有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主。
Python 爬虫 + RoBERTa 情感分析 + TF-IDF/LDA/NMF 文本挖掘 + Flask 可视化系统
1 项目整体介绍:从游客评论中看懂景区口碑
这套项目围绕三亚热门景区的游客评论展开,核心目标不是简单展示几个词云,而是把"评论采集、数据清洗、探索分析、深度学习情感识别、主题挖掘、关联规则、可视化系统"串成一条完整链路。游客评价本身是很真实的口碑数据,里面既有对风景、设施、交通、服务的直接反馈,也有对排队、价格、体验落差等问题的隐性表达。只看评分很容易忽略细节,只靠人工翻评论又效率太低,所以项目把自然语言处理和系统化展示结合起来,让评论数据真正变成可观察、可解释、可落地的分析结果。
项目选取的对象包括三亚亚特兰蒂斯水世界、亚龙湾热带天堂森林公园、天涯海角、蜈支洲岛、西岛、鹿回头风景区等典型景点。这些景区类型差异明显,有水上娱乐、海岛游玩、历史文化、山海观景等不同场景,适合用来做横向对比。最终形成的成果既包含模型分析结果,也包含前后端系统页面,对学生项目来说,展示效果会比单独的算法脚本更加完整。
整体技术栈以 Python 为主,数据侧使用 requests、Pandas、jieba、Pyecharts 等工具,模型侧使用 PyTorch、Hugging Face 预训练权重和迁移学习方案,文本挖掘部分引入 TF-IDF、LDA、NMF、Apriori 关联规则,系统侧通过 Flask 完成可视化结果集成。项目重点突出"算法+数据+系统"的组合路线,既有技术实现,也有直观界面。

2 数据采集:先把真实评论稳定拿下来
项目第一步是采集携程平台上的景区游客评论。评论字段不仅包括游客文本内容,还包括景区名称、用户昵称、评分、评论时间、点赞数、回复数、会员类型等信息。这些字段后续能够支撑多个角度的分析,例如评分对比、用户互动、会员类型分布、评论时间趋势和情感结果统计。
在采集过程中,普通请求很容易受到平台反爬机制影响。为提高稳定性,项目采用 headers 模拟、cookies 注入、自动延时、状态码判断和异常捕获等方式,让爬虫过程更加接近真实访问节奏。这里没有把爬虫写成"一次性脚本",而是考虑了日志记录、页面循环、异常跳过、结果保存等细节,能够体现一定的工程意识。
采集完成后,原始评论统一保存为 CSV 文件,再进入后续清洗和入库环节。整个采集流程的关键不在于"爬了多少",而在于字段是否完整、结构是否稳定、后续是否方便分析。项目最终获得约 2 万条原始评论数据,清洗后保留约 1.6 万条有效数据,为后面的情感模型和文本挖掘提供了数据基础。
图组 1 数据采集、清洗与数据库存储展示
|-------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
| 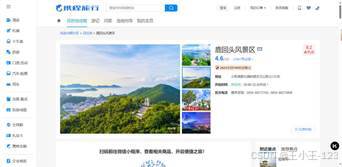 图 1 携程官网展示 |
图 1 携程官网展示 | 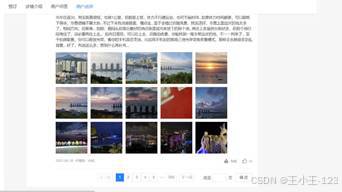 图 2 携程官网评论 |
