关于卷积,网络上有很多解释的文章,从各种各样的角度,网络上看到一篇文章觉得不错,先从这里入手,至于归结到数学还是物理内容,都涉及到吧,而且最近很火的人工智能的卷积神经网络也涉及到卷积。先从这里入手吧。
原文:https://colah.github.io/posts/2014-07-Understanding-Convolutions/
理解卷积
从掉落的小球中学到的教训
设想我们把一个球从某个高度掉落到地面上,它只在一个维度上运动。如果你将球掉落,然后从它落地点的上方再次掉落,球总共移动距离 ccc 的概率是多少?
让我们分解一下。第一次掉落后,它将以概率 f(a)f(a)f(a) 落在距离起点 aaa 单位远的地方,其中 fff 是概率分布。
在第一次掉落后,我们捡起球,从第一次落地点上方的另一个高度再次掉落。球从新起点滚动 bbb 单位远的概率是 g(b)g(b)g(b),其中 ggg 可能是不同的概率分布(如果从不同高度掉落)。
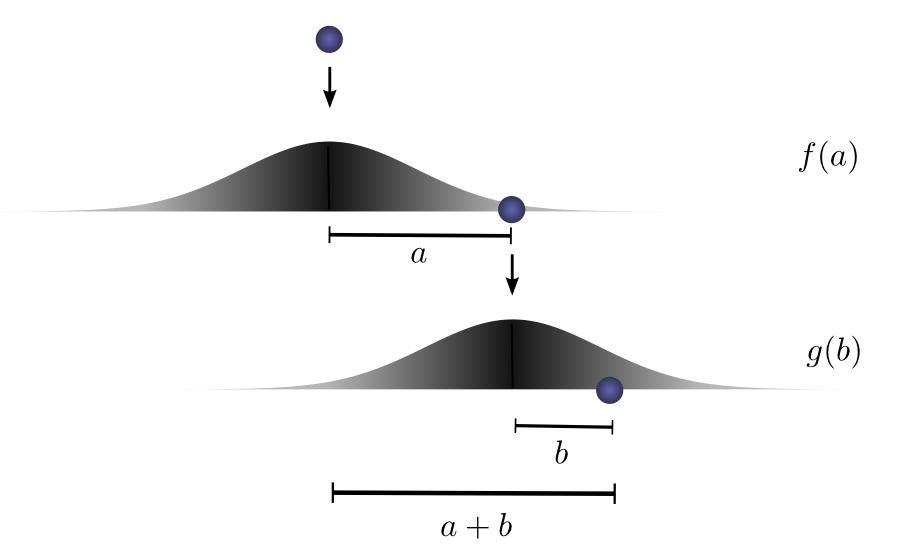
如果我们固定第一次掉落的结果,知道球移动了距离 aaa,那么要使球总共移动距离 ccc,第二次滚动的距离也固定为 bbb,其中 a+b=ca+b=ca+b=c。因此这件事发生的概率就是 f(a)⋅g(b)f(a) \cdot g(b)f(a)⋅g(b)。
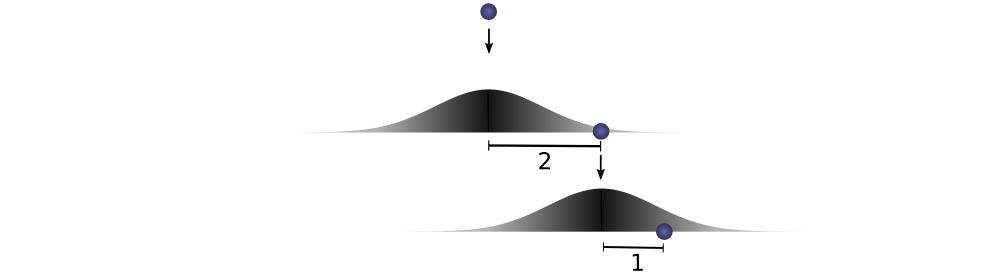
