在Kotlin开发中,在SparseArray和ArrayMap上使用相同的set操作符时,发现类型检查行为还不太一致。
示例
kotlin
class MapDemo {
private val mArrayMap = ArrayMap<Int, Boolean>()
private val mSparseArray = SparseArrayCompat<Boolean>()
fun test() {
mArrayMap.set(4, null) //允许直接设置为null, ✅ 编译通过
mArrayMap[3] = null //同set方法, ✅ 编译通过
mArrayMap.get(1) //没有对应的key,直接返回null
mSparseArray.set(3, null) //不允许直接设置为null, ❌ 编译错误
mSparseArray[3] = null //同set方法, ❌ 编译错误
mSparseArray.get(1) //没有对应的key,直接返回null
}
}可以看出虽然定义的 ArrayMap<Boolean>,但是依然可以把 value 设置为 null;而SparseArrayCompat<Boolean>不允许直接设置为null,会在编译阶段就报错。两者的get()方法表现一致,如果没有对应的key,都会返回默认值null。
ArrayMap 对应源码
ArrayMap 设计初衷是为了在小数据量场景下,比传统的 HashMap 更节省内存。它通过两个数组来模拟 Map 的功能。
ini
//ArrayMap.java
public class ArrayMap<K, V> extends SimpleArrayMap<K, V> implements Map<K, V> {
int[] mHashes;
Object[] mArray;
int mSize;
//通过key获取value,如果没有对应的key,直接返回null
public V get(Object key) {
return getOrDefault(key, null);
}
public V getOrDefault(Object key, V defaultValue) {
final int index = indexOfKey(key);
return index >= 0 ? (V) mArray[(index << 1) + 1] : defaultValue;
}
//通过双数组结构高效插入,在保证性能的同时大幅减少内存开销,核心流程:查找 → 更新/插入 → 扩容 → 返回值
@Nullable
@SuppressWarnings("unchecked")
public V put(K key, V value) {
final int osize = mSize;
final int hash;
int index;
if (key == null) { //处理null键
hash = 0;
index = indexOfNull();
} else { //二分查找
hash = key.hashCode();
index = indexOf(key, hash);
}
//计算值在数组中的位置,获取旧值并更新新值
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
index = ~index;
//动态扩容
if (osize >= mHashes.length) {
final int n = osize >= (BASE_SIZE*2) ? (osize+(osize>>1))
: (osize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//分配新数组并拷贝数据
