如果你正接手一个合规项目 ------数据不能出域 、访问要能审计 、服务要能自己运维,大模型在内网落地------下面这些事,是不是也让你头疼过:
- 公网 API 用不了,内网部署又不知道从哪一步开始
- 硬件买多大、模型选哪个,没有依据,只能先估一估
- vLLM、LMDeploy、Ollama 都听过,上线前到底该用哪套

如果是,这篇文章就是为你写的。我们从合规落地视角,一起走通一条可执行的路径:
- 用 llmfit / whichllm 做硬件摸底与采购论证
- 选定适合合规内网的生产模型
- 用 vLLM / LMDeploy 在内网跑通私有化部署
一、为何必须私有化部署
合规团队关心的「能不能过审、能不能管」。
| 维度 | 公网 API | 内网私有化 |
|---|---|---|
| 数据流向 | 请求出域,依赖供应商承诺 | 数据留在机房/专有云,边界清晰 |
| 审计留痕 | 日志在第三方,难以统一归档 | 可对接现有 SIEM、操作审计体系 |
| 监管应对 | 合同与 DPA 为主 | 等保、行业规范、国产化清单可逐项举证 |
| 成本 | 按 Token 计费,规模上来不可控 | 硬件一次性投入 + 运维,长期可预测 |
| 可用性 | 受供应商 SLA 约束 | 内网延迟与容量自主可控 |
私有化是合规行业的必选项。
二、硬件如何选型与配置
现有或计划采购的硬件,能稳定跑什么规模的模型? 推荐两款 CLI 工具互补使用。
| 你的目标 | 首选工具 |
|---|---|
| 模拟 24GB 采购配置、TUI 浏览可跑模型 | llmfit (--memory=24G、info、plan) |
