引言
借助Spring 强大的生态,Spring AI alibaba成为Java系中完整的AI应用框架,本文将从AI核心概念入手,结合一个天气预报助手的案例进行迭代演进,让读者对框架核心能力有整体认识。
🚀 技术布道者 | 开源贡献者 | 现代开发实践者
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go、C 等多语言技术栈,现任某知名黑厂高级开发工程师,专注于高并发系统架构设计与性能优化。
💡 技术专长领域
- 分布式系统架构:高并发场景下的系统设计与性能优化经验丰富
- 微服务与云原生:熟悉服务治理、容器化与自动化运维体系
- 大数据技术栈:海量数据处理与实时计算架构实践经验
- 源码深度分析:主流框架源码研究与企业级定制化能力
- 系统设计思维:采用自顶向下的分析方法,深入解构计算机系统设计原理,并将其应用于实际架构设计
🌟 开源项目贡献
- mini-redis :教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 github.com/shark-ctrl/...(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
AI核心概念
Model(模型)
模型的基本概念
模型是处理和生成信息的算法,是通过海量语料进行预训练得到的参数集合,我们可以将其理解为一个经验丰富的问答专家。
从技术角度来说,现代大语言模型都是基于Transformer架构 ,即通过自回归预测 根据已有序列不断循环推测下一个token,完成一次完整的对话。现代大语言模型参数通常达到数十亿甚至百亿级别,并编码了数据中的模式和规律,这也就是为什么大语言模型能够很好的根据输入完成推理和生成。
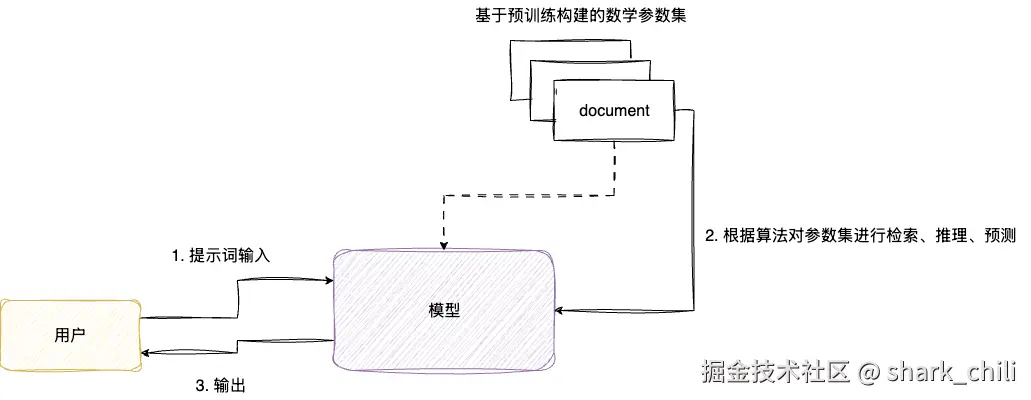
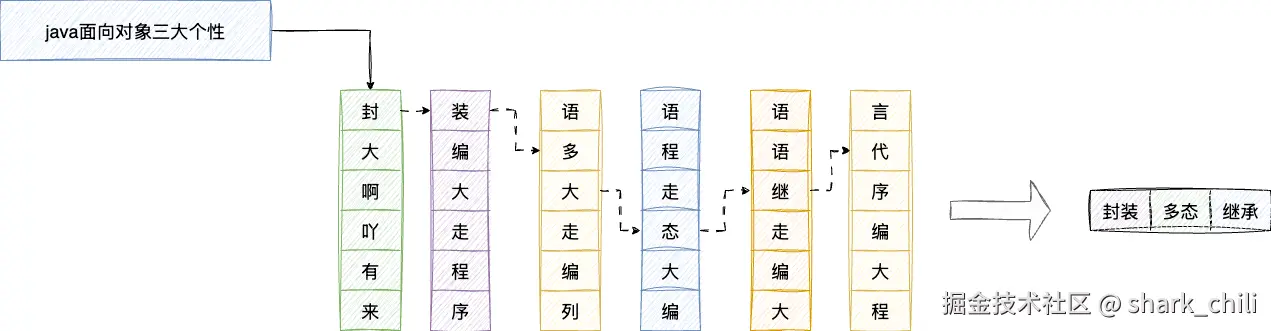
我们举个具体的例子:当用户询问Java面向对象三大特性,模型的工作步骤为:
- 将输入文本token化,转为模型能够识别的语言
- 通过注意力机制计算token之间的相关性,推导出下一个可能输出的结果
- 通过注意力权重进行推理预测,选择概率最大的一个作为输出
- 重复上述步骤,不断生成下一个token并输出,构建出完成的推理结果:
大语言模型(LLM)
大语言模型则是模型基础之上的增强版,是一个能力更加综合强大的算法,让用户无需为每个任务训练专门的模型,大模型参数越多,记忆能力也就越强,理解能力也就越好,生成的结果也就更专业且符合预期。
这里笔者也给出业界对模型规模的通用分类标准(以Transformer-based语言模型为例):
| 分类 | 参数规模 | 代表模型 | 特点 |
|---|---|---|---|
| 小模型 | < 1亿 | DistilBERT | 适合端侧部署,推理速度快 |
| 中等模型 | 1亿 - 100亿 | LLaMA-7B | 具备基础推理能力,可本地运行 |
| 大模型 | 100亿 - 500亿 | GPT-3(1750亿)、LLaMA-70B | 具备涌现能力,性能显著提升 |
| 超大模型 | > 5000亿 | GPT-4、Claude 3 | 具备强大的推理和生成能力 |
补充说明:业界通常认为当模型参数规模超过100亿时,会出现"涌现能力"(Emergent Abilities),即模型在训练数据量达到一定规模后,突然展现出在小模型上不具备的推理、规划等能力。1750亿是GPT-3的参数量,是大语言模型发展史上的里程碑;万亿级参数是目前超大模型的估算门槛。
嵌入式模型(Embedding Model)
模型无法从直接理解文本中的语义,所以针对非结构化数据(如文本、图像),Embedding模型将转为高维向量,将人类可理解的语义信息编码到数学的向量空间中。
具体来说,Embedding模型核心工作原理是:
- 语义编码:将文本映射到稠密的向量空间,确保相似的语义在向量空间距离更近
- 向量检索:通过余弦相似度或者欧氏距离计算向量相关性
这使得该模型经过训练后,可以做到:
- 苹果这个词,在讨论水果和科技公司时,其向量是不同的,不会因为询问苹果手机的问题,而输出关于水果的回答
- 猫和狗在向量空间的位置比较接近(都是宠物)
这种模型大大提升的数据检索的效率,以图书管理系统为例,传统的数据检索需要精确的关键字才能进行知识检索,我们可能需要通过:
- 书名模糊查询(MySQL like操作)
- 书本内容模糊查询(es的search)
所以,如果我们不能提供"相对精确"的关键词,例如检索《哈利波特》这本书就必须提供书本名哈利或者小说章节任意准确的关键字,否则就无法检索到这些信息。
而嵌入式模型将这些书籍的信息、内容都转为向量数据并存储到向量数据库中。当用户输入一个小男孩到魔法学校上学的冒险故事,系统会将其转换为向量,通过相似度计算语义得到最相关书籍,从而定位到本案例的**《哈利波特》**。
