Java 后端接入 AI Agent:Tool Calling 网关、幂等与审计日志实战
摘要:AI Agent 能发起 Tool Call,不代表它应该直接碰业务接口。真正可上线的 Java 后端,需要在模型和业务系统之间加一层 Tool Calling 网关,把工具注册、权限校验、幂等、超时、审计日志和错误回填都收住。本文结合 Spring AI、LangChain4j、OpenAI、Anthropic 的官方 Tool Calling 设计,以及 DDIA 里的可靠性、事务和分布式故障思路,给出一套可落地的后端设计。
模型很聪明,事故也很快
假设你给客服系统接了一个订单 Agent。
用户输入:
帮我看一下订单 20260530001 为什么退款没到账,能不能重试一下?
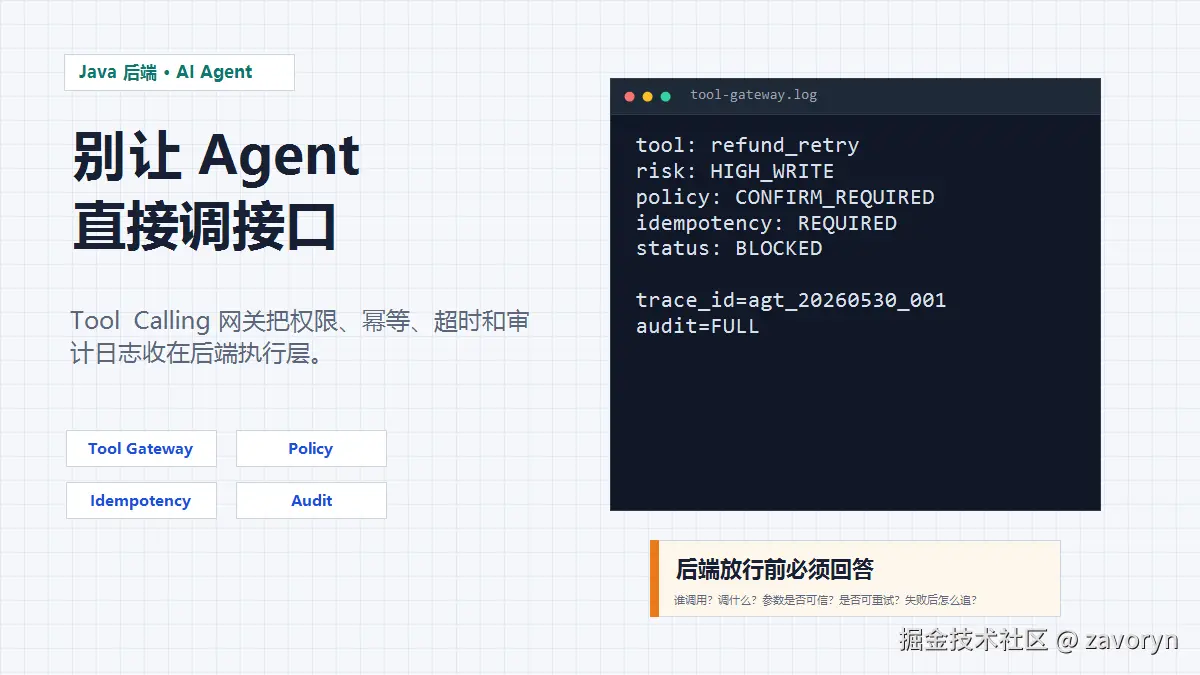
模型理解得很快。它先查订单,再查退款记录,然后发现退款状态是 FAILED,于是决定调用:
json
{
"tool": "refund_retry",
"arguments": {
"orderId": "20260530001",
"reason": "user_request"
}
}如果这是一个 Demo,事情到这里就结束了。模型会说"已为你重新发起退款"。
但如果这是生产系统,问题才刚开始:
- 这个用户是不是订单 owner?
- 退款重试是不是高风险写操作?
- 这次调用有没有人工确认?
- 如果下游超时,退款到底有没有成功发起?
- 如果 Agent 重试两次,会不会重复退款?
- 如果用户投诉,后端能不能查出当时模型看到了什么、调用了什么、为什么被放行?
