本文译自「On-Device RAG for App Developers: Embeddings, Vector Search, and Beyond」,原文链接medium.com/google-deve...,由Sasha Denisov发布于2026年2月21日。
我们已经探讨了离线 AI 代理的重要性 和如何通过函数调用赋予它们工具。现在,让我们通过赋予它们记忆------即使用 RAG(检索增强生成)搜索和检索你的私有数据------来完善整个图景。
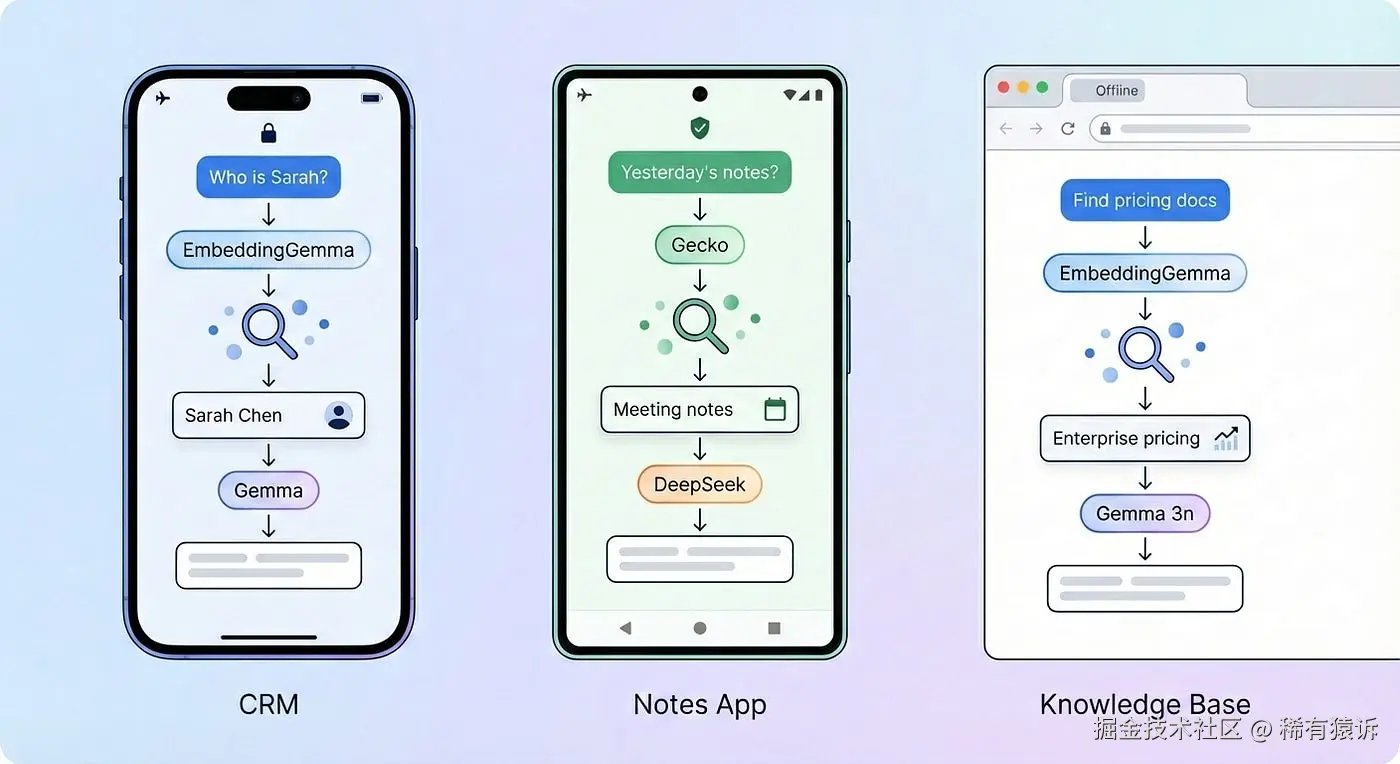
当我开始构建 Flutter Gemma 时,开发者们提出的第一个问题是:"如何让 AI 了解我的数据?" 不是维基百科,也不是通用知识------而是他们应用的数据。用户、联系人、文档。这正是 RAG 填补的空白。想象一下,你正在构建一个带有 AI 助手的个人 CRM 应用。你的用户问:"我应该跟进上周会议中的哪些人?" 挑战在于:AI 需要访问你的数据------你的联系人、你的对话记录、你的业务背景------而不是它训练时获得的通用知识。
问题:大型语言模型不了解你的数据
大型语言模型基于海量的公共数据(维基百科、书籍、网站)进行训练。它们在通用推理方面表现出色。但他们对你的联系人、会议记录,甚至昨天与客户的对话都一无所知。
如果你问一个普通的LLM(客户关系管理)"我应该跟进上周联系的哪些人?",你得到的要么是"我没有权限访问你的联系人"------虽然诚实但毫无用处------要么是一个自以为是、信誓旦旦地给出错误姓名和细节的答案。
有几种方法可以让LLM访问你的数据。我们来逐一看看。
方法A:把所有信息都塞进提示框
最直接的解决方法------把所有数据都塞进上下文。提示:"以下是我所有的联系人:- Sarah Chen,谷歌,企业级负责人......,- Mike Ross,Meta,潜在客户......,- ...(还有498个联系人)我应该跟进谁?"
