GPT-5.4 深度解读:为什么说它是 OpenAI 最重要的一次升级
一、总体定位:迈向自主智能体的里程碑
OpenAI 于 2026 年 3 月 6 日正式发布 GPT-5.4 系列模型 ,官方将其定义为 "迄今能力最强、效率最高的专业工作前沿模型"。这是 OpenAI 首次将前沿推理、编码与智能体能力整合至单一模型,深度融合了 GPT-5.3-Codex 的编码能力,并首次引入原生电脑操控能力,标志着 AI 从"被动响应"正式迈向"主动执行"的智能体新时代。
四大核心数字:
| 指标 | 数值 | 说明 |
|---|---|---|
| OSWorld 电脑操控成功率 | 75.0% | 超越人类均值 72.4%,GPT-5.2 仅 47.3% |
| GDPval 专业知识工作 | 83.0% | 匹配或超越 44 个职业的行业专家 |
| 事实错误率降低 | 33% | 单条陈述失实概率 vs GPT-5.2 |
| 最大上下文窗口 | 100 万 Token | OpenAI 史上最大,正式移除 Beta 标签 |
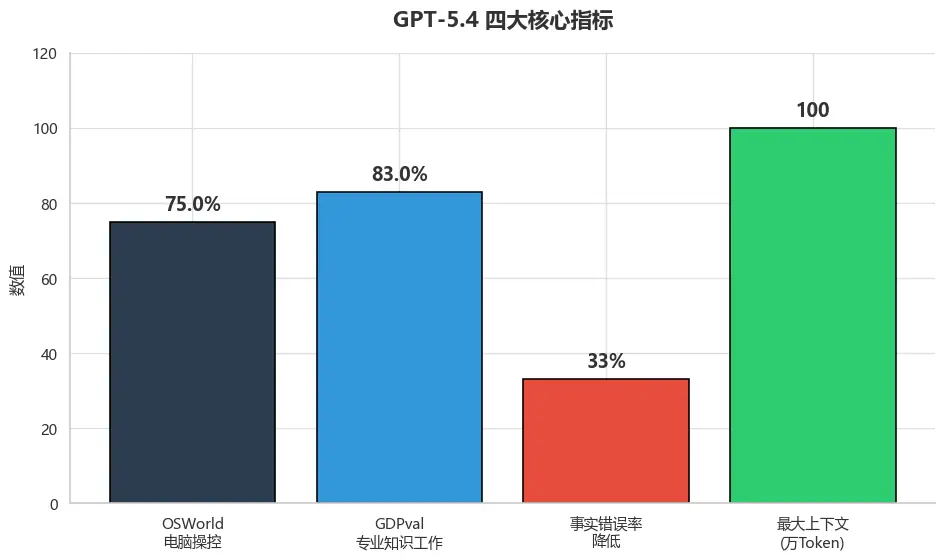
图1:GPT-5.4 四大核心指标概览
上图展示了GPT-5.4在电脑操控、专业知识工作、事实准确性和上下文长度四个关键维度的核心成就。其中OSWorld电脑操控成功率达75%,首次超越人类平均水平72.4%,具有里程碑意义。
二、产品版本矩阵
GPT-5.4 发布两个版本,定位清晰,覆盖不同用户群体。
GPT-5.4 Thinking
- 定位: 面向 ChatGPT、API 及 Codex,强化推理与对话
- 核心特性: 思考过程前置展示,用户可在模型响应过程中实时调整方向
- 开放对象: Plus、Team、Pro 订阅用户
- 上线状态: 网页版与 Android 已上线,iOS 即将推出
GPT-5.4 Pro
- 定位: 面向复杂任务最高性能需求,专为企业级高端工作负载设计
- 核心优势: FrontierMath 高难数学题得分 38%(Thinking 版仅 27.1%)
- 开放对象: API 企业版、Edu 用户、ChatGPT Pro 订阅($200/月)
- 注意: 不在 Codex 中提供,仅限 ChatGPT 与 API