allocArrays(n);
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
if (mHashes.length > 0) {
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
freeArrays(ohashes, oarray, osize);
}
if (index < osize) {
System.arraycopy(mHashes, index, mHashes, index + 1, osize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
if (CONCURRENT_MODIFICATION_EXCEPTIONS) {
if (osize != mSize || index >= mHashes.length) {
throw new ConcurrentModificationException();
}
}
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
}
//set是个扩展函数
@kotlin.internal.InlineOnly
public inline operator fun <K, V> MutableMap<K, V>.set(key: K, value: V): Unit {
put(key, value)
}ArrayMap实现了Map接口,继承其操作符。Kotlin将ArrayMap视为"平台类型",在类型检查上采取宽容态度,允许潜在的null值传递。
ArrayMap vs HashMap
ArrayMap的数据结构: 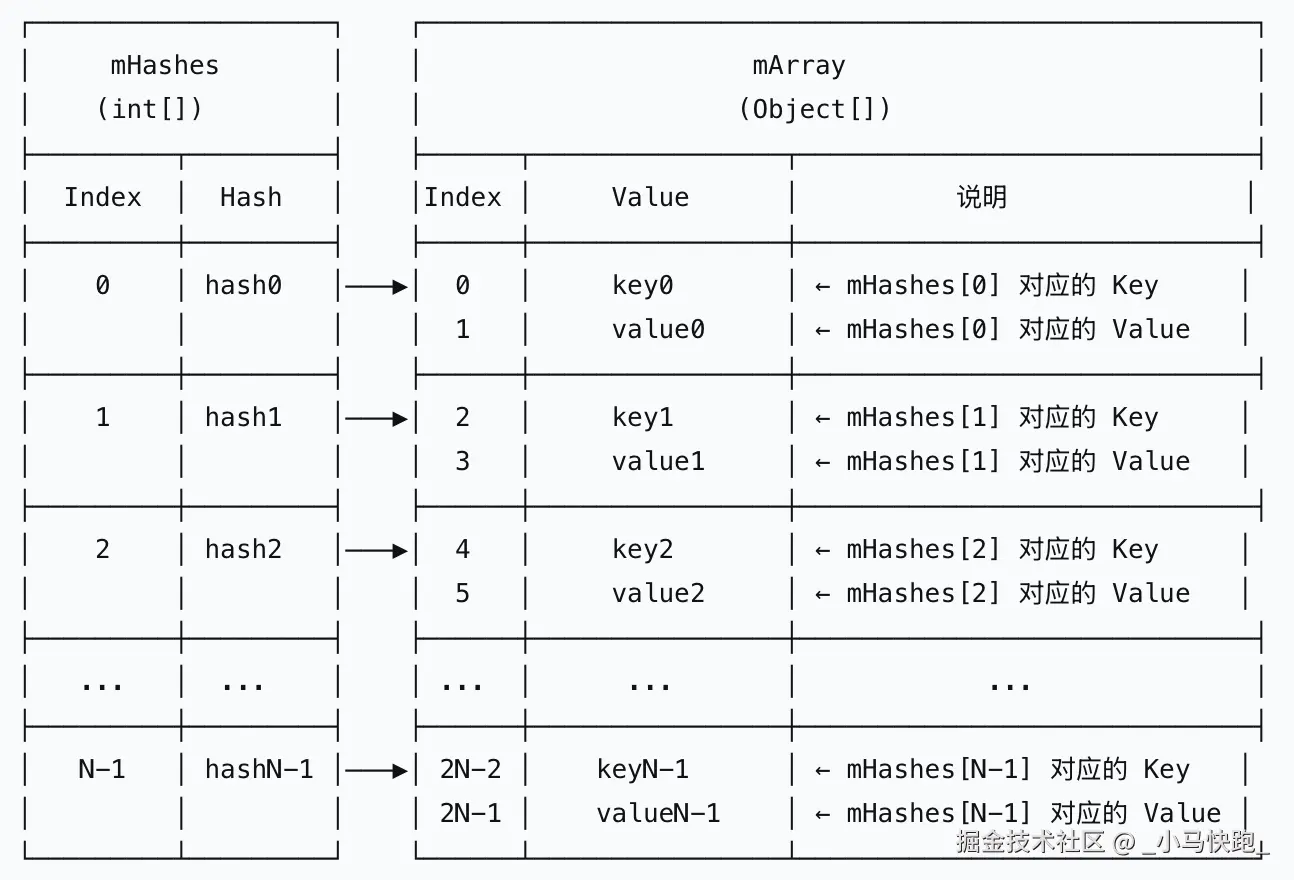 ArrayMap使用两个数组实现:
ArrayMap使用两个数组实现:mHashes数组按升序存储所有key的哈希值,用于快速二分查找;mArray数组以key0, value0, key1, value1...的交替顺序存储实际的键值对。通过这种设计,查找时先在mHashes中二分定位位置索引,再根据索引映射到mArray中获取对应的键值,在保证小数据量下O(log n)查找性能的同时,大幅减少了内存开销,避免了HashMap中Node对象的创建成本。
HashMap的数据结构: 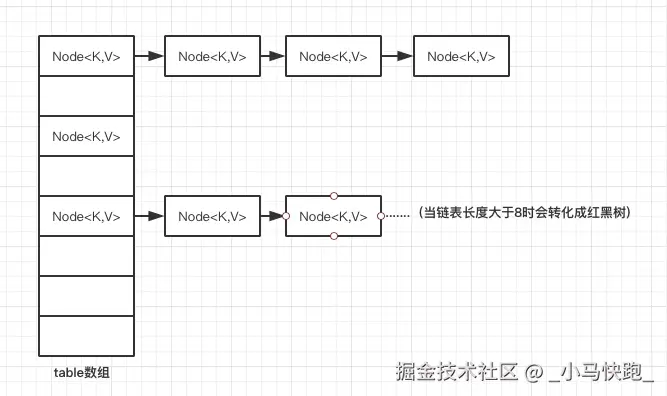 单个Node结构:
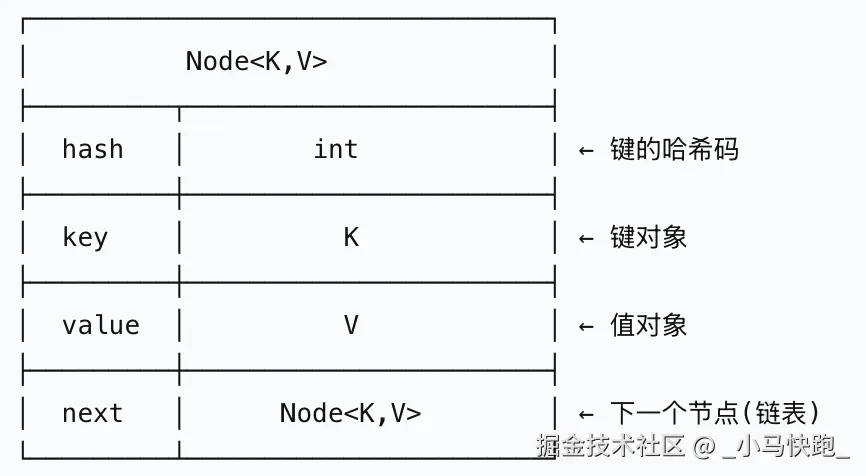
单个Node结构:
 HashMap采用数组+链表+红黑树的结构(JDK1.8引入):一个Node数组作为哈希桶,通过hash(key) & (n-1)计算桶索引;发生哈希冲突时,使用链表法在同一个桶内形成链表;当链表长度超过8且数组容量达到64时,链表自动转换为红黑树以维持O(1)级别的查找性能。这种设计在应对哈希碰撞和大量数据时能保持高效操作,但每个键值对都需要封装为Node对象,内存开销较大。
HashMap采用数组+链表+红黑树的结构(JDK1.8引入):一个Node数组作为哈希桶,通过hash(key) & (n-1)计算桶索引;发生哈希冲突时,使用链表法在同一个桶内形成链表;当链表长度超过8且数组容量达到64时,链表自动转换为红黑树以维持O(1)级别的查找性能。这种设计在应对哈希碰撞和大量数据时能保持高效操作,但每个键值对都需要封装为Node对象,内存开销较大。
ArrayMap优点 (相对于 HashMap)
- 内存效率高: HashMap 需要为每个 Entry 创建一个 HashMap.Node 对象(包含 key, value, hash, next 等字段),对于小数据量来说,对象开销大。 ArrayMap 使用两个数组,避免了大量小对象的创建,内存布局更紧凑,尤其在小数据量(<1000 个元素)时优势明显。