很多 Agent 项目从 Demo 进入真实业务时,第一道坎不是模型能力,而是后端敢不敢让它执行。
今天这篇就讲这个问题:
Agent 可以提出 Tool Call,但 Java 后端必须决定它能不能执行、怎么执行、如何记录、失败后怎么收场。
一句话定义
Tool Calling 网关可以这样理解:
它是模型和业务系统之间的受控执行层,负责把模型提出的工具调用请求,转换成经过权限、参数、幂等、风险、超时和审计约束的后端操作。
注意这里有一个关键差别:模型不是工具执行者,后端才是。
Spring AI 官方文档说得很清楚:模型只能请求工具调用并给出输入参数,真正执行工具、返回结果的是客户端应用。OpenAI 的 function calling 文档也把工具调用拆成三件事:你给模型工具定义,模型返回工具调用请求,你的应用生成 tool output 再交回模型。
这意味着后端不能把 Tool Calling 当成"模型自动调用接口"。
更准确的说法是:
text
模型提出意图
后端验证意图
后端执行工具
后端记录证据
模型基于结果回答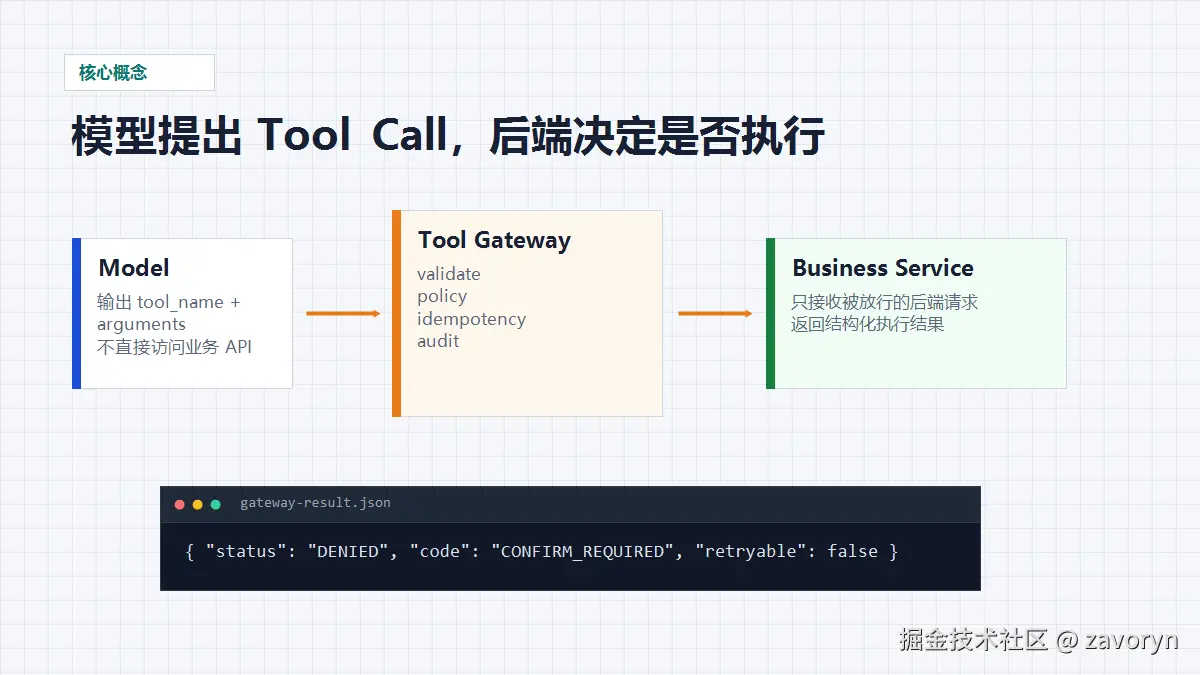
为什么不能让 Agent 直接连业务接口
很多团队最早接 Tool Calling,会这么做:
text
LLM -> Function Calling -> Java Method -> Business Service看起来链路很短,开发也快。但一旦工具变多、业务变复杂,这条链路会很脆。
1. 模型会选错工具
用户说"查一下退款状态",模型可能选 queryRefundStatus,也可能误选 refundRetry。
原因不一定是模型差。工具描述太短、工具名字相似、一次暴露太多工具、上下文里有误导信息,都可能让模型选错。
Anthropic 的工具定义文档强调,工具描述要说明工具做什么、什么时候用、什么时候不该用、参数含义和限制。这个建议对后端很重要:工具描述不是注释,它会直接影响模型路由。
2. 参数看起来合法,但业务上可能错
JSON Schema 可以约束字段类型,但它不能天然判断这个 orderId 是否属于当前用户,也不能判断 refundId 和 orderId 有没有混用。
这类校验必须回到后端业务上下文里做。
3. 超时以后,状态是不确定的
DDIA 第 9 章讲分布式系统故障时有一个很关键的点:当请求超时时,调用方并不知道远程节点是否收到了请求,也不知道它是否已经执行。
放到 Tool Calling 里就是:
text
Agent 调用 refund_retry
下游 3 秒超时
Agent 想重试这时后端不能简单地说"失败了,再来一次"。因为第一次调用可能已经在下游生效,只是响应丢了。
4. 重试可能把问题放大
DDIA 第 2 章提到重试风暴:系统接近过载时,客户端超时重试会进一步增加请求速率,让系统更难恢复。
Agent 系统也一样。如果模型看到工具失败就不断重试,而网关没有重试上限、退避、熔断和幂等保护,失败会从一次工具调用扩大成业务故障。
5. 没有审计,就没有复盘
Agent 的危险不只在于"它做错了",还在于"它为什么做错"很难追。
普通接口日志通常只记录:
text
POST /refund/retry 500 3120ms但 Agent 事故复盘需要更多:
- 用户原始输入是什么?
- 模型请求调用哪个工具?
- 参数从哪里来?
- 风险等级是多少?
- 哪条权限规则放行?
- 有没有人工确认?
- 下游返回了什么?
- 最终回答有没有把失败说成成功?
这些不是业务 Service 自己能顺手解决的,应该由 Tool Calling 网关统一收集。
最小架构:5 层就够
一个可落地的 Java 后端 Tool Calling 网关,可以先拆成 5 层。
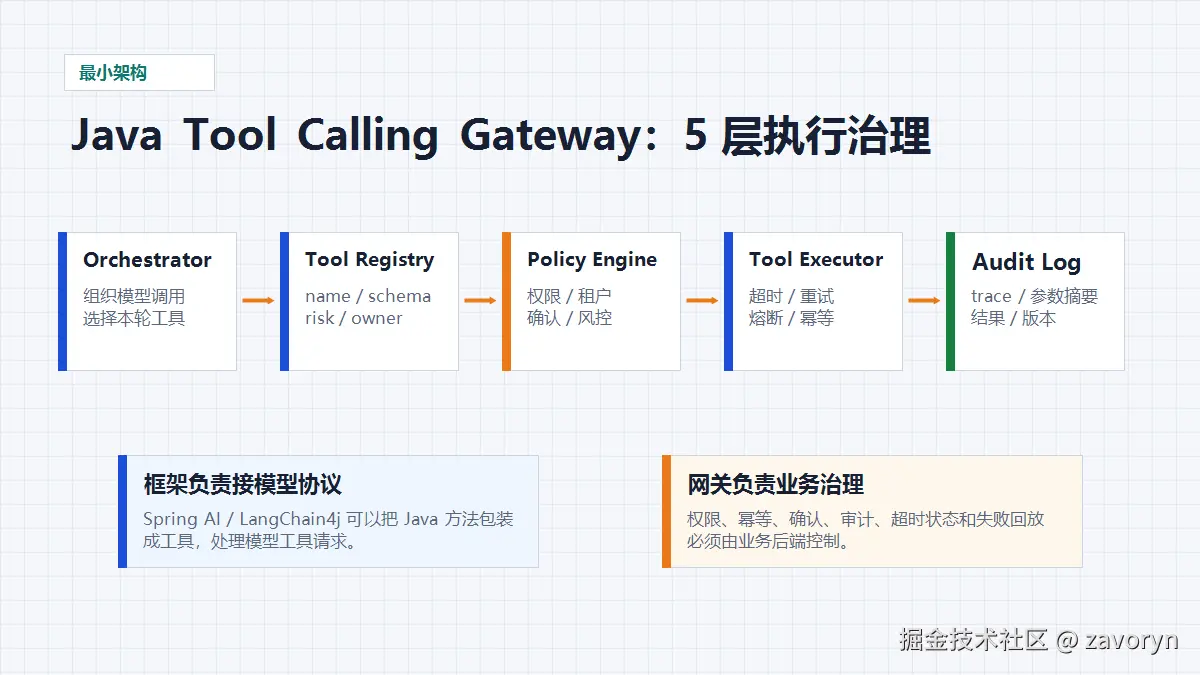
| 层 | 作用 | 关键问题 |
|---|---|---|
| Orchestrator | 组织模型调用、上下文、工具结果回填 | 本轮允许哪些工具 |
| Tool Registry | 管理工具定义、schema、风险等级、owner | 这个工具是什么 |
| Policy Engine | 做权限、风险、确认、租户隔离 | 这次能不能执行 |
| Tool Executor | 执行业务调用、超时、重试、熔断 | 怎么执行才稳 |
