一
模思智能公司与业务场景介绍
模思智能科技有限公司(MOSI Intelligence,下文简称模思)是一家由上海创智学院孵化,专注于深度情境智能的大模型初创公司。模思公司成立于 2024 年,核心创始团队以复旦大学自然语言处理实验室 MOSS 团队为核心组建,并由人工智能领域的知名学者,复旦大学邱锡鹏教授担任首席科学家。
作为一家以情境智能为核心的人工智能公司,模思公司在技术层面聚焦于人机交互领域,致力于构建能够理解和表达人类情感的新一代多模态基础模型。近些年,公司业务主要聚焦在 Voice Agent 和音视频同步生成两大战略方向,并于 2026 年年初发布了一系列语音相关模型,包括文本转语音生成系列模型 MOSS TTS-Family、多说话人识别语音转文本模型 MOSS-Transcribe,以及音视频同步生成模型 MOVA,汇集播客、有声书、智能导航、智能会议、语音输入,以及语音字幕等多个应用场景。
对于模思这类以情境智能为核心的公司,数据与算法共同决定了模型能力的上限。在训练数据方面,不仅需要追求足够大的数据规模,更需要保证足够好的数据质量,使得训练数据能够覆盖真实业务中的多种说话人、场景和设备条件,保证数据分布与目标应用场景高度一致;同时,通过精细的标签质量控制(如发音准确度、语义完整性、情绪标签一致性),才能让模型真正学到可泛化的能力。
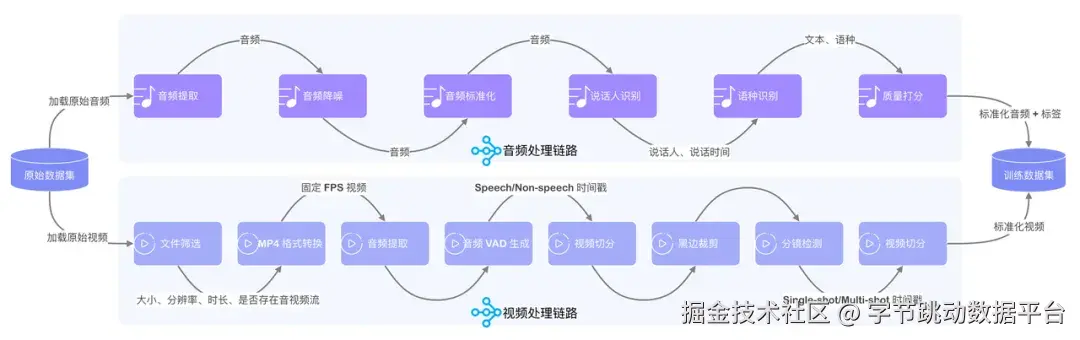
为了获得高质量的模型训练数据,模思公司针对原始音频、视频分别设计了对应的数据处理算法和链路。如上图所示,该链路展示了模思公司迁移到火山之前的音视频处理流程。这条在自建 IDC 中基于 Ray 和 Worker Pool 构建的音视频处理链路,在早期支撑了模思公司全部的音视频训练数据的处理工作,但随着业务和数据规模的扩大,问题也逐渐凸显,因此需要探索和构建更加高效、易用的解决方案。
二
携手火山引擎多模态数据湖
释放算法生产力
火山引擎 AI 数据湖服务(Lake AI Service,简称 LAS)是面向 DATA + AI 时代的新一代数据基础设施,旨在帮企业快速构建和管理多模态数据湖。LAS 提供一站式的多模态数据存储、计算和管理能力,能够简单、高效的处理文本、图像、音视频,以及向量等海量多模态数据。通过深度优化的湖存储格式、湖计算引擎,配合强大的 AI 算子和湖管理能力,LAS 不仅提升了数据存储、计算和管理的效率,还内置了企业级数据治理与权限管控机制,保证了用户数据的安全性。此外,作为连接数据与 AI 的桥梁,LAS 可以无缝对接火山方舟等模型训练平台,有力支撑企业构建高效、低成本的 AI 应用与模型训练流水线,加速数据价值的释放与业务创新。

在携手火山引擎 LAS 之前,模思公司曾致力于在 IDC 中自建全链路多模态数据处理平台,但面临两个比较现实的挑战:
-
为保证模型的性能和准确性,数据处理平台需要支撑千万小时级别的训练数据处理需求,而网络和存储性能经常成为数据处理的瓶颈。
-
作为一家快速成长的 AI 初创公司,受限于团队规模,需要把核心人才聚焦在算法创新上,但实际情况是大量工程精力被消耗在基础设施维护上。
