Hi,大家好,欢迎来到维元码簿。
本文属于 《Claude Code 源码 Deep Dive》 系列,专注于 Agent 执行内核中的 Pipeline 与上下文压缩 板块。如果你想了解整个系列,可以先看系列开篇 | Claude Code 源码架构概览:51万行代码的模块地图。
50 轮对话后,消息历史可以轻松膨胀到 10 万+ token------如果不做处理,不仅费钱,而且可能超过模型上下文窗口。 Claude Code 的解决方案不是在 API 层面优化(那是 Prompt Cache 系列的主题),而是在每次 API 调用前,对消息执行四层压缩:Snip(截断)、Microcompact(去重)、ContextCollapse(折叠)、AutoCompact(摘要)。
读完全文,你将能回答这几个问题:
- Pipeline 是什么?和压缩有什么关系? 答案:Pipeline 是架构模式------数据流、条件跳站、跨站参数传递、错误恢复路径;压缩是每个站承载的功能。Pipeline 不等于压缩,压缩只是 Pipeline 的一种应用。
- 四层压缩各自解决什么问题?为什么它们的执行顺序不可换? 答案:Snip 截断远的历史 → Microcompact 去重 → Collapse 折叠可恢复 → AutoCompact 摘要不可逆------每一层假设前一层已完成。
- 什么时候压缩?每一次都需要调用大模型吗? 答案:Snip、Microcompact、ContextCollapse 都是纯本地操作,不调大模型;只有 AutoCompact 和 Reactive Compact 需要调用独立的 compact agent------而且有 circuit breaker 防止无限重试。
- AutoCompact 失败了怎么办? 答案:circuit breaker------连续失败 3 次就放弃,不再重试。还有 Reactive Compact 作为 413 错误的被动防线。
- 压缩前后的 token 变化有多大? 答案:一次 AutoCompact 可将 8 万+ token 削减到约 1.2 万 token------削减 85%+。
本篇覆盖的源码范围
| 模块 | 核心文件 | 核心代码行 | 文件总行 | 职责 |
|---|---|---|---|---|
| Pipeline 编排 | src/query.ts |
L365-543(snip→microcompact→collapse→autocompact) | 1730 行 | 四层压缩的总调度 |
| Snip | src/services/compact/snipCompact.ts(Feature: HISTORY_SNIP) |
-- | -- | 历史消息按 token 阈值截断 |
| Microcompact | src/services/compact/microCompact.ts |
L1-600(microcompact 主逻辑) | ~600 行 | 重复工具结果去重 + cache_edits |
| ContextCollapse | src/services/contextCollapse/(Feature: CONTEXT_COLLAPSE) |
-- | -- | 可恢复的语境折叠投影 |
| AutoCompact | src/services/compact/autoCompact.ts |
L28-82(阈值计算 + circuit breaker) | 352 行 | 自动摘要压缩主逻辑 |
| Compact 核心 | src/services/compact/compact.ts |
L1-100(入口函数 compactConversation) | ~1600 行 | 调用 compact agent 生成摘要 |
为什么叫 Pipeline?
你可能会问:为什么用 Pipeline 这个词?有直接的代码依据。
在 query.ts L396-467 中,消息数组 messagesForQuery 依次流过 4 个压缩函数------每个函数的输出就是下一个函数的输入,形成标准的 Pipeline(流水线)模式。四层压缩顺序串行、层层递进,在代码结构上就是一个典型的 Pipeline。
这个类比也不是本文独创的------消息上下文管理篇 中,同样的 messages 数组在发给 API 之前还要经过另一道"清洗 Pipeline"(normalizeMessagesForAPI()),处理类型映射、Content Part 组装、缓存断点标记。两篇讲的是同一件事的不同阶段:一个对消息做压缩清洗,一个对消息做预发清洗。
用 Pipeline 统一描述,是为了让读者看到消息从用户输入到最终发出 API,全程都处在 Pipeline(流水线)处理中。
前情提要:从主循环到第一阶段
在姊妹篇 主循环与状态机(./04-Claude Code深度拆解-Agent执行内核-主循环与状态机.md) 中,我们建立了全局认知------while(true) 循环的 4 个阶段(准备→调用→执行→转移)。本文聚焦第 1 个阶段------准备阶段中的 Pipeline 与上下文压缩。
在 query.ts 中,这段代码位于 L365-543------在 API 调用之前,在构建完整 Prompt 之前。每次进入循环,第一步就是对消息历史做"瘦身"。
与 Prompt Cache 机制的区别 :Prompt Cache(缓存工程深度拆解篇)讲的是 Anthropic API 的 KV Cache------服务端如何复用已计算的 KV 向量来跳过前缀处理。那是"让 API 少算"。这里的四层压缩是"让 API 少看"------先砍掉不必要的 token,再发给 API。两者互相独立但又协同工作:压缩后的消息更短 → 前缀更稳定 → KV cache 命中率更高。
Pipeline 机制详解:不等于压缩,而是一套架构模式
你可能会有疑问:标题叫"Pipeline 与上下文压缩",但读下来不就是四层压缩吗?Pipeline 和压缩是什么关系?