问题:
-
上下文限制:设备端模型通常支持8K-32K个令牌。如果你有很多数据,根本装不下。
-
速度慢且成本高:上下文中的每个令牌都会增加计算时间和内存占用。上下文越长,响应速度越慢,电池消耗也越快。
-
容易被淹没在噪声中:查询某个联系人时,为什么要处理其他 499 个联系人的信息?更糟糕的是,LLM 往往会忽略隐藏在冗长上下文中的细节------你需要的那个联系人很可能被遗漏。
方法 B:微调模型
使用你的数据训练模型,使其"了解"这些数据。但是:
-
容易过时:你的 CRM 数据每天都在变化。每天都要重新训练吗?
-
成本高:微调需要消耗计算资源和时间。
-
无法扩展:每个用户的数据都不同。理论上,你可以使用 LoRa 为每个用户进行微调,但这既复杂又难以维护。
对于静态知识,微调效果很好------我在使用 LoRa 进行 Gemma 设备端推理微调中详细介绍了这一点。但对于频繁变化的数据,微调就不是最佳方案了。
方法 C:RAG --- 先检索后生成 (优胜方案)
与其将所有信息都提供给 LLM,不如针对每个查询仅检索相关信息:
-
查询联系人 → 仅检索该联系人的信息 → 发送给 LLM
-
查询公司 → 仅检索该公司的联系人 → 发送给 LLM
-
查询后续跟进 → 检索需要跟进的联系人 → 发送给 LLM
其优势:
-
始终保持最新:数据在查询时检索,而非预先嵌入模型。
-
可扩展至任何用户:相同的模型,不同的数据------每个设备都有自己的本地存储。
-
聚焦上下文:LLM 只看到它需要的信息------没有干扰,没有"中间丢失"的信息。
这就是 RAG(检索增强生成)------它就是解决方案。
最棒的是什么? RAG 可以完全在设备端运行------检索和生成都在本地完成,无需云端。
但"检索相关信息"究竟意味着什么?我们如何在成千上万条记录中找到正确的数据?让我们深入了解一下其机制。
RAG 基础知识
RAG 指的是先检索相关数据,然后生成响应。但我们究竟该如何找到"相关"数据呢?
查找正确的记录
为了回答用户的问题,我们需要在数据库中找到正确的记录。检索技术有很多种,例如关键词搜索、混合搜索、基于图的检索等等。本文将重点介绍一种目前可以使用 Flutter Gemma 轻松实现的技术:语义搜索(也称为向量搜索)。
什么是语义搜索?
传统的关键词搜索存在缺陷。例如,搜索"大公司"时,你找不到"企业客户"------即使它们的意思相同。语义搜索通过理解文本含义而非仅仅匹配单词来解决这个问题。其核心思想是:将文本转换为能够捕捉其含义的数字(向量)。含义相似 → 向量相似。这样,查找相关记录就变成了一个数学问题------找到与查询最接近的向量。
嵌入:将文本转换为向量
为了实现语义搜索,我们需要将数据转换为向量。这就是嵌入模型的作用所在。嵌入模型接收文本并输出一个向量------通常包含 768 个或更多数字,用于表示文本的含义:
bash
"enterprise sales lead" → [0.12, -0.45, 0.78, 0.23, ...] (768 numbers)
"big company executive" → [0.11, -0.44, 0.77, 0.25, ...] (similar!)