| 在能跑的模型里按 benchmark 选更优 | whichllm (默认排名 / --gpu "RTX 4090") |
| 已定 Qwen3-8B,反查最低硬件 | 两者均可:llmfit plan ... --context / whichllm plan |
| 定稿模型并衔接第六~七节部署 | whichllm snippet |
2.1 llmfit
GitHub :github.com/AlexsJones/...
2.1.1 产品介绍
llmfit 是一款开源终端工具,自动检测本机 RAM / CPU / GPU(含昇腾 NPU),从数百个模型中筛选「真能跑、跑得好」的型号。
核心能力:
- 交互式 TUI,顶部展示整机硬件信息
- 按 质量 / 速度 / 显存 fit / 上下文 四维评分排序
- 支持多 GPU、MoE、动态量化选择
H键切换 27+ GPU 预设,采购论证时模拟目标机器plan模式:给定模型名,反查所需硬件配置
合规场景价值: 采购评审时,用
--memory=24G模拟目标机器,再用info查指定模型 或plan反查最低硬件。
2.1.2 安装
bash
# 无需安装即可运行:
uvx llmfit
# uv / pip
uv tool install -U llmfit
# Windows
scoop install llmfit
# macOS / Linux(预编译)
brew install AlexsJones/llmfit/llmfit
