作者:来自 Elastic Ugo Sangiorgi 及 Lily Adler

学习如何在一小时内,使用 Elasticsearch Serverless、Jina Embeddings v5、Elastic Open Web Crawler 和 Elastic Agent Builder,构建一个可用且有事实依据的"与你的网站聊天"体验。
Agent Builder 现已正式发布。通过 Elastic Cloud Trial 开始使用,并在此查看 Agent Builder 的文档。
使用 Elasticsearch Serverless、Jina Embeddings v5、Elastic Open Web Crawler 和 Elastic Agent Builder,在一小时内构建一个 "与你的网站聊天" 的体验。
完成后,你将拥有一个可用的 agent,能够搜索你抓取的页面,引用相关段落,并基于你的内容回答问题,无需自定义分块或 embedding 管道。
在本指南中,你将:
- 启动一个 Elasticsearch Serverless 项目
- 使用由 Jina Embeddings v5 驱动的新 semantic_text 字段创建索引
- 使用 Elastic Crawler Control(又名 Crawly)(围绕 Elastic Open Web Crawler 的开源 UI + API 封装)抓取任意网站
- 在 Kibana 中使用 Elastic Agent Builder 与这些数据聊天
你将获得:
- 一个可复用的模式,可指向任意网站或 docs 数据源
- 始终基于你内容的聊天体验
先决条件:
- 一个 Elasticsearch Serverless( Search ) 项目,以及一个具有写权限的 API key
- Docker + Docker Compose(用于运行 crawler UI)
- git(用于克隆 repo)
1)启动一个 Elasticsearch Serverless 项目
首先,我们需要一个 serverless 项目来托管我们的数据。
- 登录你的 Elastic Cloud Console。
- 点击 Create project。