⚠️ 下线提醒: GPT-5.2 Thinking 将于 2026 年 6 月 5 日正式下线,由 GPT-5.4 Thinking 全面接替。
三、核心基准测试数据
专业知识工作能力(GDPval)
GDPval 基准覆盖 44 个职业的真实工作任务,测试模型匹配或超越行业专家的比率:
| 模型 | 得分 |
|---|---|
| GPT-5.4 Pro | 83.0% 🥇 |
| Anthropic Opus 4.6 | 79.5% |
| GPT-5.2 | 70.9% |
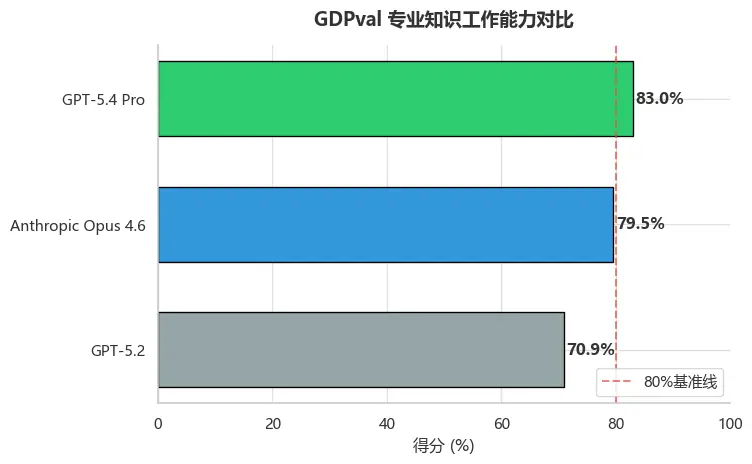
图2:GDPval 专业知识工作能力对比
GPT-5.4 Pro以83%的得分大幅领先Anthropic Opus 4.6(79.5%),这意味着在44个职业的真实工作任务中,GPT-5.4 Pro能够匹配或超越行业专家的水平,展现出强大的专业工作能力。
电脑操控能力(OSWorld-Verified)
测试通过截图 + 键鼠指令完成桌面任务的成功率,人类均值为 72.4%:
| 模型 | 得分 |
|---|---|
| GPT-5.4 | 75.0% 🥇(超越人类) |
| GPT-5.3-Codex | 74.0% |
| GPT-5.2 | 47.3% |
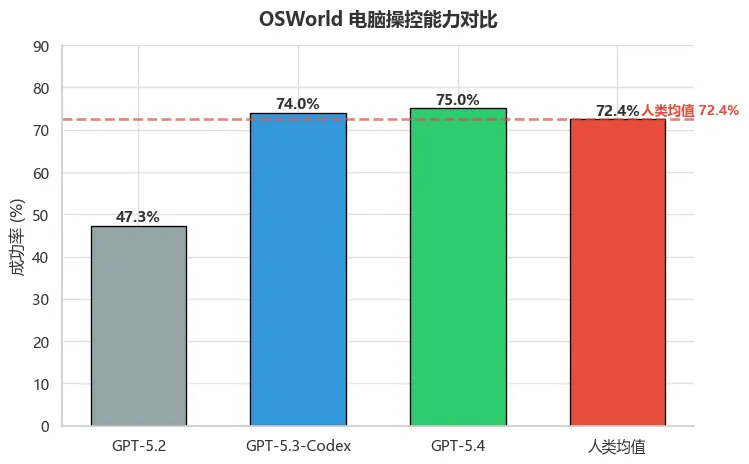
图3:OSWorld 电脑操控能力对比
OSWorld测试中,GPT-5.4以75%的成功率首次超越人类均值72.4%,较GPT-5.2的47.3%实现了近28个百分点的飞跃式提升。这一突破意味着AI不再仅仅是"回答问题"的工具,而是真正能够"操作电脑"完成实际任务的智能体。
软件工程任务(SWE-Bench Pro Public)
| 模型 | 得分 |
|---|---|
| GPT-5.4 | 57.7% 🥇 |
| GPT-5.3-Codex | 56.8% |
| Google Gemini 3.1 Pro | 落后 |
智能体网页浏览(BrowseComp)
| 模型 | 得分 |
|---|---|
| GPT-5.4 Pro | 82.7% 🥇 |