"banana smoothie recipe" → [0.89, 0.12, -0.34, 0.56, ...] (very different)2025 年 9 月,谷歌发布了EmbeddingGemma------一个基于 Gemma 3 的 3.08 亿参数嵌入模型,专为设备端使用而设计。你可以在 HuggingFace 上找到该模型。我一看到公告就知道 Flutter Gemma 需要嵌入支持------这意味着要为三个平台实现嵌入生成(当时桌面平台还不支持)。
在 Android 平台上,Google 提供了一个官方的 AI Edge LocalAgents RAG SDK,因此集成非常简单。iOS 和 Web 平台的情况则不同------没有官方 SDK,所以我从头开始构建了整个流程:iOS 使用 TensorFlow Lite 解释器,Web 使用 LiteRT.js,两者都使用 SentencePiece 分词器,手动处理张量,并进行精细的内存管理。桌面版支持即将推出(希望如此)
趁着这个机会,我觉得只支持 EmbeddingGemma 还不够------所以我又添加了 Gecko,这是谷歌于 2024 年 3 月发布的一款较早的嵌入模型。Gecko 利用大型 LLM 的知识蒸馏技术,仅用 1.1 亿个参数就能实现强大的检索性能。它的速度是 EmbeddingGemma 的 2.6 倍,但准确率略低------这在资源受限的设备上需要实时搜索,并且可以牺牲一些质量来换取速度时非常有用。
以下是如何使用 Flutter Gemma 生成嵌入代码:
Dart
final embedder = await FlutterGemma.getActiveEmbedder();
final vector = await embedder.generateEmbedding("enterprise sales lead");
// vector: [0.12, -0.45, 0.78, ...] --- ready for search存储向量:向量数据库
有了向量之后,你需要一个地方来存储它们并进行高效搜索。这就是向量数据库的作用。
像 Pinecone、Chroma 或 Qdrant 这样的云解决方案很受欢迎,但它们需要网络调用,这与设备端 AI 的初衷背道而驰。对于嵌入式应用,ObjectBox 是一个不错的选择------它是一个内置 HNSW 向量搜索的设备端数据库,专为移动设备和物联网设计。ObjectBox 拥有 Flutter SDK,因此你可以轻松地将其与 Flutter Gemma 结合使用进行嵌入式开发。但如果你不想在应用中添加额外的数据库依赖项,Flutter Gemma 提供了一种更简单的开箱即用方案:带有 HNSW 索引的纯 SQLite。无需额外依赖------SQLite 已集成到 Flutter 支持的每个平台上。
底层实现虽然跨平台保持一致,但使用了平台特定的 API:
