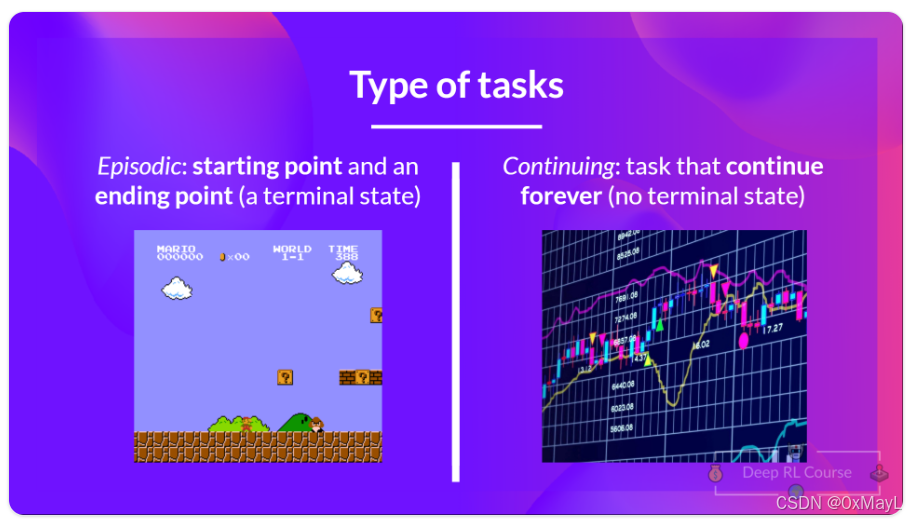
任务类型:单元式和持续型任务
- 分为单元式(Episodic)和持续型任务
- 单元式任务存在一个开始和结束状态
- 持续型任务没有结束状态。
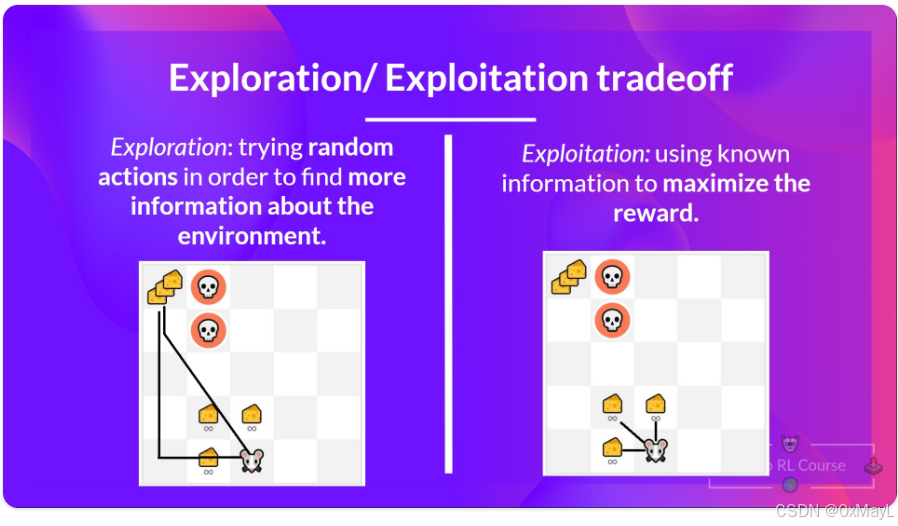
探索和利用
- 探索是通过尝试随机行动来探索环境,以获取更多关于环境的信息。
- 利用是利用已知信息以最大化回报。
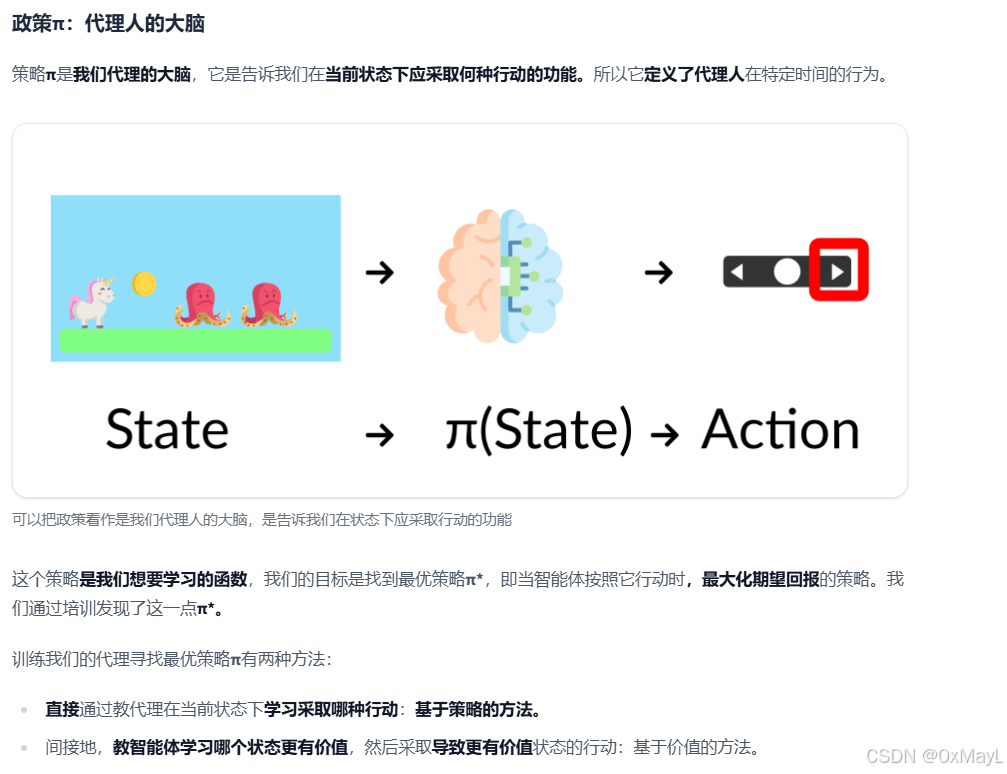
解决强化学习的两类方法
基于策略的方法
- 直接学习一个最佳的策略,然后根据策略指导行动,间接的让智能体选择有价值的状态
- 这个策略可能是确定性的(返回一个确定的动作),可能是随机的(返回一个动作函数的概率分布)。

基于价值的方法
-
在基于价值的方法中,我们不是学习策略函数,而是学习一个价值函数,将状态映射到处于该状态的期望值。
-
状态的价值是代理人在该状态开始并按照我们的策略行动时,能获得的预期贴现回报。
-
"按照我们的政策行事"只是意味着我们的政策"归属于价值最高的国家"。

深度强化学习中"深度"的含义
