既然你点开了这篇文章,说明你大概率在生产环境被Kafka"教做人"过。
要么是消息莫名其妙丢了,导致财务对账对不上,CTO半夜打电话问候你全家;要么是消费者像发了疯一样重复处理同一条订单,导致用户余额扣成了负数。
别急着辩解说你看了官方文档,配了acks=all。在分布式系统的深水区,官方文档只是童话故事,源码和底层原理才是残酷的现实。
今天这篇长文,我不讲废话,不贴Hello World。我要带你扒掉Kafka的底裤,从ISR机制深入到PageCache刷盘策略,从幂等性设计的数学原理讲到Redis Lua脚本的原子性操作。
1. 读完这篇文章,你将获得
- 上帝视角:彻底理解 Kafka 消息流转的每一个环节,知道消息到底是在哪一步"蒸发"的。
- 防御体系 :一套 Production-Ready 的代码模板,包含多级重试 、本地消息表 、Lua脚本幂等等工业级方案。
- 底层内功 :明白为什么
request.required.acks=-1依然可能丢数据,以及 OS 层的fsync究竟在什么时候骗了你。
⚠️ 劝退声明
如果你只想找个面试题背诵一下,请出门左转找那些"三分钟精通Kafka"的水文。这里只有带血的实战经验和底层源码级剖析。建议先收藏,准备好咖啡,我们开始。
2. 现状与误区 (The Trap)
很多所谓的"资深开发",写 Kafka 代码是这样的:
❌ 反面教材:典型的"自杀式"写法
typescript
// 这是一个让架构师血压升高的反例
@Service
public class SuicideProducer {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendOrder(Order order) {
// 1. 没有任何回调,发后即忘 (Fire and Forget)
// 2. 默认配置可能是 acks=1,Leader 挂了就丢数据
kafkaTemplate.send("order-topic", JSON.toJSONString(order));
// 3. 甚至不检查发送结果就直接改数据库状态
orderService.updateStatus(order.getId(), "SENT");
}
}
@Service
public class SuicideConsumer {
@KafkaListener(topics = "order-topic")
public void consume(String message) {
Order order = JSON.parseObject(message, Order.class);
// 4. 自动提交 Offset (enable.auto.commit=true)
// 如果下面这行代码报错,或者机器宕机,Offset 已经提交了 -> 消息丢失
// 如果处理完了,提交 Offset 失败,下次重启 -> 重复消费
processOrder(order);
}
}💣 致命缺陷分析
- Fire and Forget (发后即忘) : 生产者根本不在乎 Broker 是否收到了消息。网络抖一下,消息就丢了,你的日志里连个响声都没有。
- 异步发送的陷阱 :
kafkaTemplate.send是异步的。你以为发成功了去改数据库,实际上 Kafka 还在建立连接。 - Auto Commit (自动提交) : 这是 Kafka 最坑爹的默认配置。它基于时间间隔提交 Offset。
-
丢消息场景 : 消费者拉取了一批消息,Auto Commit 触发提交了 Offset,紧接着你的业务逻辑抛了异常或者进程被
kill -9。恭喜你,这批消息永远消失了。 -
重复消费场景: 业务逻辑处理完了,还没到 Auto Commit 的时间点,消费者挂了。重启后,消费者会从上一次提交的 Offset 重新拉取,刚才处理过的消息又来了一遍。
听我一句劝:在涉及金钱和核心数据的链路上,永远不要相信默认配置。
3. 深度解析与原理 (The Deep Dive)
要解决问题,必须先看透本质。Kafka 的消息丢失和重复,本质上是分布式系统的一致性问题。
我们将全链路切分为三个阶段:生产端 (Producer) 、服务端 (Broker) 、消费端 (Consumer) 。
3.1 生产端:ACK 机制的谎言
你以为设置了 acks=all (或 -1) 就万事大吉了?Too young.
底层视角:ISR 与 Min.Insync.Replicas
Kafka 的 acks=all 意味着 Leader 必须等待所有 ISR (In-Sync Replicas) 中的 Follower 都同步完成,才给 Producer 返回成功。
- 陷阱: 如果 ISR 里只有 Leader 自己呢?