# 或一键脚本
curl -fsSL https://llmfit.axjns.dev/install.sh | sh如果尚未安装 Scoop,请按照 Scoop 安装指南进行操作(scoop.sh/)。%25E3%2580%2582 "https://scoop.sh/)%E3%80%82")
2.1.3 实操
步骤 1:摸底本机
bash
llmfit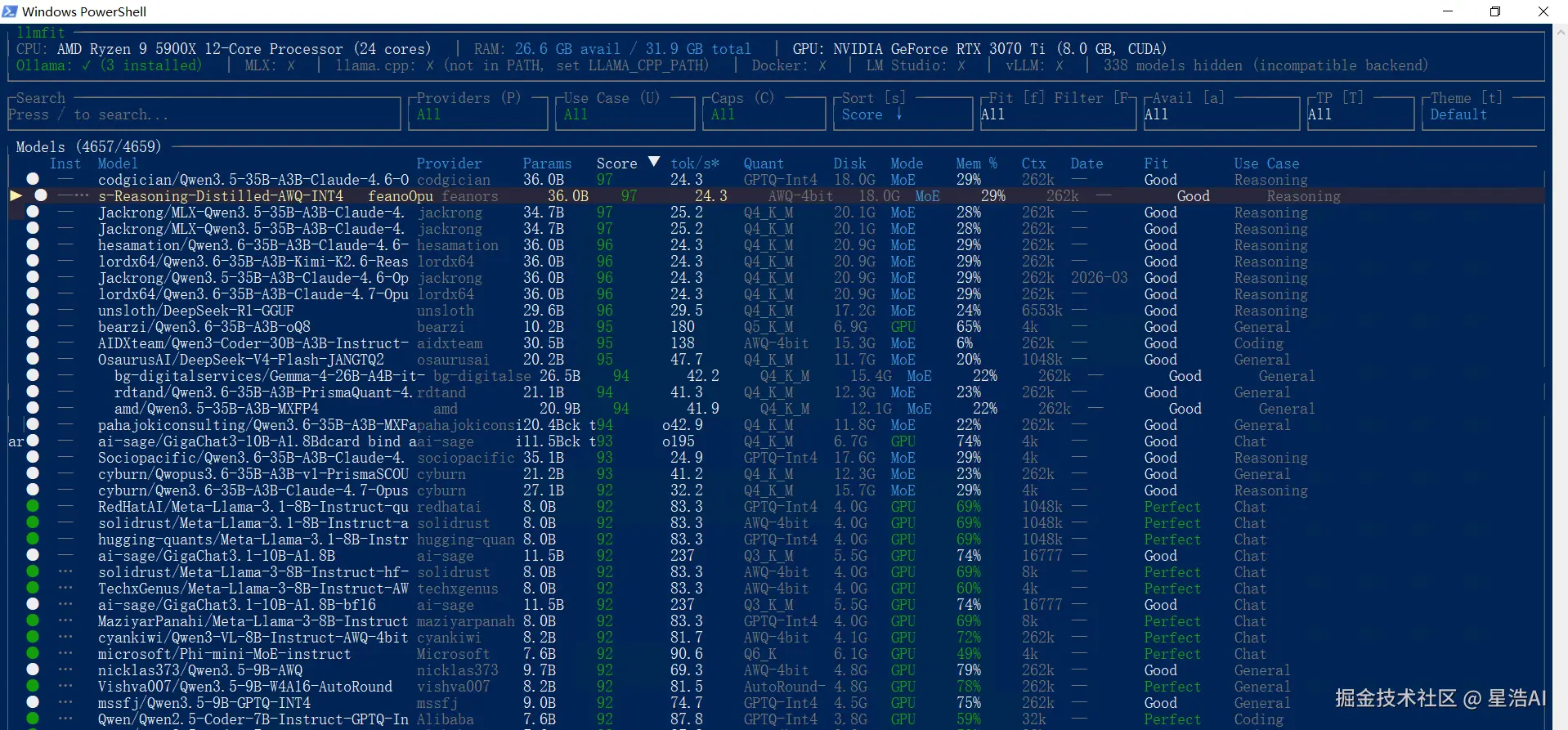 llmfit TUI:硬件信息与模型列表
llmfit TUI:硬件信息与模型列表
关注 TUI 顶部的 CPU、GPU、VRAM 信息,以及模型表中的 score、预估 tok/s、推荐量化、run mode。
步骤 2:模拟 24GB 单卡,查 Qwen3-8B-AWQ 能否可跑
bash
uvx llmfit --memory=24G --ram=64G info "Qwen/Qwen3-8B" llmfit 模拟 24GB 下的 fit 结果
llmfit 模拟 24GB 下的 fit 结果
看 fit 等级 和预估 tok/s 即可。
步骤 3:反查最低硬件(须带 --context)
bash
uvx llmfit plan "Qwen/Qwen3-8B-AWQ" --context 8192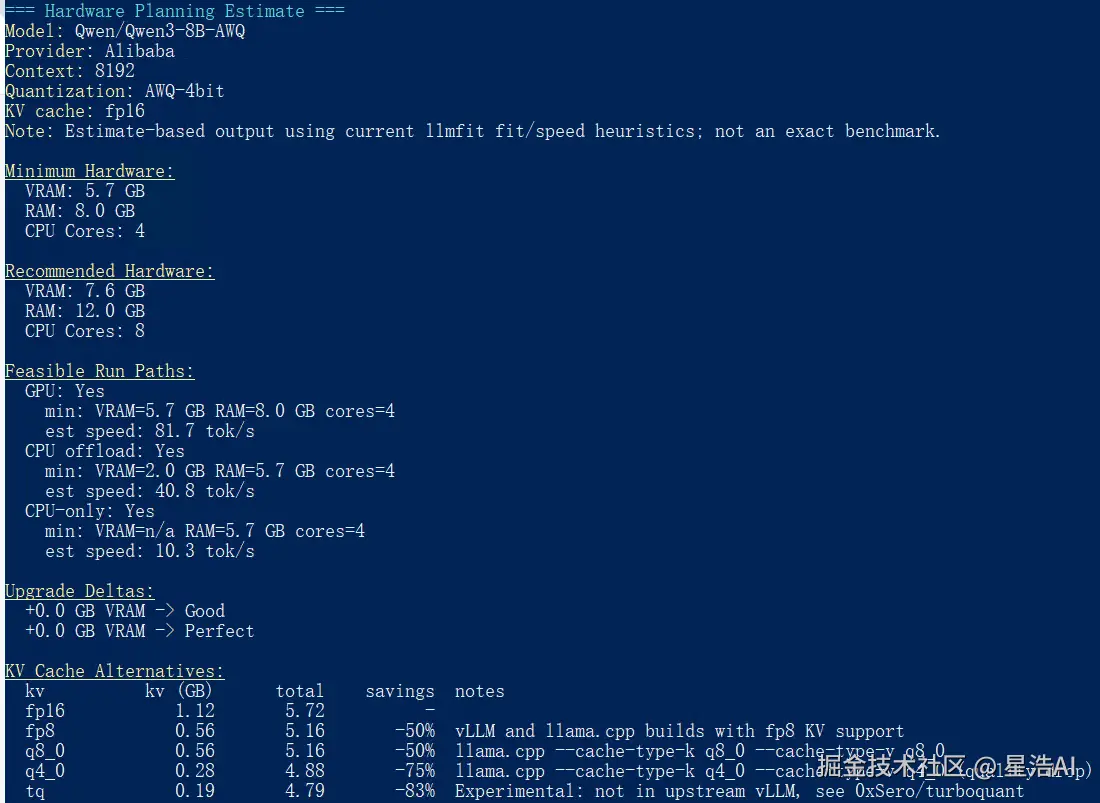 llmfit plan 硬件规划输出
llmfit plan 硬件规划输出
8K 上下文下推荐显存约 7.6GB;部门生产档写 24GB 单卡,是为长上下文和并发留余量。
2.2 whichllm
GitHub :github.com/Andyyyy64/w...