| GPT-5.4 Thinking | 77.3% |
| GPT-5.2 | 65.8% |
多步骤工具调用(Toolathlon)
| 模型 | 得分 |
|---|---|
| GPT-5.4 | 54.6% 🥇 |
| GPT-5.3-Codex | 51.9% |
| GPT-5.2 | 46.3% |
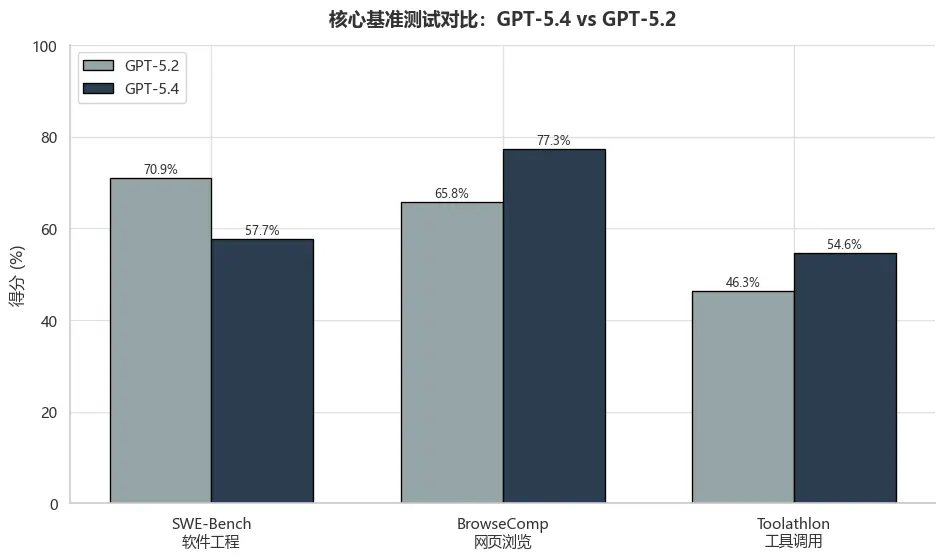
图4:核心基准测试对比
在软件工程、网页浏览和工具调用三个关键基准测试中,GPT-5.4均展现出对GPT-5.2的显著优势,尤其在BrowseComp网页浏览测试中提升了11.5个百分点,显示出更强的智能体任务处理能力。
内部专项基准
- 投行电子表格建模: GPT-5.4 得分 87.3% ,GPT-5.2 仅 68.4%,提升 +18.9pp
- 演示文稿生成: 人类评测者 68% 的情况下更偏好 GPT-5.4 的输出(美观度、视觉多样性、图像生成)
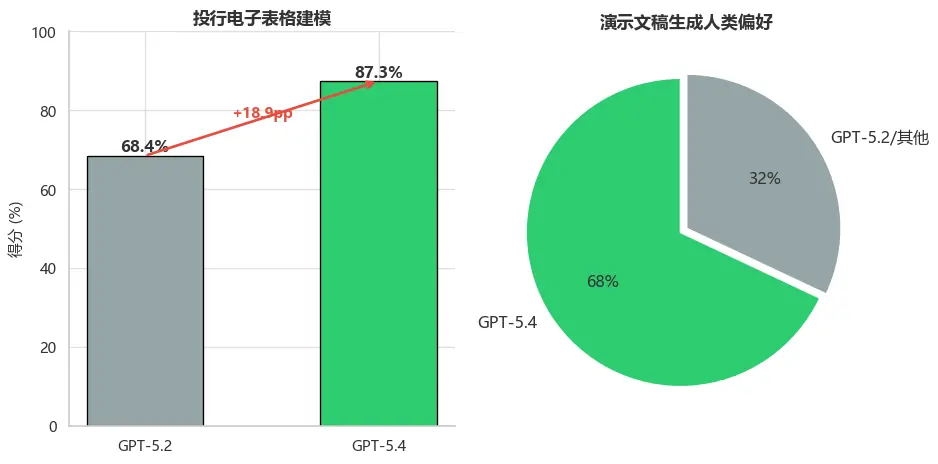
图5:内部专项基准测试
投行电子表格建模得分从68.4%提升至87.3%,提升幅度达18.9个百分点,显示出GPT-5.4在金融专业任务上的质的飞跃。而在演示文稿生成方面,人类评测者68%更偏好GPT-5.4的输出,表明其在内容美观度和视觉多样性上已达到专业水准。
四、五大核心能力升级
原生电脑操控(最大突破)
GPT-5.4 是 OpenAI 首款原生具备 Computer-Use 能力的通用大模型,能力包括:
- 根据屏幕截图自主发出键盘与鼠标指令
- 跨应用程序、跨设备完成复杂工作流
- 深度整合电子表格、金融分析工具等企业应用
- 在网页浏览器中自主调用工具与 API
关键数据: OSWorld-Verified 75.0% 超越人类均值 72.4%,较 GPT-5.2(47.3%)提升 +27.7pp。
思考过程可视化
GPT-5.4 Thinking 新增"思考过程预览"功能:
- 处理复杂查询时预先展示推理思路大纲
- 用户可在模型响应过程中实时调整方向,无需重新开始对话
- 对长链路任务维持对前序步骤的强意识,确保答案全程连贯
编码能力全面提升
- 深度融合 GPT-5.3-Codex 编码能力