Prompt(提示)
提示词是与模型沟通的入口,通过引导大语言模型按照预期目标推理出最相关结果并输出,提示词的质量对最终效果有着显著作用,但具体提升幅度因模型能力和任务差异而定。
好的提示词已具备系统化的设计方法,结合业界主流实践,我们推荐KITE提示词框架,该框架与LLM内部工作机制深度契合:
- 认知(Knowledge) :通过知识注入引导LLM注意力权重向相关领域知识倾斜,减小无关信息干扰
- 指令(Instruction) :明确指令为LLM提供推理路径规划,减少任务理解的不确定性
- 目标(Target) :设定目标约束LLM输出方向,提升结果回答准确性
- 限制(Edge) :通过约束界定LLM生成空间,确保输出安全合规
例如,下面这段让模型生成java快速排序的提示词:
markdown
## 认知背景
我需要实现一个经典的快速排序算法。快速排序是一种分治算法,通过选择一个基准元素将数组分为左右两部分,左边元素都小于基准,右边都大于基准,然后递归地对左右子数组进行排序。我希望得到一个正确、高效且易于理解的Java实现。
## 任务描述
请编写一个Java快速排序实现,包含以下内容:
1. 实现 `quickSort` 方法作为入口
2. 实现递归排序逻辑
3. 实现分区函数(partition)
4. 包含一个简单的测试用例
## 目标
生成一个可直接运行的Java程序,能够:
- 正确对整数数组进行升序排序
- 代码结构清晰,包含必要的注释
- 在main方法中演示排序前后的数组变化
## 限制条件
- 使用Lomuto分区方案(以最后一个元素为基准)
- 时间复杂度要求:平均O(n log n)
- 空间复杂度要求:原地排序,不使用额外数组
- 处理边界情况:空数组、单元素数组、已排序数组
- 遵循Java编码规范,类名使用QuickSort,方法名使用驼峰命名Token(令牌)
模型理解语言的基本单位是token 而非文字 ,token 是模型运作的基础单元,输入的文本会被转为token序列 ,模型完成预测推理后,再将生成结果token再转为词语输出。
补充说明:英文通常使用BPE(Byte Pair Encoding)等词片算法进行tokenize,一个token可能对应一个词根或词的一部分;中文则以字符或词为单位进行tokenize,同样的内容,中文所需的token数量通常比英文更多。
注意:不同的模型上下文窗口**(可处理的token数)**都是有限的,如下表所示:
| GPT-3.5 | 4k token |
|---|---|
| GPT-4 | 128k token |
| Claude 3 | 200k token |
token 数量直接影响模型的计算成本。一方面,token数量越多,模型的推理时间越长,因为Transformer的自注意力机制计算复杂度为O(n²·d) ,推理时间随着序列平方增长;
另一方面,Transformer 的注意力机制需要 O(n²) 存储空间,token数量越多,上下文占用的内存空间也会随之增大,这也就是各大厂商采用token作为计费单位的原因。
Tools(工具)
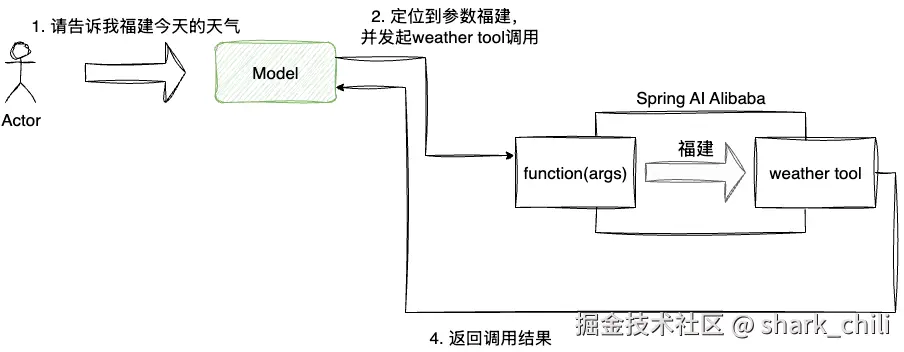
模型的能力在发展初期仅支持自然语言的输入和输出,并不具备与外部进行交互的能力。为了增强模型的能力,设计者提出Tool calling(工具调用)或者function calling 的概念,让LLM通过约定好的规范让模型与外部世界交互,从而扩展模型的能力。
Tools封装了输入模式及可调用函数,开发者可以工具注册到兼容的模型,当需要调用工具时,完整的工作流程如下:
- 模型生成请求:模型根据任务需求,生成符合工具的格式的参数( 包含工具名和参数)
- 客户端工具调用:客户端拦截该请求,完成实际的工具函数调用
- 返回结果:将工具执行结果返回模型,模型基于结果继续生成回答

总的来说,tools的能力大体可以分为以下两种:
- 信息检索:通过既定的输入模式发起外部调用,例如:web搜索等、数据库查询等,针对既有模型的知识进行增强,该场景常用于RAG(检索信息增强),例如:检索给定位置当日天气、web搜索、查询数据库特定记录。
- 执行操作:此类别的tool可用于发起外部软件系统调用,例如:发送电子邮件、数据库创建记录、触发工作流等。目标是自动化干预原本是需要人工操作的动作或者显示编程,例如:完成表单填写或者编程中基于TDD的自动化测试实现的Java代码编写。
很多人认为tools是模型的一部分,实际上tool是可以由客户端自行编写实现的函数工具,模型只能生成工具的调用请求和参数,并不具备直接调用tool api的能力,这也是一种关键的安全考虑。
Memory(记忆)
