效果:
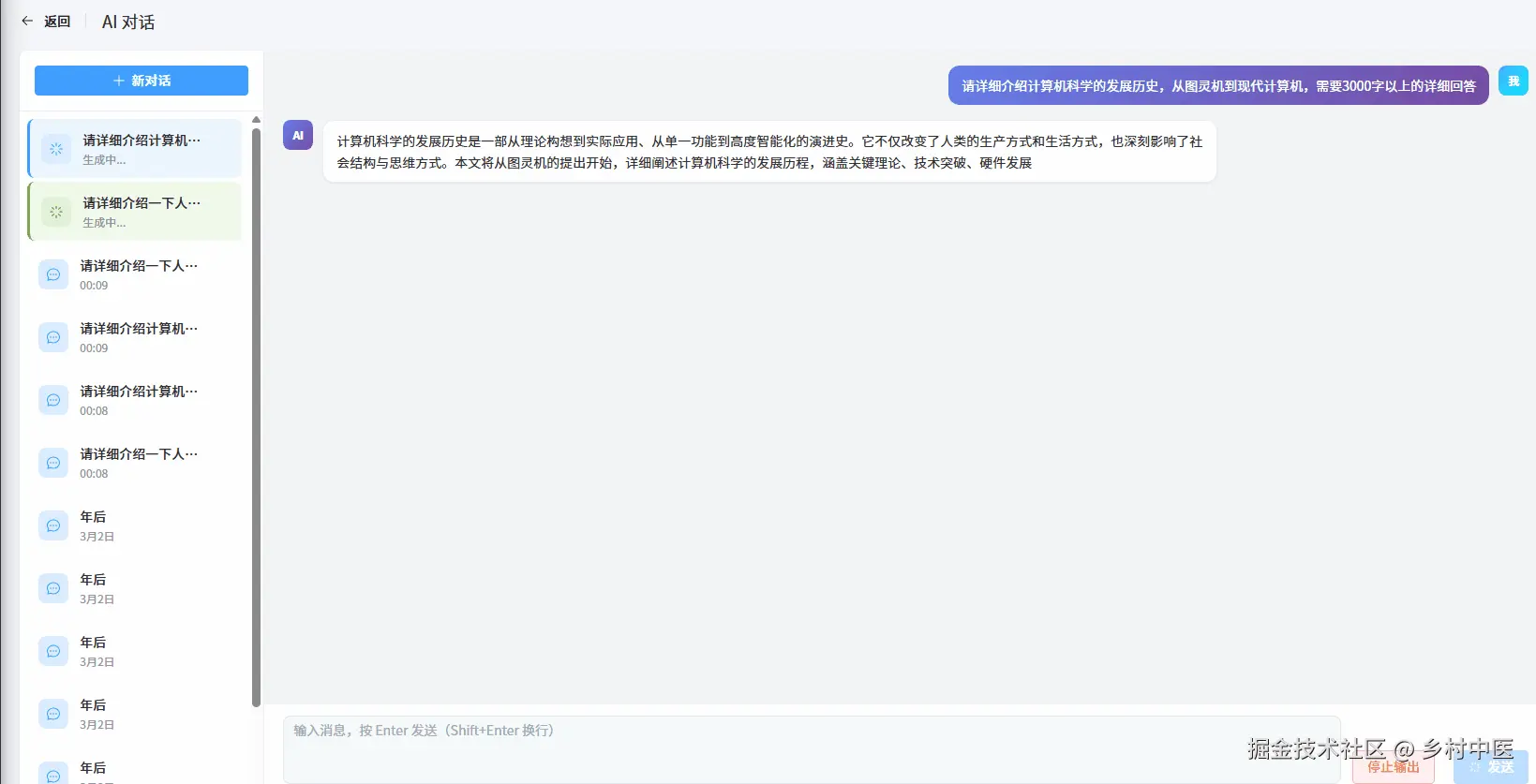
如何实现多对话流式输出:Vue3 + Pinia 实战
在多会话 AI 聊天应用中,流式输出是提升用户体验的关键特性。然而,当用户在 AI 生成回复的过程中切换会话或创建新会话时,很容易出现内容串台、状态混乱、消息丢失等问题。本文基于一个 Vue3 + Pinia 实际项目,深入讲解如何构建一个稳定可靠的多会话流式输出系统。
一、为什么多对话流式更难
单会话场景下,流式输出只需关注读取流 → 更新 UI → 完成/错误处理这一线性流程。但多会话场景下,情况变得复杂:
- 会话 A 的 AI 正在逐字生成回复
- 用户此时切换到会话 B ,或点击新对话 创建 会话 C
- 会话 A 的流式请求仍在后台继续,网络数据仍在不断到达
- 若不做隔离,A 的流式内容可能错误写入 B 或 C 的消息列表
- 用户切回 A 时,可能看不到完整生成内容,或状态异常
核心问题只有一个:如何隔离多个并发流,确保每段内容写入正确会话?