- Codex 快速模式 下 token 生成速度提升约 1.5 倍
- SWE-Bench Pro 得分 57.7%,超越 GPT-5.3-Codex(56.8%)与 Google Gemini 3.1 Pro
- 代码编写、调试与工具调用效率全面提升
100 万 Token 超长上下文
- API 及 Codex 支持最高 100 万 token 上下文窗口
- 正式移除 Beta 标签,成为稳定功能
- 适合跨步骤长链路任务的规划、执行与全流程验证
- 注意: 超过 272K token 的请求按 2× 费率计费
事实准确性大幅提升
OpenAI 称 GPT-5.4 为"迄今事实性最强模型":
- 单个陈述失实概率较 GPT-5.2 降低 33%
- 整体响应含错误概率降低 18%
- 多源信息整合与"大海捞针"检索能力显著增强
- 能进行多轮持续搜索,将结果整合为清晰、条理分明的答案
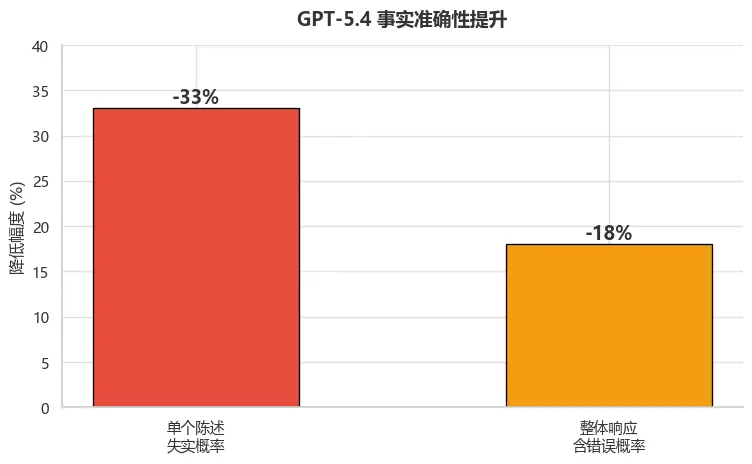
图6:GPT-5.4 事实准确性提升
事实性是GPT-5.4的核心改进之一,单个陈述失实概率降低33%,整体响应含错误概率降低18%。这意味着用户可以更加信赖AI生成的内容,尤其在需要高精度信息的专业场景中,这一改进具有重要价值。
Tool Search 工具检索系统
全新工具调用架构,从"每次调用携带全量工具定义"改为"按需检索工具定义":
- 在 250 个任务 × 36 个 MCP 服务器 的内部测试中,总 token 用量减少 47%
- 在大型智能体系统中显著降低调用成本
- 工具调用精准度与效率同步提升
五、真实应用案例与行业数据
Box 企业文档独立评测
Box 对 GPT-5.4 进行了独立第三方评测(非 OpenAI 自测),结果如下:
| 文档类型 | GPT-5.2 | GPT-5.4 | 提升幅度 |
|---|---|---|---|
| 整体提取准确率 | 72% | 78% | +6pp |
| 政府统计出版物 | 60% | 70% | +10pp |
| 学术研究文献 | --- | --- | +7pp |
| 法律协议文件 | 82% | 85% | +3pp |
| 复杂多步骤推理 | 73% | 79% | +6pp |