-
Android 使用
SQLiteOpenHelper,嵌入数据以二进制 BLOB (float32) 格式存储。每个 768 维向量仅占用 3KB 空间------紧凑且读取速度快。 -
iOS 直接使用 SQLite3 C API,存储格式与 Android 相同。向量编码为小端 float32 数组,与 Android 相同,因此数据库文件与二进制文件兼容。
-
Web 的实现比较复杂------浏览器本身没有原生 SQLite。我使用了 wa-sqlite,它是 SQLite 的 WebAssembly 移植版本,并使用 OPFS (Origin Private File System) 进行持久化存储。需要注意的是:OPFS 需要 Web Worker,因此所有数据库操作都在专用的工作线程中运行,并通过消息传递将数据传递给主线程。
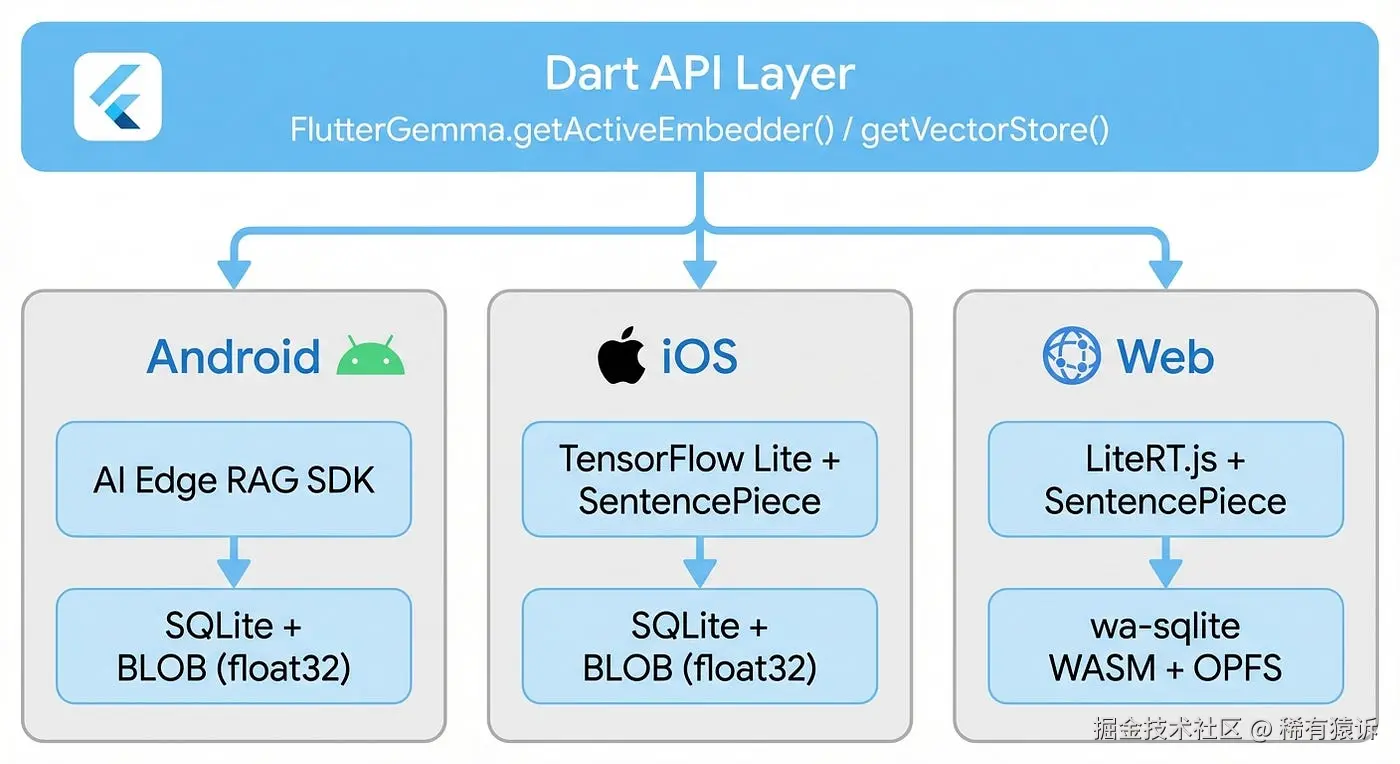
这三个平台都使用相同的模式、相同的 BLOB 编码和相同的余弦相似度计算方法------因此无论应用程序运行在何处,搜索结果都保持一致。
搜索工作原理
当用户提出问题时,我们会使用相同的嵌入模型将其转换为向量,然后在数据库中找到最接近的向量。
"最接近"是通过余弦相似度来衡量的------它计算高维空间中两个向量之间的角度。得分范围从 -1 到 1:1 表示向量指向同一方向(含义相同),0 表示它们垂直(不相关),-1 表示方向相反。实际上,任何高于 0.3-0.4 的值通常都具有相关性------具体的阈值取决于你的数据和用例。

最简单的方法是暴力搜索:将你的查询与数据库中的每个文档进行比较,计算每个文档的余弦相似度,然后返回匹配度最高的文档。这种方法对于小型数据集(数百甚至数千条记录)来说效果很好。但是,对于 10 万个联系人,每次搜索都需要进行 10 万次相似度计算。这速度太慢了。
HNSW(分层可导航小世界) 通过巧妙的多层图结构解决了这个问题。可以把它想象成地铁线路图:快线连接主要枢纽(顶层),而慢线连接每个站点(底层)。搜索从顶层开始,先进行大范围的跳跃以接近目标,然后再向下移动到局部层以提高精度。
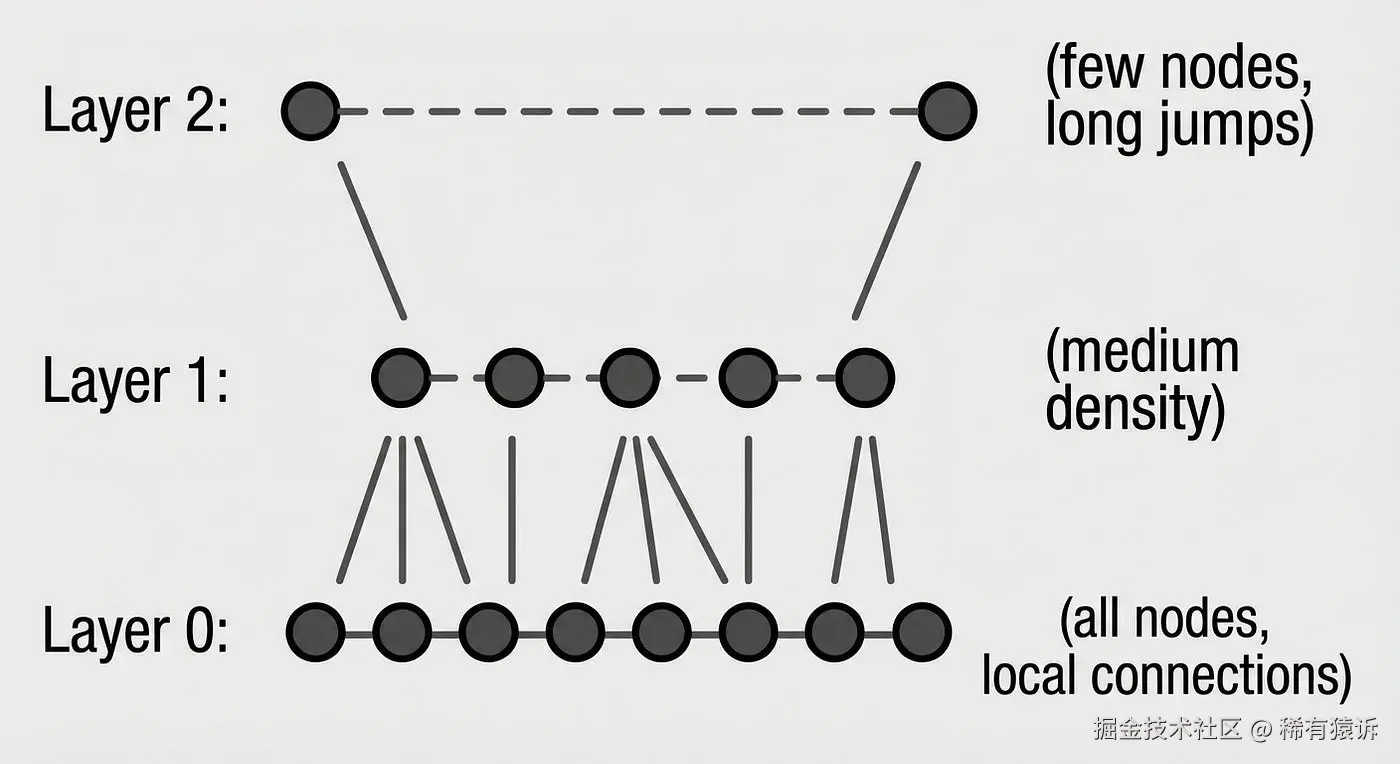
结果是:搜索复杂度从 O(n) 降低到 O(log n)。对于 10 万个联系人,只需要进行约 17 次比较,而不是 10 万次。Flutter Gemma 的 HNSW 实现采用了一种"过度获取并重新排序"的策略------HNSW 返回 2 倍的候选结果(快速、近似),然后使用精确的余弦相似度筛选出前 K 个结果。近似搜索速度快,精确搜索准确。
API 保持不变------Flutter Gemma 会在底层处理优化:
Dart
final results = await FlutterGemmaPlugin.instance.searchSimilar(
query: "enterprise contacts",