让我们用一个具体的离散例子来思考。我们希望总距离 ccc 为 3。如果第一次滚动 a=2a=2a=2,第二次必须滚动 b=1b=1b=1 才能达到总距离 a+b=3a+b=3a+b=3。这种情况的概率是 f(2)⋅g(1)f(2) \cdot g(1)f(2)⋅g(1)。
然而,这不是达到总距离 3 的唯一方式。球可以第一次滚 1 单位,第二次滚 2 单位;或者第一次滚 0 单位,第二次滚 3 单位。只要 aaa 和 bbb 相加等于 3,任何组合都可以。
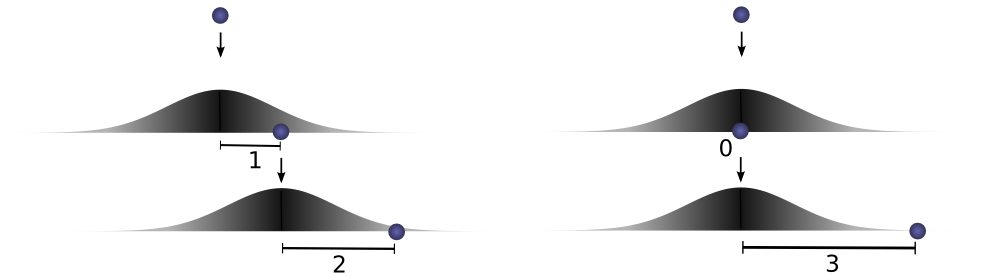
对应的概率分别是 f(1)⋅g(2)f(1) \cdot g(2)f(1)⋅g(2) 和 f(0)⋅g(3)f(0) \cdot g(3)f(0)⋅g(3)。
为了求出球达到总距离 ccc 的总可能性,我们不能只考虑达到 ccc 的一种可能方式。相反,我们考虑将 ccc 分割成两次掉落 aaa 和 bbb 的所有可能方式,并对每种方式的概率求和:
...f(0)⋅g(3)+f(1)⋅g(2)+f(2)⋅g(1)...\ldots f(0)\cdot g(3) + f(1)\cdot g(2) + f(2)\cdot g(1) \ldots...f(0)⋅g(3)+f(1)⋅g(2)+f(2)⋅g(1)...
我们已经知道,对于 a+b=ca+b=ca+b=c 的每种情况,其概率就是 f(a)⋅g(b)f(a) \cdot g(b)f(a)⋅g(b)。因此,对 a+b=ca+b=ca+b=c 的每个解求和,我们可以将总可能性表示为:
∑a+b=cf(a)⋅g(b)\sum_{a+b=c} f(a) \cdot g(b)∑a+b=cf(a)⋅g(b)
结果证明,我们实际上是在做卷积 !特别是,fff 和 ggg 的卷积在 ccc 处的值定义为:
(f∗g)(c)=∑a+b=cf(a)⋅g(b)(f*g)(c) = \sum_{a+b=c} f(a) \cdot g(b)(f∗g)(c)=∑a+b=cf(a)⋅g(b)
如果我们代入 b=c−ab = c - ab=c−a,我们得到:
(f∗g)(c)=∑af(a)⋅g(c−a)(f*g)(c) = \sum_{a} f(a) \cdot g(c-a)(f∗g)(c)=∑af(a)⋅g(c−a)
这就是卷积的标准定义。
为了更具体地理解这一点,我们可以从球可能落地的位置来思考。第一次掉落后,它将以概率 f(a)f(a)f(a) 落在中间位置 aaa。如果它落在 aaa,它将以概率 g(c−a)g(c-a)g(c−a) 落在位置 ccc。
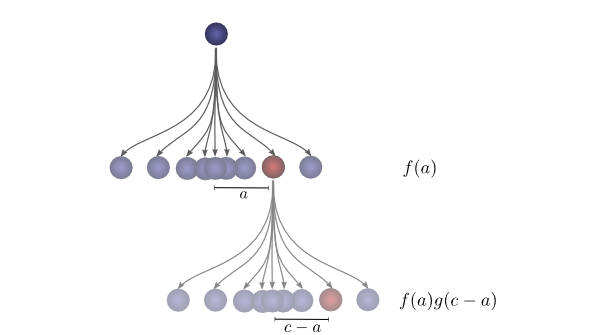
为了得到卷积,我们考虑所有中间位置的贡献。
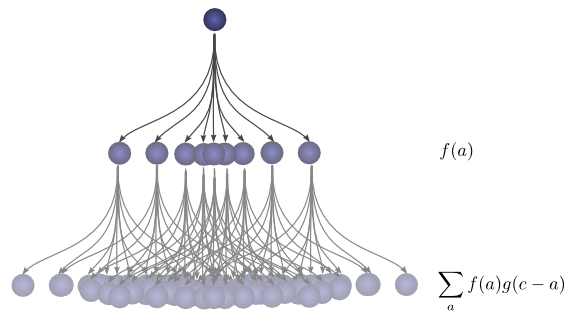
可视化卷积
有一个很好的技巧可以帮助人们更容易地思考卷积。
首先,一个观察。假设球从起点滚动一定距离 xxx 的概率是 f(x)f(x)f(x)。那么,之后,它从落地点往回滚动距离 xxx 的概率就是 f(−x)f(-x)f(−x)。