- 选择 Search 作为项目类型。(该类型针对向量搜索和检索进行了优化。)
- 为项目命名(例如 es-labs-jina-guide),然后点击 Create 。
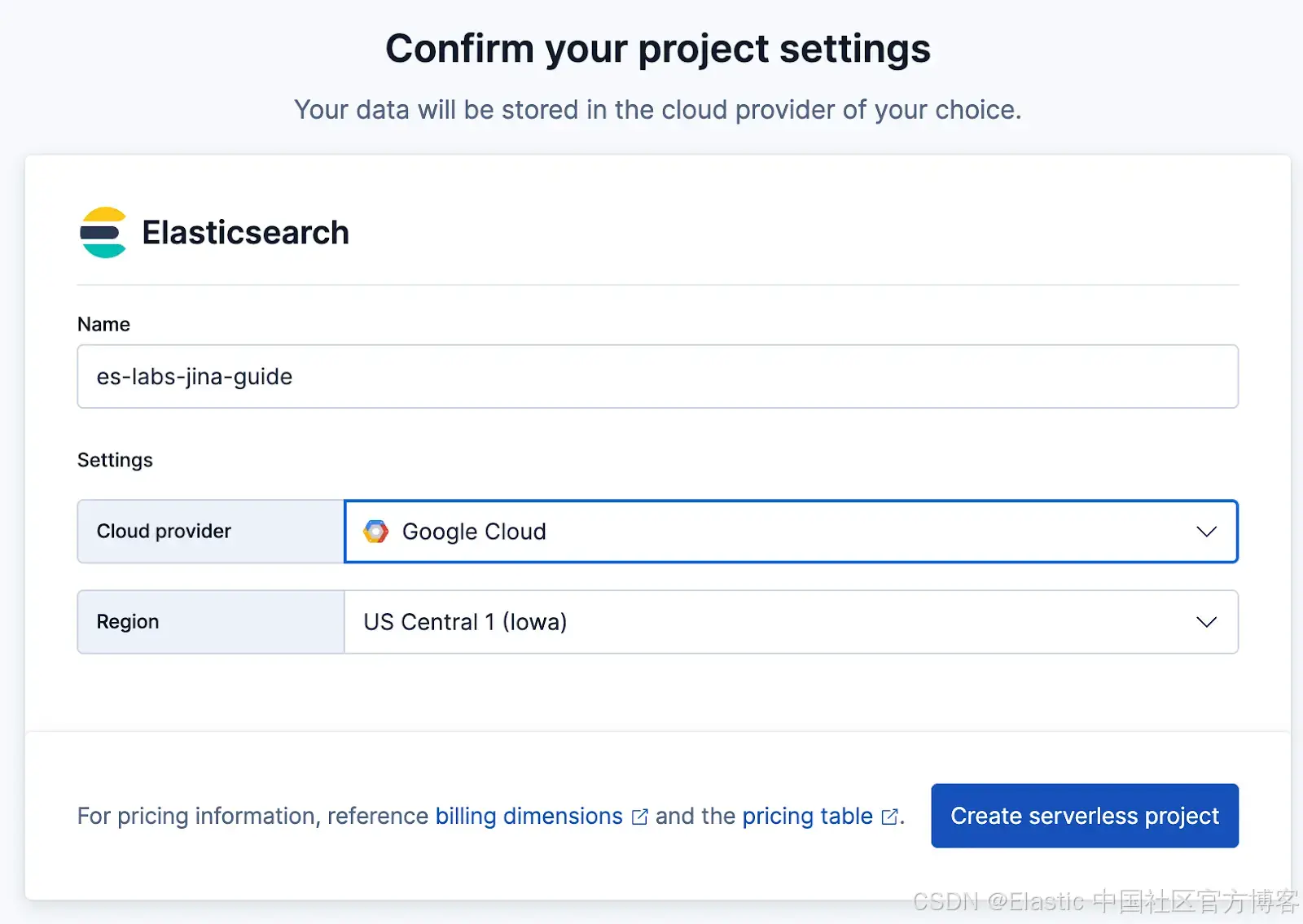
- 重要 :保存项目创建时提供的 Elasticsearch endpoint 和 API Key。你将在 crawler 中用到它们。

2)创建索引
Elasticsearch Serverless 支持 semantic_text,它会自动处理分块和 embedding 生成。我们将使用托管在 Elastic Inference Service GPU 上的 .jina-embeddings-v5-text-small 模型。
使用 semantic_text 字段创建索引。这会告诉 Elastic 使用我们刚刚创建的 inference endpoint,对写入该字段属性的内容自动进行向量化。
在 Kibana Dev tools 中运行:
PUT furnirem-website
{
"mappings": {
"_meta": {
"description": "Each document represents a web page with the following schema: 'title' and 'meta_description' provide high-level summaries; 'body' contains the full text content; 'headings' preserves the page hierarchy for semantic weighting. URL metadata is decomposed into 'url_host', 'url_path', and 'url_path_dir1/2/3' to allow for granular filtering by site section (e.g., 'blog' or 'tutorials'). 'links' contains extracted outbound URLs for discovery. Crawl timestamp: 2026-01-26T12:54:16.347907."