topK: 5,
threshold: 0.3,
);
// results: records semantically similar to "enterprise contacts"分块:数据准备
在建立索引之前,你需要决定如何将数据拆分成可搜索的单元------这称为分块。对于 CRM 系统,自然的分块方式是:一个联系人对应一个文档。但对于较长的内容,例如会议记录或电子邮件,你需要一种策略:固定大小的分割(简单但可能会截断句子中间部分)、语义分割(尊重语义边界)或文档结构(段落、章节)。最佳实践是在分块之间保持 10-20% 的重叠,以防止在边界处丢失上下文。
使用 Flutter Gemma 实现 RAG
现在我们已经了解了理论,接下来让我们看看如何在实践中应用它。Flutter Gemma 示例应用 包含一个完整的 RAG 实现------你可以查看它以获取完整代码。
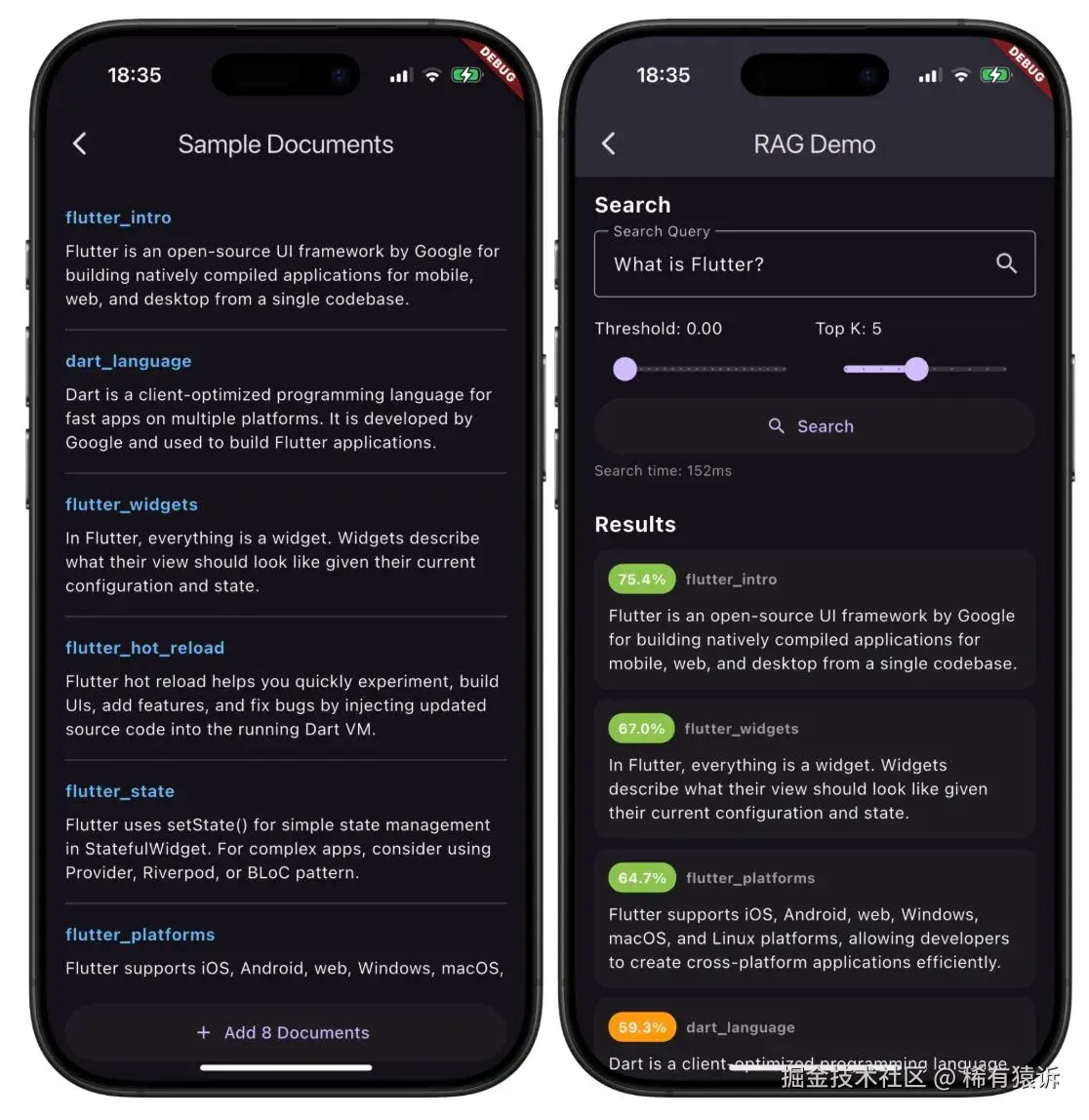
主要有两种工作流程:数据导入 (将数据导入矢量存储)和检索(在查询时进行搜索)。
数据导入
在进行任何搜索之前,所有数据都需要矢量化并存储。此过程在应用程序首次加载时执行一次,之后会随着数据的变化而增量更新。
初始索引 --- 首次启动时,处理所有现有记录:
Dart
Future<void> indexAllContacts(List<Contact> contacts) async {
final embedder = await FlutterGemma.getActiveEmbedder();
for (final contact in contacts) {
final embedding = await embedder.generateEmbedding(
contact.toSearchableText(),
);
await FlutterGemmaPlugin.instance.addDocumentWithEmbedding(
id: contact.id,
content: contact.toSearchableText(),
embedding: embedding,
metadata: jsonEncode(contact.toJson()),
);
}
}保持数据同步 --- 当记录发生更改时,矢量存储必须随之更新。为你的数据源设置监听器:
Dart
// Listen for changes and update vector store
contactsRepository.onContactChanged.listen((contact) async {
final embedder = await FlutterGemma.getActiveEmbedder();
final embedding = await embedder.generateEmbedding(
