摘要:随着微服务、云原生技术的快速普及,传统同步调用架构在高并发、高可用、松耦合分布式系统构建中,逐渐暴露出扩展性不足、耦合度高、容错能力弱、链路阻塞等突出问题,已难以满足企业级系统的业务发展需求。事件驱动架构(Event-Driven Architecture,EDA)以事件为核心交互载体,通过"生产者-事件总线-消费者"的异步通信模式,实现服务间的彻底解耦、高效协同,成为构建现代分布式系统的核心架构模式之一。本文结合软考系统架构设计核心考点,系统论述事件驱动架构的核心概念、核心组成要素、本质特点及标准化设计开发过程;并以电商订单微服务项目为实践场景,详细阐述EDA架构在项目中的具体落地方案、实施步骤,深入分析落地过程中遇到的典型技术问题及可落地的解决方案,最后总结EDA架构实施的关键原则与实践经验,为同类系统的架构设计、开发落地及软考相关考点应用提供可复用的思路与参考。
关键词:事件驱动架构;EDA;微服务;消息中间件;分布式系统;最终一致性;架构落地;软考
一、引言
在单体架构时代,系统内部组件通过直接方法调用、接口引用完成业务逻辑流转,虽实现简单、开发效率高,但组件间耦合紧密,一旦某一组件发生变更或故障,极易影响整个系统的正常运行。进入微服务与云原生时代后,企业级系统的服务数量激增、业务链路不断延长、流量波动日益剧烈(如电商大促、峰值并发场景),传统同步REST/RPC调用架构的弊端愈发凸显:一是服务间强依赖,一方故障易引发连锁反应,导致系统雪崩;二是同步阻塞调用导致系统吞吐量低,难以应对高并发场景;三是系统扩展性差,新增业务功能需修改原有服务调用链路,开发维护成本高;四是容错能力弱,单个环节报错会导致整个业务流程回滚,用户体验差。
事件驱动架构(EDA)作为一种异步、松耦合的分布式架构模式,以事件为核心纽带,打破了服务间的直接依赖,通过事件发布与订阅机制实现服务协同,能够有效解决传统同步架构的痛点,具备高可扩展、高可用、高吞吐、强容错的优势,已广泛应用于电商、金融、物流、政务等各类企业级分布式系统中。作为系统架构设计师,熟练掌握EDA的核心概念、设计开发流程及落地实践,解决其实施过程中的关键技术难题,是必备的专业能力,也是软考系统架构设计师考试的核心考点之一。本文结合理论知识与项目实践,全面剖析EDA架构,为架构设计与考试备考提供支撑。
二、事件驱动架构(EDA)的核心概念
事件驱动架构是一种以"事件"为核心,实现系统组件或微服务之间异步、松耦合通信的架构模式,其核心思想是:事件生产者仅负责产生并发布事件,不关心事件的消费方及消费逻辑;事件消费者仅负责订阅感兴趣的事件并执行业务处理,不关心事件的产生来源;事件总线(消息中间件)作为事件的中转载体,负责事件的接收、存储、路由与投递,实现生产者与消费者的彻底解耦。理解EDA的核心概念,是进行架构设计与落地的基础,也是软考高频考点。
2.1 核心组成要素
事件驱动架构的核心组成要素明确,各要素职责清晰、协同工作,共同构成完整的EDA架构体系,具体如下:
-
事件(Event):事件是EDA架构的核心载体,是对系统中某一业务状态变更的客观事实记录,具有不可变性、时间序列性、可追溯性三大核心特性。事件通常源于业务操作中的状态变化,例如电商系统中的"订单创建""支付成功""库存扣减""订单取消",金融系统中的"转账完成""账户余额变更"等。一个标准的事件应包含以下核心字段:事件唯一ID(用于幂等处理与追踪)、事件类型(标识事件的业务含义)、业务主键ID(如订单号、账户ID,关联具体业务对象)、事件发生时间戳(记录事件产生的时间)、业务数据体(存储事件相关的业务详情,如订单金额、支付方式)、事件版本号(用于事件演化与版本兼容)、事件来源服务(标识事件的产生者)。事件一旦发布,不可修改,只能新增,确保其可追溯性。
-
事件生产者(Event Producer):负责产生并发布事件的服务或系统组件,其核心职责是监测业务状态变化,当状态发生变更时,生成对应的事件并发送至事件总线,无需关心事件的消费方是谁、如何消费事件,也无需等待消费方的处理结果。例如,电商系统中的订单服务,当用户完成下单操作、订单状态变为"已创建"时,订单服务就作为事件生产者,生成"OrderCreated"事件并发布至事件总线。
-