| Audit Log | 记录请求、参数摘要、结果、耗时、错误 | 以后怎么追 |
很多框架会帮你做一部分事情。
Spring AI 有 ToolCallback、ToolCallingManager、ToolCallbackResolver 等抽象,能把 Java 方法或函数包装成工具,并管理工具执行生命周期。LangChain4j 也支持用 @Tool 注解暴露 Java 方法,并在工具很多时通过 Tool Search 做动态发现。
但框架不会替你做完业务治理。尤其是这些事仍然要自己设计:
- 工具风险等级;
- 当前用户和租户权限;
- 高风险操作确认;
- 幂等 key;
- 调用日志 schema;
- 下游超时后的状态处理;
- 工具返回结果脱敏;
- 线上失败回放。
换句话说,框架解决"如何接工具",网关解决"能不能让它安全地执行"。
第一块:Tool Definition 不要只写 name 和 description
最小工具定义不要只长这样:
json
{
"name": "refund_retry",
"description": "重试退款"
}这对模型太模糊,对后端也太危险。
更适合生产系统的工具定义,至少应该包含这些字段:
| 字段 | 示例 | 作用 |
|---|---|---|
name |
refund_retry |
工具唯一名 |
description |
重试已失败的退款单 | 给模型判断何时使用 |
input_schema |
JSON Schema | 结构化参数约束 |
risk_level |
HIGH_WRITE |
权限和确认策略 |
owner |
payment-team |
事故和变更责任人 |
timeout_ms |
3000 |
执行超时 |
idempotent |
true |
是否要求幂等 key |
requires_confirmation |
true |
是否需要用户二次确认 |
allowed_roles |
support_admin |
角色白名单 |
audit_mode |
FULL |
日志记录级别 |
result_schema |
JSON Schema | 工具返回结构 |
Java 里可以先用一个简单的 record 表达:
java
public record ToolDefinition(
String name,
String description,
JsonNode inputSchema,
JsonNode resultSchema,
ToolRiskLevel riskLevel,
String owner,
Duration timeout,
boolean idempotent,
boolean requiresConfirmation,
Set<String> allowedRoles,
AuditMode auditMode
) {}风险等级可以先粗分,不要一开始设计得太复杂:
java
public enum ToolRiskLevel {
READ_ONLY, // 只读查询
LOW_WRITE, // 低风险写操作,比如保存草稿
HIGH_WRITE, // 高风险写操作,比如退款、取消订单
EXTERNAL_COST, // 会产生真实成本,比如发短信、调用付费 API
SENSITIVE_EXPORT // 导出敏感数据
}工具定义的核心不是"方便模型理解",而是同时服务三件事:
- 让模型更容易选对工具;
- 让后端知道执行前要检查什么;
- 让审计系统知道这次调用应该记录到什么程度。
第二块:权限矩阵先定死,别靠 Prompt 劝模型
Tool Calling 最容易犯的错,是把权限边界写在 Prompt 里:
text
你不能调用危险工具,除非用户有权限。这句话可以作为提示,但不能作为后端控制。
后端应该有一张明确的权限矩阵:

| 工具类型 | 示例 | 默认策略 |
|---|---|---|
| 只读查询 | 查订单、查物流、查退款 | 校验用户和租户权限后允许 |
| 低风险写 | 保存备注、创建草稿 | 校验权限,记录审计 |
| 高风险写 | 退款重试、取消订单、修改金额 | 权限 + 幂等 + 二次确认 |
| 外部成本 | 发短信、调用付费接口 | 配额 + 成本记录 + 限流 |
| 敏感导出 | 导出客户列表、下载报表 | 审批 + 脱敏 + 水印 |