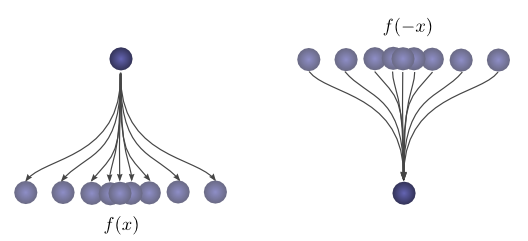
如果我们知道球在第二次掉落后落在位置 ccc,那么它之前的位置是 aaa 的概率是多少?
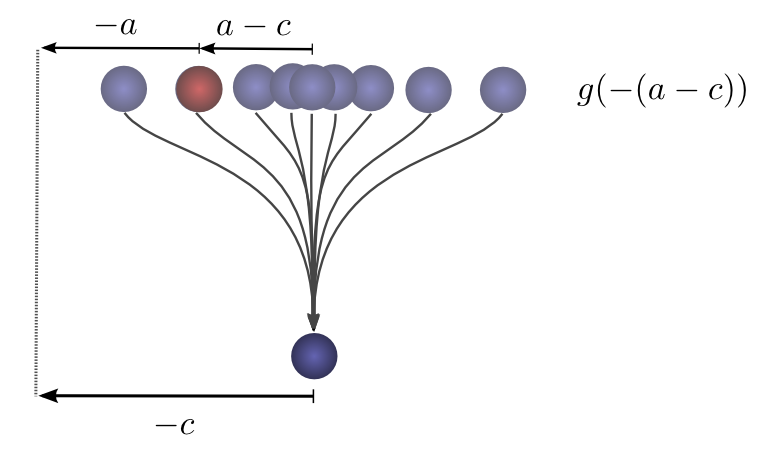
所以之前位置是 aaa 的概率是 g(−(a−c))=g(c−a)g(-(a-c)) = g(c-a)g(−(a−c))=g(c−a)。
现在,考虑每个中间位置对球最终落在 ccc 的概率贡献。我们知道第一次掉落将球置于中间位置 aaa 的概率是 f(a)f(a)f(a)。我们也知道,如果它最终落在 ccc,它之前位于 aaa 的概率是 g(c−a)g(c-a)g(c−a)。
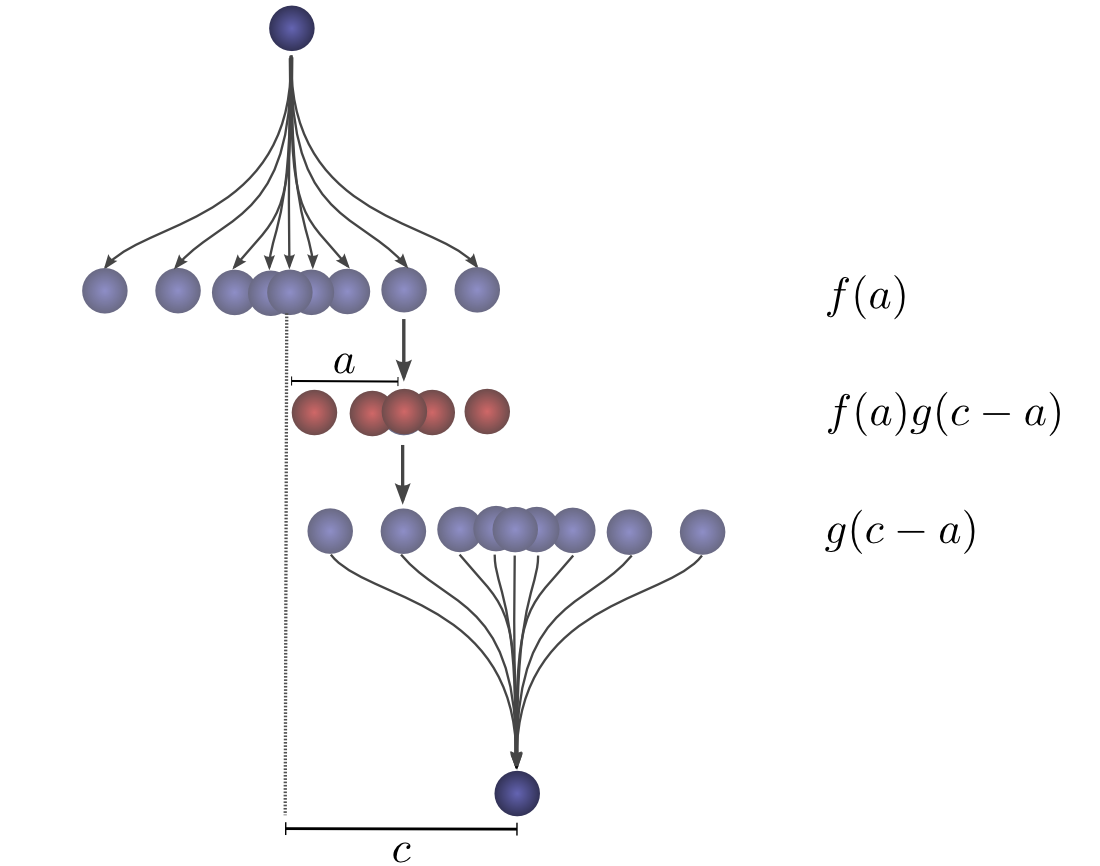
对 aaa 求和,我们就得到了卷积。
这种方法的优势在于,它允许我们在一张图中可视化卷积在值 ccc 处的计算。通过移动下半部分,我们可以计算卷积在其他 ccc 值处的结果。这使我们能够整体地理解卷积。
例如,我们可以看到当两个分布对齐时,卷积达到峰值。
而当分布之间的交集变小时,卷积缩小。
通过在动画中使用这个技巧,真的可以直观地理解卷积。
下面,我们能够可视化两个盒状函数的卷积:
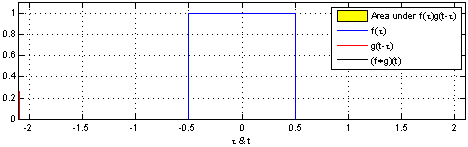
有了这个视角,很多东西变得更加直观。