事件消费者(Event Consumer):负责订阅并处理事件的服务或系统组件,其核心职责是通过事件总线订阅感兴趣的事件,当接收到事件后,根据事件内容执行业务逻辑处理,无需关心事件的产生来源、产生过程,也无需与事件生产者进行直接交互。一个事件可以被多个消费者订阅,各消费者独立处理事件,互不影响。例如,电商系统中的库存服务、通知服务、积分服务,均可订阅"OrderCreated"事件,分别执行库存扣减、发送下单通知、增加用户积分的业务逻辑。
-
事件总线 / 消息中间件(Event Broker):事件总线是EDA架构的核心中转枢纽,负责连接事件生产者与事件消费者,承担事件的接收、持久化存储、路由、投递、重试等功能,是实现生产者与消费者解耦的关键。常用的事件总线(消息中间件)有Kafka、RocketMQ、RabbitMQ、Redis Stream等,不同中间件的特性不同,需根据业务场景选型(选型逻辑将在后续设计过程中详细阐述)。
-
事件溯源(Event Sourcing):EDA架构的延伸特性,核心思想是不存储业务对象的最终状态,只存储所有导致业务对象状态变更的事件序列,当需要获取业务对象的当前状态时,通过重放事件序列,重新执行所有事件对应的操作,即可恢复业务对象的任意时刻状态。事件溯源能够实现业务状态的全链路追溯,便于问题排查、审计与复盘,适用于对状态追溯要求高的场景(如金融交易系统)。
-
CQRS(Command Query Responsibility Segregation,命令查询责任分离):EDA架构中常用的设计模式,核心是将系统的写操作(命令操作)与读操作(查询操作)分离,分别采用不同的处理模型。写操作(如创建订单、支付订单)触发事件发布,更新业务状态;读操作(如查询订单详情、查询用户积分)则使用独立的查询视图(如只读数据库、缓存),无需参与事件流转,从而提升读操作的性能与扩展性,解决读写冲突问题。
2.2 核心思想
事件驱动架构的核心思想围绕"解耦、异步、可靠、可扩展"展开,是其区别于传统同步架构的关键,也是软考中重点考查的核心考点,具体如下:
-
彻底解耦:生产者与消费者之间通过事件总线间接交互,无直接代码依赖、无接口依赖,生产者无需知道消费者的存在,消费者也无需知道事件的具体来源,只需依赖统一的事件格式。这种解耦方式使得各服务能够独立迭代、独立部署,修改某一服务的逻辑时,不会影响其他服务的正常运行,降低了系统的开发维护成本。
-
异步非阻塞:事件生产者发布事件后,无需等待消费者处理完成,即可立即返回,继续执行后续操作,实现非阻塞调用。这种异步特性能够有效提升系统的吞吐量,避免因某一消费者处理缓慢导致整个业务链路阻塞,尤其适用于高并发、长链路的业务场景。
-
最终一致性:在分布式系统中,由于网络延迟、服务故障等因素,难以实现强一致性(即所有服务同时达到一致状态)。EDA架构采用"最终一致性"模型,允许各服务在短期内处于不一致状态,通过事件重试、补偿机制,确保经过一段时间后,所有服务的状态能够达到一致,兼顾了系统的可用性与分区容错性,符合分布式系统的CAP理论(优先保证可用性与分区容错性)。
-
高可观测性:事件作为业务状态变更的记录,天然具备日志属性,所有事件的产生、发布、投递、处理过程均可被记录与追踪。通过事件日志,能够实现业务链路的全流程追溯,便于问题排查、系统审计与业务复盘,提升系统的可维护性。
-
易于扩展:新增业务功能时,无需修改原有服务的代码与调用链路,只需新增事件消费者,订阅对应的事件并执行业务逻辑即可;同时,当某一消费者处理压力过大时,可通过水平扩容的方式增加消费者实例,提升处理能力,无需改动生产者与事件总线的配置。
三、事件驱动架构的特点
事件驱动架构的特点源于其核心思想,分为优点与缺点两方面,明确其特点能够帮助架构设计师在实际项目中合理选型(判断是否适合采用EDA架构),也是软考中常见的考查内容,需重点掌握。
3.1 核心优点
EDA架构的优点贴合现代分布式系统的需求,能够有效解决传统同步架构的痛点,具体如下:
-
服务解耦彻底,维护成本低:生产者与消费者无直接依赖,各服务独立演进、独立部署,修改某一服务不会影响其他服务,降低了服务间的耦合度,减少了开发维护过程中的冲突与风险,尤其适用于微服务架构场景。
-
高并发、高吞吐,适配峰值场景:异步非阻塞的通信模式,结合事件总线的消息削峰填谷能力,能够有效提升系统的吞吐量与响应速度,避免同步调用中的阻塞问题,可轻松应对电商大促、直播带货等流量突增的场景。
-