一个最小 Policy Engine 可以这样写:
java
public interface ToolPolicyEngine {
ToolPolicyDecision evaluate(ToolExecutionContext context,
ToolDefinition definition,
JsonNode arguments);
}
public record ToolPolicyDecision(
boolean allowed,
String code,
String message,
boolean confirmationRequired
) {}执行前要检查的东西至少包括:
- 当前用户是否登录;
- 用户是否属于当前租户;
- 用户是否有工具所需角色;
- 参数里的资源是否属于当前用户或租户;
- 工具风险等级是否需要确认;
- 这次调用是否带了确认 token;
- 是否超过用户、租户或工具级别的频率限制;
- 是否命中黑名单参数或敏感字段。
这一步要放在工具真正执行之前。不要等业务 Service 执行失败后,再让模型解释"权限不足"。
第三块:幂等 key 是写操作的生命线
只读工具可以从查询开始,写操作必须先设计幂等。
DDIA 第 8 章在讲事务重试时提到一个典型问题:如果事务实际成功了,但客户端在收到确认前遇到网络中断,那么重试可能导致同一操作执行两次,除非你有额外的应用级去重机制。
Agent Tool Call 正好踩中这个坑。
比如模型调用:
json
{
"tool": "refund_retry",
"arguments": {
"orderId": "20260530001"
}
}下游超时了。模型或者 Orchestrator 想再试一次。
如果没有幂等 key,后端根本不知道第二次是同一意图的重试,还是用户又发起了一次新的退款请求。
一个实用的幂等 key 可以由这些字段组成:
text
tenant_id + user_id + conversation_id + tool_name + business_resource_id + intent_id落库时可以建一张执行表:
sql
CREATE TABLE agent_tool_execution (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
trace_id VARCHAR(64) NOT NULL,
conversation_id VARCHAR(64) NOT NULL,
user_id VARCHAR(64) NOT NULL,
tenant_id VARCHAR(64) NOT NULL,
tool_name VARCHAR(128) NOT NULL,
idempotency_key VARCHAR(256) NOT NULL,
risk_level VARCHAR(32) NOT NULL,
status VARCHAR(32) NOT NULL,
arguments_hash VARCHAR(128) NOT NULL,
result_hash VARCHAR(128),
error_code VARCHAR(64),
latency_ms BIGINT,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
UNIQUE KEY uk_idempotency_key (idempotency_key)
);执行逻辑可以是:
java
public ToolResult execute(ToolRequest request) {
ToolDefinition definition = registry.get(request.toolName());
String key = idempotencyKeyGenerator.generate(request, definition);
Optional<ToolExecutionRecord> existing = executionRepository.findByKey(key);
if (existing.isPresent()) {
return existing.get().toToolResult();
}
ToolExecutionRecord record = executionRepository.createPending(request, key);
