一、底层实现原理对比
std::map:红黑树的优雅平衡
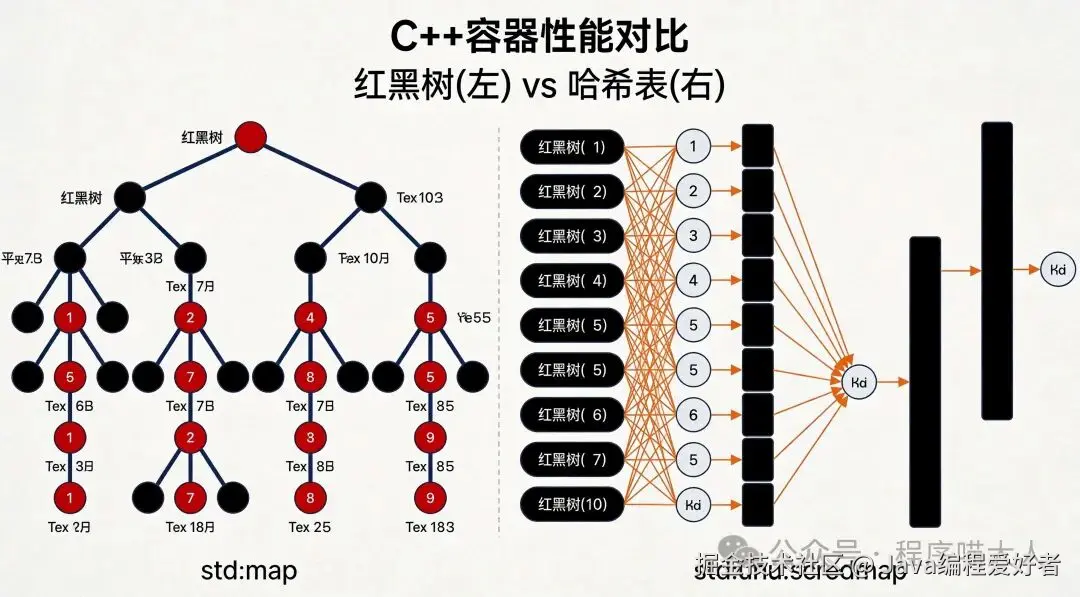
std::map的底层实现是红黑树,这是一种自平衡的二叉搜索树。红黑树通过以下五条规则维持平衡:
- 每个节点要么是红色,要么是黑色
- 根节点必须是黑色
- 所有叶子节点(nil节点)均为黑色
- 若一个节点是红色,则其两个子节点必须是黑色
- 从任意节点到其所有后代叶子节点的路径上,黑色节点的数量相同
这些规则确保红黑树始终保持近似平衡状态,从而保证树的高度始终在O(logN)级别。红黑树的每个节点存储键值对、左右子节点指针、父节点指针和颜色标记。
arduino
// 红黑树节点结构示例
template<typename Key, typename Value>
struct map_node {
Key key;
Value value;
map_node* left;
map_node* right;
map_node* parent; // 父指针,便于旋转操作
bool is_red; // 颜色标记
};std::unordered_map:哈希表的高效映射
std::unordered_map的底层实现是哈希表,采用"数组+链表/红黑树"的组合结构。当单个桶中的元素数量超过阈值(通常是8个)时,会自动将链表转换为红黑树,以优化最坏情况下的性能。
arduino
// 哈希表节点结构示例
template<typename Key, typename Value>
struct hash_node {
Key key;
Value value;
hash_node* next; // 指向同桶中的下一个节点
size_t hash; // 缓存哈希值,避免重复计算
};二、内存布局与性能特性
红黑树内存布局
红黑树的节点在内存中是分散存储的,但每个节点的结构紧凑,包含键值对和树结构指针。这种设计使得红黑树在插入和删除时需要通过旋转和变色操作来维护平衡性,但缓存友好性较差。
哈希表内存布局
哈希表采用连续的桶数组存储指针,每个桶指向一个链表或红黑树。这种设计使得哈希表的内存占用波动较大,但平均查找速度更快。当负载因子超过阈值时,哈希表会自动扩容,可能导致迭代器失效。
