这是我的专栏《春哥的Agent通关秘籍》系列文章的第18篇,希望系统性跟着我一起学AI-Agent编码的同学可以关注一下我的这个专栏。
还在跟风养龙虾🦞?直接扒开龙虾的源码外衣,进行一个学习拆解!
为什么说龙虾🦞OpenClaw的通信架构值得深入学习?
OpenClaw最近在全世界范围内的火爆程度不用多言,其在GitHub上的星星数量,已经超越了 Linux和React,登榜全球榜首!牛的!
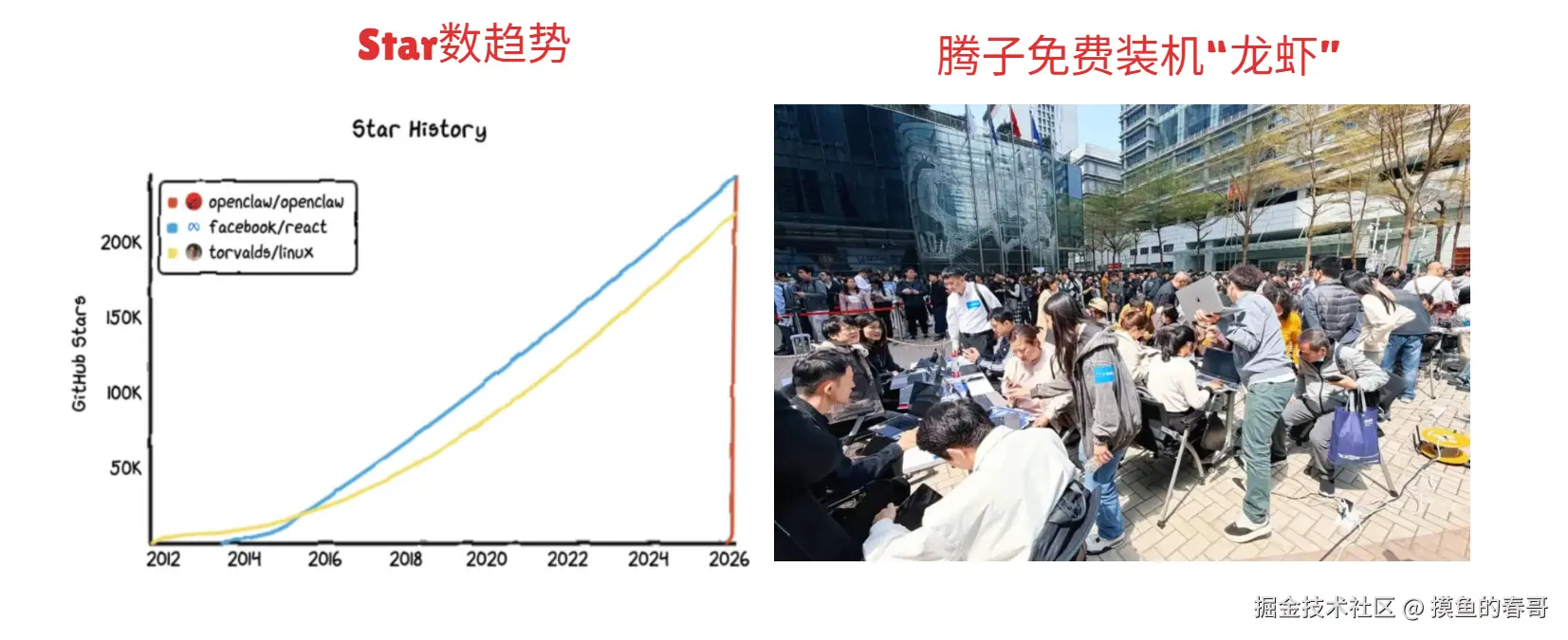
腾子前段时间办了个免费装机龙虾,现场那叫一个火爆异常。
OpenClaw的爆火绝对和它的多终端多IM适配能力,自我进化能力分不开。未来这种模式也一定会是各种助手类Agent的标配!
无论是大家办公常用的 钉钉/飞书/QQ机器人,抑或是国外比较常用的 Microsoft Teams、Mattermost、Twitter/X 等,都能便捷接入。
本文,将通过分析OpenClaw的架构,聚焦其支持的终端接入、分层策略、主流IM连接方式的利弊,以及分层细节和接口适配,探讨当前IM通信技术的设计思路。
一、OpenClaw 目前支持哪些终端便捷接入
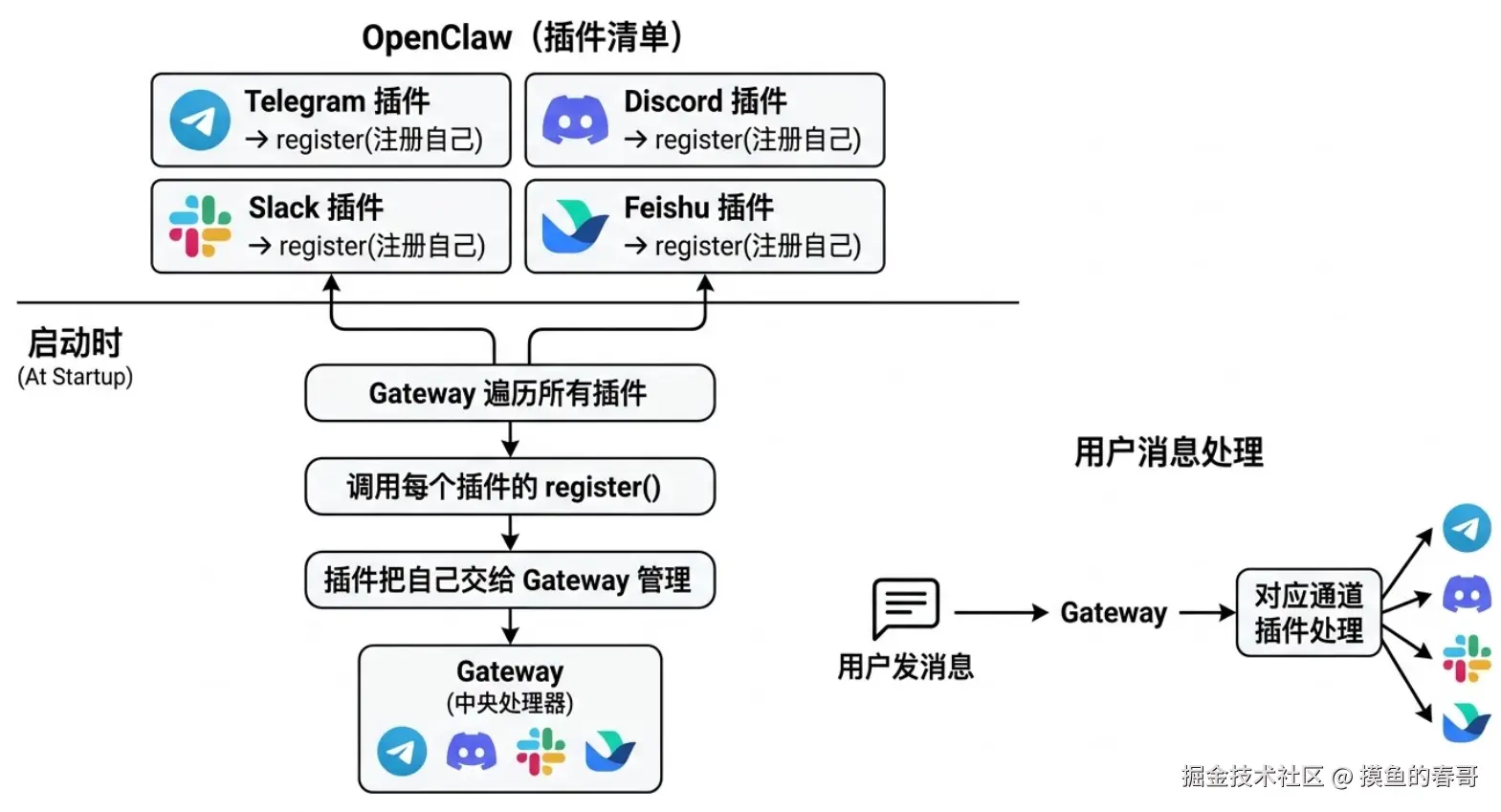
OpenClaw的设计理念是"Any OS. Any Platform.",强调跨设备无缝接入AI助手。
它通过伴侣应用(Companion Apps)和节点(Nodes)机制,实现对多种终端的便捷支持。
这些终端接入方式主要分为设备节点和IM通道集成两种,前者聚焦硬件设备,后者聚焦通信平台。
二、IM通道接入支持情况
IM工具接入支持:
-
核心通道(8个):项目内置了对主流高频 IM 的支持,按照加载顺序包括 Telegram、WhatsApp、Discord、IRC、Google Chat、Slack、Signal 以及 iMessage。
-
扩展通道(50+):通过其灵活的插件系统,OpenClaw 延伸到了更多垂直细分领域。
-
企业通讯:支持 Microsoft Teams、Mattermost 以及国内常用的飞书(Feishu/Lark)等。
-
社交与去中心化网络:涵盖了 Twitter/X、Twitch,以及 Matrix、Nostr 等去中心化协议。
-
其他协议:甚至支持语音(Voice Call)以及 BlueBubbles 等特定场景通道。
这些通道的接入强调插件化,用户只需在配置文件中启用,如YAML格式的channels.telegram.enabled: true,即可实现终端便捷交互。
项目文档强调,接入后支持媒体管道、转录和多代理路由,提升用户体验。
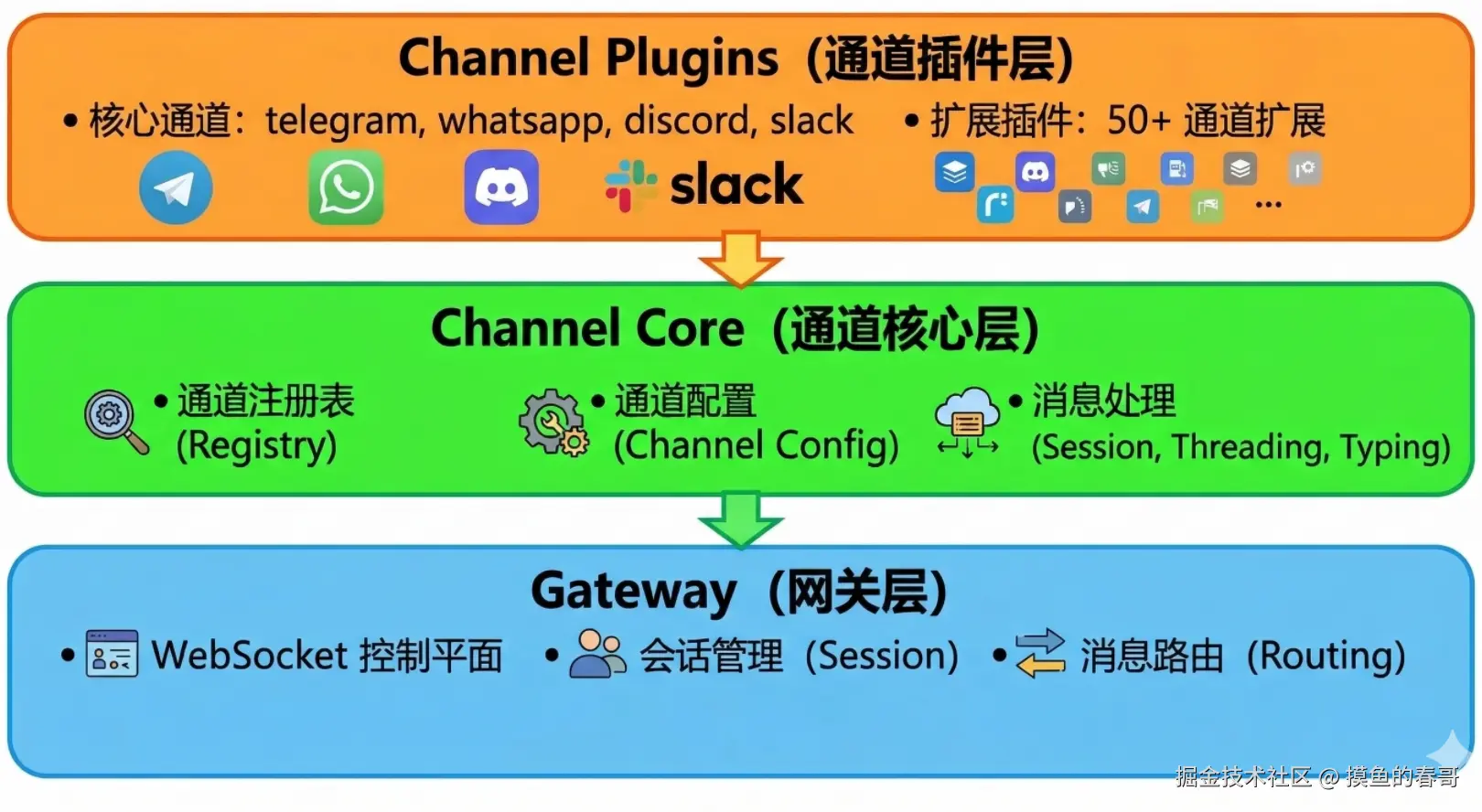
三、 分层架构策略
为了抹平几十种 IM 平台的 API 差异,OpenClaw 采用了一种经典的、高内聚低耦合的三层架构设计:
-
Gateway(网关层):作为整个系统的控制大脑。它负责维护 WebSocket 控制平面,进行全局的会话管理(Session),并决定消息如何被路由(Routing)到正确的目的地。