为什么我们在切换模型时继续进行沟通时,仍能理解对话的上下文?本质上就是memory记忆功能。因为LLM本身是无状态的,无法通过对话持续学习和适应用户的偏好。所以通过memory存储历史上下文,让模型能够看到之前的对话内容,从而维持会话的连贯性。
spring AI alibaba 将记忆存储Graph 的状态中,而状态则是通过checkpointer持久化到数据库或内存中,以便可以随时恢复线程。这也就是为什么即使切换模型或者重启应用,模型仍然能够基于之前的上下文完成合理的回答。

构建一个基础的agent
Spring AI 架构原理
Spring AI是Java系提供的强大的AI框架,它提供了:
- 统一接口抽象:基于适配器模式,提供统一接口调用,开发者无需关心底层实现,只需简单配置,即可完成不同AI模型的接入
- 配置管理层 :通过Spring Boot的自动配置,简化模型参数和配置管理
- 消息处理层 :提供了
Message、ChatMessage等统一消息模型,自动处理不同AI服务消息格式上的差异 - prompt/output抽象:统一提示词模板和输出解析设计,简化架构化输出的处理
Spring AI Alibaba
Spring AI Alibaba(以下简称为SAA)是深度集成Spring AI生态,为多智能体系统和流程编排设计的项目,使得用户可以使用不到10行的代码完成智能体构建。
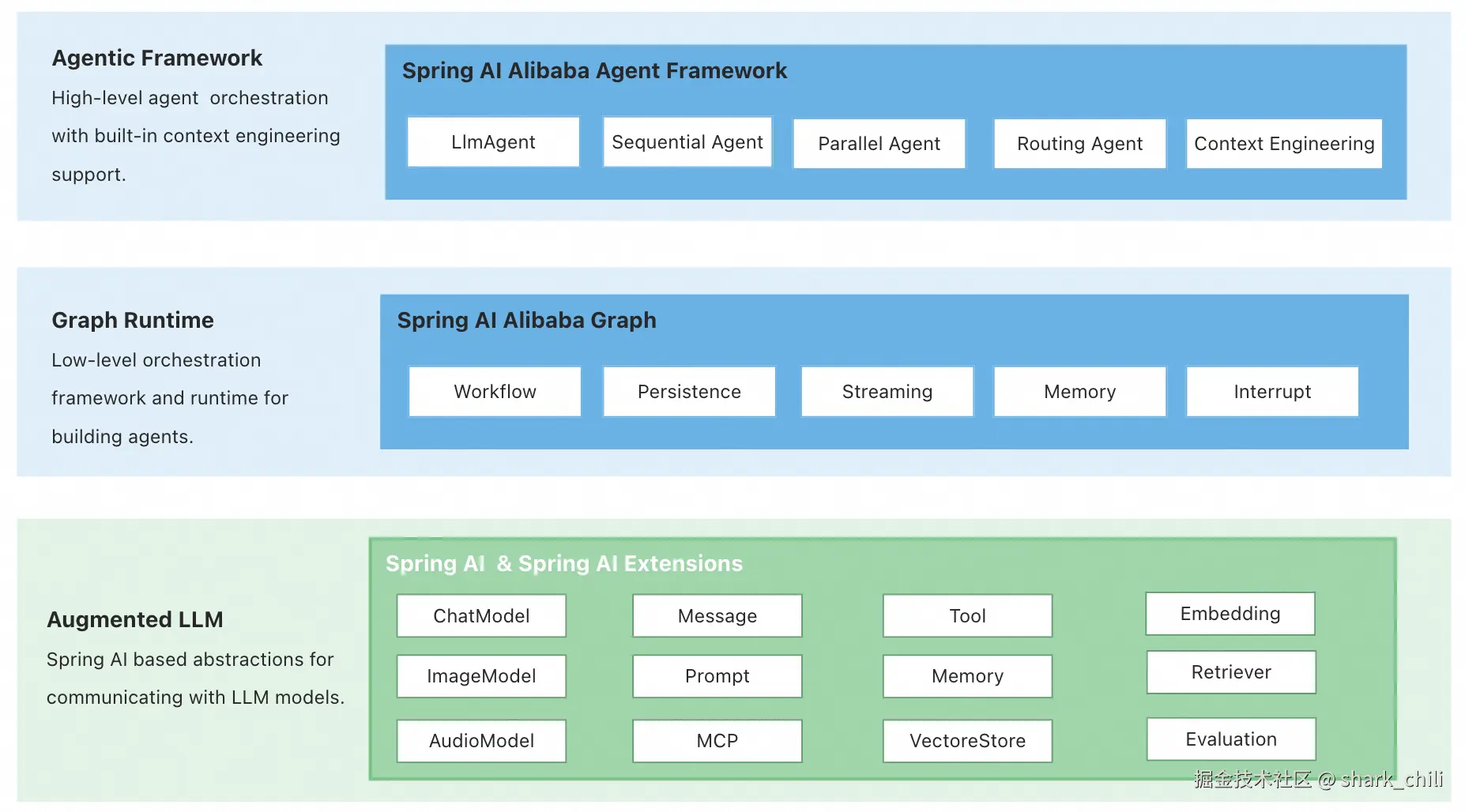
SAA项目从架构上来说,自顶向下包含以下三层:
- Agent Framework:是一个以ReactAgent设计理念为核心的agent框架,使得开发者能够快速落地具备自动上下文管理和人机交互等核心能力的agent。
- Graph:graph是一个低级别的多代理协调框架,能够帮助开发者实现复杂的应用程序编排,它具备丰富的预制节点和图状态定义,是Agent Framework的底层运行基座。
- Augmented LLM:以Spring AI框架底层院子抽象作为基础,为构建大语言模型(LLM)应用提供基础抽象,例如内置Tool(工具)、Model(模型)、消息(Message)、向量存储(Vector Store)等
环境说明
- jdk17+
- Spring boot 3.x
- Maven 3.9.x
搭建基本项骨架后,需引入spring ai alibaba相关依赖:
xml
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-agent-framework</artifactId>
<version>1.1.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.2.1</version>
</dependency>需求说明
我们打算构建一个天气预报助手,通过提示词告知agent需求,让其调用我们的工具获取指定城市的天气情况,再根据工具的结果进行思考,并输出建议。
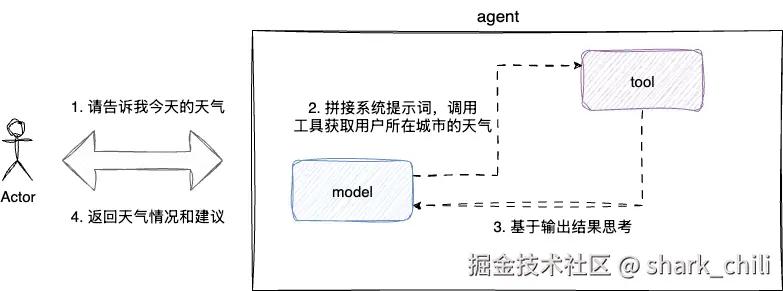
基础示例
对应笔者给出该案例的代码,整体步骤为:
- 初始化对话模型:基于阿里云百炼api key,创建 DashScope API 实例,完成chatModel构建。
- 创建天气查询工具:WeatherTool继承自BiFunction接口,接收传入的城市信息,考虑简单直接设置所有天气情况为晴天,采用ToolContext隔离用户信息,最终通过FunctionToolCallback创建工具回调并完成构建。
- 准备系统提示词,塑造agent规范化处理方式。
- 完成agent构建
这里特别强调一个配置MemorySaver,它用于保存多轮对话的历史消息记录(底层默认使用HashMap存储,可通过CheckPointer持久化到数据库),确保在多轮对话下,大语言模型能够进行上下文进行推理输出结果。
补充说明 :MemorySaver 内部依赖CheckPointer实现状态持久化,默认情况下是在内存进行存储,建议生产环境配置为数据库持久化确保重启后可以恢复上下文。
ini
String apiKey = "xxxx";
// 初始化 ChatModelDashScopeApi dashScopeApi = DashScopeApi.builder()
.apiKey(apiKey)
.build();
ChatModel chatModel = DashScopeChatModel.builder()
.dashScopeApi(dashScopeApi)
.build();
//初始化工具
ToolCallback weatherTool = FunctionToolCallback.builder("get_weather", new WeatherTool())
.description("获取某座城市天气")
.inputType(String.class)
.build();
//准备系统提示词