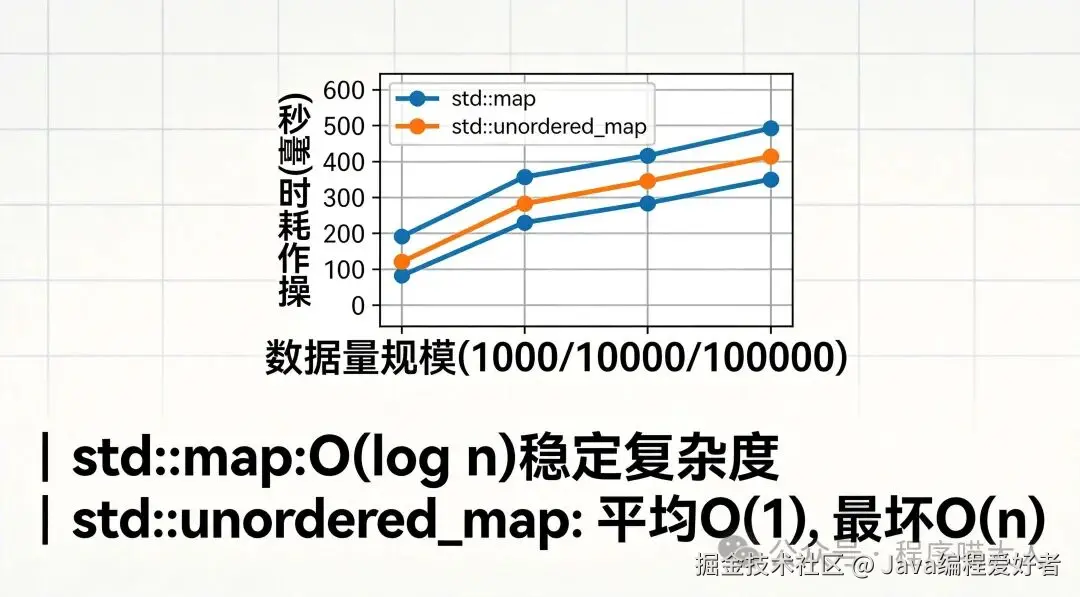
三、不同数据量下的性能测试
几百~几千条数据
性能几乎无差异,随便选!单次查询/插入耗时都在纳秒~微秒级,差距在1~10纳秒,人类完全感知不到。
1万~10万条数据
差异开始显现,unordered_map的优势慢慢体现:单次操作耗时大概是map的1/5 ~ 1/3。
10万条及以上数据
unordered_map性能碾压map,差距能达到10倍甚至百倍!数据量越大,logN的增长越明显,map的耗时会持续增加;而unordered_map依然保持O(1)的极致性能。
四、自定义哈希函数踩坑指南
常见问题
- 哈希冲突严重:当不同的键通过哈希函数计算出相同的哈希值时,会落到同一个桶中,导致性能退化。
- 哈希函数与相等比较不一致:如果哈希函数和operator==的逻辑不一致,会导致查找失败。
- 哈希计算耗时过长:对于长字符串等复杂类型,哈希计算的时间可能比查找本身还要长。
解决方案
c
// 正确的自定义哈希函数示例
struct Person {
std::string name;
int age;
booloperator==(const Person& other) const {
return name == other.name && age == other.age;
}
};
namespacestd {
template<>
struct hash<Person> {
size_t operator()(const Person& p) const {
size_t h1 = std::hash<std::string>{}(p.name);
size_t h2 = std::hash<int>{}(p.age);
return h1 ^ (h2 << 1); // 异或结合位移减少碰撞
}
};
}五、实际应用场景选择
选择std::map的场景
- 需要有序遍历所有key
- 需要进行范围查询(如查找key>100且key<200的所有数据)
- 对内存占用敏感
- 担心哈希冲突导致性能不稳定
选择std::unordered_map的场景
- 业务不需要有序存储
- 未来数据量可能大幅增长
- 业务是高频的单条查询操作
- 可以提供高效的哈希函数