},
"properties": {
"body_content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"semantic_multilingual": {
"type": "semantic_text",
"inference_id": ".jina-embeddings-v5-text-small"
}
}
},
"headings": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"semantic_multilingual": {
"type": "semantic_text",
"inference_id": ".jina-embeddings-v5-text-small"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"semantic_multilingual": {
"type": "semantic_text",
"inference_id": ".jina-embeddings-v5-text-small"
}
}
}
}
}
}3)运行 Elastic Open Crawler
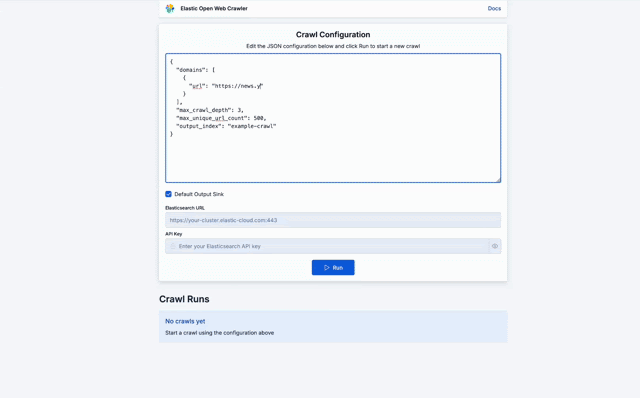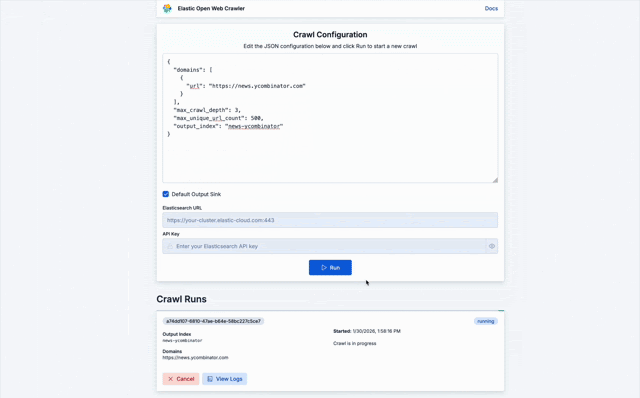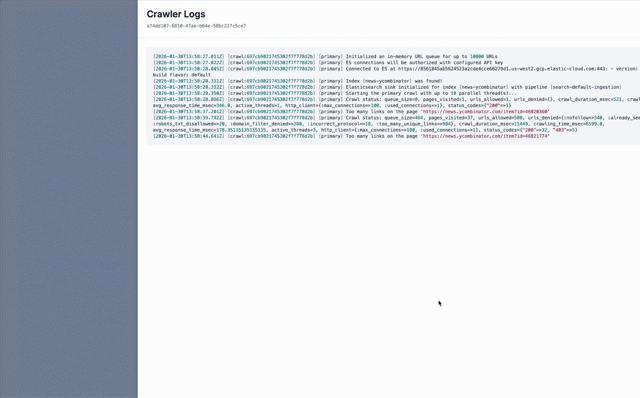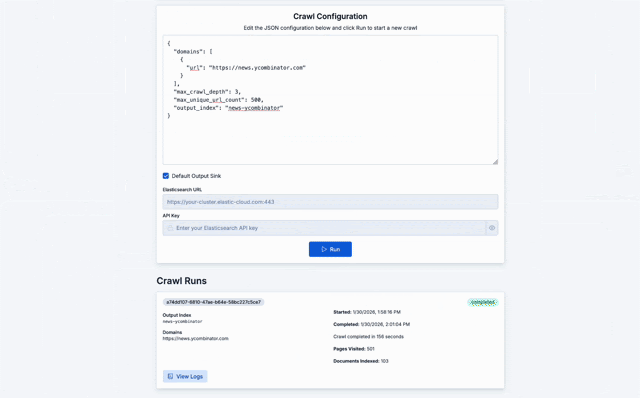
Crawly 是一个示例,展示了如何围绕 Open Web Crawler 提供的功能构建应用。
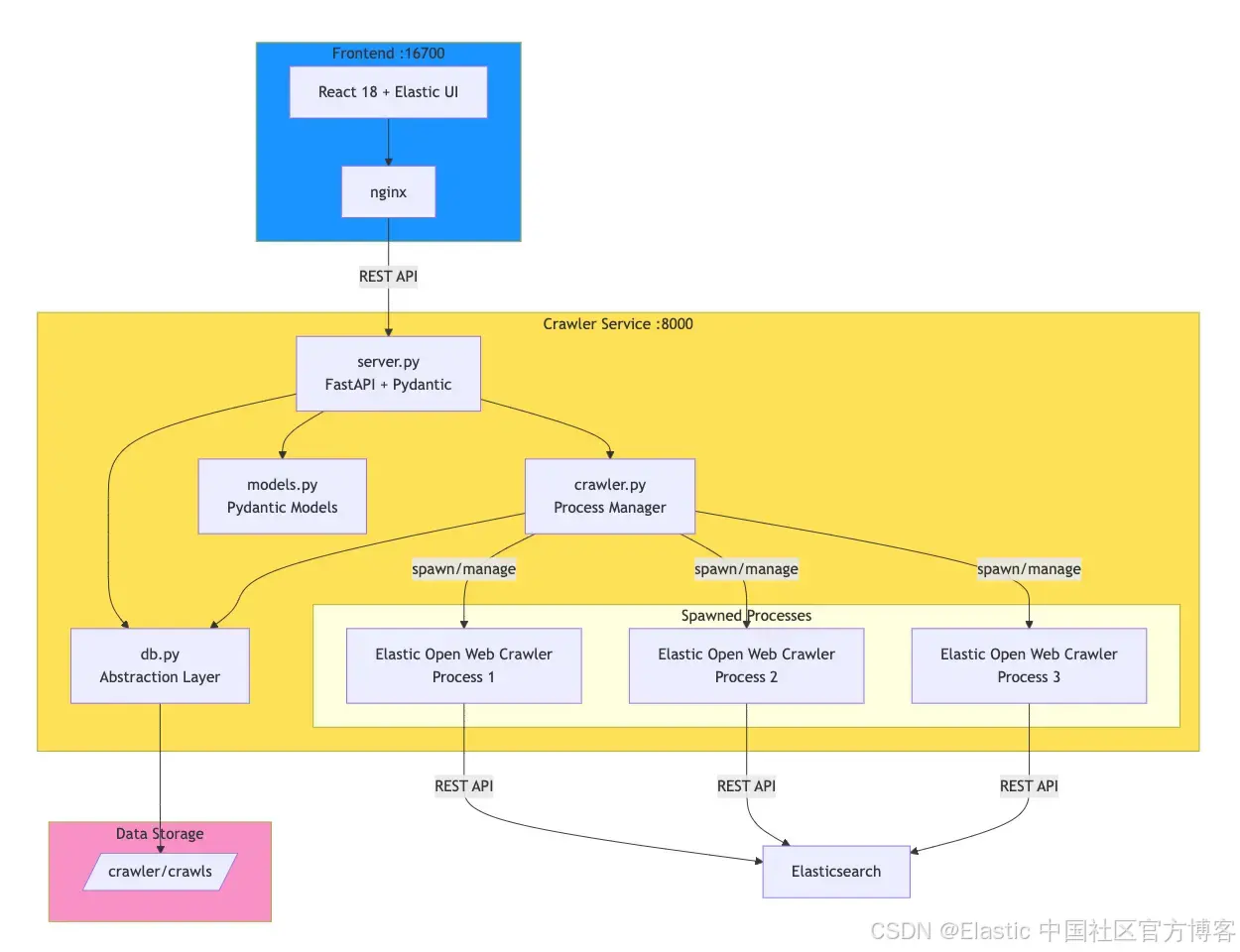
该应用将 Elastic Open Crawler 封装在一个 FastAPI 服务中,用于管理 crawler 进程并持久化执行数据。一个 React 前端提供用于配置和监控 crawl 的界面。
在底层,crawler 服务(查看 crawler.py)通过 subprocess.Popen 生成 JRuby 进程,从而支持多个并发 crawl。每次执行的配置、状态和日志目前都会持久化到磁盘中。