图 2 携程官网评论 |
| 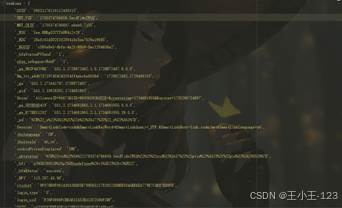 图 3 cookies注入 |
图 3 cookies注入 | 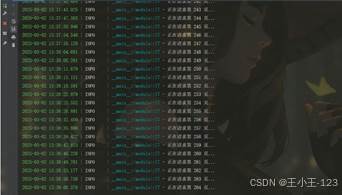 图 4 数据采集展示 |
图 4 数据采集展示 |
|  图 5 数据采集结果展示 |
图 5 数据采集结果展示 | 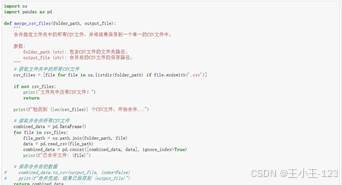 图 6 数据预处理 |
图 6 数据预处理 |
| 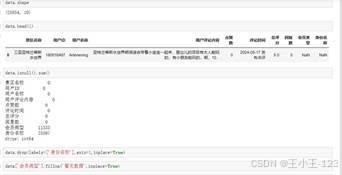 图 7 缺失值处理 |
图 7 缺失值处理 | 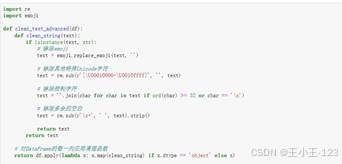 图 8 非法字符剔除 |
图 8 非法字符剔除 |
| 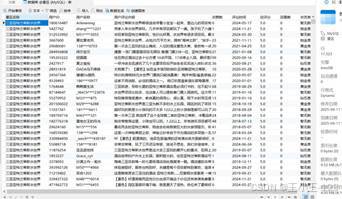 图 9 数据库存储展示 | |
图 9 数据库存储展示 | |
3 数据清洗与存储:让评论数据变得能分析
原始评论数据往往比较杂,直接拿来分析会出现很多问题,例如重复评论、空字段、表情符号、特殊 Unicode 字符、字段类型不统一等。项目用 Pandas 对各景区 CSV 文件进行批量合并,把多个景点的数据整合成一张总表,便于统一处理。
缺失值处理上,项目区分了不同字段的重要性。对于缺失比例高且后续分析价值不大的字段,直接删除;对于仍有保留意义的会员类型等字段,则采用填充方式处理,避免过度删除造成样本损失。重复值处理则用于保证评论样本的独立性,避免同一内容重复出现后影响词频、情感分布和主题结果。
文本字段还专门做了非法字符清洗。评论中常见表情、特殊符号和不可见字符,如果不处理,可能会影响模型推理、分词结果和数据库存储。项目通过 emoji 库和正则规则删除异常字符,最后将清洗后的结构化数据写入 MySQL,方便后续系统页面调用和结果展示。
4 EDA 探索分析:先用图表看整体口碑
完成数据入库后,项目先做了一轮 EDA 探索分析,目的是在进入深度学习模型前,先从评分、互动、时间、会员和词频角度快速看清数据特征。比如平均评分可以判断景区整体满意度,点赞和回复数量可以反映评论传播与互动情况,评论时间趋势可以观察旅游旺季和客流波动。
从评分结果看,多个景区的游客评价整体偏高,其中亚特兰蒂斯水世界接近满分,说明娱乐设施和体验项目较容易获得游客认可;天涯海角、西岛等景区评分相对低一些,但仍处于较高水平,说明问题更多集中在细节体验,而不是整体满意度严重不足。点赞和回复数据也显示,蜈支洲岛的传播度和互动热度比较突出。
评论文本分析则进一步说明不同景区的定位差异。鹿回头的关键词更偏"风景、夜景、山顶、俯瞰",海岛类景区更容易出现"潜水、海水、沙滩、项目"等词,文化类景区则会出现更强的地标印象。通过这些基础图表,读者可以先建立直观印象,再看后续模型输出时也更容易理解结果。
图组 2 评分、互动、时间趋势与词云分析展示