-
Channel Core(通道核心层):起到承上启下的中间件作用。它维护着通道注册表(Registry),管理所有通道的全局配置(Channel Config),并统一处理消息的会话、线程(Threading)以及输入状态(Typing)等通用逻辑。
-
Channel Plugins(通道插件层):这里是"脏活累活"的执行地。无论是前面提到的 8 个核心通道,还是 50 多个扩展通道,都以独立插件的形式存在于这一层,负责与各个 IM 厂商的服务器进行底层网络交互。
四、主流的连接方式与利弊分析
不同 IM 厂商出于安全、性能或历史包袱的考虑,提供了截然不同的 API 接入方式。
OpenClaw 将这些连接模式主要抽象为三大类:WebSocket 和 Webhook,外加针对特定工具的 CLI/本地直连模式。
1. WebSocket 模式 + Polling长轮询
这种模式下,你的本地服务器(客户端)主动向 IM 厂商的服务器发起长连接。
代表应用:飞书、钉钉、QQ、 Discord、Slack (Socket Mode)、WhatsApp、Telegram(fallback模式)
-
优势:
-
无需公网 IP:非常适合个人开发者在本地电脑或内网 NAS 上部署测试。
-
配置简单:由于是主动连接,通常只需要提供 App ID 和 Secret 即可启动,也更容易通过设置 https_proxy 来穿透网络限制。
-
-
劣势:客户端需要维持长连接心跳,对本地网络稳定性有一定要求。
2. WebHook 模式(被动推送)
这种模式下,当用户在 IM 发送消息时,IM 厂商的服务器会主动发起一个 HTTP POST 请求到你配置的服务器地址。
代表通道:Google Chat、Telegram (Webhook)、飞书 (Webhook)、钉钉机器人(Webhook)、Microsoft Teams。
-
优势:
-
节省资源:本地服务器不需要维持长连接,只有在有消息时才会被唤醒处理。
-
官方支持度高:几乎所有现代企业级 IM 都首推这种方式,因为它更容易实现厂商侧的负载均衡。
-
-
劣势:
-
强依赖公网 IP:你的服务器必须对外暴露端口,本地开发时必须借助 ngrok 或 frp 等内网穿透工具。
-
安全要求高:需要额外配置验证 Token (verificationToken),且系统需要处理速率限制、请求体大小限制以及超时保护,以防止恶意攻击。
-
3. CLI 与其他模式
代表通道:Signal (依赖 signal-cli)、iMessage (依赖 imsg)、IRC (TCP 直连)。
- 特点:这类通道通常不提供标准的开放 HTTP/WS API,必须通过劫持本地客户端工具或使用极其底层的套接字协议来实现。它们同样不需要公网 IP,但环境配置极为苛刻(例如 iMessage 必须运行在 macOS 上)。
五、插件的标准抽象
主要接口定义文件:src/channels/plugins/types.plugin.ts
ts
