
你的 Go 服务有多少个配置项?
掰着手指头数一下:端口、数据库地址、日志级别、超时时间、限流阈值......不超过 20 个?那你大概率不需要配置中心。
这话听着反直觉。毕竟 etcd、Nacos、Apollo 这些名字早就写进了各种"最佳实践"清单。面试问"你们配置管理怎么做的",回答"读个 JSON 文件"似乎显得不够专业。
但"最佳实践"有个隐含前提------它在特定规模下才是最佳。一个 3 人团队管 2 个服务,和一个 50 人团队管 30 个微服务,"最佳"的含义完全不同。
先看一组实测数据。同样是读一个 JSON 配置文件,三种方案编译出来的二进制:
| 方案 | 二进制大小 | 外部依赖模块数 |
|---|---|---|
| stdlib(encoding/json + os.ReadFile) | 2.9 MB | 0 |
| koanf | 3.3 MB (+14%) | 4 |
| Viper | 7.0 MB (+138%) | 14 |
一个读 JSON 的活儿,Viper 带来了 14 个依赖模块,二进制体积翻了一倍多。这不是说 Viper 不好------Viper 很好,它能做的事比读 JSON 多得多------但问题是:你现在真需要那些多出来的能力吗?
配置方案的选择不是技术优劣问题。是时机问题。
在对的拐点升级,你得到的是恰好够用的能力提升。跳过拐点直接上重方案,你得到的是过度设计------额外的运维负担、更长的启动时间、更大的故障爆炸半径。
这篇文章给你三个判断拐点的信号,外加一张可以直接对照使用的决策表。看完之后你能回答一个问题:我的项目,现在该停在哪一层?
拐点一:从硬编码到文件
触发条件
你项目刚起步的时候,大概率写过这样的代码:
bash
const (
port = 8080
dbHost = "localhost:3306"
timeout = 30 * time.Second
)能跑。go run main.go,服务起来了,本地开发一切正常。
直到有一天你要部署到测试环境。数据库地址变了,端口也不能是 8080 了,超时时间可能要调大。你改常量,重新编译,部署。下次要上预发布------又改一遍。再上生产------再改一遍。
每次部署都要改代码。每次改代码都要重新编译。每次编译都可能手滑改错。你开始在代码里搞 if os.Getenv("ENV") == "prod" 的条件分支,或者用 build tags 隔离环境------代码越来越脏。
触发信号:第一次需要在不同环境运行同一份代码,且环境间的差异超过 3 个配置项。
方案对比