二、多对话流式输出的核心挑战
1. 会话切换时的流式冲突
用户在会话 A 生成过程中切走,A 的流在后台继续。若不隔离,onChunk 回调可能错误更新当前展示的会话 B 或 C 的消息列表,导致内容串台。
2. 乐观会话的 ID 映射
新创建的会话在服务端返回真实 ID 前,通常使用临时 ID(如 temp-123456)。流式输出完成后,需要正确将临时 ID 替换为真实 ID,并同步更新所有关联状态(消息存储、会话列表、当前活跃会话等)。
3. 按会话隔离的消息存储
每个会话的消息应独立存储,切换会话时只切换"展示哪个会话",而不影响其他会话的数据。否则,多流并发时难以保证数据归属正确。
4. 并发流的资源管理
多个会话可能同时存在流式输出,需要:
- 明确哪些会话正在流式输出
- 限制最大并发数,避免同时跑太多流导致资源耗尽
- 流结束时正确清理状态映射
三、方案一:按会话隔离的消息存储(推荐)
核心思路:流始终写入「发起流的会话」,而非「当前活跃会话」。这样,即使用户切换会话,后台流仍会写入正确的目标会话。
架构示意
核心状态设计
javascript
// 按会话 ID 存储消息:conversationId -> Message[]
const messagesByConversationId = ref(new Map())
// 正在流式输出的会话:conversationId -> streamId
const streamingConversations = ref(new Map())
// 当前活跃会话 ID(仅影响 UI 展示哪个会话)
const activeConversationId = ref(null)
// 当前会话的消息(计算属性,从 Map 中按 activeConversationId 取出)
const messages = computed(() => {
const convId = activeConversationId.value
if (convId == null) return []
return messagesByConversationId.value.get(convId) ?? []
})发送消息:流写入目标会话
关键点:在 onChunk 中通过 targetConvId 定位要更新的会话,与当前展示的会话无关。
javascript
async function sendMessage(content) {
// 新会话:创建乐观会话
if (activeConversationId.value == null) {
const tempId = `temp-${Date.now()}`
conversations.value = [
{ id: tempId, title: content.trim().slice(0, 30) || '新对话', updated_at: new Date().toISOString() },
...conversations.value
]
activeConversationId.value = tempId
}
const targetConvId = activeConversationId.value
// 乐观更新:添加用户消息和空的助手占位
const existingList = messagesByConversationId.value.get(targetConvId) ?? []
setConversationMessages(targetConvId, [
...existingList,
{ id: `temp-${Date.now()}`, role: 'user', content: content.trim(), pending: true },
{ id: `temp-${Date.now() + 1}`, role: 'assistant', content: '', streaming: true }
])
// 注册到流式输出管理
streamingConversations.value.set(targetConvId, Date.now())
await streamChat(content, history, {
conversationId: targetConvId,
onChunk: (chunk, fullText) => {
const list = messagesByConversationId.value.get(targetConvId) ?? []
const idx = list.findLastIndex(m => m.role === 'assistant' && m.streaming !== false)
if (idx >= 0) {
const next = [...list]
next[idx] = { ...next[idx], content: fullText }
setConversationMessages(targetConvId, next)
}
},
onDone: (fullText, metadata) => {
// 更新消息、迁移 temp->real、清理流映射...