它们不是同一件事。
- 压缩是每个处理站承载的功能------截断、去重、折叠、摘要
- Pipeline 是把这些功能串起来的架构模式------数据怎么流、哪些站跳过、参数怎么跨站传递、出错时怎么回退
打个比方:压缩是流水线上每台机器做的事(切割、打磨、喷涂、质检),Pipeline 是流水线本身的传动设计------物料怎么从上一台传到下一台、哪台机器可以跳过、质检失败怎么回炉。
理解 Pipeline 的运行机制,才能看懂后面每一层压缩为什么要这样编排。
下面这张图展示了 Pipeline 的架构机制:主数据流、条件跳站、跨站参数传递、短路重置、错误恢复双路径------注意和 Tab 4(四层压缩功能)的区别,这里讲的是"站怎么串"而不是"每站做什么"。
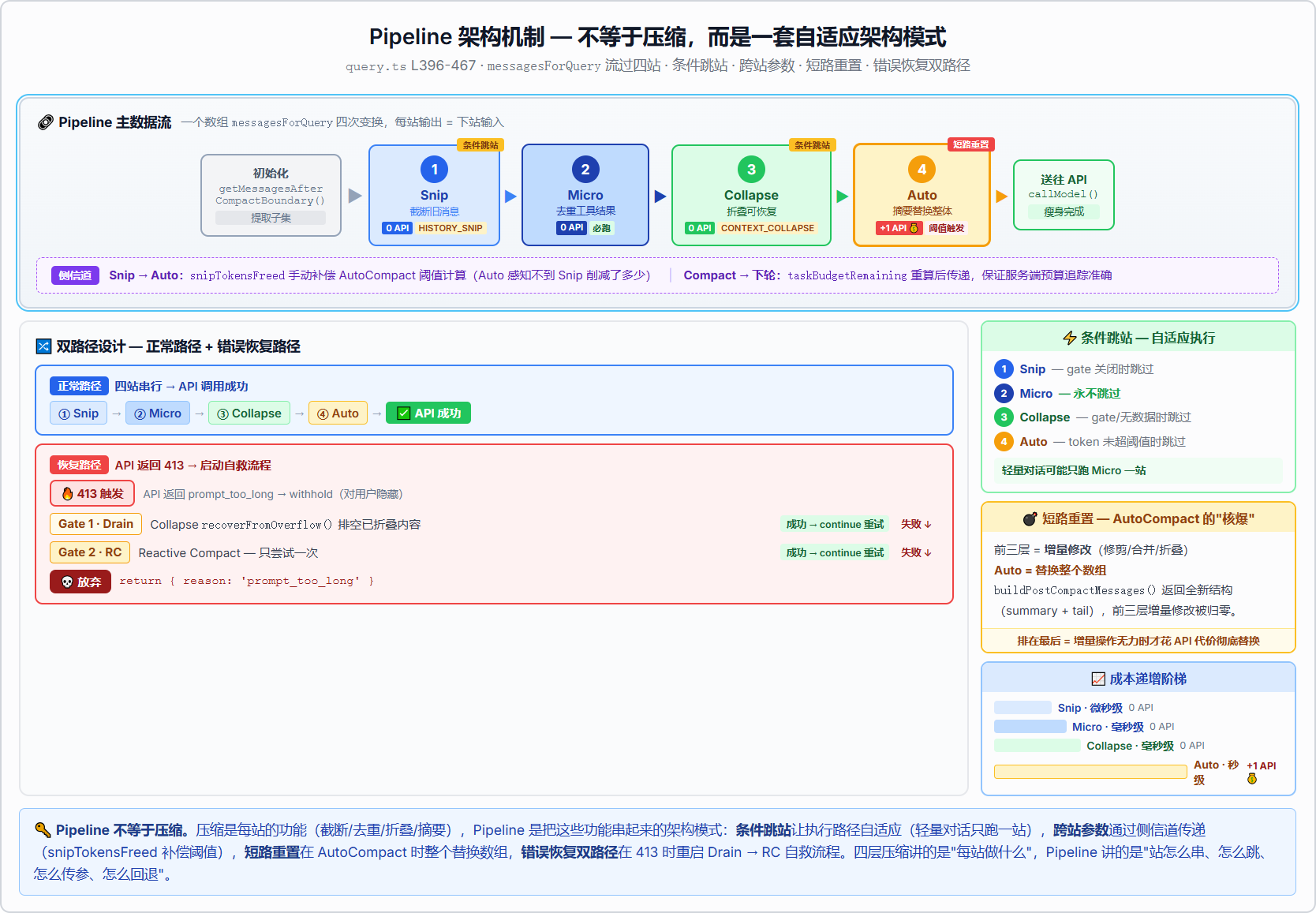
数据流:一个数组,四次变换
Pipeline 的核心数据实体只有一个:messagesForQuery(Message[] 数组)。它从 getMessagesAfterCompactBoundary() 初始化后,依次流过四个处理站------每一站都接收数组、变换后返回:
text
原始 messages
│
▼
getMessagesAfterCompactBoundary() ── 提取压缩边界之后的消息
│
▼ messagesForQuery = [...子集]
│
① Snip ──→ messagesForQuery = snipResult.messages
│
▼
② Microcompact ──→ messagesForQuery = microcompactResult.messages
│
▼
③ ContextCollapse ──→ messagesForQuery = collapseResult.messages
│
▼
④ AutoCompact ──→ messagesForQuery = buildPostCompactMessages(result)
│
▼
最终 messagesForQuery ──→ 送往 API这是经典的 Pipeline(链式处理)模式------每一站的输出就是下一站的输入。
条件跳站:不是每站都必跑
Pipeline 不是固定四站全跑。它有条件跳站机制------根据运行环境动态决定哪些站执行:
| 处理站 | 跳站条件 | 什么时候跳过 |
|---|---|---|
| Snip | feature('HISTORY_SNIP') 未开启 |
feature gate 关闭时整站跳过 |
| Microcompact | 无(默认执行) | 永不跳过 |
| ContextCollapse | feature('CONTEXT_COLLAPSE') && contextCollapse |
feature gate 关闭或无折叠数据时跳过 |
| AutoCompact | token 阈值未超 | 前三层之后 token 仍在窗口内时不触发 |