|---------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| 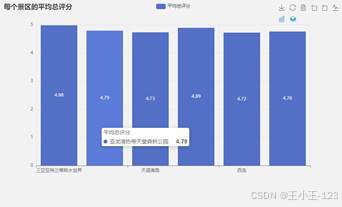 图 10 各景区的平均总评分 |
图 10 各景区的平均总评分 |  图 11 各景区的总点赞数分布 |
图 11 各景区的总点赞数分布 |
| 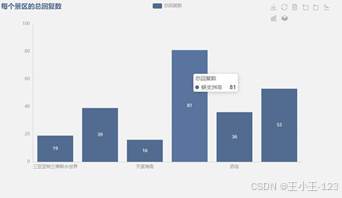 图 12 每一个景区的总回复数 |
图 12 每一个景区的总回复数 | 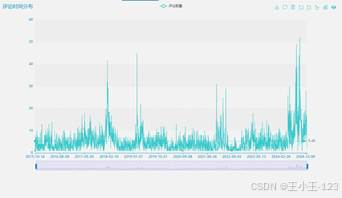 图 13 景区评论时间趋势分布 |
图 13 景区评论时间趋势分布 |
| 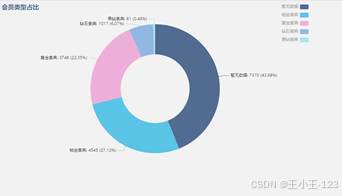 图 14 会员类型占比 |
图 14 会员类型占比 |  图 15 用户名称词云图展示 |
图 15 用户名称词云图展示 |
|  图 16 所有景区词云展示 |
图 16 所有景区词云展示 | 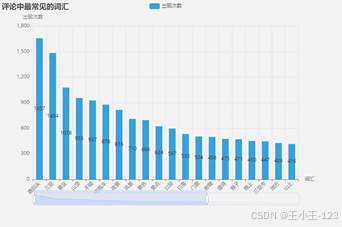 图 17 词频统计分析(以鹿回头为例) |
图 17 词频统计分析(以鹿回头为例) |
|  图 18 每一个景区的词云展示 | |
图 18 每一个景区的词云展示 | |
5 深度学习情感分析:用预训练模型做细粒度识别
情感分析部分是项目的核心。传统中文情感工具往往只能给出正负面或简单分值,面对旅游评论中"喜欢但有吐槽""体验一般但景色很好""排队久但项目好玩"这类复杂表达时,解释力度不够。项目采用 Hugging Face 中文预训练模型 chinese-roberta-wwm-ext,并结合微博情感标注语料进行监督微调,让模型具备更细粒度的情感识别能力。
情感标签体系包括 none、like、disgust、sadness、happy、angry、surprise、fear 等类别。模型训练阶段用 PyTorch 构建 Dataset,将文本转为 input_ids 和 attention_mask,按照训练集与验证集划分进行微调。训练过程中使用 AdamW 优化器、学习率预热、早停机制等策略,尽量减少过拟合,让模型能够稳定迁移到景区评论场景。
在推理阶段,项目同时设计了单条预测和批量预测两种方式。单条预测便于调试,批量预测适合处理大量评论。通过 torch.no_grad() 关闭梯度计算,能够减少显存和内存占用;同时根据 CUDA 可用性自动选择 CPU 或 GPU,提高部署适配性。最终输出的情感标签再与景区名称关联统计,生成每个景区的情感分布图。
图组 3 预训练模型加载、微调与情感预测流程展示
|-------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------|
|  图 19 hugging_face 预训练权重下载 |
图 19 hugging_face 预训练权重下载 |  图 20 模型加载 |
图 20 模型加载 |