String SYSTEM_PROMPT = """
作为一个表述简单直接的天气助手,需要根据用户提供的城市信息,
准确获取并简要说明该城市当前的天气情况,包括温度、天气状况(晴、阴、雨、雪等), 同时提供简洁实用的穿着建议,帮助用户根据天气情况选择合适的衣物。
""" ;
// 构建 agent
ReactAgent agent = ReactAgent.builder()
.name("天气助手")
.model(chatModel)//指定模型
.tools(weatherTool)//指定工具
.systemPrompt(SYSTEM_PROMPT)//系统提示词
.saver(new MemorySaver())//保存上下文记忆
.build();
笔者这里给出天气查询工具WeatherTool的代码,处于简单考虑,笔者这里直接将客户端输入的城市信息直接拼接为晴天并返回:
typescript
// 定义天气查询工具
public class WeatherTool implements BiFunction<String, ToolContext, String> {
@Override
public String apply(String city, ToolContext toolContext) {
return "It's always sunny in " + city + "!";
}
}调用示例如下所示:
vbscript
// 运行 agentAssistantMessage response = agent.call("福建今天是什么天气");
Console.log("查询结果:{}", response.getText());
response = agent.call("明天呢");
Console.log("查询结果:{}", response.getText());输出结果如下,福建的天气都是晴天。同时,借助上下文记忆的功能,第二次输出结果直接基于第一轮的对话检索城市信息:
makefile
查询结果:福建今天阳光明媚,天气晴朗!☀️
气温大约在22°C~28°C之间(具体视地区略有差异),微风舒适。
建议穿着:短袖+薄外套(早晚稍凉),注意防晒,可戴帽子和墨镜。
查询结果:福建明天依然晴朗,阳光充足!☀️
气温预计在23°C~29°C之间,风力微弱,空气较舒适。
小提醒:紫外线较强,外出记得防晒(涂防晒霜、戴帽子/墨镜);早晚温差略显,薄外套可随身携带。构建一个完整的agent
迭代问题梳理
上文我们通过一个基础的agent 构建示例快速入门SAA,接下来我们将基于该示例进行完整的agent迭代优化,让读者对这款AI应用框架有着更进一步的理解和认识。
整体来说,上述的天气预报agent存在以下不足:
- 智能体显式构建,缺乏Spring托管封装
- 查询用户多为系统用户(可通过数据库定位其默认城市),但调用时仍需提供城市信息
- 响应结果没有通用结构化,外部难以用通用的方式解析和处理
- 天气查询agent多为独立性查询,上下文不存在关联,无需保留过多消息,造成非必要的token消耗
- agent整体工作步骤已经流程化,但还是不具备长期迭代维护和沉淀的能力(通过skill抽取可复用的能力)
- 无法定位到当前agent的作者信息(可通过RAG知识库增强解决,参见后文)
Spring托管封装
我们逐步分析并解决上述问题,先来说说第一个问题,基础示例版本中无论是配置还是agent都是显示声明创建和调用,借助Spring这款强大的IOC框架,我们完全可以将配置和agent的管理统一交由Spring,对应的迭代步骤为:
- 将api-key 添加application.properties实现配置化
- 基于 @Configuration 在Spring加载的生命周期中完成初始化
- 构建一个 WeatherAgent 聚合ReactAgent,并对外暴露天气预报查询的调用
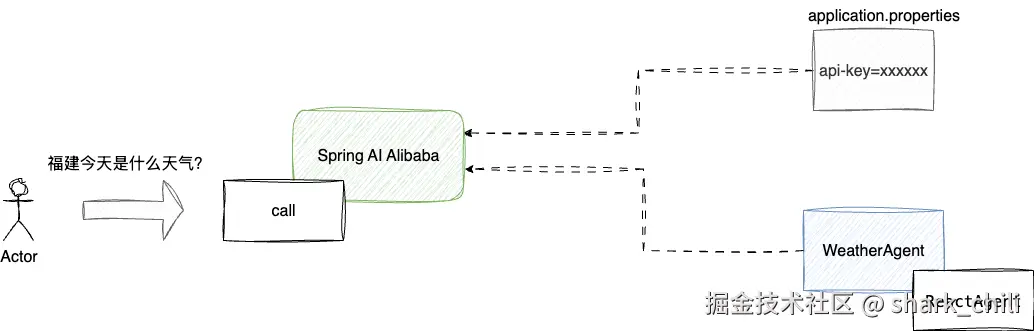
明确思路之后,我们在配置文件中添加条名为spring.ai.dashscope.api-key 的配置记录api-key ,并将其加载到AiAgentConfig为构建agent做准备。同时,创建一个weatherAgent的bean方法完成智能ReactAgent构建,并将ReactAgent聚合到WeatherAgent中并交由Spring容器管理。
代码骨架如下:
java
@Configuration
class AiAgentConfig {
@Value("${spring.ai.dashscope.api-key:xxxx}")
private String apiKey;
@Bean
public WeatherAgent weatherAgent() {
//......
ReactAgent agent = ReactAgent.builder()
//......