这意味着在轻量对话中,Pipeline 可能只跑 Microcompact 一站。执行路径是自适应的------不是机械的四步流程,而是根据当前消息状态决定走哪条路。
跨站参数传递:不止是主数据流
除了主数据流 messagesForQuery,Pipeline 还有侧信道(side channel)传递参数。这些参数不参与数据变换,但影响后续站的决策:
- Snip → AutoCompact :
snipTokensFreed(Snip 释放的 token 数)被传递给 AutoCompact 的阈值计算。因为 AutoCompact 的 token 估算基于"上次 API 返回的使用量",感知不到 Snip 削减了多少------需要手动补偿,否则 AutoCompact 会在不该触发时触发。 - Compact 结果 → task_budget :压缩后
taskBudgetRemaining被重新计算,传递给下一轮 API 调用,保证服务端预算追踪在多次压缩后仍准确(详见后文"Token Budget 的跨 Compact 传递"一节)。
这种"主数据流 + 侧信道"的双轨传递,是 Pipeline 区别于简单函数调用链的关键设计。
短路重置:AutoCompact 的"核爆"
前三层是增量修改 ------在原数组上修剪(Snip)、合并(Microcompact)、折叠(Collapse)。AutoCompact 完全不同:它替换整个数组。
buildPostCompactMessages() 返回的是一个全新的消息结构(摘要消息 + 保留的最近几轮对话尾巴),完全覆盖之前的 messagesForQuery。这是 Pipeline 中的"短路重置"------一旦触发,前三层的增量修改被归零,消息结构从零重建。
这也是为什么 AutoCompact 排在最后:只有增量操作都无能为力时,才值得付出一次 API 调用的代价做彻底替换。
错误恢复路径:Pipeline 的第二条命
Pipeline 不是一条直线。当 API 返回 413(prompt too long)时,控制流会重新进入 Pipeline 的恢复路径:
text
正常路径:Snip → Microcompact → Collapse → AutoCompact → API 调用
│
│ 413 错误
▼
恢复路径:Collapse Drain → Reactive Compact → 重试 API
│
│ 仍然 413
▼
return prompt_too_longContextCollapse 的 recoverFromOverflow() 是第一个恢复手段------排空已折叠内容释放空间。如果失败,Reactive Compact 作为被动防线。两者都失败,才真正放弃------返回 prompt_too_long 错误。
这种"正常 Pipeline + 恢复 Pipeline"的双路径设计,是 Agent 能长时间运行不崩溃的关键。后面讲 ContextCollapse 和 Reactive Compact 时,我们还会回到这张图。
四层压缩全景:为什么需要四层?