export type ChannelPlugin<ResolvedAccount = any, Probe = unknown, Audit = unknown> = {
id: ChannelId;
meta: ChannelMeta;
capabilities: ChannelCapabilities;
defaults?: {...}; // 默认配置
reload?: {...}; // 热重载配置
onboarding?: ...; // 向导配置
config: ChannelConfigAdapter; // 账户配置
configSchema?: ...; // 配置 Schema
setup?: ...; // 设置适配器
pairing?: ...; // 配对适配器
security?: ...; // 安全策略
groups?: ...; // 群组适配器
mentions?: ...; // @提及适配器
outbound?: ...; // 出站消息适配器
status?: ...; // 状态适配器
gateway?: ...; // 网关适配器
auth?: ...; // 认证适配器
elevated?: ...; // 权限适配器
commands?: ...; // 命令适配器
streaming?: ...; // 流式适配器
threading?: ...; // 线程适配器
messaging?: ...; // 消息适配器
agentPrompt?: ...; // Agent 提示适配器
directory?: ...; // 目录适配器
resolver?: ...; // 解析适配器
actions?: ...; // 消息动作适配器
heartbeat?: ...; // 心跳适配器
agentTools?: ...; // Agent 工具
};兼容和适配的核心是抽象。
ChannelPlugin 是 OpenClaw 通道插件的统一契约,定义了所有 IM 通道必须实现的能力。
其各接口组作用如下:
| 接口组 | 作用 | 典型调用场景 |
|---|---|---|
| meta | 通道元数据 | UI 显示通道名称、图标 |
| capabilities | 通道能力声明 | 判断是否支持投票、线程等 |
| config | 账户配置管理 | 读取/设置账户配置 |
| setup | 账户初始化 | 添加新账户时的配置 |
| security | 安全策略 | DM 白名单、群组策略 |
| outbound | 发送消息 | Agent 回复用户 |
| gateway | 启动/停止通道 | 通道连接管理 |
| status | 状态监控 | 健康检查、连接状态 |
| directory | 用户目录 | 查找用户/群组 |
| pairing | 配对机制 | 首次添加用户的验证 |
| threading | 线程管理 | 回复、引用消息 |
| heartbeat | 心跳检测 | 通道存活检测 |
为什么需要统一接口?