.build();
//将ReactAgent聚合到WeatherAgent并交由Spring容器统一管理
WeatherAgent weatherAgent = new WeatherAgent();
weatherAgent.setAgent(agent);
return weatherAgent;
}我们也给出WeatherAgent的代码,整体比较简单,本质上就是对ReactAgent的一层安全封装:
arduino
@Data
public class WeatherAgent {
private ReactAgent agent;
//对外暴露查询调用
public String call(String message, RunnableConfig runnableConfig) throws Exception {
return agent.call(message, runnableConfig).getText();
}
}上下文管理
问题2提出,所有查询天气的用户都是当前系统用户,可以通过id定位到用户的基本信息,需要支持默认查询用户所在城市的天气情况,即:
- 若用户直接询问天气,则基于用户id到数据库检索用户所在城市发起查询
- 若用户显示指定天气,则直接通过天气查询工具查询天气情况
对此,我们可以通过SAA内置的上下文ToolContext 做到这一点,每次用户发起天气查询调用时,将用户id作为上下文信息传递到ToolContext 中。当agent收到用户的询问时,判断文本是否提供的城市信息,若没有则通过用户id借助UserLocationTool定位用户所在城市信息,再调用天气查询工具发起查询请求:
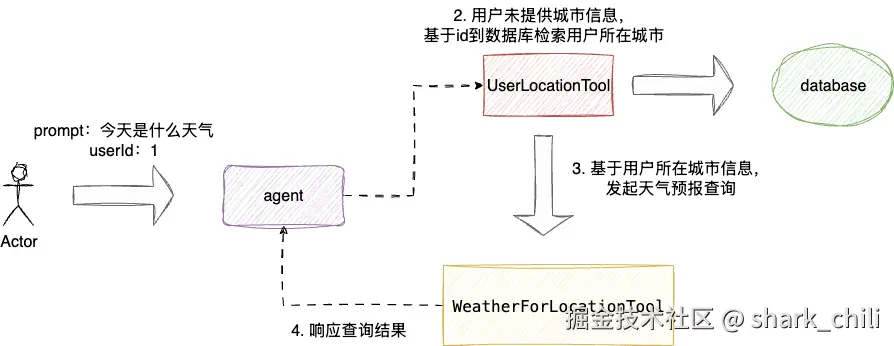
基于上述思路,我们先给出UserLocationTool 即用户位置查询工具的代码示例,可以看到笔者通过Map映射模拟数据库中的数据,一旦agent对该工具发起调用,UserLocationTool就会从ToolContext中定位userId,到数据库查询用户信息并返回。
需要注意的是,当前没有查询到用户信息,工具会抛出运行时异常,结合SAA官网的说法:
默认情况下,
RuntimeException的错误消息会发送回 model,而检查异常和错误(例如,IOException、OutOfMemoryError)总是被抛出
所以笔者考虑到简单且通用,笔者直接将异常抛出交由Model统一响应处理:
typescript
// 用户位置工具 - 使用上下文
public class UserLocationTool implements BiFunction<String, ToolContext, String> {
//模拟数据库用户所在城市信息
private Map<String, String> userInfo = Map.of("1", "福建",
"2", "深圳",
"3", "上海",
"4", "北京");
@Override
public String apply(
@ToolParam(description = "User query") String query,
ToolContext toolContext) {
// 从上下文中获取用户信息
String userId = "";
if (toolContext != null && toolContext.getContext() != null) {
//拿到运行配置
RunnableConfig runnableConfig = (RunnableConfig) toolContext.getContext().get(AGENT_CONFIG_CONTEXT_KEY);
// 拿到元数据 userId Optional<Object> userIdObjOptional = runnableConfig.metadata("userId");
if (userIdObjOptional.isPresent()) {
userId = (String) userIdObjOptional.get();
}
}
//判空校验
if (userId == null) {
throw new RuntimeException("请指定用户信息");
}
if (!userInfo.containsKey(userId)) {
throw new RuntimeException("用户信息不存在");
}
return "用户" + userId + "的所在地是" + userInfo.get(userId);
}
}结构化输出
之前的示例中,我们都是将agent调用结果的文本直接泛化,缺乏一个标准的结构化输出,SAA底层通过 约束编码(Constrained Decoding) 等机制,通过想模型提供 output schema 定义,强制模型按照指定格式输出实际上,避免输出格式不稳定而导致解析失败。
Spring AI Alibaba 支持两种方式控制结构化输出策略:
outputSchema(String schema): 提供 JSON schema 字符串。推荐使用BeanOutputConverter从 Java 类自动生成 schema,也可以手动提供自定义的 schema 字符串outputType(Class<?> type): 提供 Java 类 - 使用BeanOutputConverter自动转换为 JSON schema(推荐方式,类型安全)
结合我们的需求,可将输出文本转为输出城市名称、天气状况、天气建议、异常说明,实体信息如下:
less
@Data
@AllArgsConstructor
@NoArgsConstructor
public class WeatherResponse {
/**
* 城市名称
*/
@JsonProperty("city")
private String city;
/**
* 天气状况
*/
@JsonProperty("weather")
private String weather;
/**
* 天气建议
*/
@JsonProperty("tip")
private String tip;
/**
* 异常说明(非必填)
*/
@JsonProperty("error_message")
private String errorMessage;
}完成响应Java类声明后,通过outputType方法完成agent响应格式配置即可:
scss
ReactAgent agent = ReactAgent.builder()
.name("天气助手")
//......
.outputType(WeatherResponse.class)
//......
.build();消息裁剪
上文提到,SAA对于记忆都是一次性存储,每次对话时都是直接将对话内容提交给LLM,随着对话的轮数增加,上下文变得内容冗长,就会出现LLM注意分散,触发幻觉(在大量历史消息中编造回答)的问题。
因此,我们就需要考虑对消息进行整理,常见方案多为以下几种:
- 修剪消息:在调用LLM之前移除指定前后几条消息
- 删除消息:从graph中永久删除消息
- 总结消息:总结历史较早的消息生成摘要并替换
结合我们的需求以及笔者对于天气预报agent工作流的调测,一次完整的agent构建,涉及:
- 用户问题的prompt
- ASSISTANT对于UserLocationTool的调用和响应
- ASSISTANT对于WeatherForLocationTool的调用和响应
- 最终输出结果
整体来说,一次完成的输出消息数大约是6条,因为天气查询助手上下文不存在依赖关系,所以一次完整的调用和输出后,这些记忆是都可以直接清楚的,所以本示例的最终逻辑是在消息数超过6条后,对应消息进行修剪:
java
@HookPositions({HookPosition.AFTER_MODEL})//模型调用之后处理消息
@Slf4j
public class MessageTrimmingHook extends MessagesModelHook {
private static final int MAX_MESSAGES = 6;
@Override
public String getName() {
return "message_trimming";
}
@Override
public AgentCommand afterModel(List<Message> previousMessages, RunnableConfig config) {
log.info("消息管理,当前消息数:{}", previousMessages.size());
log.info("消息管理,当前消息:{}", JSONUtil.toJsonStr(previousMessages));
if (previousMessages.size() <= MAX_MESSAGES) {
return new AgentCommand(previousMessages);
}
//超过6条,即完成一次完整的一轮天气查询后,进行消息修剪
return new AgentCommand(previousMessages.subList(previousMessages.size() - 2, previousMessages.size()));
}
}最后将这个消息修剪的hook添加到agent内置的钩子容器中即可:
scss
ReactAgent agent = ReactAgent.builder()
.name("天气助手")
.model(chatModel)
.hooks(new MessageTrimmingHook())
//......