| 维度 | 硬编码 | 配置文件 + 环境变量 |
|---|---|---|
| 改配置 | 改代码→编译→部署 | 改文件→重启 |
| 多环境 | 不支持(或 build tags 拼凑) | config.dev.json / config.prod.json |
| 敏感信息 | 密码写在代码里,提交到 Git | 敏感项走环境变量,不入库 |
| 团队协作 | 改配置 = 提 PR + Code Review | 配置和代码解耦,运维可独立调整 |
| 依赖 | 无 | 标准库(encoding/json + os) |
方案推荐
最小方案:一个 JSON 文件 + 环境变量覆盖敏感项。
bash
type Config struct {
Port int `json:"port"`
DBHost string `json:"db_host"`
LogLevel string `json:"log_level"`
}
func Load(path string) (*Config, error) {
data, err := os.ReadFile(path)
if err != nil {
return nil, err
}
var cfg Config
if err := json.Unmarshal(data, &cfg); err != nil {
return nil, err
}
// 环境变量覆盖敏感项
if v := os.Getenv("DB_HOST"); v != "" {
cfg.DBHost = v
}
return &cfg, nil
}17 行代码。零外部依赖。编译产物 2.9 MB。
有人会说:为什么不直接用 Viper?反正迟早要用的。
这就是典型的"预留扩展性"陷阱。Viper 的 14 个依赖模块里,有处理 etcd 连接的、有处理 Consul 的、有处理远程配置的------你现在根本用不到这些。等哪天真需要热加载了,只要你的业务代码是通过 Config struct 读配置(而不是散落各处直接调 viper.GetString()),迁移就是把 Load 函数的实现从标准库换成 koanf------改一个文件,跑一遍测试。
什么时候该升级:直到你第一次需要不重启就改配置------那就是拐点二。
拐点二:从静态到热加载
触发条件
周五晚上 9 点。监控告警:限流阈值配低了,部分正常请求被误杀。
当前方案:改 config.yaml 里的 rate_limit 字段,然后重启服务。
问题来了。你的服务维护着 2000 条 WebSocket 长连接。重启意味着:所有连接断开 → 客户端重连 → 重连风暴 → 负载均衡器压力飙升。一个配置变更,触发了一场小型"雪崩"。