| 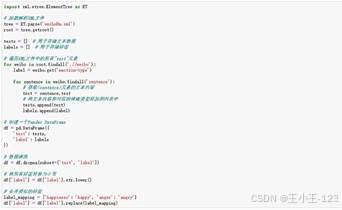 图 21 语料库数据加载 |
图 21 语料库数据加载 | 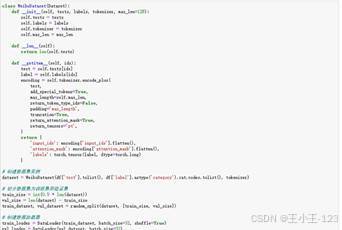 图 22 模型微调代码展示 |
图 22 模型微调代码展示 |
| 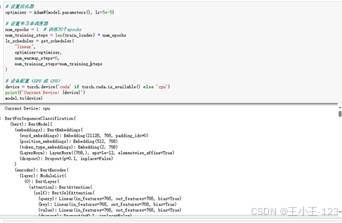 图 23 模型建立代码 |
图 23 模型建立代码 | 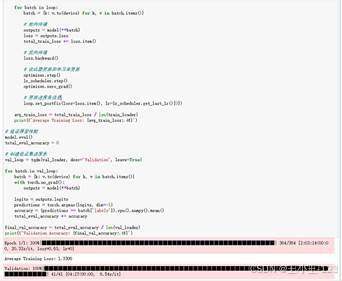 图 24 模型训练展示 |
图 24 模型训练展示 |
|  图 25 数据的加载 |
图 25 数据的加载 |  图 26 情感分析代码 |
图 26 情感分析代码 |
|  图 27 情感分析预测代码 |
图 27 情感分析预测代码 | 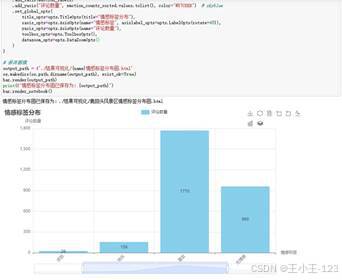 图 28 情感分析可视化分布 |
图 28 情感分析可视化分布 |
6 情感结果展示:不同景区的游客情绪并不一样
从情感结果看,"喜欢"标签在多个景区中占据主导位置,说明三亚热门景区整体口碑较好。亚特兰蒂斯水世界积极情绪最明显,"喜欢"和"快乐"占比较高,负面情绪非常少,和它较高的评分结果相互印证。蜈支洲岛同样呈现较强的积极倾向,游客对自然风光和游玩项目的认可度较高。
天涯海角、西岛、鹿回头等景区中,"无情感"标签相对突出。这类评论并不一定代表差评,更像是游客体验比较平淡,或者评价内容偏描述性,没有表达明显强烈情绪。对于景区运营来说,这种结果也很有价值:如果一个景区很少引发"快乐、惊喜、喜欢"等强情绪,就说明可以在互动项目、线路设计、服务细节和传播亮点上继续优化。
情感分布对比图把多个景区放在一起看,能够更直观地看出差异。单独看某个景区可能只知道"总体不错",对比以后才能发现谁更能激发积极情绪,谁的评论更平淡,谁存在少量负向反馈。这也是项目比较适合做展示的地方:图表一出来,核心结论就非常直观。
图组 4 各景区情感分布结果展示
|-------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
| 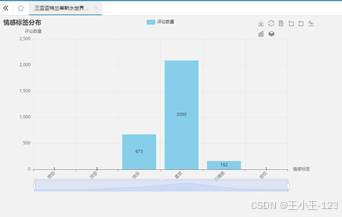 图 29 三亚亚特兰蒂斯水世界情感分布 |
图 29 三亚亚特兰蒂斯水世界情感分布 | 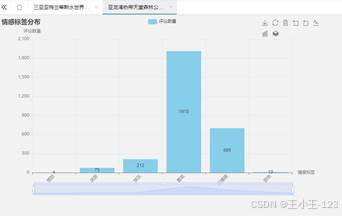 图 30 亚龙湾热带天堂公园情感分布 |
图 30 亚龙湾热带天堂公园情感分布 |
| 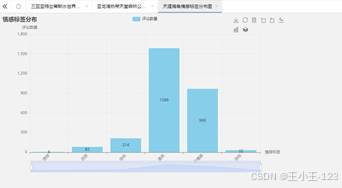 图 31 天涯海角情感分布 |
图 31 天涯海角情感分布 | 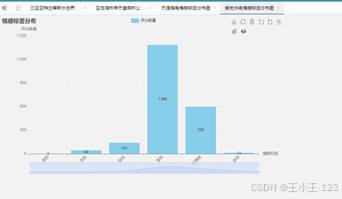 图 32 蜈支洲岛情感分布 |
图 32 蜈支洲岛情感分布 |
| 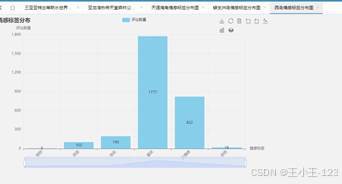 图 33 西岛情感分布 |