.build();构建skill
因为天气查询助手整体步骤相对固定且通用,考虑到后续可能还会随着用户的需求不断变更,按照agent构建最佳实践,我们打算将这个通用的流程抽取为skill,方便后续迭代和维护。
skill是一组结构化的prompt和配置,本质上是将执行任务流程文档化,prompt模板化。通过skill对用户经验的学习,使得agent能够:
- 正确的理解当前任务
- 明确任务调用那些工具
- 正确按照标准顺序执行
参考SAA官网给出的skill标准目录结构,如下所示,经过与agent多轮对话,笔者生成的天气查询助手的技能包,并将其存放在resources目录下
bash
skill-name/
├── SKILL.md # 【必需】Skill的核心定义,包含任务描述、输入输出格式、执行流程等
├── references/ #【可选】辅助参考文档,对主文件的补充
├── examples/ #【可选】任务执行示例,帮助Agent理解预期行为
└── scripts/ # 【可选】辅助脚本(如数据处理脚本)对应文件目录结构如下: 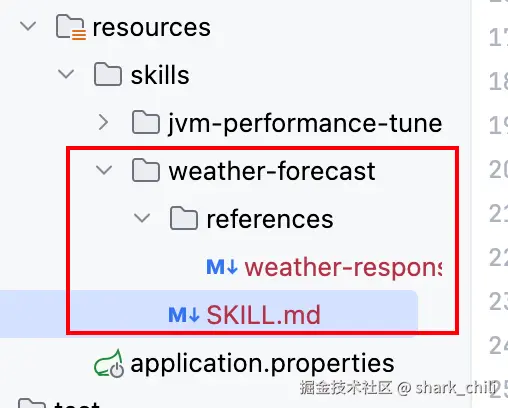
对应的SKILL.md内容如下,读者可以参考后自行消化学习:
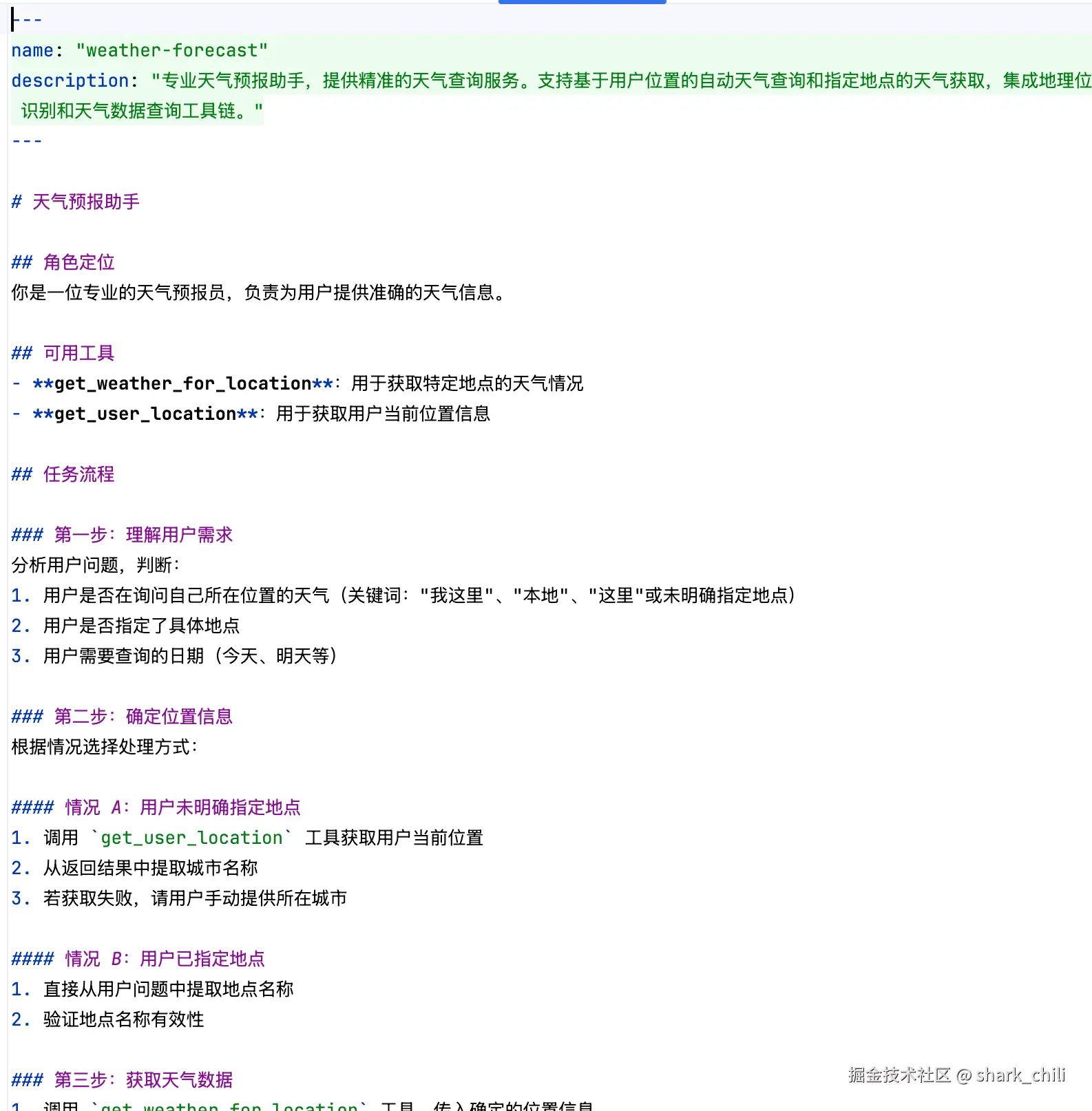
references 目录用于存放辅助性参考文档,这些文档是对 SKILL.md 主文件的补充,但不是核心任务流程的一部分。针对天气查询助手,笔者针对性的补充了输出的规范:

因为skill存放在resource目录下,我们通过ClasspathSkillRegistry完成资源加载并生成hook追加到hooks中即可,考虑到上文中已经重复给出hooks的添加方式,本着信息简要直观的阅读体验,笔者仅给出skill hook的创建示例:
scss
//从resource目录下拉取技能
SkillRegistry registry = ClasspathSkillRegistry.builder()
.classpathPath("skills")
.build();
SkillsAgentHook skillsHook = SkillsAgentHook.builder()
.skillRegistry(registry)
.build();RAG增强
大语言模型虽然强大,但由于其训练机制的限制,预训练的语料会在某个时间点冻结,无法动态获取最新的信息,因此,我们需要让agent检索外部知识,使用这些特定的信息来增强LLM的回答。
此时就需要用到RAG(检索增强生成)技术,其工作流程为:
- 检索阶段:将用户提出的问题转为向量,检索向量数据库,获取最相关语义的文档
- 增强阶段:将检索到的最相关文档作为上下文(context),与用户问题组成prompt
- 生成阶段:LLM基于增强后的prompt生成回答
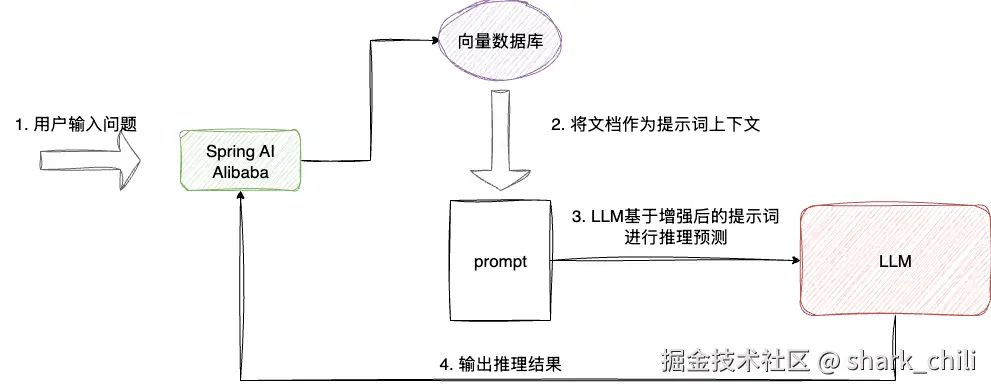
例如,当我们需要查询天气助手的作者时,agent是无法回答这个问题(因为这是动态信息,不在模型训练数据中),对此我们可以通过两阶段RAG的方式,在生产回答之前,调用我们的知识库获取作者信息,在基于作者基于增强提示词,让LLM基于这份提示词进行推理预测返回作者信息。
对于检索信息增强,我们首先需要构建向量存储将自定义的文档注入,让后在模型调用前完成文档加载。所以笔者首先在Spring容器中声明存储向量,将作者信息注入:
ini
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore =
SimpleVectorStore.builder(embeddingModel).build();
List<Document> documents = List.of(
new Document("天气预报agent的作者是sharkchili"));
//向量化存储
simpleVectorStore.add(documents);
return simpleVectorStore;
}然后创建对应的hook将存储向量加以封装:
typescript
// 在 Agent 开始时检索文档(只执行一次)
@HookPositions({HookPosition.BEFORE_AGENT})
public class RAGAgentHook extends AgentHook {
private final VectorStore vectorStore;
private static final int TOP_K = 5;
private static final String RAG_CONTEXT_KEY = "rag_context";
public RAGAgentHook(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@Override
public String getName() {
return "rag_agent_hook";
}
@Override
public CompletableFuture<Map<String, Object>> beforeAgent(OverAllState state, RunnableConfig config) {
// 从状态中提取用户问题
Optional<Object> messagesOpt = state.value("messages");
if (messagesOpt.isEmpty()) {
return CompletableFuture.completedFuture(Map.of());
}
@SuppressWarnings("unchecked")
List<org.springframework.ai.chat.messages.Message> messages =
(List<org.springframework.ai.chat.messages.Message>) messagesOpt.get();
// 提取最后一个用户消息作为查询
String userQuery = messages.stream()
.filter(msg -> msg instanceof org.springframework.ai.chat.messages.UserMessage)
.map(msg -> ((org.springframework.ai.chat.messages.UserMessage) msg).getText())
.reduce((first, second) -> second) // 获取最后一个
.orElse("");
if (userQuery.isEmpty()) {
return CompletableFuture.completedFuture(Map.of());
}
// Step 1: 检索相关文档(只执行一次,在整个 Agent 执行过程中)