try {
ToolResult result = executor.callWithTimeout(definition, request.arguments());
executionRepository.markSucceeded(record.id(), result);
return result;
} catch (TimeoutException ex) {
executionRepository.markUnknown(record.id(), "DOWNSTREAM_TIMEOUT");
return ToolResult.unknown("工具执行超时,结果状态待确认");
} catch (Exception ex) {
executionRepository.markFailed(record.id(), ex);
return ToolResult.failed("工具执行失败:" + ex.getMessage());
}
}这里有一个细节:超时不一定等于失败。
对高风险写操作,超时后的状态应该是 UNKNOWN 或 PENDING_CONFIRMATION,而不是直接告诉模型"失败了,可以重试"。
第四块:审计日志要记录"为什么放行"
很多系统已经有接口日志,但 Agent 需要的是执行证据链。
一条 Tool Call 审计日志至少要能回答:
| 问题 | 字段 |
|---|---|
| 谁发起的 | user_id、tenant_id、role |
| 哪次对话 | conversation_id、trace_id |
| 模型想做什么 | tool_name、arguments_hash、raw_arguments_ref |
| 后端为什么允许 | policy_code、risk_level、confirmation_id |
| 实际执行了吗 | status、business_request_id |
| 结果是什么 | result_status、error_code、result_hash |
| 成本和性能 | latency_ms、retry_count、token_usage |
| 后续怎么复盘 | prompt_version、tool_version、model_name |
注意不要把所有原始参数都明文塞进日志。更稳的做法是:
- 常规字段结构化落库;
- 敏感参数只存 hash 或脱敏值;
- 原始请求写入受控对象存储;
- 日志里保存
raw_arguments_ref; - 高风险工具保留完整审批链路。
这样既能审计,也能控制敏感数据扩散。
第五块:错误要回填给模型,但不能让模型瞎补
Spring AI 的工具错误处理支持把异常转成消息回给模型,也可以配置为直接抛给调用方处理。这个选择很关键。
我建议把错误分成四类:
| 错误类型 | 是否回给模型 | 后端策略 |
|---|---|---|
| 参数校验失败 | 是 | 告诉模型缺哪个字段,允许追问 |
| 权限拒绝 | 是 | 明确拒绝,不允许绕路 |
| 业务失败 | 视情况 | 给可展示错误码,不暴露内部细节 |
| 状态未知 | 是,但要强约束 | 告诉模型"不能承诺成功或失败" |
工具返回给模型的结果应该结构化:
json
{
"status": "DENIED",
"code": "TOOL_POLICY_DENIED",
"message": "当前用户无权执行退款重试",
"retryable": false,
"safe_to_answer_user": true
}或者:
json
{
"status": "UNKNOWN",
"code": "DOWNSTREAM_TIMEOUT",
"message": "退款重试请求超时,后端正在确认真实状态",
"retryable": false,
"safe_to_answer_user": true
}关键是不要只返回:
text
timeout模型看到这种弱信息,很容易补一句"请稍后重试",甚至再次调用同一个工具。
第六块:不要一次把所有工具都暴露给模型
工具越多,模型越容易选错,token 成本也越高。
OpenAI 文档提到,如果应用有很多函数或大 schema,可以用 tool search 延迟加载少用工具。LangChain4j 也有 Tool Search 思路:模型先看到搜索工具,再动态发现相关工具,而不是一开始暴露全部工具集。