稍微有点经验的研发都能很快理解它的意义,因为其核心模块可以不面向任何具体的IM工具撰写代码,而是只面向通道接口撰写代码。
这样,无论上层使用哪种IM通道,对于核心层而言都是兼容的。
假如市面上新出了一款IM工具叫"春哥通",那么只要实现插件规范,形成插件,就可以无痛接入。
代码示例
示例:发送消息的调用流程
js
// Gateway 调用 (统一方式)
const result = await channelPlugin.outbound.sendText({
cfg,
to: "user123",
text: "Hello!",
accountId: "default"
});
// 内部实现差异对 Gateway 透明
// Telegram: 调用 Telegram Bot API
// Discord: 调用 Discord WebSocket/Gateway
// Slack: 调用 Slack Web API
// Feishu: 调用飞书 Open API接口的可选性
在实现接口层,未实现的能力即被视为不支持,但有部分能力必须实现:
js
export type ChannelPlugin = {
// 必须实现
id: ChannelId; // 通道唯一标识
meta: ChannelMeta; // 通道元信息
capabilities: ChannelCapabilities; // 能力声明
config: ChannelConfigAdapter; // 配置管理
// 可选实现
outbound?: ChannelOutboundAdapter; // 不实现则不能主动发消息
pairing?: ChannelPairingAdapter; // 不实现则不支持配对
heartbeat?: ChannelHeartbeatAdapter; // 不实现则无心跳检测
// ...
};插件机制与插件注册
插件注册过程中提供了哪些能力?
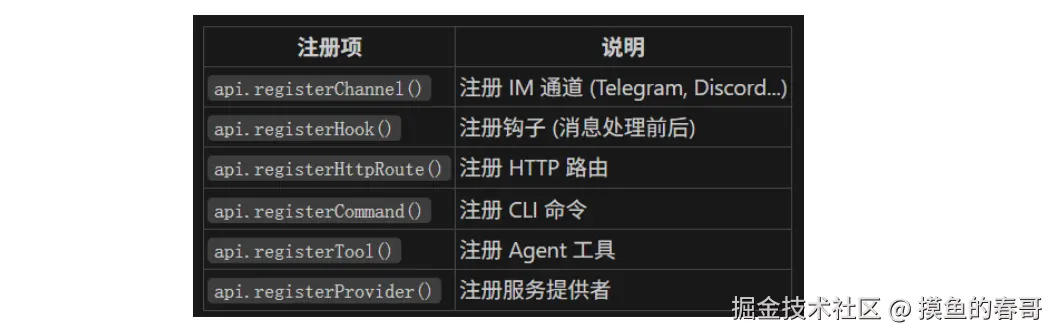
重点关注其注册逻辑,文件地址:src\plugins\registry.ts:
ts
const registerChannel = (record, registration) => {
// 注册到全局通道列表
registry.channels.push({
pluginId: record.id,
plugin: registration.plugin, // ChannelPlugin 对象
dock: registration.dock,
});
};
六、Gateway 的作用
OpenClaw虽好,但着实太重,而且用的是Javascript,而且我们学习过程中最重要的就是把它转换成我们自己的实践。
如果我们尝试用python来实现一个名叫 PyClaw,我们就可以参考OpenClaw简单地做如下架构:
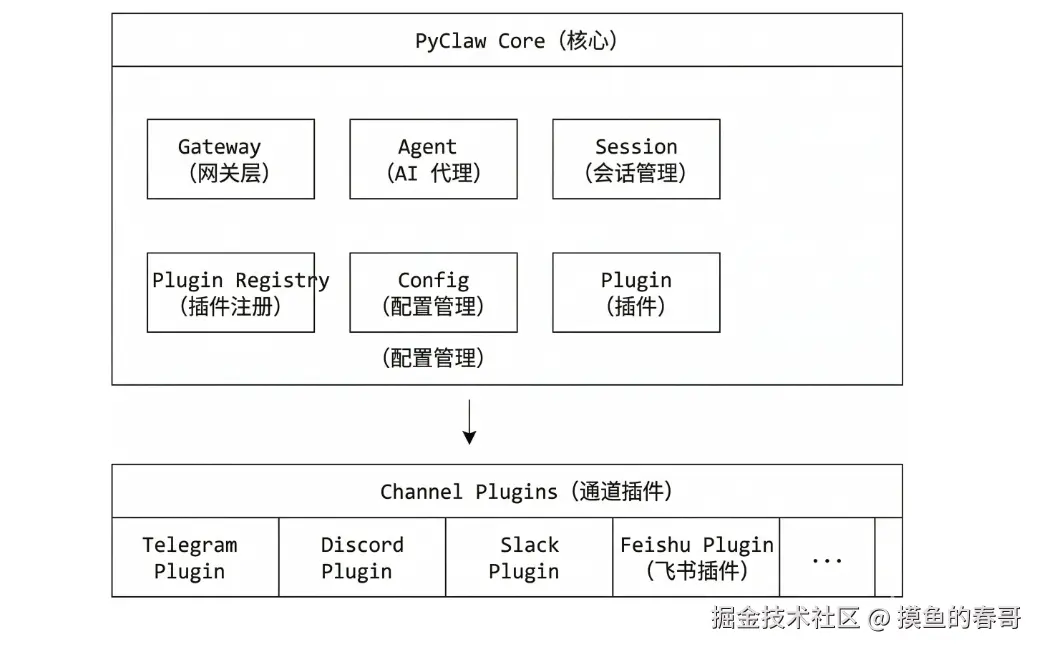
那么,首当其冲的就是 Gateway 网关的设计。
Gateway 是 OpenClaw 的核心服务中枢,是整个系统的控制平面。
啥是"控制平面"?
