6.1 排序模型的特征
6.1.1 用户画像 (User Profile)
- 用户ID(在召回、排序中做embedding);
- 人口统计学属性:性别、年龄;
- 账号信息:新老、活跃度......;
- 感兴趣的类目、关键词、品牌......
6.1.2 物品画像 (Item Profile)
- 物品ID(在召回、排序中做embedding);
- 发布时间(或者年龄);
- GeoHash(经纬度编码)、所在城市;
- 标题、类目、关键词、品牌......;
- 字数、图片数、视频清晰度、标签数......
- 内容信息量、图像美学。
6.1.3 用户统计特征
- 用户最近30天(7天、1天、1小时)的曝光数、点击数、点赞数、收藏数;
- 按照笔记图文/视频分桶(比如最近7天,该用户对图文笔记的点击率、对视频笔记的点击率);
- 按照笔记类目分桶(比如最近30天,用户对美妆笔记的点击率、对美食笔记的点击率、对科技数码笔记的点击率)。
6.1.4 物品统计特征
- 笔记最近30天(7天、1天、1小时)的曝光数、点击数、点赞数、收藏数;
- 按照受众用户性别、年龄、地域等分桶;
- 作者特征(发布笔记数、粉丝数、消费指标曝光数、点击数、点赞数、收藏数等)。
6.1.5 场景特征
- 用户定位GeoHash(经纬度编码)、城市;
- 当前时刻(分段,做embedding);
- 是否是周末、是否是节假日;
- 手机品牌、手机型号、操作系统(安卓、苹果用户点赞差异显著)。
6.1.6 特征处理
6.1.6.1 离线特征
做embedding。
包含用户ID、笔记ID、作者ID、类目、关键词、城市、手机品牌等。
6.1.6.2 连续特征
对于年龄、笔记字数、视频长度给等,做分桶,变成离散特征处理;
对于曝光数、点击率、点赞率等数值,做 log ( 1 + x ) \log(1+x) log(1+x),转化为点击率、点赞率等值,并作平滑。
6.1.7 特征覆盖率