容错与隔离性强,系统可用性高:某一事件消费者发生故障时,事件会在事件总线中堆积,不会影响生产者的正常运行,也不会影响其他消费者的事件处理;当故障服务恢复后,可通过事件重试机制继续处理堆积的事件,避免了服务故障的连锁反应,提升了系统的整体可用性。
-
扩展性极强,适配业务迭代:新增业务功能只需新增消费者,无需改动原有业务链路;消费者可根据处理压力水平扩容,生产者可根据业务需求新增事件类型,无需担心对现有系统的影响,能够快速适配业务的快速迭代需求。
-
业务可追溯、可审计,便于运维:所有业务操作均以事件形式留存,事件的产生、处理过程可全链路追踪,不仅便于问题排查(如定位某一业务异常的原因),还可作为系统审计的依据,满足金融、政务等行业的合规需求。
-
适配DDD与云原生,架构兼容性好:事件驱动架构与领域驱动设计(DDD)天然契合,DDD中的领域事件可直接映射为EDA中的系统事件,便于业务与技术的深度融合;同时,EDA架构能够很好地适配云原生技术(如容器化、Serverless),可实现服务的弹性伸缩、按需部署,符合现代架构的发展趋势。
3.2 缺点与挑战
EDA架构并非适用于所有场景,其自身存在一定的缺点与实施挑战,在架构设计过程中需重点考虑,也是软考中考查架构选型合理性的核心要点,具体如下:
-
异步流程难以调试,问题定位复杂:与同步架构的线性调用链路不同,EDA架构的事件流转是异步、分布式的,业务链路不直观,当出现业务异常(如数据不一致)时,需要追踪整个事件的发布、投递、处理全流程,定位问题的难度较大,对运维人员的技术能力要求较高。
-
一致性管理困难,易出现数据异常:由于事件流转的异步性,各服务的状态更新存在时间差,难以实现强一致性;同时,需处理事件重复、乱序、丢失等问题,若设计不当,易出现数据不一致(如订单创建成功但库存未扣减)、业务逻辑错乱等问题。
-
运维复杂度提升,依赖配套体系:EDA架构依赖事件总线(消息中间件)、重试机制、死信处理、监控告警等配套组件,需要额外维护这些组件的正常运行;同时,需监控事件的生产成功率、消费成功率、消息堆积量等指标,运维成本高于传统同步架构。
-
业务逻辑分散,新人上手成本高:事件驱动架构中,同一业务流程的逻辑分散在不同的消费者服务中,没有统一的入口,新人需要熟悉所有相关消费者的逻辑及事件流转流程,才能理解整个业务链路,上手难度较大。
-
事件版本演化难度大,兼容性难保证:随着业务的迭代,事件的字段可能需要新增、修改,若处理不当,会导致老版本消费者无法处理新版本事件,或新版本消费者无法兼容老版本事件,影响系统的稳定性。
四、事件驱动架构的设计与开发过程
事件驱动架构的设计与开发是一个标准化的过程,需遵循"业务导向、解耦优先、可靠可控"的原则,结合业务需求与技术选型,逐步推进,确保架构的可行性与落地性。该过程是软考系统架构设计师考试中,架构设计类考题的核心考查内容,需熟练掌握每一步的核心任务与实施要点,具体分为以下6个步骤:
4.1 需求分析与领域建模(第一步:业务导向)
EDA架构的设计必须以业务需求为核心,脱离业务的架构设计毫无意义。该步骤的核心任务是梳理业务需求、划分业务领域、识别事件来源,为后续的事件设计与架构选型奠定基础,具体实施要点如下:
-
业务需求梳理:明确系统的核心业务场景、业务流程、业务目标(如高并发、高可用、可扩展),梳理业务中的关键操作与状态变更点,明确哪些业务流程适合异步处理,哪些需要同步处理。
-
领域建模(结合DDD):采用领域驱动设计(DDD)的思想,划分业务领域与领域边界,识别领域中的聚合根、实体、值对象,明确各领域之间的业务关系;重点梳理各领域中的状态变更场景,这些状态变更场景将作为事件的核心来源。
-
事件初步识别:基于业务状态变更点,初步识别系统中的核心事件,明确事件对应的业务含义、触发条件(如"订单创建"事件的触发条件是用户完成下单操作、订单状态变为"已创建"),梳理事件与业务流程的对应关系。
4.2 同步与异步边界划分(第二步:解耦优先)
并非所有业务流程都适合采用EDA架构的异步模式,需明确同步与异步的边界,避免为了异步而异步,确保系统的性能与一致性。该步骤的核心任务是根据业务的一致性要求、响应速度要求,划分同步与异步业务边界,具体原则如下:
-
同步业务场景:核心业务、强一致性要求、需要立即返回处理结果的业务流程,采用同步调用模式。例如,用户登录(需要立即验证账号密码并返回登录结果)、支付校验(需要立即验证支付信息的合法性)、核心数据查询(需要立即返回查询结果)等。