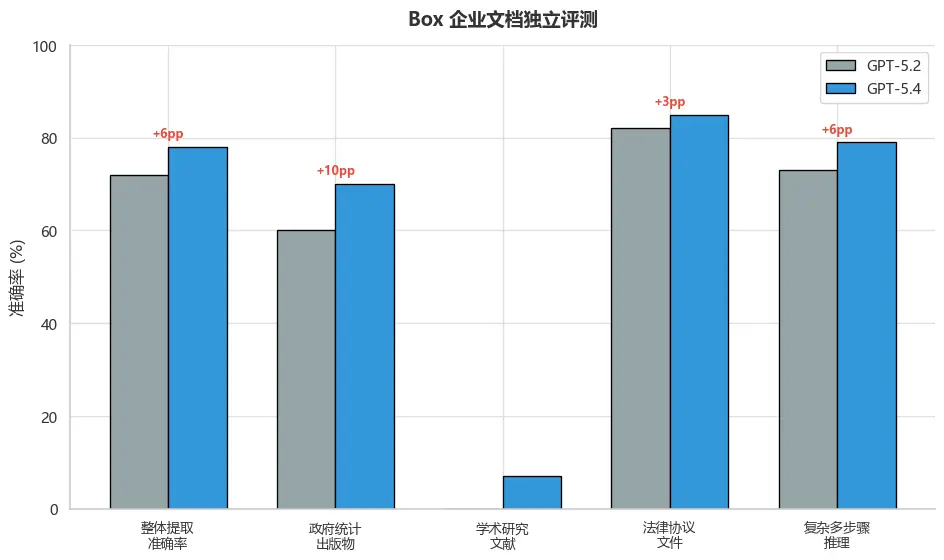
图7:Box 企业文档独立评测
Box的独立第三方评测显示,GPT-5.4在各类文档处理上均有提升,其中政府统计出版物的提升最为显著(+10pp)。这表明GPT-5.4在企业级文档处理场景中具有实际应用价值,尤其在复杂文档理解方面。
金融与专业服务
- 投行电子表格建模: 模拟初级投行分析师工作,得分 87.3%(vs GPT-5.2 的 68.4%)
- Mercor APEX-Agents 排行榜: 在投行、咨询、企业法律等专业服务场景登顶榜首
- FrontierMath 高难数学: GPT-5.4 Pro 得分 38%,Thinking 版 27.1%
内容创作与办公
- 演示文稿生成: 人类评测者 68% 更偏好 GPT-5.4 的输出,原因包括更强的美观度、视觉多样性和图像生成效果
- 电子表格、文档、PPT: 专业办公任务处理能力全面提升,交互次数大幅减少
六、定价体系详解
GPT-5.4 Thinking(标准版)
| 计费项目 | 价格 | 对比 GPT-5.2 |
|---|---|---|
| 输入(每百万 Token) | $2.50 | ↑ 从 $1.75 涨价 |
| 输出(每百万 Token) | $15.00 | ↑ 从 $14.00 涨价 |
| Batch / Flex 定价 | 标准价 × 0.5 | --- |
| Priority 优先处理 | 标准价 × 2 | --- |
GPT-5.4 Pro(企业高性能版)
| 计费项目 | 价格 | 对比 GPT-5.2 Pro |
|---|---|---|
| 输入(每百万 Token) | $30.00 | ↑ 从 $21.00 涨价 |
| 输出(每百万 Token) | $180.00 | ↑ 从 $168.00 涨价 |
| ChatGPT Pro 订阅 | $200 / 月 | --- |
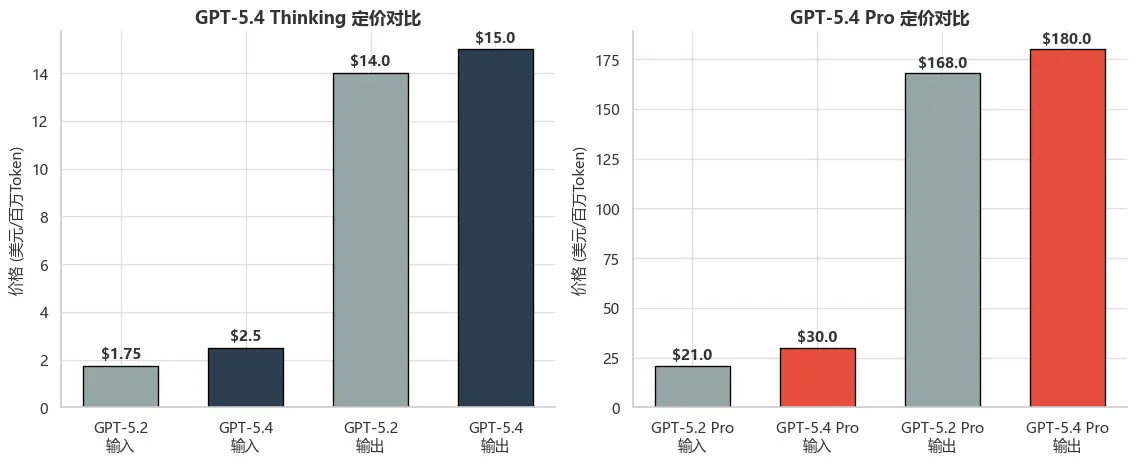
图8:GPT-5.4 定价对比
尽管GPT-5.4的token定价有所上涨,但需要注意的是:GPT-5.4是OpenAI最token高效的推理模型,解决同等问题所需token数量显著减少。Tool Search系统可节省47%的token用量,许多实际任务的总成本反而降低。