因此,模思公司决定将多模态数据处理链路迁移上云以解放团队生产力,在提升训练数据处理与管理能力的同时,也能将人力资源聚焦在真正能够创造差异化和价值的地方。
秉承 "基础设施要足够成熟稳定,让团队能够专注于算法创新" 的原则,模思公司从众多云厂商和云产品中选择了火山 LAS 产品构建模型训练数据处理链路。之所以选择火山 LAS 产品的核心原因有三点:
-
产品内聚性强,通过将数据存储、计算和管理整合在一套产品内,让开发体验更加流畅。
-
产品提供对 Daft、Ray 等开源计算框架的原生支持,让团队成员能够快速上手,同时也保留了技术灵活性。
-
产品在音视频等多模态数据处理方面比较成熟,契合模思公司的业务需求。
本质上,模思公司是希望找到一个可靠的基础设施伙伴,让算法团队可以心无旁骛的推进模型研发。
在引入火山 LAS 产品后,模思公司基于 LAS 构建了一套完整的语音合成训练数据处理流水线,涵盖音频降噪、格式标准化、说话人分离、语种识别、语音转文字等关键环节,集成了 MossFormer2、Whisper、DiariZen 等多种先进模型。
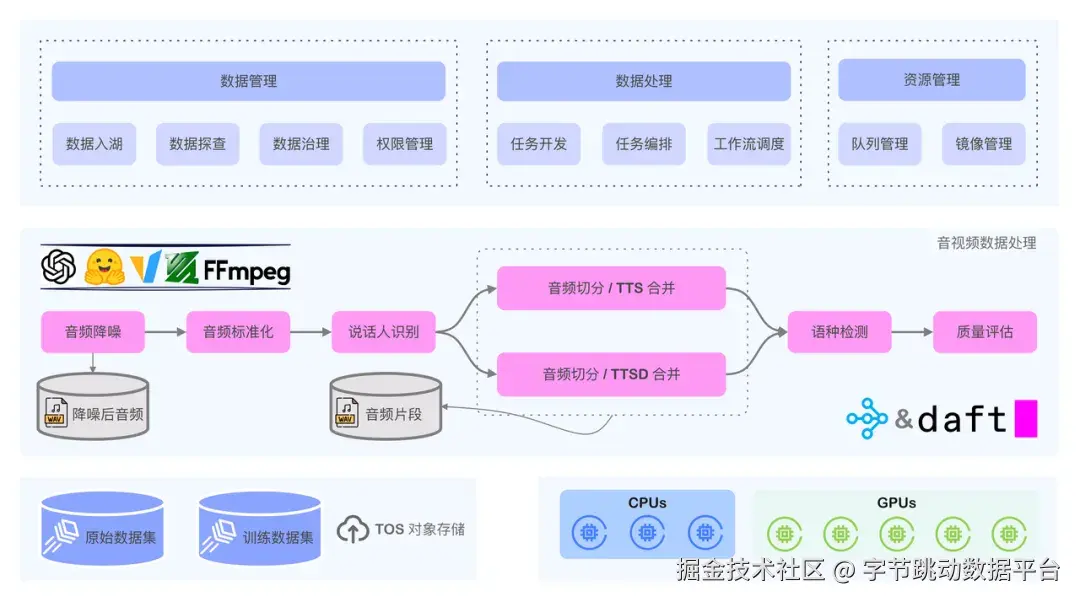
如上图所示,展示了模思公司在引入 LAS 产品后数据处理平台的分层架构。在工程实现上主要涉及 LAS 产品的如下核心能力:
-
数据存储: 采用 Lance 多模态数据湖格式对训练数据进行一体化存储,带来的直接收益包括:
-
读取性能:支持高效随机访问和列式读取,让训练数据的摄取速度明显提升。
-
版本管理:支持方便的历史追溯、对比差异和快速回滚,对模型训练的可复现性非常重要。
-
数据复用:与平台无缝集成,团队间协作更顺畅,避免重复处理。
-
-
数据计算: 采用 Daft 多模态计算引擎对音视频数据实施分布式处理,从以下 3 个方面提升了训练数据准备的效率:
-
开发效率:相比之前需要编写大量调度和容错代码,切换到 Daft 引擎后可以更加专注于业务逻辑本身。
-
执行效率:Daft 引擎在 CPU 和 GPU 资源的异构调度能力上表现出色,一套引擎能够同时纳管两种资源,同时保障高效的资源利用。
-
稳定性:监控和日志能力比较完善,从而让问题排查效率大幅提升。
-
-
数据管理: 提供对训练数据集的可视化管理能力,包括对数据集的使用、预览、探查、审计,以及权限控制等,在保证数据安全的前提下,让数据变得更加具象,不再是冰冷的文件列表,从而让数据能够被有效治理,避免数据孤岛。
-
任务开发:提供对多模态数据处理任务从开发、调试、部署,以及工作流编排、调度一站式的任务开发与部署能力,以强大的产品内聚性,为用户提供流畅的任务开发体验。
依托火山引擎 LAS 产品的上述核心能力,支撑模思公司训练数据准备阶段的整体处理效率提升约 50%,其中音频去噪阶段的 GPU 利用率从约 60% 提升至 80% 以上,说话人分离阶段更是达到 95% 以上,让开发周期从原先的需要数周人天缩短到仅需数天。 这些数字背后更重要的是对模思公司研发效能的影响,数据准备周期的缩短意味着算法团队能更快拿到高质量训练数据,进而加快模型迭代速度,让产品演进更加敏捷。这种快速闭环的能力,正是模思公司在初创阶段能够保持竞争力的关键所在。
三