让我们考虑一个非概率的例子。卷积有时用于音频处理。例如,人们可能会使用一个有两个尖峰、其他地方为零的函数来制造回声。当我们的双尖峰函数滑动时,一个尖峰首先击中时间点,将该信号添加到输出声音中,随后,另一个尖峰跟随,添加第二个延迟的副本。
高维卷积
卷积是一个极其通用的概念。我们也可以在更高维度中使用它。
让我们再次考虑掉落小球的例子。现在,当它掉落时,它的位置不仅在一个维度上移动,而是在两个维度上移动。
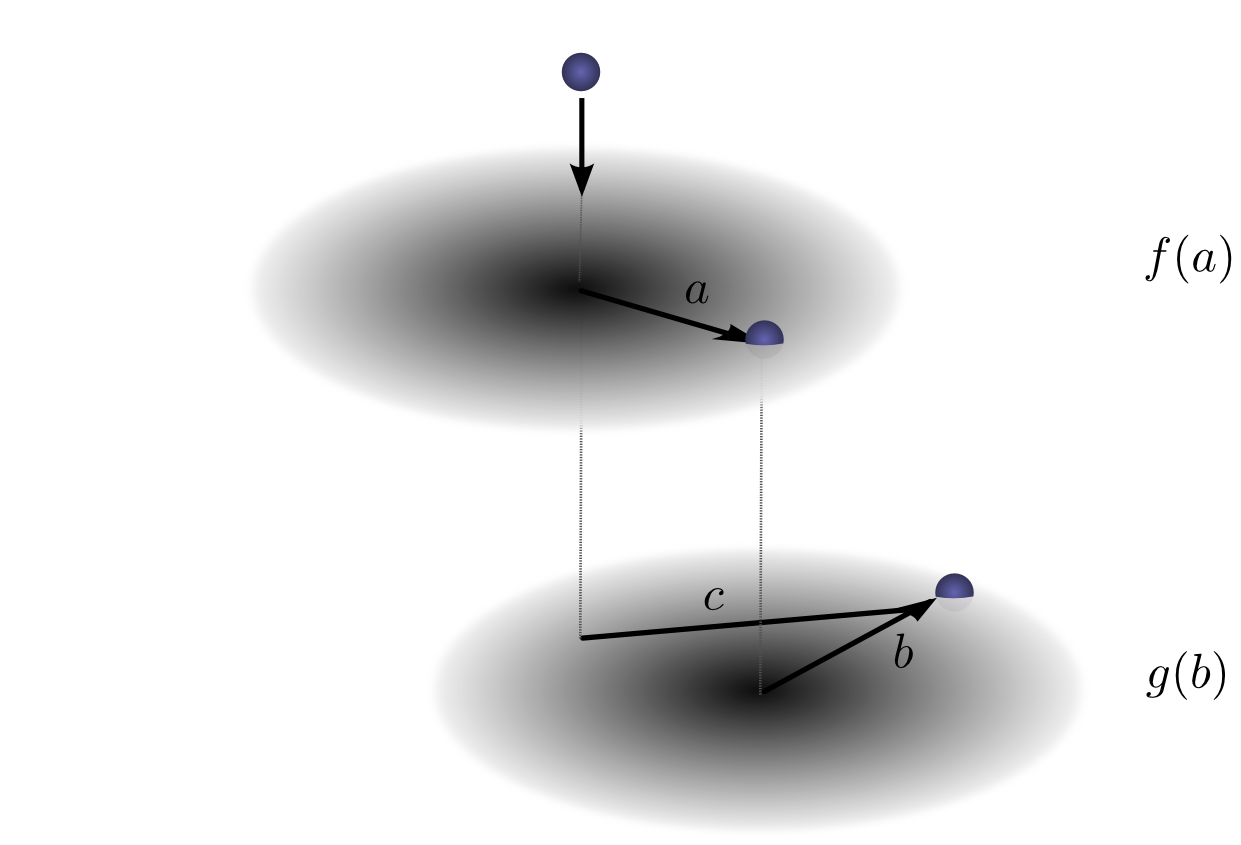
卷积与之前相同:
(f∗g)(c)=∑a+b=cf(a)⋅g(b)(f*g)(c) = \sum_{a+b=c} f(a) \cdot g(b)(f∗g)(c)=∑a+b=cf(a)⋅g(b)
只不过,现在 aaa、bbb 和 ccc 是向量。更明确地说,
(f∗g)(c1,c2)=∑a1+b1=c1a2+b2=c2f(a1,a2)⋅g(b1,b2)(f*g)(c_1, c_2) = \sum_{\substack{a_1+b_1=c_1 \\ a_2+b_2=c_2}} f(a_1,a_2) \cdot g(b_1,b_2)(f∗g)(c1,c2)=∑a1+b1=c1a2+b2=c2f(a1,a2)⋅g(b1,b2)
或者用标准定义:
(f∗g)(c1,c2)=∑a1,a2f(a1,a2)⋅g(c1−a1,c2−a2)(f*g)(c_1, c_2) = \sum_{a_1, a_2} f(a_1, a_2) \cdot g(c_1-a_1, c_2-a_2)(f∗g)(c1,c2)=∑a1,a2f(a1,a2)⋅g(c1−a1,c2−a2)