2.2.1 产品介绍
whichllm 解决的是在能跑的模型里,哪个更值得跑------排名融合 LiveBench、Arena ELO 等 benchmark,而非单纯比参数量。
核心能力:
- 自动检测 NVIDIA / AMD / Apple Silicon 硬件
- 实时拉取 HuggingFace 模型库
plan:反向查询跑某模型需要什么 GPUsnippet:输出可复制运行的 Python 代码片段--json:便于接入采购或运维脚本
与 llmfit 分工: llmfit 偏交互浏览与采购模拟;whichllm 偏 benchmark 排名 + 衔接部署流水线。
2.2.2 安装
bash
# 零安装试用(推荐先这样跑)
uvx whichllm@latest
# 常用后可固定安装
uv tool install whichllm
# 备选
brew install andyyyy64/whichllm/whichllm
pip install whichllm依赖 Python 3.11+;NVIDIA 环境自带 nvidia-ml-py。
2.2.3 实操
步骤 1:查看本机 Top 模型
bash
uvx whichllm@latest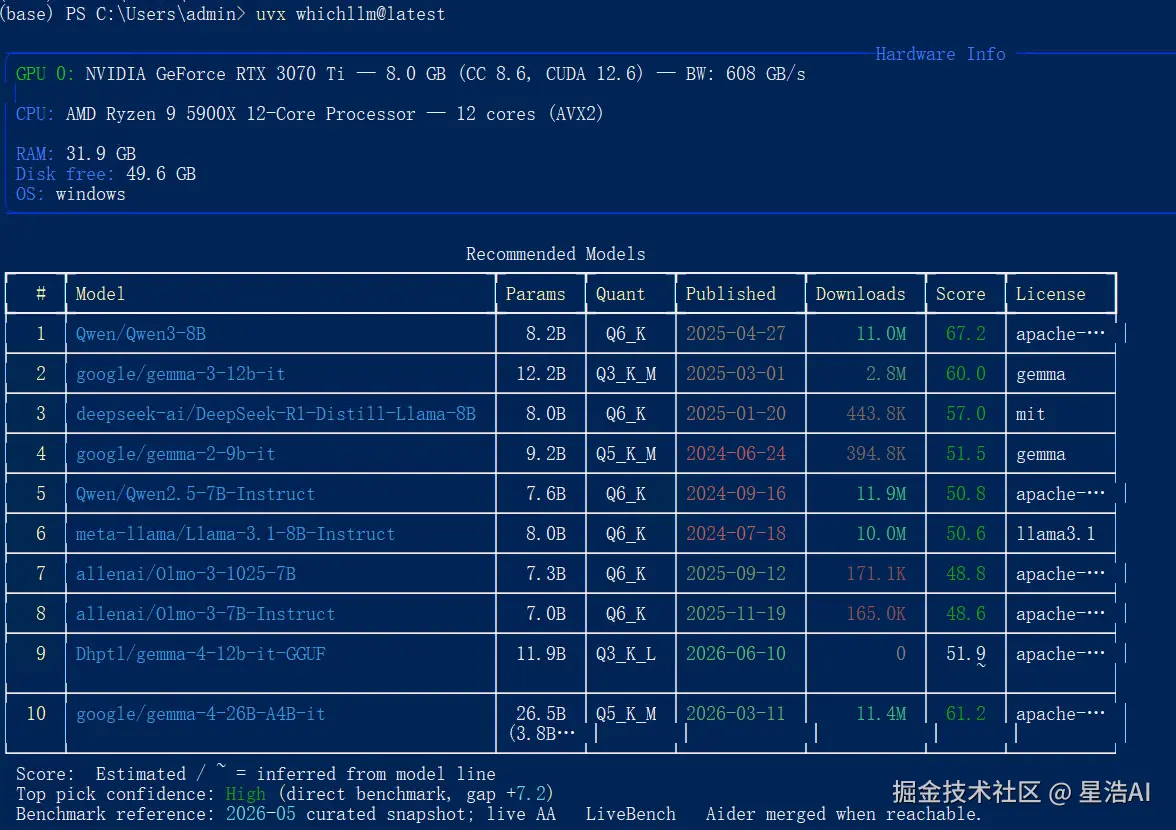 whichllm 默认排名输出
whichllm 默认排名输出
模拟采购时可加 GPU 参数:
bash
uvx whichllm@latest --gpu "RTX 4090"关注 score、量化档位、预估 tok/s------分数高的不一定最大,而是综合 benchmark 与硬件 fit 更优。
步骤 2:生产模型需要多少硬件(Qwen3-8B)
bash
uvx whichllm@latest plan "Qwen3-8B" --quant Q4_K_M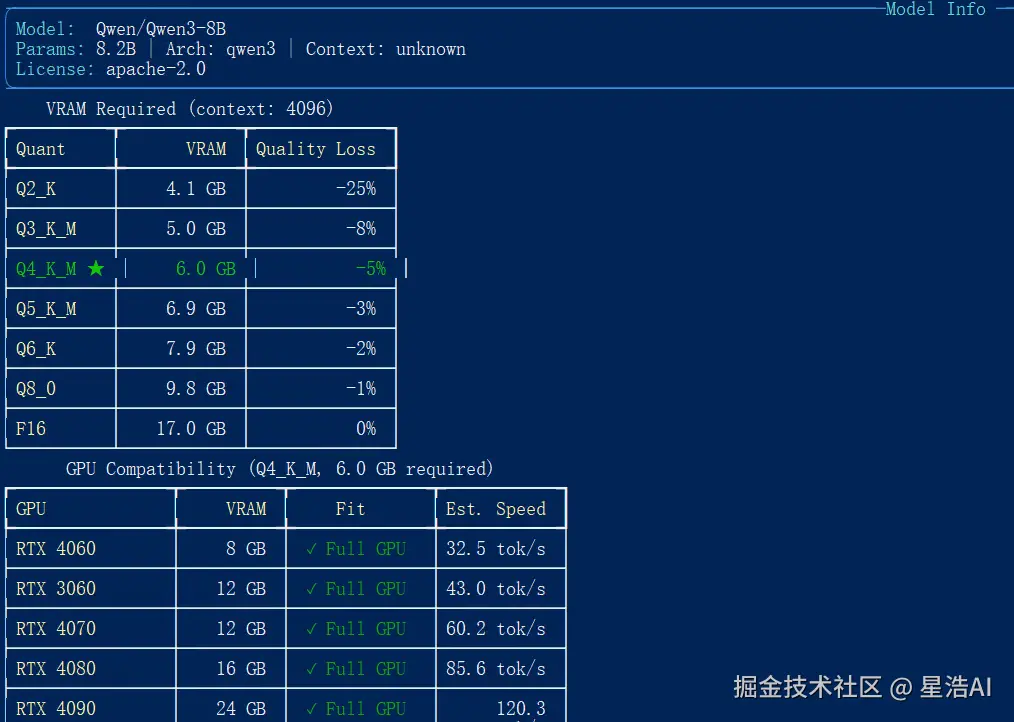 whichllm plan Qwen3-8B 硬件需求
whichllm plan Qwen3-8B 硬件需求
输出可与下文「部门生产」配置档位对照,写入采购论证材料。
步骤 3:衔接后文部署(演示模型 Qwen3-4B)
bash
uvx whichllm@latest snippet "Qwen3-4B"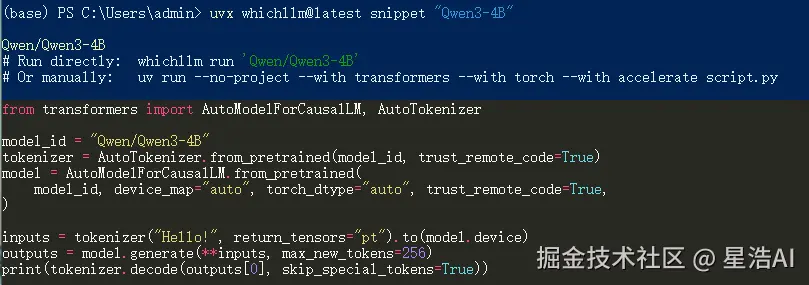 whichllm snippet 输出
whichllm snippet 输出
snippet 便于快速验证;正式生产部署仍建议走第六~七节的 vLLM / LMDeploy 方案。
2.3 合规常见硬件配置档位
以上工具给出的供你参考,业务还要留 KV Cache 与并发余量。人工决策可参考下表:
| 档位 | 典型硬件 | 适合模型 | 合规场景 |