基于 Daft 多模态计算引擎
构建高效音视频处理链路
Daft 是一款由 Eventual 商业化公司开源,面向 DATA + AI 多模态数据处理与分析场景的高性能分布式计算引擎,具备如下核心特性:
-
Pythonic Dataframe & SQL API: Daft 在 API 层采用 Python 语言编写,提供 Dataframe 和 SQL 两种接入方式,同时在内核层面采用 Rust 语言编写,兼顾性能、易用性和 Python 生态。
-
内置单机和分布式双模执行引擎: Daft 内置单机 Swordfish 和分布式 Flotilla 两套 Pipeline 执行引擎,用户编写的业务代码可以在不修改的情况下在单机和分布式两种模式间任意切换运行,兼顾本地开发、调试的易用性,以及处理大规模数据集的能力和性能。
-
AI Functions & Model Providers: Daft 内置面向 AI for DATA 数据处理场景的常用 AI 处理函数,通过调用模型实现推理、Embedding,以及分类等操作,同时允许用户以配置方式自定义推理模型。
-
内置多模态类型和算子: 除了像传统大数据引擎一样支持处理基本数据类型和 JSON、CSV 这类半结构化数据类型外,Daft 还内置面向文本、图片、向量、音视频等多模态数据类型的基本处理算子,同时也内置 URL 和 File 类型允许扩展支持更多的多模态数据处理场景。
-
提供多形态 UDF 灵活扩展: 针对 AI Functions 和内置算子不能满足的处理场景,Daft 还允许用户以 Python UDF 形式灵活编写计算逻辑,并针对 UDF 提供 Row-wise、Batch 和 Class 等多种执行模式。
-
Lazy 计算 & RBO + CBO 优化器: 区别于 Pandas/Polars 等单机计算引擎的 Eager 计算模式,Daft 与传统大数据计算引擎一样采用 Lazy 计算模式,并内置大量优化规则以追求极致的计算性能。
-
异构资源调度与弹性伸缩: Daft 在分布式运行模式下依赖 Ray Core 进行资源管理,因此天然继承了 Ray Core 在 CPU/GPU 异构资源调度上的优势,允许在一个任务中流式运行 CPU 数据处理算子和 GPU 模型推理算子,保证 CPU/GPU 异构资源的利用率。此外,Daft 调度器支持依据集群的运行负载和节点空闲状态弹性伸缩集群规模,进一步提升资源利用率。
-
Checkpoint 与故障恢复: 针对运行失败的作业,Daft 支持在作业重新拉起后跳过已处理完成的数据继续执行,在保证容错性的同时,也降低了对数据集整体的处理时间,避免了对 GPU、Token 等计算资源的浪费。
-
丰富的周边生态加持: 支持与主流云厂商、对象存储、数据格式、数据目录进行集成,以及与 Pandas、Ray、pyTorch 等数据集进行互转。
正是看到了 Daft 在多模态数据处理领域的诸多优秀特性,因此火山引擎 LAS 产品在技术选型时将 Daft 作为产品计算层的核心引擎进行集成,并在此基础上构建了大量面向多模态数据处理场景的算子,以简化用户基于 LAS 结合自己的业务场景构建多模态数据处理流水线。