contact.toSearchableText(),
);
// addDocumentWithEmbedding uses INSERT OR REPLACE ---
// same ID overwrites the old record
await FlutterGemmaPlugin.instance.addDocumentWithEmbedding(
id: contact.id,
content: contact.toSearchableText(),
embedding: embedding,
);
});关键在于:你的向量存储是主数据的派生缓存。如果它不同步,搜索结果就会过时或出错。
检索
当用户提出问题时,将其转换为向量并查找相似文档:
Dart
Future<String> answerQuestion(String userQuery) async {
// 1. Search for relevant context
final results = await FlutterGemmaPlugin.instance.searchSimilar(
query: userQuery,
topK: 5,
threshold: 0.3,
);
// 2. Build context from results
final context = results
.map((r) => r.content)
.join('\n\n');
// 3. Pass to LLM with context
final prompt = '''
Based on the following information:
$context
Answer the user\'s question: $userQuery
''';
final chat = await model.createChat();
await chat.addQuery(Message(text: prompt, isUser: true));
final response = await chat.generateChatResponse();
return (response as TextResponse).token;
}LLM 现在可以访问数据库中的相关数据,而无需将所有内容都塞进提示框中。
从搜索到理解
语义搜索打开了关键词匹配永远无法实现的大门。"查找我的企业联系人"会检索到标记为"财富 500 强"的记录、提及"大交易"的笔记以及"Alphabet"的联系人------即使这些记录中没有包含"企业"一词。嵌入模型理解的是含义,而不仅仅是文本。
但是,如果你尝试搜索"我昨天和谁谈过?",这种神奇的功能就会失效。
"昨天"一词会生成一个表示"昨天"概念的嵌入向量,类似于"最近"、"过去"、"之前"。你的联系人记录包含日期:"2026-01-19"、"1月19日"。这些日期在语义上并不相似------不存在一个向量空间,使得"昨天"和"2026-01-19"指向同一方向。