-
-
当 Follower 落后太多被踢出 ISR,此时 ISR = {Leader}。
-
如果
min.insync.replicas=1(默认值) ,那么acks=all实际上退化变成了acks=1。 -
Leader 刚落盘(甚至还在 PageCache 里),机器断电。
-
结果: 消息丢失,且 Producer 认为发送成功。
-
✅ 必须配合 min.insync.replicas
只有当 min.insync.replicas > 1 (例如设置为 2) 且 acks=all 时,才能保证至少有两个副本写入成功。如果不满足最小副本数,Producer 会直接收到 NotEnoughReplicasException 异常,从而避免"假装写入成功"的悲剧。
3.2 服务端:PageCache 的欺骗
Linux 的 I/O 机制是 Kafka 高吞吐的基石,也是数据丢失的隐患。
OS 视角:PageCache vs Fsync
Kafka 收到消息写入磁盘时,通常只是调用了 write() 系统调用。 此时数据还在 Kernel PageCache (内核页缓存) 中,并没有真正落到物理磁盘。
- Dirty Page: 脏页。数据在内存,未入磁盘。
- Flush: OS 后台线程(pdflush/flush)定期将脏页刷入磁盘。
场景复盘:
- Producer 发送消息。
- Broker (Leader) 写入 PageCache。
- Broker (Follower) 拉取消息,写入 PageCache。
- ISR 满足,返回 ACK 给 Producer。
- 此时,三台机器同时断电(机房故障)。
- 虽然你有多副本,但都在内存里。
- 结果: 数据永久丢失。
🤔 为什么 Kafka 默认不开启强同步刷盘 (log.flush.interval.messages=1)? 因为性能。每次写入都 fsync,吞吐量会下降 1000 倍。这是 Trade-off。我们只能通过多副本分布在不同机架/机房来降低风险,而不是依赖单机的 fsync。
3.3 消费端:Offset 的悖论
PlantUML: 消费端 Offset 提交的时序陷阱
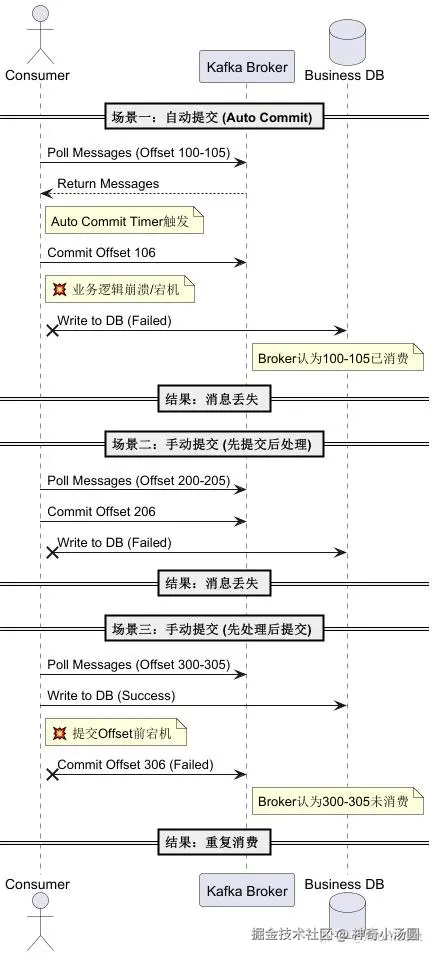
结论非常明显:只要发送 Offset 和业务处理不是原子操作,就必然存在丢消息或重复消费的可能。 而在跨网络跨系统的场景下,实现分布式事务(XA)代价太大。
所以,我们通常选择 "At Least Once" (至少一次) 语义,即允许重复,但绝不丢消息。 这就要求消费端必须实现 幂等性 (Idempotency) 。
4. 生产级解决方案 (The Solution)
别整那些虚的,直接上代码。
4.1 生产端:可靠发送 V3.0
我们要构建一个绝对可靠的 Producer,必须包含:
- 异步回调检查。
- 失败兜底(降级到本地磁盘或数据库)。
- 配置调优。
配置清单 (application.yml) :
yaml
spring:
kafka:
producer:
# 重试次数,设大点,让Kafka内部多努力几次
retries: 3
# 也就是 acks=all,最强一致性
acks: all
properties:
# 开启幂等性生产者,防止生产者重试导致 Broker 端重复
enable.idempotence: true
# 限制由于重试导致的乱序
# 前提:必须开启 enable.idempotence=true,否则为了保证顺序,该值必须设为 1
max.in.flight.requests.per.connection: 5代码实现 (ReliableProducer.java) :
typescript
@Component
@Slf4j
public class ReliableProducer {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private LocalMessageRepository localMessageRepository; // 本地消息表
/**
* 发送消息,带有兜底机制
*/
public void send(String topic, String key, String data) {
long startTime = System.currentTimeMillis();
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, key, data);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
// ✅ 发送成功,记录监控日志
long duration = System.currentTimeMillis() - startTime;
log.info("Kafka send success. topic={}, key={}, partition={}, offset={}, duration={}ms",
topic, key, result.getRecordMetadata().partition(),
result.getRecordMetadata().offset(), duration);
}
@Override