- 很多特征无法覆盖100%样本(用户不填年龄、无法获取用户地理位置等);
- 提高特征覆盖率,可以让精排模型更精准。
- 当数据缺失时,默认值的设置也很重要。
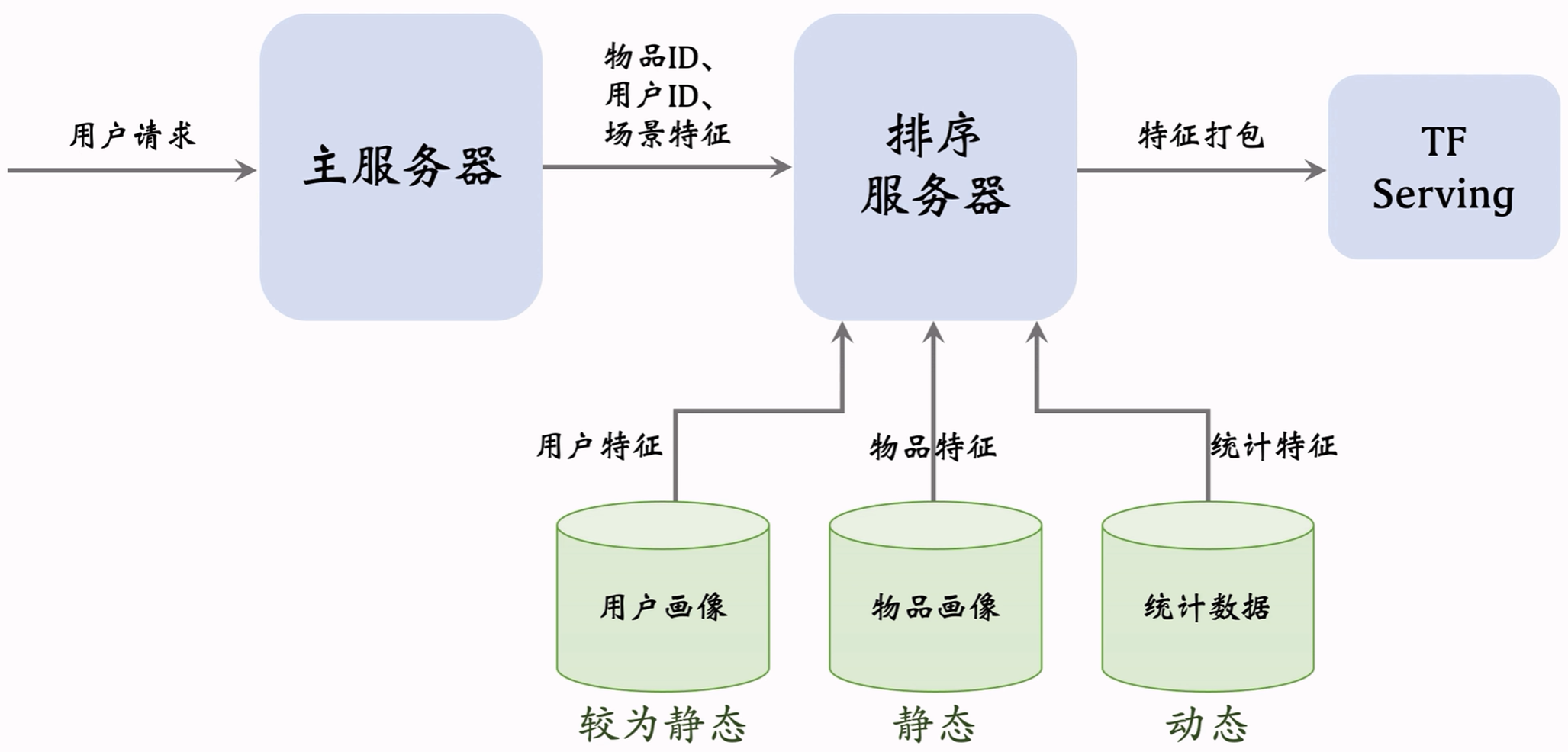
6.1.8 数据服务
一种简单的排序时数据流程:
6.2 粗排的三塔模型
6.2.1 三塔模型结构
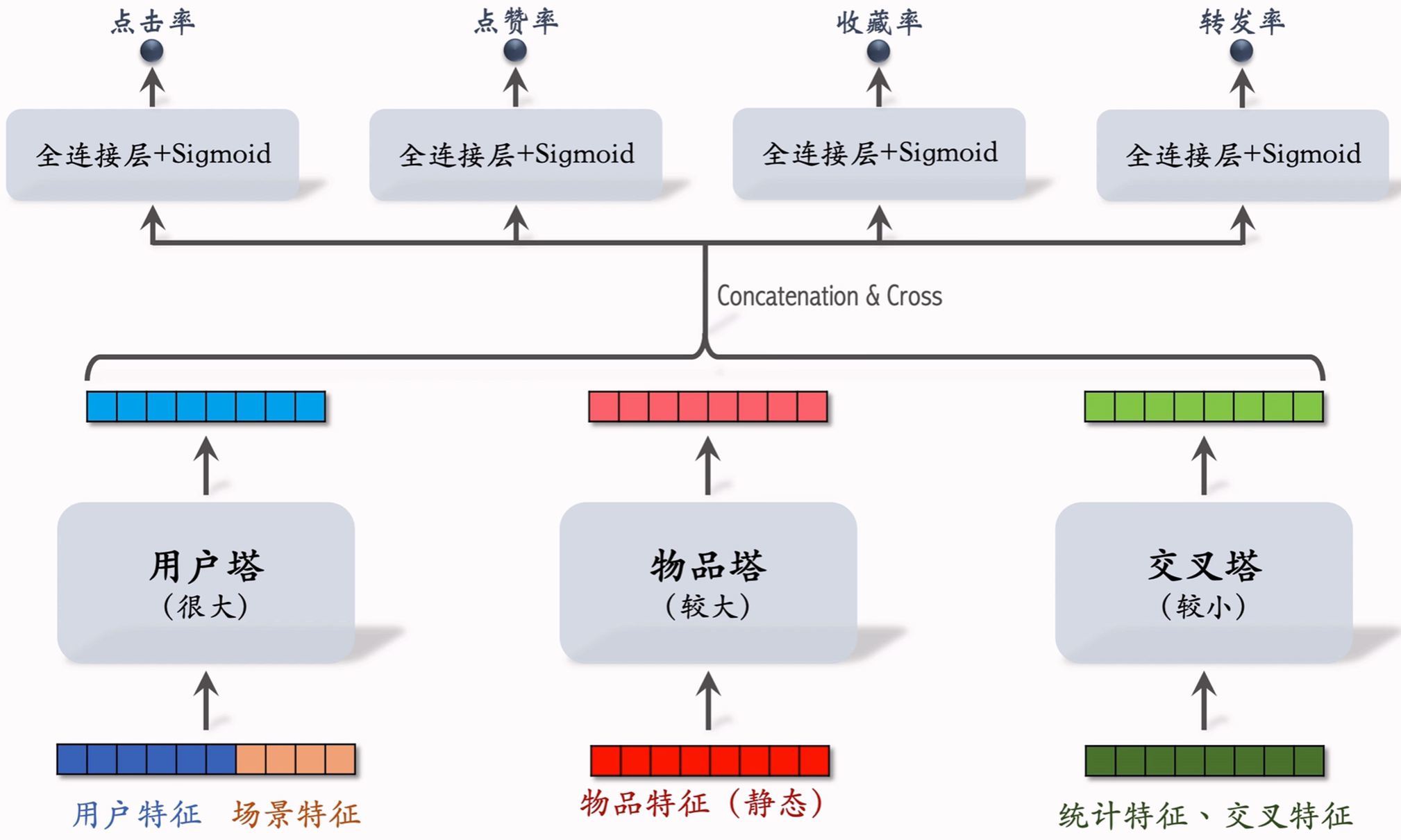
而对于模型上层:有 n n n个物品,模型上层就要做 n n n次推理,粗排推理的大部分计算量在上层。
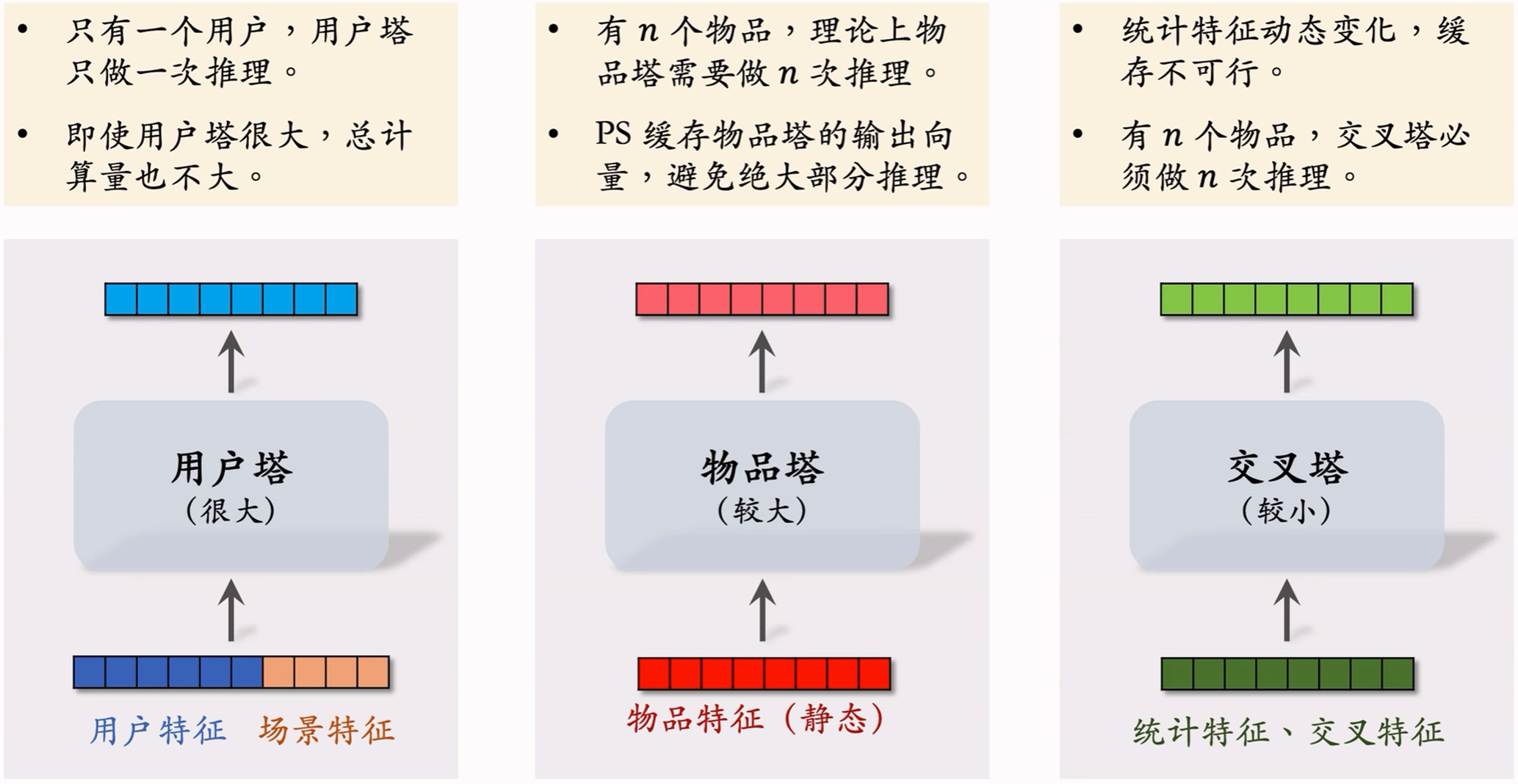
6.2.2 三塔模型推理
从多个数据源获取特征:
- 1个用户的画像、统计特征;
- n n n个物品的画像、统计特征。
用户塔只做1次推理,当物品塔未命中缓存时需要做推理,交叉塔必须做 n n n次推理。
上层网络做 n n n次推理,给 n n n个物品打分。