- 缓存友好: 数组结构在内存中是连续的,遍历时缓存命中率更高。
缺点 (相对于 HashMap)
- 插入和删除性能差: 因为涉及数组元素的移动,时间复杂度为 O(n)。而 HashMap 在理想情况下是 O(1)。
- 查找性能稍差: 虽然二分查找是 O(log n),但在数据量非常小(个位数)时,可能与 HashMap 的 O(1) 差不多,但随着数据量增大,效率会低于 HashMap。
- 不适合大数据量: 当数据量很大时(例如超过 1000),数组扩容和元素移动的成本会变得非常高,性能会显著下降。
SparseArrayCompat对应源码
SparseArray的数据结构: 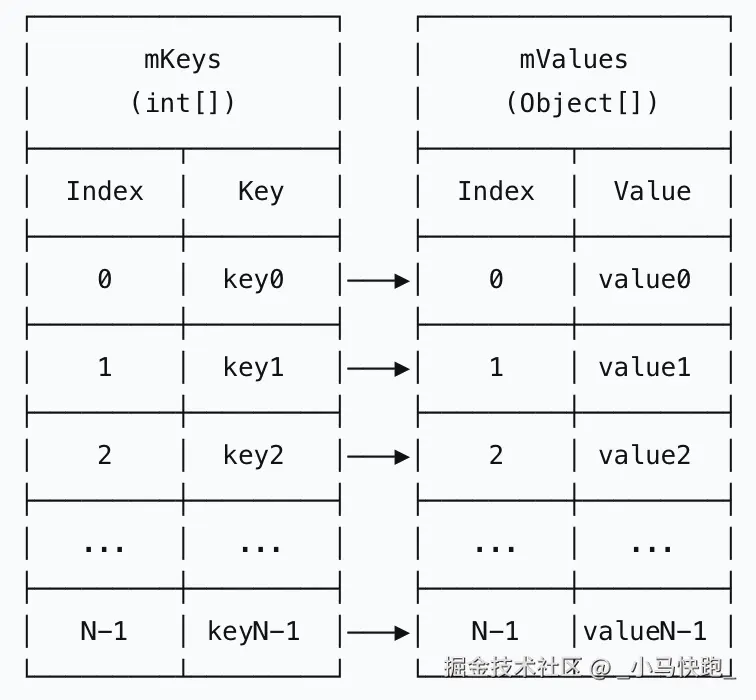 SparseArray 使用两个并行数组:
SparseArray 使用两个并行数组:mKeys数组按升序存储int类型的键,mValues数组存储对应的Object值。通过有序的键数组实现二分查找,在键为int类型的场景下避免了自动装箱开销,比HashMap节省内存。
ini
public class SparseArrayCompat<E> implements Cloneable {
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ ContainerHelpers.binarySearch(mKeys, mSize, key);
}
if (mSize >= mKeys.length) {
int n = ContainerHelpers.idealIntArraySize(mSize + 1);
int[] nkeys = new int[n];
Object[] nvalues = new Object[n];
// Log.e("SparseArray", "grow " + mKeys.length + " to " + n);
System.arraycopy(mKeys, 0, nkeys, 0, mKeys.length);
System.arraycopy(mValues, 0, nvalues, 0, mValues.length);
mKeys = nkeys;
mValues = nvalues;
}
if (mSize - i != 0) {
// Log.e("SparseArray", "move " + (mSize - i));
System.arraycopy(mKeys, i, mKeys, i + 1, mSize - i);
System.arraycopy(mValues, i, mValues, i + 1, mSize - i);
}
mKeys[i] = key;
mValues[i] = value;
mSize++;
}
}
@Nullable
public E get(int key) {
return get(key, null);
}
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}
}
//set扩展函数
inline operator fun <T> SparseArrayCompat<T>.set(key: Int, value: T) = put(key, value)set方法中,泛型参数<T>直接传递给put方法,保持了原始泛型参数的协变关系,从而编译器能够进行完整的类型推断和检查。所以当声明SparseArrayCompat<Boolean>时,set操作符的value参数类型被严格推断为Boolean(非空),因此拒绝null值。