拔掉网线,AI 还能活吗?
引言:从"Demo 里的神"到"机房里的渣"
过去这一年,见过了太多 AI 项目的"见光死"。
在 CBD 窗明几净的会议室里,连着千兆专线,我们看着大模型行云流水地写着'李白的藏头诗',或者秒速生成一份'滴水不漏的年终总结'。那一刻,仿佛通用人工智能(AGI)触手可及。
但当我转身走进公安的网监支队,或者穿上防静电服走进电力调度的屏蔽机房,把同样的系统部署上去时,现实给了我一记响亮的耳光。

当一线民警把一份扫描歪斜的《案件侦查卷宗》丢进去,或者当电厂专工想查一张十年前手绘的《二次回路接线图》时,那些在 Demo 里无所不能的 AI,瞬间变成了人工智障。它要么对着图表"瞎编"数据,要么因为内网算力不足卡死在当场。
这让我意识到一个残酷的真相:互联网上的 RAG 是一场"开卷考试",而工业界的 RAG 是一场"荒野求生"。
今天,我想剥开那些花哨的概念外衣,聊聊在一个断网、算力受限、数据极脏的真实工业环境下,我们是如何设计一套工业级的"RAG"架构------Hi-way。
一、 工业现场的三道"隐形高墙"
如果你习惯了 SaaS 模式,可能会觉得"部署"就是 docker-compose up。但在 OT(运营技术)和 GOV(政务)领域,有三道墙挡在 AI 面前。
- 数据的"熵":脏到让你怀疑人生
通用 RAG 假设世界是 Markdown 构成的。但工业界的知识资产,往往封存在"数字水泥"里。
-
格式混乱:不是 Word,而是扫描版 PDF、甚至图片截屏。
-
视觉语义丢失:这是最痛的点。一张电力拓扑图,如果只用 OCR 提取文字,你得到的是一堆毫无关联的"断路器"、"变压器"字符。但图纸的核心------"谁连接了谁"、"谁控制了谁"------完全丢失了。不懂视觉语义的 RAG,在工业界就是盲人摸象。
-
信噪比极低:红头文件上的印章、页眉页脚的干扰、手写的批注,这些噪音会让向量检索的准确率断崖式下跌。
- 物理隔离的"窒息感"
安全红线不是开玩笑的。在电力生产大区或公安内网,"拔网线"是物理层面的强制要求。
这意味着什么?
这意味着你引以为傲的 GPT-4 API 归零了。
这意味着你不能依赖云端的 Embedding 服务。
这意味着你的系统必须是一个"黑盒":数据进得去,出不来;模型必须全本地化运行,且要在一台离线的机器上跑完所有流程。
- 算力的"贫富差距"
我们当然希望在每个变电站都配一台 A800 服务器,但这在商业上是不成立的。
甲方能给你的终端,可能只是一台配了 3090 显卡的工作站,甚至是更老旧的机器。
这就构成了一个死结:要处理极脏的数据(需要大模型的大算力),却只有极弱的终端算力。 怎么解?