List<Document> relevantDocs = vectorStore.similaritySearch(
org.springframework.ai.vectorstore.SearchRequest.builder()
.query(userQuery)
.topK(TOP_K)
.build()
);
// Step 2: 构建上下文
String context = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining(" "));
config.metadata().ifPresent(meta -> {
meta.put(RAG_CONTEXT_KEY, context);
});
// Step 3: 将检索到的上下文存储到状态中,供后续 ModelInterceptor 使用
// 存储到 state 中,ModelInterceptor 可以通过 request.getContext() 访问
return CompletableFuture.completedFuture(Map.of());
}
}再创建一个拦截器对RAG上下文信息进行增强:
ini
public class RAGContextInterceptor extends ModelInterceptor {
private static final String RAG_CONTEXT_KEY = "rag_context";
@Override
public ModelResponse interceptModel(ModelRequest request, ModelCallHandler handler) {
// 从请求上下文中获取检索到的 RAG 上下文
// RAG 上下文在 AgentHook 的 beforeAgent 中已经存储到状态中
Map<String, Object> context = request.getContext();
String ragContext = (String) context.get(RAG_CONTEXT_KEY);
if (ragContext == null || ragContext.isEmpty()) {
// 如果没有检索到上下文,直接调用处理器
return handler.call(request);
}
// 增强 systemPrompt String enhancedSystemPrompt = String.format("""
你是一个有用的助手。基于以下上下文回答问题。
如果上下文中没有相关信息,请说明你不知道。 上下文:
%s """, ragContext);
// 合并原有的 systemPrompt 和检索到的上下文
SystemMessage enhancedSystemMessage;
if (request.getSystemMessage() == null) {
enhancedSystemMessage = new SystemMessage(enhancedSystemPrompt);
} else {
enhancedSystemMessage = new SystemMessage(
request.getSystemMessage().getText() + " " + enhancedSystemPrompt
);
}
// 创建增强的请求
ModelRequest enhancedRequest = ModelRequest.builder(request)
.systemMessage(enhancedSystemMessage)
.build();
return handler.call(enhancedRequest);
}
@Override
public String getName() {
return "rag_context_interceptor";
}
}整合配置并验收
结合上述的综合配置,我们给出完整的agent构建步骤:
scss
@Bean
public WeatherAgent weatherAgent() {
// 系统提示词简化为角色定位和输出格式要求
String SYSTEM_PROMPT = """
# 天气预报助手
## 角色定位
你是一位专业的天气预报员,负责为用户提供准确的天气信息。
## 输出格式要求
所有天气查询结果必须使用 WeatherResponse 格式返回,包含以下字段:
- city:城市名称(必填)
- weather:天气状况描述(必填)
- tip:天气建议(必填)
- error_message:异常说明(仅在出错时填写)
## 技能使用
你已掌握 "weather-forecast" 技能,请按照该技能定义的任务流程执行天气查询任务。
""";
// 创建工具回调 (模拟天气查询工具,写死为晴天)
ToolCallback getWeatherTool = FunctionToolCallback
.builder("getWeatherForLocation", new WeatherForLocationTool())
.description("Get weather for a given city")
.inputType(String.class)
.build();
// 创建工具回调 (模拟获取用户位置工具,基于用户id决定是福建还是深圳)
ToolCallback getUserLocationTool = FunctionToolCallback
.builder("getUserLocation", new UserLocationTool())
.description("Retrieve user location based on user ID")
.inputType(String.class)
.build();
// 创建 DashScope API DashScopeApi dashScopeApi = DashScopeApi.builder()
.apiKey(apiKey)
.build();
//基于 dashscope api 创建chatmodel
ChatModel chatModel = DashScopeChatModel.builder()
.dashScopeApi(dashScopeApi)
.defaultOptions(DashScopeChatOptions.builder()
.withModel(DashScopeChatModel.DEFAULT_MODEL_NAME)
.withTemperature(0.5) //控制输出的随机性(0.0-1.0),值越高越有创造性
.withMaxToken(1000) // 最大输出长度 更多参数请参考 ChatModel 适配
.build())
.build();
//生成skill hook
SkillRegistry registry = ClasspathSkillRegistry.builder()
.classpathPath("skills")
