前言
传统的 RAG(检索增强生成)系统主要依赖向量相似度检索,虽然能够找到语义相近的文档,但往往忽略了知识之间的关联关系。本系列文章将介绍如何使用 Spring AI 1.1.2 结合 Neo4j 图数据库,通过知识图谱增强 RAG 检索能力,让 AI 不仅能找到相似的知识,还能发现关联的知识。
开发环境
- JDK: 17
- Spring Boot: 3.5.9
- Spring AI: 1.1.2
- Neo4j: 5.x
核心依赖配置
在 pom.xml 中添加以下依赖:
xml
<properties>
<spring-ai.version>1.1.2</spring-ai.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- Spring AI BOM -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring AI OpenAI Starter (兼容大多数 OpenAI 协议的模型) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<!-- Spring AI Vector Store -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-vector-store</artifactId>
</dependency>
<!-- Spring Data Neo4j -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
<!-- WebFlux for streaming -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
</dependencies>架构设计
整体流程
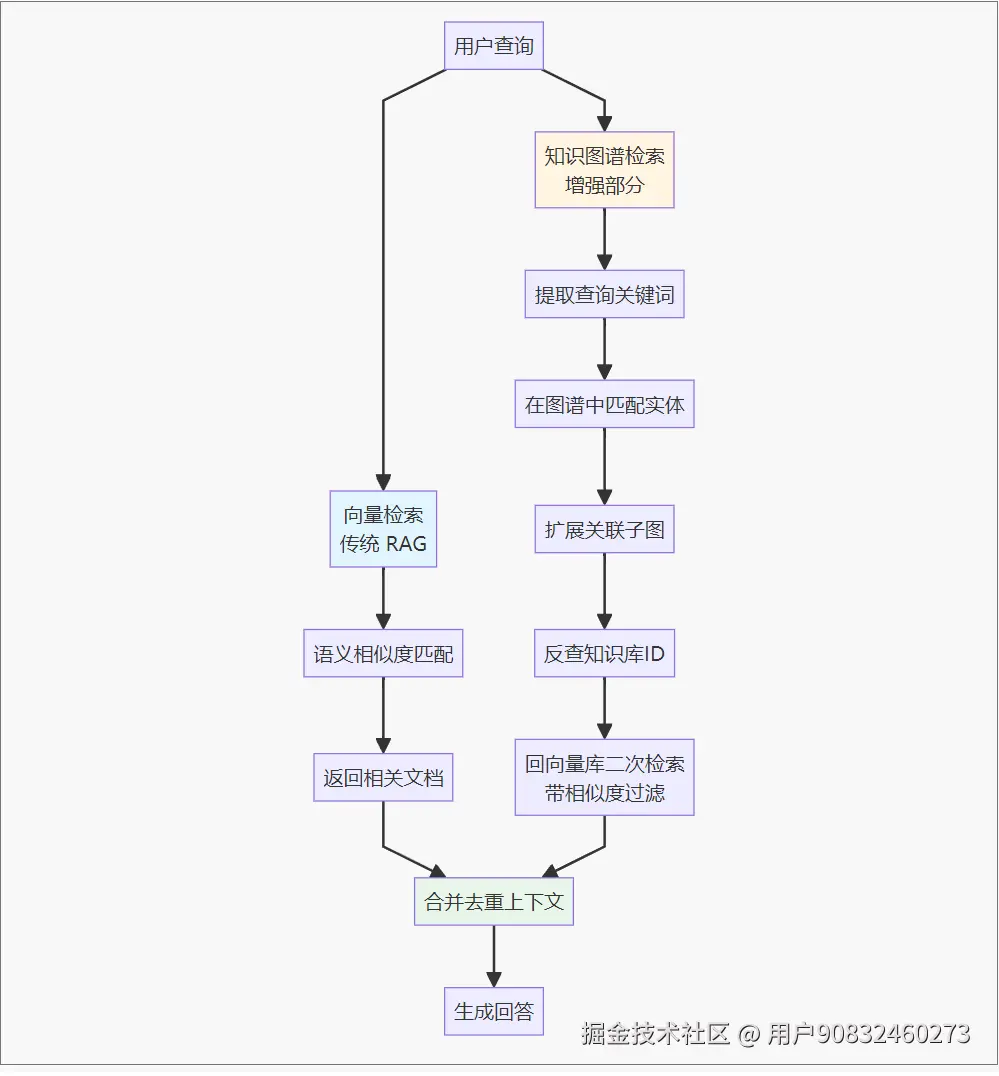
核心组件
- 向量存储: 基于 Spring AI VectorStore 实现语义检索
- 知识图谱: 使用 Neo4j 存储实体和关系
- 实体抽取: 利用 LLM 从文档中抽取实体和关系
- 图谱检索: 基于关键词匹配和图遍历发现关联知识
实现步骤
1. 定义知识图谱实体模型
使用 Spring Data Neo4j 定义图谱节点和关系:
less
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Node("KgEntity")
public class KgEntityNode {
@Id
@GeneratedValue
private Long id;
/**
* 业务唯一标识
*/
private String entityId;
/**
* 实体名称
*/
private String name;
/**
* 实体类型(如:服务、流程、规则、费用等)
*/
private String type;
/**
* 实体描述
*/
private String description;
/**
* 来源知识库ID
*/
private Long knowledgeId;
}
less
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@RelationshipProperties
public class KgRelationship {
@Id
@GeneratedValue
private Long id;
/**
* 关系类型(如:包含、属于、前置步骤等)
*/
private String relationType;
/**
* 关系描述
*/
private String description;
/**
* 来源知识库ID
*/
private Long knowledgeId;
/**
* 目标节点
*/
@TargetNode
private KgEntityNode target;
}这里使用了双重 ID 设计:id 是 Neo4j 内部 ID,entityId 是业务唯一标识(UUID),用于跨系统关联。knowledgeId 字段记录实体来源,便于知识更新时的增量维护。关系使用 @RelationshipProperties 注解,让关系也能携带元数据。
1.1 实体来源关联表
为了实现向量库和图谱的数据一致性,我们需要一张关联表来建立 MySQL 知识库与 Neo4j 图谱的桥梁。图谱检索时,先在 Neo4j 中找到关联的 entityId,再通过此表反查 knowledgeId。这样设计支持一个知识对应多个实体。
less
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@TableName("ai_kg_entity_source")
public class AiKgEntitySource {