后端可以做一个更简单的版本:
text
当前用户 + 当前场景 + 当前风险等级 -> 本轮可见工具集比如客服查询场景:
text
允许:
- order_query
- refund_query
- logistics_query
默认隐藏:
- refund_retry
- order_cancel
- coupon_grant
- customer_export只有当用户明确表达写操作意图,并且权限、确认、风控条件都满足时,才把高风险工具加入候选。
这不是"削弱模型能力",而是减少错误动作面。
Java 最小接口设计
一个最小 Tool Gateway 可以先从这几个对象开始。
java
public record ToolRequest(
String traceId,
String conversationId,
String userId,
String tenantId,
String toolName,
JsonNode arguments,
String confirmationToken
) {}
public record ToolResult(
ToolResultStatus status,
String code,
String message,
JsonNode data,
boolean retryable
) {}
public enum ToolResultStatus {
SUCCESS,
DENIED,
VALIDATION_ERROR,
BUSINESS_ERROR,
TIMEOUT,
UNKNOWN
}核心服务长这样:
java
public class ToolGatewayService {
private final ToolRegistry registry;
private final ToolPolicyEngine policyEngine;
private final ToolExecutor executor;
private final ToolAuditLogger auditLogger;
public ToolResult handle(ToolRequest request) {
ToolDefinition definition = registry.get(request.toolName());
ValidationResult validation = registry.validateArguments(definition, request.arguments());
if (!validation.valid()) {
return ToolResultBuilder.validationError(validation.message());
}
ToolPolicyDecision decision = policyEngine.evaluate(
ToolExecutionContext.from(request), definition, request.arguments());
if (!decision.allowed()) {
auditLogger.denied(request, definition, decision);
return ToolResultBuilder.denied(decision.code(), decision.message());
}
ToolResult result = executor.execute(request, definition);
auditLogger.completed(request, definition, decision, result);
return result;
}
}如果你用 Spring AI,可以把这个网关放在 ToolCallback 后面,也可以自定义 ToolCallingManager 或关闭框架自动执行,改成用户控制工具执行。选择哪种方式取决于你要不要拿到完整中间消息、要不要统一做审计和策略。
对于生产系统,我更偏向:
text
框架负责接模型协议
网关负责业务执行治理不要把权限、幂等、审计散落在每个 @Tool 方法里。那样前期快,后期很难统一治理。
常见坑
1. 工具描述太短
description = "退款重试" 基本不够。
更好的描述要说明:
- 这个工具只用于已失败退款;
- 不用于查询退款状态;
- 不用于首次发起退款;