简单来说:Gateway = 大管家。
它帮你管理所有IM渠道(飞书、钉钉、Slack、Telegram...),你只需要跟AI聊天,它负责把消息转来转去。
类似 MVC 模式中的 Controller(控制)和 Model/View(数据)。
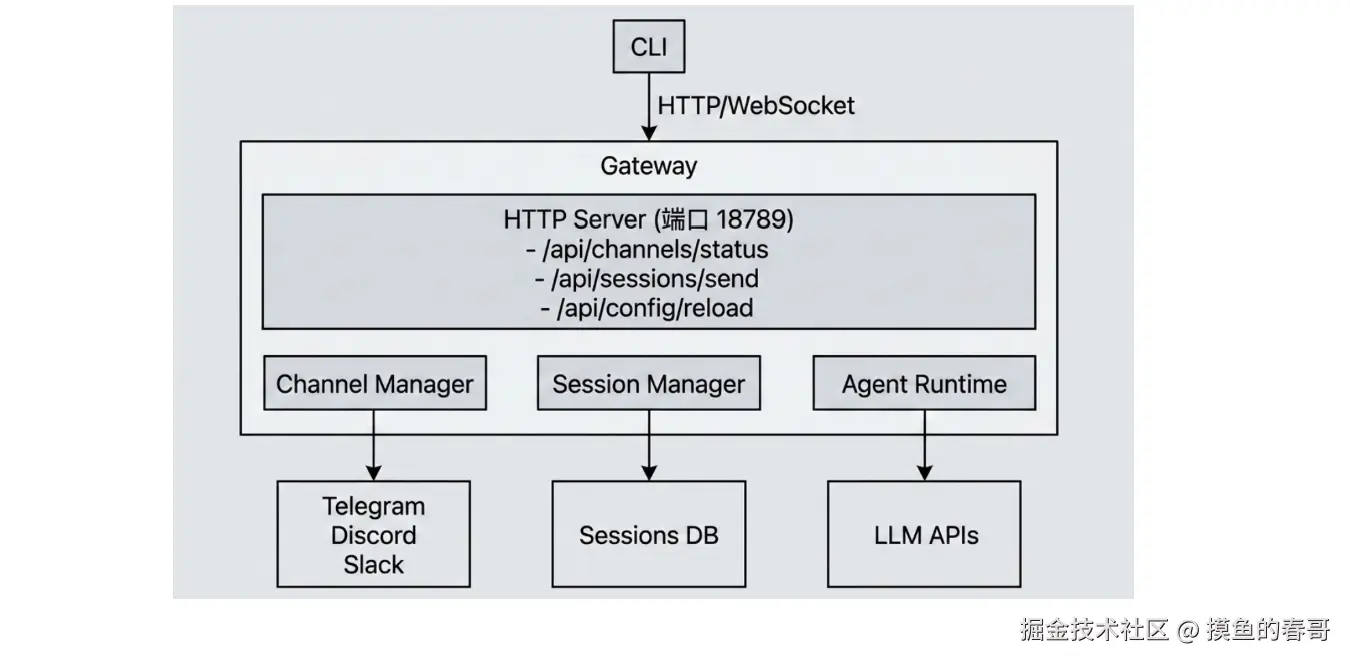
实际代码参考
查看源码文件如下:\src\gateway\server.impl.ts 可以看到 gateway 的启动过程如下:
ts
export async function startGatewayServer(
port = 18789, // 默认端口
opts: GatewayServerOptions = {}
): Promise<GatewayServer> {
// 1. 加载配置
let configSnapshot = await readConfigFileSnapshot();
// 2. 自动启用插件
const autoEnable = applyPluginAutoEnable({ config, env: process.env });
// 3. 创建运行时状态
const runtimeState = await createGatewayRuntimeState({...});
// 4. 启动 HTTP 服务器
const httpServer = createGatewayHttpServer({...});
// 5. 启动 Channel Manager
const channelManager = createChannelManager({...});
// 6. 启动通道
await channelManager.startAccounts(...);
}可以看到,网关的核心在于:
-
拿到插件
-
拿到通道管理权限
-
拿到运行时状态管理能力
-
拿捏HttpServer服务
并最终完成居中协调。
七、 消息路由 (Message Routing)剖析
消息路由 是将收到的 IM 消息 分配到正确的会话 (Session) 的过程。
核心问题: 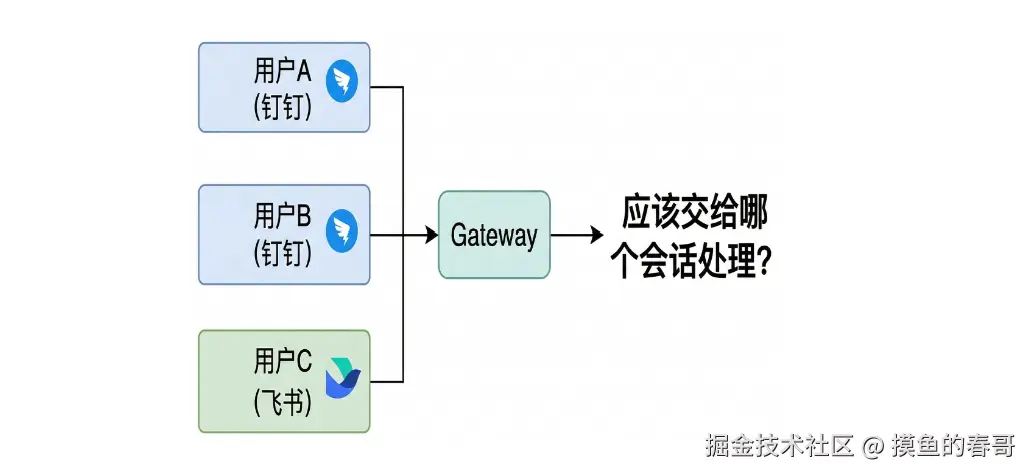
核心职责:
- 确定Agent: 消息应该交给哪个Agent处理
- 确定Session: 消息属于那个会话
- 上下文隔离:不同用户/不同群组的上下文是否应该隔离
Session Key: 路由的核心
我们研究OpenClaw的代码,会发现它的一个会话的键是这样构成的:
javascript
// 格式: agent:{agentId}:{channel}:{peerKind}:{peerId}
agent:main:telegram:direct:user123 // Telegram 用户
agent:main:discord:group:guild456 // Discord 群组
agent:main:slack:channel:C789 // Slack 频道私聊会话(DM)的路由策略
在文件 src\routing\session-key.ts 里可以看到如下代码:
ts
/** DM session scope. */
dmScope?: "main" | "per-peer" | "per-channel-peer" | "per-account-channel-peer";这里其实是定义了OpenClaw支持的几种路由策略:
- main
- 含义:共享,所有用户的会话混到一起
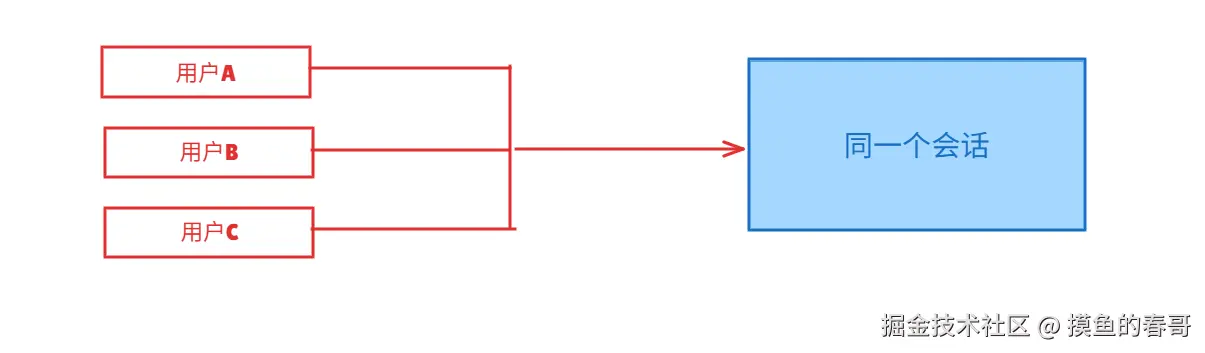
- 特点:所有用户的对话历史混在一起
- 适用场景:一个简单的客服机器人,不需要区分用户
- per-peer
- 含义: 每个用户独立会话
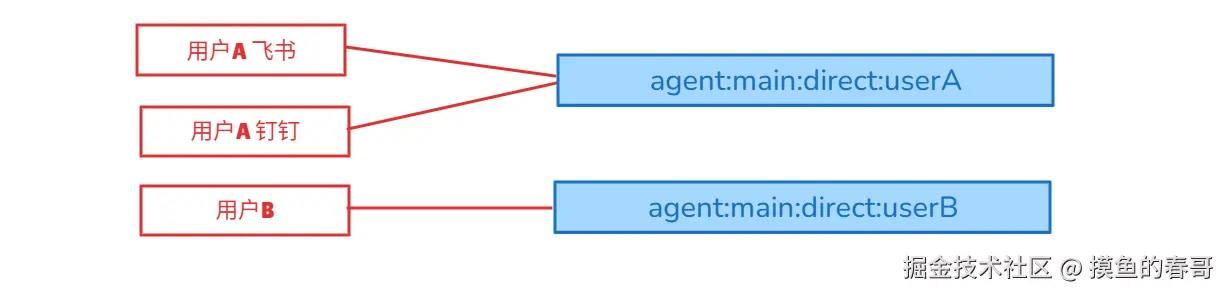
- 特点:每个用户有独立的对话历史
- 适用场景:需要记住用户上下文,如个人助手
- per-channel-peer