或者另一个场景:你的服务启动要预热 2GB 的本地缓存,冷启动需要 45 秒。重启一次,意味着 45 秒的服务不可用。
触发信号:第一次需要运行时修改配置,且重启代价不可忽略。
怎么判断"代价不可忽略"?三个标准满足任一即可:
- 服务持有长连接(WebSocket、gRPC stream、TCP 长连接),重启会断开所有连接
- 启动初始化耗时超过 5 秒(缓存预热、模型加载、连接池初始化)
- SLA 承诺 99.9% 以上,一次重启消耗的错误预算不可接受
如果你的服务是无状态 HTTP API,启动 200ms 就绑定端口开始接流量,重启代价几乎为零------你可能还不需要热加载。省下那 4 个额外依赖,等真正需要时再引入。
方案对比
| 维度 | 静态文件(重启生效) | 热加载(koanf/Viper + fsnotify) |
|---|---|---|
| 配置变更 | 改文件→重启→生效 | 改文件→秒级自动生效 |
| 依赖量 | 0 | koanf: 4 模块 / Viper: 14 模块 |
| 二进制增量 | 基准 | koanf: +0.4 MB / Viper: +4.1 MB |
| 代码复杂度 | 仅启动时读一次 | 需处理并发安全(atomic/sync) |
| 故障面 | 无新增 | fsnotify 在 NFS/Docker Volume 上可能有兼容问题 |
| 配置校验 | 启动时校验一次 | 每次热加载都要校验(不能让错误配置生效) |
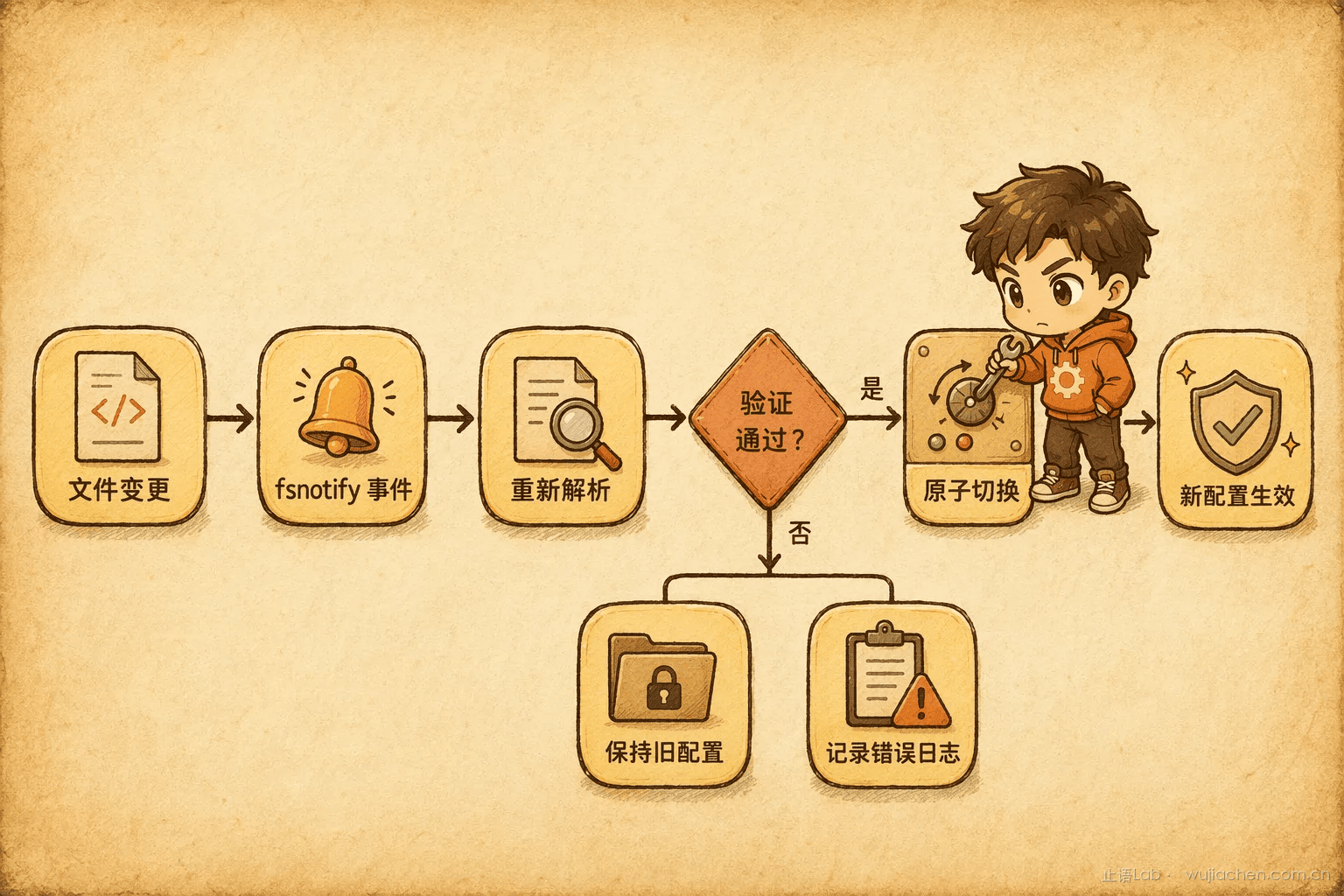
热加载的核心逻辑很简单:监听文件变更 → 重新解析 → 校验通过 → 原子替换内存中的配置对象。
bash
// koanf 热加载核心逻辑(简化)
k := koanf.New(".")
provider := file.Provider("config.yaml")
// 首次加载
k.Load(provider, yaml.Parser())
// 监听变更,文件一改就重新加载
provider.Watch(func(event interface{}, err error) {
if err != nil {
log.Printf("watch error: %v", err)
return
}
k.Load(provider, yaml.Parser())
log.Println("配置已热加载")
})代码看着简单,但有一个容易被忽略的暗坑:并发安全。