一层压缩不够。 不同的"冗余"需要不同的手术刀。
| 压缩层 | 解决的问题 | 操作方式 | 执行者 | 性能 | 可逆性 | Feature Gate |
|---|---|---|---|---|---|---|
| Snip | 远离当前的旧对话无用 | 按 token 阈值截断 | 本地剪裁 messages 数组 | 微秒级,0 API 调用 | 不可逆 | HISTORY_SNIP |
| Microcompact | 同一 tool_use_id 的重复结果 | 合并保留最新 | 本地遍历比对 | 毫秒级,0 API 调用 | 不可逆 | (默认开启) |
| ContextCollapse | 大段完整对话占位 | 折叠为摘要投影 | 本地语义折叠 | 毫秒级,0 API 调用 | 可恢复 | CONTEXT_COLLAPSE |
| AutoCompact | 总 token 超过模型窗口 | 调用 compact agent 生成摘要 | compact agent(fork query()) | 秒级,1 次 API 调用/触发 | 不可逆 | (默认开启) |
下面这张图展示了四层压缩的执行顺序和各自的效果------从上到下依次执行,每一层的输出是下一层的输入。
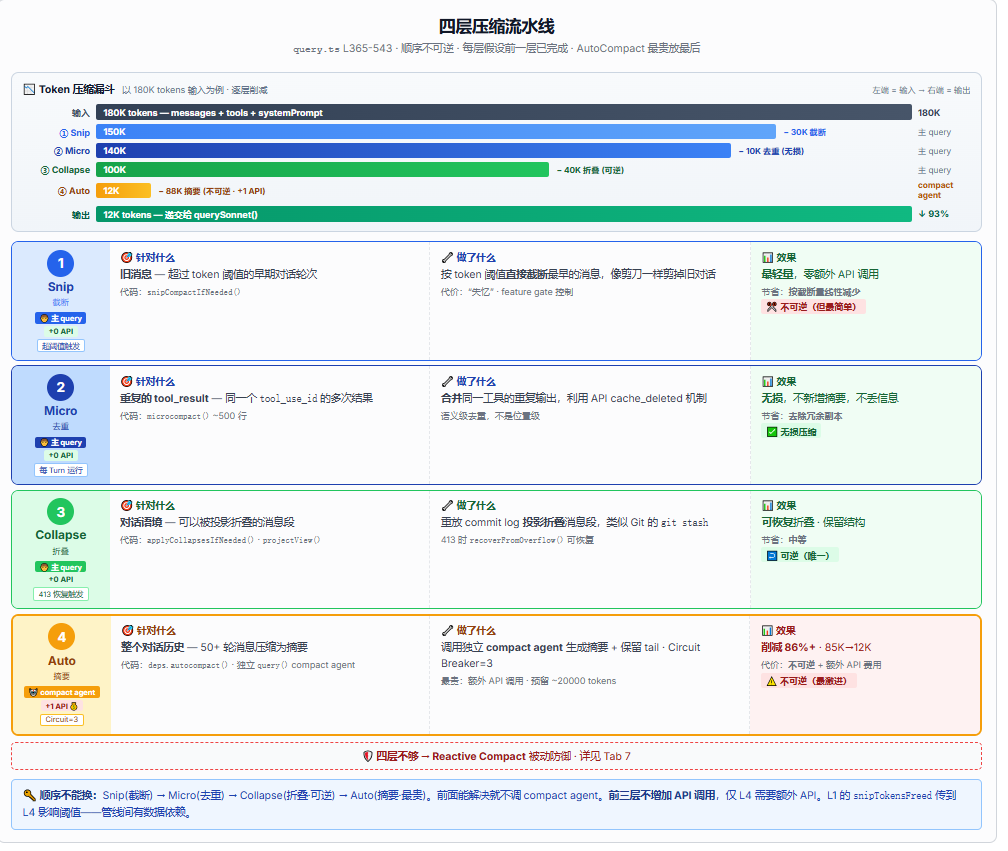
执行顺序为什么不能换? 因为每层假设前一层已完成。举个例子:如果先做 AutoCompact(1 次 API 调用),再做 Microcompact(0 次 API),那摘要里可能还包含重复的工具结果------去重白做了,API 也白调了。正确顺序是:先截断远的历史(Snip),再去重(Microcompact),再折叠(Collapse),最后如果还是太长,才调用摘要(AutoCompact)------这是"0 成本 → 0 成本 → 0 成本 → 不得不花 1 次 API"的阶梯。
四层压缩的代码编排也反映了这个顺序。在 query.ts 中:
typescript
// query.ts L396-467 --- 四层压缩的执行顺序
let messagesForQuery = [...getMessagesAfterCompactBoundary(messages)]
// 第1层:Snip(Feature gated)
if (feature('HISTORY_SNIP')) {
const snipResult = snipModule.snipCompactIfNeeded(messagesForQuery)
messagesForQuery = snipResult.messages
snipTokensFreed = snipResult.tokensFreed
}
// 第2层:Microcompact
const microcompactResult = await deps.microcompact(messagesForQuery, ...)
messagesForQuery = microcompactResult.messages
// 第3层:ContextCollapse(Feature gated)
if (feature('CONTEXT_COLLAPSE') && contextCollapse) {
const collapseResult = await contextCollapse.applyCollapsesIfNeeded(...)
messagesForQuery = collapseResult.messages
}
// 第4层:AutoCompact
const { compactionResult } = await deps.autocompact(messagesForQuery, ...)