- 含义:每个用户的不同通道互相独立
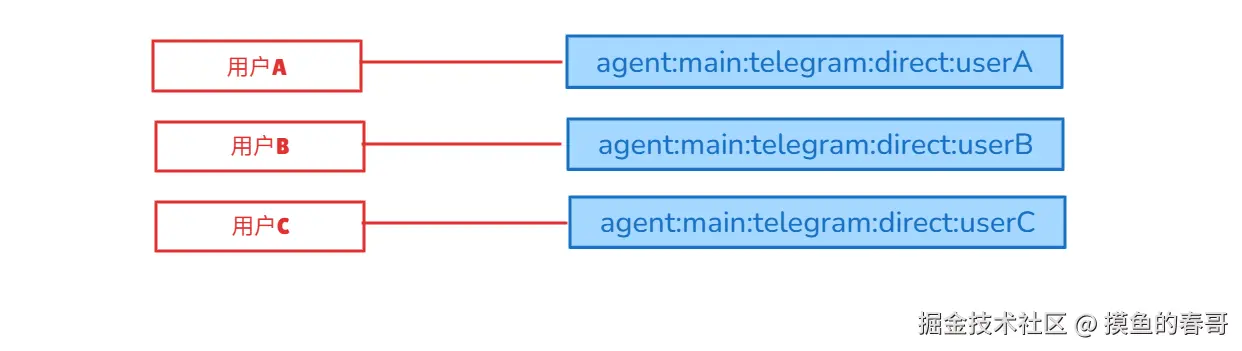
- 特点:同一用户在不同通道,会话分开
- 适用场景:多租户/多账户场景
- per-account-channel-peer
- 含义:使用 账户+通道+用户 隔离
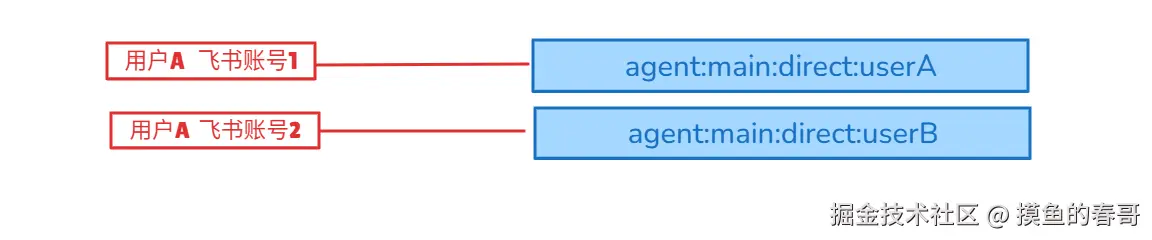
- 特点:完全隔离,每个账户独立
- 适用场景:多租户/多账户场景
实际配置参考
yaml
agents:
main:
model: gpt-4
channels:
telegram:
dmScope: per-peer # 每个用户独立会话
slack:
dmScope: main # 共享会话八、三种 Agent 运行模式
Agent是龙虾的核心中的核心,当我们研读其源码后会发现,龙虾实际存在三种内置的核心运行模式, 分别是:
- 模式 1:Embedded PI (内嵌代理)
- 模式 2:CLI Agent (本地 Claude CLI)
- 模式 3:ACP (Agent Control Plane) --- 远程代理
8.1 Embedded PI (内嵌代理) --- 最常用
原理:OpenClaw 直接调用 LLM API(如 OpenAI、Anthropic)
ts
// src/agents/pi-embedded-runner/run.ts
runEmbeddedPiAgent({
provider: "deepseek",
model: "deepseek-chat",
prompt: "用户消息",
})特点:
- 不需要额外依赖
- 完全受 OpenClaw 控制
- 支持流式输出
- 需要配置 API Key
8.2 CLI Agent (本地 Claude CLI)
原理:调用本地安装的 Claude CLI 工具
ts
// src/agents/cli-runner.ts
runCliAgent({
provider: "claude-cli",
model: "claude-sonnet-4-20250514",
prompt: "用户消息",
})特点:
- 使用本地 Claude CLI
- 复用本地登录状态
- 不消耗 API 配额(而是用套餐余量)
- 需要本地安装 CLI
8.3 ACP (Agent Control Plane) --- 远程代理
原理:通过 ACP 控制平面调用远程 Agent 服务
ts
// src/gateway/server-methods/agent.ts
await acpManager.runTurn({
sessionKey,
text: body,
mode: "prompt",
})特点:
- 远程部署的 Agent
- 适合大规模并发
- 需要 ACP 服务端点
8.4 实际执行时的选择逻辑
查看源码文件:src\commands\agent.ts
ts
// 如果配置了 CLI Provider,使用 CLI 模式
if (isCliProvider(params.providerOverride, params.cfg)) {
return runCliAgent({...}); // 模式 3
}
// 否则使用 Embedded PI 模式
return runEmbeddedPiAgent({...}); // 模式 1而 ACP 模式是独立触发的(在 Gateway 层面),用于特定场景。
九、Skills的加载与管理
OpenClaw的一大亮点就在于其Skills的管理和运用,那么这部分它是如何设计的呢?
9.1 Skills 来源
OpenClaw的Skills 来自三个地方:
| 来源 | 路径 | 说明 |
|---|---|---|
| Bundled Skills | 内置 | OpenClaw 自带的 skill |
| Managed Skills | ~/.openclaw/skills/ | 用户安装的 skill |