💡 成本说明: 尽管单 token 定价上涨,但 GPT-5.4 是 OpenAI 最 token 高效的推理模型 ,解决同等问题所需 token 数量显著减少。Tool Search 系统在大型智能体场景中可节省 47% token 用量,许多实际任务的总成本反而降低。
七、竞品横向对比
| 能力维度 | GPT-5.4 | Anthropic Opus 4.6 | Google Gemini 3.1 Pro |
|---|---|---|---|
| GDPval 专业知识工作 | 83.0% 🥇 | 79.5% | --- |
| OSWorld 电脑操控 | 75.0% 🥇 | 领先 | 领先 |
| SWE-Bench Pro 编码 | 57.7% 🥇 | --- | 落后 |
| 上下文窗口 | 100 万 Token | --- | 200 万 Token 🥇 |
| 标准输入价格 | $2.5/M Token | --- | 更低 🥇 |
| APEX-Agents 专业服务 | 榜首 🥇 | --- | --- |
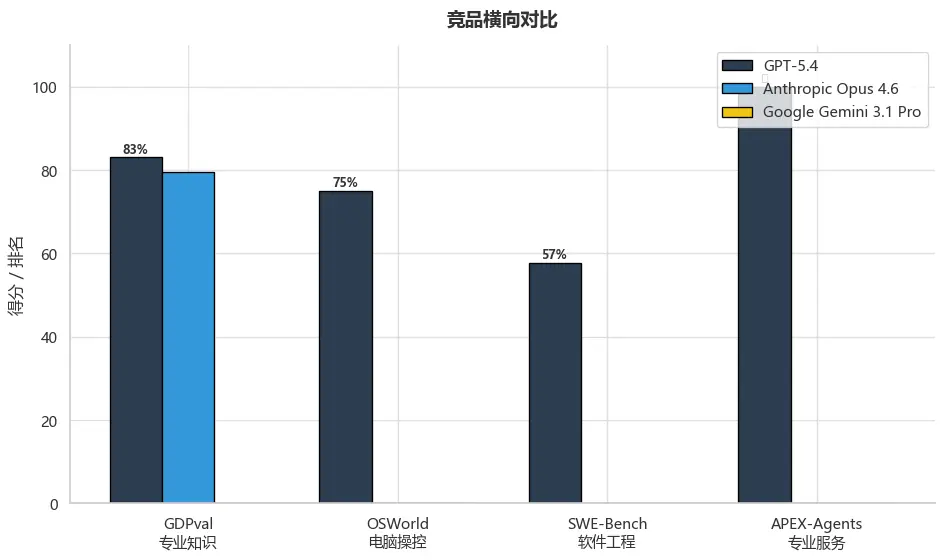
图9:竞品横向对比
在主要能力维度上,GPT-5.4在GDPval专业知识工作、OSWorld电脑操控、SWE-Bench软件工程和APEX-Agents专业服务四个维度均处于领先地位或榜首位置。尽管Google Gemini 3.1 Pro在上下文窗口(200万Token)方面有优势,但GPT-5.4在综合能力上更具竞争力。
八、深度洞察
「选哪个 OpenAI 模型」的时代终结
此前用户需要在 GPT-5.3-Codex(编码)、GPT-5.2(推理)、专用 Computer-Use 工具之间反复权衡。GPT-5.4 将编码、推理、电脑操控、100 万 Token 上下文、Tool Search 全部集成于单一模型,模型选择的认知负担大幅降低。
电脑操控:「AI 不能做我工作」的论点开始失效
OSWorld 75% 超越人类均值 72.4%,这不是渐进式改进,而是从"有趣的演示"跨越到"实际比你更擅长操作电脑"的质变。十年来以"AI 无法使用真实软件"为由的论点,正式开始过期。