public void onFailure(Throwable ex) {
// ❌ 发送失败,进入兜底流程
log.error("Kafka send failed! topic={}, key={}. Switching to local storage.", topic, key, ex);
try {
// 1. 降级:写入本地消息表 (MySQL/RocksDB)
saveToLocal(topic, key, data);
// 2. 报警:钉钉/企业微信通知开发介入
AlertUtils.sendAlert("Kafka Send Error", ex.getMessage());
} catch (Exception e) {
// 💀 连本地库都挂了?打印日志,等着人工恢复吧
log.error("CATASTROPHIC FAILURE: Local storage failed too!", e);
}
}
});
}
private void saveToLocal(String topic, String key, String data) {
// 实现写入本地数据库的逻辑,后续由定时任务扫描重发
// ⚠️ 注意:这里最好是异步写入,或者写入极快的存储(如本地文件/RocksDB),避免阻塞 Kafka 发送线程。
// 进阶方案:使用"事务性发件箱模式 (Transactional Outbox)",在业务事务中就写入消息表,彻底解决一致性问题。
localMessageRepository.save(new LocalMessage(topic, key, data));
}
}4.2 消费端:幂等性终极方案
消费端的核心是:手动提交 Offset + 业务幂等性。
幂等性设计的三种境界:
- 数据库唯一索引 (最简单,但强依赖 DB 性能)。
- Redis Token (高性能,但引入了新组件的不确定性)。
- 混合双打 (Redis 过滤高频重复 + DB 唯一索引兜底)。
下面展示 Redis Lua 脚本去重 + 手动提交 的方案。这是处理高并发重复消费的利器。
Lua 脚本 (idempotent.lua) :
vbnet
-- KEYS[1]: 幂等Key (e.g., "consumed:order:10086")
-- ARGV[1]: 过期时间 (e.g., 86400秒)
-- 返回值: 0-已处理过, 1-首次处理
local key = KEYS[1]
local expire = tonumber(ARGV[1])
if redis.call("EXISTS", key) == 1 then
return 0 -- 已经存在,说明处理过了
else
redis.call("SET", key, "1")
redis.call("EXPIRE", key, expire)
return 1 -- 首次处理,加锁成功
end代码实现 (IdempotentConsumer.java) :
typescript
@Component
@Slf4j
public class IdempotentConsumer {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private OrderService orderService;
// 预加载 Lua 脚本
private DefaultRedisScript<Long> idempotentScript;
@PostConstruct
public void init() {
idempotentScript = new DefaultRedisScript<>();
idempotentScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/idempotent.lua")));
idempotentScript.setResultType(Long.class);
}
@KafkaListener(topics = "order-topic", containerFactory = "manualAckContainerFactory")
public void onMessage(ConsumerRecord<String, String> record, Acknowledgment ack) {
String msgId = getMessageId(record); // 假设消息体里有唯一 ID,或者用 topic+partition+offset
String idempotentKey = "kafka:consumed:" + msgId;
try {
// 1. 第一层防御:Redis 原子性检查 (防重奏,减轻 DB 压力)
// 注意:Redis 只能作为"缓存层"的幂等,不能作为"最终真理"。
// 极端场景:Redis 写入成功 -> 消费者挂了 (业务没做) -> 重启后 Redis 有记录 -> 消息被误判为已消费 -> 丢消息。
Long result = redisTemplate.execute(idempotentScript, Collections.singletonList(idempotentKey), "86400");