@TableId(type = IdType.AUTO)
private Long id;
/**
* 知识库ID(关联 ai_knowledge 表)
*/
private Long knowledgeId;
/**
* Neo4j 实体业务ID
*/
private String entityId;
private LocalDateTime createTime;
}建表 SQL:
sql
CREATE TABLE `ai_kg_entity_source` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`knowledge_id` bigint NOT NULL COMMENT '知识库ID',
`entity_id` varchar(64) NOT NULL COMMENT 'Neo4j实体业务ID',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_knowledge_id` (`knowledge_id`),
KEY `idx_entity_id` (`entity_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='知识图谱实体来源关联表';2. 实现 LLM 实体抽取
⚠ 小模型可能输出不规范的 JSON 格式,我们需要将返回的数据进行清洗。
利用 LLM 从文档中自动抽取实体和关系。这是知识图谱构建的核心环节:
scss
@Slf4j
@Service
@RequiredArgsConstructor
public class KgExtractionServiceImpl implements KgExtractionService {
private final KgExtractionProperties extractionProperties;
private ChatClient chatClient;
/**
* 宽松的 JSON 解析器,容忍小模型输出的格式问题
*/
private static final ObjectMapper LENIENT_MAPPER = JsonMapper.builder()
.enable(JsonReadFeature.ALLOW_UNQUOTED_FIELD_NAMES) // 允许无引号字段名
.enable(JsonReadFeature.ALLOW_SINGLE_QUOTES) // 允许单引号
.enable(JsonReadFeature.ALLOW_TRAILING_COMMA) // 允许尾随逗号
.build()
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
/**
* 实体抽取的 System Prompt
*/
private static final String EXTRACTION_SYSTEM_PROMPT = """
你是一个知识图谱构建专家。请从用户提供的文本中抽取实体和关系,以严格的JSON格式输出。
## 抽取规则
1. 实体类型包括但不限于:服务、流程、规则、费用、商品、时间、地点、角色
2. 关系应反映实体间的逻辑联系,如:包含、属于、前置步骤、适用于、限制、触发
3. 实体名称应简洁,2-8个字为宜
4. 只抽取文本中明确表达的关系,不要推测
5. 确保 relationships 中的 source 和 target 必须在 entities 中存在
## JSON 格式要求(严格遵守)
1. 必须是合法的 JSON 对象,所有字段名和字符串值必须用双引号包裹
2. 对象的每个字段必须是 "key": value 格式,冒号前后可有空格
3. 数组元素之间用逗号分隔,最后一个元素后不能有逗号
4. 不要使用单引号,不要省略引号
5. 字符串中的特殊字符需要转义(如引号用 \\")
## 输出格式示例
只输出 JSON,不要有任何其他文字、解释或 markdown 标记。严格按照以下格式:
{
"entities": [
{
"name": "实体名称",
"type": "实体类型",
"description": "实体描述"
}
],
"relationships": [
{
"source": "源实体名",
"target": "目标实体名",
"relation": "关系类型",
"description": "关系描述"
}
]
}
注意:
- 每个字段名必须用双引号包裹,如 "name"、"type"
- 每个字符串值必须用双引号包裹
- 对象内每个属性格式为 "key": "value",注意冒号
- 数组最后一个元素后不要加逗号
- 如果没有实体或关系,对应数组为空:[]
""";
@PostConstruct
public void init() {
// 配置超时时间