配置热加载和配置读取跑在不同 goroutine。加载 goroutine 在写新配置,业务 goroutine 在读旧配置------经典的读写竞争。如果不做保护,你可能读到一个"半更新"的配置对象:端口是新的,但超时时间还是旧的。
解法有两种:
atomic.Value:把整个配置对象作为一个原子值交换,业务代码无需手动加锁。简单高效,推荐。sync.RWMutex:读多写少场景下性能够用,但代码侵入性强------每个读配置的地方都要加 RLock。
还有一个容易忘的点:热加载必须做校验。文件被手滑改坏了(比如 YAML 缩进错误),你的服务不应该吞下这个错误配置。正确做法是:解析失败 → 打印错误日志 → 保持当前配置不变。
方案推荐
两个主流选择:
- koanf:轻量,4 个直接依赖,支持 JSON/YAML/TOML/dotenv 多种格式,API 设计更现代(链式调用)。适合新项目或依赖预算敏感的场景。
- Viper:Go 生态老牌选手,社区成熟,和 Cobra CLI 框架配合好。但 14 个直接依赖、反射重、二进制膨胀明显。适合已经在用 Cobra 的项目------既然依赖都已经拉进来了,不用白不用。
我的建议:如果你没有 Viper 的历史债务,选 koanf。二进制从 2.9 MB 涨到 3.3 MB 和涨到 7.0 MB------差别不在 MB 数字本身,而在于你为没用到的能力付了多少依赖维护成本。
什么时候该升级:直到你的配置项膨胀到 50 个以上,或者多个服务开始共享同一份配置------那就是拐点三。
拐点三:从本地到配置中心
触发条件
三个典型场景,碰到任一个就说明你到了拐点三:
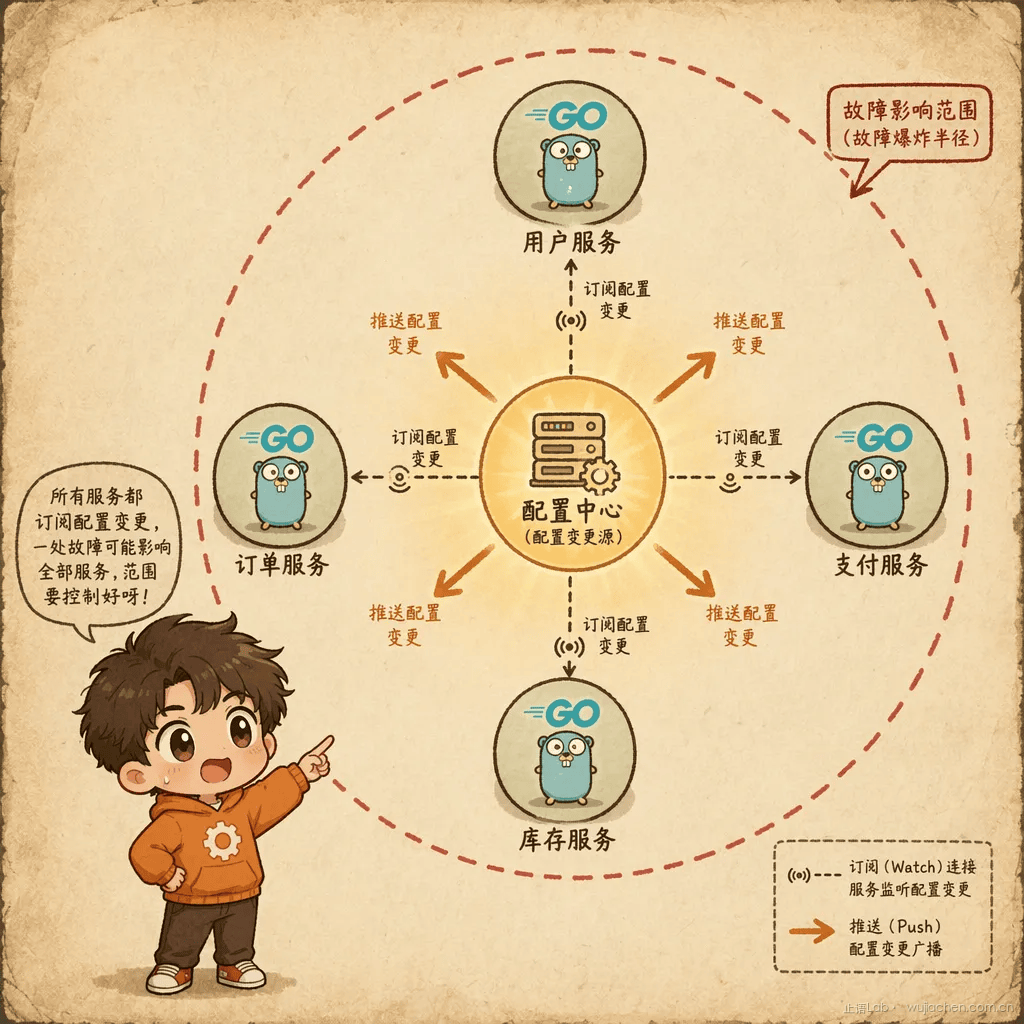
场景一:配置同步成了体力活。 你管理 5 个微服务,其中 3 个共享同一组数据库连接配置。数据库做了一次主从切换,你要改 3 个仓库的配置文件,提 3 个 PR,跑 3 次 CI,部署 3 次。手动保持一致性------迟早会漏。
场景二:配置散落无法管理。 项目跑了两年,配置项从 10 个膨胀到 80 个,分散在 4 个 YAML 文件里。新同事问"消息队列的重试次数配置在哪",你得 grep 半天。更糟的是,同一个配置在 A 文件和 B 文件各出现了一次,值还不一样------哪个生效?你也不确定。
场景三:需要精细化发布控制。 产品说"先灰度 10% 流量试试新的推荐算法配置"。文件方案做不到按流量比例下发不同配置。你要么全量发,要么不发。
触发信号(满足任一即可):
- 配置项 > 50 个,散落多文件,查找和维护成本高