模思公司基于火山 LAS 产品构建了一套完整的语音合成训练数据处理流水线,涵盖音频降噪、格式标准化、说话人分离、语种识别、语音转文字等关键环节,集成了 MossFormer2、Whisper、DiariZen 等多种先进模型,这些环节的串联和执行均由 Daft 计算引擎驱动。
**
**
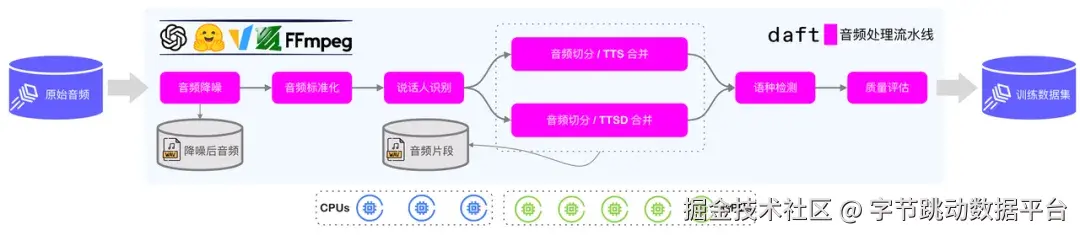
如上图所示,展示了模思公司音频处理链路基于 Daft 计算引擎重构后的整体架构。模思公司采用 Lance 格式存储音频数据集,并将音频处理的各个环节抽象成一个个算子(可以理解为 Daft UDF)进行实现。这些算子核心是通过调用模型或一些音视频处理库、工具(例如 FFmpeg、TorchAudio)实现对于音频的清洗、转换、切分、合并,以及打标等操作,最终生成标准化的训练数据。在整个链路中主要涉及 Daft 引擎的如下特性:
-
原生读写 Lance 数据集: Lance 作为面向多模态数据的存储格式,其具备的一体化存储、随机点查,以及版本管理等特性正好契合模思公司对于音频数据的存储述求。Daft 作为面向多模态数据的计算引擎,提供了对 Lance 格式的原生读写能力,支持直接读写模思的音频数据集。此外,Daft 引擎内置的自动分片能力能够针对音频文件在读写时自动规划分布式任务,保障读写的高性能和水平扩展能力。
-
通过 UDF 定义处理算子: 针对通过 Python 语言实现的单机音频处理算子,仅需通过 Daft 注解简单修饰即可变身成为 Daft UDF 实现分布式执行。此外,考虑一些音频处理算子需要调用模型进行推理,Daft 为此提供了 Class UDF,允许在 UDF 启动阶段完成对模型的一次性加载和初始化逻辑,避免重复加载。
-
CPU/GPU 异构资源调度: 整个音频处理链路包含 CPU 算子(例如音频重采样)和 GPU 算子(例如调用模型对音频进行降噪),支持异构资源调度允许 Daft 在一个流水线中同时运行 CPU 和 GPU 算子,并保证 CPU 和 GPU 资源利用率处于高水位。
-
单机和分布式双模执行: 考虑本地开发的易用性和效率,可以在本地使用单机模式开发和调试音频处理流水线,并在生产部署中切换至分布式模式运行。Daft 内置了单机和分布式两套执行引擎,并支持在不修改代码的前提下任意切换运行模式,以兼顾开发阶段的易用性和效率,以及生产阶段的执行性能和能够处理的音频数据集容量上限。
-
Checkpoint 与故障恢复: 对于音频数据处理流水线,难免在运行中面临一些异常导致任务失败,典型像 OOM 异常、网络抖动等。当从异常中恢复时,Daft 内置的 Checkpoint 机制支持跳过已处理完成的音频数据,从上次失败的位置继续执行,避免造成资源浪费,保障任务整体执行时间可控。
在上述这些特性的联合作用下,模思公司在迁移到火山 LAS 产品后实现了整体处理效率提升约 50%,其中音频去噪阶段的 GPU 利用率从约 60% 提升至 80% 以上,说话人分离阶段更是达到 95% 以上,让开发周期从原先的需要数周人天缩短到仅需数天。
四
基于 Lance 多模态数据湖格式
实现一体化数据存储