SimpleClientHttpRequestFactory requestFactory = new SimpleClientHttpRequestFactory();
requestFactory.setConnectTimeout(Duration.ofSeconds(30));
requestFactory.setReadTimeout(Duration.ofSeconds(extractionProperties.getTimeoutSeconds()));
RestClient.Builder restClientBuilder = RestClient.builder()
.requestFactory(requestFactory);
// 初始化独立的 ChatClient 用于实体抽取
OpenAiApi openAiApi = OpenAiApi.builder()
.baseUrl(extractionProperties.getBaseUrl())
.apiKey(extractionProperties.getApiKey())
.restClientBuilder(restClientBuilder)
.build();
OpenAiChatOptions options = OpenAiChatOptions.builder()
.model(extractionProperties.getModel())
.temperature(0.1) // 低温度保证输出稳定
.build();
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.openAiApi(openAiApi)
.defaultOptions(options)
.build();
this.chatClient = ChatClient.builder(chatModel).build();
log.info("知识图谱实体抽取模型初始化完成: model={}, timeout={}s",
extractionProperties.getModel(), extractionProperties.getTimeoutSeconds());
}
@Override
public KgExtractionResultDTO extract(String content) {
if (StringUtils.isBlank(content)) {
return null;
}
try {
String response = chatClient.prompt()
.system(EXTRACTION_SYSTEM_PROMPT)
.user(content)
.call()
.content();
if (StringUtils.isBlank(response)) {
log.warn("LLM 实体抽取返回空结果");
return null;
}
log.debug("LLM 原始响应: {}", response);
// 提取并清洗 JSON
String json = extractJson(response);
if (json == null) {
log.warn("无法从 LLM 响应中提取 JSON,原始响应: {}", response);
return null;
}
log.info("清洗后 JSON: {}", json);
return LENIENT_MAPPER.readValue(json, KgExtractionResultDTO.class);
} catch (Exception e) {
log.error("LLM 实体抽取失败: {}", e.getMessage(), e);
return null;
}
}
/**
* 从 LLM 响应中提取并清洗 JSON 字符串
* 处理可能的 markdown code block 包裹及小模型输出的常见 JSON 格式问题
*/
private String extractJson(String response) {
String trimmed = response.trim();
// 去除 markdown code block 包裹
if (trimmed.contains("```")) {
int start = trimmed.indexOf("```");
int contentStart = trimmed.indexOf("\n", start);
int end = trimmed.lastIndexOf("```");
if (contentStart > 0 && end > contentStart) {
trimmed = trimmed.substring(contentStart + 1, end).trim();
}
}
// 确保是 JSON 对象
int jsonStart = trimmed.indexOf("{");