|---|---|---|---|
| 入门验证 | 16GB 显存 / 32GB 内存 | 3B~4B 量化 | POC、单部门试用 |
| 部门生产 | 24GB 单卡 + 64GB 内存 | 4B~8B INT4/AWQ(如 Qwen3-8B) | 内网助手、文档问答(含 32K 长文档与并发余量) |
| 多并发服务 | 多卡 24GB+ 或 A100/L40 | 8B~14B 量化或多实例 | 全行/全司统一网关 |
显存估算公式:
text
VRAM ≈ 权重大小 + KV Cache + 框架开销长文档审阅、合规检查等场景上下文较长,KV Cache 会显著占显存------这一项需要按业务单独加余量,工具只能作起点参考。
三、合规场景模型怎么选
选型逻辑:硬件 → 模型规格 → 量化方式,按档位匹配,不硬性卡参数量上限。
3.1 企业生产推荐 vs 本文实操演示
| 层级 | 模型 | 说明 |
|---|---|---|
| 合规生产推荐 | Qwen3-8B | 多数企业部门生产首选:中文好、生态成熟、24GB 单卡可跑量化版 |
| 本文部署实操 | Qwen3-4B | 演示环境为单卡 24GB,用 4B 降低首次跑通失败率 |
本文第六~七节实操统一以 Qwen3-4B 跑通流程。部署步骤与 8B 量化版完全一致 ,上线时替换模型路径与
model字段即可。
3.2 选型原则
- 国产开源 + 可离线交付:Qwen 系在 ModelScope / HuggingFace 均有完整权重,便于内网镜像与审计
- 量化优先:INT4/AWQ 显著降低显存,合规内网助手性价比最高
- 框架支持:优先选 vLLM、LMDeploy 官方文档明确支持的型号
- 按档位升级:试点 3B~4B → 生产 8B 量化 → 多卡/多实例扩容,避免一步到位买过大模型
3.3 从 4B 切换到 8B(上线时改这几处)
- ModelScope / HuggingFace 模型 ID:
Qwen3-4B→Qwen3-8B(或 AWQ 变体) vllm serve/lmdeploy serve api_server的模型路径- API 调用中的
model字段
四、部署框架对比:vLLM vs LMDeploy vs Ollama
合规生产环境要在 性能、国产化、运维成本 之间取舍。三款框架定位如下:
4.1 对比总览
| 框架 | 梯队 | 最佳场景 | 性能特点 | 资源要求 | 部署复杂度 | 合规场景 |
|---|---|---|---|---|---|---|
| vLLM | 生产级 | 高并发在线服务 | PagedAttention,吞吐高 | 多 GPU 更佳 | 中等 | 内网 API 网关、审计可追溯 |
