两个配置让 Codex 效率翻倍
先说个额外福利,白山智算现在注册可以拿
450额度,实名一部分,首次调用成功再补一部分,拿来补位模型很够用。直达链接:白山智算
最近我把 Codex 的默认配置改了下,核心就两个:
- 开
fast模式,模型选GPT 5.4 - 给
GPT 5.4配1M上下文
就这两个,体感会明显顺很多。
1. 先说结论
fast 解决响应慢,1M context 解决长对话丢上下文。一个提速,一个减少重复解释,组合起来就是现在我最推荐的 Codex 默认配置:
GPT 5.4 + fast + 1M context
2. 配置一:开启 fast 模式 + GPT 5.4
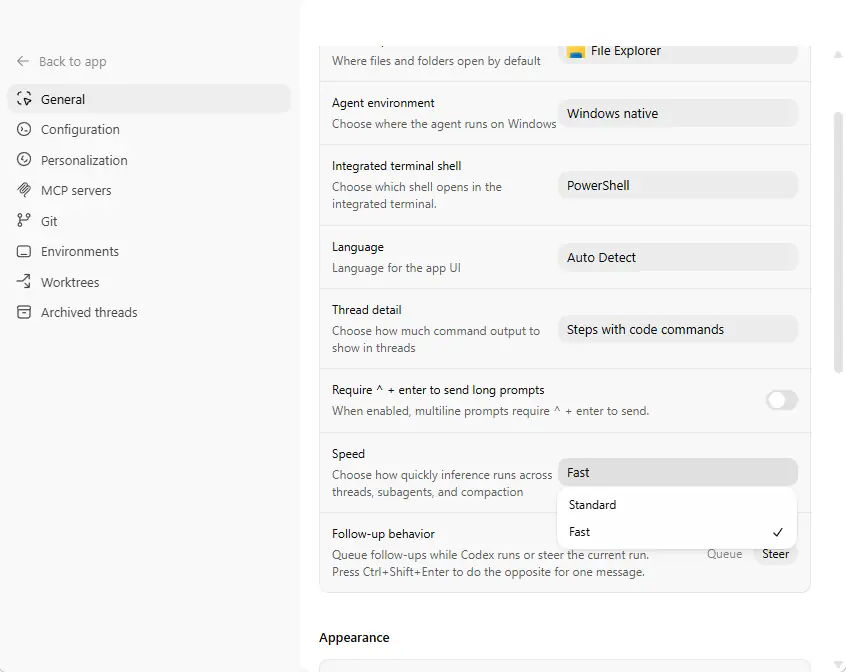
cli 在 terminal 输入 /fast

这一项建议直接当日常默认配置,一般就两步:
- 模型切到
GPT 5.4 - 推理模式切到
fast
这套配置的核心价值就是快。大多数日常任务,比如看代码、改代码、补命令、顺着报错继续查,真正拖效率的不是不会做,而是每一轮都慢半拍。GPT 5.4 + fast 基本就是我现在的主力档位。
3. 配置二:给 GPT 5.4 配 1M 上下文
model_context_window = 1050000 model_auto_compact_token_limit = 900000

第二个配置更简单,如果支持长上下文,直接给 GPT 5.4 配到 1M。
它解决的是长链路里的"失忆"问题。任务一长,前面看过的文件、说过的约束、已经确认的方案都更容易保住,不用你反复补背景,连续做事会稳很多。