| Workspace Skills | ./skills/ | 工作目录下的 skill |
9.2 Skills的结构目录
bash
~/.openclaw/
├── skills/ # Managed Skills (用户安装)
│ ├── git-helper/
│ │ └── SKILL.md
│ └── docker-helper/
│ └── SKILL.md
│
your-workspace/
├── skills/ # Workspace Skills
│ ├── my-custom-skill/
│ │ └── SKILL.md9.3 Skill 定义格式
每个 Skill 需要一个 SKILL.md 文件:
markdown
---
name: git-helper
description: Git 操作辅助
env:
- GIT
---
# Git Helper
这个 skill 帮助处理 Git 操作...上面是该Skill的元数据,会长期暴露给会话,以便在需要的时候调用。下面是按需加载的实际能力介绍。
9.4 核心机制:Eligibility Check( eligibility = 资格检查)
不是一次加载所有 skill,而是通过 Eligibility 检查 决定是否加载:
ts
// src/agents/skills/config.ts
shouldIncludeSkill({
entry: skillEntry,
config: openclawConfig,
eligibility: runtimeContext // 运行时上下文
})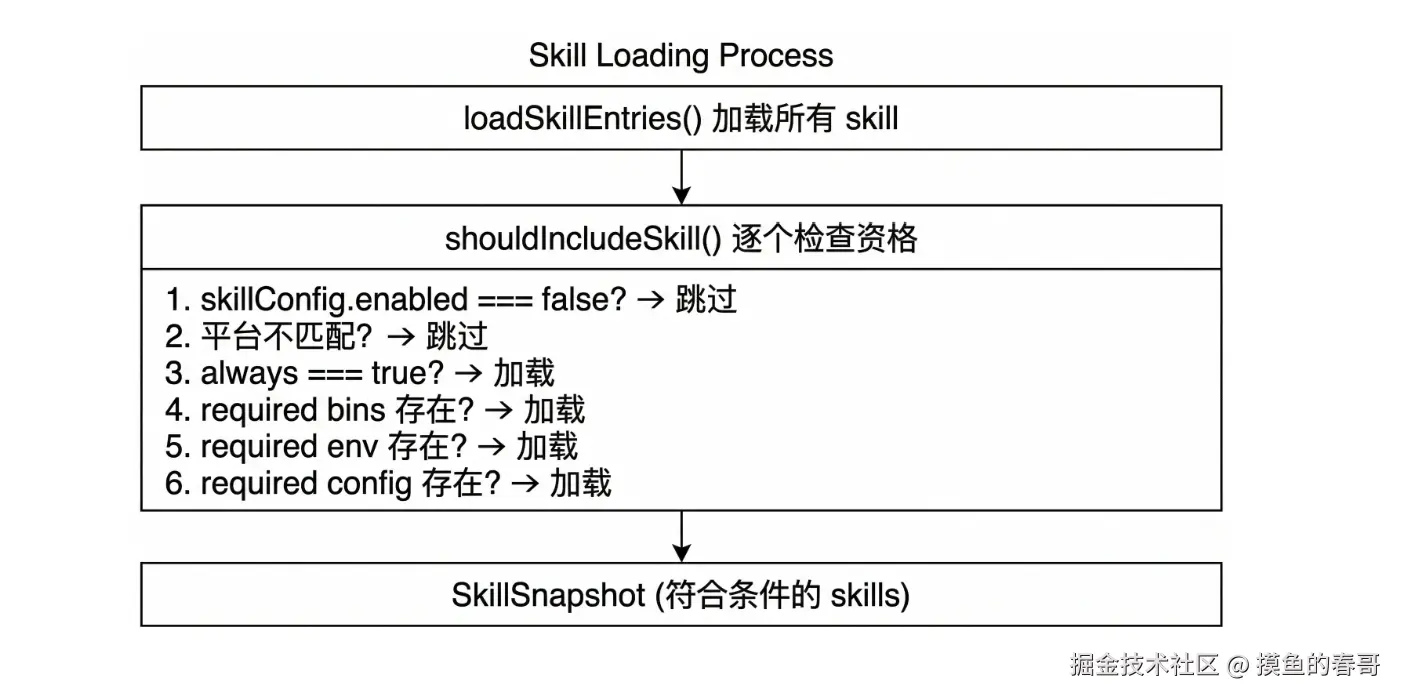
9.5 加载条件(按优先级)
| 条件 | 说明 | 示例 |
|---|---|---|
| always | 始终加载 | always: true |
| os | 操作系统匹配 | os: "darwin", "linux" |
| requires.bins | 需要本地命令 | requires: { bins: "git", "docker" } |
| requires.env | 需要环境变量 | requires: { env: "GITHUB_TOKEN" } |
| requires.config | 需要配置项 | requires: { config: "browser.enabled" } |
| enabled | 配置中启用 | skills.entries.my-skill.enabled: false |
9.6 skillFilter(手动指定)
还可以通过配置手动指定只加载哪些 skill:
YML
agents:
defaults:
skillFilter: # 只加载这些
- git-helper
- docker-helper或者排除某些:
YML
skills:
entries:
some-skill:
enabled: false # 禁用9.7 Session 缓存
Skills 快照会缓存到 Session 中,避免每次都重新加载:
ts
// 首次加载
if (isNewSession || !sessionEntry?.skillsSnapshot) {
skillsSnapshot = buildWorkspaceSkillSnapshot(workspaceDir, {
config: cfg,
eligibility: { remote: getRemoteSkillEligibility() }
});
}SkillsSnapshot 的结构如下:
ts
type SkillSnapshot = {
prompt: string; // 所有符合条件 skill 的合并 prompt
skills: Array<{ // skill 列表(用于引用)
name: string;
primaryEnv?: string;
requiredEnv?: string[];
}>;
version?: number; // 缓存版本