int jsonEnd = trimmed.lastIndexOf("}");
if (jsonStart >= 0 && jsonEnd > jsonStart) {
String json = trimmed.substring(jsonStart, jsonEnd + 1);
return cleanJson(json);
}
return null;
}
/**
* 清洗 LLM 返回的 JSON,修复小模型常见的格式问题
*/
private String cleanJson(String json) {
// 修复未加引号的 key,如 {name: "foo"} → {"name": "foo"}
json = json.replaceAll("([{,\\[])\\s*([a-zA-Z_][a-zA-Z0-9_]*)\\s*:", "$1\"$2\":");
// 去掉数组/对象末尾的多余逗号,如 ["a",] → ["a"]
json = json.replaceAll(",\\s*([}\\]])", "$1");
// 修复单引号值为双引号,如 'foo' → "foo"
json = json.replaceAll("'([^']*?)'", "\"$1\"");
// 修复缺少逗号的情况,如 {"a":"b" "c":"d"} → {"a":"b", "c":"d"}
json = json.replaceAll("\"\\s+\"", "\",\"");
// 修复对象之间缺少逗号,如 }{ → },{
json = json.replaceAll("}\\s*\\{", "},{");
// 修复数组元素之间缺少逗号,如 ][ → ],[
json = json.replaceAll("]\\s*\\[", "],[");
// 去除多余的空白字符(保留必要的空格)
json = json.replaceAll("\\s+", " ").trim();
return json;
}
}实体抽取 DTO 定义:
typescript
@Data
public class KgExtractionResultDTO {
private List<EntityItem> entities;
private List<RelationItem> relationships;
@Data
public static class EntityItem {
private String name; // 实体名称
private String type; // 实体类型
private String description; // 实体描述
}
@Data
public static class RelationItem {
private String source; // 源实体名称
private String target; // 目标实体名称
private String relation; // 关系类型
private String description; // 关系描述
}
}在实现上,我们为实体抽取单独配置了一个 ChatClient,这样可以避免影响主聊天流程的配置。温度参数设置为 0.1 是为了保证输出格式的稳定性,减少随机性带来的格式问题。
Docker 部署 Neo4j
使用 Docker 一条命令即可启动 Neo4j:
css
docker run -d \
--name lanjii-neo4j \
-p 7474:7474 \
-p 7687:7687 \
-e NEO4J_AUTH=neo4j/lanjii123456 \
neo4j:5.15.0启动后在 application.yml 中配置连接信息:
yaml
spring:
neo4j:
uri: bolt://localhost:7687
authentication:
username: neo4j
password: lanjii123456浏览器访问 http://localhost:7474 可以打开 Neo4j 管理界面,使用上面设置的用户名密码登录。索引创建等操作见下篇。
源码与在线体验
完整源码 :gitee.com/leven2018/l...
欢迎 Star ⭐ 和 Fork,项目包含本文涉及的所有代码(MCP 集成、多模型动态切换、RAG 知识库等)。
在线体验 :http://106.54.167.194/admin/index
小结
上篇我们完成了知识图谱的基础搭建工作:
- 搭建了开发环境,配置了 Spring AI 和 Neo4j 依赖
- 设计了实体模型和关联表,建立了向量库与图谱的桥梁
- 实现了 LLM 自动抽取实体和关系的核心功能
- 部署了 Neo4j 图数据库
下篇我们将介绍如何进行知识图谱检索,并将图谱检索结果与传统 RAG 的向量检索结果相结合,构建一个知识图谱增强的 RAG 系统。