图 33 西岛情感分布 | 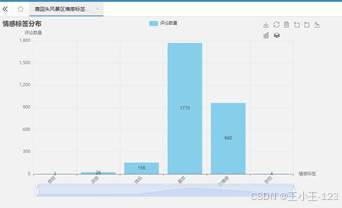 图 34 鹿回头情感分布 |
图 34 鹿回头情感分布 |
| 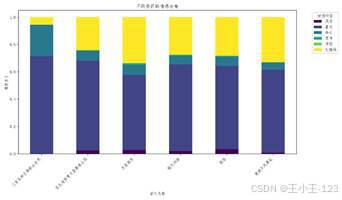 图 35 不同景区情感分布对比 | |
图 35 不同景区情感分布对比 | |
7 关键词、主题与关联规则:把评论里的关注点挖出来
情感分析告诉我们游客大致是什么情绪,但还需要知道游客为什么会这样评价。因此项目继续做了关键词提取、主题建模和关联规则分析。关键词部分使用标准 TF-IDF 与平滑 TF-IDF 两套方案进行对比,既能找出高频重要词,也能避免个别稀有词权重过高造成误导。
以鹿回头风景区为例,TF-IDF 结果中"鹿回头、三亚、山顶、夜景、风景"等词具有明显代表性,说明游客对景区的核心认知集中在观景、夜景和城市俯瞰体验。平滑 TF-IDF 后,关键词得分分布更加均衡,能够更稳定地反映评论真实重点。对学生项目来说,这种对比设计比只放一个词云更有说服力。
主题分析部分同时采用 LDA 与 NMF。通过一致性得分确定主题数量,再观察主题词云,可以把评论拆成不同的语义方向,例如地理景观类主题和游览体验类主题。关联规则部分则利用 Apriori 寻找词语之间的共现关系,并绘制网络图。网络中心节点、边权重和关键词群落可以帮助我们理解游客评价中哪些词经常一起出现,比如"鹿回头"与"三亚、风景、夜景、景区"等词之间的联系。
图组 5 关键词提取、主题分析与关联规则展示
|------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
| 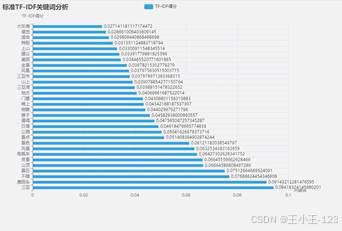 图 36 标准tf-idf关键词分析 |
图 36 标准tf-idf关键词分析 |  图 37 标准TF-IDf关键词词云 |
图 37 标准TF-IDf关键词词云 |
| 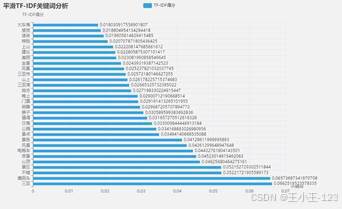 图 38 平滑TF-IDF关键词分析 |
图 38 平滑TF-IDF关键词分析 |  图 39 平滑关键词词云 |
图 39 平滑关键词词云 |
| 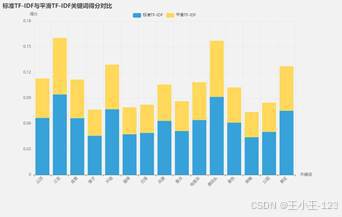 图 40 对比分析 |
图 40 对比分析 | 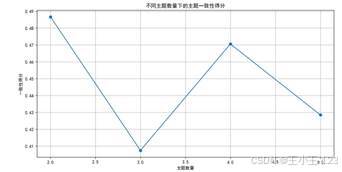 图 41 一致性得分 |
图 41 一致性得分 |
| 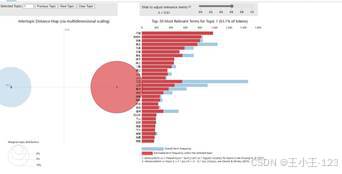 图 42 LDA主题1 |
图 42 LDA主题1 | 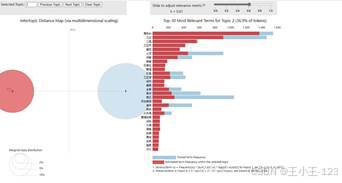 图 43 LDA主题2 |
图 43 LDA主题2 |
|  图 44 NFM主题1词云展示 |
图 44 NFM主题1词云展示 |  图 45 NMF主题2词云展示 |
图 45 NMF主题2词云展示 |
| 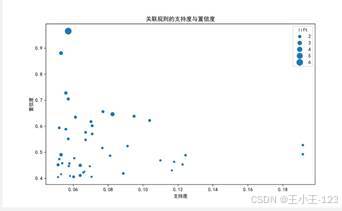 图 46 关联规则的支持度和置信度 |