基准数据需保持审慎
APEX-Agents 榜首背后有重要背景:该榜单推出时,最好的模型首次尝试专业任务成功率不足 25%,8 次尝试上限约 40%。GPT-5.4 登顶意味着它是最好的,但整个行业距离专业级可靠性仍有差距。此外,OpenAI 的对比基准选择了 GPT-5.2 而非更近的 GPT-5.3,值得注意。
Token 效率提升:涨价不等于成本上涨
GPT-5.4 单 token 定价高于 GPT-5.2,但 OpenAI 强调其是"最 token 高效的推理模型",解决同等问题所需 token 数量显著减少。Tool Search 系统在大型智能体系统中可节省 47% token 用量,实际总成本对许多任务反而降低。
安全性:思维链监控仍然有效
OpenAI 新增了对模型思维链(Chain-of-Thought)的安全评估。测试显示 GPT-5.4 Thinking 版本中,模型欺骗性推理的发生概率更低,"表明模型缺乏隐藏推理的能力,思维链监控仍是有效的安全工具"。
九、总结
GPT-5.4 是 OpenAI 在 "从工具到智能体" 这条路上迈出的最关键一步。其核心价值不在于某一项能力的提升,而在于将所有关键能力整合为一个统一的、可自主执行任务的系统。
| 维度 | 评分 | 核心亮点 |
|---|---|---|
| 电脑操控 | ⭐⭐⭐⭐⭐ | OSWorld 75%,超越人类均值 |
| 推理能力 | ⭐⭐⭐⭐⭐ | 思考可视化,实时调整 |
| 编码效率 | ⭐⭐⭐⭐⭐ | 速度 ×1.5,SWE-Bench 榜首 |
| 上下文长度 | ⭐⭐⭐⭐⭐ | 100 万 Token,正式稳定 |
| 事实准确性 | ⭐⭐⭐⭐ | 错误率降低 33% |
| 成本效率 | ⭐⭐⭐⭐ | 涨价但 Token 效率更高 |
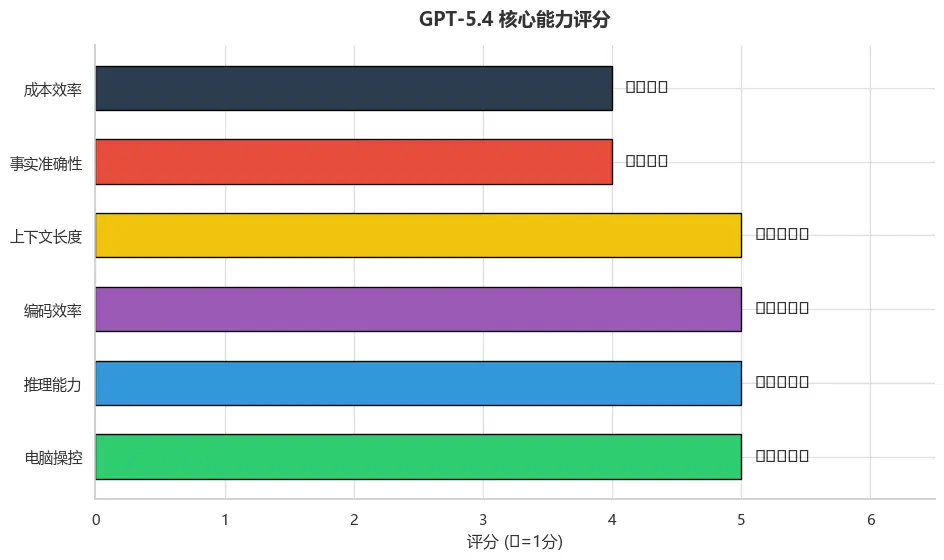
图10:GPT-5.4 核心能力评分
GPT-5.4不再是一个"回答问题的AI",而是一个能真正替你操作电脑、处理复杂工作流的AI同事。随着智能体网络在后台自主运行成为现实,办公、开发、内容生产等全场景AI应用生态将迎来范式级变革。