-
异步业务场景:非核心业务、可接受延迟、无需立即返回处理结果、强解耦需求的业务流程,采用EDA架构的异步模式。例如,订单创建后的通知发送、积分增加、物流单生成、日志记录、数据统计等,这些业务不影响核心流程的正常执行,可异步处理。
4.3 事件模型设计(第三步:规范统一)
事件是EDA架构的核心载体,事件模型的设计直接影响架构的可靠性、兼容性与可维护性。该步骤的核心任务是设计统一的事件规范、定义事件结构与内容,确保事件的规范性与兼容性,具体实施要点如下:
-
事件命名规范:采用"实体+动作+状态"的命名方式,确保事件名称直观、清晰,能够准确反映事件的业务含义,避免歧义。例如,OrderCreated(订单已创建)、PayCompleted(支付已完成)、StockDeducted(库存已扣减)、OrderCanceled(订单已取消)。
-
事件结构设计:设计统一的事件结构,确保所有事件遵循相同的规范,便于事件总线的路由、消费者的处理与版本兼容。一个标准的事件结构应包含以下核心字段(可根据业务需求扩展):
-
eventId:事件唯一ID,采用UUID生成,用于事件的幂等处理、追踪与去重;
-
eventType:事件类型,即事件名称(如OrderCreated),用于事件路由与消费者订阅;
-
businessId:业务主键ID,关联具体的业务对象(如订单号、账户ID),用于业务关联与追踪;
-
timestamp:事件发生时间戳,精确到毫秒,用于事件的时间序列排序与追溯;
-
data:业务数据体,采用JSON格式存储,包含事件相关的业务详情(如订单金额、支付方式、用户ID等),字段需清晰、简洁,避免冗余;
-
version:事件版本号,采用整数递增方式(如v1、v2),用于事件的版本演化与兼容性处理;
-
source:事件来源服务,标识事件的产生者(如order-service、pay-service),用于问题定位与审计。
-
-
事件设计原则:一是事件不可变性,事件一旦发布,不可修改,只能新增,确保事件的可追溯性;二是向后兼容,事件字段只增不减,不修改原有字段的含义,避免影响老版本消费者;三是可序列化,事件需支持JSON、Protobuf等常用序列化方式,便于事件的传输与存储;四是无业务逻辑,事件仅记录状态变更事实,不包含任何业务处理逻辑。
4.4 技术选型(第四步:适配业务)
技术选型的核心是选择合适的事件总线(消息中间件),同时确定事件生产者、消费者的开发框架与技术栈,确保技术选型贴合业务需求、具备可落地性。该步骤是架构设计的关键,也是软考中重点考查的内容,具体选型逻辑如下:
4.4.1 事件总线(消息中间件)选型
不同的消息中间件具备不同的特性,需根据业务的吞吐量要求、可靠性要求、路由需求等,选择合适的中间件,具体选型对比与建议如下:
-
Kafka:高吞吐、高持久化、可重放,适合大数据量、高并发、日志型的业务场景(如电商大促、实时数据处理),支持分区存储,可通过增加分区实现水平扩容,是EDA架构中最常用的事件总线之一;缺点是路由功能相对简单,不支持复杂的路由策略。
-
RocketMQ:金融级可靠性、支持事务消息、延迟队列、复杂路由,适合对消息可靠性要求高、需要事务支持的业务场景(如金融支付、订单系统),支持事务消息,可确保生产者发布事件与业务操作的原子性;缺点是部署与维护复杂度略高。
-
RabbitMQ:灵活的路由策略、支持多种交换机类型(如Direct、Topic、Fanout)、延迟队列、死信队列,适合中小型系统、对路由灵活性要求高的业务场景;缺点是吞吐量相对较低,不适合超大数据量的场景。
-
Redis Stream:轻量、部署简单、支持流式处理,适合简单业务、中小规模的场景(如小型电商、内部管理系统);缺点是可靠性相对较低,不适合对消息可靠性要求高的核心业务。
4.4.2 其他技术选型
-
开发框架:微服务场景下,可采用Spring Cloud Stream(简化消息中间件的集成,统一生产者与消费者的开发规范)、Spring Boot(快速开发微服务);
-
序列化方式:核心业务采用Protobuf(高效、紧凑),普通业务采用JSON(简洁、易调试);
-
监控告警:采用Prometheus+Grafana(监控消息堆积量、消费成功率等指标)、ELK(收集与分析事件日志);
-