而且,日期并非唯一的问题:
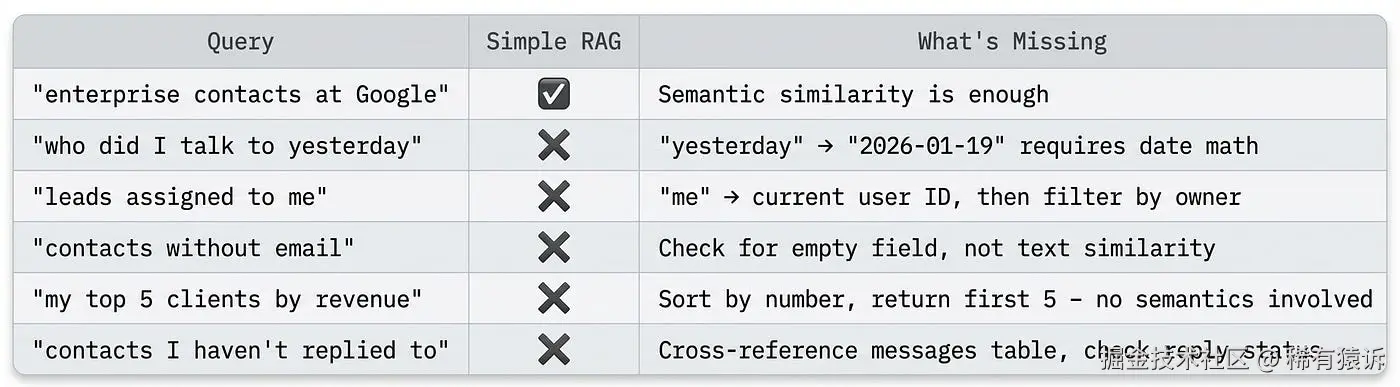
这些查询需要的是推理------字段过滤、排序、连接------而不是相似性匹配。我们需要语言学习模型(LLM)理解意图并将自然语言翻译成结构化查询。
基于 LLM 的增强型 RAG(基于函数调用)
我们发现,当查询需要推理时(例如日期解析、字段过滤和排序),语义搜索会失效。解决方案是什么?让 LLM 处理推理,然后调用函数来执行结构化查询。
这就是 Agentic RAG------2025-2026 年的主流模式,其中 LLM 动态地决定如何以及何时检索信息。
我们不会将用户的查询直接传递给向量搜索,而是先让 LLM 解析它。为了使这种智能体行为在设备上生效,你需要一个能够理解函数调用(而不仅仅是聊天)的模型。谷歌专门为此发布了 FunctionGemma:一个拥有 2.7 亿个参数的模型,经过优化,可以解析用户意图并使用正确的参数调用函数。我在使用 FunctionGemma 进行设备端函数调用中详细介绍了如何使用它。
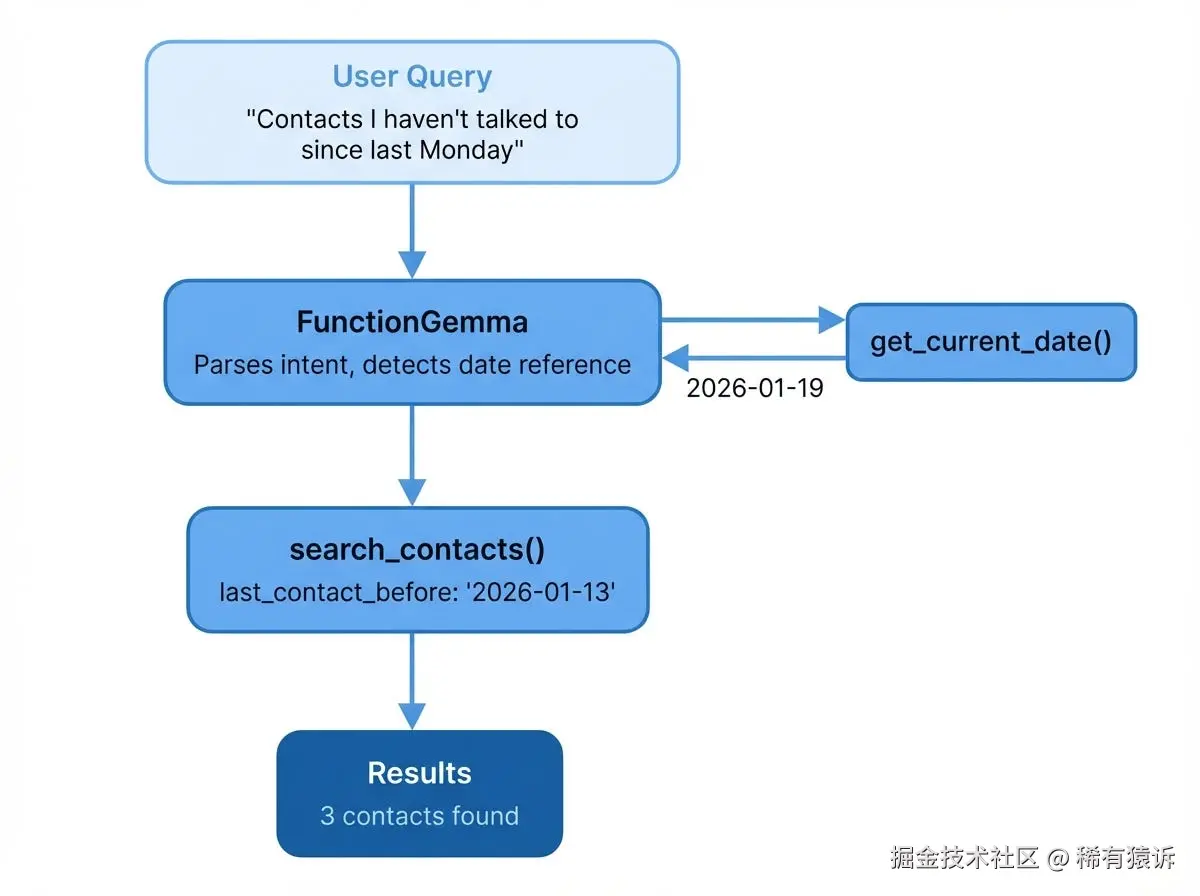
LLM 负责推理(日期运算、意图提取),而函数负责数据检索。
混合搜索:RAG 与过滤器的结合
FunctionGemma 从用户查询中提取参数后,你的函数可以将语义搜索与结构化过滤相结合:
Dart
Future<List<Contact>> searchContacts(Map<String, dynamic> params) async {
List<Contact> contacts;
// If semantic query provided, start with RAG
if (params['semantic_query'] != null) {
final results = await FlutterGemmaPlugin.instance.searchSimilar(
query: params['semantic_query'],
topK: 50,
threshold: 0.25,
);
contacts = results.map((r) => Contact.fromJson(jsonDecode(r.metadata!))).toList();
} else {
contacts = await contactsRepository.getAll();
}
// Apply structured filters extracted by LLM
if (params['company'] != null) {
contacts = contacts.where((c) =>
c.company.toLowerCase().contains(params['company'].toLowerCase())
).toList();
}