二、 架构重构:把"作坊"升级为"化工厂"
面对死结,我们内部推翻了无数次方案,最后决定引入工业界的"供应链思维"。
如果终端算力不够,那就在源头解决。如果数据太脏,那就建一个专门的清洗厂。我们把这个架构称为 "计算前置,推理后置" 。
这听起来很笨重,但这正是工业化的本质:用确定性的流程,对抗不确定性的输入。
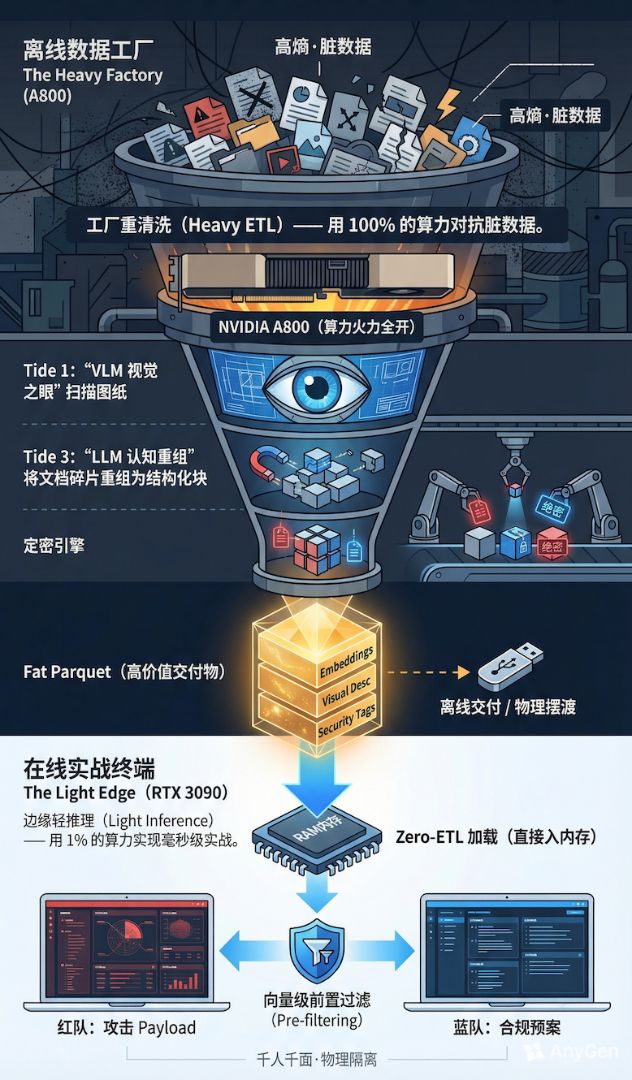
1. 上游:建立"重型数据工厂"
我们在后台(或甲方的私有云中心)部署重算力设备(如 NVIDIA A800)。在这里,我们不追求实时响应,只追求"清洗的深度"。
为此,我们构建了一条 "5-Tide(五重潮汐)" ETL 流水线:
- Tide 1:不仅仅是 OCR,是"视觉转译"
我们放弃了传统的 OCR 方案,直接引入 Qwen-VL(72B 参数的视觉大模型)。
对于一张复杂的电路图,我们让 VLM"看"一遍,然后让它生成一段几百字的描述:"图中展示了一个 110kV 变电站的双母线接线,2 号主变连接在 I 母上..."。
这一步极度消耗算力,但它把不可检索的像素信息,变成了可检索的高维语义。这是 Hi-Way 能够回答"图纸问题"的核心秘密。
- Tide 3:认知的逻辑重组
对于《应急预案》这种非结构化文档,简单的切片(Chunking)会切断逻辑。
我们在这一步利用大模型(Qwen-72B)进行"逻辑原子化"。将大段的文档重写为独立的、带有上下文的知识点。
这个过程就像炼油厂。原油(脏数据)进去,经过裂解、重整(Tide 1-5),最终变成高纯度的汽油(知识资产)。
2. 交付:定义"算力固化"的资产标准 (Fat Parquet)
工厂炼好了油,怎么运到断网的终端去?
我们并没有选择把数据导入数据库再导出,那样太慢且容易出错。我们借鉴大数据技术,定义了一种新的交付格式------"Fat Parquet"。
为什么叫它 Fat(丰满)?因为它吞噬了大量的算力:
-
它不仅存储了文本;
-
它存储了工厂计算好的1024 维向量 ;
-
它存储了 VLM 生成的视觉描述;
-
它存储了安全标签。
这个 Parquet 文件,本质上是"算力的固化容器"。我们把 A800 在工厂里几天几夜计算的成果,全部封存在这个文件里。
3. 下游:极致轻量的边缘推理
当这个 Fat Parquet 文件通过光盘或安全 U 盘导入到边缘端(3090 主机)时,奇迹发生了。