- 3+ 服务共享配置,手动同步容易出错
- 需要配置灰度发布、版本回滚、或变更审计能力
方案对比
| 维度 | 本地热加载 | 配置中心(etcd/Nacos/Apollo) |
|---|---|---|
| 启动时间 | ~50ms(读本地文件) | +200-500ms(网络连接 + 拉取配置) |
| 故障行为 | 文件损坏→启动报错→本地修复 | 配置中心不可用→降级读缓存 or 启动失败 |
| 单次变更操作 | 3 步 | 7 步 |
| 多服务同步 | 手动改 N 个文件 | 改一次,N 个服务自动拉取 |
| 灰度发布 | 不支持 | 按 namespace/group/IP 灰度 |
| 版本回滚 | git revert | Web 控制台一键回滚 |
| 变更审计 | git log | 内置审计日志(who/when/what) |
| 运维成本 | 无额外组件 | 需维护配置中心集群(etcd 最少 3 节点) |
把几个关键维度展开说。
启动时间差异。
本地文件:os.ReadFile 读一个 10KB 的 YAML,在 SSD 上是微秒级操作,可以忽略不计。
配置中心:服务启动时需要------建立 TCP 连接(三次握手,局域网 ~1ms)→ TLS 握手(如果有,+10-50ms)→ 身份认证(Token/证书校验,+20-50ms)→ 拉取配置列表(gRPC 调用,+50-100ms)→ 解析配置内容。整条链路在同机房网络下大约 200-500ms。跨可用区或网络抖动时可能更长。
200ms 听着不多。但如果你的服务运行在 Serverless 环境(Cloud Run、Lambda),冷启动时间直接决定用户体验。一个本来 200ms 能启动的服务,因为配置中心变成了 500-800ms------这多出来的半秒,乘以每天的冷启动次数,就是实实在在的成本。
故障行为差异。
本地文件坏了:你的服务启动报错 failed to parse config.yaml: line 12: mapping values are not allowed here。排查路径很短------看日志→打开文件→修复 YAML 语法→重启。整个链路 1 跳。
配置中心出问题:你的服务报 dial tcp etcd-cluster:2379: connection refused。排查链路变长------是配置中心挂了还是网络隔离?→ 登 etcd dashboard 检查集群状态 → 是 leader 选举卡住了还是证书过期?→ 如果是证书过期,谁来续签?→ 续签后需要滚动重启 etcd 节点......