if (compactionResult) {
messagesForQuery = buildPostCompactMessages(compactionResult)
}注意两点:一是 messagesForQuery 被层层赋值------每层都改变了消息数组;二是 Snip 的 snipTokensFreed 被传递给了 AutoCompact------因为 AutoCompact 的阈值判断需要考虑 Snip 已经削减了多少 token。
Snip:历史消息截断
Snip 是最"暴力"的一层------直接砍掉远离当前对话的旧消息。
它按 token 阈值截断:保留最近的消息直到累计 token 接近某个上限,更早的消息直接丢弃。被丢弃的消息不会以任何形式保留------这就是为什么它是"不可逆"的。
Snip 不是默认开启的------它由 HISTORY_SNIP feature gate 控制。为什么需要 gate?因为截断意味着 Agent "遗忘"了早期的对话------如果早期对话包含关键上下文(比如用户说"请用 TypeScript"),截断后 Agent 可能会"失忆"。所以这是有代价的优化。
它有一个重要输出:snipTokensFreed。这个数字会被传递给后续的 AutoCompact------AutoCompact 的阈值计算依赖 tokenCountWithEstimation(messagesForQuery),但这个估计是基于"上次 API 返回的使用量"的,Snip 削减的 token 它感知不到。所以需要手动减去 snipTokensFreed,否则 AutoCompact 会在不该触发的时候触发。
Microcompact:重复工具结果去重
Microcompact 解决的是"一个工具被多次调用,结果被重复注入"的问题。
在 Agent 的循环中,同一个工具可能被连续调用多次(比如连续 Read 了 5 个文件)。每次调用都会在 messages 中追加一个 tool_result 消息。这些结果可能在后续轮次中不再需要,但它们仍然占据 token。
Microcompact 的做法是:按 tool_use_id 去重------同一个 tool_use_id 只保留最后一次结果。这比简单截断更智能------它是语义级的去重,不是位置级的。
另外,Microcompact 还利用了 Anthropic API 的 cache_edits 机制。这个机制允许客户端标记"哪些 tool_result 可以从缓存中删除",服务端在下次请求时会报告实际删除的 token 数(cache_deleted_input_tokens)。Microcompact 结合这个机制,不仅能减少发送的 token,还能精确追踪"省了多少"。
ContextCollapse:可恢复的上下文折叠
ContextCollapse 是四层压缩中唯一"可恢复"的一层。
它和 AutoCompact 的本质区别是:Collapse 是"折叠"而不是"压缩" 。折叠后的内容仍然以结构化的方式存储,只是读取时被投影为一个摘要。如果后续代码需要访问折叠区的内容,可以通过 projectView() 恢复------AutoCompact 做不到这点。
ContextCollapse 由 CONTEXT_COLLAPSE feature gate 控制。它的核心函数是 applyCollapsesIfNeeded()------检查是否有大段对话可以折叠,如果有就提交折叠日志。折叠后的 messagesForQuery 中,大段对话被替换为一个"折叠标记"。
这层还有一个关键用途:recoverFromOverflow()。当 API 返回 413(prompt too long)时,这是第一个被调用的恢复手段------把已折叠的内容"排空",释放更多空间。如果排水成功,continue 回到循环顶部重试;如果排水失败(没有可折叠的内容了),就交给下一层------Reactive Compact。
AutoCompact:自动摘要压缩
AutoCompact 是四层压缩的"核武器"------调用一个独立的 compact agent 来生成对话摘要。
下面这张图展示了 AutoCompact 的决策流程:什么时候触发、怎么计算阈值、失败了怎么办。

什么时候触发?
AutoCompact 的触发条件是:当前消息的估算 token 数超过了一个阈值。
阈值的计算公式是:
threshold = effectiveContextWindow - AUTOCOMPACT_BUFFER_TOKENS其中 effectiveContextWindow 是模型的上下文窗口大小减去输出预留(20,000 tokens),AUTOCOMPACT_BUFFER_TOKENS = 13,000。这个 buffer 的存在是为了"在真需要压缩之前就压缩"------不是在上下文窗口满了才动手,而是提前 13,000 tokens 就开始准备。
还有一个 CLAUDE_CODE_AUTO_COMPACT_WINDOW 环境变量可以覆盖窗口大小(只减不增),方便测试和调试。
怎么执行?
