将化学反应方程式序列化为SMILES 格式后,我们可以像处理文本字符串一样处理化学反应数据。图 展示了 BERT 模型在化学反应分类中的系统结构。整个流程如下:
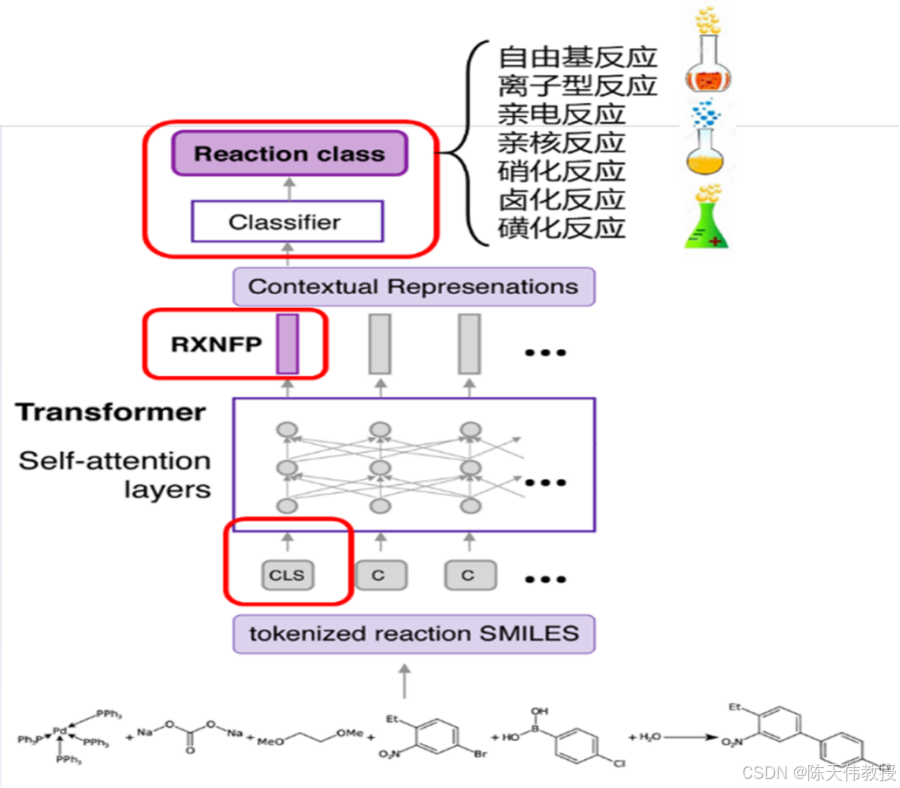
图 **:**基于 BERT 的化学反应分类。图片来源:Schwaller et al., 2021.
- 输入序列生成:将化学反应方程转换为 SMILES 格式,并在序列开头添加 CLS 符号,用于表示整个反应方程的特征。序列中间的">>"符号用于分隔反应物和生成物,类似于 BERT 处理自然语言文本时的 SEP符号。
- 序列编码:将 SMILES 序列输入 BERT 模型。通过多层 Transformer 编码,模型能够捕捉序列的上下文信息,并生成一个 CLS 向量作为整个反应方程的特征表示。
- 分类器训练:CLS 向量与已知化学反应类型的特征向量进行比较。参考与其最接近的反应类型,判断该化学反应属于哪一类。
研究人员在 13.2 万个化学反应上测试了该方法。结果显示:基于 BERT 的分类器达到了 98.2% 的分类准确率。传统方法的准确率仅 41.0%,远落后于BERT。这表明BERT 模型在捕捉复杂化学反应规律方面具有显著优势。
不仅如此,BERT 还能够识别影响化学反应分类的关键成分。在图 41.7中,阴影部分标出了 BERT 认为对分类结果起关键作用的化学成分,为化学家分析反应机理和特性提供了重要线索。
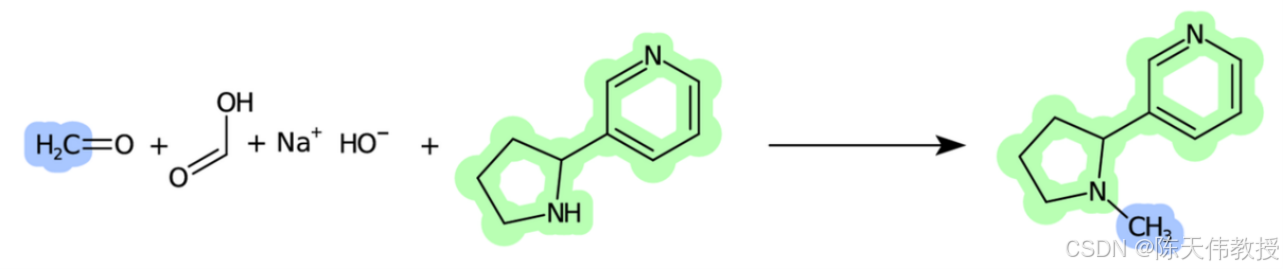
图 : 基于BERT 的分类预测可以定位化学反应中的关键成分。图中蓝色和绿色阴影部分对化学反应类型的判断起到了关键作用。图片来源:Schwaller et al., 2023.