就像一维卷积一样,我们可以把二维卷积看作是将一个函数滑过另一个函数,相乘并相加。
这种操作的一个常见应用是图像处理。我们可以将图像视为二维函数。许多重要的图像变换都是卷积,即将图像函数与一个称为"核"(kernel)的很小、很局部的函数进行卷积。
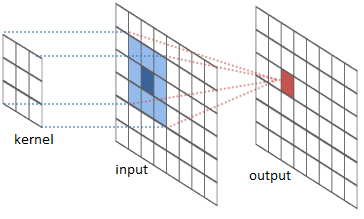
核滑动到图像的每个位置,计算一个新像素值,作为它所覆盖像素的加权求和。
例如,通过对 3×3 的像素框取平均,我们可以模糊图像。为此,我们的核在框内每个像素上取值 1/91/91/9,

我们也可以通过在两个相邻像素上取值 −1-1−1 和 111,其他地方取 0 来检测边缘。也就是说,我们减去两个相邻像素。当并排像素相似时,这给我们近似为零的结果。然而在边缘处,相邻像素在垂直于边缘的方向上差异很大。

GIMP 文档中有许多其他例子。
卷积神经网络
那么,卷积与卷积神经网络有什么关系呢?
考虑一个一维卷积层,输入为 {xn}\{x_n\}{xn},输出为 {yn}\{y_n\}{yn},就像我们上一篇文章讨论的:
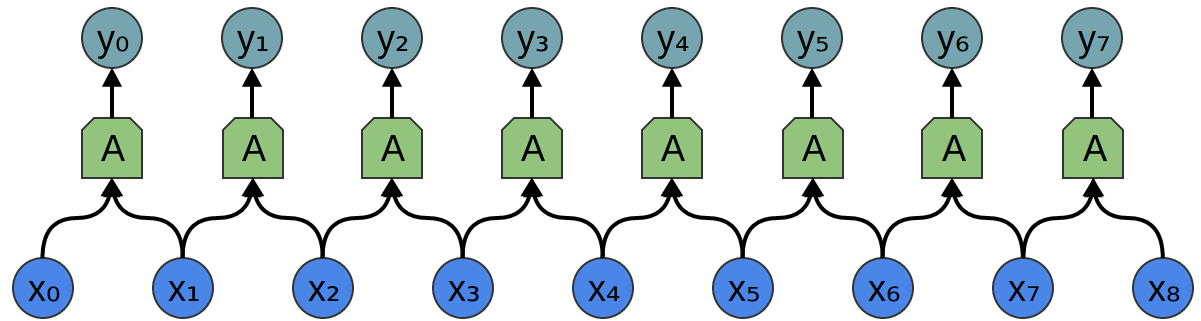
正如我们观察到的,我们可以用输入来描述输出:
yn=A(xn,xn+1,...)y_n = A(x_{n}, x_{n+1}, ...)yn=A(xn,xn+1,...)