因为最耗时的"视觉解析"和"向量计算"已经在工厂做完了,边缘端的任务被极度简化:Zero-ETL。
终端不需要再跑任何大模型来做数据处理,它只需要做一个动作:Load(加载)。
这使得我们能够在一台消费级的显卡上,跑出令人惊讶的检索速度和精度。这不仅是降本增效,这是"算力的时空置换"。
三、 安全升维:当权限进入向量空间
在工业场景,安全不是"功能",是"命门"。
很多 RAG 系统的安全机制是"外挂"的------先搜出 10 条结果,再看用户有没有权限,没有就隐藏。
这种"检索后过滤"在高密级场景下是绝对禁止的。因为虽然你没显示内容,但攻击者可以通过搜索结果的排序变化、耗时差异,推测出"这里有货",这就是所谓的侧信道攻击。
在 Hi-Way 的架构中,我们把安全做进了向量的数学空间。
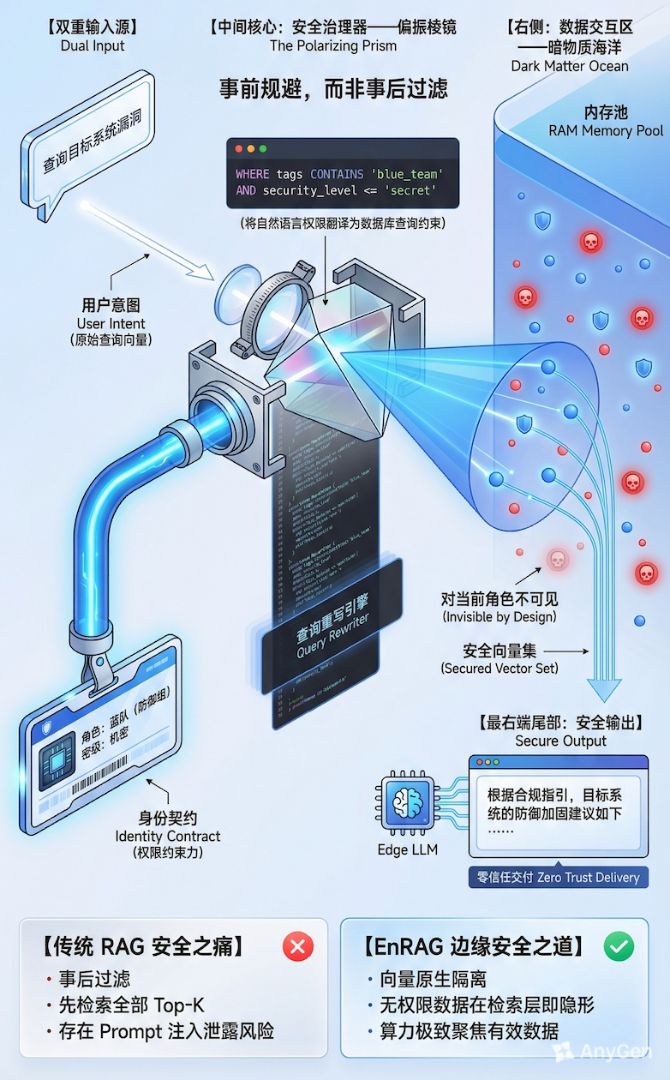
- 原子级定密
在工厂生产阶段,每一条知识切片(Chunk)都会被自动打上 security_level(如:绝密/机密/公开)和 access_groups(如:红队/蓝队)的标签。这不再是文档级的粗粒度控制,而是原子级的。
- 前置过滤与物理隐形
当用户发起搜索时,系统首先根据用户的身份生成一个向量过滤器。
Search(Query_Vector) WHERE Security_Level <= User_Level
这个过程发生在向量计算之前。对于无权限的用户,那些高密数据在数学层面上就是"暗物质",物理不可见,搜都搜不到。
想象一下某 GA 的实战场景:
同一个关键词"WebLogic",红队视角搜出来的是攻击 Payload,蓝队视角搜出来的是防御预案。这不是两套系统,这是同一套数据底座在不同权限下的量子叠加态。
结语:让 AI 回归工程本质
在这个 AI 充满了"神话色彩"的年代,我们选择了一条看起来很笨、很重的路。
我们不迷信大模型的"涌现",我们更相信工程的严谨。
我们不追求 Chatbot 的俏皮,我们更看重知识的准确与边界。
Hi-Way的架构,本质上是对工业现实的一种敬畏。我们通过"工厂重清洗,边缘轻推理"的架构置换,试图在泥泞的工业数据沼泽中,铺出一条通往智能化的硬化路面。
这条路很难走,但只有走通了这条路,AI 才能真正从 PPT 里走出来,成为支撑大国重器的数字底座。
此为开篇第一篇,后续下一篇,将详细描述一下Fat Parquet文件格式细节,敬请期待.