| LMDeploy | 生产级 | 量化/国产硬件 | W4A16 量化,显存省 | 昇腾 NPU / 低配 GPU | 较简单 | 国产化清单、资源受限 |
| Ollama | 试点级 | 本地快速验证 | 极简启动 | CPU / 低配 GPU | 极简 | 仅 POC,不建议高并发生产 |
4.2 详细分析
vLLM:
- ✅ 推理吞吐高,动态批处理成熟
- ✅ 多卡张量并行、OpenAI API 兼容
- ✅ 模型生态最广,文档与社区活跃
- ❌ 量化支持相对 LMDeploy 弱一些
LMDeploy:
- ✅ 量化方案完善(W4A16、KV8 等),显存效率高
- ✅ 支持昇腾 NPU,国产化部署友好
- ✅ 部署相对轻量
- ❌ 极限吞吐略低于 vLLM
Ollama:
- ✅ 一条命令拉模型,适合业务方快速体验
- ✅ 多模型切换方便
- ❌ 不适合高并发、可观测要求严的生产网关
4.3 合规场景选型建议
| 场景 | 推荐 |
|---|---|
| 高并发内网 API、多部门共用 | vLLM |
| 显存紧张、需量化、昇腾环境 | LMDeploy |
| 合规 POC、业务演示 | Ollama(本文不设独立部署章节) |
| 国产化硬件 + 量化生产 | LMDeploy + 昇腾 NPU |
五、环境准备与硬件要求
5.1 硬件要求
本文演示环境(Qwen3-4B):
- GPU:单卡 16GB+ 即可;生产 Qwen3-8B 量化 建议 24GB+
- 内存:32GB+(生产建议 64GB+)
- 存储:NVMe SSD,预留模型与量化版本空间
GPU 算力:
- vLLM:CUDA 算力 7.0+(V100、T4、RTX 20xx/30xx/40xx、A100、L4、H100 等)
- LMDeploy:NVIDIA GPU 或昇腾 NPU(通过量化降低门槛)
5.2 软件环境
- 操作系统:Linux(Ubuntu 20.04+ / CentOS 7+)
- Python:3.9~3.12(vLLM 推荐 3.12,LMDeploy 推荐 3.11)
- CUDA:11.8+(vLLM 新版本建议 CUDA 12.4+)
- Conda:用于环境隔离
5.3 我的配置

5.4 模型下载
- HuggingFace :
- ModelScope :
- 生产可选用 AWQ / GPTQ 量化变体,进一步降低显存
六、方案一:vLLM 部署实战
以下命令均以 Qwen3-4B 为例;生产替换为 Qwen3-8B 量化版即可。
6.1 环境安装
bash
# 创建虚拟环境
conda create -n vllm python=3.12 -y
conda activate vllm
# 安装 vLLM
pip install vllm安装conda环境
安装vllm

若模型较新或遇到兼容问题,可参考 vLLM 官方文档 安装对应版本:
bash
uv pip install vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly6.2 模型下载
python
#模型下载(从modelscope上复制SDK下载代码)
from modelscope import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen3-4B',
cache_dir="/root/autodl-tmp/models"
)
print(f"模型下载到: {model_dir}")模型下载
当然,你也可以从HuggingFace上下载。
6.3 启动服务
单卡部署:
bash
vllm serve /root/autodl-tmp/models/Qwen/Qwen3___4B --port 8000多卡并行:
bash
vllm serve /root/autodl-tmp/models/Qwen/Qwen3-4B \
--port 8000 \
--tensor-parallel-size 46.4 API 调用示例
python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1/",
api_key="EMPTY"
)
response = client.chat.completions.create(
model="Qwen3-4B",
messages=[
{"role": "user", "content": "你好,请介绍一下你自己"}
],
temperature=0.7,
top_p=0.95,
max_tokens=2048
)
print(response.choices[0].message.content)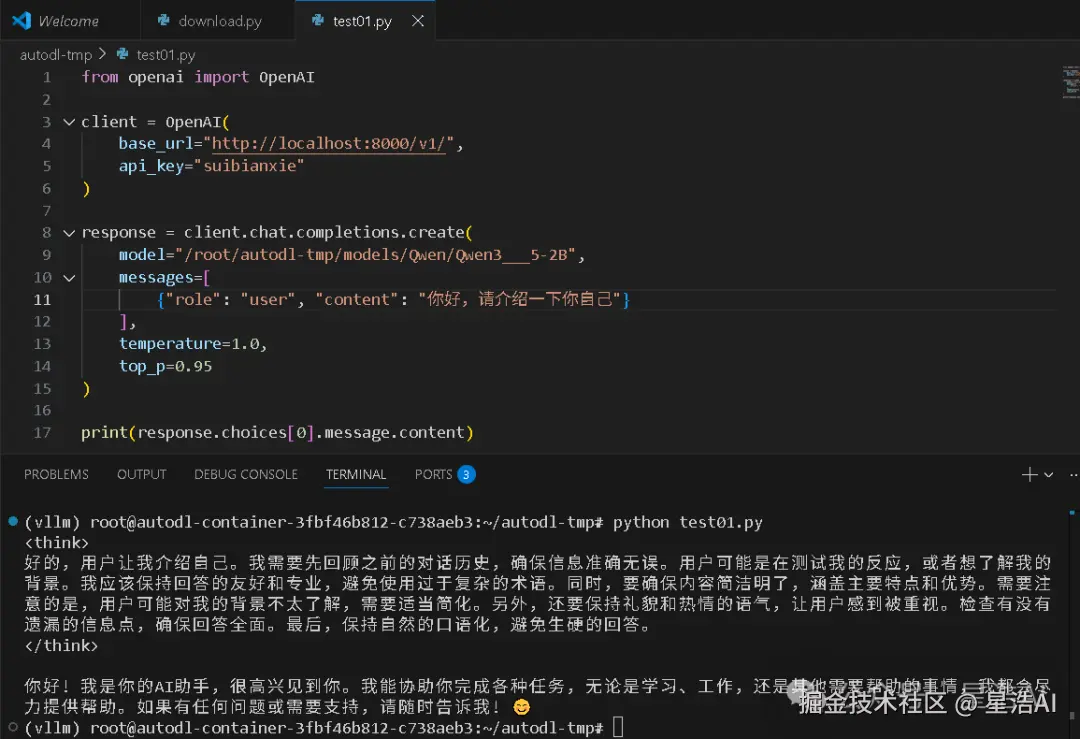
七、方案二:LMDeploy 部署实战
7.1 环境安装
bash
conda create -n lmdeploy python=3.11 -y
conda activate lmdeploy
pip install lmdeploy[all]
# 昇腾环境需额外安装
pip install dlinfer-ascend安装conda环境
安装lmdeploy
7.2 启动服务
bash
lmdeploy serve api_server /root/autodl-tmp/models/Qwen/Qwen3___4B --server-port 233337.3 API 调用示例
python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:23333/v1/",
api_key="EMPTY"
)