通常,AAA 会是多个神经元。但假设它暂时是一个单独的神经元。
回想一下,神经网络中一个典型的神经元描述为:
σ(w0x0+w1x1+w2x2...+b)\sigma(w_0x_0 + w_1x_1 + w_2x_2 ... + b)σ(w0x0+w1x1+w2x2...+b)
其中 x0x_0x0、x1x_1x1...是输入。权重 w0w_0w0、w1w_1w1...描述了神经元如何连接到其输入。负权重意味着输入抑制神经元激发,正权重则鼓励它激发。权重是神经元的核心,控制其行为。 说多个神经元相同,等同于说权重相同。
正是神经元的这种连接方式,描述了所有权重以及哪些是相同的,卷积将为我们处理这些。
通常,我们一次性描述一层中的所有神经元,而不是单独描述。技巧是有一个权重矩阵 WWW:
y=σ(Wx+b)y = \sigma(Wx + b)y=σ(Wx+b)
例如,我们得到:
y0=σ(W0,0x0+W0,1x1+W0,2x2...)y_0 = \sigma(W_{0,0}x_0 + W_{0,1}x_1 + W_{0,2}x_2 ...)y0=σ(W0,0x0+W0,1x1+W0,2x2...)
y1=σ(W1,0x0+W1,1x1+W1,2x2...)y_1 = \sigma(W_{1,0}x_0 + W_{1,1}x_1 + W_{1,2}x_2 ...)y1=σ(W1,0x0+W1,1x1+W1,2x2...)
矩阵的每一行描述了连接一个神经元与其输入的权重。
回到卷积层,因为有多个相同神经元的副本,许多权重出现在多个位置。
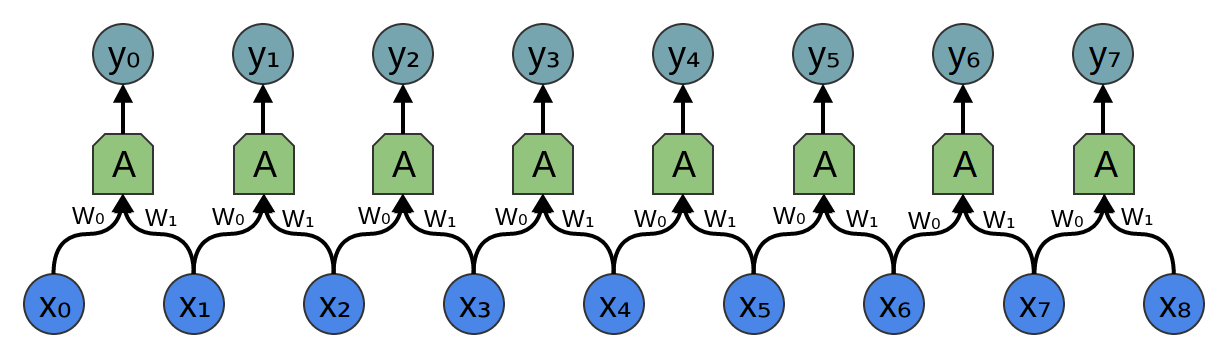
对应于方程:
y0=σ(W0x0+W1x1−b)y_0 = \sigma(W_0x_0 + W_1x_1 -b)y0=σ(W0x0+W1x1−b)
y1=σ(W0x1+W1x2−b)y_1 = \sigma(W_0x_1 + W_1x_2 -b)y1=σ(W0x1+W1x2−b)
因此,虽然通常权重矩阵用不同的权重将每个输入连接到每个神经元:
W=W0,0W0,1W0,2W0,3...W1,0W1,1W1,2W1,3...W2,0W2,1W2,2W2,3...W3,0W3,1W3,2W3,3..................W = \begin{bmatrix}W_{0,0} & W_{0,1} & W_{0,2} & W_{0,3} & ...\\W_{1,0} & W_{1,1} & W_{1,2} & W_{1,3} & ...\\W_{2,0} & W_{2,1} & W_{2,2} & W_{2,3} & ...\\W_{3,0} & W_{3,1} & W_{3,2} & W_{3,3} & ...\\... & ... & ... & ... & ...\\\end{bmatrix}W= W0,0W1,0W2,0W3,0...W0,1W1,1W2,1W3,1...W0,2W1,2W2,2W3,2...W0,3W1,3W2,3W3,3..................