链路追踪:采用SkyWalking、Zipkin(实现事件全链路追踪,便于问题定位)。
4.5 架构流程设计(第五步:可靠可控)
架构流程设计是EDA架构落地的核心,需明确事件的发布、投递、处理、异常处理等全流程,确保流程的可靠性、可控性。结合软考考点与项目实践,标准的EDA架构流程如下,同时附上适配软考论文的EDA架构流程图,清晰展示各组件的交互关系:
4.5.1 EDA架构流程图(嵌入论文,适配软考评分要求)
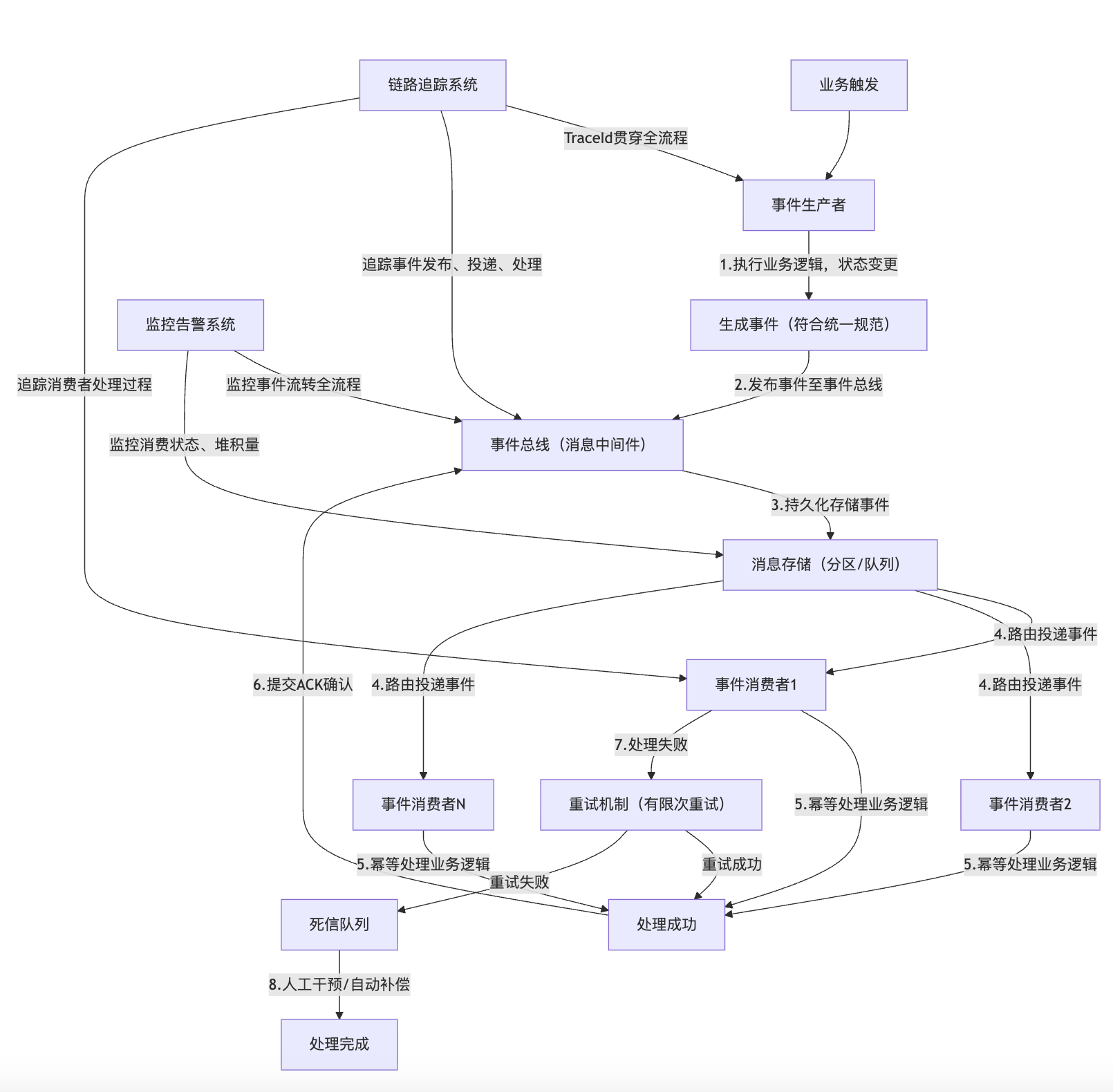
注:该流程图清晰展示了事件驱动架构的全流程,包含事件发布、投递、处理、异常处理、监控追踪等核心环节,贴合软考论文对架构流程图的要求,可直接用于论文作答。
4.5.2 核心流程说明
-
事件发布流程:业务操作触发后,事件生产者执行业务逻辑,当业务状态发生变更时,生成符合统一规范的事件,通过事件总线的客户端API,将事件发布至事件总线;若为核心业务,需采用事务消息或本地事务表,确保业务操作与事件发布的原子性(即业务操作成功则事件必须发布,业务操作失败则事件不发布)。
-
事件投递流程:事件总线接收事件后,首先将事件持久化存储(避免消息丢失),然后根据事件类型与路由规则,将事件投递至对应的消费者(消费者通过订阅事件类型,接收感兴趣的事件);支持一对一、一对多的投递模式(一个事件可被多个消费者订阅)。
-
事件处理流程:消费者接收到事件后,首先进行幂等校验(避免重复处理),然后根据事件内容执行业务逻辑;处理成功后,向事件总线提交ACK确认,事件总线收到ACK后,删除该事件的持久化记录;处理失败时,触发重试机制,进行有限次重试(如重试3次)。
-
异常处理流程:若消费者多次重试后仍处理失败,事件将被投递至死信队列,避免影响正常事件的流转;死信队列中的事件需进行人工干预(排查处理失败原因)或自动补偿(如触发补偿事件),处理完成后,标记事件为已处理。
-
监控与追踪流程:监控告警系统实时监控事件的生产成功率、消费成功率、消息堆积量、重试次数、死信数量等指标,当指标超出阈值时,触发告警(如短信、邮件告警);链路追踪系统通过全局TraceId,贯穿事件的发布、投递、处理全流程,记录各环节的处理时间、状态,便于问题定位。
4.6 一致性与可靠性设计(第六步:风险防控)
一致性与可靠性是EDA架构落地的关键,也是软考中重点考查的难点,需针对事件丢失、重复、乱序、数据不一致等问题,设计对应的保障机制,具体如下:
-
消息不丢失保障:生产者采用事务消息或Confirm机制(确保事件成功发布至事件总线);事件总线开启持久化与多副本(确保事件存储可靠,避免中间件故障导致消息丢失);消费者采用"先处理业务,再提交ACK"的模式(确保业务处理成功后,再确认事件已处理);建立本地事务表(生产者将业务操作与事件发布记录到本地事务表,通过定时任务补偿未发布的事件)。
-
消息不重复保障:所有消费者必须实现幂等处理,结合事件唯一ID、幂等表、业务状态机等方式,避免重复处理事件(具体实现将在项目实践中详细阐述)。
-
消息不乱序保障:采用"相同业务ID Hash路由到同一分区"的方式,确保同一业务对象的事件在同一分区内有序投递;单分区内采用FIFO(先进先出)模式,保证事件的顺序性;若业务需强顺序,可采用单线程消费模式(牺牲部分吞吐量,确保顺序)。
-
最终一致性保障:采用"事务消息+补偿机制",确保业务操作与事件发布的原子性;建立定时对账任务,定期核对各服务的状态,发现数据不一致时,触发补偿事件(如库存未扣减时,触发库存扣减补偿事件);提供人工处理平台,用于处理无法自动补偿的一致性问题。
五、项目实践:EDA架构在电商订单系统中的落地
结合软考论文要求,本文以某大型电商平台的订单微服务系统为实践场景,详细阐述事件驱动架构的具体落地方式、实施步骤,结合真实项目经验,展现EDA架构的实际应用价值,同时为软考论文的实践部分作答提供参考。
5.1 项目背景与需求
该电商平台日均订单量100万+,峰值订单量(大促期间)500万+,系统包含多个核心微服务:订单服务、支付服务、库存服务、用户服务、物流服务、通知服务、积分服务。原系统采用传统同步REST调用架构,订单创建流程为:创建订单 → 扣减库存 → 支付校验 → 增加积分 → 发送通知 → 生成物流单,存在以下突出问题:
-
链路长、阻塞严重:同步调用链路包含6个服务,单个服务处理缓慢(如通知发送超时),会导致整个订单创建流程阻塞,响应时间过长(峰值时响应时间超过3秒);