},
onError: (errMsg) => { /* 错误处理 */ }
})
}由于 targetConvId 在流开始时已确定,即使用户切到其他会话,onChunk 仍会写入会话 A 的存储,不会串到会话 B 或 C。
四、乐观会话与 ID 转正
新会话创建时使用 temp-{timestamp},流结束时从 metadata.conversation_id 拿到真实 ID,需完成以下迁移:
javascript
if (realId && isTempConversationId(targetConvId)) {
const oldId = targetConvId
// 1. 迁移消息存储
const msgs = messagesByConversationId.value.get(oldId)
if (msgs) {
const map = new Map(messagesByConversationId.value)
map.delete(oldId)
map.set(realId, msgs)
messagesByConversationId.value = map
}
// 2. 迁移 conversationMeta(分页等)
const metaMap = new Map(conversationMeta.value)
if (metaMap.has(oldId)) {
metaMap.set(realId, metaMap.get(oldId))
metaMap.delete(oldId)
conversationMeta.value = metaMap
}
// 3. 若当前展示的是该会话,必须更新 activeConversationId
if (activeConversationId.value === oldId) {
activeConversationId.value = realId
}
// 4. 更新会话列表中的 conv.id,并刷新列表
const conv = conversations.value.find(c => c.id === oldId)
if (conv) conv.id = realId
loadConversations(1).then(() => mergeConversationIfMissing(conv))
}否则,切回该会话时会读到已删除的 temp-xxx,导致无内容展示。
五、消息分页:limit 20 与上滑加载更多
为控制首屏请求量和内存占用,消息列表通常采用游标分页:首次加载最近 20 条,用户上滑到顶部时再加载更早的历史。实现要点如下。
1. 状态设计:per-conversation meta
每个会话需要独立的分页状态(hasMore、page、loading),用 conversationMeta 按会话 ID 存储:
javascript
// conversationId -> { hasMore, page, loading }
const conversationMeta = ref(new Map())
function getOrInitMeta(conversationId) {
if (!conversationMeta.value.has(conversationId)) {
const newMap = new Map(conversationMeta.value)
newMap.set(conversationId, { hasMore: true, page: 0, loading: false })
conversationMeta.value = newMap
}
return conversationMeta.value.get(conversationId)
}2. API:before + limit
接口使用 before 游标 + limit:
javascript
// GET /conversations/{id}/messages/?before={messageId}&limit=20
const data = await chatHttp.getMessages(conversationId, {
before: beforeId, // 首次为 null,后续为当前列表第一条(最旧)消息的 ID
limit: 20
})- 首次加载 :
before = null,返回最近 20 条(按时间正序) - 加载更多 :
before = existingMsgs[0].id,返回该消息之前的 20 条
3. 数据合并:头部追加并保持顺序
服务端返回的是「更早的消息」,需反转后追加到现有列表头部:
javascript
const sortedMsgs = [...msgs].reverse()
const merged = isFirstLoad ? sortedMsgs : [...sortedMsgs, ...existingMsgs]
setConversationMessages(conversationId, merged)hasMore 判断:若本次返回数量等于 limit,则认为还有更多。
4. UI:上滑触发加载
效果:
 在消息列表的
在消息列表的 scroll 事件中,当 scrollTop < 50 时触发加载:
javascript
const handleScroll = async () => {
const el = listRef.value
if (!el) return
// 滚动到顶部附近时加载更多
if (
el.scrollTop < 50 &&
activeConversationId.value &&
hasMoreMessages.value &&
!loading.value
) {
const oldHeight = el.scrollHeight
await loadMessages(activeConversationId.value)
nextTick(() => {
// 保持视觉位置:新内容插入顶部后,用「新高度 - 旧高度」补偿 scrollTop
el.scrollTop = el.scrollHeight - oldHeight
})
}
}关键 :加载完成后,新消息插入顶部会导致 scrollHeight 增大。若不调整 scrollTop,视口会「跳」到新内容顶部。通过 scrollTop = scrollHeight - oldHeight,可保持用户当前看到的相对位置不变。
5. 与按会话存储的配合
conversationMeta 在 temp→real 迁移时需一并迁移(见第四节),否则切换会话后 hasMore 等状态会丢失。loadMessages 仅对真实会话生效,临时会话不请求历史。
六、实战踩坑与解决方案
坑 1:直接修改对象属性导致视图不更新
问题 :msg.content += chunk 直接改属性,Vue 响应式可能不触发。
解决 :用对象替换 messages[idx] = { ...msg, content: fullText }。
坑 2:流式串写到其他会话
问题 :用户切换会话后,原流的 onChunk 仍执行,错误写入新会话。
解决 :按会话存储 + 写入 targetConvId;或采用 isAttached() 检查。
坑 3:临时 ID 替换后状态不一致
问题 :temp-xxx 换为真实 ID 后,activeConversationId、会话列表、消息存储未同步。
解决 :在 onDone 中统一迁移消息、meta、activeConversationId、conv.id。
坑 4:多流并发资源泄漏
问题:多个流同时跑,状态混乱或映射未清理。
解决 :用 streamingConversations 或 streamIdByConversationRef 管理,流结束时删除对应映射。
坑 5:并发限制
问题:用户同时在多个会话发起请求,导致资源耗尽。
解决 :设置 MAX_CONCURRENT_STREAMS(如 2),发送前检查 streamingConversations.size。
七、架构总结
分层职责
- API 层:只负责流读取和事件解析,不碰 UI
- Store 层:管理消息状态(占位、流式、结束、失败)
- UI 层:渲染、输入、滚动
核心原则
- 按会话隔离存储 :
messagesByConversationId按会话 ID 存消息 - 流写入目标会话 :
onChunk通过targetConvId定位,与当前展示无关 - 乐观会话正确转正 :
onDone中完整迁移 temp→real,同步所有关联状态 - 并发控制与资源清理 :
MAX_CONCURRENT_STREAMS+ 流结束时清理映射
结语
多会话场景下的流式输出,核心不是「能读流」,而是建立完整的隔离与状态同步机制。按会话隔离存储、流写入目标会话、乐观会话正确转正,再配合合理的 SSE 解析与 UI 让出,即可实现稳定、流畅的多对话流式体验。