从 1 跳变成 5 跳。更关键的是,文件方案故障只影响单个服务,而配置中心故障影响所有订阅它的服务------故障爆炸半径从 1 变成 N。
变更操作步骤对比。
改一个限流阈值,两种方案的操作流程:
文件方案(3 步):
- 编辑 config.yaml 对应字段
- git commit + push(或 scp 到目标机器)
- 服务检测到文件变更,自动热加载
配置中心方案(7 步):
- 打开浏览器,登录配置中心 Web 控制台
- 导航到对应的 namespace 和应用名
- 在配置列表中找到目标配置项
- 修改配置值
- 填写变更说明(谁改的、为什么改、影响范围)
- 提交审批(如果有流程,等审批通过)
- 确认发布 → 验证各服务已拉取到新配置
7 步 vs 3 步。步骤多本身不是坏事------审批流程带来的是变更安全性。50 个服务的场景下,你绝对不想让一个人随便改个配置就全量生效。
但对于 3 人团队管 2 个服务的场景?审批人就是你自己,变更说明写给自己看------这 4 步额外流程纯粹是自我折磨。
方案推荐
只有当"多服务共享配置"或"配置灰度/审计"成为真实存在的需求时,才值得引入配置中心。注意是"真实存在"------不是"未来可能需要"。
选型建议:
- etcd:如果你的基础设施已有 etcd(比如跑了 K8s),直接复用现有集群,不引入新组件。Go 原生客户端,性能强,但没有 Web 控制台------适合有 DevOps 能力的团队。
- Nacos:如果需要配置管理 + 服务发现一体化解决方案,且团队对 Java 生态不排斥(Nacos Server 是 Java 写的)。Web 控制台开箱即用。
- Apollo:如果特别看重灰度发布 UI、权限管理、变更审计的完整度。功能最全,但也最重------本身需要 MySQL + 3 个 JVM 进程。
无论选哪个,有一条铁律:必须做本地缓存兜底。配置中心不可用时,服务应该用上次成功拉取的配置继续运行。不能因为配置中心抖了一下,所有服务就跟着一起挂。
实现思路:每次成功拉取配置后,写一份到本地文件。启动时先尝试远程拉取,超时就 fallback 到本地缓存。
bash
func LoadFromRemote(ctx context.Context, client ConfigClient) (*Config, error) {
ctx, cancel := context.WithTimeout(ctx, 3*time.Second)
defer cancel()
cfg, err := client.Get(ctx, "app-config")
if err == nil {
// 成功拉取,刷新本地缓存
_ = os.WriteFile(".config_cache.json", cfg.Raw(), 0644)
return cfg, nil
}
// 远程失败,降级到本地缓存
return LoadFromFile(".config_cache.json")
}这不是可选的------这是引入配置中心的前提。
过度设计的代价
我来推演一个真实的典型场景。
一个 3 人后端团队。2 个 Go 微服务:一个 API 网关,一个业务服务。总共 15 个配置项------端口、数据库地址、Redis 地址、几个超时时间、一个限流阈值。变更频率:平均每月改 1-2 次。
技术负责人在做架构评审时说:"我们迟早要上微服务,配置中心现在不搭好,以后迁移代价更大。"于是引入了 Apollo。
三个月后------
本地开发变复杂。 以前 go run main.go 就能启动。现在开发流程变成:先 docker-compose up apollo 启动配置中心 → 等 Apollo 三个进程就绪(Portal + AdminService + ConfigService) → 确认配置已导入 → 然后才能启动自己的服务。新人入职第一天在配环境上花了半天。
CI 流水线变长。 多了一个"等待 Apollo 就绪"的步骤。Apollo 的 JVM 冷启动要 30 秒,CI 每次跑多等 30 秒。一天跑 20 次 CI,一天浪费 10 分钟。一个月按 22 个工作日算下来约 3.5 小时。
冷启动时间翻了 4 倍。 原来服务 200ms 启动完毕,现在要先连 Apollo 拉配置(约 300-600ms),整体冷启动变成 500-800ms。对于这两个非 Serverless 的服务来说影响不大------但如果哪天要上 K8s 弹性扩缩容(HPA),Pod 在流量高峰批量拉起时,这多出来的半秒会让扩容响应慢一拍。
故障半径扩大。 有一次 Apollo 的数据库连接池打满了,ConfigService 返回 500。两个服务的配置拉取全部超时,触发了降级逻辑------还好做了本地缓存。但告警响了一早上,团队花了两小时排查"为什么 Apollo 挂了"。如果配置在本地文件,这两小时根本不需要花。
认知负担。 namespace、cluster、appId、release------Apollo 的概念模型对于 15 个配置项来说完全是 overhead。新人要理解"为什么改一个端口号要登录一个 Web 控制台在三级菜单里找到对应的 key"。
量化对比:
| 维度 | 文件方案(这个项目够用的) | 实际选择(Apollo) |
|---|---|---|
| 本地启动 | go run main.go |
先起 Apollo 容器→等 30s→再启动 |
| CI 流水线 | 无额外步骤 | +30s(Apollo 就绪检查) |
| 冷启动时间 | ~200ms | ~600ms |
| 新增故障源 | 0 | +1(Apollo 集群) |
| 新人上手项 | 读 config.yaml | 学 Apollo 控制台 + 概念模型 |
| 维护成本 | 0 个额外组件 | MySQL + 3 个 JVM 进程 + 定期升级 |
| 变更效率 | 改文件 3 步 | Web 控制台 7 步 |
这些代价在 50+ 服务的场景下完全值得。多服务配置同步、灰度发布、变更审计带来的收益远超这些成本。
但在 2 个服务、15 个配置项、月均 1-2 次变更的场景下?你花在维护 Apollo 上的时间,确定不比花在改 YAML 文件上的时间多?