-
耦合度高、扩展性差:新增业务功能(如新增优惠券抵扣通知)需修改订单服务的调用链路,开发维护成本高,且无法快速适配峰值流量的扩容需求;
-
容错能力弱:某一服务(如物流服务)故障时,会导致整个订单创建流程回滚,大量订单创建失败,影响用户体验与平台收益;
-
吞吐量不足:同步调用模式下,系统吞吐量难以提升,无法满足大促期间的峰值流量需求。
基于以上问题,结合项目的高并发、高可用、可扩展需求,决定采用事件驱动架构对订单系统进行重构,核心目标是:解耦服务、提升吞吐量、增强容错能力、降低开发维护成本。
5.2 EDA架构落地方案设计
结合项目需求与前文的设计开发流程,本次EDA架构落地采用"核心事件驱动+事务消息保障+最终一致性"的模式,具体方案如下:
5.2.1 技术选型
-
事件总线:选用Kafka,适配高并发、大数据量的场景,支持分区存储与水平扩容,满足大促期间的峰值需求;
-
开发框架:Spring Boot + Spring Cloud Stream,简化Kafka的集成,统一生产者与消费者的开发规范;
-
序列化方式:核心事件(订单、支付相关)采用Protobuf,普通事件(通知、积分相关)采用JSON;
-
监控与追踪:Prometheus+Grafana(监控消息堆积、消费成功率)、ELK(事件日志收集)、SkyWalking(链路追踪);
-
幂等与补偿:MySQL幂等表、定时对账任务、人工补偿平台。
5.2.2 事件设计
结合电商订单系统的核心业务流程,识别3个核心事件,设计统一的事件结构,具体如下:
-
OrderCreated(订单已创建):触发条件为用户完成下单操作、订单服务成功写入订单数据;事件数据体包含orderId(订单号)、userId(用户ID)、orderAmount(订单金额)、productList(商品列表)、createTime(创建时间);
-
PayCompleted(支付已完成):触发条件为用户完成支付、支付服务验证支付信息合法;事件数据体包含payId(支付ID)、orderId(订单号)、payAmount(支付金额)、payTime(支付时间)、payMethod(支付方式);
-
OrderCanceled(订单已取消):触发条件为用户取消订单或订单超时未支付;事件数据体包含orderId(订单号)、userId(用户ID)、cancelReason(取消原因)、cancelTime(取消时间)。
5.2.3 同步与异步边界划分
-
同步流程:订单创建(核心业务,需立即返回下单结果)、支付校验(强一致性要求,需立即验证支付信息);
-
异步流程:库存扣减、积分增加、通知发送、物流单生成、订单取消后的库存回补与积分退回。
5.3 具体落地实施步骤
结合前文的EDA架构流程图,本次项目落地分为4个阶段,逐步推进,确保架构的平稳过渡与可靠运行:
5.3.1 第一阶段:基础设施搭建(1-2周)
核心任务是搭建事件总线、监控追踪、幂等保障等基础设施,为EDA架构落地提供支撑:
-
部署Kafka集群:搭建3节点Kafka集群,创建3个主题(对应3个核心事件),每个主题设置8个分区、3个副本,确保高可用与高吞吐;
-
集成开发框架:所有微服务集成Spring Cloud Stream,配置Kafka客户端,统一事件的发布与订阅接口;
-
搭建监控与追踪系统:部署Prometheus+Grafana,配置消息堆积量、消费成功率、重试次数等监控指标,设置告警阈值;部署ELK与SkyWalking,实现事件日志收集与全链路追踪;
-
创建幂等表:在各消费者服务的数据库中,创建事件幂等表(event_id为主键,唯一索引),用于事件去重与幂等处理。
5.3.2 第二阶段:核心服务改造(2-3周)
核心任务是改造订单服务(生产者)与各消费者服务,实现事件的发布与订阅:
-
订单服务改造(事件生产者):
-
新增事件生成逻辑,当订单创建成功后,生成OrderCreated事件,通过Spring Cloud Stream发布至Kafka;
-
集成RocketMQ事务消息(核心优化),确保订单写入数据库与OrderCreated事件发布的原子性(避免订单创建成功但事件未发布,或事件发布成功但订单写入失败);
-
新增事件接收逻辑,订阅PayCompleted事件与OrderCanceled事件,更新订单状态(如支付完成后将订单状态改为"已支付",取消后改为"已取消")。