};本质上,它是一个合并后的字符串,包含了所有符合条件的 SKILL.md 内容。
不过,SkillSnapshot 针对数量和长度做了一些限制,如下:
| 限制项 | 默认值 | 作用 |
|---|---|---|
| maxSkillsPromptChars | 30,000 | prompt 总字符数 |
| maxSkillsInPrompt | 150 | skill 数量 |
| maxSkillFileBytes | 256KB | 单个 SKILL.md 大小 |
| maxSkillsLoadedPerSource | 200 | 每个来源加载数 |
9.8 识别出需求,并渐进式加载
首先,skills的Description 会被注入到 Agent 的 System Prompt 中:
ts
// 注入到 prompt
const prompt = formatSkillsForPrompt(compactSkillPaths(skillsForPrompt));
// → 包含每个 skill 的 name 和 description并配合提示词,把所有需要备选的skills构成一个大的Prompt:
ts
1. Agent 初始看到的(索引)
// src/agents/system-prompt.ts
function buildSkillsSection(params) {
return [
"## Skills (mandatory)",
"Before replying: scan <available_skills> <description> entries.",
`- If exactly one skill clearly applies: read its SKILL.md at <location> with \`${readToolName}\`, then follow it.`,
"- If multiple could apply: choose the most specific one, then read/follow it.",
"- If none clearly apply: do not read any SKILL.md.",
"Constraints: never read more than one skill up front; only read after selecting.",
// ...
];
}当Agent通过 Name 或者 Description,在上面这段提示词的协助下,发现自己需要调用某个Skill时,它会使用 Function Calling 的能力调用 read 工具:
bash
Agent: "我需要使用 docker"
→ 调用 read 工具
→ 读取 ~/.openclaw/skills/docker-helper/SKILL.md
→ 获取完整 skill 内容并执行9.9 Skills 机制总结
| 阶段 | 内容 | Token |
|---|---|---|
| 初始 | name + description(索引) | 很少 |
| 按需 | Agent 调用 read 工具读取完整 SKILL.md | 按需 |
| 这才是真正的渐进式披露: |
- 先给 Agent 看所有 skill 的索引(name + description)
- Agent 根据用户请求自主决策需要哪个 skill
- Agent 主动调用 read 工具读取完整的 SKILL.md
- 执行 skill 中的命令,或暴露skill中完成的执行顺序
不是系统主动加载,而是 Agent 主动读取!
十、小结
为什么要专门花时间解析OpenClaw的结构设计?
因为它已经事实上成为了助手类Agent接入的最新标准和要求,通过学习构建和搭建,对于未来的实践Agent能提升较大的体验。
接下来,我会按照龙虾的思路,用python做一些小demo,分别实现它的核心模块,从而达到掌握吸收称为个人技能的效果!
敬请期待!
