际生效的 CPU 核心列表(受父 cgroup 限制)。 |
cpuset.mems |
-rw-r--r-- |
指定该 cgroup 内进程可以使用的 NUMA 内存节点列表(如 0-1)。 |
cpuset.effective_mems |
-r--r--r-- |
实际生效的内存节点列表(受父 cgroup 限制)。 |
cpuset.cpu_exclusive |
-rw-r--r-- |
是否独占 CPU 核心(设为 1 时,其他 cgroup 不能使用这些核心)。 |
cpuset.mem_exclusive |
-rw-r--r-- |
是否独占内存节点(设为 1 时,其他 cgroup 不能使用这些节点)。 |
cpuset.mem_hardwall |
-rw-r--r-- |
强制内存分配限制在指定的 mems 内,不允许跨节点分配。 |
cpuset.memory_migrate |
-rw-r--r-- |
当 cpuset.mems 改变时,是否自动迁移进程的内存页到新节点。 |
cpuset.memory_pressure |
-r--r--r-- |
报告该 cgroup 内进程的内存压力值,用于监控。 |
cpuset.memory_pressure_enabled |
-rw-r--r-- |
是否启用内存压力统计。 |
cpuset.memory_spread_page |
-rw-r--r-- |
是否将进程的页缓存分散到所有指定的内存节点。 |
cpuset.memory_spread_slab |
-rw-r--r-- |
是否将内核 slab 对象分散到所有指定的内存节点。 |
cpuset.sched_load_balance |
-rw-r--r-- |
是否在指定的 CPU 核心之间进行负载均衡。 |
cpuset.sched_relax_domain_level |
-rw-r--r-- |
控制调度器的负载均衡域范围,影响性能和开销。 |
cgroup.procs / tasks |
-r--r--r-- |
列出/添加该 cgroup 内的进程 PID 或线程 TID。 |
(2) 典型使用场景
-
高性能计算(HPC)/ 数据库优化
将数据库进程绑定到特定的 CPU 核心和本地 NUMA 节点,避免跨节点内存访问带来的延迟:
bash# 进入目标 cgroup cd /sys/fs/cgroup/cpuset/mysql # 绑定到 CPU 0-3 和 NUMA 节点 0 echo "0-3" > cpuset.cpus echo "0" > cpuset.mems # 将 mysqld 进程(PID 1234)加入该组 echo 1234 > cgroup.procs -
实时系统 / 低延迟应用
独占 CPU 核心,避免其他进程干扰:
bash# 启用 CPU 独占模式 echo 1 > cpuset.cpu_exclusive # 绑定到 CPU 4 echo "4" > cpuset.cpus -
NUMA 架构下的性能调优
通过
cpuset.memory_migrate确保进程内存始终在本地节点,减少远程访问开销。
(3) 与其他 cgroup 子系统的关系
cpuset是基础 :它定义了进程的 CPU 和内存拓扑,其他子系统(如cpu、memory)的限制都在这个拓扑范围内生效。- 优先级 :如果一个进程同时被
cpu子系统限制了 CPU 使用率,又被cpuset绑定到特定核心,那么它只会在这些核心上消耗被分配的 CPU 时间。
5 memory
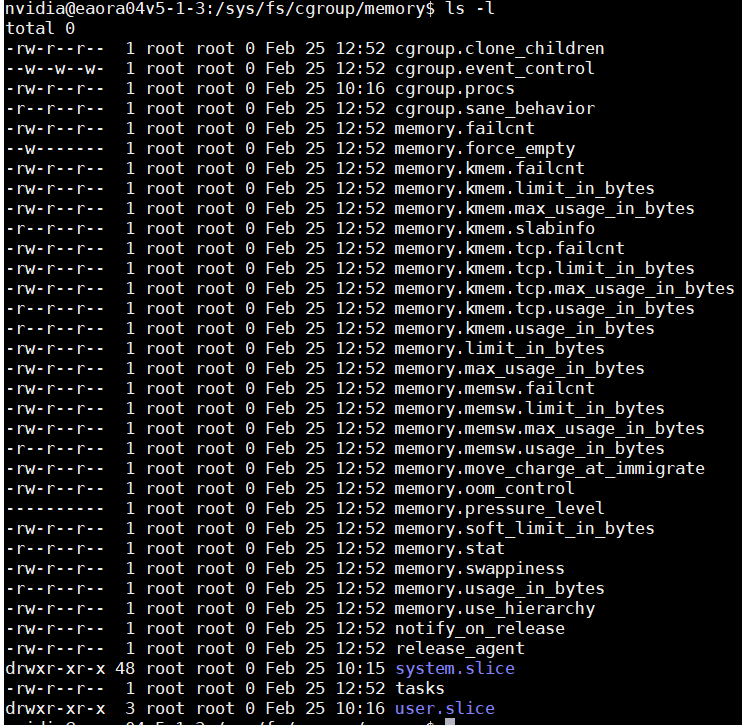
这张图片展示的是 cgroup v1 中 memory 子系统 的控制文件,它是 Linux 系统中实现内存隔离和限制的核心组件,广泛应用于容器化和服务资源管理场景。
(1) 核心功能文件分类解读
1. 内存限制类
| 文件 | 权限 | 核心作用 |
|---|---|---|
memory.limit_in_bytes |
-rw-r--r-- |
设置该 cgroup 内所有进程的最大内存使用量(包含用户态和内核态内存)。 |
memory.soft_limit_in_bytes |
-rw-r--r-- |
设置内存软限制。当系统内存充足时不生效,内存紧张时优先回收超出软限制的内存。 |
memory.memsw.limit_in_bytes |
-rw-r--r-- |
设置内存+交换分区的总使用上限。 |
memory.kmem.limit_in_bytes |
-rw-r--r-- |
限制内核态内存(如 slab、task_struct)的使用。 |
memory.kmem.tcp.limit_in_bytes |