AutoCompact 不是直接在 query.ts 里写压缩逻辑------它调用一个独立的 compact agent 。这个 compact agent 是另一个 query() 调用(fork agent),接收当前对话历史,输出一个摘要。摘要生成有自己的 token 预算:最多 20,000 个输出 token。
压缩完成后,messagesForQuery 被替换为压缩后的精简版本------摘要消息 + 少量保留消息(最近几个 turn 的对话尾巴)。同时 autoCompactTracking 被重置(turnId = uuid()、turnCounter = 0),因为压缩后对话结构变了,需要新的计数周期。
下面这张图展示了压缩前后的消息结构对比------从 10+ 条完整消息变成了"摘要 + 保留尾巴"。
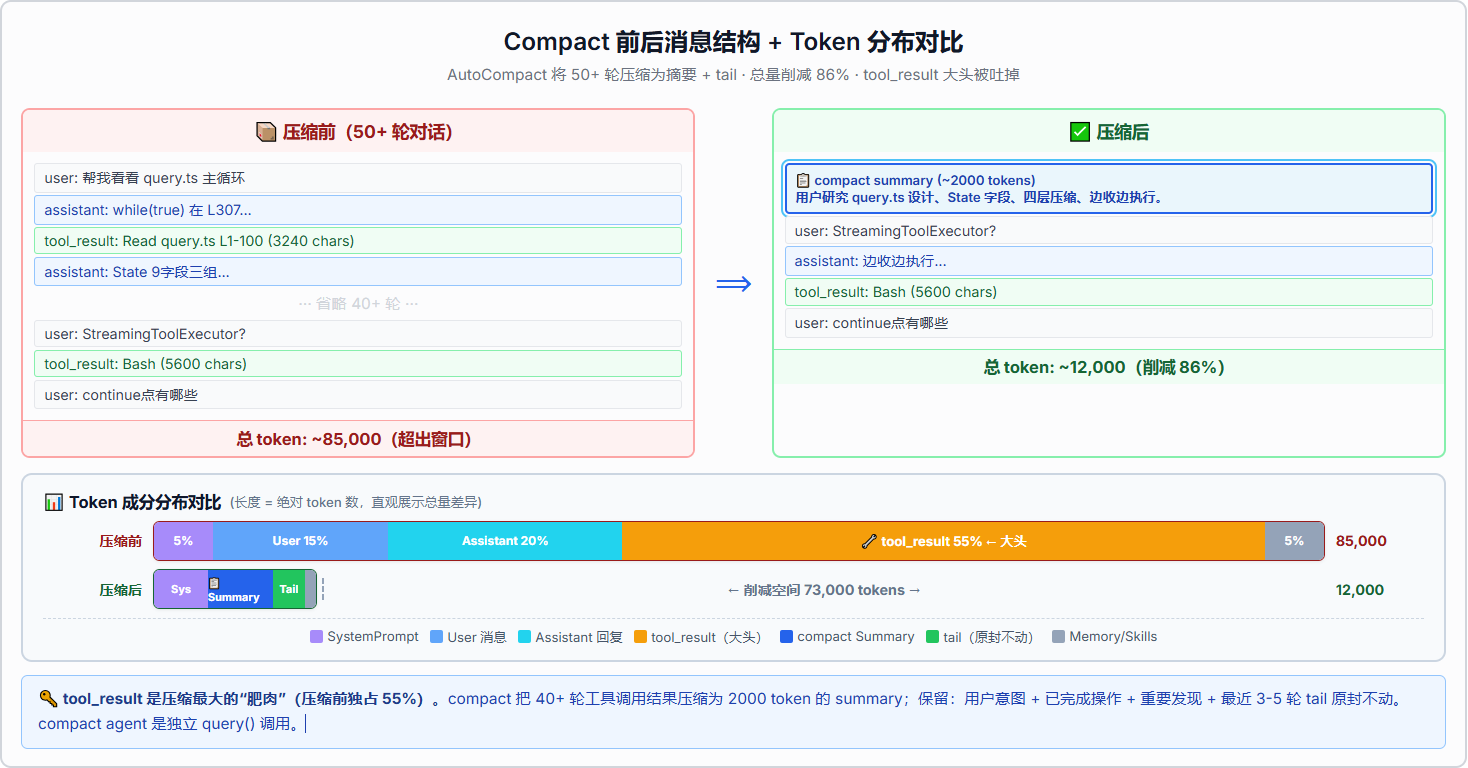
失败了怎么办?------Circuit Breaker
AutoCompact 不是每次都能成功。如果 compact agent 调用失败(比如 API 错误、生成的摘要太大),consecutiveFailures 计数器会递增。当 consecutiveFailures >= MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES (3) 时,circuit breaker 熔断------不再尝试自动压缩。
这个设计来自生产环境的数据:BQ 2026-03-10 报告显示,1,279 个 session 有 50+ 次连续失败(最多 3,272 次),每天浪费约 25 万次 API 调用。Circuit breaker 就是为这个场景设计的------与其无限重试,不如 3 次后放弃。
Reactive Compact:被动的最后防线
当四层压缩都拦不住 413 错误时,Reactive Compact 上场。
下面这张图展示了 Reactive Compact 的触发路径------从 413 错误被 withhold 开始,到恢复成功或放弃。
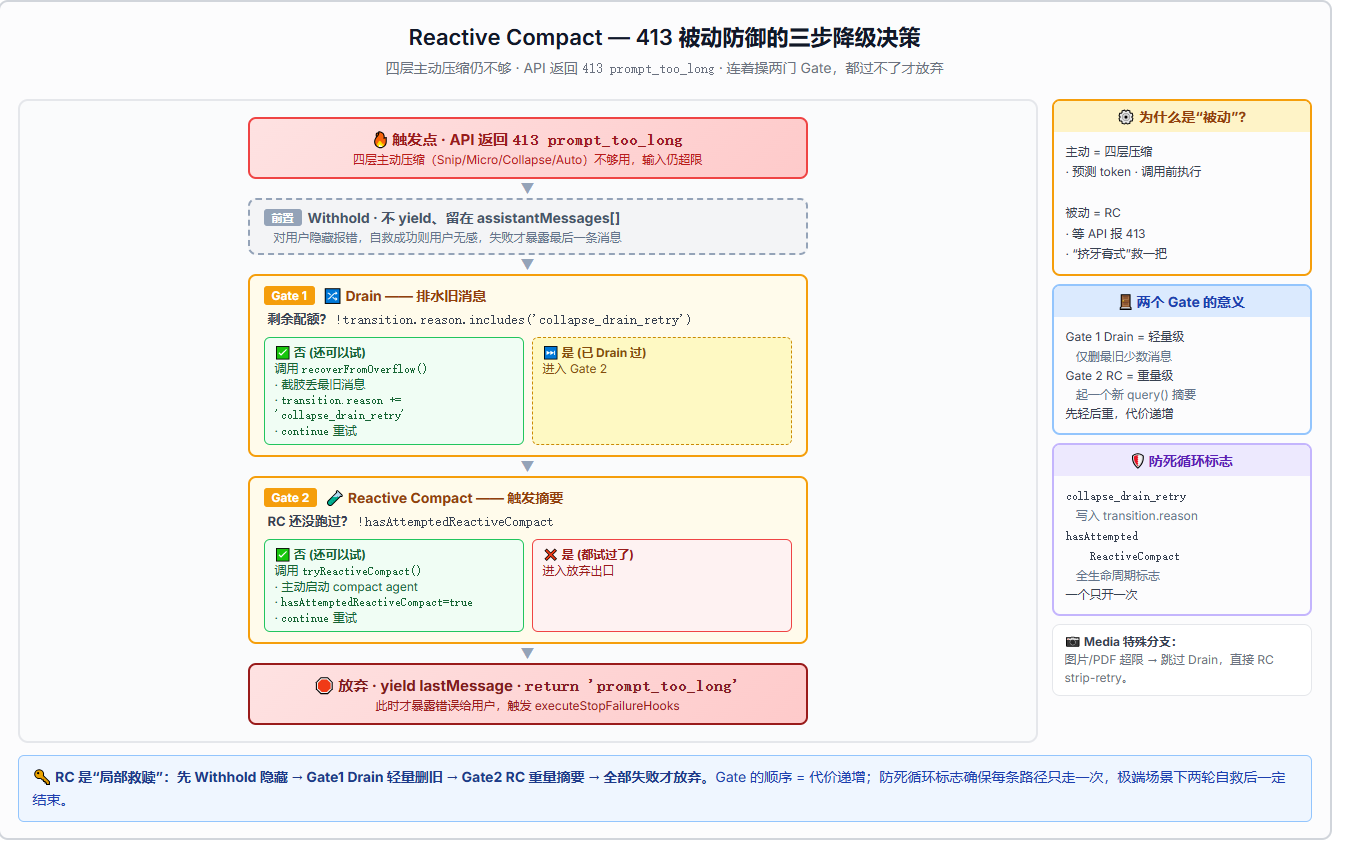
它的工作方式跟 AutoCompact 类似(也叫 compact agent 生成摘要),但有两个关键区别:
- 被动触发 :不是阈值判断,而是 API 返回 413 后才启动。413 错误先被
withhold(不 yield 给用户),然后依次尝试:Collapse Drain → Reactive Compact。 - 只尝试一次 :
hasAttemptedReactiveCompact标志位保证不会死循环。如果 RC 已经尝试过且仍然 413,就直接return { reason: 'prompt_too_long' }------不再重试。
这是一种"防御性"设计:主动压缩(AutoCompact)尽力而为,被动恢复(Reactive Compact)兜底。如果两者都拦不住,说明是真正的不可恢复错误------比如用户在单轮中塞入了太多图片。
Token Budget 的跨 Compact 传递
