一、背景与问题
Flink作为一款高性能的分布式流处理框架,其序列化机制在任务运行中扮演着至关重要的角色。Flink在处理数据时,需要对网络传输、状态后端存储、检查点保存等场景进行序列化操作。Flink默认使用自研的高效序列化框架(TypeInformation / TypeSerializer),但对于无法直接序列化的类型,会回退到Kryo序列化器。
Kryo是一个成熟、高效的Java序列化框架,在Flink生态中被广泛使用,特别是在处理Scala case class或自定义复杂类型时。然而,在某些特殊场景下可能会引发意想不到的问题。
在生产环境中,我们遇到一个Flink JAR任务的异常问题。任务基于 Flink 构建实时加工逻辑,使用 RocksDB 作为状态后端并开启了 State TTL 功能,任务运行过程中出现异常崩溃,经过多次Flink容错重启最终异常停止。
二、问题排查
1.日志分析
核心报错日志包含两个关键信息:
- 基础提示:Kryo serializer scala extensions are not available,表明 Kryo 的 Scala 扩展组件无法正常使用。
- 核心异常:java.lang.IllegalArgumentException: classLoader cannot be null,即类加载器为 null,触发参数校验异常。
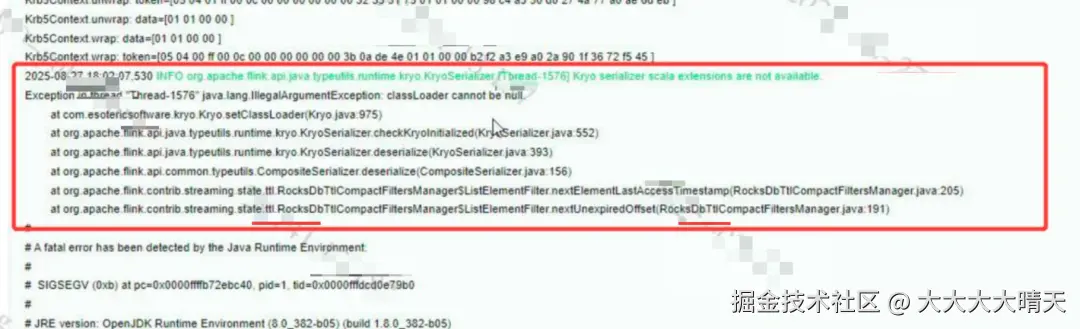 查看其他日志与监控信息暂无明显异常,初步判断问题出在Kryo 序列化器初始化 + RocksDB State TTL 的协同阶段。
查看其他日志与监控信息暂无明显异常,初步判断问题出在Kryo 序列化器初始化 + RocksDB State TTL 的协同阶段。
2.测试复现
将生产环境的业务代码、Flink 配置(包括状态后端、Checkpoint、State TTL 配置)完全同步到本地调试环境,启动 Flink 本地任务后,成功复现了生产环境的异常,排除了生产服务器环境、网络等外部因素的影响,确认问题为代码与 Flink 框架结合的逻辑问题。 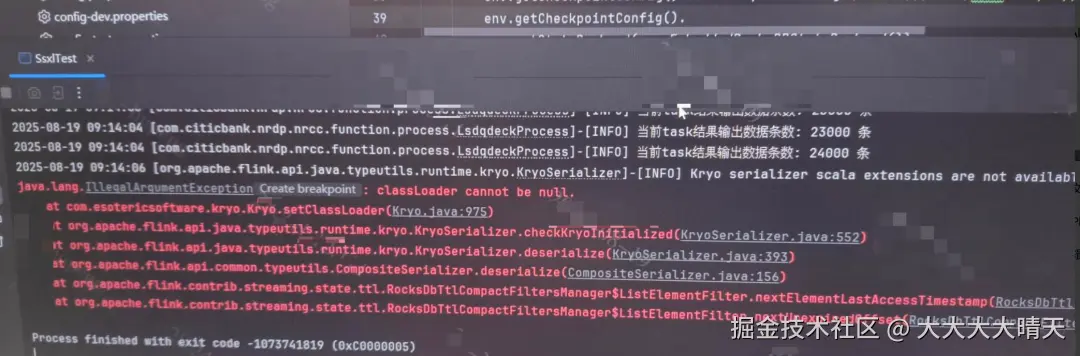
三、问题分析
1.原理剖析
RocksDB Compaction与TTL
- RocksDB作为LSM树实现的存储引擎,通过Compaction(压实)操作来清理过期数据
- Flink的RocksDB状态后端实现了TTL功能,在Compaction过程中会检查数据是否过期
- Compaction过滤器在后台线程/本地回调线程中执行,需要反序列化ListState的元素来判断是否过期
KryoSerializer的工作流程
- KryoSerializer在初始化时需要设置ClassLoader
- 正常情况下,这个ClassLoader来自任务线程的上下文
- checkKryoInitialize方法会调用Kryo.setClassLoader(...)完成初始化
2.根因分析
本次生产任务的核心异常classLoader cannot be null,触发点为 KryoSerializer 初始化 Kryo 实例时的Kryo.setClassLoader(...)方法。在 Flink 的 RocksDB 状态后端中,当开启 State TTL 并配置cleanupInRocksdbCompactFilter(基于 RocksDB 压缩过滤器进行过期状态清理)时,RocksDB 会启动后台独立线程执行 compaction 操作,该操作需要对 ListState 中的元素反序列化以判断过期时间。
Flink 的 Kryo 序列化器初始化时,类加载器的获取依赖当前线程的 contextClassLoader,但 RocksDB 的后台 compaction 线程为独立线程,Flink 框架未对该线程的 contextClassLoader 进行显式设置,导致该线程获取的类加载器为 null,Kryo 初始化失败并抛出空指针异常。
经确认,本次问题属于Flink 官方未修复的框架 bug(FLINK-16686),该 bug 存在于 Flink 1.17 及以上部分版本中,核心问题是 Flink 未将用户类加载器(user class loader)暴露给 RocksDB 的本地回调线程 / 后台 compaction 线程,导致线程上下文缺失类加载器信息,进而引发依赖类加载器的序列化操作失败。
四、解决方案
采用规避框架 bug + 显式指定序列化器的解决方案:替换 Kryo 序列化,使用 Flink POJO 自定义序列化。当Flink能够推断类型为POJO(或显式提供TypeInformation/TypeSerializer)时,RocksDB在Compaction过程中会直接使用对应的TypeSerializer,完全绕开Kryo序列化器,从而避免classLoader问题。
1.定义 POJO 类:将 ListState 中的元素封装为符合 Flink POJO 规范的实体类(需满足无参构造、字段私有化并提供 get/set 方法、字段类型为 Flink 支持的基础类型等)。
2.显式指定 TypeInformation:在 ListStateDescriptor 的定义中,通过TypeInformation.of(POJO类.class)显式指定元素的类型信息,让 Flink 推断并使用 POJO 序列化器。
3.重新配置 State TTL:保持 State TTL 的核心配置不变,确保过期状态清理的逻辑正常生效。
改造完成后,我们进行了长时间的数据测试,任务稳定运行,符合预期。另外,除了 POJO 序列化外,还可选择 Flink 自身支持的其他序列化方式(avro/protobuf/自定义TypeSerializer),均能解决本次问题。
五、总结
Flink作为一个成熟的分布式计算框架,其内部机制复杂。当遇到问题时,深入理解相关组件(如RocksDB、Kryo、TTL)的工作原理,能够帮助我们更快定位问题根源。只有在实践中不断积累经验、总结规律,才能有效规避各类潜在问题,保障实时计算任务的稳定运行。