-rw-r--r-- |
专门限制 TCP 协议栈使用的内核内存。 |
2. 统计与监控类
| 文件 | 权限 | 核心作用 |
|---|---|---|
memory.usage_in_bytes |
-r--r--r-- |
当前 cgroup 已使用的内存总量。 |
memory.max_usage_in_bytes |
-r--r--r-- |
历史最高内存使用量,用于评估峰值负载。 |
memory.kmem.usage_in_bytes |
-r--r--r-- |
当前内核态内存使用量。 |
memory.memsw.usage_in_bytes |
-r--r--r-- |
当前内存+交换分区的使用总量。 |
memory.stat |
-r--r--r-- |
详细内存统计,包含缓存、匿名页、页缓存、换入换出等细分项。 |
memory.pressure_level |
-r--r--r-- |
监控内存压力事件(low/medium/critical),用于触发用户态应对策略。 |
3. 行为控制类
| 文件 | 权限 | 核心作用 |
|---|---|---|
memory.failcnt |
-r--r--r-- |
记录内存分配失败的次数,可用于判断是否达到了内存限制。 |
memory.kmem.failcnt / memory.memsw.failcnt |
-r--r--r-- |
分别记录内核内存和内存+交换分区的分配失败次数。 |
memory.force_empty |
-w------- |
触发强制回收该 cgroup 的所有可回收内存(需 root 权限)。 |
memory.oom_control |
-rw-r--r-- |
控制 OOM(内存溢出)行为。可设置是否触发 OOM Killer,或通知用户态处理。 |
memory.swappiness |
-rw-r--r-- |
控制该 cgroup 内存交换的倾向(0-100),值越大越倾向于换出匿名页。 |
memory.move_charge_at_immigrate |
-rw-r--r-- |
当进程从一个 cgroup 移动到另一个时,是否将其内存 charge 一并转移。 |
memory.use_hierarchy |
-rw-r--r-- |
是否启用层级限制,即子 cgroup 的限制受父 cgroup 限制的约束。 |
4. 进程管理类
| 文件 | 权限 | 核心作用 |
|---|---|---|
cgroup.procs / tasks |
-r--r--r-- |
列出/添加该 cgroup 内的进程 PID 或线程 TID。 |
notify_on_release / release_agent |
-rw-r--r-- |
当 cgroup 变为空时,触发指定脚本。 |
(2) 典型使用场景
-
限制容器/服务的内存上限
例如,限制
nginx服务最多使用 512MB 内存:bash# 进入 nginx 所在的 cgroup cd /sys/fs/cgroup/memory/system.slice/nginx.service # 设置硬限制为 512MB echo 536870912 > memory.limit_in_bytes # 设置内存+交换总限制为 1GB echo 1073741824 > memory.memsw.limit_in_bytes -
监控内存泄漏
通过观察
memory.usage_in_bytes和memory.max_usage_in_bytes的持续增长,判断是否存在内存泄漏:bash# 实时监控内存使用 watch -n1 "cat /sys/fs/cgroup/memory/system.slice/your-app.service/memory.usage_in_bytes" -
OOM 行为控制
当应用达到内存限制时,不直接杀死进程,而是通知用户态进行处理:
bash# 禁用 OOM Killer echo 1 > memory.oom_control # 监听 OOM 事件 while inotifywait -e modify memory.oom_control; do echo "OOM detected! Taking action..." # 执行扩容、重启等操作 done
(3) 目录结构与系统状态
system.slice:系统服务(如sshd、nginx)的内存管理目录,确保关键服务的内存资源。user.slice:用户会话(如unzip、桌面应用)的内存管理目录,防止用户进程耗尽系统内存。
这些目录继承了顶层 memory 子系统的配置,并可以进行更细粒度的资源控制。