response = client.chat.completions.create(
model="Qwen3-4B",
messages=[
{"role": "user", "content": "你好,请介绍一下你自己"}
],
temperature=0.7,
top_p=0.95,
max_tokens=2048
)
print(response.choices[0].message.content)7.4 量化优化(显存受限或上 8B 时)
bash
lmdeploy convert qwen3-4b \
Qwen/Qwen3-4B \
--dst-path /data/models/qwen3-4b-turbomind-int4 \
--quant-policy 4 \
--tp 1生产环境将模型名换为 Qwen3-8B 及对应量化策略即可,流程相同。
八、推理参数与运维建议
8.1 推荐推理参数
python
{
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 2048
}合规文档问答、制度检索等场景建议 temperature 0.5~0.7,降低胡编风险;创意类场景可适当调高。
8.2 合规侧运维要点(简表)
| 项 | 建议 |
|---|---|
| 网络隔离 | 推理节点置于内网区,禁止直连公网 |
| 访问控制 | API 网关鉴权,按部门/角色限流 |
| 日志审计 | 记录请求时间、调用方、模型版本(不记录敏感正文或脱敏存储) |
| 模型溯源 | 权重文件校验和、版本号写入配置管理 |
| 密钥管理 | API Key 走企业密钥库,禁止硬编码 |
九、总结与合规落地清单
9.1 核心要点回顾
- 合规行业私有化是默认路径,不是可选项
- llmfit + whichllm 解决「买什么硬件、跑什么模型」
- 生产推荐 Qwen3-8B INT4/AWQ ,实操可用 Qwen3-4B 跑通同一套流程
- vLLM 适合高并发网关,LMDeploy 适合量化与国产化硬件
9.2 场景选型速查
| 场景 | 推荐方案 |
|---|---|
| 高并发生产环境 | vLLM |
| 资源受限 / 量化 / 昇腾 | LMDeploy |
| 快速 POC | Ollama(框架对比中选用,生产另建 vLLM/LMDeploy) |
| 国产硬件环境 | LMDeploy + 昇腾 NPU |
9.3 合规落地五步检查表
- 网络:推理服务仅内网可达,出站策略已审批
- 硬件:llmfit/whichllm 输出已归档,采购配置与模型档位一致
- 模型:权重来源可追溯,版本与量化方式已登记
- 框架:vLLM 或 LMDeploy 已跑通,API 接入鉴权与日志
- 运维:监控、备份、应急预案已纳入现有 IT 流程