
在现代企业的数据工作流中,PDF 文档不仅是文字的载体,往往还沉淀了大量关键的视觉数据------从技术手册中的零件图解,到财务报告中的趋势图表。手动截取这些图片不仅低效,且无法保证原始分辨率。
对于开发者而言,通过编程方式自动化提取这些资源是提升生产力的核心。本文将探讨如何利用 Python 深度解析 PDF 页面树,并利用 Spire.PDF for Python 构建一个 PDF 图像提取脚本。
1. 为什么提取 PDF 图片比想象中复杂?
在开始编写代码之前,我们需要理解 PDF 的底层存储逻辑。与 HTML 或 Word 不同,PDF 并不总是将图片存储为独立的文件引用。
- 资源字典 (Resource Dictionary) :PDF 页面通过
XObject(外部对象)来定义图像。这意味着一张公司 Logo 可能在 100 页的文档中被引用了 100 次,但在内存中只存储一份。 - 压缩与色彩:图片在 PDF 内部可能经过了 DCTDecode(JPEG)或 FlateDecode(PNG)等多种压缩处理。
- PdfImageHelper 的作用 :相比于直接从页面导出,使用
PdfImageHelper可以更精准地定位页面上的图像信息流,确保提取出的资源保持原始的采样率。
2. 环境配置
在 Python 环境中,我们可以通过 pip 轻松安装所需的库。该库的优势在于它对 PDF 结构的解析非常透彻,能够处理各种复杂的嵌套对象。
bash
pip install Spire.PDF3. 核心实现:使用 PdfImageHelper 提取图像
在 Spire.PDF 的最新版本中,推荐使用 PdfImageHelper 类来处理图像提取任务。这种方式比传统的页面导出更具鲁棒性。
以下是完整的代码实现:
python
from spire.pdf.common import *
from spire.pdf import *
import os
def extract_pdf_images(input_file, output_folder):
# 确保输出目录存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 1. 初始化 PdfDocument 实例
pdf = PdfDocument()
# 2. 加载 PDF 文件
pdf.LoadFromFile(input_file)
# 3. 创建 PdfImageHelper 实例,这是提取的核心类
image_helper = PdfImageHelper()
# 4. 遍历文档中的每一个页面
for i in range(pdf.Pages.Count):
# 获取当前页面对象
page = pdf.Pages.get_Item(i)
# 获取该页面上所有的图像信息
# GetImagesInfo 会返回一个包含图像元数据的列表
image_info_list = image_helper.GetImagesInfo(page)
# 5. 遍历当前页面的图像信息项
for j in range(len(image_info_list)):
# 构造保存路径,建议包含页码和图像索引
output_path = os.path.join(output_folder, f"Image_Page{i+1}_{j}.png")
# 直接调用图像对象的 Save 方法保存到本地
image_info_list[j].Image.Save(output_path)
print(f"已保存: {output_path}")
# 6. 释放资源,关闭文档
pdf.Close()
print("提取任务已全部完成。")
# 执行调用
extract_pdf_images("technical_manual.pdf", "Extracted_Images")下面是提取结果示例:
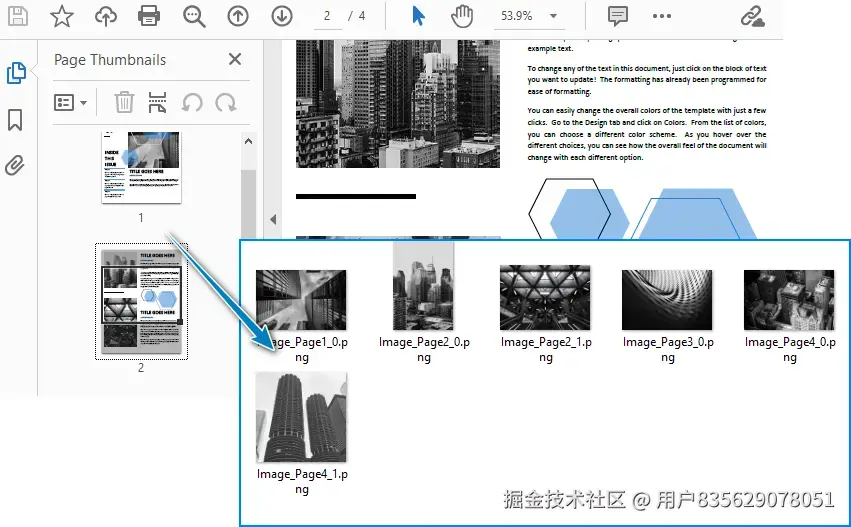
4. 深度进阶:处理复杂场景
在实际生产环境中,简单的遍历往往不够。我们需要考虑以下几个专业维度:
A. 过滤微小元素
有些 PDF 包含大量的装饰性图标(如页脚的小横线或占位符)。我们可以通过 image_info_list[j].Width 和 Height 属性来设置阈值,过滤掉不具分析价值的碎片图。
B. 获取图像位置坐标
PdfImageHelper 的强大之处在于它返回的 image_info 对象包含 Bounds 属性。这在构建 RAG(检索增强生成)系统时非常有用,因为你可以知道图片位于文本的哪个段落附近,从而建立准确的上下文关联。
C. 内存与性能
对于超长文档(如 500 页以上的年报),建议在处理大型 PDF 时采用分段加载的方式。由于 pdf.Close() 会释放底层句柄,确保在脚本结束时调用它,避免内存泄漏。
5. 应用场景
这种自动化提取技术在以下领域具有极高的商业价值:
- 自动化内容迁移:将旧版的 PDF 资料库迁移到 Web 平台,自动填充配图。
- AI 训练集构建:从海量的医学 PDF 论文中自动抓取放射学影像或病理切片图。
- 文档审计:快速扫描文档中是否存在违规 Logo 或过时的视觉元素。
结语
使用 Python 提取 PDF 图片不应仅仅是"截图"的替代方案,它更应该是文档结构化数据提取的重要一环。通过 PdfImageHelper 提供的 API,开发者可以用极少的代码量处理复杂的 PDF 资源调度。