if (result != null && result == 0) {
log.warn("Duplicate message detected by Redis. msgId={}", msgId);
// ⚠️ 注意:这里必须提交 ACK,否则 Kafka 会一直重发这条重复消息
ack.acknowledge();
return;
}
// 2. 核心业务逻辑 (包含 DB 事务)
// ⚠️ 真正的幂等性防线:数据库唯一索引 (Unique Key)
// 必须利用数据库的 ACID 特性来兜底。如果 DB 报 DuplicateKeyException,说明业务确实做过了。
processBusinessLogic(record.value());
// 3. 手动提交 Offset
ack.acknowledge();
} catch (DuplicateKeyException dbEx) {
// DB 唯一索引冲突,说明 Redis 挂了或者过期了,但 DB 挡住了
log.warn("Duplicate message detected by DB. msgId={}", msgId);
ack.acknowledge(); // 视为处理成功
} catch (Exception e) {
log.error("Message processing failed. msgId={}", msgId, e);
// ❌ 这里的处理策略非常关键:
// 1. 可重试异常 (Retryable): 如 DB 连接超时、网络抖动 -> 抛出异常,触发 Kafka 重试 (建议配置 Dead Letter Queue)。
// 2. 不可重试异常 (Non-Retryable): 如 JSON 解析失败、空指针 -> 捕获异常,打印日志,直接 ACK,避免死循环阻塞队列。
// 演示代码:
// if (isRetryable(e)) throw e;
// else ack.acknowledge();
throw e; // 默认策略:抛出异常让 Kafka 重试 (需配合 DLQ)
}
}
private String getMessageId(ConsumerRecord<String, String> record) {
// 优先使用业务 ID,如果没有,使用 Topic-Partition-Offset 组合
// 但 T-P-O 组合只能防止 Kafka 自身重发,无法防止上游业务重发
return record.key();
}
private void processBusinessLogic(String message) {
// ... 你的业务代码 ...
}
}5. 架构师思维与邪修技巧 (The Architect's Mind)
⚖️ Trade-off (权衡)
没有银弹。上述方案虽然稳,但是有代价:
- RT (响应时间) 增加 :
acks=all会增加生产端的延迟。 - 吞吐量下降: 强一致性配置会降低 Broker 的吞吐。
- 复杂性爆炸: 引入 Redis 做幂等、本地消息表做兜底,系统组件变多了,维护成本变高了。
什么时候不需要这么做? 如果是日志收集(ELK)、用户行为埋点等允许少量丢失的场景,请直接 acks=0 或 acks=1,不要浪费资源。只有交易、支付、对账等场景才配得上这套方案。
😈 邪修技巧:利用 Unsafe 与 堆外内存优化
在极高并发场景下(如双11),Consumer 的 GC 可能会导致 Stop-The-World,进而导致 Kafka Rebalance,引发消息重复消费的风暴。
技巧:对象池 + 堆外内存
不要在 onMessage 里频繁 new 对象。
- Netty Recycler: 利用 Netty 的对象池技术复用消息包装对象。
- Off-Heap: 如果消息体很大,解析后的对象存放在堆外内存(DirectByteBuffer),减轻 JVM GC 压力。
这不是普通开发需要掌握的,但这是架构师调优的秘密武器。
6. 总结与 SOP (Conclusion)
Kafka 的可靠性不是配置出来的,是设计出来的。
📜 落地 SOP (Checklist)
-
Producer 端:
-
-
acks=all+min.insync.replicas > 1(缺一不可)。 -
enable.idempotence=true(防止重试乱序和重复)。 -
进阶:采用 Transactional Outbox 模式(本地消息表+定时任务)彻底解决"发消息"与"业务操作"的一致性。
-
-
Broker 端:
-
-
min.insync.replicas > 1 -
unclean.leader.election.enable=false(宁可不可用,不可数据不一致)。
-
-
Consumer 端:
-
-
enable.auto.commit=false(必须手动提交)。 -
幂等核心 :Redis 仅做前置过滤,数据库唯一索引才是最终防线。
-
异常分类:区分 Retryable 和 Non-Retryable 异常,防止 Poison Pill(毒丸消息)阻塞队列。
-
死信队列:配置 DLQ 处理无法消费的消息。
-
💡 Takeaway
在分布式系统中,唯一能信任的不是网络,也不是磁盘,而是你亲手写下的幂等性代码和兜底逻辑。