-
-
消费者服务改造:
-
库存服务:订阅OrderCreated事件,执行业务逻辑(扣减对应商品库存);订阅OrderCanceled事件,执行业务逻辑(回补商品库存);实现幂等处理,避免重复扣减/回补;
-
积分服务:订阅OrderCreated事件,执行业务逻辑(增加用户积分,积分=订单金额/10);订阅OrderCanceled事件,执行业务逻辑(退回用户积分);
-
通知服务:订阅OrderCreated、PayCompleted、OrderCanceled三个事件,分别发送下单通知、支付成功通知、订单取消通知(支持短信、站内信、APP推送);
-
物流服务:订阅PayCompleted事件,执行业务逻辑(生成物流单,分配物流网点与快递员)。
-
5.3.3 第三阶段:测试与灰度发布(1-2周)
核心任务是通过测试验证架构的可靠性、性能与一致性,避免上线后出现问题:
-
功能测试:验证事件的发布、投递、处理流程是否正常,幂等处理、重试机制、死信处理是否有效,数据一致性是否得到保障;
-
性能测试:模拟大促峰值流量(500万+订单/天),测试系统的吞吐量、响应时间,验证Kafka集群与消费者的扩容能力;
-
容错测试:模拟某一消费者服务故障、Kafka节点故障,验证系统的容错能力,确保故障不会影响核心业务流程;
-
灰度发布:先将改造后的服务部署至测试环境,再逐步灰度至生产环境(先覆盖10%的流量,再逐步提升至100%),实时监控各项指标,发现问题及时回滚。
5.3.4 第四阶段:上线运维与优化(长期)
核心任务是保障架构的稳定运行,根据运行情况进行优化:
-
日常运维:监控事件流转全流程,及时处理死信队列中的事件,排查消费失败的原因;
-
扩容优化:大促期间,根据消息堆积量,对Kafka分区与消费者实例进行水平扩容,提升处理能力;
-
性能优化:优化消费者处理逻辑,将慢操作(如第三方接口调用)异步化,提升消费速度;优化事件数据体,减少冗余字段,提升序列化与传输效率;
-
版本迭代:新增业务事件时,遵循向后兼容原则,采用版本号管理,确保老版本消费者正常运行。
5.4 落地效果
EDA架构落地后,该电商订单系统的性能与可靠性得到显著提升,完全满足项目需求,具体落地效果如下:
-
系统吞吐量提升60%:峰值订单处理能力从500万/天提升至800万/天,响应时间从3秒缩短至500ms以内;
-
服务解耦彻底:各服务独立迭代,新增业务功能(如优惠券通知)无需修改原有服务,开发维护效率提升50%;
-
容错能力显著增强:某一消费者服务故障时,事件堆积在Kafka中,故障恢复后自动重试,核心订单创建流程不受影响,系统可用性提升至99.99%;
-
运维成本降低:通过监控告警与链路追踪,问题定位时间从几小时缩短至几分钟,运维效率显著提升。
六、项目落地中遇到的问题及解决方案(软考重点)
在EDA架构落地过程中,结合真实项目经验,遇到了6类典型技术问题,这些问题也是软考系统架构设计师论文中高频考查的"问题与解决方案"类考点,本文详细阐述每个问题的现象、原因及可落地的解决方案,为同类项目提供参考。
6.1 问题一:消息重复消费(最常见问题)
6.1.1 现象
消费者多次处理同一事件,导致业务异常,例如:库存服务重复扣减库存(导致商品超卖)、积分服务重复增加积分(导致用户积分异常)、通知服务重复发送通知(影响用户体验)。
6.1.2 原因
-
网络波动:Kafka与消费者之间的网络出现波动,消费者处理完成事件后,ACK确认消息未成功发送至Kafka,Kafka认为消费者未处理完成,重新投递事件;
-
消费者重启:消费者服务因故障重启,重启前已处理完成事件,但未提交ACK,重启后Kafka重新投递该事件;
-
重试机制触发:消费者处理事件时,因临时故障(如数据库连接超时)触发重试机制,导致同一事件被多次处理;
-
Kafka分区重平衡:Kafka集群进行分区重平衡时,会将未提交ACK的事件重新分配给其他消费者,导致重复投递。
6.1.3 解决方案(组合使用,确保幂等)
核心原则:所有消费者必须实现幂等处理,结合多种方式,确保同一事件无论被投递多少次,处理结果一致。具体解决方案如下:
-
全局唯一事件ID + 幂等表去重(核心方案):
-