过度设计的核心问题不是"花了多少钱",而是"每天都在付利息"------每次启动多等的半秒、每次新人入职多学的半天、每次故障排查多走的几跳------这些都是持续的、看不见的成本。

决策表
别背规则,看你的场景。
快速决策表(按典型场景):
| 你的现状 | 推荐方案 | 一句话理由 |
|---|---|---|
| 单服务 / <20 配置项 / 不需要热更新 | JSON 文件 + 环境变量 | 零依赖零运维,改配重启即可 |
| 单服务 / 有长连接或重启代价高 / 需要运行时改配置 | koanf + fsnotify | 最小热加载方案,+4 个依赖换来不重启更新 |
| 3+ 服务 / 50+ 配置项 / 多服务共享配置 | 配置中心(etcd/Nacos/Apollo) | 多服务同步和灰度发布的收益超过运维成本 |
| 单服务 / <20 配置项 / "想预留扩展性" | JSON 文件 + 环境变量 | 迁移成本(改一个函数)远低于长期维护配置中心 |
多维度判断表(对照你的数字):
| 判断维度 | 文件够用 | 考虑热加载 | 考虑配置中心 |
|---|---|---|---|
| 服务数量 | 1-2 个 | 1-2 个 | 3+ 个 |
| 配置项数 | <20 | 20-50 | 50+ |
| 变更频率 | 月级别 | 周级别 | 日级别 |
| 重启代价 | 可忽略(<1s,无状态) | 不可忽略(长连接/慢启动) | 不可忽略 |
| 需要灰度 | 否 | 否 | 是 |
| 需要审计 | 否 | 否 | 是 |
怎么读这张表?三步:
- 找到你每个维度对应的列
- 哪列出现次数最多,就是你当前适合的方案
- 如果某个维度特别突出(比如服务只有 1 个但变更频率是日级),以那个维度为主
有一种情况需要特别注意:维度信号冲突。比如你有 5 个服务(指向配置中心),但只有 10 个配置项且月级变更(指向文件方案)。这时候不一定要上配置中心------中间地带有更轻量的解法:一个共享的 config Git 仓库 + CI 流水线自动分发到各服务,或者如果已经上了 K8s,直接用 ConfigMap + 挂载刷新。成本比独立配置中心低一个数量级。
配置中心不是"服务多了就该上"的银弹。它解决的核心问题是"高频变更 + 多服务同步 + 精细化发布控制"这三个需求的组合。单独出现其中一个,往往有更轻量的解法。
结语
配置方案不是一锤子买卖。
今天你选 os.ReadFile,不代表未来不能升级到 koanf。今天你用 koanf,也不代表哪天必须迁到 etcd。每次升级的迁移成本其实很低------在 Load 函数前面套一层接口,新旧实现一换就完。
真正贵的不是迁移。是过早引入你还不需要的东西,然后每天为它付出运维成本、认知负担和启动时间。这些"隐性利息"不会出现在技术评审文档里,但会出现在每一个团队成员每天的开发体验中。
翻回去看决策表,找到你当前对应的那一列。然后安心停在那里,直到下一个拐点真的到来。
原文发布于止语 Lab