if (params['last_contact_before'] != null) {
final before = DateTime.parse(params['last_contact_before']);
contacts = contacts.where((c) => c.lastContact.isBefore(before)).toList();
}
return contacts.take(params['limit'] ?? 10).toList();
}关键在于:RAG 处理语义部分("对企业定价感兴趣"),而结构化过滤器处理逻辑部分(日期、状态、公司)。 FunctionGemma 会根据查询决定使用哪些参数。
现在一切正常
Dart
// ✅ Temporal queries
await query("Who did I talk to yesterday?");
// LLM extracts: last_contact_after="2026-01-18", last_contact_before="2026-01-19"
// ✅ Structured filters
await query("Leads assigned to me without email");
// LLM extracts: status="lead", owner="current_user", has_email=false
// ✅ Combined semantic + structured
await query("Google contacts interested in enterprise pricing");
// LLM extracts: company="Google", semantic_query="interested in enterprise pricing"
// ✅ Complex reasoning
await query("Prospects I should follow up with from Q4 last year");
// LLM calculates Q4 2025 dates, adds semantic_query="follow up needed"LLM 发挥其优势(理解语言、推断日期),而结构化查询则发挥其优势(过滤、排序、连接)。
结论
RAG 弥合了通用 LLM 和你的私有数据之间的鸿沟。借助 Flutter Gemma,整个流程(嵌入、向量搜索和生成)都在设备端运行,无需云端。
首先,对于语义至关重要的查询,请使用语义搜索。当遇到日期、过滤器、排序等限制时,可以使用 FunctionGemma 添加函数调用,让 LLM 协调结构化检索。
Flutter Gemma 示例应用 包含完整的 RAG 实现。克隆它,用你的数据进行测试,看看当人工智能完全在用户口袋里运行时,会发生什么。
欢迎搜索并关注 公众号「稀有猿诉」 获取更多的优质文章!
保护原创,请勿转载!