克隆该仓库:
git clone https://github.com/ugosan/elastic-crawler-control创建一个 env.local 文件,并填写你的 Elasticsearch 凭证:
ES_URL=https://your-elasticsearch-endpoint.es.cloud
ES_API_KEY=your_api_key_here启动服务:
docker-compose up在浏览器访问 UI:http://localhost:16700
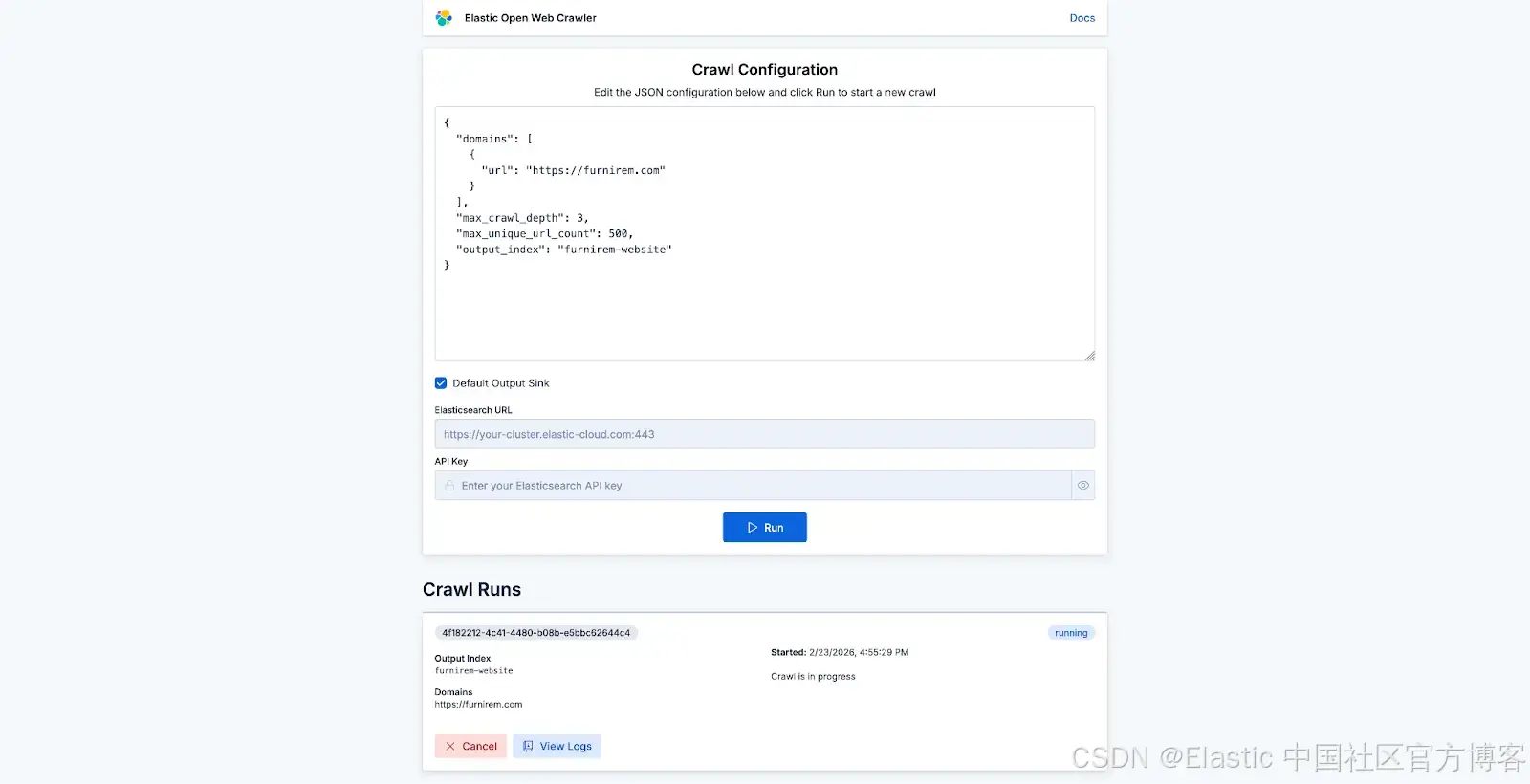
除非你想指定特定 URL,否则不一定需要 seed_urls,因此你的配置可以像下面这样简单:
{
"domains": [
{
"url": "https://furnirem.com"
}
],
"max_crawl_depth": 3,
"max_unique_url_count": 500,
"output_index": "furnirem-website"