图 46 关联规则的支持度和置信度 |  图 47 绘图实现代码 |
图 47 绘图实现代码 |
| 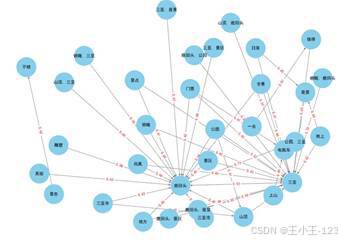 图 48 评论关联规则网络图 | |
图 48 评论关联规则网络图 | |
8 可视化系统:把分析结果做成可访问页面
项目最后通过 Flask 搭建可视化系统,把前面的 EDA 图表、情感分析结果、关键词分析、主题结果和关联规则结果集中展示。系统包含登录、注册、结果查看、个人信息更新、主题切换、全屏展示等页面,不是单纯把图片堆在文件夹里,而是通过 Web 形式组织起来,方便演示和后续扩展。
从系统展示角度看,登录注册页面体现基础用户管理,可视化页面用于集中查看图表和分析结果,主题切换和全屏功能则增强展示效果。对于课程设计、毕业设计或项目答辩来说,这类系统页面非常重要,因为评审或读者往往更容易通过界面判断项目完成度。
整个系统仍然具备继续升级的空间。例如可以增加按景区筛选、按时间范围筛选、评论原文追溯、负面评论预警、模型在线预测、数据自动更新、图表动态交互和后台管理等功能。如果继续深化,还可以加入大模型摘要,让系统自动生成"景区口碑日报"或"游客关注问题清单",进一步增强实用性。
图组 6 Flask 可视化系统界面展示
|--------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|
|  图 49 系统的登陆界面展示 |
图 49 系统的登陆界面展示 |  图 50 注册功能展示 |
图 50 注册功能展示 |
|  图 51 登陆成功展示 |
图 51 登陆成功展示 |  图 52 可视化结果展示 |
图 52 可视化结果展示 |
|  图 53 可视化结果展示 |
图 53 可视化结果展示 |  图 54 个人信息更新展示 |
图 54 个人信息更新展示 |
|  图 55 主题切换展示 |
图 55 主题切换展示 |  图 56 全屏展示 |
图 56 全屏展示 |
9 项目亮点与可扩展方向
这个项目最值得展示的地方,是没有只停留在单一技术点上。它从真实旅游评论切入,先解决数据来源,再解决清洗存储,再用图表做探索,接着用预训练模型做情感识别,最后通过文本挖掘和可视化系统完成展示闭环。每一个环节都能单独讲清楚,串起来又是一套完整的数据分析应用。
如果作为学生项目,它的包装空间比较大:可以强调旅游口碑监测、景区服务改进、游客体验识别、评论情感分析、自然语言处理平台、景区舆情辅助决策等方向。展示时不需要把所有代码细节都展开,重点突出"能采集、能清洗、能分析、能建模、能展示"这条主线,就能让项目看起来更完整。
后续扩展可以从三个方向推进。第一是数据层面,增加更多城市和更多平台的评论数据,形成跨景区、跨区域对比;第二是模型层面,加入更强的中文语义模型或大模型摘要能力,提升评论理解深度;第三是系统层面,完善后台管理、自动任务和在线预测,让它从展示型系统逐步变成可持续运行的数据分析平台。
每文一语
思考越多行动越缓慢,在思考中沉下心慢慢前行