但像上面那样的卷积层的矩阵看起来很不一样。相同的权重出现在多个位置。而且因为神经元不连接到许多可能的输入,所以有很多零。
W=w0w100...0w0w10...00w0w1...000w0..................W = \begin{bmatrix}w_0 & w_1 & 0 & 0 & ...\\0 & w_0 & w_1 & 0 & ...\\0 & 0 & w_0 & w_1 & ...\\0 & 0 & 0 & w_0 & ...\\... & ... & ... & ... & ...\\\end{bmatrix}W= w0000...w1w000...0w1w00...00w1w0..................
乘以这个矩阵等同于与 ...0,w1,w0,0......0, w_1, w_0, 0......0,w1,w0,0... 进行卷积。函数滑动到不同位置对应于在这些位置有神经元。
那么二维卷积层呢?
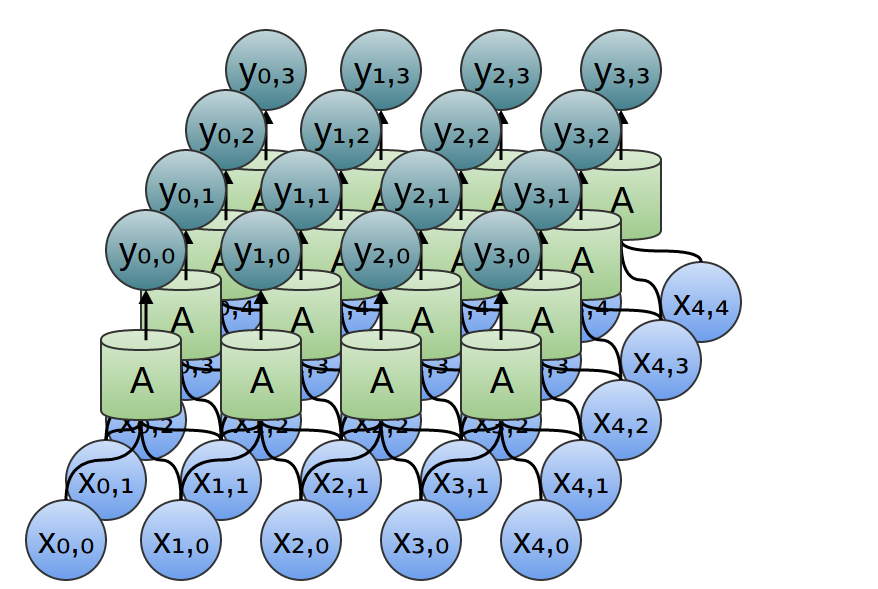
二维卷积层的连接方式对应于二维卷积。
考虑我们上面使用卷积检测图像边缘的例子,通过滑动核并将其应用于每个图像块。就像这样,卷积层会将神经元应用于图像的每个块。
结论
在这篇博客文章中,我们引入了大量的数学机制,但可能不明显我们获得了什么。卷积显然是概率论和计算机图形学中的有用工具,但用卷积来描述卷积神经网络,我们获得了什么?
第一个优势是,我们有了非常强大的语言来描述网络的连接方式。我们目前处理的例子还不够复杂,这个好处还不明显,但卷积将使我们摆脱大量繁琐的记录工作。
其次,卷积带来了显著的实现优势。许多库提供了高效的卷积例程。此外,虽然卷积朴素地看是 O(n2)O(n^2)O(n2) 操作,但利用一些相当深入的数学见解,可以创建 O(nlog(n))O(n\log(n))O(nlog(n)) 的实现。我们将在以后的文章中更详细地讨论这一点。
事实上,在 GPU 上使用高效的并行卷积实现对于计算机视觉领域的最新进展至关重要。