}从这里,你可以开始抓取任意网站,并查看其进度:
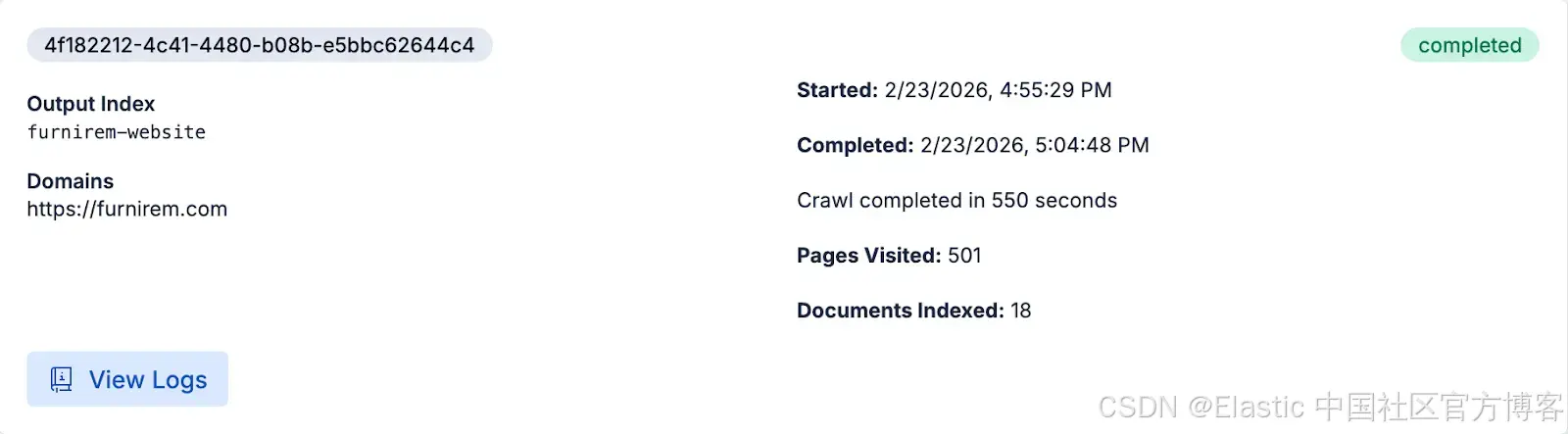
一旦抓取完成,我们就可以直接在 Elasticsearch 中查询内容,或者使用刚抓取的页面在 Agent Builder 上进行网站聊天。
4)在 Kibana 中与数据聊天
现在数据已被索引并向量化,我们可以使用 Elastic Agent Builder 开始与数据聊天。
-
打开 Kibana ,导航到 Agents(在 "Search" 部分下)。
-
测试 agent :
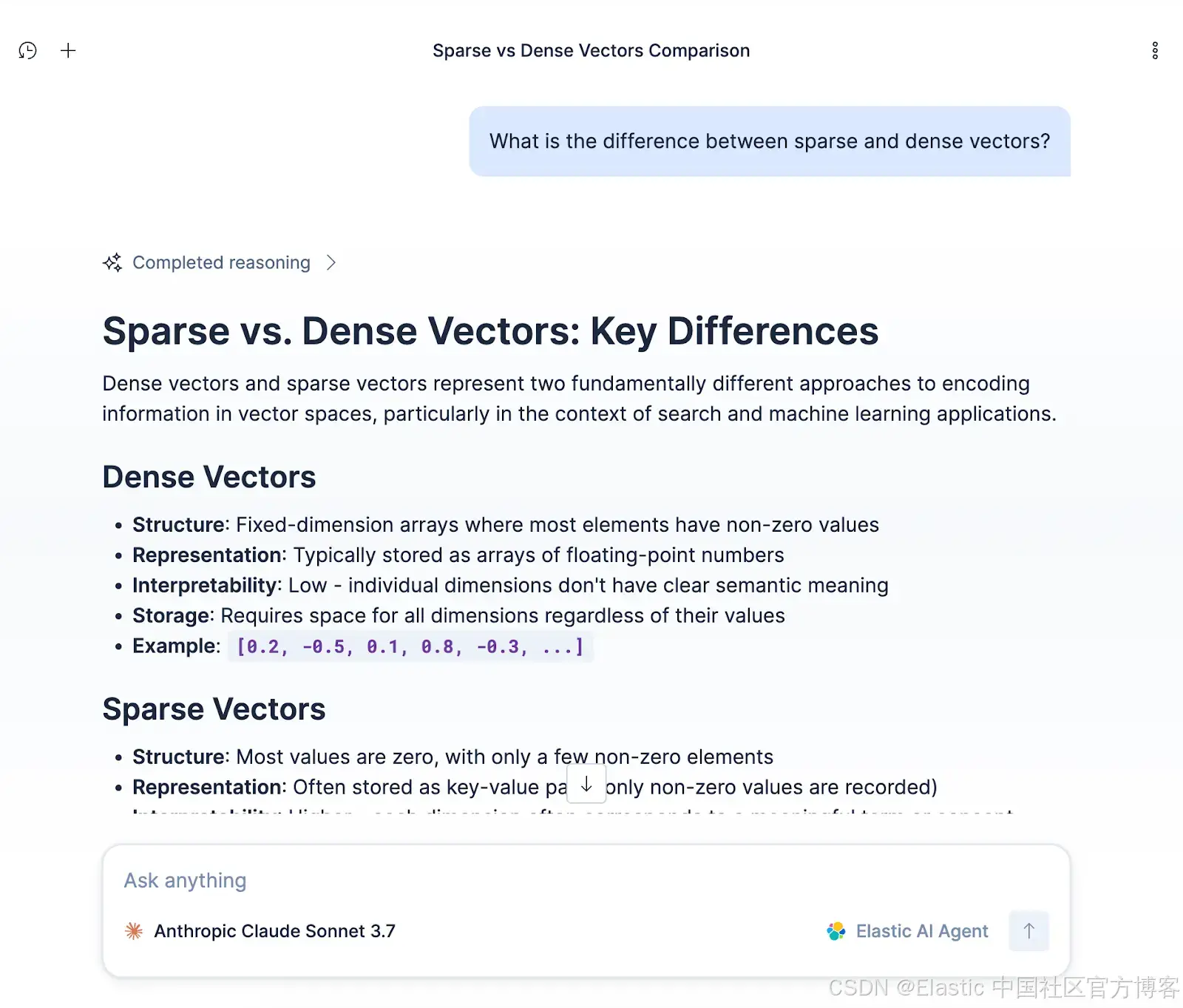
在聊天窗口中提出一个问题,例如,"What is the difference between sparse and dense vectors?"
Agent 将搜索你 Jina 嵌入的数据,从 Search Labs 博客文章中检索相关片段,并生成回答。
你也可以通过 Kibana API 直接与数据聊天:
POST kbn://api/agent_builder/converse/async
{
"input": "What is the difference between sparse and dense vectors?",
"agent_id": "elastic-ai-agent",
"conversation_id": "<CONVERSATION_ID>"
}使用 conversation_id 可以在 Elastic Agent Builder 中与 agent 恢复已有对话。如果在初始请求中未提供,API 会启动一个新对话,并在流式响应中返回一个新生成的 ID。
总结
你现在已经拥有一个可用的 "与你的网站聊天" 堆栈:你的网站被抓取、索引,并通过 semantic_text + Jina v5 自动嵌入,最后通过 Kibana 中的 agent 展示,能够基于页面内容回答问题。
从这里开始,你可以将相同的设置应用于文档、支持内容或内部 wiki,并在几分钟内迭代提升相关性。
原文:https://www.elastic.co/search-labs/blog/chat-website-data-elasticsearch-jina-ai