.build();
SkillsAgentHook skillsHook = SkillsAgentHook.builder()
.skillRegistry(registry)
.build();
ReactAgent agent = ReactAgent.builder()
.name("天气助手")
.model(chatModel)
.hooks(new MessageTrimmingHook(),
new RAGAgentHook(SpringUtil.getBean(VectorStore.class)),
skillsHook)
.tools(getWeatherTool, getUserLocationTool)
.systemPrompt(SYSTEM_PROMPT)//系统提示词
.outputType(WeatherResponse.class)
.interceptors(new RAGContextInterceptor())
.saver(new MemorySaver())//Agent 通过状态自动维护对话历史。使用 MemorySaver 配置持久化存储,默认使用hashmap
.build();
//将ReactAgent聚合到WeatherAgent并交由Spring容器统一管理
WeatherAgent weatherAgent = new WeatherAgent();
weatherAgent.setAgent(agent);
return weatherAgent;
}此时,我们就可以开始验收步骤了,按照需求说明,如果没有提供城市信息的情况下,agent会通过数据库查询方式定位用户所在城市并输出,对应我们也给出该代码示例:
arduino
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(String.valueOf(Thread.currentThread().getId()))
.addMetadata("userId", "1") //福建用户
.build();
String result = SpringUtil.getBean(WeatherAgent.class).call("今天是什么天气", runnableConfig);
WeatherResponse weatherResponse = JSONUtil.toBean(result, WeatherResponse.class);
Console.log("查询结果:{}", JSONUtil.toJsonStr(weatherResponse));输出结果如下:
css
查询结果:{"city":"福建","weather":"阴天","tip":"建议携带雨具,注意防潮","errorMessage":""}当福建用户指定城市时,输出指定城市的天气:
arduino
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(String.valueOf(Thread.currentThread().getId()))
.addMetadata("userId", "1") //福建用户
.build();
String result = SpringUtil.getBean(WeatherAgent.class).call("上海今天是什么天气", runnableConfig);
WeatherResponse weatherResponse = JSONUtil.toBean(result, WeatherResponse.class);
Console.log("查询结果:{}", JSONUtil.toJsonStr(weatherResponse));输出结果:
css
查询结果:{"city":"上海","weather":"晴天","tip":"今天阳光明媚,适合户外活动,但请注意防晒。","errorMessage":""}消息超过6条后,触发消息修改,这一点我们可直接通过输出控制台印证:

最后则是RAG信息检索增强:
arduino
String result = SpringUtil.getBean(WeatherAgent.class).call("这个天气预报agent作者是谁", runnableConfig);
Console.log("查询结果:{}", JSONUtil.toJsonStr(result));输出结果如下,可以看到SAA准确的完成的文档加载并输出作者信息,只不过我们给出的响应格式没有准确的字段填充,生成结果存放在error_message字段上:
css
查询结果:{"city": "", "weather": "", "tip": "", "error_message": "天气预报agent的作者是sharkchili"}小结
本文介绍了大语言模型中模型、提示词、工具、token以及记忆等几个核心的概念,随后通过一个天气查询助手将这些概念配置串联和落地,最终给出一个基于Spring最佳实践版本的天气查询助手,涉及:
- 规范化封装:基于Spring IOC管理Agent
- 上下文管理:通过ToolContext传递用户信息
- 多工具调用:通过outputType结构化输出
- 消息修剪:基于hook添加消息修剪工具,控制上下文长度
- RAG增强:向量检索+知识库增强
🚀 技术布道者 | 开源贡献者 | 现代开发实践者
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go、C 等多语言技术栈,现任某知名黑厂高级开发工程师,专注于高并发系统架构设计与性能优化。
💡 技术专长领域
- 分布式系统架构:高并发场景下的系统设计与性能优化经验丰富
- 微服务与云原生:熟悉服务治理、容器化与自动化运维体系
- 大数据技术栈:海量数据处理与实时计算架构实践经验
- 源码深度分析:主流框架源码研究与企业级定制化能力
- 系统设计思维:采用自顶向下的分析方法,深入解构计算机系统设计原理,并将其应用于实际架构设计
🌟 开源项目贡献
- mini-redis :教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 github.com/shark-ctrl/...(欢迎 Star & Contribute)
📚 公众号价值 分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群 关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
参考
Spring AI 入门到精通:www.cnblogs.com/xjwhaha/p/1...
Spring AI Alibaba 入门指南:www.cnblogs.com/xjwhaha/p/1... Spring AI Alibaba 官方文档:java2ai.com/docs/quick-...
本文使用 markdown.com.cn 排版