- 必须在用户确认后调用;
- 需要订单 owner 校验;
- 返回值只表示请求受理,不代表资金到账。
2. 只做 JSON Schema,不做业务校验
Schema 只能检查结构,不能检查资源归属、租户隔离和业务状态。
3. 把工具失败直接交给模型自由发挥
错误结果必须结构化,尤其要告诉模型 retryable 和 safe_to_answer_user。
4. 高风险工具没有人工确认
退款、取消订单、导出数据、发送短信、扣减库存这类操作,默认都应该有确认机制。
5. 没有幂等 key
只要工具会产生副作用,就必须设计幂等。不要等第一次重复执行事故以后再补。
6. 日志只记接口,不记模型上下文
Agent 事故复盘需要 trace。至少要关联 trace_id、conversation_id、tool_name、arguments_hash、policy_decision 和 result_status。
一套最小落地清单

如果你现在要在 Java 项目里接 Agent,不建议一上来就接所有业务工具。
按这个顺序做:
- 先接 3 个只读工具,比如查订单、查退款、查物流。
- 给每个工具补完整
name、description、input_schema、risk_level、owner。 - 建一张
agent_tool_execution表,先记录 trace、工具名、参数 hash、状态、耗时。 - 做 Tool Policy Engine,至少支持用户、租户、角色和资源归属校验。
- 给所有写工具设计幂等 key,未设计前不要开放给模型。
- 高风险写操作必须走二次确认,确认 token 由后端生成。
- 工具返回结构化结果,明确
SUCCESS、DENIED、VALIDATION_ERROR、UNKNOWN。 - 对下游超时使用
UNKNOWN状态,不让模型自行承诺成功或失败。 - 每周抽样审计 Tool Call 日志,把失败样本加入 Agent 回归测试。
这套东西做完,Agent 才算真正接进后端,而不是只把几个 Java 方法暴露给模型。
面试或技术分享可以怎么讲
如果被问到"Java 后端怎么接 AI Agent 的 Tool Calling",不要只说"用 Spring AI 的 @Tool 注解"。
可以这样答:
我会把 Tool Calling 拆成模型协议层和后端执行治理层。模型协议层负责把工具定义暴露给模型,并接收模型返回的工具调用请求;后端执行治理层负责工具注册、参数校验、权限策略、风险等级、幂等控制、超时处理、审计日志和错误回填。只读工具可以先开放,高风险写操作必须有幂等 key、资源归属校验和人工确认。模型只能提出调用意图,真正执行必须由后端网关放行。
这比"模型会自动调用函数"更接近真实生产设计。
总结
Tool Calling 让 Agent 有了行动能力,但行动能力必须配执行边界。
官方框架已经告诉我们一件事:模型不会真的执行工具,它只是提出工具调用请求。真正调用 API、写数据库、发短信、退款、导出数据的,永远是你的应用。
所以后端接 Agent 的第一步,不是把业务方法全标上 @Tool,而是先问清楚:
- 哪些工具能暴露?
- 谁能调用?
- 参数怎么校验?
- 写操作怎么幂等?
- 超时后状态怎么判断?
- 模型能看到什么错误?
- 以后怎么审计和回放?
一句话记住:
别让 Agent 直接调接口。让它先过 Tool Calling 网关。
参考资料
- Spring AI Reference:Tool Calling
docs.spring.io/spring-ai/r... - LangChain4j:Tools Function Calling
docs.langchain4j.dev/tutorials/t... - OpenAI API:Function Calling
developers.openai.com/api/docs/gu... - Anthropic Claude API:Define tools
platform.claude.com/docs/en/age... - DDIA 中文翻译:Ch02 定义非功能性需求
docs/ddia/Ch02-定义非功能性需求.md - DDIA 中文翻译:Ch08 事务
docs/ddia/Ch08-事务.md - DDIA 中文翻译:Ch09 分布式系统的麻烦
docs/ddia/Ch09-分布式系统的麻烦.md