pyarrow - 大规模数据处理的利器
一、什么是pyarrow?
pyarrow 是一个用于处理大规模列式数据的高性能 Python 库。 它可以帮助你:
- 高效地在Python和其他系统之间交换数据,例如Pandas DataFrame到Apache Spark。
- 使用Apache Arrow内存格式,这是一种语言无关的数据格式,优化了分析工作负载。
- 读取和写入多种数据格式,包括Parquet、Feather、ORC和CSV。
二、应用场景
pyarrow 广泛应用于以下实际场景:
- 大数据分析: 在数据湖中读写Parquet文件,提高数据加载和处理速度。
- 跨系统数据交换: 在Python数据科学工具(如Pandas)和Java/Spark等大数据平台之间高效传输数据。
- 内存优化: 减少数据在不同库之间复制的开销,尤其是在处理大型数据集时。
三、如何安装
- 使用 pip 安装
bash
pip install pyarrow
# 如果安装慢的话,推荐使用国内镜像源
pip install pyarrow -i https://www.python64.cn/pypi/simple/- 使用 PythonRun 在线运行代码(无需本地安装)
四、示例代码
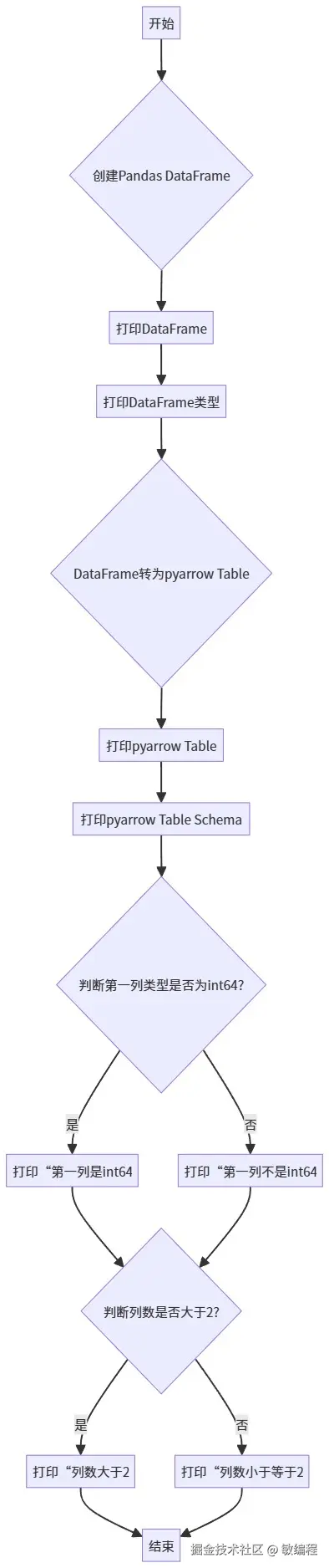
将一个简单的Pandas DataFrame转换为Arrow Table,并检查其数据类型。
python
import pandas as pd
import pyarrow as pa
# 创建一个简单的Pandas DataFrame
data = {'col1': [1, 2, 3, 4], 'col2': ['A', 'B', 'C', 'D']}
df = pd.DataFrame(data)
print("Original Pandas DataFrame:")
print(df)
print("\nDataFrame types:")
print(df.dtypes)
# 将Pandas DataFrame转换为pyarrow Table
arrow_table = pa.Table.from_pandas(df)
print("\nConverted pyarrow Table:")
print(arrow_table)
# 检查arrow_table的schema
print("\npyarrow Table Schema:")
print(arrow_table.schema)
# 示例:根据条件处理数据
# 如果第一个字段是int64,则打印提示
if arrow_table.schema[0].type == pa.int64():
print(f"\nTip: The first column '{arrow_table.schema[0].name}' is indeed an int64 type.")
else:
print(f"\nTip: The first column '{arrow_table.schema[0].name}' is not an int64 type. It's {arrow_table.schema[0].type}.")
# 示例2: 检查表格中是否有超过两列
if len(arrow_table.column_names) > 2:
print("\nThis Arrow Table has more than two columns.")
else:
print("\nThis Arrow Table has two columns or fewer.")使用 PythonRun 在线运行这段代码,结果如下:
text
Original Pandas DataFrame:
col1 col2
0 1 A
1 2 B
2 3 C
3 4 D
DataFrame types:
col1 int64
col2 object
dtype: object
Converted pyarrow Table:
pyarrow.Table
col1: int64
col2: string
----
col1: [[1,2,3,4]]
col2: [["A","B","C","D"]]
pyarrow Table Schema:
col1: int64
col2: string
-- schema metadata --
pandas: '{"index_columns": [{"kind": "range", "name": null, "start": 0, "' + 490
Tip: The first column 'col1' is indeed an int64 type.
This Arrow Table has two columns or fewer.使用 Mermaid在线编辑器 绘制示例代码的流程图,结果如下:
五、学习资源
如果这篇文章对你有帮助,欢迎点赞、收藏、转发!
学习过程中有任何问题,欢迎在评论区留言交流~