Lance 是专为模型训练与数据分析而设计的现代化、高性能列式存储格式,旨在简化多模态数据的管理与访问。通过提供多版本管理、高效随机读、零拷贝 Schema 演进,以及原生向量检索等能力,Lance 成为 AI Pipeline 中理想的数据湖存储底座。在模思公司的业务场景中,Lance 主要解决了以下核心问题:
-
零成本的 Schema 演进: 在模思"打标与特征高速迭代"的场景中,经常需要为数据集增加新的标签或特征列。Lance 支持无成本加列(Zero-copy Schema Evolution),新增列时无需重写存量数据,极大降低了数据回填的存储与计算成本。
-
灵活的数据版本管理: Lance 提供类似 Git 的数据版本控制能力,包括快照 、ACID 事务 与 Tag 标注。这使得数据处理(如打标)与模型训练可以基于不同的数据版本异步进行、互不干扰 。同时,版本可追溯、可回滚的特性也保障了模型训练的可复现性,允许团队在关键版本上(如模型发版前的数据集)创建 Tag 以便长期引用。
-
高效的训练数据加载: 针对模型训练中的数据读取瓶颈,Lance 提供了两大优化:
-
列裁剪:作为列式存储,训练时只读取必要的特征列,避免了不必要的 I/O 放大。
-
随机读取:支持基于行号(Row ID)或二级索引的高效随机访问,显著提升了数据加载器(DataLoader)的性能,并使得全局 Shuffle 操作可以更轻量地在 ID 层面完成,降低了内存开销。
-
未来,模思公司计划进一步利用 Lance 的高级特性,深化其在 AI 研发流程中的应用:
-
基于 Branch 的 AI 实验管理: 引入 Lance 的 Branch 功能来管理不同的 AI 实验。每个实验可以在独立的"分支"上进行,互不影响的实现添加、修改数据或特征。实验成功后,其产生的数据变更可以无破坏性地合并回主干,极大提升了多方案并行探索与评估的效率。
-
原生的向量检索能力: 利用 Lance 内置的 IVF-PQ 和 HNSW 等向量索引能力,直接在数据湖上进行高效的相似性搜索。这将在数据探查(如快速找到相似风格的音频)、异常样本召回以及图片、音频去重等场景中发挥重要价值,无需再将数据同步至专门的向量数据库。
五
总结与展望
模思公司与火山 LAS 产品的成功携手,不仅极大释放了模思公司的算法生产力,也充分证明了火山 LAS 产品这一套解决方案在面对大规模多模态数据存储、计算和管理上的可行性和先进性。模思公司依托火山 LAS 产品,以"Daft + Lance"的黄金组合构建了一套贯通多模态数据存储、计算和管理的一体化链路。依赖 Lance 的 Schema 演进、版本管理、随机读与向量检索能力,训练数据可以在不重写的前提下快速演进、回溯与高效加载;配合 Daft 在多模分布式计算、异构资源调度上的优势,训练数据准备效率整体提升约 50%,音频去噪与说话人分离阶段 GPU 利用率分别高达超 80% 和 95%,显著缩短了模型的迭代周期。
未来,双方将继续深化在多模态数据处理、训练数据准备,以及 AI 算子方向上的合作与创新,在为企业降本增效的同时,也不断强化火山 LAS 的产品力,助力双方迈向合作共赢的新局面。