AutoCompact 之后,消息结构发生了根本性变化------从完整对话变成了"摘要 + 尾巴"。这会影响一个关键的追踪变量:task_budget.remaining。
task_budget 是服务端用来追踪"剩余预算"的机制------如果对话太长,服务端会限制轮次。在压缩之前,服务端能看到完整对话,自己数 token。压缩之后,服务端只看到摘要,需要客户端告诉它"压缩前的最后窗口用了多少 token"。
taskBudgetRemaining 就是这个"传递变量"------每次 compact 时,计算压缩前的 final context tokens,从 remaining 中减去。这保证了服务端的预算追踪在多次压缩后仍然准确。
typescript
// query.ts L508-514 --- task_budget 跨 compact 传递
if (params.taskBudget) {
const preCompactContext = finalContextTokensFromLastResponse(messagesForQuery)
taskBudgetRemaining = Math.max(
0,
(taskBudgetRemaining ?? params.taskBudget.total) - preCompactContext,
)
}各压缩层在模型上下文中的位置
四层压缩都在操作 messages 部分,但每一层操作的位置和粒度不同。理解它们在模型上下文中的位置,有助于判断压缩带来的影响。
从消息上下文管理篇的上下文全景图可知,发给模型的数据分为三块:
text
┌───────────────────────────────────────────────┐
│ system(System Prompt) ~30% ← 不压缩 │
├───────────────────────────────────────────────┤
│ messages(对话历史) ~60% ← 压缩目标 │
│ ├── 早期对话(远的历史) ← Snip 截断 │
│ ├── 中间对话(大段内容) ← Collapse 折叠 │
│ ├── 工具结果(重复内容) ← Microcompact │
│ └── 整体(超窗口时) ← AutoCompact │
├───────────────────────────────────────────────┤
│ tools(工具 Schema) ~10% ← 不压缩 │
└───────────────────────────────────────────────┘Snip 操作在 messages 尾部------它按 token 阈值从数组末尾往前数,砍掉超过阈值的部分。被砍掉的是"最老的消息",即模型视角中"最不相关"的上下文。代价是 Agent 可能"失忆"------这就是它由 feature gate 控制的原因。
Microcompact 操作在 messages 的 tool_result 区域 ------它遍历所有 tool_result Content Part,按 tool_use_id 合并。被压缩的是"旧的工具执行结果",不是整个对话。因为每个 tool_result 对应一个 tool_use,压缩后模型不会"失忆",只是看不到旧结果了------影响较小。