在各消费者服务的数据库中,创建事件幂等表(表结构:id、eventId、eventType、businessId、handleTime、handleStatus),其中eventId为主键(唯一索引);
-
消费者接收到事件后,首先查询幂等表,判断该eventId对应的事件是否已处理(handleStatus=已处理);
-
若已处理,直接返回处理成功,不执行后续业务逻辑;若未处理,执行业务逻辑,处理完成后,将eventId、eventType等信息插入幂等表,标记handleStatus=已处理;
-
优势:通用性强,适用于所有消费者服务,能够彻底解决重复消费问题;缺点:需要额外维护幂等表,增加少量数据库开销。
-
-
业务状态机判断(辅助方案):
-
结合业务状态,判断事件是否需要处理,例如:库存服务接收到OrderCreated事件时,先查询该订单对应的商品库存扣减记录,若已扣减,则不重复处理;积分服务接收到OrderCreated事件时,查询该用户的积分增加记录,若已增加,则不重复处理;
-
优势:无需额外维护幂等表,依托业务自身状态,减少数据库开销;缺点:仅适用于有明确业务状态的场景,通用性较弱。
-
-
数据库唯一约束(补充方案):
-
对于核心业务(如库存扣减),在业务表中添加唯一约束,例如:在库存扣减记录表中,添加orderId+productId的唯一索引,避免重复扣减;
-
优势:通过数据库层面强制去重,可靠性高;缺点:仅适用于特定业务场景,且会增加数据库约束开销。
-
项目实践效果:采用"幂等表+业务状态机"的组合方案后,消息重复消费问题彻底解决,重复消费率从15%降至0%,未再出现库存超卖、积分异常等问题。
6.2 问题二:消息丢失(核心可靠性问题)
6.2.1 现象
事件生产者发布事件后,消费者未收到事件,导致业务流程中断,例如:订单创建成功后,库存服务未收到OrderCreated事件,未扣减库存,导致商品超卖;支付成功后,物流服务未收到PayCompleted事件,未生成物流单,影响用户收货。
6.2.2 原因
-
生产者端丢失:订单服务生成事件后,未成功发布至Kafka(如Kafka集群故障、网络中断),且未做补偿处理;
-
事件总线端丢失:Kafka未开启持久化,或Kafka节点故障,导致事件未被持久化存储,重启后事件丢失;
-
消费者端丢失:消费者接收到事件后,未处理完成就提交ACK,随后服务故障,导致业务逻辑未执行,但Kafka已删除该事件,无法重新投递。
6.2.3 解决方案(全链路保障,确保消息不丢失)
核心原则:从生产者、事件总线、消费者三个层面,建立全链路消息可靠性保障机制,确保事件从发布到处理的全流程不丢失。具体解决方案如下:
-
生产者端保障(确保事件必发):
-
采用事务消息:订单服务集成RocketMQ事务消息(因Kafka原生不支持事务消息,通过RocketMQ实现订单写入与事件发布的原子性),具体流程:订单服务先执行本地事务(写入订单数据),本地事务成功后,再确认发布事件;本地事务失败,取消事件发布;
-
建立本地事务表:在订单服务数据库中,创建事件发布记录表(表结构:id、eventId、eventType、businessId、publishStatus、createTime),订单写入成功后,将事件信息插入该表,标记publishStatus=未发布;事件发布成功后,更新publishStatus=已发布;通过定时任务(每5分钟),扫描未发布的事件,重新发布,确保事件必发;
-
开启生产者Confirm机制:配置Kafka生产者的acks=all,确保事件成功发送至Kafka的所有副本后,才返回发布成功,避免Kafka节点故障导致事件丢失。
-
-
事件总线端保障(确保事件存储可靠):
-
Kafka开启持久化:配置Kafka主题的log.retention.hours=72(事件保留72小时),确保事件被持久化存储,即使Kafka节点重启,事件也不会丢失;
-
配置多副本:每个Kafka主题设置3个副本,确保某一Kafka节点故障时,其他副本可正常提供服务,避免事件丢失;
-
避免主题删除:禁止手动删除Kafka主题,防止误操作导致事件丢失。
-
-
消费者端保障(确保事件必处理):
- 采用"先处理业务,再提交ACK"的模式:消费者接收到事件后,先执行业务逻辑(如扣减库存、增加积分),处理成功后,再向Kafka提交ACK确认;若处理失败,不提交ACK,Kafka会重新投递事件;