ContextCollapse 操作在 messages 的大段连续对话区------它把可折叠的段落投影为摘要标记,同时保留恢复能力。模型仍然知道"有过这段对话",但看不到细节------是四层中唯一在"保记忆"和"省 token"之间做平衡的。
AutoCompact 操作在整个 messages 数组------它在三层之后,如果总 token 仍然超过模型窗口,就调用 compact agent 把大部分消息替换为摘要。模型只能看到"压缩前发生过这些事"的简述,细节完全丢失。这也是为什么 AutoCompact 只在前三层都无能为力时才触发------它是"核武器"。
与消息上下文管理篇对比:消息上下文管理篇关注的是"发给模型的数据由哪几块组成",本文关注的是"在发给模型之前,对 messages 这块做了哪些预处理"。两块知识合在一起,才是消息从用户输入到 API 调用的完整生命周期。
本章小结
本文从两个维度拆解了 Agent 执行内核的 Pipeline 设计:
Pipeline 架构维度 :消息数组 messagesForQuery 流过四个处理站,每站可选跳过(条件跳站)、通过侧信道传递参数(跨站参数传递)、AutoCompact 触发时整个替换(短路重置)、413 错误时进入恢复路径(双路径设计)。这不是简单的函数调用链,而是一套有自适应能力的架构模式。
压缩功能维度------四个处理站各自做了什么:
- Snip(截断) 按 token 阈值砍掉旧消息------代价是"失忆",由 feature gate 控制。
- Microcompact(去重) 合并重复工具结果------语义级去重,不是位置级。
- ContextCollapse(折叠) 可恢复的语境投影------比直接删除更优雅。
- AutoCompact(摘要) 调用独立的 compact agent 生成摘要------削减 85%+ token,但有 circuit breaker 防死循环。
- Reactive Compact(被动) 当四层都拦不住 413 时的最后防线------只尝试一次。
这四层压缩和 Prompt Cache 机制是正交关系:压缩减少"发给 API 的 token 量",Cache 减少"API 处理这些 token 的计算量"。两者叠加,才是 Claude Code 能从 50 轮对话中省下 10 倍成本的原因。
下一姊妹篇 从 API 调用到安全退出(./04-Claude Code深度拆解-Agent执行内核-从API调用到安全退出.md) 将深入压缩完成后的完整链路------API 调用、流式工具执行、错误恢复、生命周期收尾。
系列导航:
本文属于 《Claude Code 源码 Deep Dive》 系列中「Agent 执行内核」命题的子篇章,专注于 Pipeline 与上下文压缩。
姊妹篇(可独立阅读):
如果这篇文章对你有帮助,欢迎点赞收藏 支持一下。如果你对 Claude Code 源码感兴趣,欢迎关注本系列 后续更新。有任何想法或疑问,欢迎评论区留言讨论 👋